The full stack
We'll now discuss the full stack of an application for structured LLM outputs.
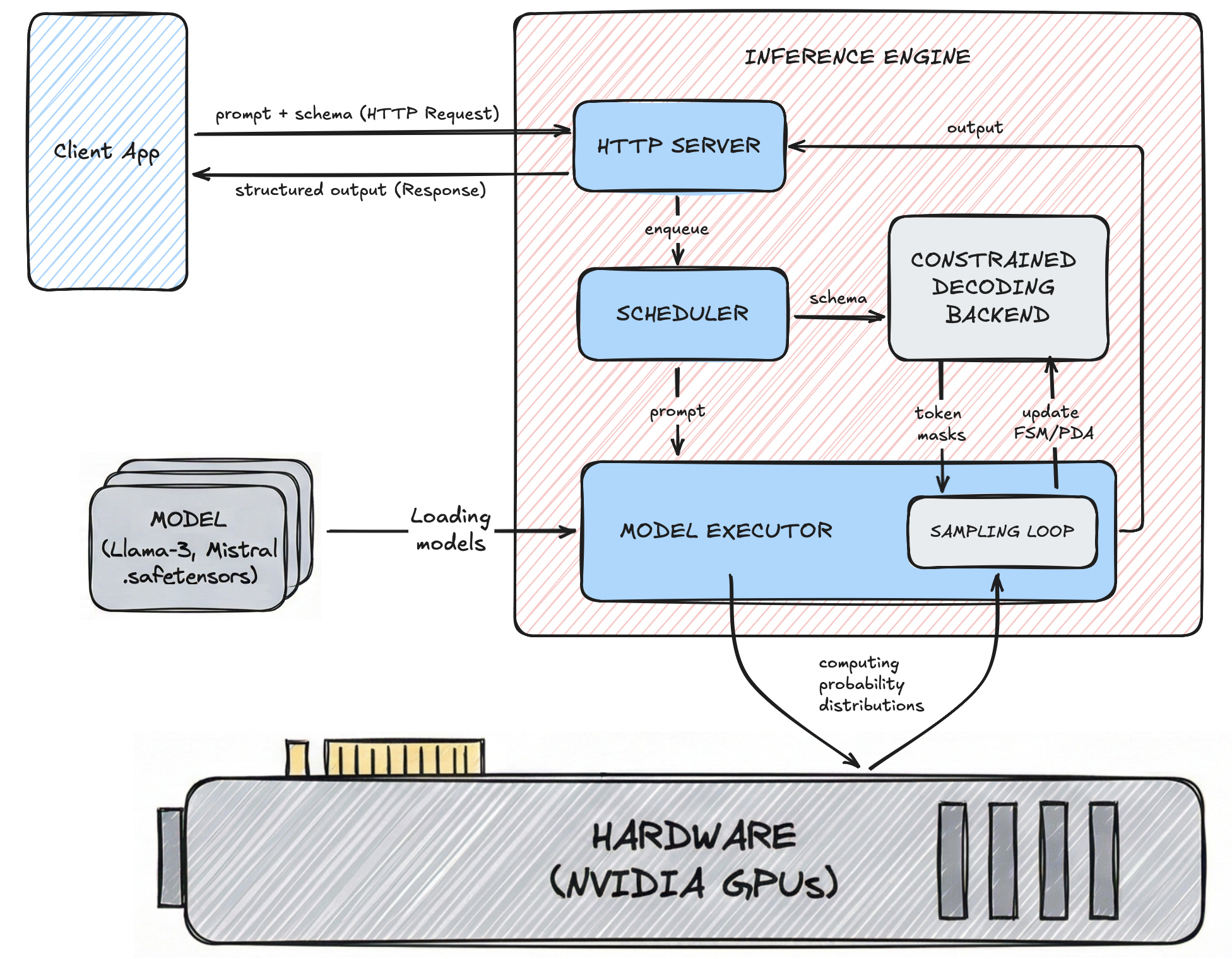
Client App
This is your application code. You send an HTTP request containing a text prompt and a schema to the inference engine, and receive the structured response. Your application can be an automated agent, RAG pipeline, etc.
Inference engine
The inference engine sets up a server that brings everything together - LLM model, GPU, constrained decoding backend, model executor - and provides an API for your application code to send inputs (prompts and schemas) and get structured outputs.
Beyond this, an inference engine minimizes latency and costs through several optimizations: batching, cache management, efficient GPU utilization, parallelism, etc.
It consists of:
-
HTTP Server: acts as the gateway for the inference engine and manages requests from the client app. Upon receiving a valid request, it places the job in the scheduler.
-
Scheduler: manages the queue of pending requests and prevents bottlenecks. It determines when to send prompts to the Model Executor, using techniques like continuous batching to process multiple requests simultaneously.
-
Model Executor: orchestrates the actual output generation process. It feeds the prompt and model weights into the GPU to get raw probability distributions. It runs a Sampling Loop that accepts token masks from the Constrained Decoding Backend, filters out invalid tokens before finalizing the output token, sends feedback to the Constrained Decoding Backend, and updates the output sequence for the next token generation step.
Constrained Decoding Backend
The constrained decoding backend interacts with the inference engine. It sends token masks for each token generation step, and fetches output tokens to update the FSM/PDA for the next token generation step.
LLM Model
An LLM model is basically a bunch of static binary files, often in .safetensors format, that contain the LLM's architecture and pre-trained weights. The inference engine loads them into the GPU, where the probability distributions are computed.
GPUs
GPUs perform massive parallel matrix multiplications to calculate probability distributions. The memory bandwidth and computing power of GPUs dictate the maximum throughput and latency you can get.