LLM outputs
LLMs produce outputs through a sampling process.
The internals
Before LLMs came into existence, models read text piece by piece, with a small memory window. They lost context in long texts, and failed to link pieces of text that were far apart.

Then, transformers came along. Transformers are neural networks based on a mechanism called "attention", which allows them to process entire text sequences at once. They can see how every piece of the text sequence relates to every other piece, regardless of distance.
An LLM is made of many layers of transformers.
Tokens
Given a text sequence, a transformer needs to split it into pieces. But what exactly is a "piece"?
In theory, these pieces could be words → The, ultimate, number, is, 16, +, 26, =, 42, .. They could also be characters →T, h, e, u, l, t, i, m, a, t, e, 1, 6, = , ..
While words and characters make sense for humans, they are not practical for a transformer.
Characters are too small. Even simple sentences will split into an unmanageably large number of pieces. This will also dilute meaning, as a single letter tells the transformer almost nothing. It also wastes memory, as the transformer has to look at many pieces to understand context.
Words are too many. Transformers memorize pieces, how they relate to each other, and how they are used with each other. Memorizing the vocabulary of all words will make the transformer slow and heavy. Also, it would have to separately learn walk, walks, walking, walked.
So we find a middle ground. We break the text into subword pieces that are neither characters nor words, but something in between. These pieces are called tokens. We use algorithms to figure out the best subword pieces, that capture and represent the recurring patterns in natural language. While choosing tokens, these algorithms balance token length and vocabulary size.
understanding→under,stand,ingwalking→walk,ing"20251201"→2025,12,01status=active→status=,act,ive{"id": 12, "ok": true}→{,"id,":,12,,,"ok":,true}
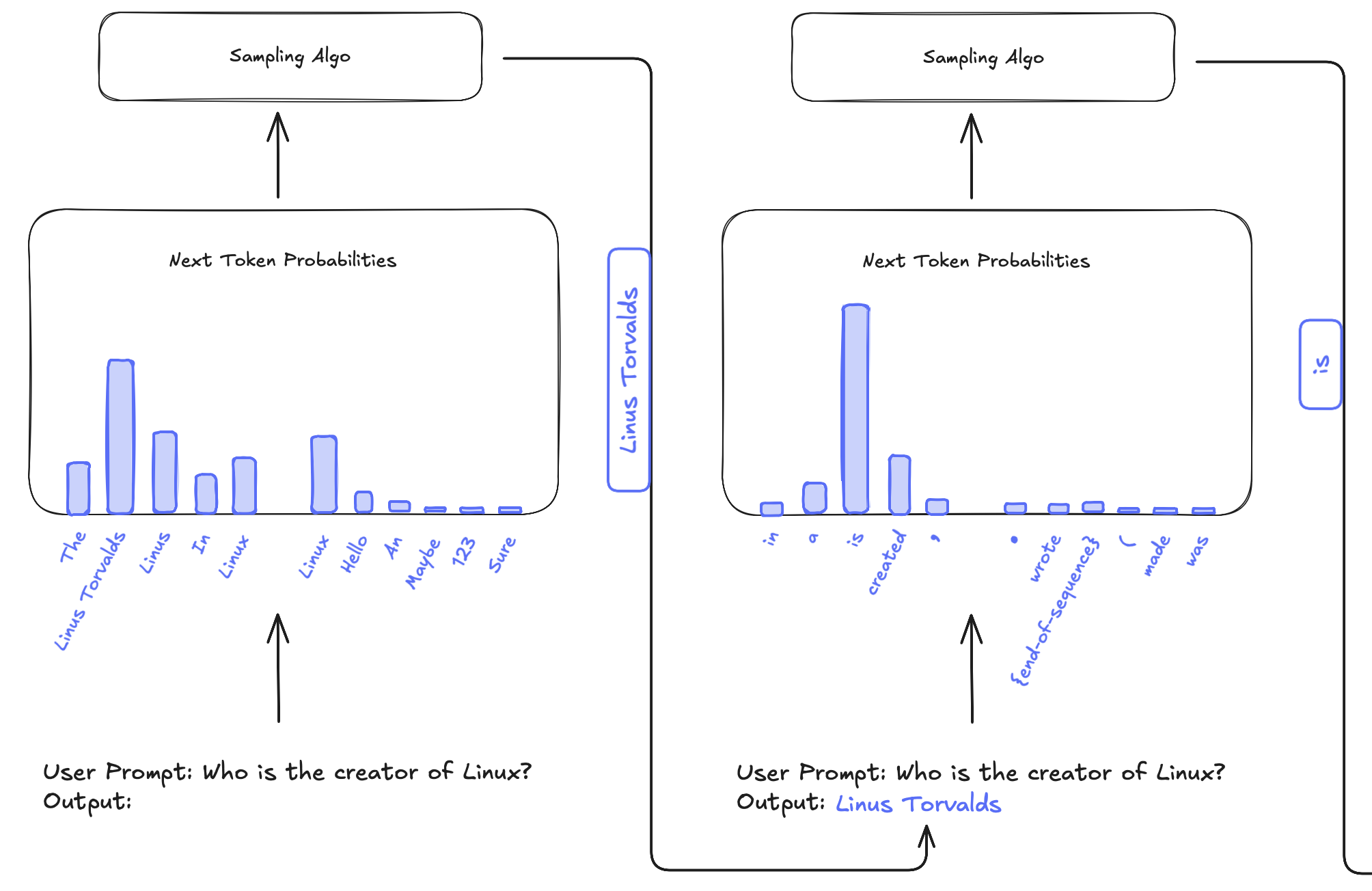
Sampling tokens
An LLM is trained on large volumes of text. Given a random text sequence, it is trained to predict the next token that is most likely to follow the text sequence. The LLM splits text sequences into tokens, identifies statistical relationships between these tokens, and learns natural language patterns.
When we give a prompt, the LLM:
- splits the prompt into a token set.
- assigns a probability to every token in its vocabulary (>32k tokens) based on the input token set, which is the likelihood of a vocabulary token being the next token.
- picks a token from the probability distribution to be the next token, using a sampling algorithm.
- appends the token to the token set.
- uses the updated token set to predict the next token.
This runs in a loop, until the model picks the "end-of-sequence" token in a token generation step. All the new tokens it added along the way form the output.
Subscribe to our newsletter
Updates from the LLM developer community in your inbox. Twice a month.
- Developer insights
- Latest breakthroughs
- Useful tools & techniques