
Meta just released Muse Spark. The announcement says it beats GPT-5.4 on health tasks, ranks top-five globally on the Artificial Analysis Intelligence Index, and scores 89.5% on something called GPQA Diamond.
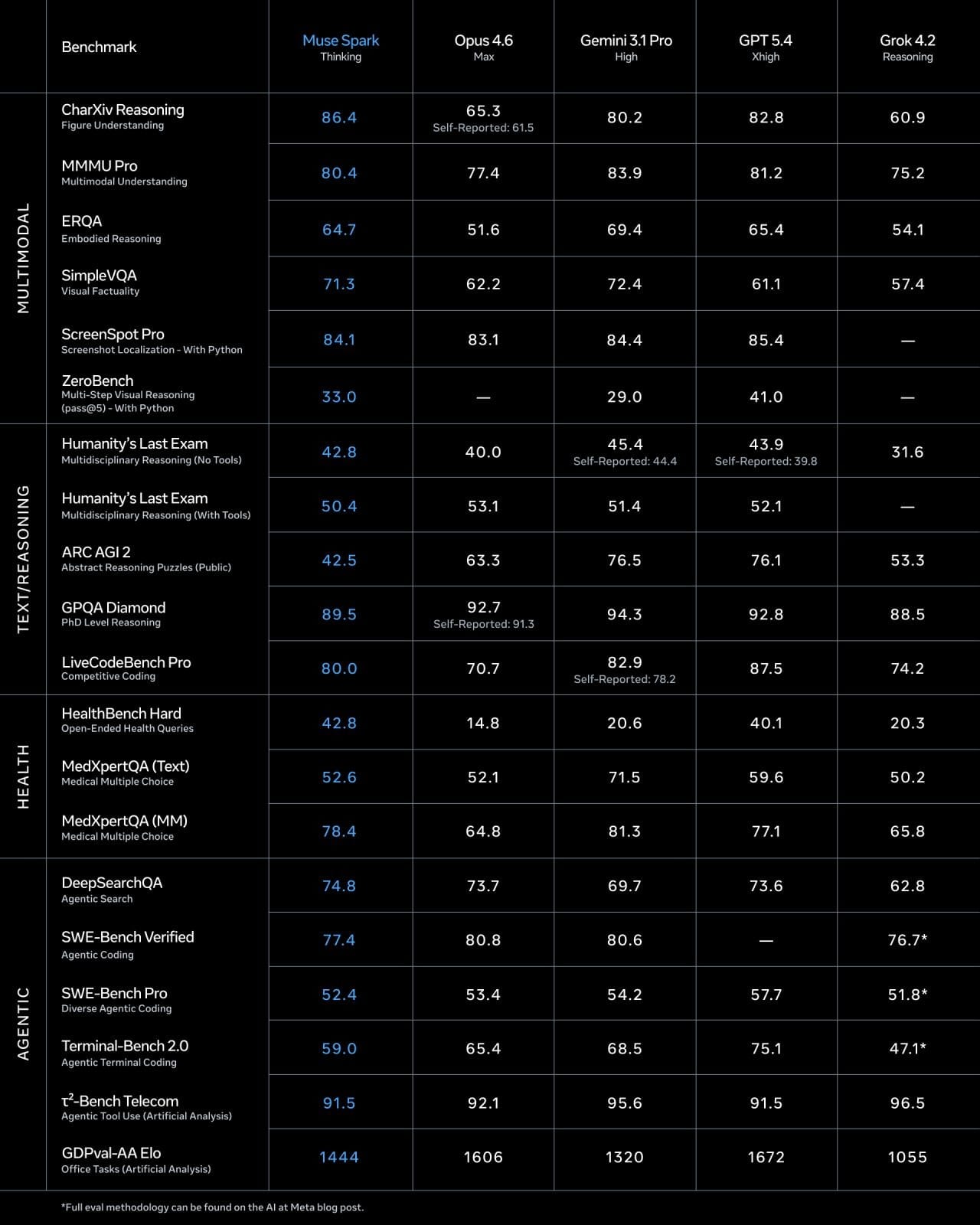
Eleven months ago, Meta said almost identical things about Llama 4, before people actually used it and the numbers collapsed.
So what are these benchmarks? How do the scores get calculated? And why does a model that tops every leaderboard sometimes feel mediocre the moment you use it?
This guide explains what the biggest AI benchmarks actually measure, including MMLU, GPQA Diamond, HumanEval, SWE-bench, HealthBench, Humanity’s Last Exam, and Chatbot Arena. It also explains how benchmark scores are calculated, why some tests matter more than others, and how AI labs can inflate benchmark results without improving real-world performance.
What Is an AI Benchmark?
A benchmark is just a standardized test. A fixed set of questions or tasks, given to every AI model in the same way, scored the same way. The idea is that if everyone takes the same test, you can compare the results fairly. But there's a practice the AI community has started calling benchmaxxxing: squeezing every possible point out of a benchmark through evaluation choices, cherrypicked settings, and training strategies that improve the score without necessarily improving the model.
We'll get into the specifics of how this works as we go through each benchmark.
MMLU and MMLU-Pro: The Knowledge Test
What it is: Over 15,000 multiple-choice questions across 57 subjects. Law, medicine, chemistry, history, economics, computer science. Four answer choices per question.
What an actual question looks like:
A 60-year-old man presents with progressive weakness, hyporeflexia, and fasciculations in both legs. MRI shows anterior horn cell degeneration. Which of the following is the most likely diagnosis? (A) Multiple sclerosis (B) Amyotrophic lateral sclerosis (C) Guillain-Barré syndrome (D) Myasthenia gravis
The model outputs a letter. The test runner checks if it matches the answer key.
How the score is calculated: Before each question, the model is shown 5 example questions with correct answers, this is called 5-shot prompting. Then comes the real question. Score = correct answers ÷ total questions, expressed as a percentage.
Why it's nearly useless in 2026: Top models now score above 88% on MMLU. GPT-5.4, Claude Opus 4.6, and Gemini 3.1 Pro are all bunched together above 87%. The test can no longer separate them, it's like using a bathroom scale to measure the weight difference between two people of similar build. Technically possible, practically meaningless.
Researchers responded by building MMLU-Pro: same subjects, harder questions, ten answer choices instead of four, with options designed to look plausible even to knowledgeable humans. On MMLU-Pro, the gaps between models start showing up again.
→ When you see MMLU in a press release in 2026, it's mostly padding. It's also the benchmark most likely to be inflated by training data contamination: models have had three years of internet data that overlaps heavily with MMLU-style questions.
Build your own no-code agent for free
Try here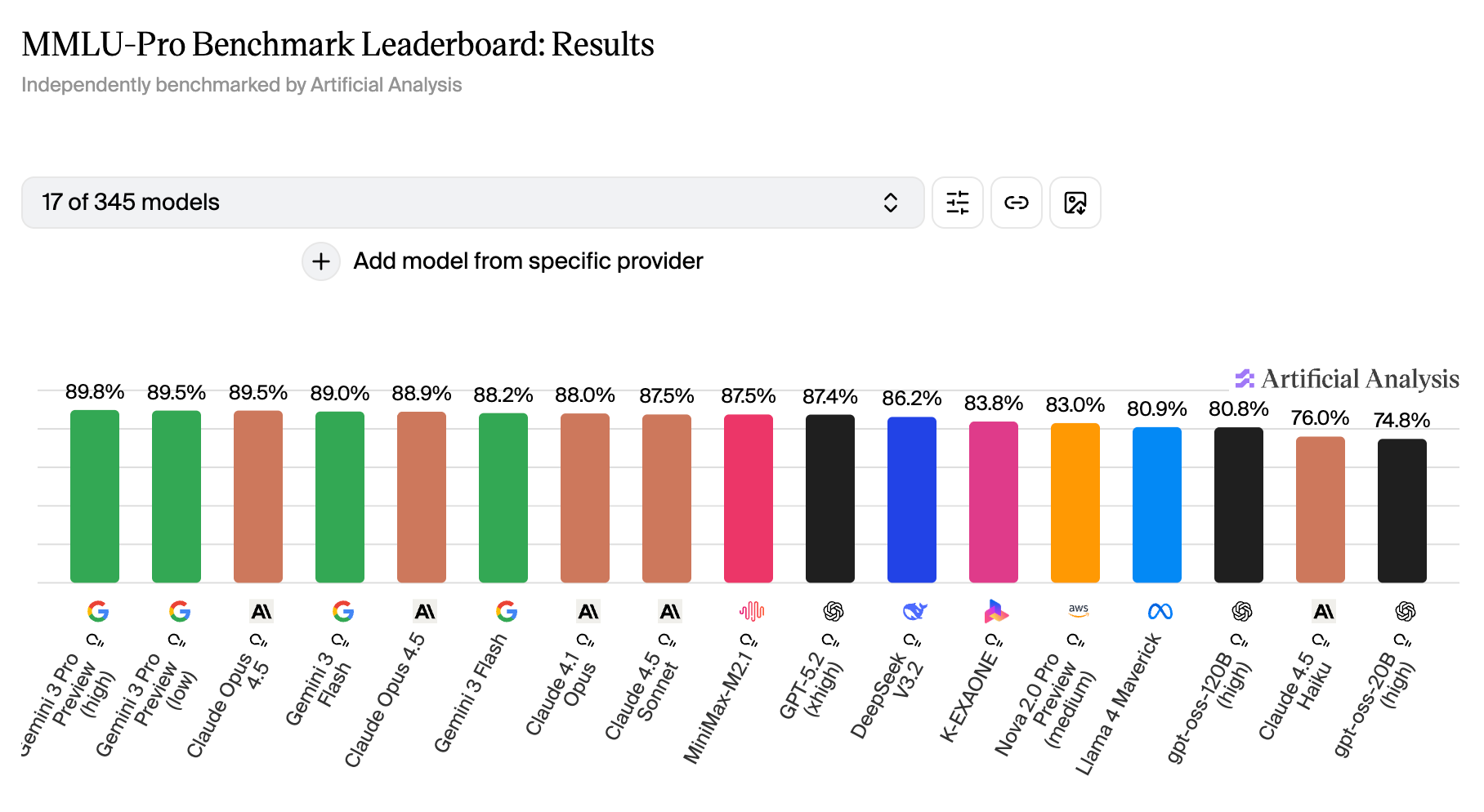
GPQA Diamond: The Scientific Reasoning Test
This is the most credible academic benchmark in use today. The way it was built is what makes it trustworthy.
How the questions were made: Researchers hired PhD scientists in biology, physics, and chemistry. Each scientist wrote a question in their own field. Then a second PhD scientist in the same field attempted to answer it. If that second expert got it wrong, the question passed the filter. Then three more people, smart non-domain experts given unlimited internet access and 30 minutes, tried to answer it. If they also failed, the question made it into the Diamond subset.
The result: 198 questions that require you to actually reason through hard science. You cannot Google them. The answers aren't in Wikipedia.
What an actual question looks like:
Two quantum states with energies E1 and E2 have a lifetime of 10⁻⁹ sec and 10⁻⁸ sec, respectively. We want to clearly distinguish these two energy levels. Which of the following could be their energy difference so they can be clearly resolved? (A) 10⁻⁸ eV (B) 10⁻⁹ eV (C) 10⁻⁴ eV (D) 10⁻¹¹ eV
To answer this, you need to know the energy-time uncertainty principle from quantum mechanics, calculate the natural linewidths of the energy levels, and check which energy difference is large enough to resolve them. The answer is (A), but you can't find that by searching. You have to derive it.
How the score is calculated: Same letter-pick system as MMLU. The model is told to reason step by step and must end its response with "ANSWER: LETTER" - capital letters only. If the model doesn't follow that exact format, it gets zero for that question regardless of whether the reasoning was correct. This strict formatting rule is intentional: it forces models to commit to a specific answer rather than hedging.
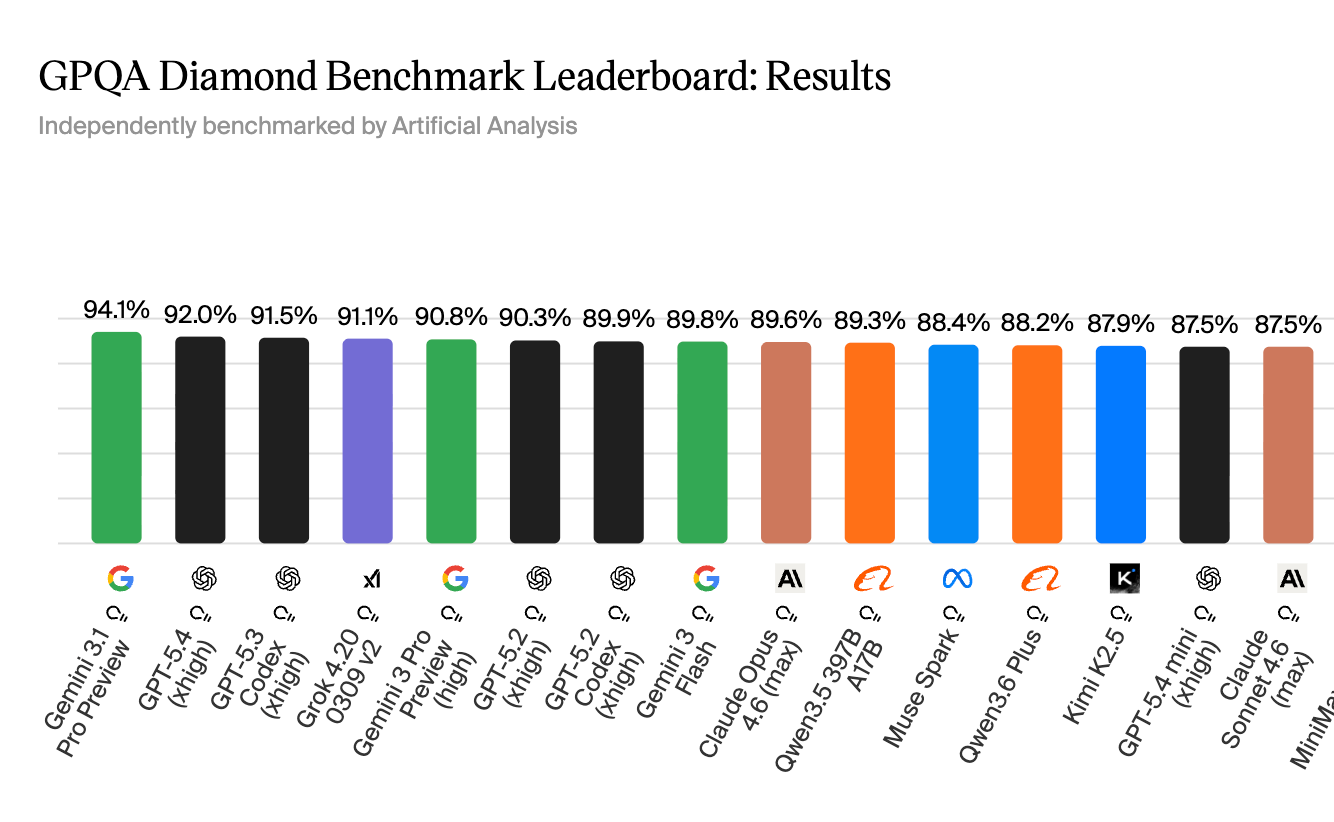
The benchmark in numbers:
- Random guessing: 25% (four choices)
- Smart non-experts with internet access: 34%
- PhD-level domain experts: 65%
- GPT-4 when it launched (2023): 39%
- Muse Spark today: 89.5%
- Gemini 3.1 Pro: 94.3%
- Claude Opus 4.6: 92.8%
That jump from 39% to 89% in three years is real. These models have genuinely gotten better at scientific reasoning. But Muse Spark is still about 5 points behind Gemini on this test, across 198 questions. That's roughly 10 questions. Meta calls this "competitive" which is technically accurate.
HumanEval: The Basic Coding Test
What it is: 164 Python programming problems. Each problem is a function signature with a docstring explaining what the function should do.
What an actual question looks like:

The model writes the function body. An automated test runner then executes the code against 10-15 hidden test cases, inputs with known correct outputs. Either every test case passes, or the problem fails.
How the score is calculated: The main metric is pass@1: did the model's first attempt pass all the hidden tests? Score = number of problems where the code worked ÷ 164 total problems.
Example of pass vs. fail:
A correct solution for the above returns "fl" for ["flower","flow","flight"] and "" for ["dog","racecar","car"] and handles edge cases like an empty list. A model that hardcodes the visible examples but fails on an edge case like a single-element list gets zero for that problem.
Why it's outdated: Top models now solve 90%+ of these 164 problems. They've had years to train on HumanEval-style tasks. Researchers openly question how many models may have seen these exact problems in training. Leading with HumanEval in 2026 is like a car company leading their safety pitch with a test from 2015.
Build your own no-code agent for free
Try hereSWE-bench: The Real Software Engineering Test
What it is: Real GitHub issues from real open-source repositories. The model is given the issue description and the full codebase and must produce a code patch (a diff) that fixes the bug.
What an actual task looks like:
A developer files a GitHub issue in the sympy math library: "The simplify() function returns the wrong result when called on expressions containing nested Piecewise objects under certain conditions."
The model gets the issue text, navigates a codebase with thousands of files, identifies the source of the bug, and writes a patch. That patch is automatically applied to the codebase, and the existing test suite runs to check that the fix works and didn't break anything else.
How the score is calculated: Pass/fail at the issue level. Score = percentage of issues where the model's patch passed all tests.
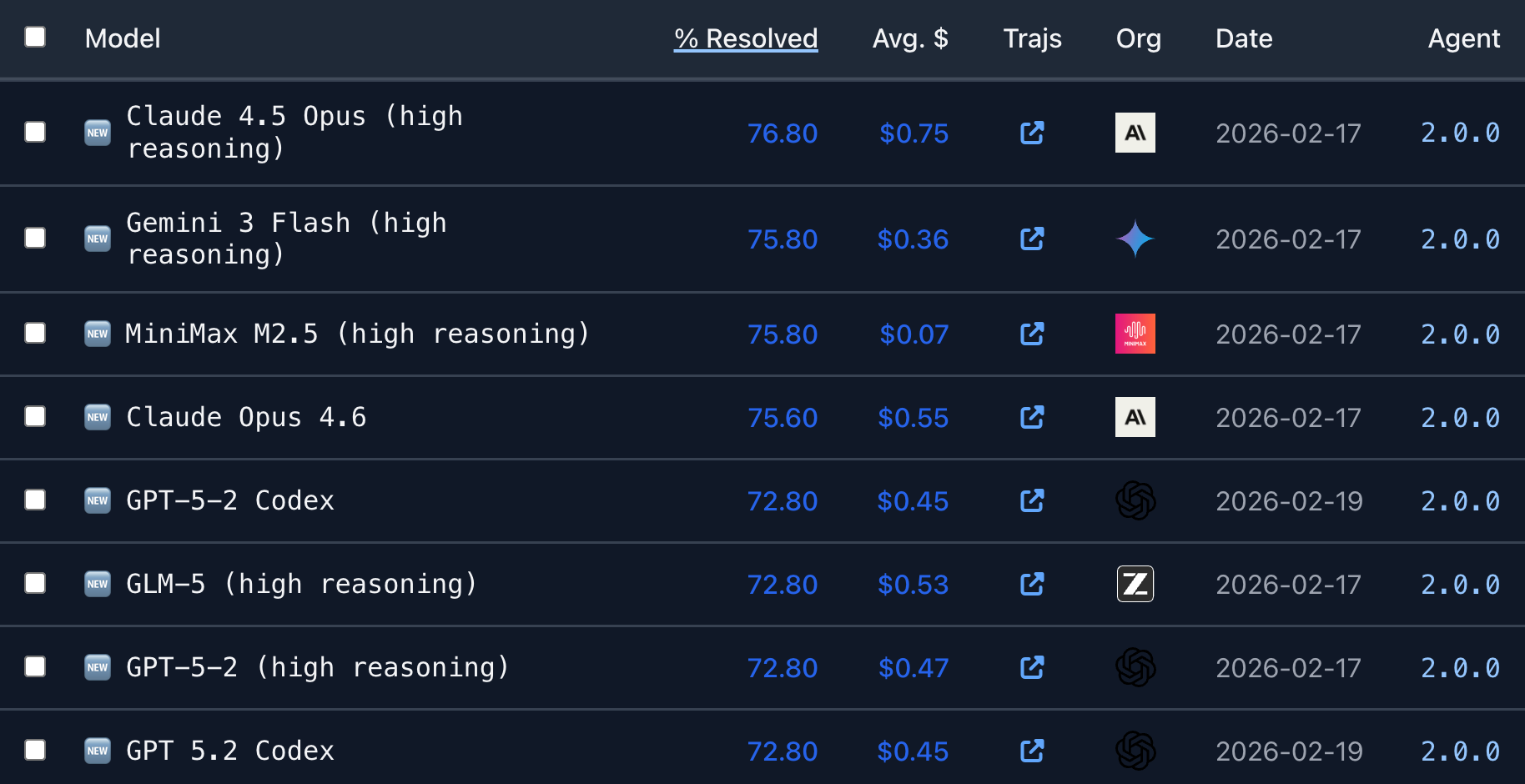
Why this benchmark matters more than HumanEval: Because there's no memorization shortcut. The repositories are real, the bugs are real, and the evaluation environment is strictly controlled. You either fixed the bug or you didn't.
Where Muse Spark stands here: Meta's own blog post acknowledges "current performance gaps, specifically in coding workflows." SWE-bench is almost certainly where that shows up. Claude Opus 4.6 currently leads most coding evaluations.
Humanity’s Last Exam: The Frontier Reasoning Test
What it is: Around 2,500 questions written by researchers specifically designed to exceed what current AI can answer: PhD-level and beyond, across math, science, history, and law.
Why Muse Spark highlights it: In its "Contemplating" mode, which launches multiple sub-agents working in parallel on different parts of a problem, Muse Spark scored 50.2%. GPT-5.4 in its highest-effort mode scored 43.9%. Gemini's Deep Think mode scored 48.4%.
This is Muse Spark's most legitimate lead across any benchmark. The gap is real (6+ points over GPT-5.4) and the benchmark is genuinely hard. One caveat: Contemplating mode uses significantly more compute than a standard response. You're paying, in time and in API cost for that performance.
HealthBench: The Clinical Reasoning Test
What it is: Clinical and medical reasoning tasks evaluated by physicians. Questions cover patient symptom interpretation, drug interactions, treatment decisions, and health information accuracy.
How the score is calculated: Unlike automated benchmarks, HealthBench answers are graded against physician-defined standards. The score represents the percentage of answers that met clinical accuracy requirements.
The numbers: Muse Spark 42.8%. GPT-5.4 40.1%. Gemini 3.1 Pro 20.6%.
42.8%. GPT-5.4 scored 40.1%. Gemini 3.1 Pro scored 20.6%. This is Muse Spark's most defensible lead in any benchmark. A 22-point gap over Gemini on a physician-graded test is significant.
Build your own no-code agent for free
Try here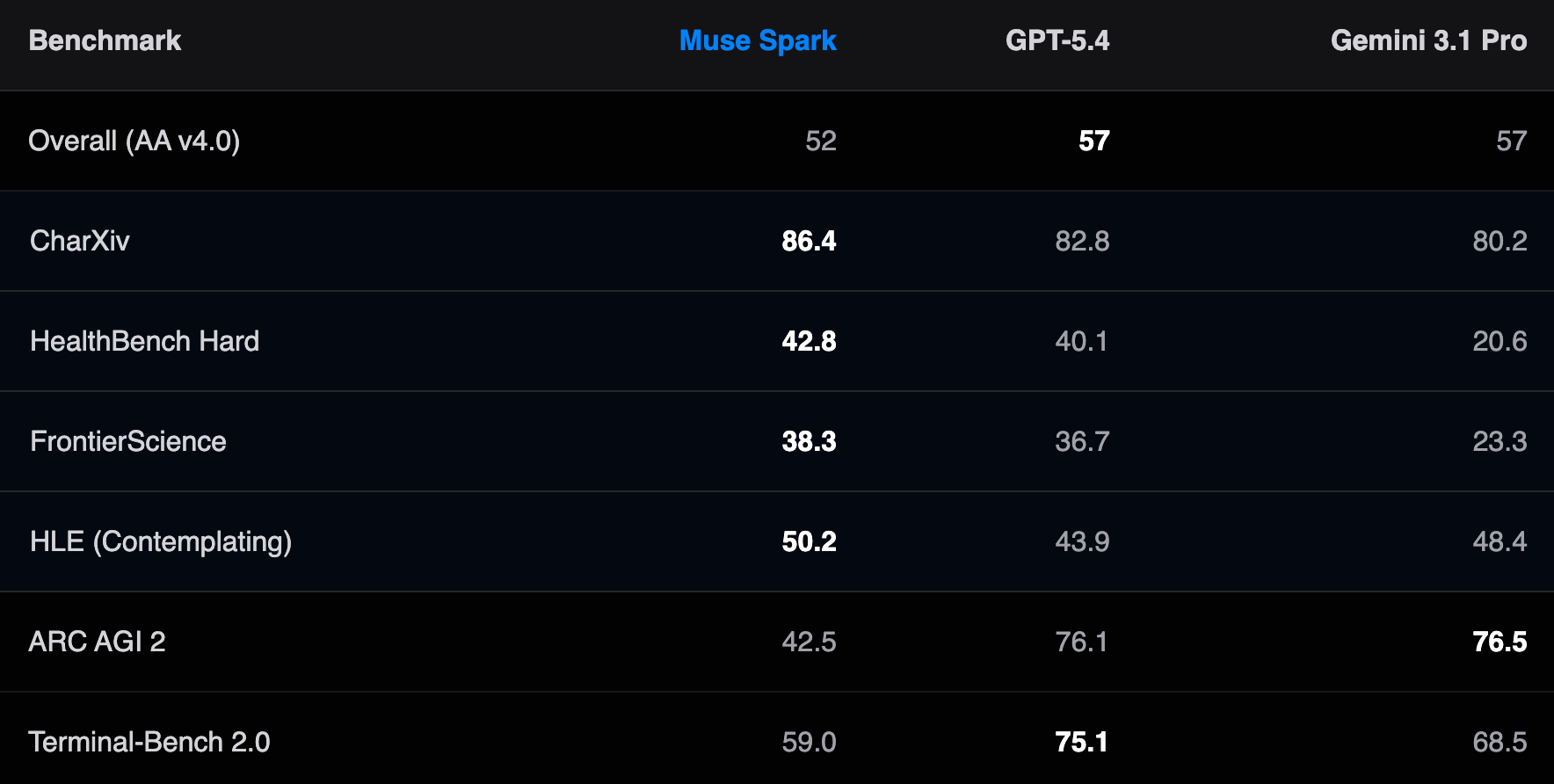
Chatbot Arena: The Human Preference Test
This one is different from every other benchmark, and understanding how it works explains the Llama 4 scandal.
What it tests: Whether a human user prefers one model's response over another.
How it works: Two anonymous models are shown the same prompt. A real user reads both responses and picks which one they prefer. Millions of these pairwise comparisons are run. The results feed into a statistical model called Bradley-Terry, which converts win/loss records into ELO scores: the same system used to rank chess players.
If Model A beats Model B in 60% of comparisons, Model A gets more points. Over time, after enough comparisons, the rankings stabilize into a leaderboard.
Why this benchmark is gameable: Human users tend to prefer responses that are long, confident-sounding, and well-formatted, even when a shorter, more accurate answer would serve them better. A model that adds enthusiasm, uses bold text, and gives elaborately structured responses will score better on LMArena than a model that gives a direct, correct answer in two sentences.
And this is what happened with Llama 4.
The Llama 4 Incident
When Meta released Llama 4 in April 2025, its announcement said the model ranked #2 on LMArena, just behind Gemini 2.5 Pro, with an ELO score of 1417. That number was technically accurate, but the model that earned that score was not the one being released to the public.
The model Meta submitted to LMArena was called "Llama-4-Maverick-03-26-Experimental." Researchers who later compared it against the publicly downloadable version found consistent behavioral differences:
The experimental version (LMArena): verbose responses, heavy use of emojis, elaborate formatting, dramatic structure, long elaborations even for simple questions.
The public version (what you'd actually use): concise, plain, direct, no emojis.
LMArena's voting system reliably preferred the first style. Real users in real use cases preferred the second. When the actual public model was separately added to the leaderboard, it ranked 32nd.
There's another number worth knowing: when LMArena turned on Style Control, removing the formatting and length advantage, Llama 4 Maverick dropped from 2nd place to 5th. The model's content quality, stripped of its presentational packaging, was much less impressive.
LMArena stated publicly: "Meta's interpretation of our policy did not match what we expect from model providers. Meta should have made it clearer that 'Llama-4-Maverick-03-26-Experimental' was a customized model to optimize for human preference." They updated their submission rules after.
And on ARC-AGI: a benchmark designed to test genuine novel reasoning, not pattern matching, Llama 4 Maverick scored 4.38% on ARC-AGI-1, and 0.00% on ARC-AGI-2. This was never in the press release.
Build your own no-code agent for free
Try hereHow AI Labs Game Benchmark Scores: Goodhart's Law and Benchmaxxxing

There's a principle from economics called Goodhart's Law: when a measure becomes a target, it stops being a good measure.
In plain English: the moment everyone agrees that GPQA Diamond is the number that matters, labs start optimizing specifically for GPQA Diamond. Scores go up but the real-world capability may not move at all.
This has a name in the AI community now: benchmaxxxing. It's the practice of squeezing every possible point out of a benchmark through techniques that improve the score without necessarily improving the model. Some of these techniques are legitimate engineering and some are closer to the gaming Meta did with LMArena. The line is genuinely blurry, which is part of what makes this hard to call out.
That’s how benchmaxxxing actually looks like in practice:
Cherry-picking which benchmarks to publish. Every model gets evaluated on dozens of benchmarks internally. The ones that appear in the press release are the ones the model did well on. The rest disappear. This is universal, every lab does it. Llama 4's ARC-AGI score of 0.00% was not in the announcement.
Choosing favorable evaluation settings. Many benchmarks can be run in different ways: different prompting styles, different numbers of example questions shown beforehand, different temperatures. Labs run all the variants internally and publish the best result. This is technically allowed but rarely disclosed.
Training on benchmark-adjacent data. If you know a benchmark tests quantum mechanics reasoning, you can make sure your training set is heavy on quantum mechanics. The questions themselves aren't in the training data, but the knowledge required to answer them is saturated. This is nearly impossible to distinguish from genuine capability improvement from the outside.
Benchmark contamination, the serious version. Sometimes actual benchmark questions, or near-identical variants, end up in training data. This can happen accidentally when training on internet scrapes. It can also happen less accidentally. Susan Zhang, a former Meta AI researcher who later moved to Google DeepMind, shared research earlier in 2025 documenting how benchmark datasets can be contaminated through training corpus overlap. When a model sees the question and answer during training, it's essentially memorized the test. And the score reflects memory, not reasoning.
Majority voting and repeated sampling. Some labs run each benchmark question multiple times and take the most common answer. A model that scores 80% on one attempt might score 88% across 32 attempts. Meta specifically disclosed they don't do this for Muse Spark's reported numbers, they use zero temperature, single attempts.
The deepest problem with Goodhart's Law in AI is that it creates a ratchet effect. Each new model needs to beat the previous one's benchmark scores, or it's declared a failure. So every release gets more optimized for the benchmarks that exist, which makes those benchmarks less informative over time, which drives the creation of harder benchmarks, which then also get optimized for. MMLU was the gold standard in 2022 but it's saturated now. GPQA Diamond replaced it.
What Benchmarks Still Can’t Tell You
Speed. GPQA Diamond says nothing about whether the model responds in 1 second or 10.
Cost. A model scoring 92% at $15 per million tokens versus one scoring 89% at $1 per million tokens are different choices depending on how much volume you're running.
Consistency. A model averaging 90% on a benchmark but producing catastrophically wrong answers 2% of the time is a different risk profile from one that scores 85% uniformly. Benchmarks report averages. Averages hide tails.
Your specific task. None of these benchmarks were designed for your documents, your prompts, or your users. A model that dominates GPQA Diamond might handle an insurance form extraction task worse than a smaller, cheaper model trained on domain-specific data.
Evaluate AI Models for Your Own Use Case
You can actually evaluate the best model for you, yourself.
Take your ten or twenty most representative tasks: the actual prompts, documents, or questions you'd send to the model in practice. Run every model you're considering on those exact inputs. Score the outputs yourself (or have someone with domain expertise do it.)
That single custom test will tell you more than any benchmark table in a press release. Because benchmarks tell you where a model claims to stand. Your test set tells you where it actually has to show up.