Constrained method
We cannot sit and hope that the "most likely" token is correct. We need to stop treating the LLM like a black box, and intervene in the sampling process.
We use constrained decoding to do this.
How it works
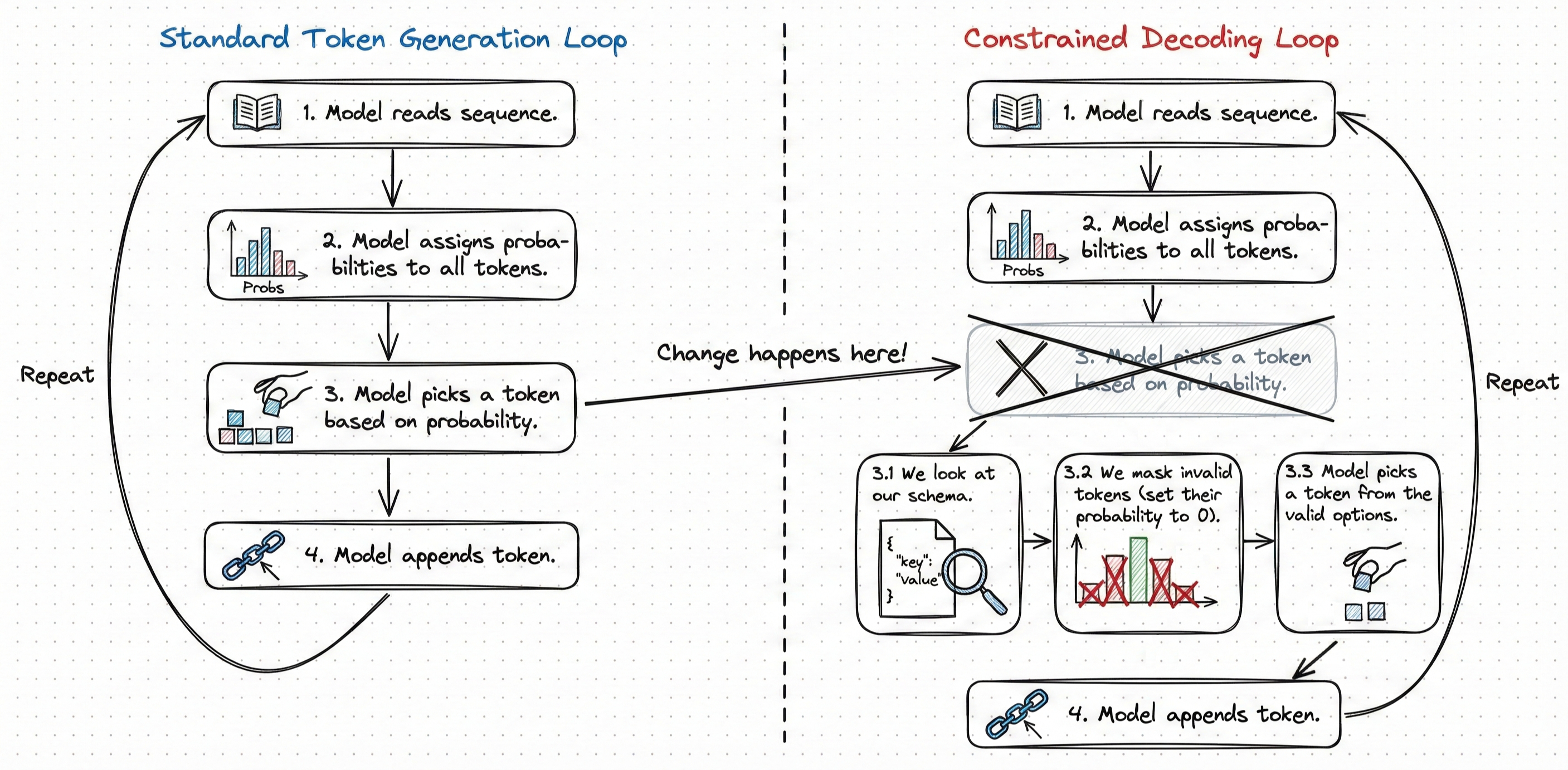
An LLM produces output one token at a time. To produce a token, it calculates a probability distribution over its entire token vocabulary. Then, it picks a token from the probability distribution using a sampling algorithm.
We change this:
-
The LLM calculates a probability distribution over its entire token vocabulary.
-
We check all the tokens in the probability distribution against our schema.
-
We identify tokens that will break our schema if picked in the current token generation step.
-
We manually set the probabilities of these "invalid tokens" to 0.
-
The LLM picks a token from the remaining "valid tokens".
This is called token masking.
Revisiting the example
Here's the JSON output we wanted in our chatbot:
{
"customer": {
"id": "C-10322",
"name": "Ariana Reed"
},
"order": {
"items": [
{"sku": "BW-CITRUS", "qty": 3},
{"sku": "CANDLE-LAVENDER", "qty": 1}
],
"total_usd": 54.00,
"discount_usd": 10.00
}
}
Here's a simulation of constrained decoding generating the above JSON output:
Token Step 1
The LLM reads the prompt and starts producing the first token. In a normal run, it will pick Sure. After token masking, it picks { from the remaining "valid tokens".
SureHere{{"{"customer"{"cust{'cust{"id":{"order":SureHere{{"{"customer"{"cust{'cust{"id":{"order":After the last key "discount_usd": 10.00 and closing braces }}, constrained decoding masks all the vocabulary tokens except the "end-of-sequence" token, and the output stops.
The constrained decoding approach will never produce an output that violates our schema.
Constrained decoding enforces the schema, while the LLM is still responsible for filling in the values within the schema.
How to implement
Implementing constrained decoding from scratch is a complex task:
- We need to check every single token in the LLMs vocabulary (>32k tokens) against our schema, and we need to do this for every output token. This runs on CPUs, while LLMs run on incredibly fast GPUs. If the CPU lags, the GPU sits idle waiting for the token mask. This increases latency and costs. We need efficient data structures to check the vocabulary against the schema.
- The LLM doesn't know its probability distribution is being masked. The LLM might pick a token allowed by the mask in the current step, with the expectation that it will pick and append a specific token in the next step. If that specific token is masked in the next step, the LLM is forced to pick among the remaining valid tokens, which will affect output quality (see this example). We need to be able to backtrack paths, or pre-compute paths that don't run into this problem.
- The above problem belongs to a larger set of problems that arise in constrainted decoding: Whenever we mask the "most likely" tokens, we derail the LLM from its natural path and the patterns it has learned. LLMs are known to produce low quality outputs on such unnatural paths. We need methods that don't degrade output quality.
Luckily, there are implementations available today that solve some of these problems, and even better ones are emerging fast. We'll cover them shortly.