LLGuidance
llguidance is a state-of-the-art constrained decoding backend, with support for high throughput and complex schemas. It accepts regex, CFGs, JSON templates. Instead of a standard PDA, llguidance uses a highly optimized Earley parser to represent schema.
The Earley parser simulates a non-deterministic PDA. Read more
The Earley parser computes token masks on-the-fly during each token generation step, instead of pre-computing them. This makes sense: In large / infinite / recursive schemas, valid tokens for a token generation step may depend on nesting tokens like (, {, etc. that have been generated in previous token generation steps. We don't have this information before-hand.
There are two major optimizations in llguidance that make it fast:
-
Token Trie
llguidance uses a prefix tree (trie) to compute token masks. We'll show this in an example. Say our LLM has a tiny vocabulary of tokens and we want to constrain the output to integers:
"a", "ab", "an", "and", "ant", "1", "10", "103", "108", "1e", "1e1", "1e2”
llguidance organizes the token vocabulary as a trie.
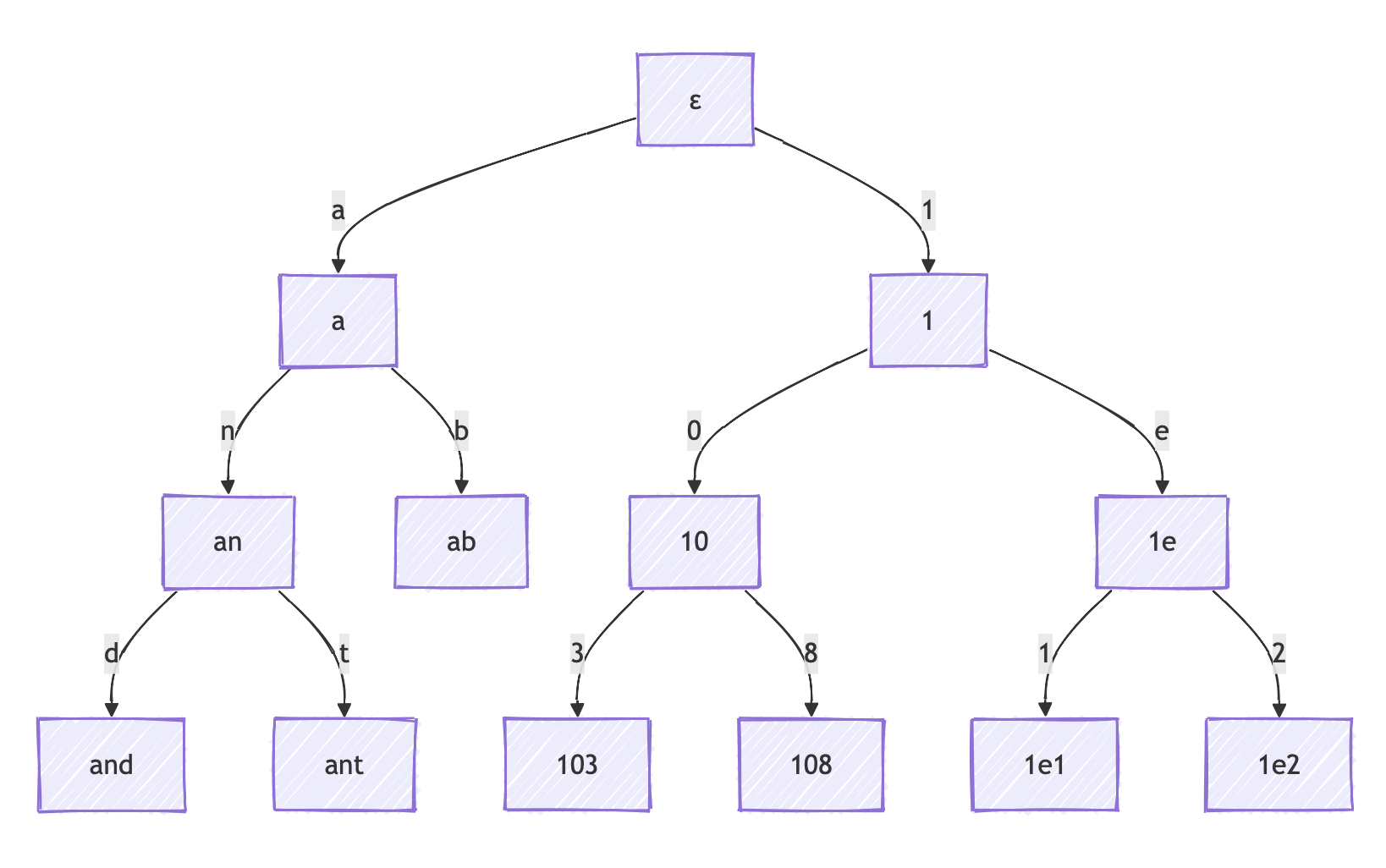
Each node is a token, and each edge is a byte. It parses the trie to find valid tokens:
llguidance can prune an entire branch, if the branch root is an invalid token. By the end of the traversal, we get a mask of valid tokens (
1,10,103,108), without explicitly checking majority of the vocabulary tokens. This makes token masking fast.
LLMs use byte-level encodings for tokens. Certain token combinations can be invalid UTF-8 sequences. Letter "A" (0x41) could also be encoded as 0xC1 0x81, but it's invalid in UTF-8. In every token generation step, llguidance first eliminates token encodings that will result in invalid UTF-8. This cheap operation (in microseconds) discards 30-50% search space.
-
Layered Parsing
Back in the 1970s, computers had memory in kilobytes, and compilers had to be efficient in parsing C source code and converting it into machine code. Instead of parsing every character, compilers used regex to split code into words (called lexemes), and used CFGs to parse these lexemes. This was faster than doing compute-heavy parsing on every character.
Virtually all programming language definitions today have this lexer/parser separation. Now, token masking is also a specific problem where one has to do lots of parsing quickly. llguidance takes inspiration from this analogy, and splits its parser:
-
Lexer (regex layer)
Consider this JSON:
{"question": "THE ULTIMATE", "answer": 42}. For the model, this is a token stream:{"->question->":"->THE->U->LT->IMATE->","...The entire parser, with syntax and nesting checks, isn't required at every token step. While generating a string in-between, like
THE ULTIMATE, we don't care about syntax or nesting, we only want a valid string. We treat these "in-between" parts as lexemes:LBRACESTRING("question")COLONSTRING("THE ULTIMATE")
llguidance assigns a regex schema to each lexeme. When the model is generating tokens within a lexeme, like within
STRING("THE ULTIMATE"), the Earley parser sleeps and gives control to a lightweight regex parser. The regex parser computes token masks only to ensure tokens create a valid string, without checking for syntax or nesting. -
Parser (CFG layer)
llguidance gives control to the Earley parser only at lexeme boundaries. After
THE,U,LT,IMATEtokens are generated, we reach the string lexeme boundary, and control is given back to the Earley parser, which determines the next lexeme, and control is then given back to the lexer.
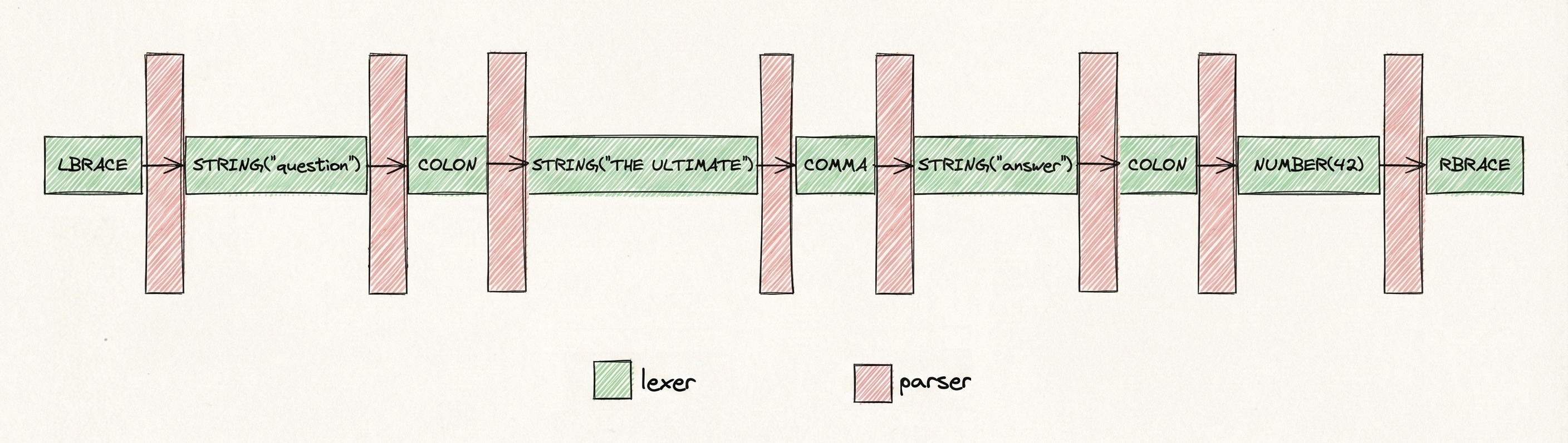
Control switches back and forth. Typically LLM tokens are somewhat aligned with lexemes, meaning that when walking the trie, the heavy and slow Earley parser needs to be invoked in under 0.5% of trie nodes, leaving the rest to the lexer. This dramatically speeds up token masking.
-
When to use it?
-
llguidance is a solid bet for most production workloads with high throughput or complex schemas. Compared to Outlines, the optimizations discussed above save milliseconds in time-per-token and seconds in time-to-first-token.
-
llguidance is the de facto backend for dynamic schemas. There is no pre-computation, and thus, no time-to-first-token costs when changing schemas.
-
It's also the de facto backend for interleaved flows: prompt → output → prompt → output...
-
Earley parser's algorithm works great in schemas that stay ambiguous during output generation, like oneOf constraints, math expressions, code with comments. We'll show what we mean by this, and briefly explain why Earley parser is a fit. Imagine you want the LLM to generate a profile that is either a human User or an bot User. Here's how both User objects look like:
{
"anyOf": [
{
"name": "string",
"type": "object",
"properties": {
"id": { "type": "string" },
"email": { "type": "string" } // Only Humans have emails
}
},
{
"name": "string",
"type": "object",
"properties": {
"id": { "type": "string" },
"version": { "type": "integer" } // Only Bots have versions
}
}
]
}Both User objects share the exact same starting field (id), but diverge later. The LLM begins generating the JSON. It outputs:
{ "id": "12345",. When the PDA sees{, it wants to start on either the HumanRule or the BotRule path. Both rules start with "id". The PDA cannot tell which one to pick. To make this work on a PDA, you typically have to rewrite your grammar carefully. This is difficult to do, especially for deeply nested schemas.Here's what the Earley parser does: It keeps both paths active. The LLM keeps generating output, and the parser keeps masking tokens based on both paths. At each output token step, valid tokens become a union of valid tokens on both paths. As the LLM generates
"id": "12345", the parser still keeps both paths active. The moment the LLM generates the next character:- the parser drops the BotRule path if it is "e" (start of "email").
- the parser drops the HumanRule path if it is "v" (start of "version").
Thus, the Earley parser maintains a "set of all possible paths" (Earley sets) during output generation, and drops paths as they become invalid. It can handle ambiguous schemas without needing you to painstakingly restructure your schema's grammar.