Data Extraction Agent
AI document parsing and extraction
Convert complex documents into clean, structured data for LLM-based use cases. RAG pipelines, AI agents, JSON extraction, and more.
Not building a pipeline? See Data Extraction for AP, orders, and logistics



Quick start
Upload a document. Get structured data back.
No templates, no per-format setup, no prompt engineering. The API returns clean markdown plus structured JSON for tables and fields.
View full API reference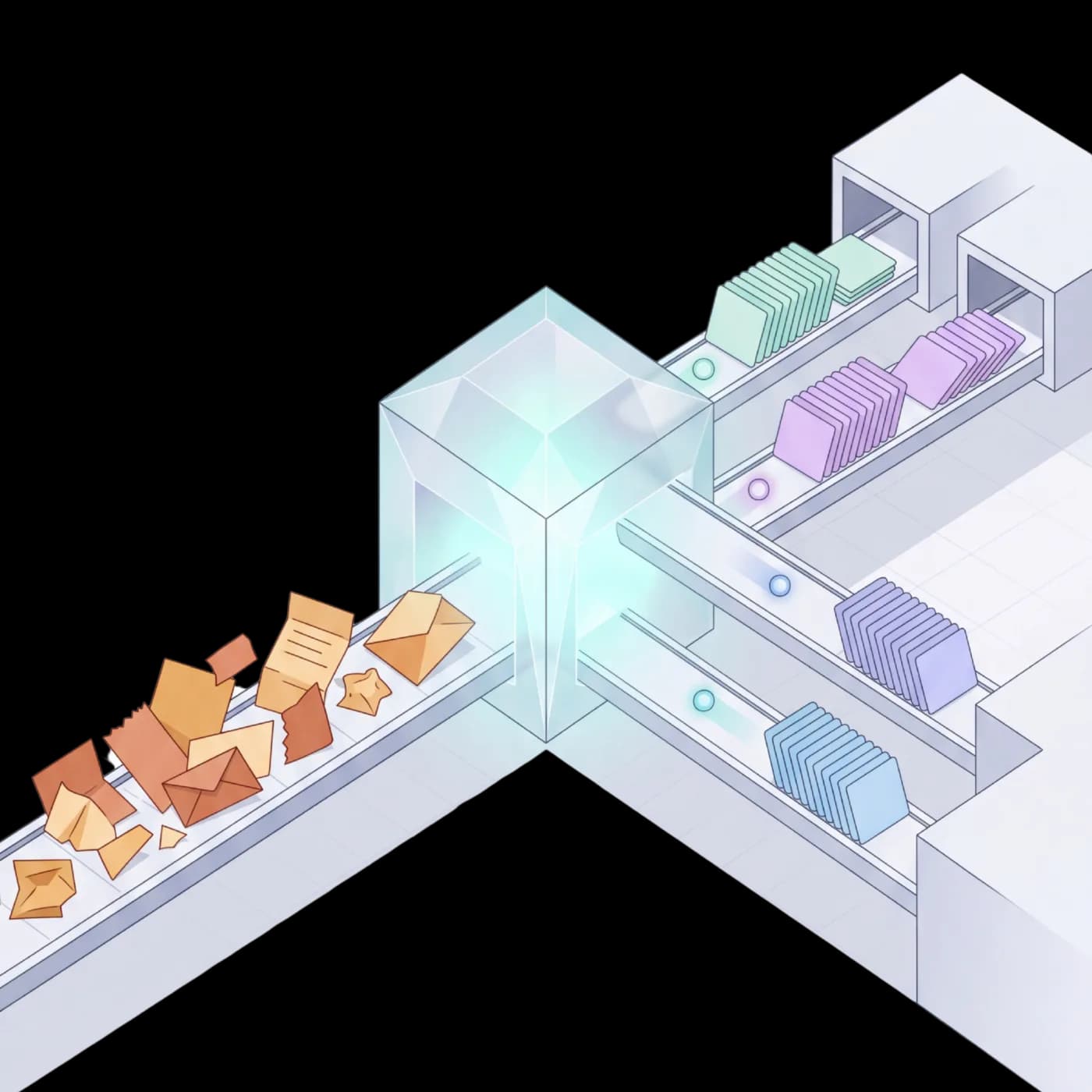
Flexible APIs
APIs to parse, extract, chunk. One endpoint per job. Consistent schema across all of them.
Parse
Parse documents the way a person does. Layout, structure, and meaning preserved. The agentic layer reviews and corrects outputs in real-time, even on edge cases.
See API docs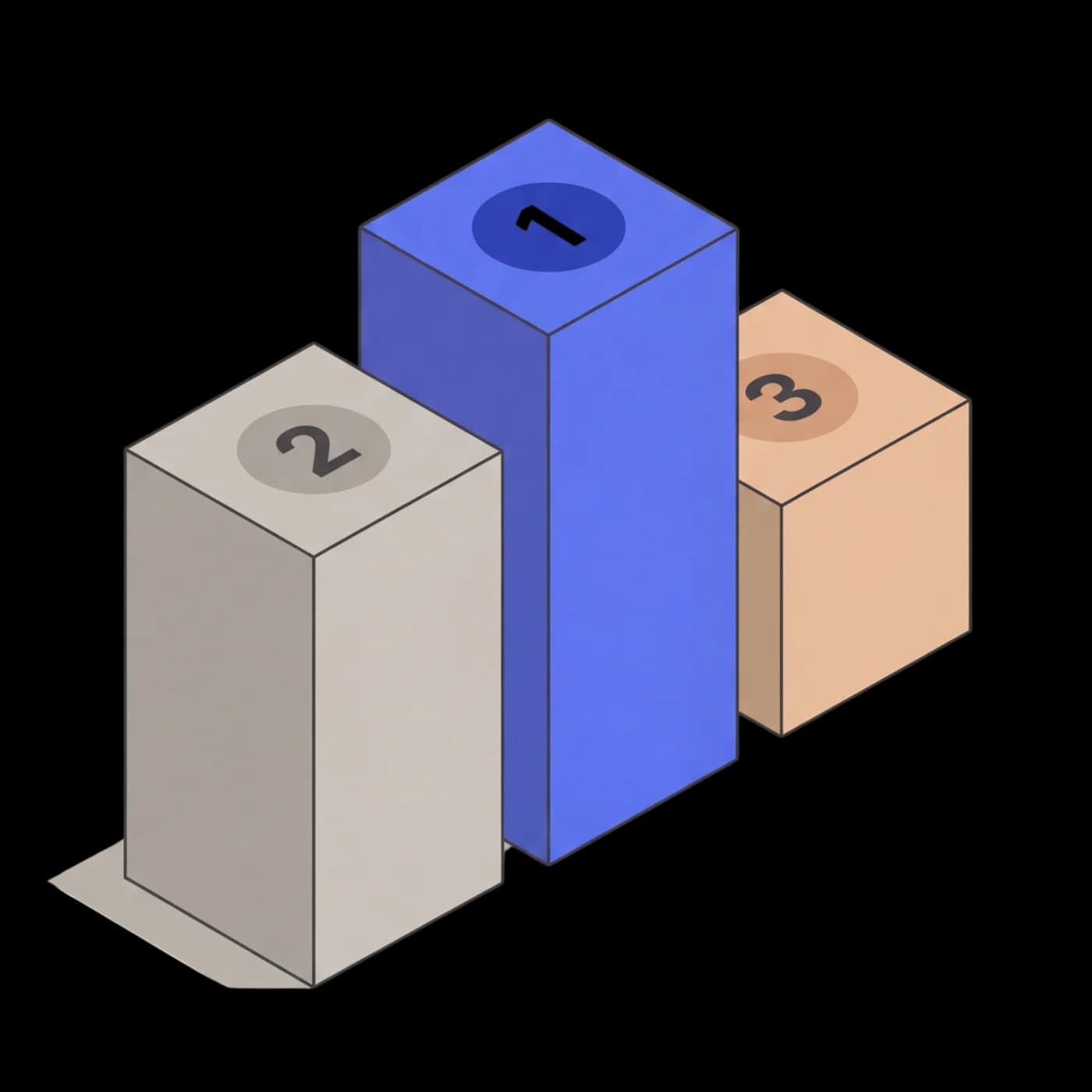
IDP Leaderboard
Ranked #1 overall.
Higher combined accuracy than GPT-5.4, Gemini 3 Pro, and every other VLM across OlmOCR, OmniDoc, and IDP Core.
Available via API. Deploy in your own VPC or on-prem for strict data residency and compliance.
Capability profile
Strong across every dimension.
Text extraction, formulas, tables, layout, key information, and visual QA — one model handles every document understanding task in a single API.
Real-world performance
Public benchmarks saturate. We score the documents that ship to production.
Trained and tested on the document types that hit real extraction pipelines every day — dense filings, multi-column legal text, clinical records.
Enterprise-ready
Security, scale, support.
Built for your most demanding production pipelines.
Feature-rich
Everything an agent needs. Nothing it doesn't.
Two-line setup, lightning-fast processing, enterprise-grade scalability.
State-of-the-art accuracy for document understanding and retrieval pipelines.
Purpose-built outputs and integrations for agent frameworks and LLM tool use.
Native OCR and understanding across 100+ languages, including mixed-script documents.
PDFs, images, Word, Excel in. JSON, Markdown, CSV, or custom shapes out.
Classify document types and split multi-document files automatically.
Developers love Nanonets
Trusted by top AI teams and developers.
“icymi there's two new Nanonets OCR models, Nanonets-OCR2-3B and Nanonets-OCR2-1.5B-exp. It even handles flowcharts and it's multilingual and Apache-2.0 licensed.”
“Just deployed Nanonets-OCR2 on nvidia RTX PRO 6000 blackwell. I cannot max it! The model is too small and the GPU is too powerful.”
“Finally @nanonets released Nanonets-OCR2 on the hub. A 3B multilingual VLM which can handle complex document layouts, tables, math, watermarks and more.”
“After 1M+ downloads of their previous model, @nanonets is launching Nanonets-OCR2, a next-gen suite for image-to-markdown conversion.”
“One of the best OCR tools is @nanonets OCR. It works very well even when text and background colors are the same. I highly recommend it.”
“Nanonets played a pivotal role in AP automation at Asian Paints. Document extraction was key, and it led to faster reimbursement claims and reduced errors.”
Open-source contributions
Community pulse.
Open-sourcing models and research is how we contribute to the broader document AI community.
See it run on your process, with your documents.
Start free. No credit card. Or talk to our team about your workflow.