
PDFs are everywhere. They’re the go-to format for sharing and storing documents, but trying to extract usable data from them? That’s a whole different story.
For the longest time, many of us relied on copy pasting to pull information from PDFs. While this would still be easily doable for, say, 1-2 short PDFs, as the amount of data grows, this old-school approach doesn't work. Whether it’s tables, forms, or unstructured text, getting the data you need from a PDF can be a frustrating, time-consuming task.
Hence the need for AI. With the right tools, AI makes PDF data extraction faster, more accurate, and a whole lot easier to scale. In this article, we’ll explore three AI-powered methods for extracting data from PDFs.
- Online tools for quick and easy tasks
- Large Language Models (LLMs) like ChatGPT and Claude for interactive data extraction
- AI-powered platforms like Nanonets that automate the whole process
We’ll walk you through when to use each method, what works best for different document types, and why Nanonets stands out from the crowd. By the end, you’ll know exactly which solution fits your needs. Ready to make PDF data extraction painless? Let’s get started!
How to extract data from PDFs using AI?
With the onset of AI, there are multiple solutions to extract meaningful data from PDFs. These can be game changing, saving hours of manual effort without compromising on the accuracy.
Method 1: Using online tools
One of the simplest ways to extract data from PDFs using AI is through online tools. There are various tools in the market today, such as, SmallPDF or Ask your PDF. These platforms offer user-friendly interfaces that allow users to upload PDF documents and ask questions about their content.
We tried out askyourpdf.com with a handwritten legal document. It contained details about a juror, both personal and professional in nature. You can take a look at the results below but before that, here is a stepwise process you can follow to try this tool out for yourself:
Step 1: Visit askyourpdf.com and click on Get Started for Free.
Step 2: You will be led to a login screen with SSO options. You can choose the option best suited for you.

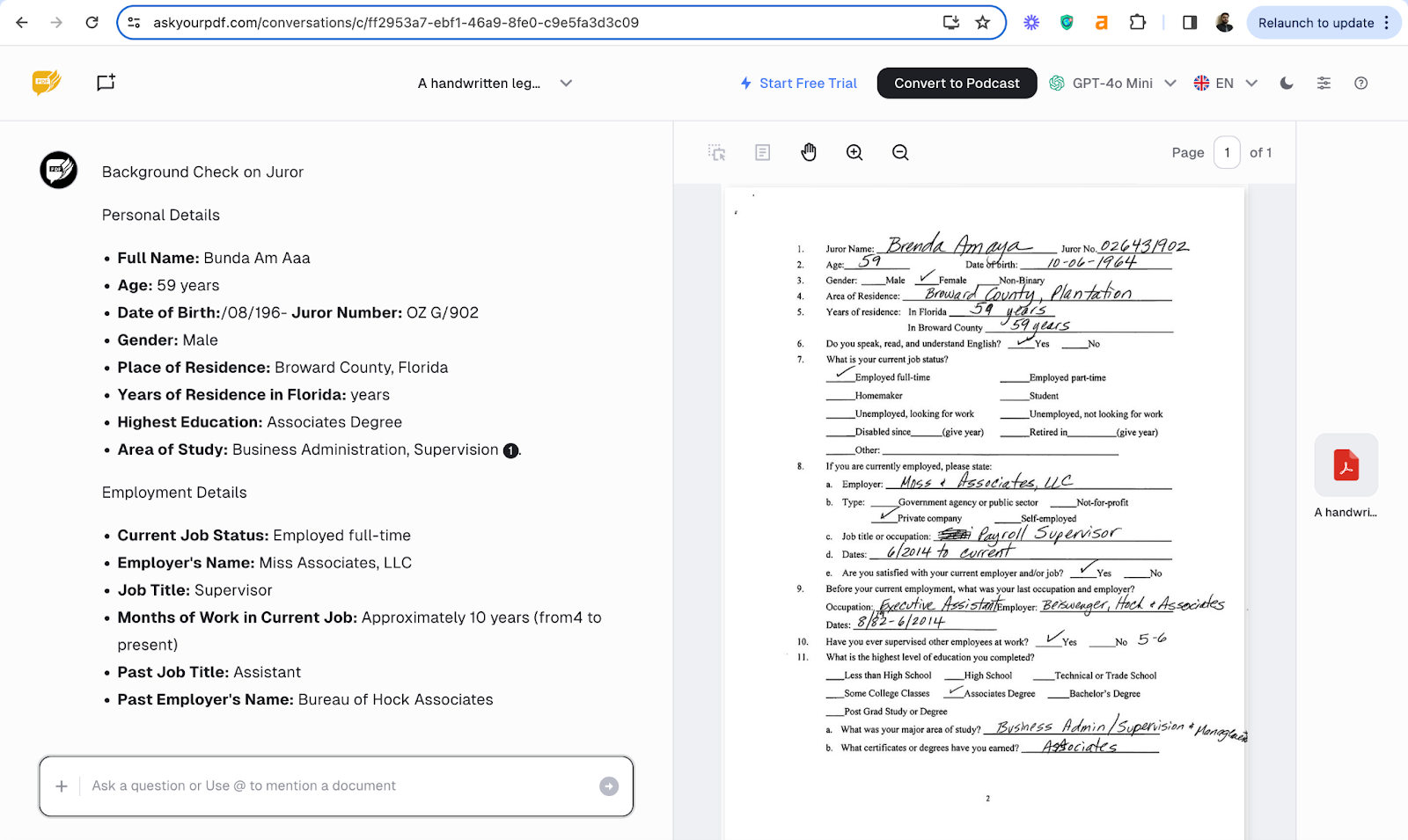
Step 3: Once signed in, you will be asked to upload a PDF document. We uploaded a juror form (handwritten) and tried out a few prompts.
“I need to do a background check on the Juror. I need help finding the following data points from the uploaded document:
1. Personal details like, full name, age, DOB, juror no., gender, place of residence, highest education, area of study
2. Employment details like, current job status, employer's name, job title and months of work in current job, past job title, past employer's name, duration in the past job.
Can you arrange this in an excel sheet?”
Result:
The extracted data was not accurate. The tool did not support direct extraction of data to an editable format, like an Excel spreadsheet.
This method is ideal for:
- Simple text-based PDFs
- Short documents with straightforward content
- PDFs with easily identifiable information
1. Ease of use: These tools typically have intuitive interfaces, requiring minimal technical expertise.
2. Quick results: For simple queries, users can get instant answers without complex setup.
3. Easy access: Being web-based, these tools can be accessed from any device with an internet connection.
4. Cost-effective for occasional use: Many offer free tiers or pay-per-use models, suitable for infrequent extraction needs.
1. Limited accuracy: The AI models behind these tools may not always provide precise or contextually relevant answers. They are prone to hallucination and struggle with complex layouts (multiple pages, tables, etc.) and document types, such as handwritten forms.
2. Lack of customisation: Users have little control over the extraction process or the ability to train the model on specific document types.
3. Security: Uploading sensitive documents to third-party websites may pose security risks.
4. No batch processing: They are typically designed for one-off queries rather than processing large volumes of documents.
5. No export options: There are no in-built options for export or integration with other software.
Final verdict: This method is suitable for one-off quick references to documents but will not support automation of manual processes in organisations.
Method 2: Use Large Language Models (LLMs) like ChatGPT
Large Language Models such as ChatGPT by OpenAI or Claude by Anthropic have gained significant attention for their ability to understand context and generate human-like text. These models can be leveraged for PDF data extraction by feeding them the content of PDF documents and asking specific questions.
Needless to say, they can be trained to extract specific text from document types and create a structured and automated process for PDF data extraction. We tried the same legal document (handwritten from) out on Claude. Take a look below.
Step 1: Visit claude.ai and log in using SSO or whichever option is convenient for you.

Step 2: Upload the image of the document you want to extract text from and enter the prompt. We tried it using the legal document (handwritten juror form) from the previous method.
“I need to do a background check on the Juror. I need help finding the following data points from the uploaded document:
1. Personal details like, full name, age, DOB, juror no., gender, place of residence, highest education, area of study
2. Employment details like, current job status, employer's name, job title and months of work in current job, past job title, past employer's name, duration in the past job.
Can you arrange this in an excel sheet?”
Result:
While the result was satisfactory in terms of accuracy (given that it was a handwritten legal form), it didn’t support direct extraction of data into an Excel sheet. This would have to be set up using API endpoints which might require coding proficiency.

This method is ideal for:
- Text-heavy PDFs with narrative content
- Reports, articles, and research papers
- Documents requiring natural language understanding
1. Natural language processing: LLMs excel at understanding context and can extract information from complex textual content.
2. Flexibility: LLMs can answer a wide range of questions about the document's content, including simple mathematical questions, like, “How long has the juror served under their current employer?”
3. Multilingual support: LLMs can work with documents in various languages, depending on the LLM.
1. Lack of structure preservation: LLMs may struggle with maintaining the original document's structure, especially for forms and tables.
2. Inconsistent outputs: Responses can vary between queries, leading to potential inconsistencies in extracted data.
3. Potential for LLM hallucinations: LLMs might generate believable but factually incorrect information when uncertain.
4. Data privacy concerns: Sending sensitive document content to external LLM services raises security issues.
5. Coding Proficiency: To set up an automated process, one might have to set up parsing of extracted data to the destination software using APi endpoints as direct integration isn't supported.
Read About: Extract text from PDF using ChatGPT
Method 3: Use AI-powered Intelligent Document Processing (IDP) Platforms like Nanonets
AI-powered IDP platforms represent the most advanced and comprehensive solution for AI-based PDF data extraction. These systems combine multiple AI technologies, including computer vision, natural language processing, and machine learning, to provide highly accurate and versatile extraction capabilities.
Let us show you how Nanonets can process the same legal document (handwritten juror form) using the zero-training extractor and also set up end-to-end workflow automation for the same.
Step 1: Visit app.nanonets.com and sign in using your preferred option.
Once signed in, click on New workflow on the left panel > Zero-training extractor and enter the fields you want to extract from your document type. Click Continue.

Step 2: Upload your file and allow a few seconds for processing.

This method is ideal for:
- Complex, multi-page documents, such as invoices, leases, receipts, bank statements, tax forms, etc.
- Single page documents like, passports, driver’s licenses, etc.
- Documents with complex layouts including tables.
- Handwritten documents
1. High accuracy and consistency: Advanced AI models that do require minimal to no training and can be set up in seconds.
2. Versatility: Can handle all document types and layouts, including nested tables, multiple line items, etc.
3. Customisation: Allows for training on specific document types and extraction of custom fields.
4. Scalability and Security: Capable of processing large volumes of documents efficiently in a secure way.
5. Integration capabilities: One-click integrations into popular third-party software. Option for APIs and connectors for seamless integration with existing systems.
Benefits of using AI-based IDPs to extract data from PDFs
The adoption of AI-powered solutions for PDF data extraction brings a host of benefits to organisations across industries. We covered 3 ways one can leverage AI to extract data from a PDF, each with its own set of limitations. However, when it comes to automating processes involving PDF data extraction or even harnessing data for analysis, the choice couldn’t be clearer.
Let's explore the key advantages that make AI-powered IDPs have when it comes to data extraction from PDFs:
1. Increased efficiency and speed
AI-driven extraction dramatically reduces the time required to process PDF documents. What once took hours or days of manual work can now be accomplished in minutes or seconds. This increased speed allows organizations to process large volumes of documents quickly and allocate human resources to strategic tasks. It ultimately ends up accelerating decision-making processes based on extracted data.
2. Improved accuracy and consistency
Human error is a significant concern in manual data extraction. AI-powered IDPs minimise these errors, ensuring a consistent output with standardised formats that ultimately ends up improving the quality of extracted data.
3. Cost reduction
While there may be initial investment costs, AI-powered data extraction from PDFs leads to significant long-term savings. As a business scales, the number of documents involved also increases. This could lead to significant labor costs. Relying on manual workforce can also lead to error costs especially when it comes to core financial processes, such as invoice processing. AI-powered IDPs reduce such costs dramatically. Additionally, they can quickly adapt to new document types, handle multiple languages, and process thousands of documents in minutes.
4. Enhanced data accessibility and utilisation
AI extraction transforms unstructured PDF data into structured, searchable information, enabling easy one-click integrations with databases and analytics tools. This leads to enhanced ability to derive insights from this data. It also empowers compliance by creating a central repository of information.
Conclusion
PDF data extraction will never be the same again. AI has revolutionised it fundamentally. As we've explored in this article, the challenges of manual data extraction – time-consuming processes, error-prone results, and limited scalability – are being overcome through innovative AI technologies.
We've examined three distinct methods for leveraging AI in PDF data extraction:
1. Online tools like askyourpdf.com, which offer simplicity and accessibility for basic extraction needs.
2. Large Language Models such as ChatGPT, which excel at understanding and interpreting complex textual content.
3. AI-powered Intelligent Document Processing (IDP) platforms like Nanonets, which provide comprehensive, accurate, and scalable solutions for a wide range of document types and extraction needs.
By embracing AI-powered IDPs, organisations can transform their document processing workflows, unleash the power of their data, and position themselves for success in an increasingly data-driven world.
Whether you're dealing with invoices, forms, contracts, or any other type of PDF document, the time to explore AI-powered extraction solutions is now. With platforms like Nanonets leading the way, the possibilities for efficient, accurate, and insightful data extraction are limitless. Take the first step towards revolutionising your document processing today, and unlock the true potential of your organisation's data.