Chain-of-thought
LLMs cannot do formal reasoning. But they often give an illusion of it, by doing such a great job of predicting the output distribution that it imitates the output of a formal reasoner.
LLMs imitate formal reasoning the best when they generate the output distribution as a series of reasoning steps, instead of generating the final output directly. Nudging them to do so is called chain-of-thought (CoT) prompting.
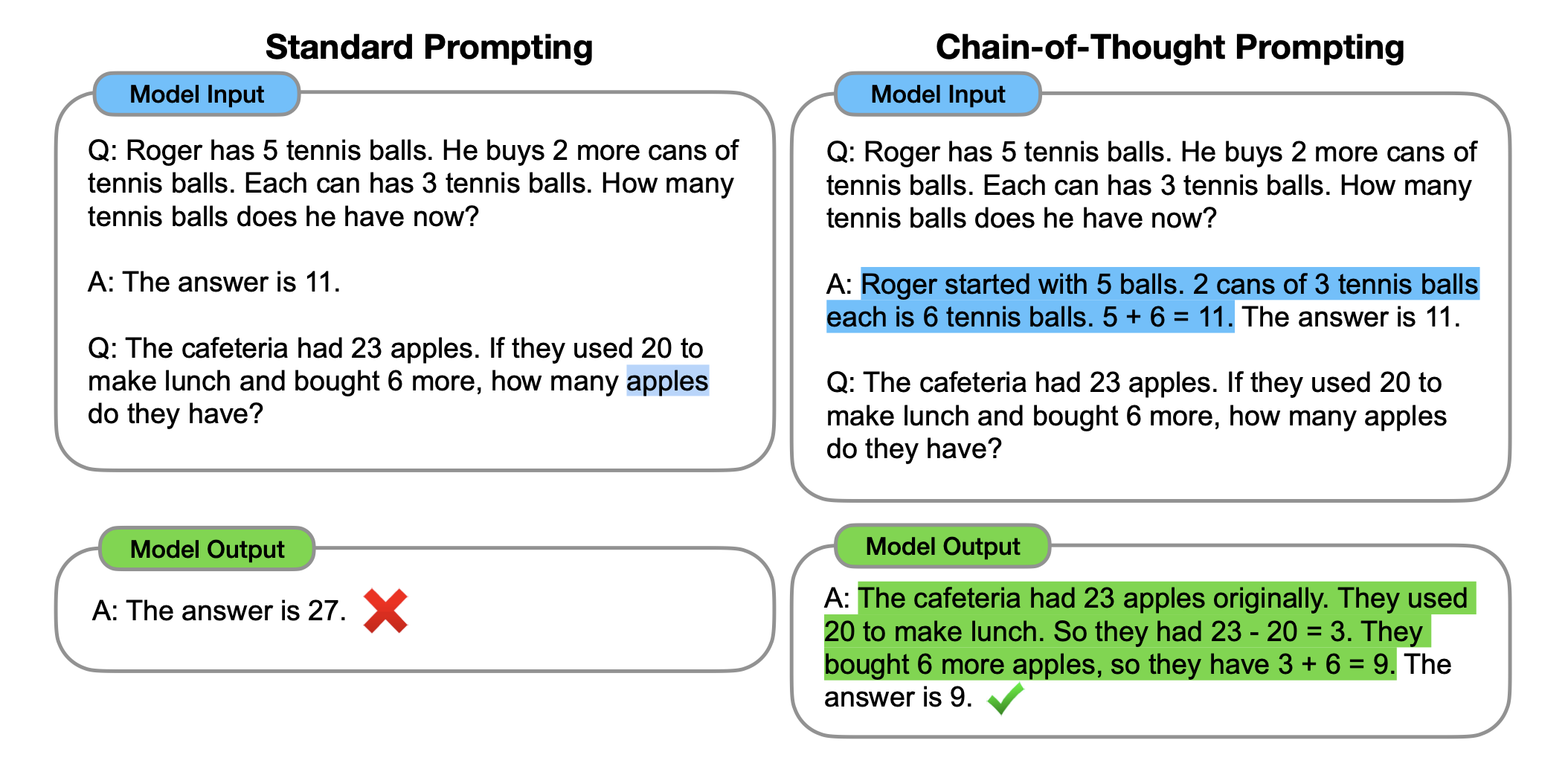
This concept applies to structured outputs as well.
Consider an agent for qualifying leads. It reads replies to your cold emails and classifies leads as "interested" or "not interested". Here's a reply:
"Hi team, I looked at your demo and it's impressive. The features are exactly what we need and I'm a big fan of your UX. I would love to see how this integrates with our workflow. However, we are undergoing a budget freeze until Q4, so we cannot buy anything right now."
You force a strict enum immediately { "status": "interested" | "not_interested" }. The LLM might output {"status": "interested"}, which might not be what you were looking for.
Why does this happen?
The reply is full of positive words: impressive, exactly what we need, big fan, would love to see. The negation logic (However... cannot buy) appears at the end, but the overall "vibe" of the reply is still positive.
Since we forced immediate generation of the enum, the LLM is unable to include reasoning steps in its output distribution. It falls prey to bias introduced by the positive words.
A better schema would be:
{
"reasoning": "",
"status": "interested" | "not_interested"
}
If the LLM is allowed to generate a "reasoning" field first, it will generate tokens like:
{
"reasoning": "The user compliments the product but explicitly states their inability to buy due to a budget freeze.",
"status":
}
These tokens generated for the reasoning field will be available to the LLM when it generates the status field later. They will shift the LLM's probability distribution towards not_interested.
When adding chain-of-thought fields, do not:
- add constraints within these fields.
reasoning: "The lead is [interested | not_interested] because [reason]."
- add prompt instructions on how to generate these fields.
- prompt saying "to generate the reasoning field, first identify the sentiment then look for budget mentions then conclude".
Doing this will introduce bias in the probability distribution and defeat the purpose of the chain-of-thought fields. The LLM must be free while generating the output distribution within these fields.
For example compare these two prompts, both are doing the same thing, but one is much easier for a model to know what you want.
Rate this essay from 0-100 so i can grade it.
I care about gramatical correctness, complexity, and the depth of details they went into.
<essay>
Answer with the following rubric schema for this essay:
{
grammatical_correctness: [
{
mistake: string
serverity: "low" | "medium" | "high"
}
]
reading_level: {
value: int
reason: string[]
}
details: [
{
quote: string[]
reason_for_inclusion: string
}
]
}
<essay>
Here is another CoT prompt, for semantic labeling of financial news statements:
Consider each sentence from the view point of an investor only; i.e. whether the news may have positive, negative or neutral influence on the stock price.
Positive: News likely to cause the stock price to rise.
Negative: News likely to cause the stock price to fall.
Neutral: News with no clear impact or irrelevant to financial performance.
Task: For each sentence,
1. Write a reasoning summary on how investor sentiment will be / will not be affected
2. Classify each sentence into a positive, negative or neutral category based on the reasoning summary.
For each sentence, write the reasoning summary first and then classify into a category.
Output a google sheet with the 4 sheets:
1. Positive sentences: ID, sentence_text, reasoning_summary of sentences labeled positive
2. Negative sentences: ID, sentence_text, reasoning_summary of sentences labeled negative
3. Neutral sentences: ID, sentence_text, reasoning_summary of sentences labeled neutral
4. Output: ID, sentence_text, label of all sentences
There’s no magic bullet for semantic accuracy. A good analogy is security software. You cannot guarantee your software is completely secure, you can just add more code and optimizations to make it harder for your system to be hacked. You can also consider adding a human review step (this requires building out workflows and UIs).