For engineering teams
Document extraction your pipeline can rely on.
A production-grade API that reads any document and returns structured JSON. Plug into LangChain, LlamaIndex, or your own agent stack. Ranked #1 on the IDP Leaderboard.
How it works
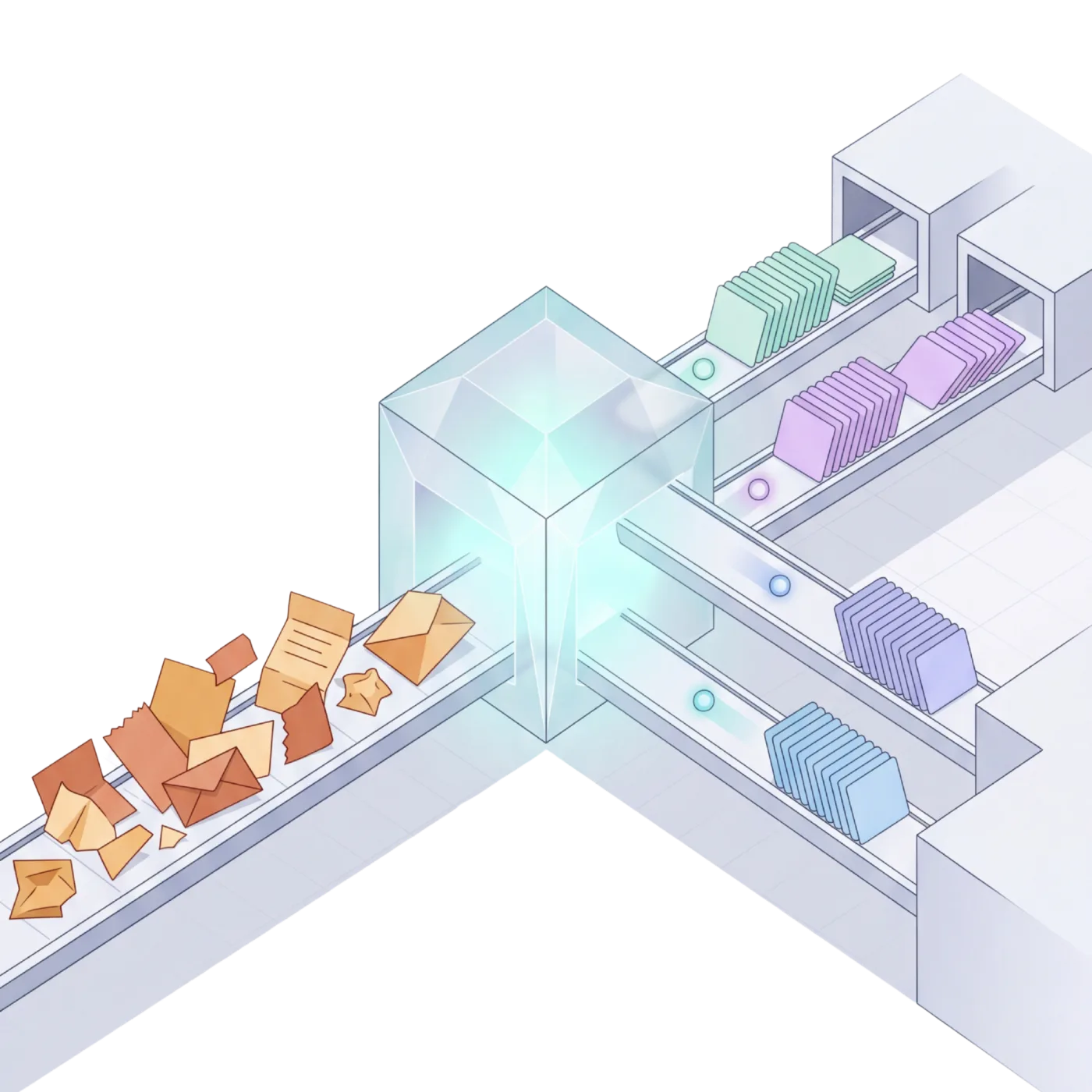
Send. Extract. Validate. Deliver. Your pipeline handles decisions. The API handles documents.
Use cases
Every document problem engineering teams run into.
One API, one integration.
Document extraction API
POST any document, get structured JSON back. Invoices, contracts, forms, receipts, bank statements. Tables preserved as arrays. Line items extracted with quantities, amounts, and codes. Plugs into any backend.
Agent pipeline integration
Drop Nanonets into your LangChain or LlamaIndex pipeline as a document reader tool. The extraction layer handles unstructured input so your agent logic can focus on decisions, not parsing.
Custom model training
Start with a pre-trained extraction model and fine-tune on your document types. Upload samples, label fields, and deploy a model specific to your vendors, formats, and business rules.
Webhook-triggered automation
Configure webhooks to fire on document receipt, extraction complete, or exception flagged. Build event-driven pipelines without polling. Retry logic and delivery guarantees included.
Multi-format ingestion
One API endpoint handles PDFs, scanned images, Word documents, spreadsheets, and email attachments. No per-format routing, no format detection code. The same structured output regardless of input type.
ERP and database posting
Pre-built connectors push extracted data directly to SAP, NetSuite, Oracle, and Dynamics. Or deliver clean JSON to your own database. The pipeline ends at the system of record, not a staging file.
Built for production
Document extraction that holds up in production. Not just in demos.
Not a generic LLM wrapper. Nanonets is built specifically for document extraction accuracy — field-level validation, table structure preservation, and business rule application. Benchmarked against every major IDP platform.
99%+ field accuracy on real documents from real vendors, not clean test sets. Handles handwriting, poor scans, multi-page invoices, and unusual layouts without manual intervention or per-sender template maintenance.
GL coding logic, duplicate detection, approval routing, and validation rules live in a context graph, not in your codebase. Change a rule without a deployment. Your application stays clean.
LangChain, LlamaIndex, REST, webhooks, direct ERP connectors. Nanonets fits into the pipeline you are building — it does not ask you to rebuild your architecture around it.
Agents used by engineering teams


"We evaluated every major IDP vendor. Nanonets was the only one that handled our document variety out of the box and gave us an API we could actually build on without maintaining per-sender templates."
See it run on your process, with your documents.
Start free. No credit card. Or talk to our team about your workflow.