Choosing the right method
The answer varies case-to-case, but we'll touch a bit on how to think about this.
Extreme performance
Use SGLang or vLLM as the inference engine, and llguidance or xgrammar as the backend. Either of these configurations handle high-performance productions well.
In general, Xgrammar has a slight edge in static schemas, while llguidance has the edge in dynamic schemas. SGLang has the edge in most schemas except ones with very low cache hit rates, where vLLM is the better choice.
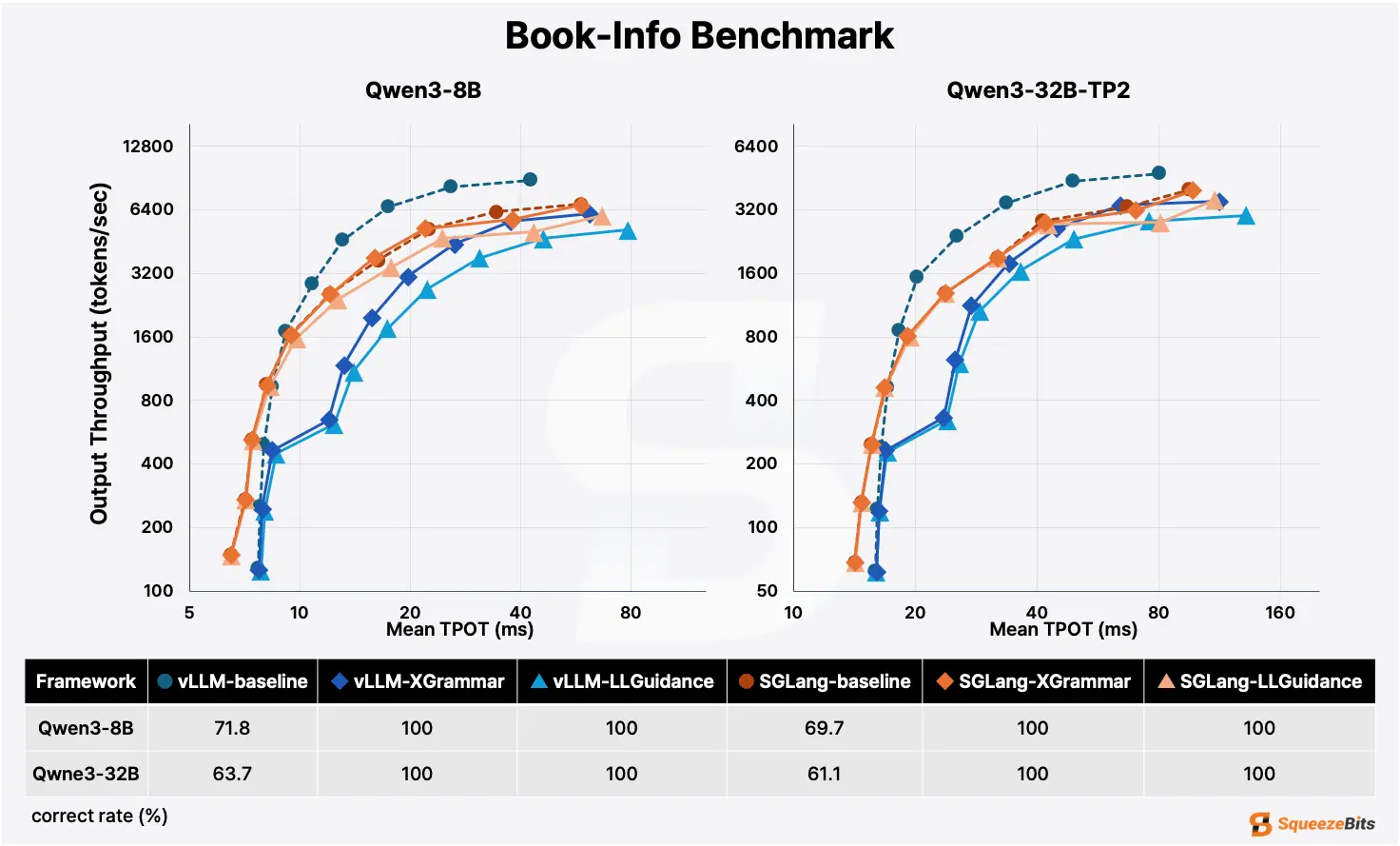
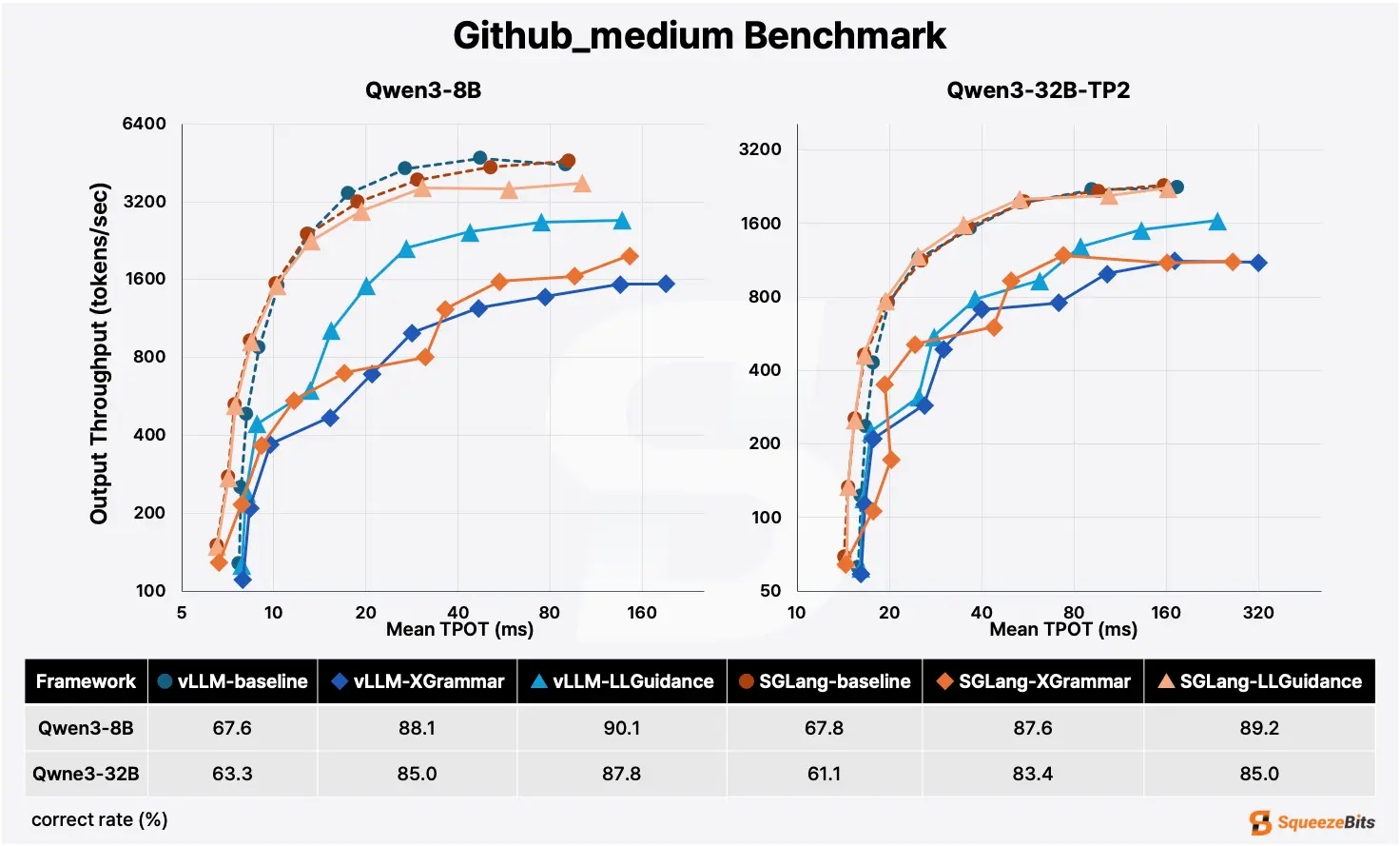
Developer experience with good enough performance
Use Outlines for the best developer experience coupled with decent performance on slightly less demanding productions. Similarly, you can use Guidance to improve your developer experience on large, infinite, or complex schemas.
Your Macbook, or a cheap cloud instance
Ollama is the best choice. It is very easy to use, and good enough for prototypes, running scripts, POCs, internal agents, independent tasks.
Alternatively, you could also consider the unconstrained method if you can get a good enough schema adherence rate, or if you can live with a few errors.
Edge devices
use MLC-LLM, WebLLM, or llama.cpp for client-side inference on laptops, phones, tablets, browsers, Raspberry Pis, etc.
Don't want to implement?
Save effort by using commercial APIs from the big three providers (OpenAI, Gemini, Anthropic). They provide access to the best models, with decent latency and pricing, but are currently limited to simple schemas.
Explore specialized APIs that optimize for your specific use case (eg. docstrange API for OCR / document extraction).
Support for complex schemas
Obviously, you need to make sure any complex constraints in your schema are supported. Everyone keeps adding more and more support regularly, so refer to the official docs to check.
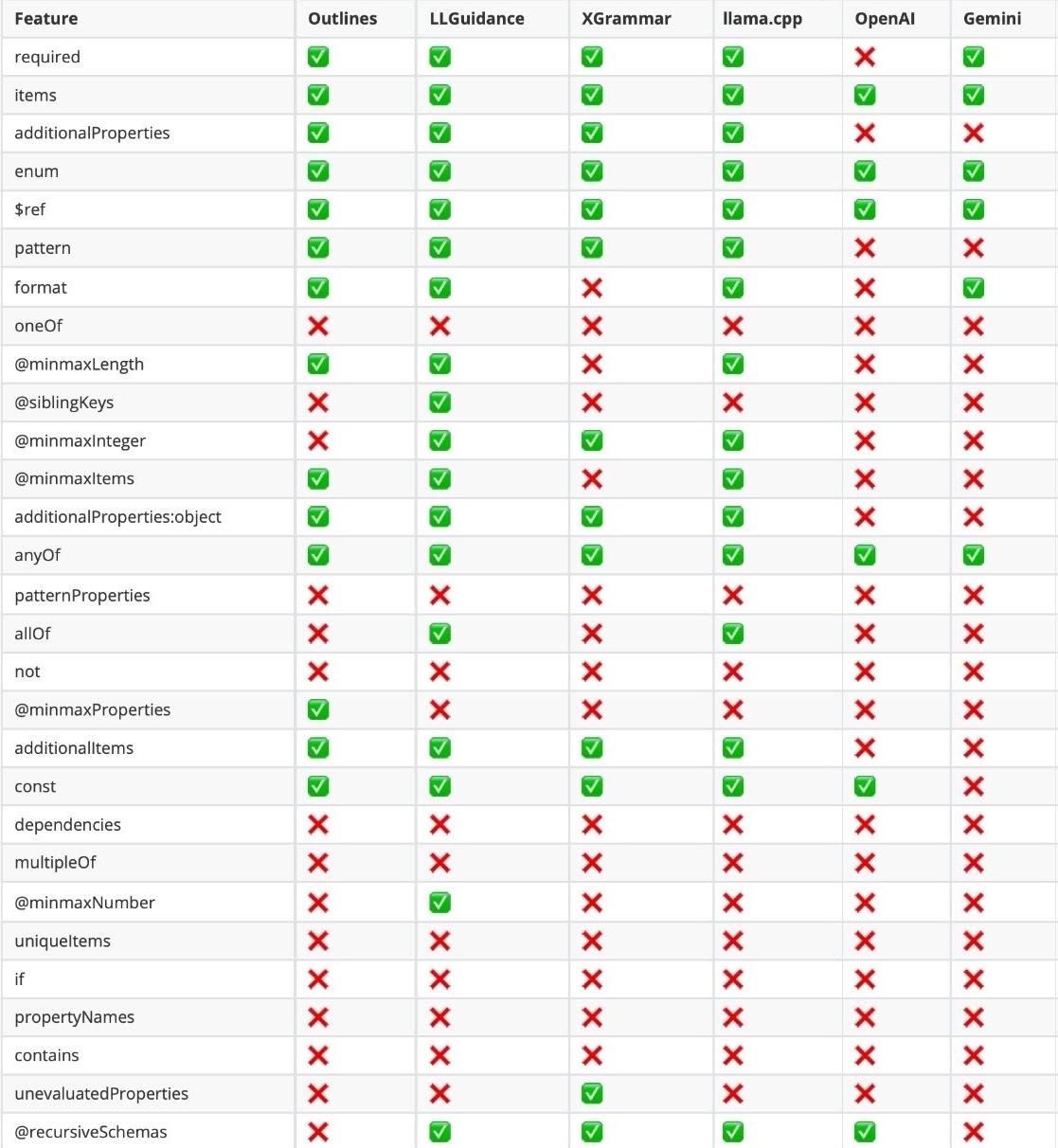
Stateful generation and interleaved flows
Try Guidance. If you need fine-grained control and speed, use its backend llguidance directly.
Output quality
If you are not satisfied with the outputs you get after setting up, you can try experimenting with different models. Try using a larger open source model, a task/domain specific open source model, or a closed source model API.
Lower quality of outputs could also be due to constrained decoding causing a distribution shift in the model's natural path and probability distributions. Try CoT / hybrid constrained decoding (both discussed in later sections) or the unconstrained method.
You could also try training / fine-tuning a model on your own data, if you are really committed to your task accuracy. This is beyond the scope of this handbook, but we have attached some resources at the end of this section.