LM Format Enforcer
LM Format Enforcer (LMFE) takes a different approach than the FSM / PDA based backends we just discussed. It creates a character level parser and a token vocabulary prefix tree (trie, similar to the one we saw in llguidance):
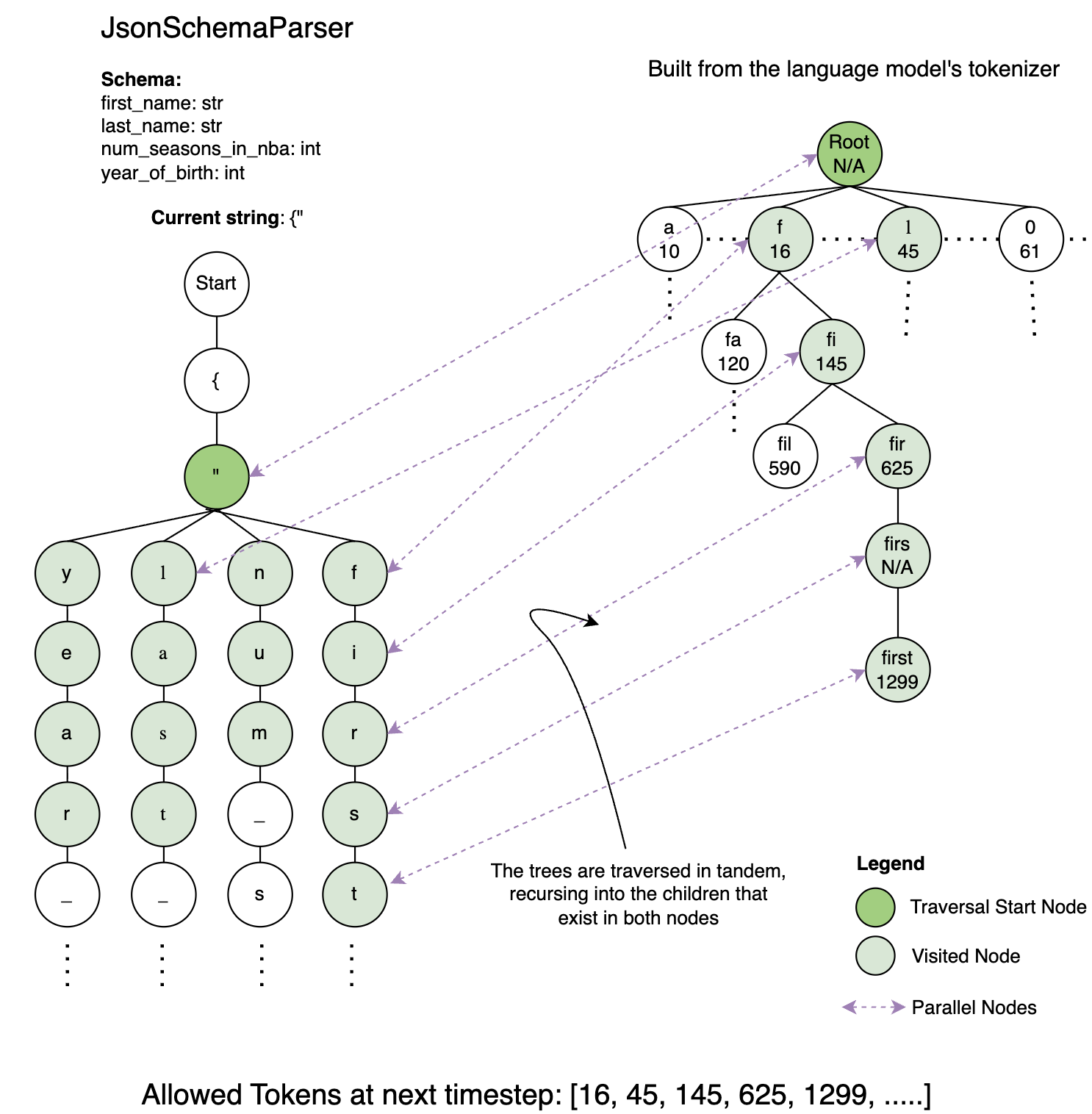
The character level parser is an interface with methods add_character() and get_allowed_characters(). To create allowed next characters from a character, it uses regex. The prefix tree (trie) is pre-built, containing every token in the token vocabulary. This maps the entire potential output space of the model.
LMFE performs a recursive search on both trees simultaneously. At any generation step, the valid tokens are the set intersection of valid next characters allowed by the CharacterLevelParser and valid tokens available in the TokenizerPrefixTree.
While constraining the LLM output in this manner, LMFE creates a couple of allowances:
- It allows the LLM to output JSON fields in any order.
- It allows the LLM to generate the whitespace it wants, provided it remains valid JSON.
As we know, forcing a model to output a specific whitespace or field order that contradicts its training data puts the model's internal state into a suboptimal value. It forces the model to generate a token it assigns a low probability to (e.g., a specific indentation), which degrades the semantic quality of subsequent tokens.
Another one of LMFE's strongest features is its diagnostic capability. It allows you to peer into the "aggressiveness" of the constraint. By enabling output_scores=True, you can generate a dataframe comparing:
- The Generated Token: What LMFE forced the model to output.
- The Leading Token: What the model wanted to output.
Limitations
-
It relies on interegular, which does not support the full Python regex standard (e.g., lookaheads/lookbehinds are limited). Also, large / infinite / recursive schemas are not supported.
-
Its Python-centric, on-the-fly intersection logic introduces high latency per token compared to Outlines, llguidance, Xgrammar.
When to use it?
-
If you find that other backends are causing your model to hallucinate or degrade in reasoning quality because the constraints are too rigid, LMFE's flexible parsing is a strong alternative.
-
Use it for prompt debugging. The diagnostic scores are invaluable when you need to understand why a model is failing to adhere to a schema. It helps you align your prompt with your constraints.
-
Use it for unbatched local inference for prototyping, POCs, scripts, etc.