Classement des documents
Nous vivons dans un monde numérique, où les entreprises et les organisations se développent rapidement grâce à la technologie. Les organisations traitent de grandes quantités de données, notamment en ce qui concerne la classification des données ou des documents, sans même s'en rendre compte.
L'information est ce qui nous aide à prendre de meilleures décisions. Par conséquent, de nombreuses organisations s'appuient sur différentes manières de collecter, classer et stocker les données afin d'effectuer une analyse plus approfondie ; par exemple, un logiciel de numérisation et d'indexation . Cependant, il est hautement impossible pour des agents humains de gérer des volumes aussi importants de données ou de documents. C’est là qu’intervient la classification automatique des documents. Cela nous aide non seulement à enregistrer des informations, mais nous aide également à retrouver ces documents chaque fois que nécessaire.
Nous approfondirons la classification des documents et discuterons de différentes approches pour le faire plus efficacement. De plus, nous découvrirons également certaines techniques de classification de documents et parlerons de scénarios réels. Voici la table des matières.
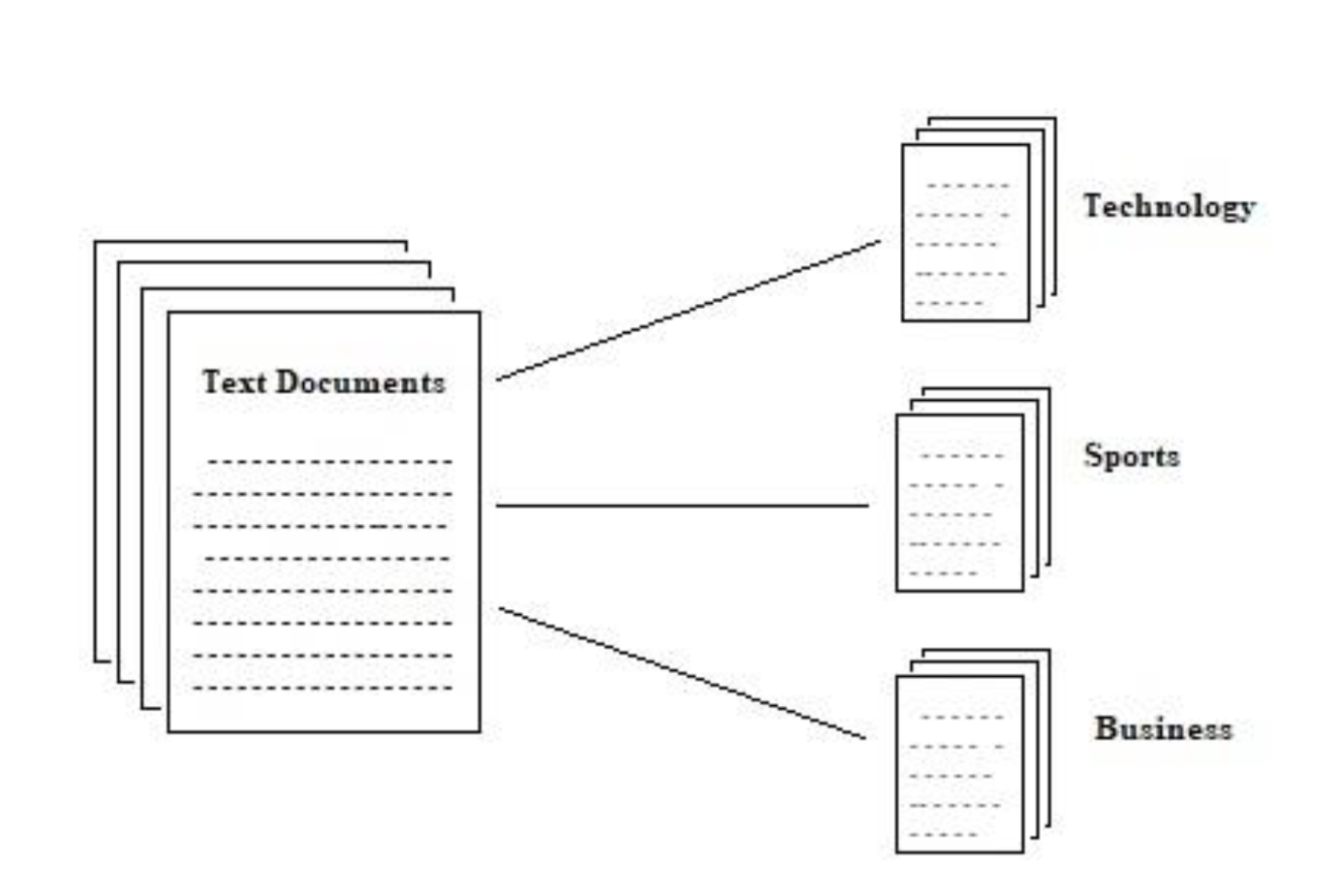
Table des matières
- Qu'est-ce que la classification des documents
- Comment fonctionne la classification des documents
- Pourquoi les entreprises utilisent la classification des documents
- Un classificateur de documents automatisé
- Classificateur de documents Nanonets
Qu'est-ce que la classification des documents
La classification des documents, comme son nom l'indique, est le processus de classification des documents en catégories ou classes pertinentes. Elle est considérée comme l'une des branches de la classification de texte, où le classificateur est capable d'attribuer une classe appropriée au document à partir d'une liste de classes prédéfinies. Cela rend le processus d’organisation et de conservation des documents/données facile et efficace.
Par exemple, considérez différents types de factures comme les remboursements, les factures pro forma , les dépenses de bureau, les factures de logiciels tiers, etc., qu'une organisation pourrait recevoir. Généralement, celles-ci sont organisées en différents dossiers en fonction du type de facture. Imaginez maintenant faire cela pour une entreprise entière, organisant quelques millions de factures. Il est très peu probable d'atteindre une précision à cent pour cent, et les vérifier manuellement un par un prend du temps et est fastidieux. Par conséquent, dans des cas comme celui-ci, un algorithme automatisé tel que la classification des documents pourrait s’avérer très utile.
Parlons d'un autre exemple simple. Supposons que vous soyez un responsable des opérations qui doit traiter des centaines d'e-mails chaque jour. Ceux-ci peuvent contenir des documents financiers sensibles, des conversations de bureau, des informations logistiques ou même quelque chose d'inutile (SPAM) ! Aujourd'hui, la plupart des services comme Gmail, Yahoo, etc. font un travail remarquable en classant les courriers indésirables comme SPAM ou NON SPAM en fonction de leur contenu. Il s’agit d’une utilisation étendue de la classification des documents !
La classification des documents peut être réalisée par des algorithmes d'apprentissage automatique traditionnels ainsi que par des réseaux neuronaux profonds. Nous en apprendrons davantage sur le fonctionnement de ces algorithmes dans la section suivante.
Comment fonctionne la classification des documents
La classification des documents est l'un des problèmes classiques de l'extraction ou de la récupération d'informations. Il joue un rôle essentiel dans diverses applications et cas d'utilisation pour gérer efficacement le texte et de grandes quantités d'informations non structurées. Pour réaliser la classification des documents, nous pouvons suivre deux méthodologies différentes : la classification manuelle et automatique. Dans la classification manuelle des documents, comme indiqué, les utilisateurs interprètent manuellement la signification du texte et d'autres éléments pour identifier les relations entre les concepts et catégoriser les documents. En revanche, la classification automatique des documents applique des techniques intelligentes telles que le Machine Learning et le Deep Learning pour classer automatiquement les documents. Ce processus est beaucoup plus rapide, plus évolutif, précis et plus rentable que la classification manuelle.
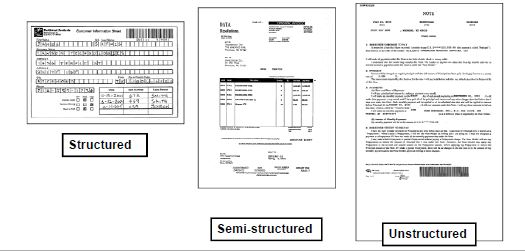
Avant de découvrir les différentes approches de classification automatique des documents, commençons par comprendre les différents types de documents :
- Documents structurés : dans les documents structurés ou les formulaires fixes, les informations sont bien formatées. Les polices et les chiffres sont cohérents et ne présentent pas beaucoup d'écarts. Les mises en page ou modèles sont entièrement statiques. Il est facile de créer une solution automatisée sur des documents structurés, car ils sont prévisibles et cohérents.
- Documents non structurés : ces documents contiennent des informations présentées dans un format ouvert, par exemple des lettres, des commandes, des contrats et des connaissements. Dans les documents non structurés, il est difficile de localiser les coordonnées d'une information particulière, car elles sont incohérentes. Dans certains cas, les tableaux de ces documents ne comportent aucune bordure, ce qui rend plus difficile pour les algorithmes de localiser leur position exacte. Les méthodologies NLP et NER étendues sont largement utilisées pour créer des algorithmes intelligents pour de tels documents.
- Documents semi-structurés : les documents semi-structurés sont généralement une combinaison de documents structurés et non structurés.
Maintenant que nous avons vu différents types de documents, découvrons les différentes techniques qui peuvent être utilisées pour réaliser la classification des documents !
- Apprentissage supervisé : dans cette méthode, le système apprend à partir d'exemples qui ont à la fois des entrées et leurs classes ou sorties correspondantes. L'algorithme est formé sur un ensemble de documents étiquetés manuellement. Une fois la formation terminée, le classificateur peut alors prédire les catégories avec un indicateur de confiance ; même pour les types de données/documents inédits.
- Apprentissage non supervisé : dans cette approche, des documents similaires sont classés en différents groupes sans aucune formation préalable. Cette catégorisation peut être effectuée en fonction du modèle, des mots de police ou des balises, etc. Ces algorithmes peuvent atteindre une plus grande précision si des règles spécifiques sont définies et affinées.
- Basée sur des règles : la technique basée sur des règles est l'une des méthodes traditionnelles de classification de documents qui exploite la capacité de compréhension du langage naturel d'un système et l'écriture de règles grammaticales qui demanderaient au système d'agir comme un humain lors de la classification d'un document. Cette méthode a l’avantage d’améliorer régulièrement les performances au lieu de s’appuyer uniquement sur des statistiques ou des mathématiques comme les deux méthodes précédentes. Cette méthode est associée à une plus grande précision, en particulier dans les scénarios complexes. Cependant, la construction d’un modèle de pointe basé sur des règles prend du temps et est difficile à mettre à l’échelle.
Pourquoi les entreprises utilisent la classification des documents
Aujourd’hui, presque toutes les entreprises doivent gérer des documents pour gérer leurs finances, leurs investissements, leurs opérations, etc. S'appuyer sur une classification manuelle pour de telles tâches est difficile, prend du temps, est sujet aux erreurs et est très inefficace. C'est là qu'intervient le catégoriseur automatique de documents, qui permet aux entreprises, aux entreprises et aux organisations de n'importe quel secteur d'organiser le contenu, en le rendant disponible à tout moment de manière efficace.
Prenons l’exemple d’un responsable des opérations qui surveille régulièrement toutes les opérations essentielles et les tâches liées aux patients au sein d’un hôpital. Il comprend de nombreux documents, tels que des lettres de confirmation de rendez-vous, le suivi des prescriptions des médecins, des détails sur les médicaments, des informations de paiement et d'autres détails sur les rendez-vous. Lorsqu'il s'agit de centaines de patients, il est facile de simplement stocker manuellement ces documents dans différents dossiers. Lorsqu'il existe des milliers de dossiers de ce type, le personnel opérationnel ne peut pas surveiller toutes ces informations individuellement. Cependant, ces dossiers sont extrêmement essentiels à analyser pour prendre de meilleures décisions commerciales. Considérons maintenant le même scénario avec un pipeline de classification des documents en place :
Choisissez des modèles pour différents types de documents
- Ajoutez des métadonnées au modèle comme l'identifiant du patient, l'identifiant de la facture, le médecin consultant, etc.
- Capturer et sauvegarder tous les documents sur une base de données ou une machine et les collecter quotidiennement
- Prétraitez chaque document en fonction du modèle et redimensionnez-les de manière cohérente
- Annotez initialement quelques documents pour former un modèle très précis
- Préparer les annotations et les documents correspondants à l'aide de différents chargeurs de données et fonctions de transformation
- Utilisez un classificateur de documents automatisé (un modèle d'apprentissage automatique ou un modèle d'apprentissage profond) pour séparer ces documents en fonction de leur type
- Évaluer le modèle et affiner les paramètres en fonction des mesures de performance
- Appliquer des algorithmes d'extraction d'informations pour extraire des informations et des tableaux cruciaux
- Exportez toutes les informations dans le format souhaité, tel que CSV, Excel, base de données, etc.
- Déployer des modèles en production pour les utiliser
Un processus automatisé de classification des documents
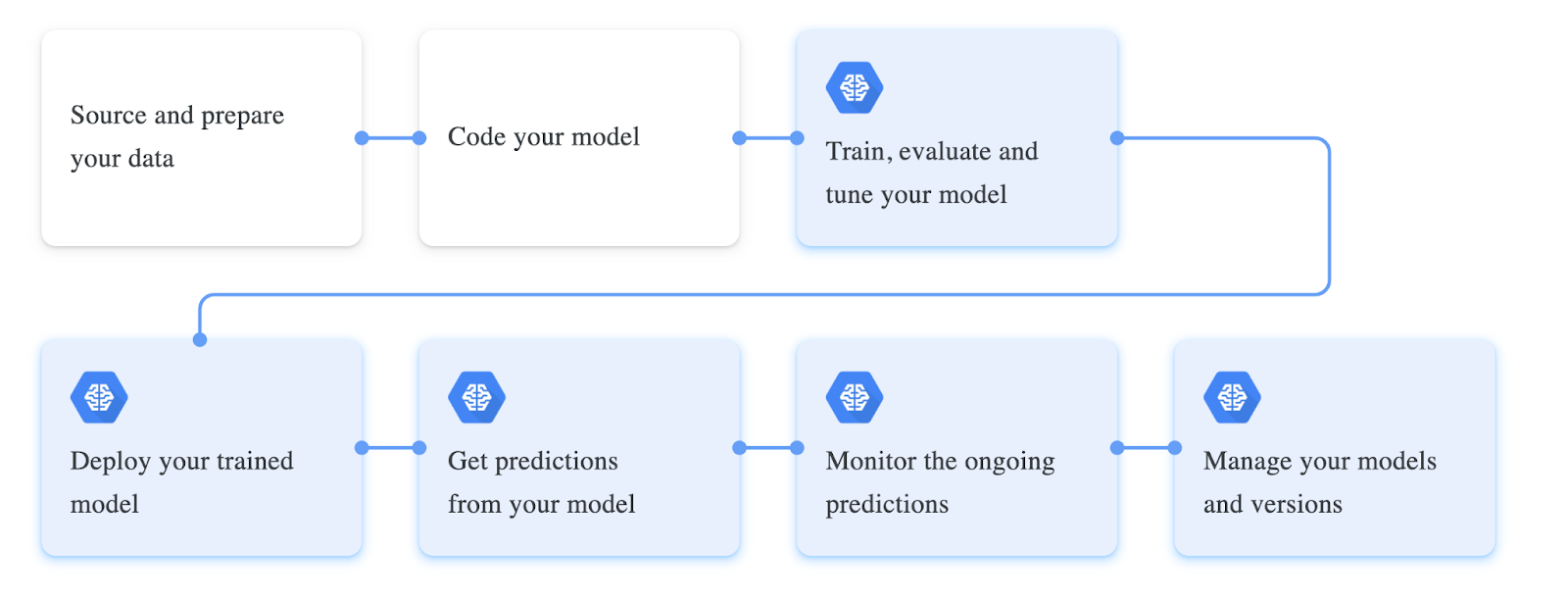
Jusqu'à présent, nous avons vu ce qu'est la classification des documents et les différentes techniques utilisées pour créer de tels algorithmes basés sur différents types de données. Apprenons maintenant un peu plus sur les workflows d'apprentissage automatique et d'apprentissage profond impliqués dans la création de ces algorithmes :
- Collecte de données : les algorithmes de ML ou Deep Learning sont construits et entraînés sur des ensembles de données massifs. Pour créer un algorithme de classification de documents très précis, il est important de rassembler différents types de documents avec suffisamment d'exemples pour chaque catégorie afin que l'algorithme puisse apprendre à les différencier. Cependant, si les données sont incohérentes ou non structurées, il est fortement recommandé d'effectuer quelques étapes de prétraitement.
- Mise en place des hyperparamètres : cette partie est cruciale pour entraîner tout modèle de machine learning ou de deep learning ; nous devrons définir tous les paramètres critiques utilisés pour entraîner le modèle. Principalement, déterminer la bonne fonction de coût et le bon optimiseur est extrêmement essentiel. Cependant, sur la base des métriques, nous pouvons les affiner pour rendre le modèle beaucoup plus précis.
- Entraînement du modèle : L'étape suivante consiste à entraîner le modèle après avoir chargé et défini les hyperparamètres. Si votre modèle est basé sur des algorithmes d'apprentissage automatique classiques, nous pouvons coder la logique basée sur l'algorithme ou importer les modèles à partir de bibliothèques populaires. Si le modèle est basé sur des réseaux de neurones, nous devrons peut-être en définir un en fonction des données, ou affiner un modèle sur des architectures populaires telles que VGG16, RESNET, etc. Si vous débutez, vous pouvez consulter un quelques bibliothèques ML/DL open source basées sur Python comme Tensorflow, PyTorch, Sklearn.
- Évaluation du modèle : une fois le processus de formation terminé, il est essentiel de l'évaluer sur des données invisibles. Pour cela, dans la plupart des cas, l’ensemble de données sera initialement divisé en ensembles d’entraînement et de test. Nous utiliserons l'ensemble de données de formation pour la formation et, à des fins d'évaluation, nous utiliserons l'ensemble de données de test ; la répartition moyenne est généralement de 7 : 3 pour les ensembles de données d’entraînement et de test, respectivement. Quelques mesures fréquemment prises en compte incluent le score de rappel de précision, la matrice de confusion et l'erreur quadratique moyenne.
Voici les différentes étapes impliquées dans le développement et la formation d’un réseau neuronal profond :
Classificateur de documents Nanonets
Dans ce blog, nous avons appris beaucoup de choses sur la classification des documents et parlé de quelques cas d'utilisation sur la façon dont la classification des documents peut aider à automatiser les tâches manuelles. De plus, nous avons discuté d'un flux de travail basé sur l'apprentissage en profondeur qui peut nous aider à créer un classificateur de documents entièrement à partir de zéro. Mais que se passerait-il si nous vous disions qu'il existe un moyen de former des modèles de classification de documents personnalisés sur vos données sans écrire de code ?
Nanonets est une plate-forme OCR sans code basée sur l'IA qui peut vous aider à automatiser vos cas d'utilisation de traitement manuel de documents de saisie de données. Créez/entraînez des modèles OCR sur vos propres données et exportez-les au format JSON/CSV ou dans tout autre format souhaité.
Construire un classificateur de documents sur des nanonets
Si vous souhaitez créer un classificateur de documents, vous pouvez commencer avec le séparateur de types de documents ou le catégoriseur de documents pré-entraînés Nanonets.
- Inscrivez-vous ou connectez-vous à Nanonets.
- Choisissez maintenant « Créer un séparateur de type de document » sous le tableau de bord.
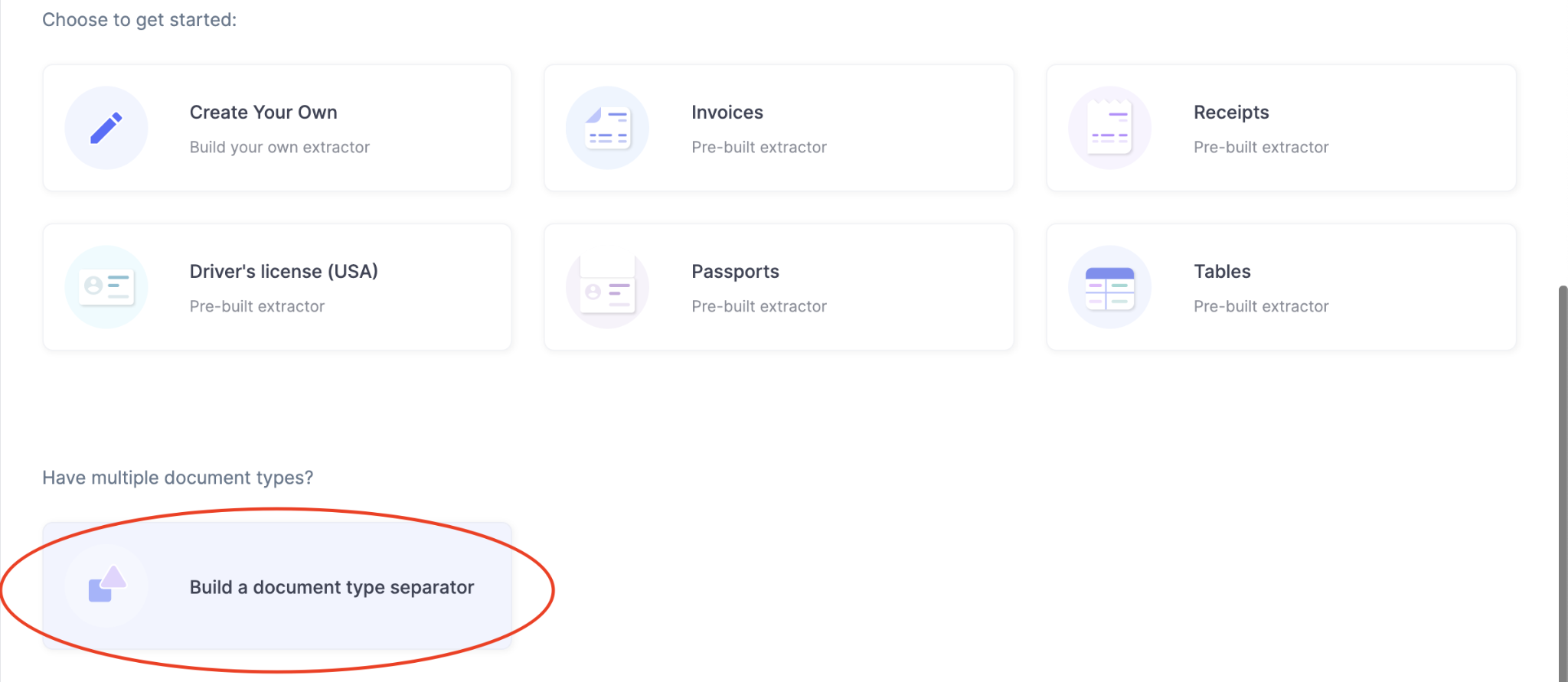
- Ensuite, spécifiez les différents types ou classes de documents que vous souhaitez classer. Par exemple, disons que nous cherchons à organiser trois documents : les factures de transport aérien, les factures et les fiches de salaire. Nous pouvons définir les catégories sur airway_bills, factures, salaires_slips.
- Ensuite, téléchargez des exemples de documents basés sur les classes et cliquez sur le bouton Train. Une fois la formation terminée, les mesures d'évaluation sont affichées. Sur la base des métriques, recyclez-vous ou continuez avec le modèle existant.
- Vous pouvez également télécharger des données invisibles et utiliser des API ou des webhooks pour déduire le modèle formé !
Et juste comme ça, sans écrire le moindre morceau de code, nous disposons d’un modèle de classification de documents très performant !
Pourquoi utiliser les nanonets
Voici quelques-uns des avantages de l’utilisation de Nanonets comme classificateur de documents.
Interface utilisateur simple : Nanonets fournit une interface utilisateur simple et facile à utiliser pour former des modèles d'apprentissage automatique de pointe. Tout ce que nous avons à faire est de télécharger les documents, de les annoter et de les entraîner sans écrire une seule ligne de code à l'intérieur de la plateforme.
Ajouter des règles et des paramètres personnalisés : lors de la formation de modèles sur des Nanonets, cela nous offre la possibilité de personnaliser les modèles. Grâce à cela, nous pouvons choisir des champs particuliers à extraire sur nos documents. Par exemple, si vos documents commerciaux comportent 100 champs et que vous souhaitez simplement extraire une trentaine de champs, Nanonet peut vous aider à le faire en sélectionnant simplement les champs nécessaires sur le modèle. Cela s'applique à tous les documents en configurant simplement un seul modèle.
Haute précision, moins de temps de traitement : Nanonets est très connu pour ses modèles de pointe, car il offre une précision de plus de 95 % dans l'identification du texte, des tableaux et des paires clé-valeur n'importe où dans les documents. Toutes les données extraites peuvent être évaluées sur l'interface graphique, en cas d'erreurs, la valeur correcte peut être mentionnée et le modèle se rectifie en un rien de temps.
Fonctionnalités de post-traitement : Nanonets offre la possibilité d'ajouter des règles de post-traitement même après la formation du modèle. Nous pouvons donc ajouter des informations supplémentaires à la sortie sans réentraîner le modèle.
Intégrer des applications : les Nanonets peuvent facilement s'intégrer à tout type de sources de données telles qu'Excel, Google Sheets et bases de données à l'aide d'outils d'automatisation tels que Zapier. Leur utilisation dans nos flux de travail nous aidera à exécuter des tâches en arrière-plan sans aucune intervention humaine !
API et Webhooks : Nanonets fournit une large gamme d'API avec une excellente documentation à l'appui. Grâce à ceux-ci, nous pouvons facilement utiliser des modèles formés dans des projets Web sans nous soucier de l'infrastructure. De plus, les webhooks peuvent être utilisés pour alimenter le partage de données unidirectionnel basé sur des déclencheurs.