
Building on its simplicity, Excel table has been the most predominant way of storing any structured data digitally. The seemingly simple spreadsheets are actually tightly linked to the daily data processing by large corporations and organizations. In a few clicks, companies can now distribute tasks to different workers, keep track of budgets from multiple cash flows, and even make accurate predictions from past data.
However, while we can achieve many tasks with ease when all the data is correctly imported into Excel, the process of extracting data from pre-existing tables, scans, or even images in the first place isn’t easy. Since the common spreadsheet representation now brings many benefits to data processing and visualization, the task of extracting data through computer vision, image processing, and deep learning approaches has emerged to be one of the hot topics in today’s research community – Delivering error-free tabular data extraction seems to be something so close yet so difficult to achieve.
This article introduces the high level steps of tackling this task, followed by the latest advances on data extraction approaches and tutorials to manually and automatically achieve such tasks, and finally accompanied by a brief highlight on the current solutions in the market to accomplish these tasks.

Convert PDFs to Excel spreadsheets in seconds with AI!
▼
Convert PDFs to Excel spreadsheets in seconds with AI!
Decomposition of the problem
The task of extracting tabular data can be divided into two sub-problems: 1) extracting tables from scans/images/PDF documents where the format is not recognizable by machines and 2) understanding/interpreting the words inside table cells so that it could be properly imported into CSV files for spreadsheets.
Use Cases of Tabular Data Extraction

Business Cash Flow Tracking
If your company's buying and selling sources are from the same source, you can quickly compare receipts manually for easy tracking. However, that is often not the case especially for large corporations. Funds can come in and move out of the company from a variety of sources and often have different receipt and invoice formats. Investors, buyers, and sellers could all be distinct and could come from different locations or even countries. The problem exacerbates when payments are made in other languages.
Year after year, vast amounts of resources are needed to hire employees to complete these seemingly simple but error-prone tasks. An automated method of scanning and extracting tabular data will dramatically help these companies save money, time and resources.Furthermore, a well-documented spreadsheet could also make the post processing for data analyses much simpler. Companies could easily make budget and financial projections through machine learning algorithms simply by extracting the data from multiple organized excel sheets.
Cross-Business Record Transfer

When relocating to new locations, nations, or opting for different services, customers have to transfer identical data from prior systems to the new service provider. Such data could include but is not limited to medical data, bank statements, etc.
By incorporating systems to understand and translate the data from one service to another, companies can greatly benefit with the reduction of costs.
Accounting Firms
Accounting firms have a twin problem: difficult cash flow reconciliation for each of its customer companies and the different tabular and data storage formats across firms from multiple countries. During busy tax reporting seasons when time matters the most, an automated data extraction solution with minimal error rate will therefore be helpful in alleviating the heavy manual labour.
How does it work?

While almost everyone knows that machine learning can help in facilitating this automation, few actually know the concepts behind it.
In fact, what we use in this case is a concept called deep learning, which is a sub-branch of machine learning: a general branch of understanding/learning the intermediate system/function between a set of inputs and outputs, such that we can utilize the function to make future predictions. In short, deep learning simulates the function via a powerful tool named neural networks, which is a mimic of biological neural networks. We learn the proper weights and neurons through a minimization of the difference between our prediction and the actual ground truth.
There are a lot of variations on how this network can be constructed. Below we describe the necessary variants required for tabular data to be extracted
CNN
Convolutional Neural Networks (CNNs) are made up of neurons with learnable weights and biases, much similar to Neural Networks. The main difference is that we assume the inputs are pictures for CNNs, allowing us to embed specific attributes into the architecture called Kernels, which is a sliding window that aggregates neighbouring features together as a weighted sum to feed into the next layer. As a result, the forward function is more efficient to implement and substantially improves. CNNs come in handy when we want to find certain objects inside an image, and in this case, a table.
RNN
Recurrent neural networks (RNNs), on the other hand, are a class of networks that allow previous outputs to be used as inputs for the next prediction. This is especially helpful when the prediction is dependent on results of previous time (e.g., In weather forecasting, the question of whether it would rain today is heavily dependent on whether it rained the day before). This type of architecture is helpful when trying to understand the meaning of a sentence where previous words may have an effect on what the current word could be/means.
Putting The Concepts Together
By training on the proper datasets, we can now extract tabular data via the following procedure:
- Using a CNN to classify the type of document is within one image. This allows us to be more specific when choosing different trained table detectors which could potentially work better in different scenarios (e.g., one for invoice and one for bank statements)
- Using a CNN to further detect the tables, rows, and columns.
- Combining CNNs and RNNs to perform optical character recognition, which allows us to understand what exactly is stored in each table, row, or column. Understanding the “language” can allow us to put our extracted data into designated formats (e.g., CSV or JSON) where we can further adopt for statistical analyses and cross-comparisons.
Want to extract tabular data from invoices, receipts or any other type of document? Check out Nanonets' AI-based OCR to extract tabular data.
Tutorial
Converting PDF to Images
Extracting tabular data using computer vision ultimately means that the data has to be preprocessed into image formats if it isn't already. The most common document type that needs to be converted is PDF, and thus our first step will be to convert pdf files into image files for further processing. To do so, we would require the pdf2image library which can be stored as the following.
pip install pdf2imageAfterwards, we can write the following to preprocess pdf files.
from pdf2image import convert_from_path, convert_from_bytes
from pdf2image.exceptions import (
PDFInfoNotInstalledError,
PDFPageCountError,
PDFSyntaxError
)
images = convert_from_path('example.pdf')
images = convert_from_bytes(open('example.pdf','rb').read())The presented code provides both from bytes and from path. Choose the one suited for your needs.
Finding Tables
To find tables within an image, an naive way will be to detect lines and boundaries that looks like a table. The simplest way will be to use traditional computer vision methods via OpenCV (a lot of tutorials can be found here on their official website). To use it simply install it with:
pip install opencv-pythonHowever, if your company has abundant data of what the typical tables in your database of files look like, you may also follow object detection methods to find tables. Some notable methods include Faster RCNN and YOLO. Note that by training your own model for this, however, you would require computational resources such as GPUs during the training, along with a substantial amount of data ranging from all kinds of scenarios which the image/scanned PDF is captured in.
Content Extraction via Google Vision API
Finally, with the bounding box of table cells estabilished, we can now move on to OCR, which Google Vision API for OCR retrieval seems to be one of the best options. Google vision API are trained base on the massive crowdsourcing owing to their vast customer base. Therefore, instead of training your personal OCR, using their services may have much higher accuracies.
The entire Google Vision API is easy to setup; one may refer to its official guide for the detailed setup procedure.
The following is the code for OCR Retrieval:
def detect_document(path):
"""Detects document features in an image."""
from google.cloud import vision
import io
client = vision.ImageAnnotatorClient()
with io.open(path, 'rb') as image_file:
content = image_file.read()
image = vision.Image(content=content)
response = client.document_text_detection(image=image)
for page in response.full_text_annotation.pages:
for block in page.blocks:
print('\nBlock confidence: {}\n'.format(block.confidence))
for paragraph in block.paragraphs:
print('Paragraph confidence: {}'.format(
paragraph.confidence))
for word in paragraph.words:
word_text = ''.join([
symbol.text for symbol in word.symbols
])
print('Word text: {} (confidence: {})'.format(
word_text, word.confidence))
for symbol in word.symbols:
print('\tSymbol: {} (confidence: {})'.format(
symbol.text, symbol.confidence))
if response.error.message:
raise Exception(
'{}\nFor more info on error messages, check: '
'https://cloud.google.com/apis/design/errors'.format(
response.error.message))If you are using remote images from Google clouds, you may use the following code instead:
def detect_text_uri(uri):
"""Detects text in the file located in Google Cloud Storage or on the Web.
""" from google.cloud import vision
client = vision.ImageAnnotatorClient()
image = vision.Image()
image.source.image_uri = uri
response = client.text_detection(image=image)
texts = response.text_annotations print('Texts:')
for text in texts:
print('\n"{}"'.format(text.description))
vertices = (['({},{})'.format(vertex.x, vertex.y) for vertex in text.bounding_poly.vertices]) print('bounds: {}'.format(','.join(vertices)))
if response.error.message:
raise Exception(
'{}\nFor more info on error messages, check: ' 'https://cloud.google.com/apis/design/errors'.format( response.error.message))Google's API is very flexible in the sense that their machine learning model is very strong and robust to a lot of challenging scenarios. Be aware that the function document_text_detection particularly trained and specialised in very condensed texts that appears mostly in PDFs. While this suits the need for many, if your PDF has words somewhat more scarce, it may be better to use their other text detection function which focuses more on in-the-wild images.
More codes regarding the usage of Google API can be retrieved here: https://cloud.google.com/vision; you may also refer to codes in other languages (e.g., Java or Go) if you are more familiar with them.
There are also other OCR services/APIs from Amazon and Microsoft, and you can always use the PyTesseract library to train on your model for specific purposes.
Want to extract tabular data from invoices, receipts or any other type of document? Check out Nanonets' AI-based OCR to extract tabular data.
Don’t know coding? Try Nanonets!
If you are a person without computer science background or your business needs such capability, Nanonets offers one of the best table extracting technologies that could perform well beyond one single data type. Here is a short tutorial of how to use it:
Step 1.
Go to nanonets.com and register/log in.
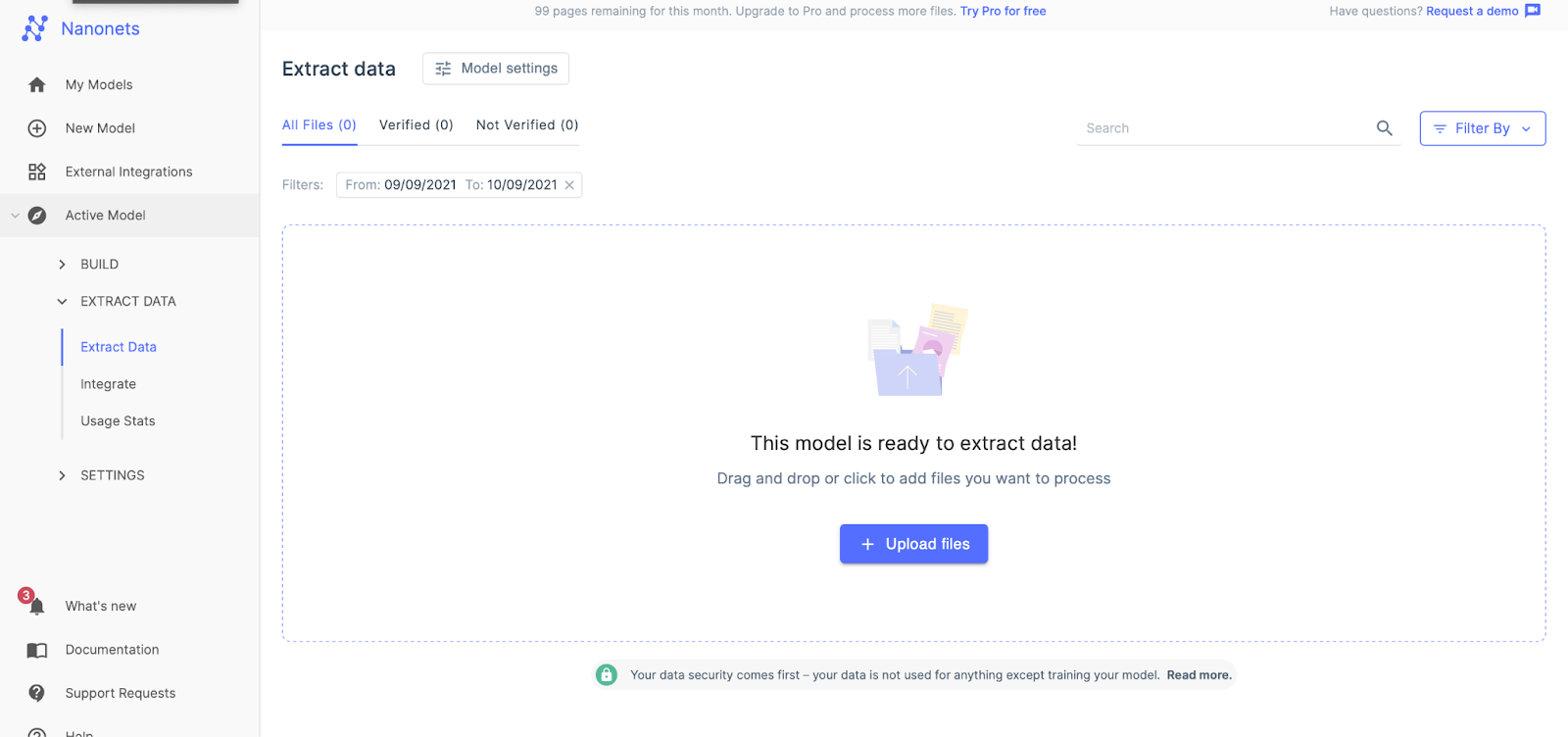
Step 2.
After registration, go to the “Choose to get started” area, where all the pre-built extractors are made and click on the “Tables” tab for the extractor designed for extracting tabular data.
Step 3.

After a few seconds, the extract data page will pop up saying it is ready. Upload the file for extraction.
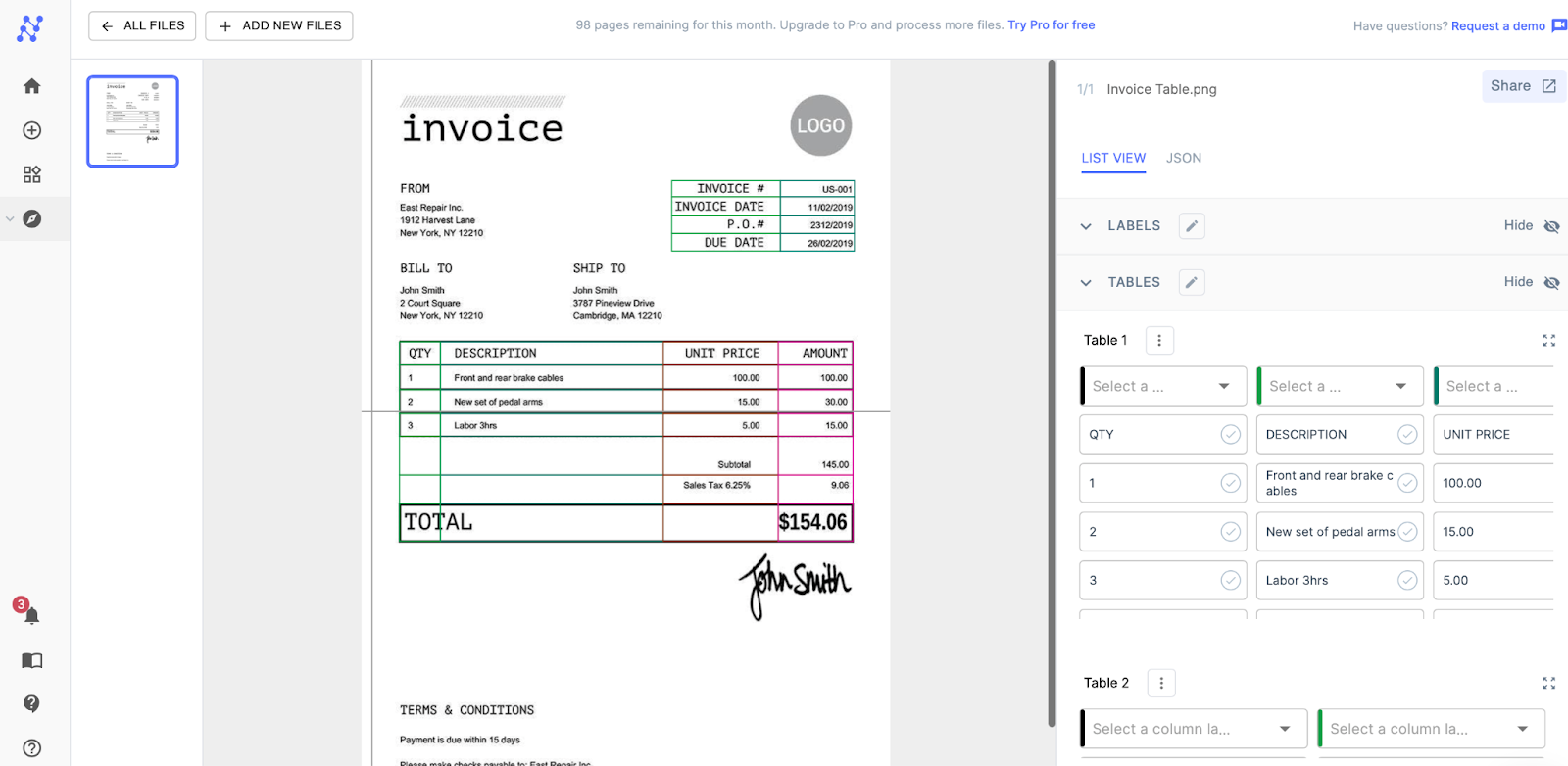
Step 4.
After processing, Nanonets extracts all tabular information accurately, even skipping the empty spaces! The data can also be put into JSON for downloading and further computations.
Conclusion
And there you have it! A brief history into the progression of techniques in extracting tabular data and how to incorporate it into your businesses easily. Hopefully this saves you much labour previously required in keying in and double checking data.