Regex
Regex is used for finite schemas.
Examples
A regex schema can specify a JSON, CSV, XML, string, date, etc:
r'\{"name": "[^"]+", "age": \d{1,3}\}'
r'"[^"]+",\d+,\d{4}-\d{2}-\d{2}'
r'<item id="\d+">[^<]+</item>'
r'ORD-\d{4}-[A-Z]{3}'
r'^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$'
r'\d{4}-\d{2}-\d{2}'
r'The (first|second|third) option is (better|worse) because .{10,100}\.'
Here's the regex schema for our expense auditing example:
\{
\s*"billable_items":\s*\[\s*("[^"]*"(,\s*"[^"]*")*)?\s*\],\s*
"total_claim":\s*\d+,\s*
"trip_duration_days":\s*\d+\s*
\}
Regex uses FSMs
A constrained decoding backend converts a regex schema into a Finite State Machine (FSM). When each output token is being generated, the FSM is used to check the probability distribution and mask invalid tokens.
We'll use an example to show how this works. Say we want to generate a fictional character. The character must have a name ("John" or "Paul") and an age (20 or 30). Here's the regex schema:
\{"name":("John"|"Paul"),"age":(20|30)\}
This is converted into an FSM, where the states represent the current state of the output, and the transitions represent valid characters that can be used to move to the next state.

But an LLM generates tokens, not characters. The vocabulary might have the token {"name":, and the LLM might use it to transition from State 0 → State 8. The vocabulary might not have the singular token for {, and the LLM won't be able to transition from State 0 → State 1.
We need a token-based FSM to interact in the LLM's sampling process. To create it, we use the tokens present in the token vocabulary, and generate an FSM with all states and transitions possible using those tokens.

This token-based FSM is used to check the probability distribution and mask invalid tokens when each output token is being generated:
- When the LLM starts generating the first output token, the FSM is at state 0.
- The LLM generates the probability distribution, and the FSM masks all tokens in it except the ones that can transition to one of the next states.
- Valid tokens are
{and{". The LLM picks one, and the FSM goes to one of the new states using the transition corresponding to the picked token.
This loop continues until the FSM reaches a final state, at which point it masks all tokens except the "end-of-sequence" token. The LLM is now forced to stop, and the output is returned.
Constrained decoding with FSMs
Limitations
FSMs fail when a schema requires large / infinite number of states and transitions. For example, JSON schema to represent a Wikipedia article with the first article it links to (this is a real game):
{
"title": "Linus Torvalds",
"link": {
"title": "Linux kernel",
"link": {
"title": "Free and open-source software",
"link": {
"title": "Software",
"link": {
...
}
}
}
}
}
This JSON will keep nesting until no further links are found on an article. At that point, it is closed with the same number of } as the nesting depth. An FSM for this schema needs separate branches for separate nesting depths, because the number of closing } is not fixed:
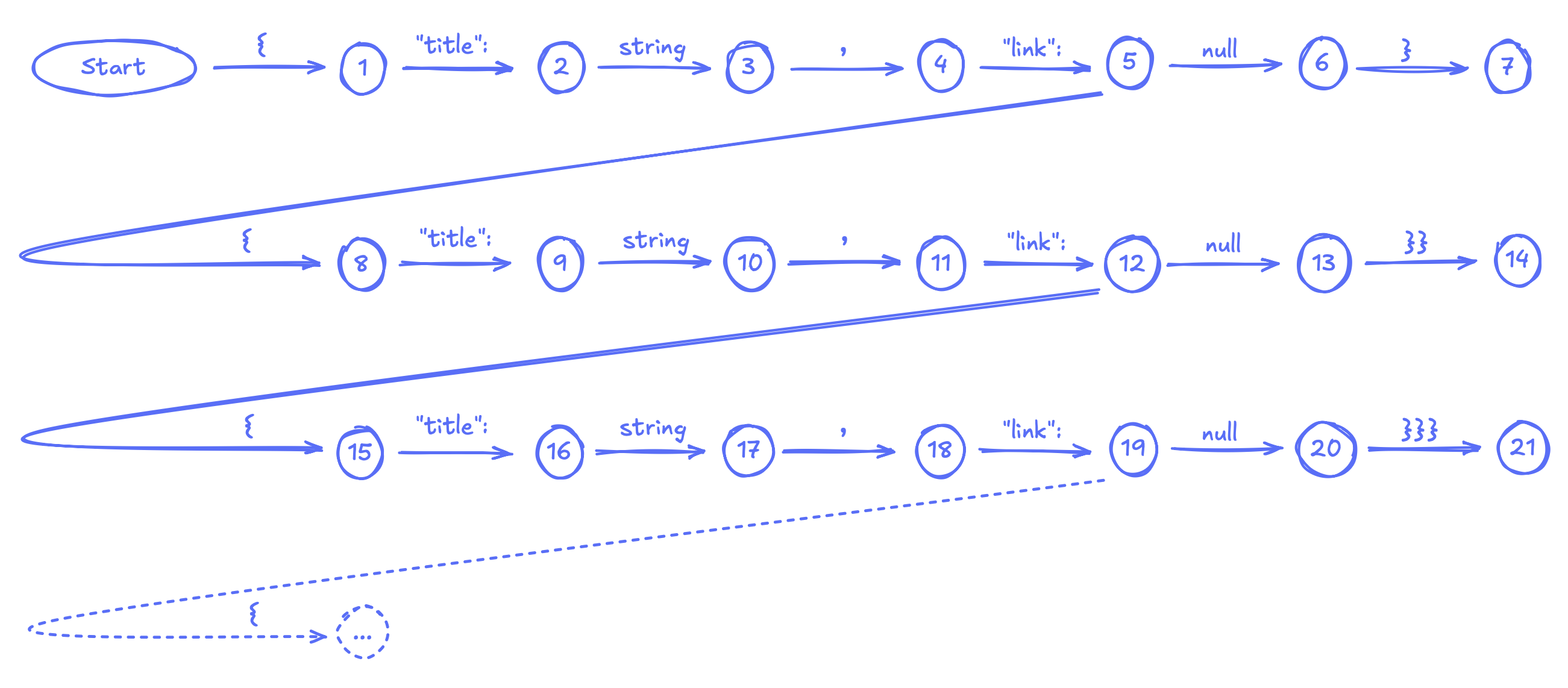
FSMs are obviously unsuitable here. They'll take forever to compile and cause memory explosion. More examples of schemas that require large / infinite number of states and transitions: