Document APIs for agents and developers
Use the world's best models to transform documents into data. Built for AI agents and modern applications.











.svg)






.svg)

Community
The world's best open source models
Don't take our word for it, here's what the community has to say
1M+
DOWNLOADS ON HUGGINFACE
#1
POST ON HACKER NEWS
X
THIS GUY AT HUGGINGFACE SAID WE'RE COOL
Skip the build. Deploy AI Agents
Let our experts deploy a fully managed AI workforce that understands your documents and syncs your data natively to ERPs like SAP, Oracle, and Salesforce.
MODEL COMPARISON
Leading the Benchmarks
Nanonets-OCR2-Plus outperforms all foundational models and open-source alternatives on industry-standard benchmarks

WHY CHOOSE NANONETS
Built for developers who demand precision, speed and control

On-premise from day 0
Deploy on your infrastructure with complete data sovereignty and security from the start.
Most useful tool for document agents
Purpose-built for AI agents with structured outputs and seamless integration capabilities.
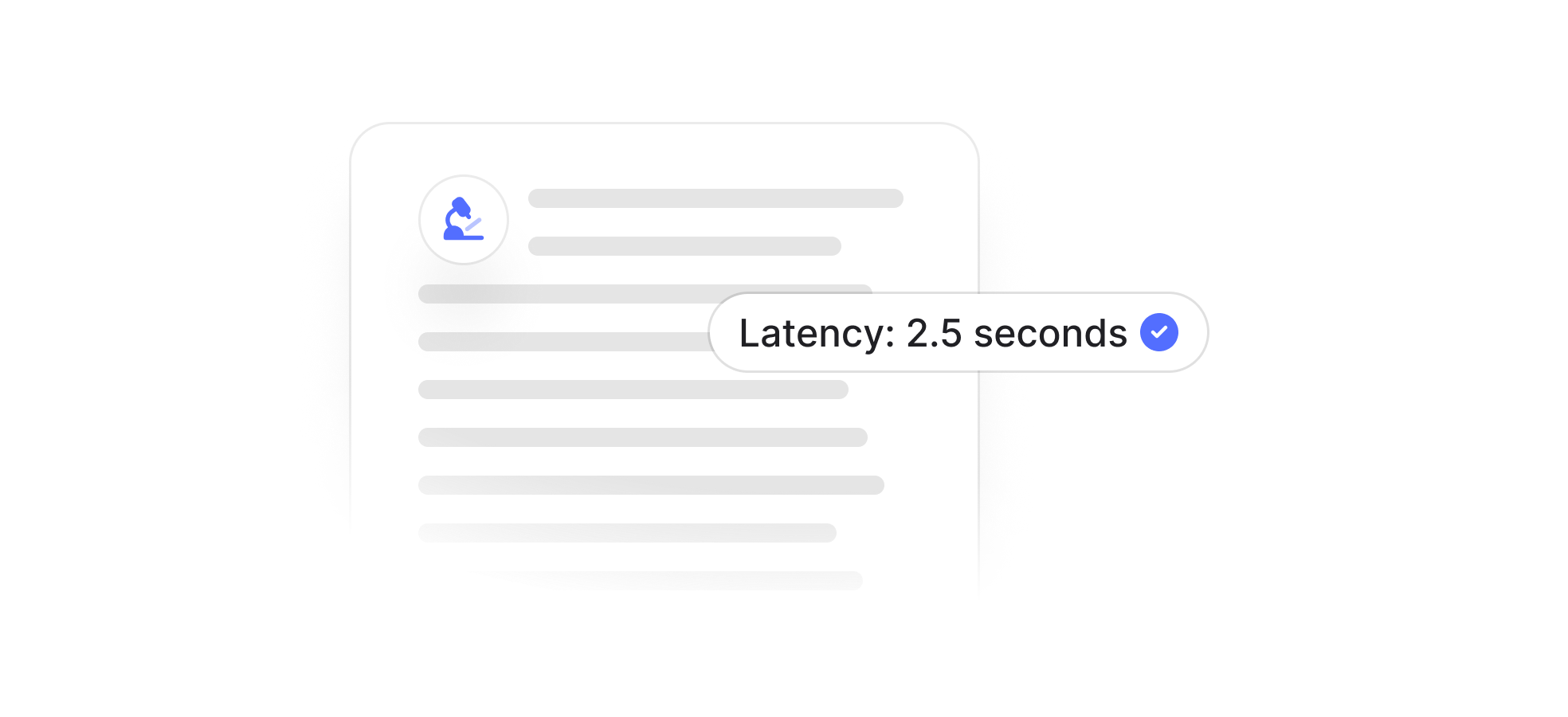
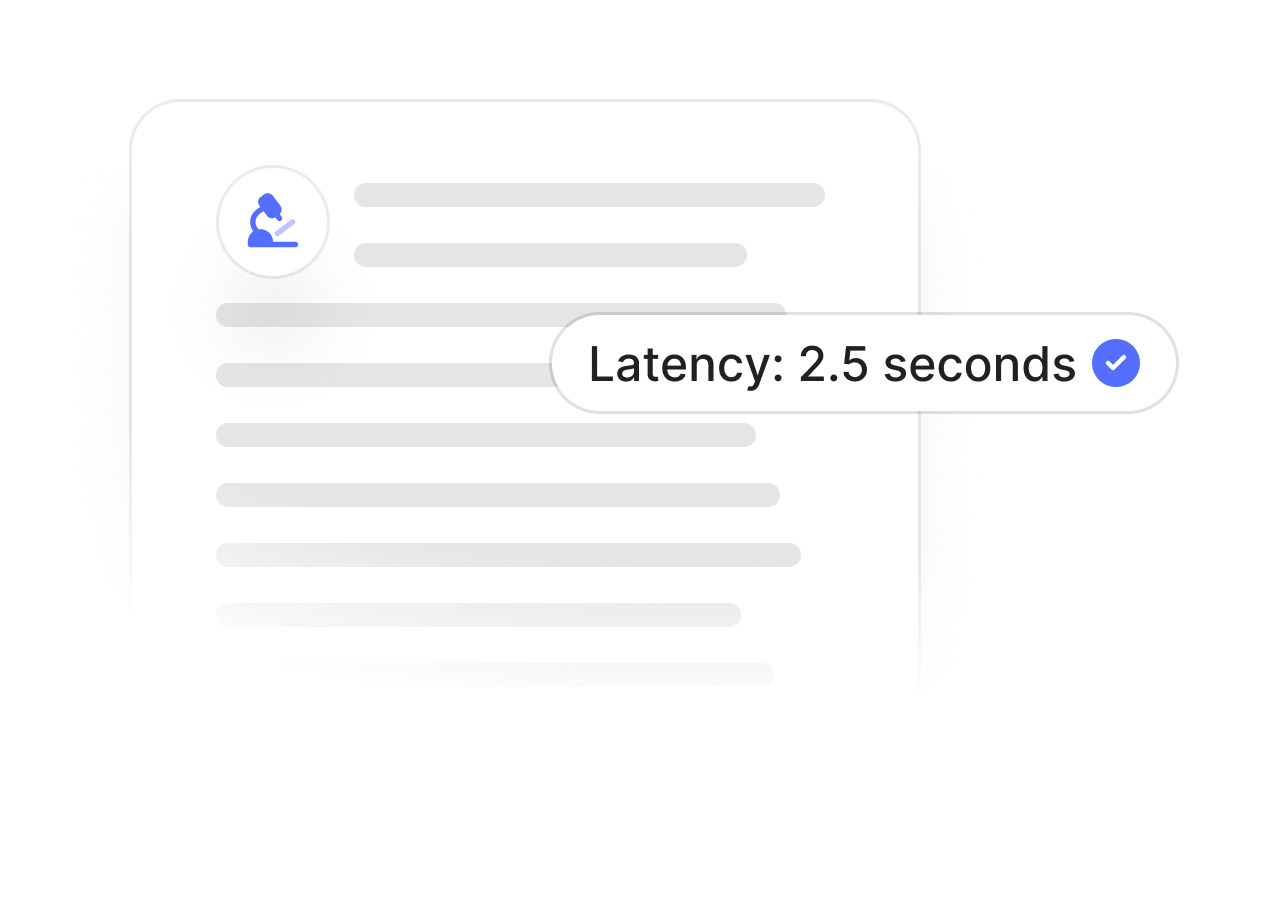
Low latency, high throughput
Easy setup in 2 lines of code with lightning-fast processing and enterprise-grade scalability.


Highest accuracy for RAG applications
State-of-the-art accuracy for document understanding and retrieval augmented generation workflows.
Benchmark results based on Key Information Extraction (KIE) accuracy across multiple document types
OUR APIs
From document to decision, automated
See what we offer for each of your document usecases
Document to JSON
Extract structured data from documents into JSON format. Perfect for feeding data into databases, APIs, and AI applications.

Custom schemas
Nested objects
Type validation
Learn more
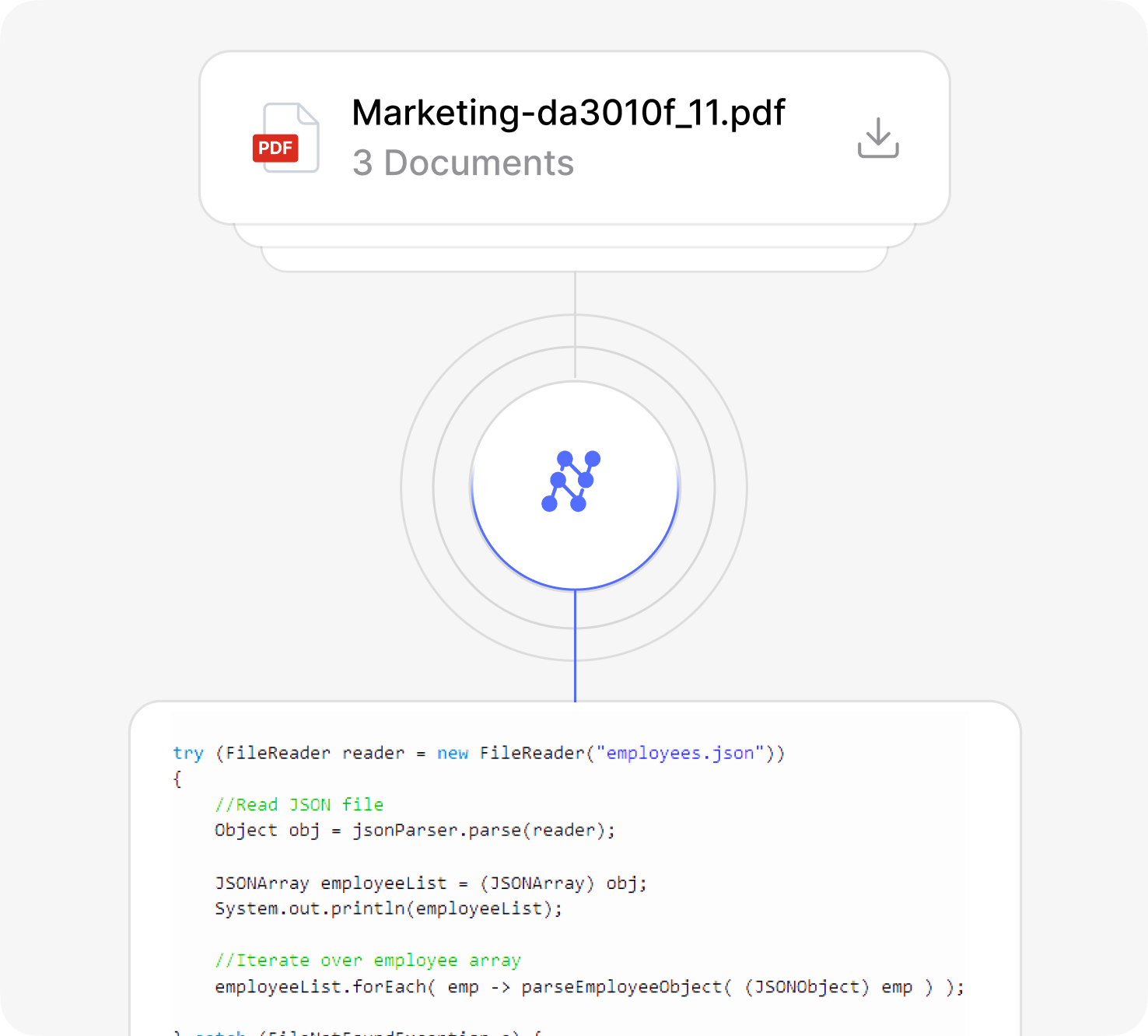

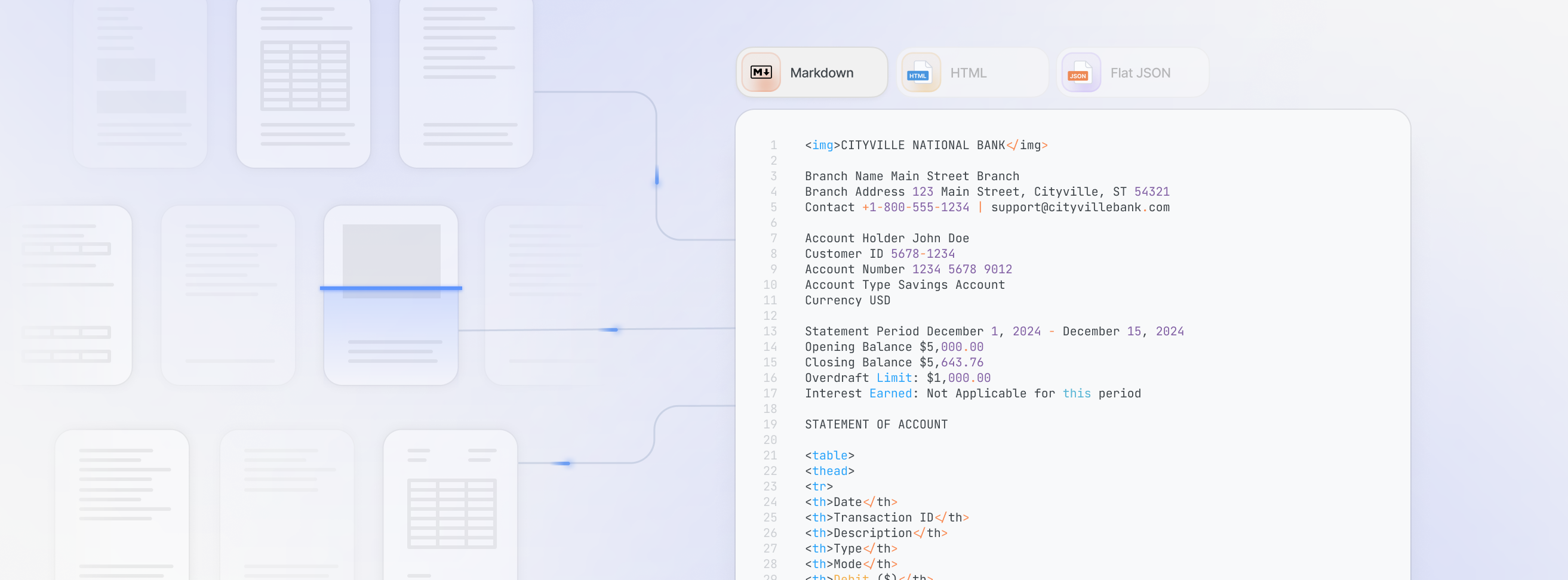
Document to Markdown
Convert any document into clean, structured Markdown with perfect formatting preservation. Ideal for content pipelines and documentation workflows.
Preserves formatting
Table extraction
Header hierarchy
Learn more
Classify and Split
Automatically classify document types and intelligently split multi-document files. Streamline your document processing pipeline.
Auto-classification
Smart splitting
Batch processing
Learn more
FEATURES YOUR TEAM WILL LOVE
Everything you need for production-grade document processing
Layout Understanding
Automatically classify document types and intelligently split multi-document files. Streamline your document processing pipeline.

LLM Ready
Optimized outputs for large language models with structured data formats.
Multi-Language Support
Process documents in 100+ languages with native OCR and understanding capabilities.
.png)
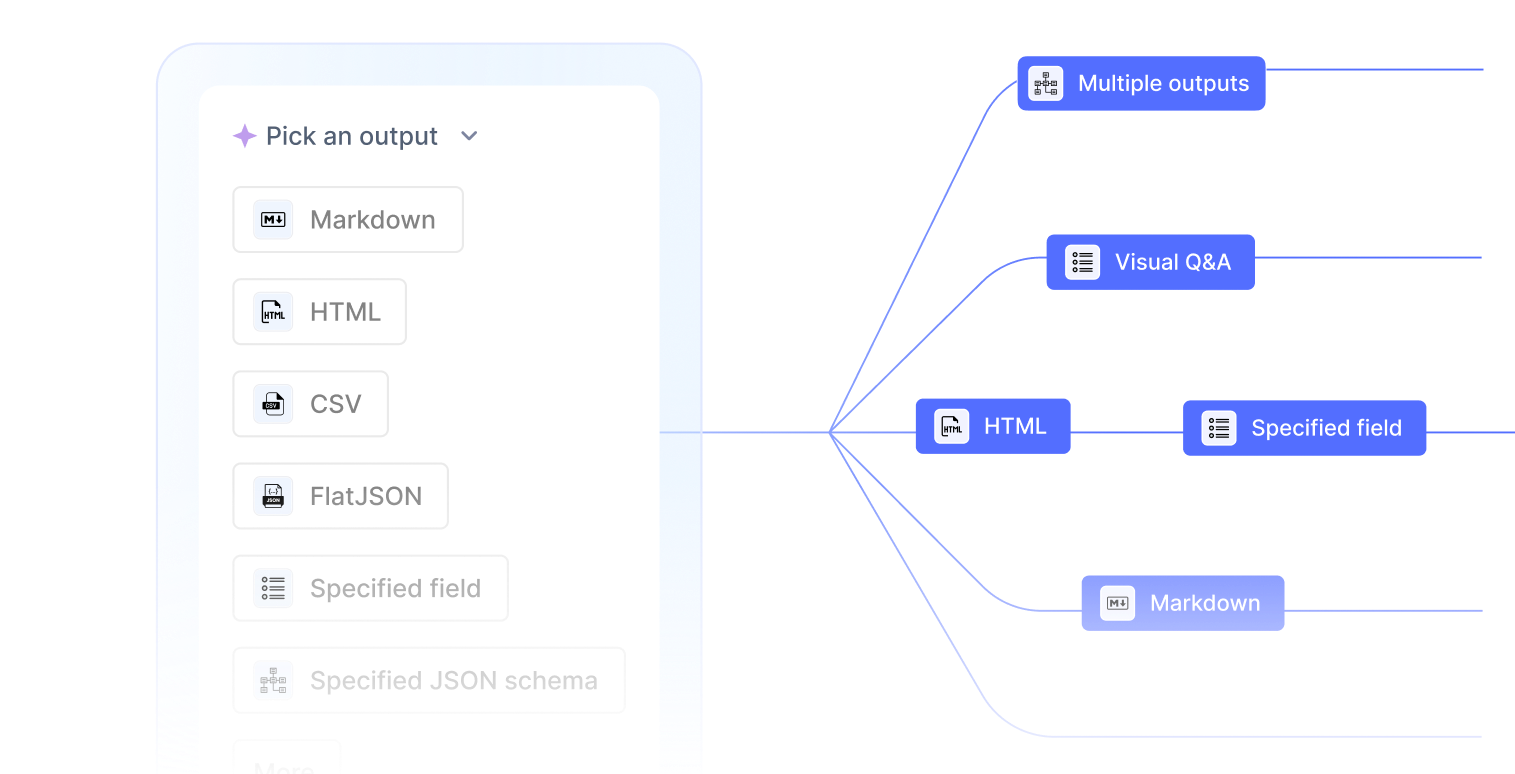
All Input & Output Types
Support for PDF, images, Word, Excel, and more. Output to JSON, Markdown, CSV, or custom formats.

See what teams are saying about us
Trusted by Developers
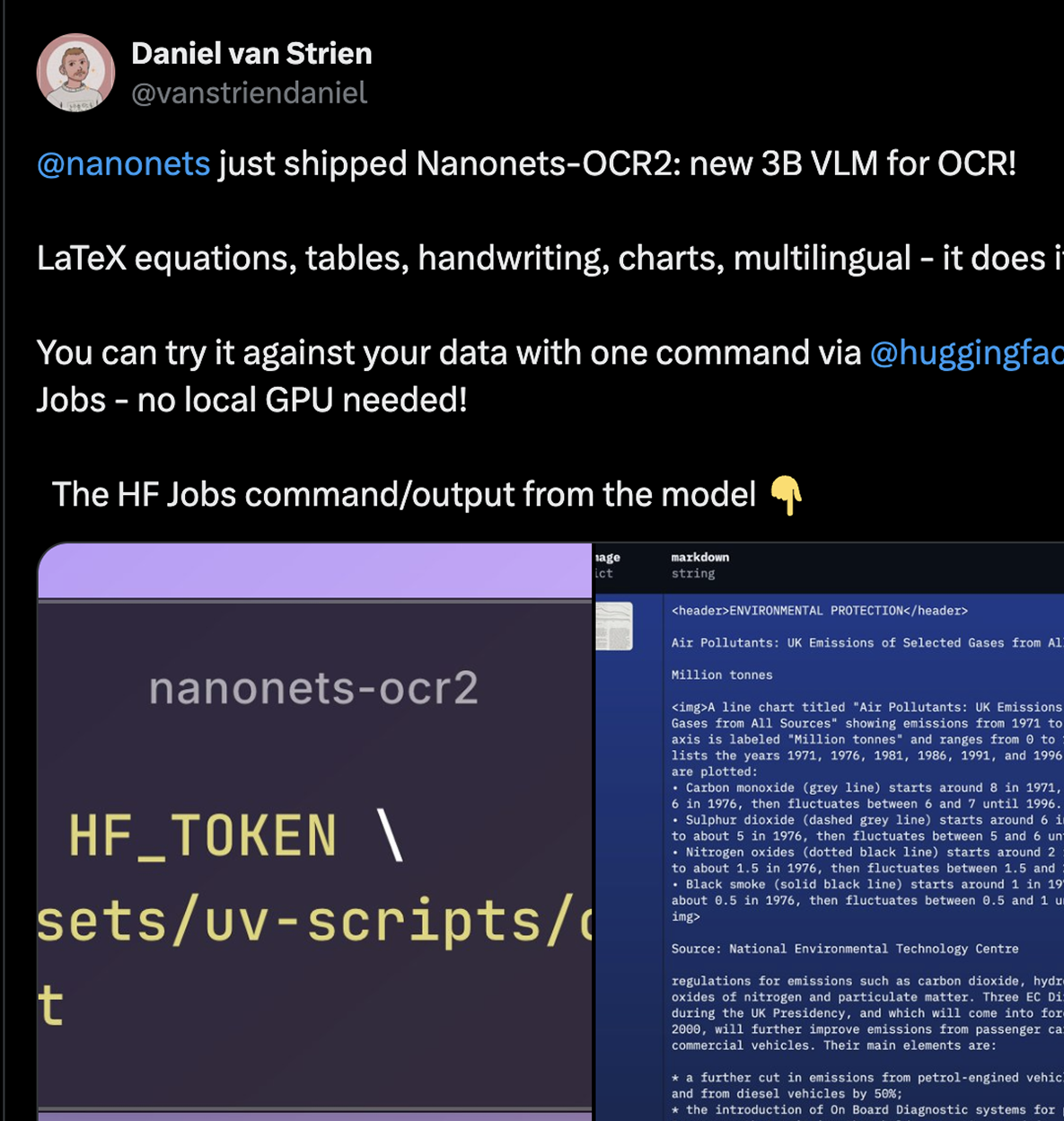
icymi there's a two new Nanonets OCR models, Nanonets-OCR2-3B and Nanonets-OCR2-1.5B-exp
this model can handle forms (checkboxes), recognize watermarks, describes images, charts in docs and more!
it even handles flowcharts it's multilingual and Apache-2.0 licensed

merve

Open Source @ HuggingFace
just deployed Nanonets-OCR2 on nvidia RTX PRO 6000 blackwelli cannot max it!
the model is too small and the GPU is too powerful!

Maziyar PANAHI
Creator of @OpenMed_AI
One of the best OCR tools is @nanonets OCR.It works very well even when text and background colors are the same.I highly recommend it; it's much better than others.

Shivam Baldha
Engineering Lead at DataCore
Finally @nanonets (an SF-based document AI startup) released Nanonets-OCR2 on the hub.
A 3B multilingual VLM which can handle a huge range of things from checkboxes to LaTeX and complex tables
It beats Gemini 2.5 Flash and GPT-5 on their internal benchmarks

Niels Rogge
ML Engineer @ ML6Team
After 1M+ downloads of their previous model, @nanonets is launching Nanonets-OCR2, a next-gen suite for image-to-markdown conversion & visual QA.
From LaTeX math & tables → mermaid charts, signatures → watermarks. It handles it all.

Y Combinator
Only 2 models (GPT-5 and nanonets-ocr2-3B) pass the phishing test, again highlighting how you cannot blindly trust VLMs.
VLMs dont read text, they predict it.Attached individual results for all models tested.

Rann
Data security is our top priority
Nanonets prioritises the confidentiality and integrity of your data. As a testament to our commitment, we adhere to stringent compliance standards, including GDPR, SOC 2, and HIPAA. Privacy Policy



why choose nanonets
Built for developers who demand precision, speed and control

Highest accuracy for RAG applications
State-of-the-art accuracy for document understanding and retrieval augmented generation workflows.

Most useful tool for document agents
Purpose-built for AI agents with structured outputs and seamless integration capabilities.
On-premise from day 0
Deploy on your infrastructure with complete data sovereignty and security from the start.

Low latency, high throughput
Easy setup in 2 lines of code with lightning-fast processing and enterprise-grade scalability.
features your team will love
Everything needed for production-grade document processing in single API call

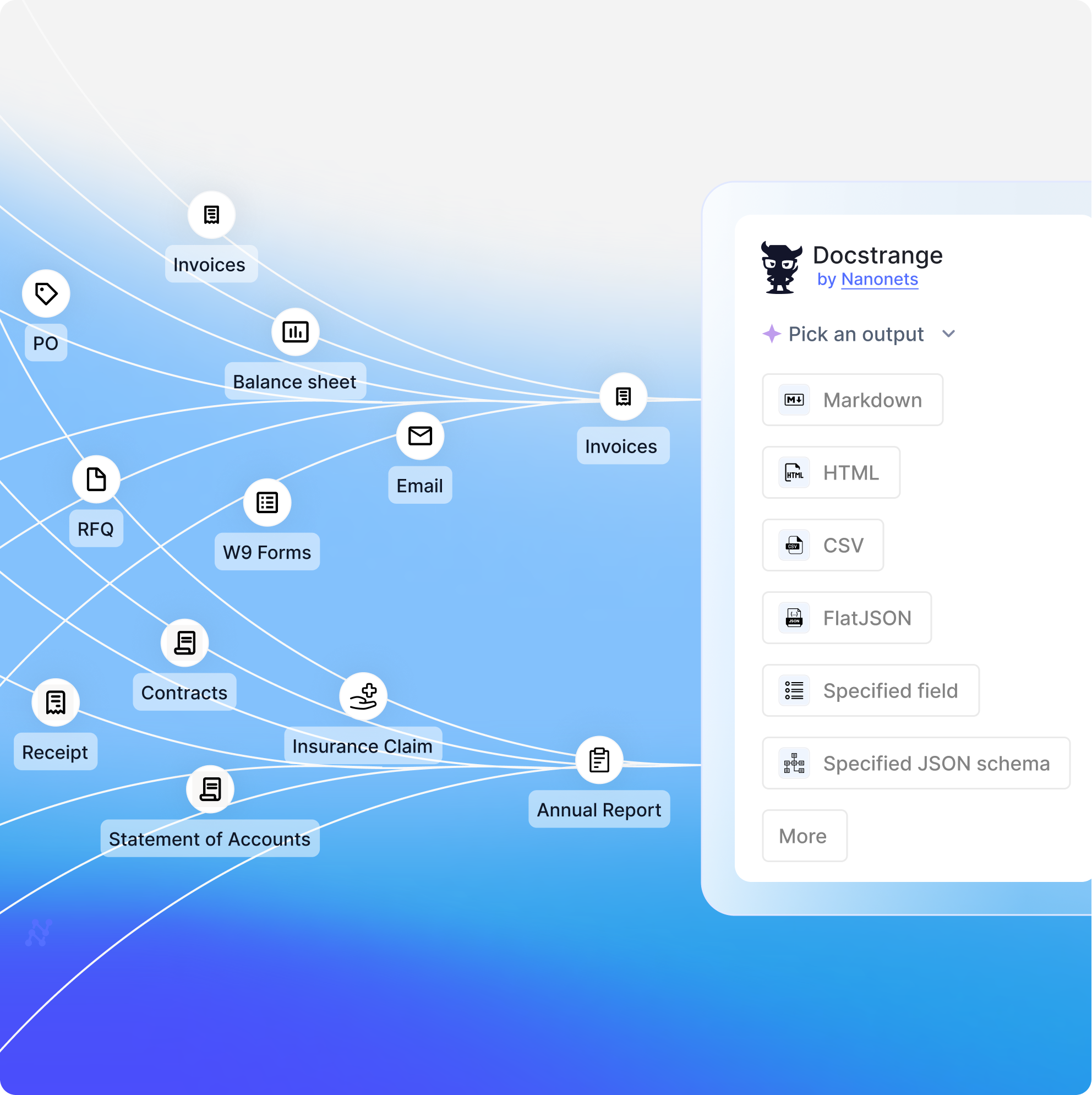

Layout understanding
Advanced layout detection preserves document structure, tables, and hierarchies with pixel-perfect accuracy.
LLM Ready
Optimized outputs for large language models with structured data formats.
Multi-language Support
Process documents in 100+ languages with native OCR and understanding capabilities.
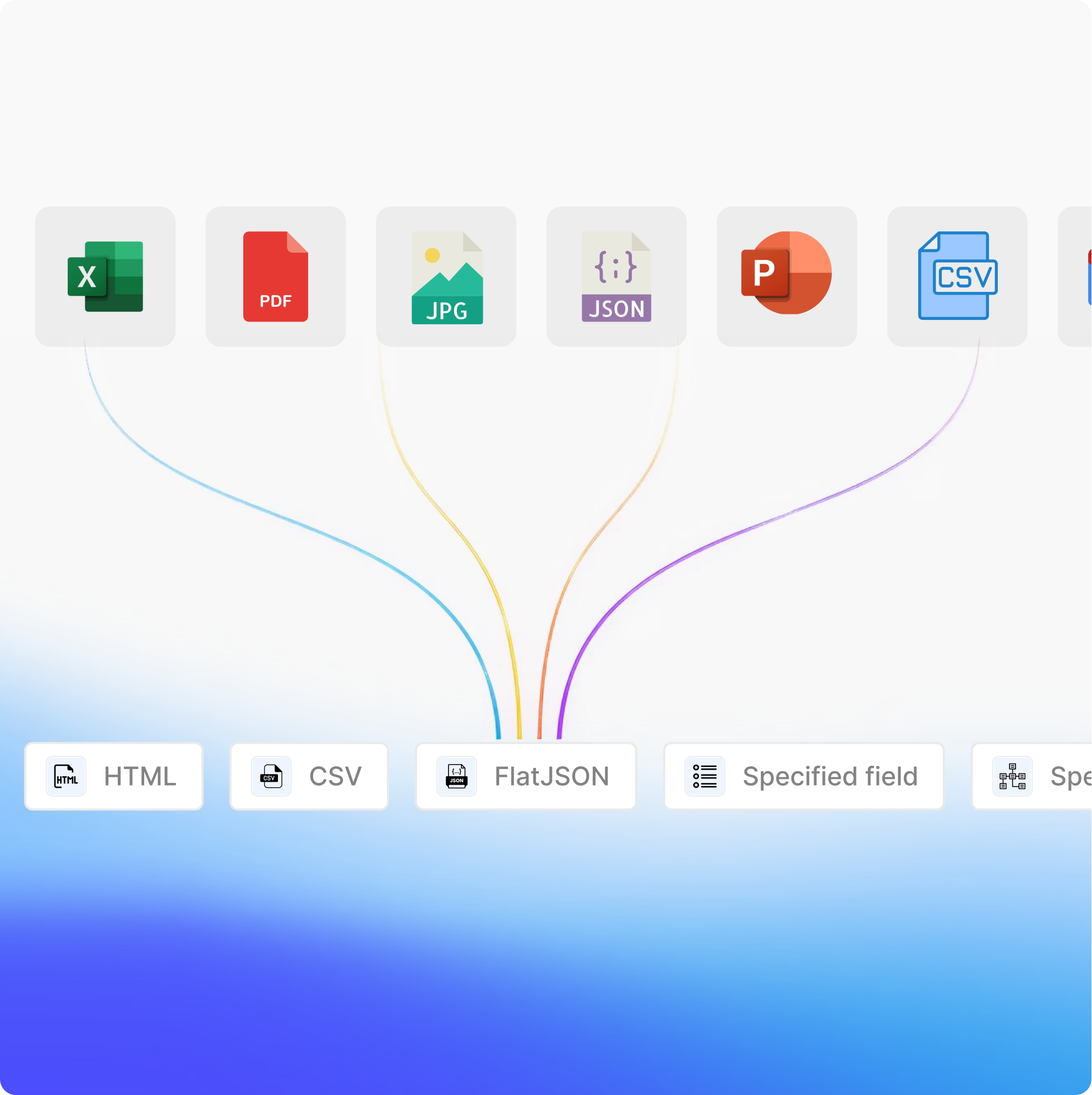
All Input & Output Types
Support for PDF, images, Word, Excel, and more. Output to JSON, Markdown, CSV, or custom formats.
On-Premise Deployment
Full control over your data with on-premise deployment options and enterprise security compliance.
Our APIs
Products
See what we offer for each of your document usecases
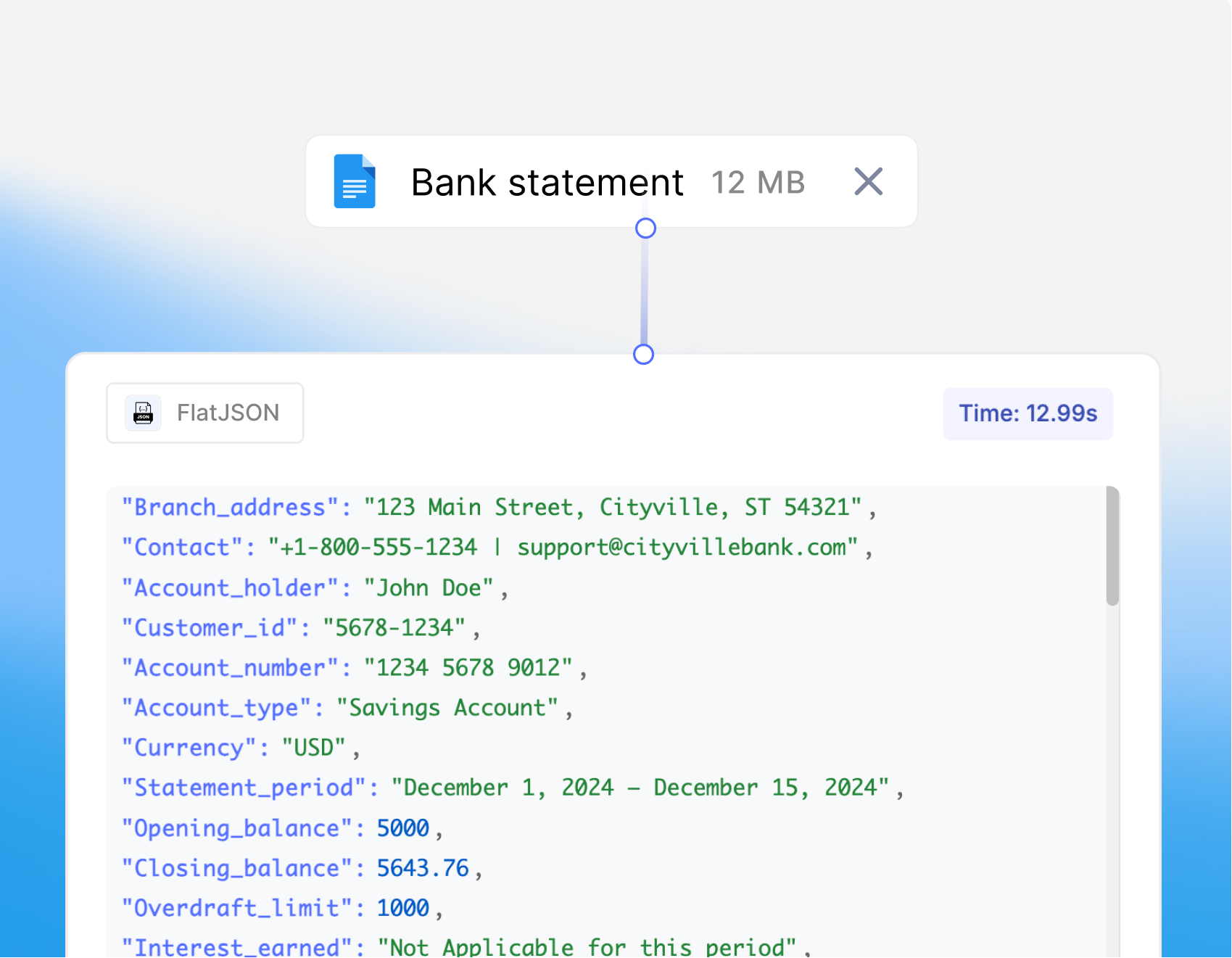

Document to JSON
Extract structured data from documents into JSON format. Perfect for feeding data into databases, APIs, and AI applications.

Custom schemas
Nested objects
Type validation
Document to Markdown
Convert any document into clean, structured Markdown with perfect formatting preservation. Ideal for content pipelines and documentation workflows.
Preserves formatting
Table extraction
Header hierarchy

Classify and Split
Automatically classify document types and intelligently split multi-document files. Streamline your document processing pipeline.
Auto-classification
Smart splitting
Batch processing
why choose nanonets
Built for developers who demand precision, speed and control

On-premise from day 0
Deploy on your infrastructure with complete data sovereignty and security from the start.
Highest accuracy for RAG applications
State-of-the-art accuracy for document understanding and retrieval augmented generation workflows.
Most useful tool for document agents
Purpose-built for AI agents with structured outputs and seamless integration capabilities.
Low latency, high throughput
Easy setup in 2 lines of code with lightning-fast processing and enterprise-grade scalability.



On-premise from day 0
Deploy on your infrastructure with complete data sovereignty and security from the start.

Highest accuracy for RAG applications
State-of-the-art accuracy for document understanding and retrieval augmented generation workflows.

Most useful tool for document agents
Purpose-built for AI agents with structured outputs and seamless integration capabilities.

Low latency, high throughput
Easy setup in 2 lines of code with lightning-fast processing and enterprise-grade scalability.