This post is mostly going to focus on invoice OCR and invoice information extraction using OCR and deep learning. We will also touch upon what is wrong with the current state of invoice recognition OCR and information extraction in invoice processing.
For a long time, we have relied on paper invoices to process payments and maintain accounts. Reconciling invoices typically involves someone manually spending hours browsing through several invoices and jotting things down in a ledger.
But can this process be done better, more efficiently, with less wastage of paper, human labor and time?
Among the several drawbacks of going through these procedures manually are higher costs, greater manpower requirement, a higher amount of time consumed in repetitive tasks and a greater carbon footprint.
Let's find out how invoice OCR and invoice digitization can help in this regard.
What is an invoice OCR?
Invoice OCR refers to the process of extracting relevant data from scanned or PDF invoices and converting it into a machine-readable format that is both editable and searchable.
Digitizing an Invoice
The process of digitizing an invoice can be broken down into 3 steps:
- Converting the physical document to a digital variant - this could be done through
- invoice scanning
- clicking an image through a camera
- Information Extraction - this can be done by
- Humans - manually done by reviewers who will analyse the invoice for errors, read the text in it and enter it into a software for storage and future retrieval.
- Machines -
- Optical Character Recognition (invoice OCR) - recognizing the text and numbers present in the documents.
- Information Extraction - once the Process of OCR is complete it’s important to identify which piece of text corresponds to which extracted field. If a field is the total, subtotal, date of invoice, vendor etc.
- Data dump - once the information has been extracted it needs to be stored in a retrievable format like
- A database
- An excel sheet
- An ERP system.
Why digitize invoices?
Digitizing information offers several advantages that businesses can gain on multiple grounds. Businesses can track their processes better, can provide better customer service, improve the productivity of their employees, and reduce costs.
Here are some reasons why you should consider digitizing invoices for your own business.
- To automate processes
With deep learning and OCR, you can automatically take these invoice images, extract tables and text from them, extract the values of different fields, make error corrections, check if the products match your approvable inventory and finally process the claim if everything checks out. This is a massive leap from what the insurance industry has traditionally done, but it can prove very beneficial nevertheless. - To increase efficiency
By digitizing invoices, several processes can be made a lot faster and smoother. Take for example a retail store chain that deals with a few regular vendors for commodities and process payments at the end of every month. This store can save a lot of time by automating the process of invoice management. Vendors just have to upload the bills on an app or a website and they can get instant feedback on if the images are of good resolution if the image is of the entire invoice if the image is fake or was digitally manipulated, etc saving a lot of time. - To reduce costs
The same retail stores' franchise saves a lot of money by automating invoice digitization using PDF OCR and deep learning. An invoice which has to pass through the hands of three reviewers so there are no errors reduces to one. The number of invoices processed by a computer is several times faster than what a human could do. The time includes checking if the invoice is a fraud, if it has all the information, if all the information is correct, entering all of the data manually into a spreadsheet or a database, running calculations and finally processing the payment. - For better storage
In the case of disputes, the vendor can reach the app and look through all the invoices he/she uploaded and the post-processing results of each invoice, explaining the commodities, their quantities, the costs of each, the taxes and the discounts. The company, having automated the process of entering this data into a database, can also now retrieve this information anytime. - To increase customer satisfaction
Invoice processing in a similar way can also help companies improve their customer service. Your delivery from an e-commerce platform missing a product? Reach out to them, send them the invoice and explain what's missing and the company will automatically read the receipt, find what left their warehouses and send you a response saying your missing product is now on the way! - To reduce the ecological footprint
Doing some simple calculations like those done here we realize that a mid-sized organization processing 50000 invoices a month ends up sacrificing more than 30 trees a year. This number is most of the time going to increase due to the duplication of invoices. This same volume of paper is also going to require 2.5 million liters of water to manufacture. In such a time, taking the steps necessary by organizations to reduce their ecological footprint can go a long way in helping the environment.
Evolution of the invoicing process
The process of reviewing invoices has evolved a lot over time. The growth in technology has seen the process of invoice processing move through three major phases.
Phase 1: Manual Reviewing
Consider a use case where an organisation is going through it's process of reimbursing its regular vendors for the expenses of the month.

The following steps are followed to process invoices -
- People are expected to submit several invoices in person to the concerned organisation's point of contact.
- This person would in turn forward all the invoices to a reviewer who will review every document entirely. This includes writing down or entering each detail into a software like name of the person making the purchase, name of the store purchased from, date and time of purchase, items purchased, their costs, discounts and taxes.
- The sum total of each invoice calculated, again manually or if the data entry software is specifically designed for accounting purposes, using said software.
- A final bill/receipt is made with the final figures and the payments are processed.
Phase 2: Invoice Scanning and Manual Reviewing
With the advent of OCR techniques, much time was saved by automatically extracting the text out of a digital image of any invoice or a document. This is where most organisations that use OCR for any form of automation are currently.
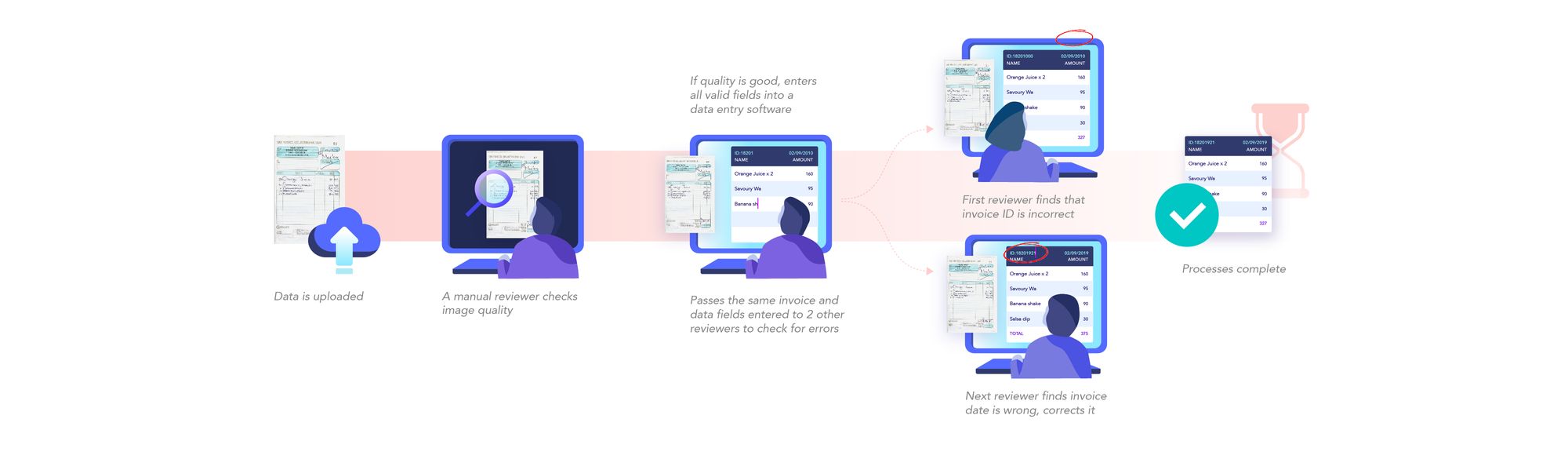
- Digital copies of invoices are obtained by scanning invoices or taking pictures using a camera.
- The text is extracted from these invoices using OCR. This is able to provide digital text that makes data entry a little easier. But a lot of work still needs to be done manually.
- The OCR results of each invoice have to be parsed appropriately to find the relevant data and discard the irrelevant data.
- Once this is done, the data has to be entered into accounting automation software which provides the reviewer with a template to make his task easier. This template is unique to each use case, organisation and mostly for each different kind of invoice. While the OCR process helps the invoice processing, it doesn't solve many tedious parts due to the unstructured data extracion results of OCR.
- The data entered is put through manual review to correct errors. This process takes some time since it goes through multiple reviewers due to poor performance of currently available OCR tools.
- Finally, the calculations are done and the payment details are forwarded to the finance division.
How to digitize invoices better?
By using OCR and deep learning, we have enabled machines to perform as well and in some cases even better than humans.
Digitizing invoices involves several human moderated steps :
- Digital images of invoices taken and uploaded by the user.
- Image verified to be fit for further processing - good resolution, all data visible in the image, dates verified, etc.
- Images checked for fraud.
- Text in these images extracted and put in the right format.
- Text data entered into tables, spreadsheets, databases, balance sheets, etc.
Phase 3: Deep Learning and OCR

Deep learning approaches have seen advancement in the particular problem of reading the text and extracting structured and unstructured information from images. By merging existing deep learning methods with optical character recognition technology, companies and individuals have been able to automate the process of digitizing documents and enabled easier manual data entry procedures, better logging and storage, lower errors and better response times.
Several tools are available in the market and the open-source community for such tasks, all with their pros and cons. Some of them are Google Vision API (Google Docs OCR), Amazon Rekognition and Microsoft Cognitive Services. The most commonly used open-source tools are Attention-OCR and Tesseract.
All these tools fall short in the same manner - bad accuracy, which requires manual error correction, and the need for rule-based engines following the text extraction to actually be able to use the data in any meaningful manner. We will talk more about these problems and more in the coming sections.
What makes the problem interesting?
The OCR landscape mostly consists of rule-based engines that rely heavily on post-processing OCR results by matching patterns or defining specific templates that the OCR results are forced to fit in. This approach has seen some success, but requires a layer of software built on top of the OCR engines, which is a resource-consuming task.
A bigger problem with this rule-based approach is that this added layer of software has to be designed again every time you are dealing with a new invoice template. Automating the templating process along with OCR can create a massive impact for anyone working with invoices.
And that's just the problem we at Nanonets resolved to solve.
A lesser-known approach to this problem includes using machine learning to learn the structure of a document or an invoice itself, allowing us to work with data, localize the fields we need to extract first as if we were solving an Object Detection problem (and not OCR) and then getting the text out of it. This can be done by modeling your neural networks in a way to learn how to identify and extract tables, understanding columns and fields present in it, what columns and fields are commonly found in an invoice notwithstanding the format.
The advantage of such an approach is that it becomes possible to make a machine learning model that can be generalized to any kind of document or invoice and can be used out of the box without any customizations. Adding a continuous learning loop by collecting new data and retraining models periodically can lead to great performance on a large variety of data.
Why current deep learning tools don't suffice?
Even with all the benefits automated invoice processing has to offer, industries haven't seen widespread adoption of OCR and deep learning technologies and there are several reasons for it.
Let's try to understand with an example - a health insurance company dealing with prescriptions and invoices. Automating claims processing in your insurance company by letting users upload images of invoices by taking pictures on their phones or computers or scanning invoices will increase the convenience for customers and will attract them more. These uploaded images usually go through several rounds of the manual review where you verify if the invoices are legitimate if the numbers add up, it the products mentioned in the receipts are valid for an insurance claim, etc. But with invoice processing automation, these tasks can be done in a fraction of the time taken to do it manually, and with at least a 50% reduction in manpower required.
But there are roadblocks to building such an end to end approach that performs as per an industry use-case, can drive automation while making sure errors do not consume much of the budget and is also driving higher rates of customer onboarding.
Accuracy of OCR technology
Currently, the best OCR tools available in the market do not perform satisfactorily to apply these APIs at scale for any use case. According to this article, Google Vision, the best OCR API available right now is only able to provide an 80% accuracy. The accuracies of other products in the market like Amazon Rekognition and Microsoft Cognitive Services are dismal. Microsoft performed with an accuracy of 65% whereas AWS rekognition only performed with a 21% accuracy.
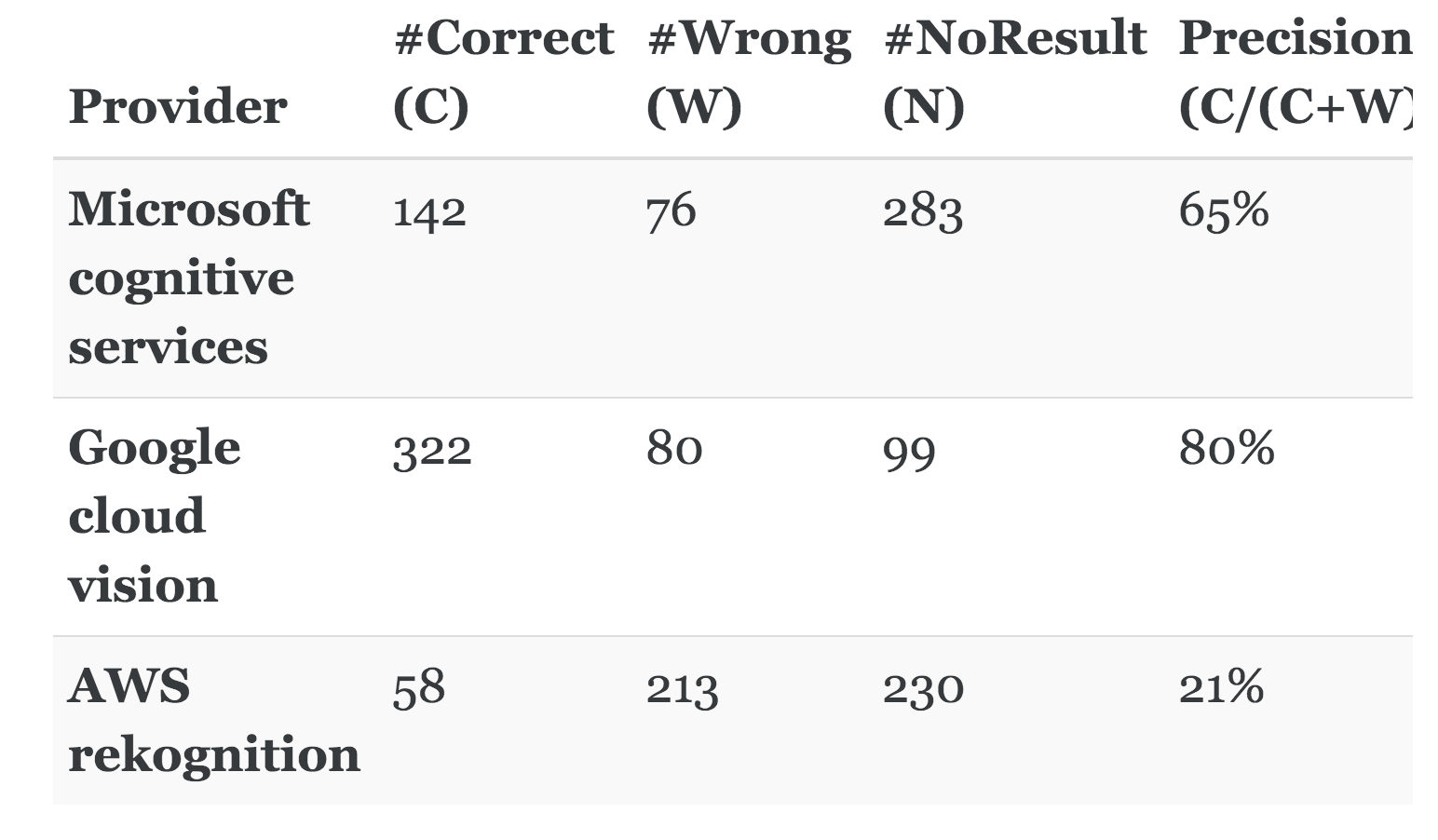
This is made worse by the fact that these APIs do not allow for custom training for specific data the company would be using the most. Investing in software that performs worse than humans in terms of accuracy, still needs manual entry, manual error correction and manual review seems like a waste of time and money.
Deep Learning expertise
OCR products like Google Vision face several drawbacks when it has to deal with text in different orientations, different languages, shadowy or noisy text. They do not allow you to use your data and build custom models, making the product's direct integration into an organization's workflow difficult. Many times, to work around a problem like this, organizations have to hire a data science or machine learning team and build these tools for themselves. This takes time, money and effort.
Following this, the data scientists have to align their knowledge and expertise with company goals and figure out exactly what metrics to optimize to deliver those results. This requires the data scientist to understand a business proposition, turn it into a mathematical problem, understand company SLAs, find the right data, build machine learning models, tune them to get the required accuracy while making sure the error cases are handled gracefully as well.
Getting the right data
A very important part of building the right machine learning model is finding the right data, and there just isn't enough data for us to work with. There are datasets available for OCR for tasks like number plate recognition or handwriting recognition but these datasets are hardly enough to get the kind of accuracy an insurance claims processing or a vendor repayment assignment would require.
These use cases require us to build our models and train them on the kind of data we are going to be dealing with the most while also making sure that errors are minimized and the dataset is balanced. Dealing with, say prescriptions from doctors or receipts from small vendors require our models to perform well on digital as well as handwritten text documents.
Computational resources
The task of building an in-house ML solution involves more than just hiring the best machine learning engineers to design the algorithms with the best accuracy. The computational requirements for building models on image data are high and usually includes GPUs either on-premise or on-cloud. Running a K-80 GPU instance on Google Cloud Platform costs around $230 a month. These costs spike up when you have to train models or retrain old models with new data.
If building an in-house solution is the approach you choose, the costs of building it must be compensated by an increased amount of customers signing up, an increased rate of processing invoices and a decrease in the number of manual reviewers required.
Tailoring solutions to your business needs

Building a vendor repayment system, for example, requires us to include several steps. Finding an automated workflow for your organizational needs is not the same as building a machine learning model that will give you good accuracy.
What you need is models that can:
- Deliver at least human-level accuracy
- Can handle all sorts of data
- Accommodate error handling
- Increase the convenience of human supervision
- Provide transparency in the data processing steps
- Check for fraud
- Allow post-processing OCR results to put them in a structure
- Allow making sure all required fields are there and the values are correct
- Allow easy storing and databasing of this data
- Allow automating notification procedures depending on the results
This is, as you might have guessed, a long and difficult procedure, often with not so straightforward solutions.
Nanonets supports invoice capture & invoice automation in over 60 languages. Build your own model or request a demo today!
Enter Nanonets

With Nanonets you do not have to worry about finding machine learning talent, building models, understanding cloud infrastructure or deployment. All you need is a business problem that you need solutions for.
Easy to use web-based GUI
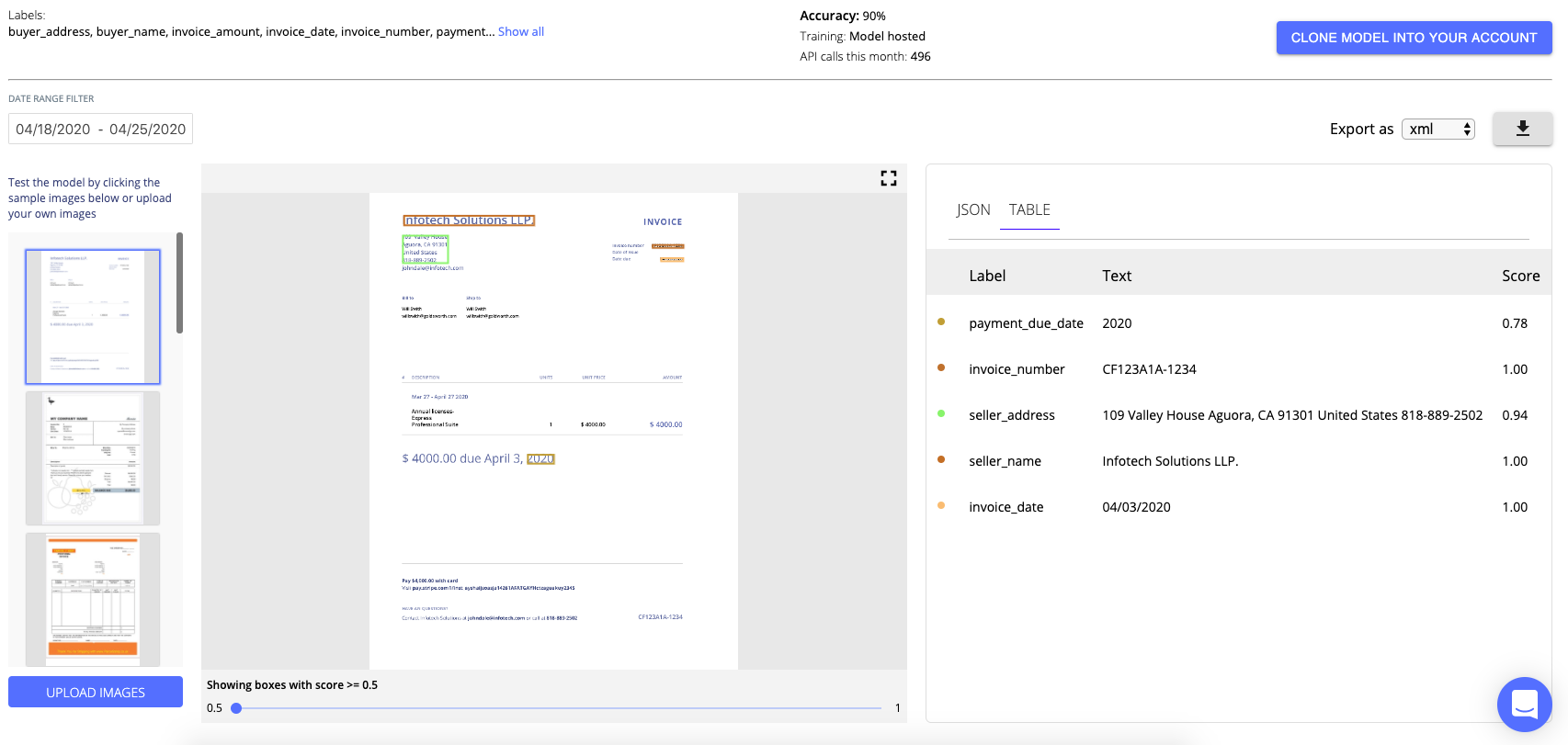
Nanonets offers an easy to use web-based GUI that communicates with their API and lets you create models, train them on your data, get important metrics like precision and accuracy and run inference on your images, all without writing any code.
Cloud-hosted models
Besides providing several models that can be used out of the box directly to get solutions, users can build their models that are hosted on the cloud and can be accessed with an API request for inference purposes. No need to worry about getting a GCP instance or GPUs for training.
State-of-the-art algorithms
The models built use state-of-the-art algorithms to get you the best results. These models constantly evolve to become better with more and better data and better technology, better architecture design, and more robust hyperparameter settings.
Field extraction
The greatest challenge in building an invoice digitization product is to give structure to the extracted text. This is made easier by our OCR API that automatically extracts all the necessary fields with the values and puts them in a table or a JSON format for you to access and build upon easily.
Automation driven
We at Nanonets believe that automating processes like invoice digitization can create a massive impact on your organization in terms of monetary benefits, customer satisfaction, and employee satisfaction. Nanonets strives to make machine learning ubiquitous and to that end, our goal remains to make any business problem you have solved in a way that requires minimal human supervision and budgets in the future.
OCR with Nanonets
The Nanonets Platform allows you to build OCR models with ease. You can upload your data, annotate it, set the model to train and wait for getting predictions through a browser based UI without writing a single line of code, worrying about GPUs or finding the right architectures for your deep learning models.
Update: Our models are even more accurate. We've added new fields like PO number, email IDs and table extraction for further improving your invoice automation workflows.
Start Digitising Invoices with Nanonets - 1 Click Digitisation:
Setup a Demo
Setup a demo to learn about how Nanonets can help you solve this problem
Further Reading
- Automated invoice handling with machine learning and OCR
- Template Matching-Based Method for Intelligent Invoice Information Identification
- Quick Steps to Digitalization of Your Receipts and Invoices
Update:
Added more reading material about different approaches in automating invoice processing using OCR and Deep Learning.