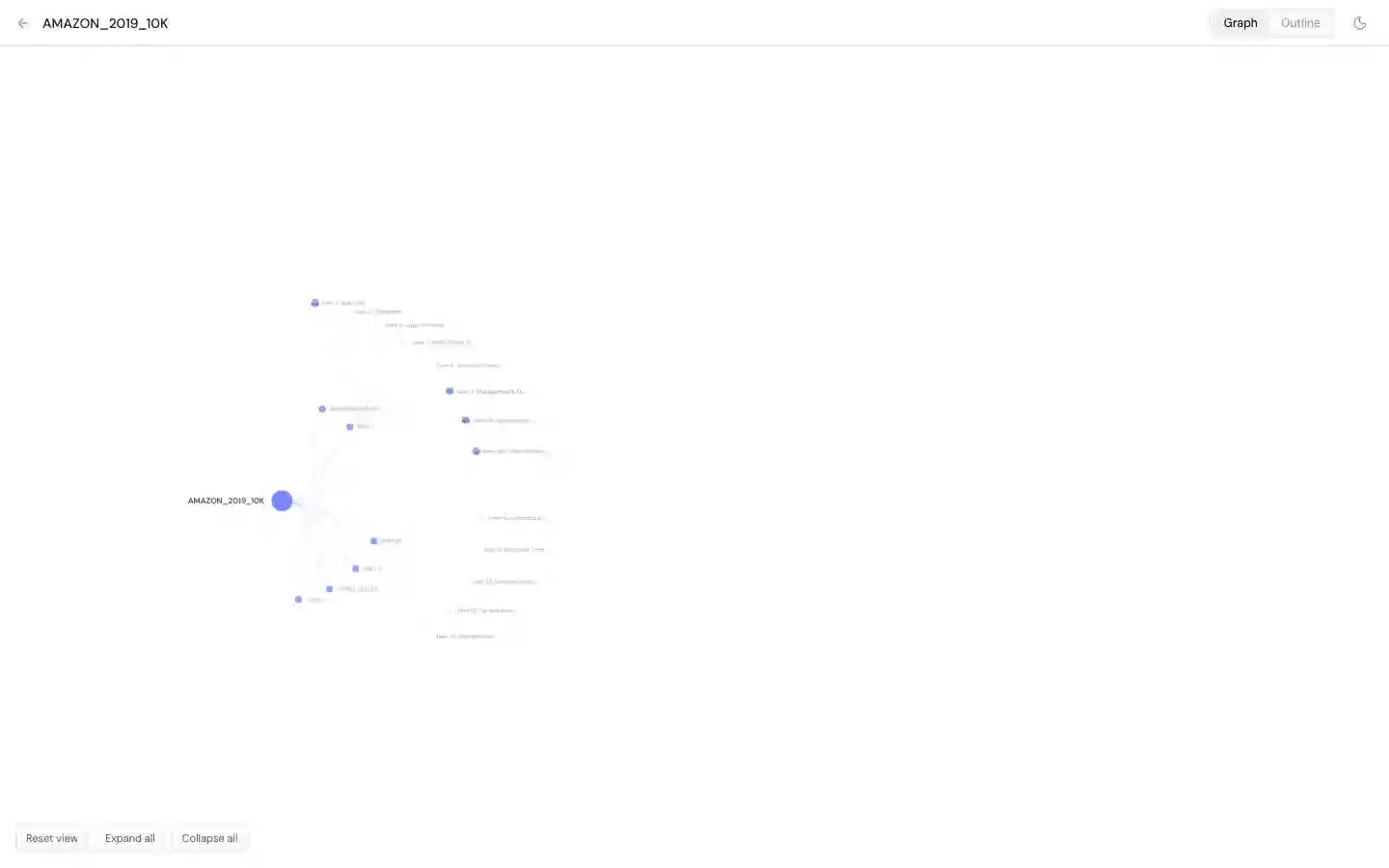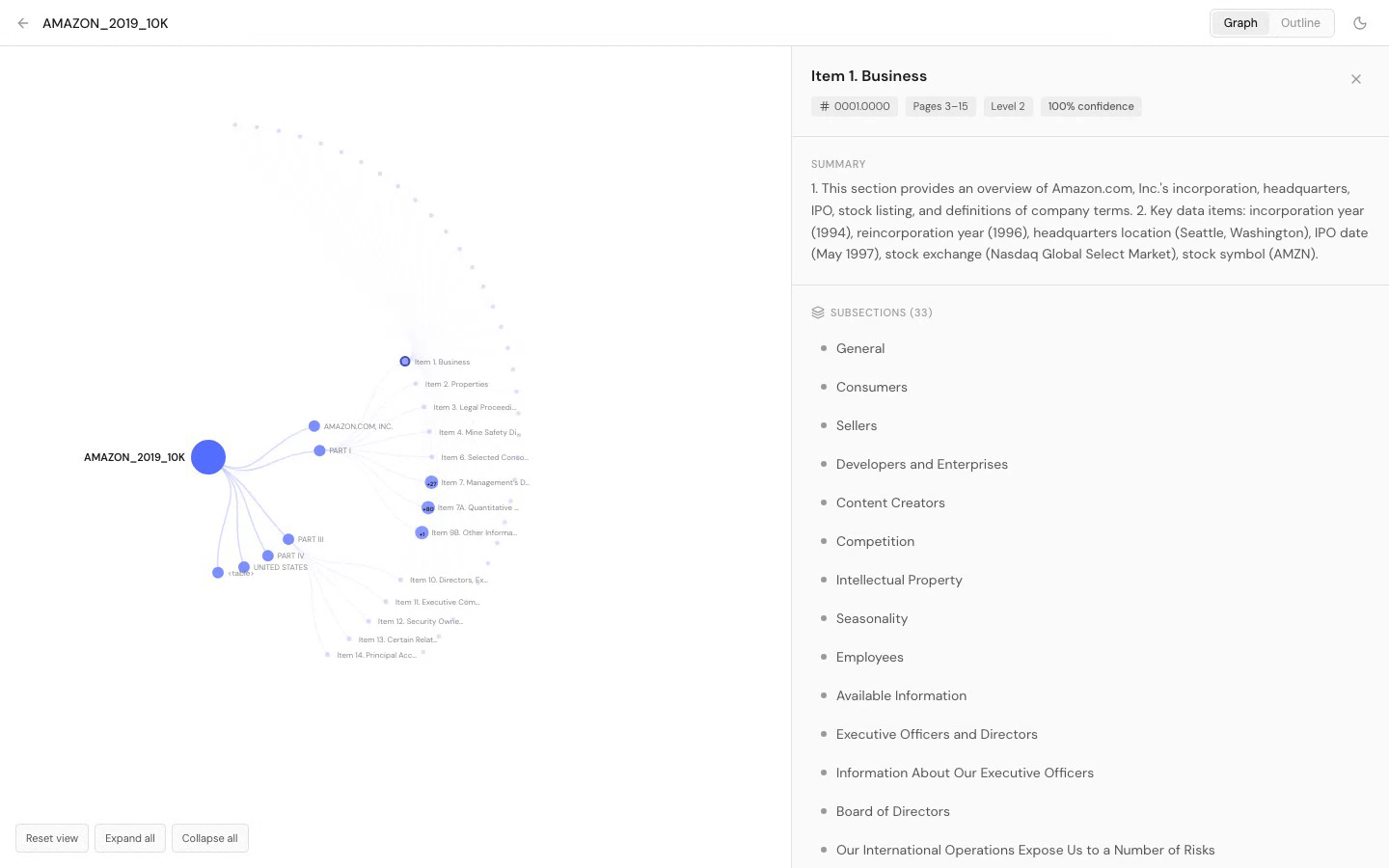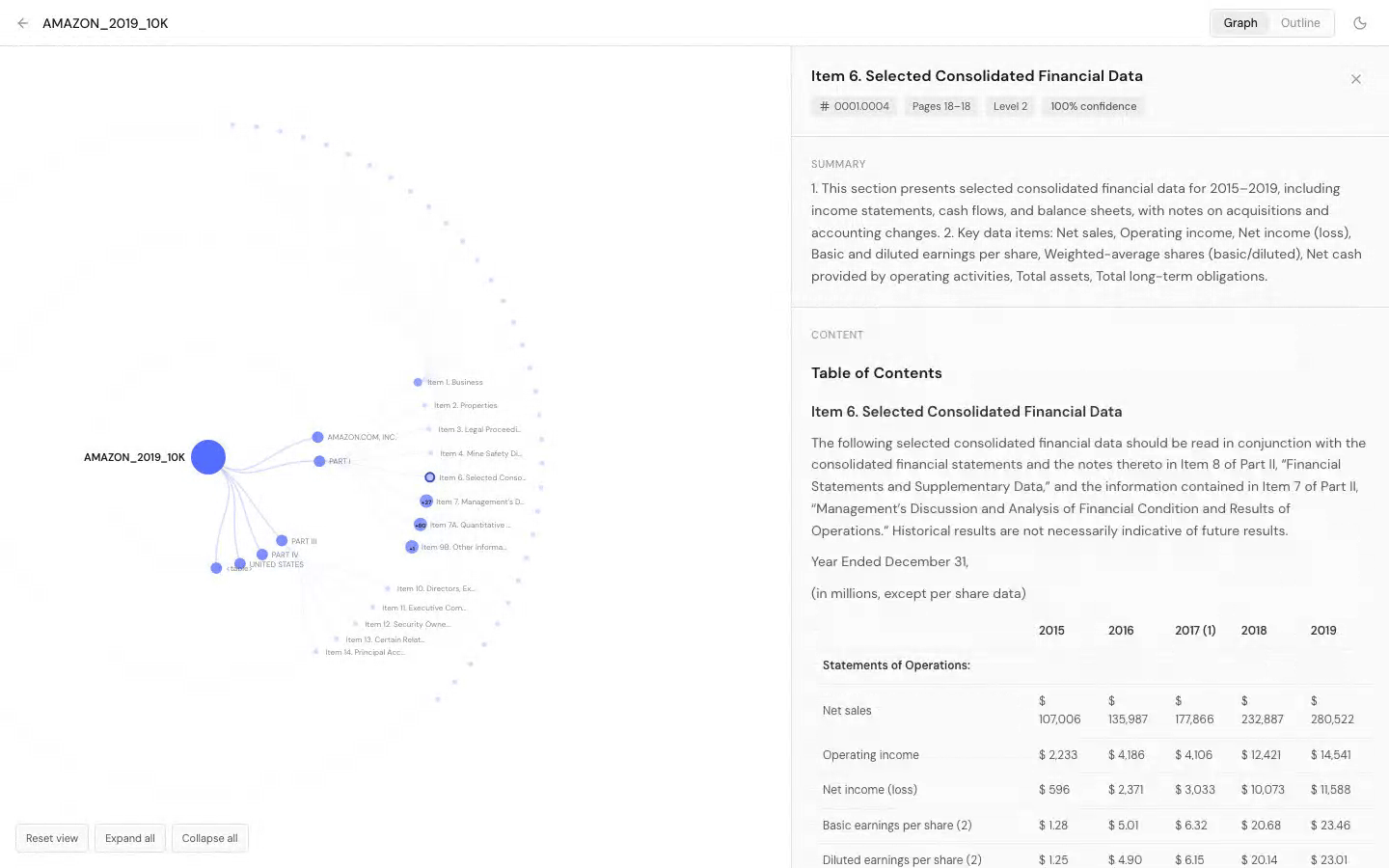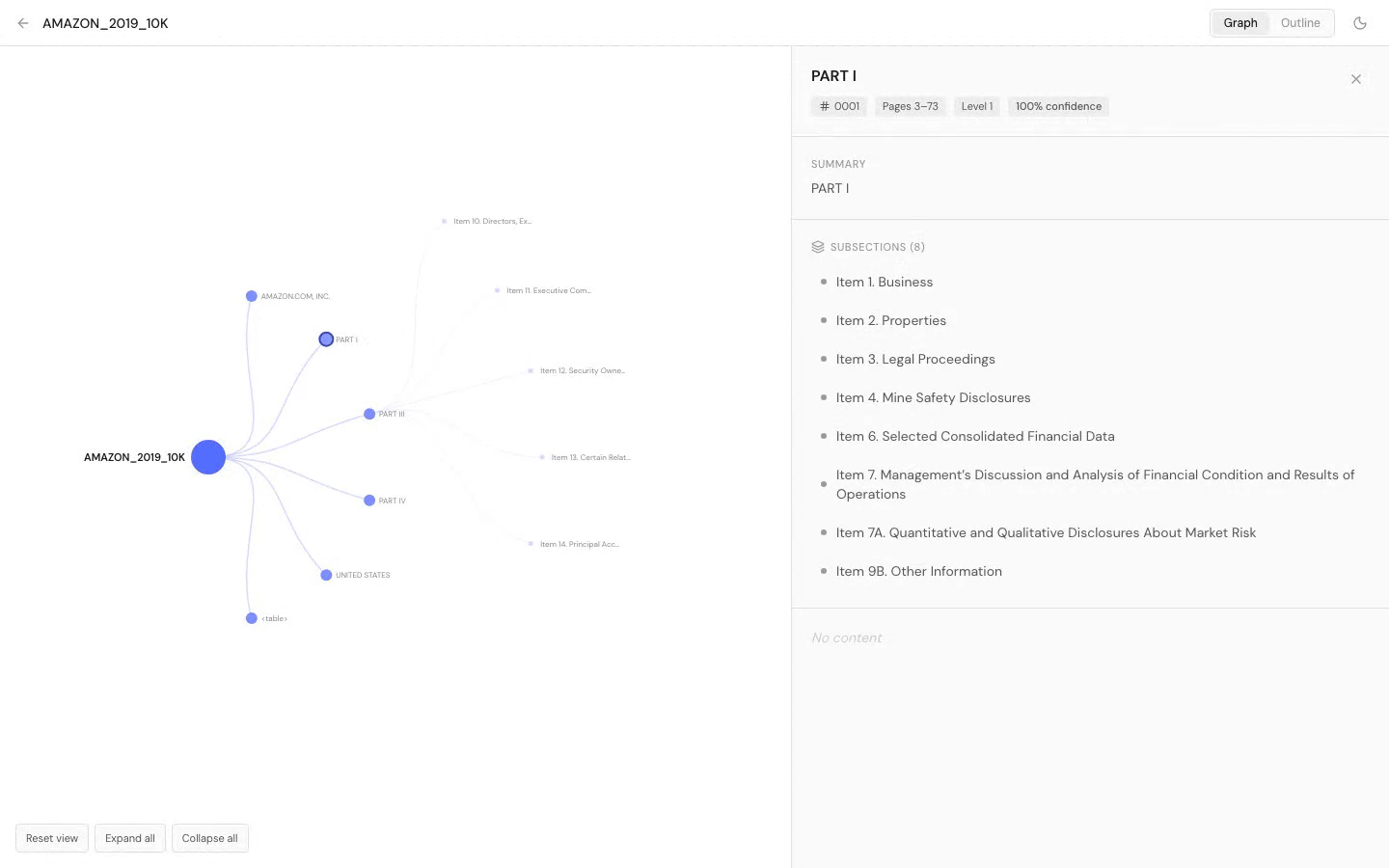
93.1 on olmOCR benchmark. 90.5 on OmniDocBench. #1 on IDP Leaderboard.
Specialized VLMs
General VLMs
Nanonets OCR-3
Chandra OCR 2
LightOn OCR-2
Deepseek- OCR2
Mistral OCR 3
Gemini 3.1 Pro
GPT-5.4
OlmOCR Benchmark
87.4
85.9
83.2
76.3
81.7
79.6
81.0
ArXiv Math
89.2
90.2
89.6
81.9
85.4
70.6
83.1
H&F
96.6
92.5
–
95.6
93.8
–
–
Long/Tiny
93.4
92.1
91.4
88.7
88.9
90.3
82.6
Multi-Col
87.6
83.5
84.8
83.6
82.1
79.2
83.7
Old Scans
49.6
49.8
42.2
33.7
48.8
47.5
43.9
Scans Math
88.9
89.3
85.6
68.8
68.3
84.9
82.3
Tables
94.2
89.9
89.0
78.1
86.1
84.9
91.1
OmniDocBench (v1.5)
90.5
85.5
–
87.7
85.3
85.3
85.3
LLM as a Judge: Corrected Scores
437 of 864 failed tests were identified as evaluator brittleness, not model errors. Weighted average: 94.9% (7,986 / 8,413 tests pass).
ArXiv Math
H&F
Long/Tiny
Multi-Col
Old Scans
Scans Math
Tables
Overall
Official
89.2
96.6
93.4
87.6
49.6
88.9
94.2
87.4
Corrected
95.5
96.7
96.6
94.1
67.3
95.9
98.9
93.1
But we're more proud of these scores
While a lot of OCR models today are busy benchmaxxing on saturated benchmarks that don't translate into real-world use, Nanonets OCR-3 is specifically trained and tested on real-world documents.
94.5%
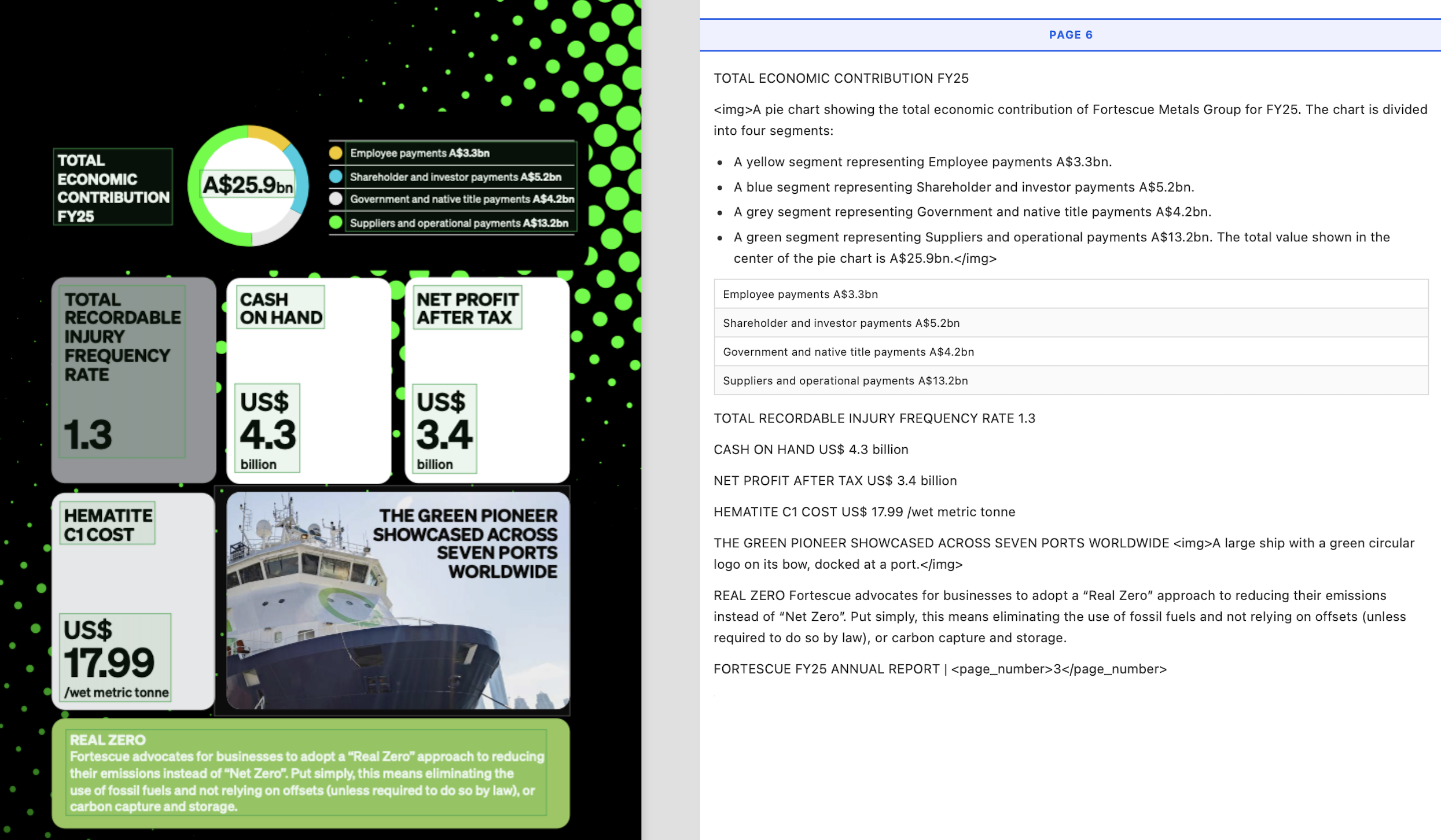
FinanceBench
Dense SEC 10-K filings averaging 143 pages with nested tables, footnotes and cross-references.
96.0%
DocBench Legal
Multi-column court filings and legislation with complex formatting, citations and structural hierarchy.
If you have built a document pipeline, LLM-based or otherwise, you already know how brittle they are.
Nanonets OCR-3 is a Mixture-of-Experts model purpose-built to handle these pains. The model API exposes five endpoints to cover all use cases:
/parse — Send a document, get back structured markdown. Layout preserved, simple tables as markdown pipes, complex tables as HTML, reading order correct, metadata with bounding boxes and confidence scores on every element. One call replaces your entire parsing stack.
/extract — Pass a document and your schema. Get back a schema-compliant, type-safe object along with metadata with bounding boxes and confidence scores on every element. Works on invoices, forms, contracts, medical records, and any other document with a repeating structure.
/split — Send a large PDF or multiple PDFs, get back split or classified documents based on your own logic using document structure and content. Useful when your input is a batch scan or a mixed upload and you need to route each document type separately.
/chunk — Splits a document into context-aware chunks optimized for RAG retrieval and inference. Unlike traditional chunking methods, it respects document structure as sections stay together, tables don't get cut in half, etc.
/vqa — Ask a question about a document, get a grounded answer with bounding boxes over the source regions. Useful for building UIs over documents and sending precise regions to downstream LLMs without needing to build a retrieval pipeline first.
Confidence scores, bounding boxes, VQA
Nanonets OCR-3 ships with three critical output features that most OCR models and document pipelines miss today.
1. Confidence scores
Every extraction comes with confidence scores, which enables you to build pipelines with 100% accuracy. You can pass high-confidence outputs directly, route low-confidence outputs to HIL or larger models, and ensure your production databases aren't poisoned with incorrect data.
2. Bounding boxes
OCR-3 outputs spatial coordinates for every element. This enables you to highlight source locations in your UI, power citation trails in RAG pipelines, pass charts/images/sections exclusively to VLMs, and feed precise regions to document agents and downstream LLMs.
Give document agents surgical precision
Agent: Verify the total revenue claim against the table
REGIONS
1Revenue KPI[32,172,140,48]
2Quarterly Data Table[32,420,476,120]
3Executive Summary[32,100,476,60]
EXECUTION
✓
LOCATE
Find revenue claim in executive summary at [32,92,476,60]
Annual sum = $12.4M+$16.1M+$18.7M+$24.2M = $71.4M ✓ Matches claim
3. Visual Question Answering
The model's API natively supports visual question answering. You can ask questions about a document and get grounded answers with supporting evidence from the page.
Query:
Fine-tuned on edge cases
We’ve been working in the space since the last 7 years, and have repeatedly seen the same edge cases where OCR fails. Nanonets OCR-3 is extensively fine-tuned on these edge cases:
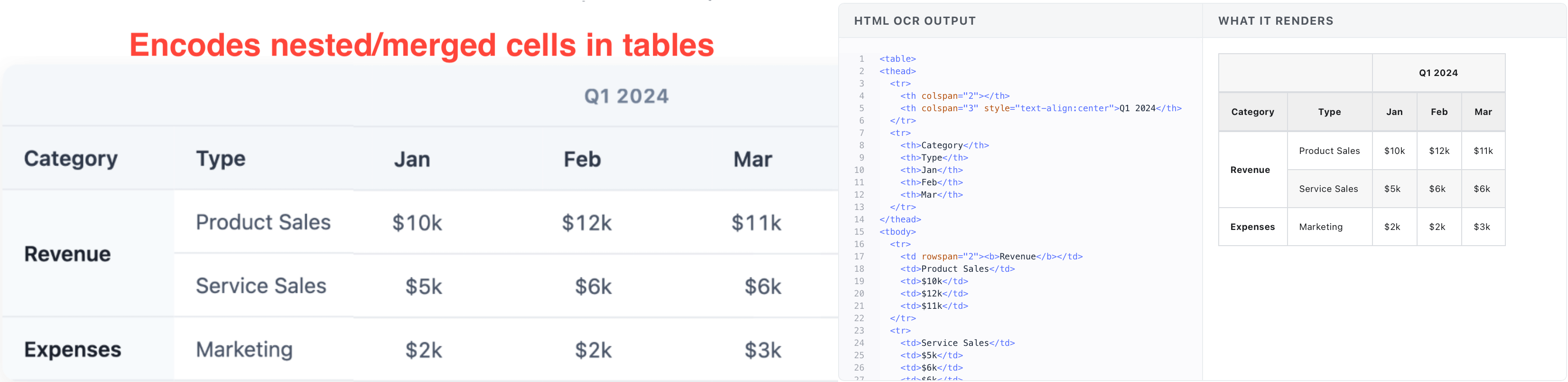
OCR-3 parses simple tables in markdown and complex tables in HTML. It preserves colspan / rowspan in merged cells, does not flatten nested tables, preserves indentation level as metadata, and retains structure perfectly on sparse tables.
Trained and tested to perform context-aware parsing on complex documents ensuring accurate layout extraction and reading order.
Extensive fine-tuning runs on W-2, W-4, 1040, etc. to ensure 99%+ extraction accuracy on forms.
The model API is integrated with OCR engines for deterministic, character-level accuracy on complex numbers and dates where pure VLMs are prone to hallucinations.
NanoIndex: A New Vectorless RAG Framework
Bad document ingestion is the #1 reason RAG pipelines fail. NanoIndex fixes this. Vectorless, context-aware, layout-aware, with pixel level precision.
How it works
Run Nanonets OCR-3 on your documents.
OCR-3 extracts structured markdown, hierarchy, tables, and bounding boxes.
A deterministic tree builder turns that into a navigable tree. Zero LLM calls.
Your downstream LLM navigates the tree, returns answers with citations and page numbers.
Why OCR-3
The pipeline depends on extraction quality. OCR-3 provides in a single API call: structured markdown with headings preserved, table-of-contents and hierarchy detection, tables as structured data, bounding boxes per element for page-level citations, and layout understanding that distinguishes headers from body text.
NanoIndex in action. Full source code and examples dropping next week.
Devlog
Compared to v2, our new model is bigger (35B parameters), yet it is faster and cheaper.
Here’s how we achieved it:
1. Token Efficiency
Training on full-resolution images the whole time is expensive and, it turns out, unnecessary. We trained 75% of the time on low-resolution images and 25% on full resolution. The model performs the same as training on 100% full resolution.
Most of what a document model needs to learn is structural. Where are the tables? What’s a header versus body text? How do columns relate? Low-resolution images teach this fine.
High-resolution matters for character-level detail, but you don’t need to see every character in crispy detail to learn layout.
At inference, the model caps token usage at 1280 tokens per image. This results in predictable latency and costs without degradation in accuracy.
2. MoE architecture
The new architecture is a Mixture-of-Experts model.
A standard transformer runs every parameter on every token. MoE activates only the relevant experts - 2 or 3 sub-networks out of many.
For us, this meant 2x faster inference compared to the previous dense model at equivalent quality. The experts specialized on their own and we didn’t need to design that in.
3. Preventing catastrophic forgetting
We realized that this is a real phenomenon first-hand. Fine tune too hard on one domain and the model forgets everything else.
We used frozen backbone layers, EWC regularization, replay buffers (15% of each batch was non-document data), and alternating OCR/general-knowledge training phases.
The model still handles general tasks accurately, which matters for VQA, agents, etc.
Lastly, we trained the model on over 11 million documents in just under a month, and to do this, we used optimization techniques like:
Gradient checkpointing - instead of storing all intermediate activations in memory during the forward pass, we recomputed them during backprop. It was slower compute, but it cut memory by roughly 60–70%. This let us fit larger batch sizes on the same hardware.
Mixed precision training - forward and backward passes in FP16, weight updates in FP32. This means we use half the memory bandwidth for most of the work, with FP32 precision for where it matters (such as numerical stability).
Distributed training - model and data parallelism across GPU clusters.
Learning rate scheduling - warmup for the first few thousand steps, then cosine decay. The warmup prevents the early instability you get when gradients are large and the model is far from any sensible solution. Cosine decay lets the model settle into a good minimum rather than oscillating.
None of this is novel but getting it tuned correctly for our specific architecture took almost a week.
We'll release a full-length technical blog on our methodology soon. Stay tuned if you're interested.