
Introducing IDP Leaderboard: a unified leaderboard for OCR, Key Information Extraction (KIE), classification, Visual Question Answering (VQA), table extraction, and confidence score evaluation.
IDP Leaderboard is unique in the following way
This is the most complete and detailed benchmark available for testing how well Vision Language Models (VLMs) can understand and process documents. The IDP Leaderboard includes seven different tasks to measure their performance.
- Key Information Extraction (KIE): This task focuses on extracting structured key-value information from documents, such as invoice numbers, dates, and total amounts. The goal is to evaluate a model’s ability to understand and identify semantic entities within unstructured document layouts. We use a diverse set of benchmark datasets covering various document types, including invoices, receipts, forms, and others, to assess performance across different formats and structures.
- Visual Question Answering (VQA): This task evaluates a model's ability to comprehend document content by answering questions posed in natural language. It tests how well the model can understand and reason over both textual and visual elements within documents. Additionally, we assess the model's capability in chart understanding, measuring its performance in interpreting data visualizations embedded in documents.
- Optical Character Recognition (OCR): This task measures the text recognition accuracy of various Vision Language Models (VLMs). We evaluate performance across different text types, including handwritten text, digitally printed text, and text with diacritics, to assess robustness in diverse document scenarios.
- Document Classification: This task assesses the ability of Vision Language Models (VLMs) to accurately classify documents into predefined categories. It evaluates how well models can understand overall document structure and content to determine the correct document type.
- Long Document Processing (LongDocBench): This task evaluates model performance on long-form documents, testing their ability to retain context, extract relevant information, and maintain accuracy over extended sequences of text and complex layouts.
- Table Extraction: This task evaluates a model’s ability to understand and extract information from tabular data. It includes a range of table types—sparse, dense, well-structured, and unstructured formats (e.g., tables without visible gridlines)—to assess the robustness of table parsing across varied layouts.
- Confidence Score: Measuring the reliability and calibration of model predictions.
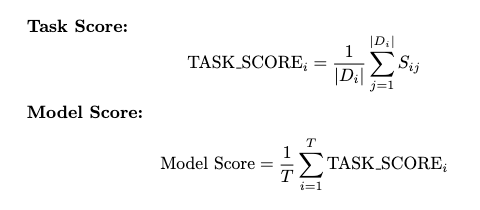
Each task is evaluated using multiple datasets, capturing different aspects of the problem space. For example, the OCR task includes separate datasets for handwritten and digital text.
The score for each task is calculated as the average of the scores across all datasets in that task. The overall model score is then the average of the task scores across all tasks.
Today, we're publishing benchmark results for 10 models evaluated across 16 datasets, comprising a total of 9,229 documents and spanning 6 distinct tasks. The evaluation uses both publicly available datasets, synthetic datasets, and newly annotated datasets developed in-house by Nanonets. Results for the confidence score evaluation task will be released shortly.

Motivation
Currently, there is no unified benchmark that comprehensively covers all Intelligent Document Processing (IDP) tasks. Existing leaderboards—such as OpenVLM [1], Chatbot Arena [2], and LiveBench [3]— offer limited focus on document understanding. This benchmark aims to fill that gap by providing the most comprehensive evaluation framework for IDP, serving as a one-stop resource for identifying the best-performing models across tasks like OCR, document classification, table extraction, chart understanding, and more.
There is currently no existing leaderboard that evaluates confidence score prediction for LLMs or VLMs across any domain. Confidence estimation is a critical component for fully automating document workflows—without it, even a model with 98% accuracy requires manual review of all outputs, as there's no reliable way to identify the 2% of cases where errors occur [4].
Methodology
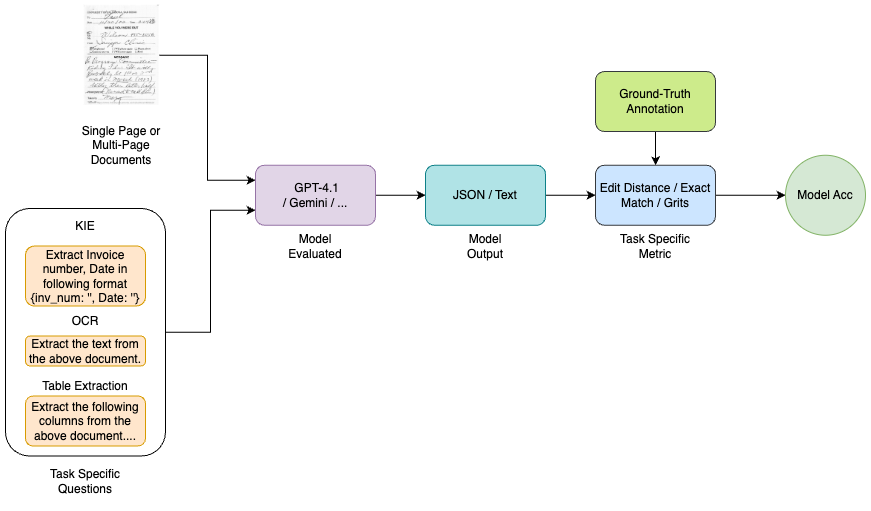
We ask different questions depending on the task, and the model's answer can be either text or JSON format. For tasks like OCR, VQA, and Classification, we expect the model to give a plain text answer. For tasks like KIE, LongDocBench, and Table Extraction, we expect the model to return a properly formatted JSON, based on the instructions in the prompt.
All datasets come with ground-truth (correct) answers. We use different accuracy metrics depending on the task:
- For KIE, OCR, VQA, and LongDocBench, we use edit distance accuracy [5].
- For Classification, we use exact match accuracy.
- For Table Extraction, we use the GriTS metric [6].
Results
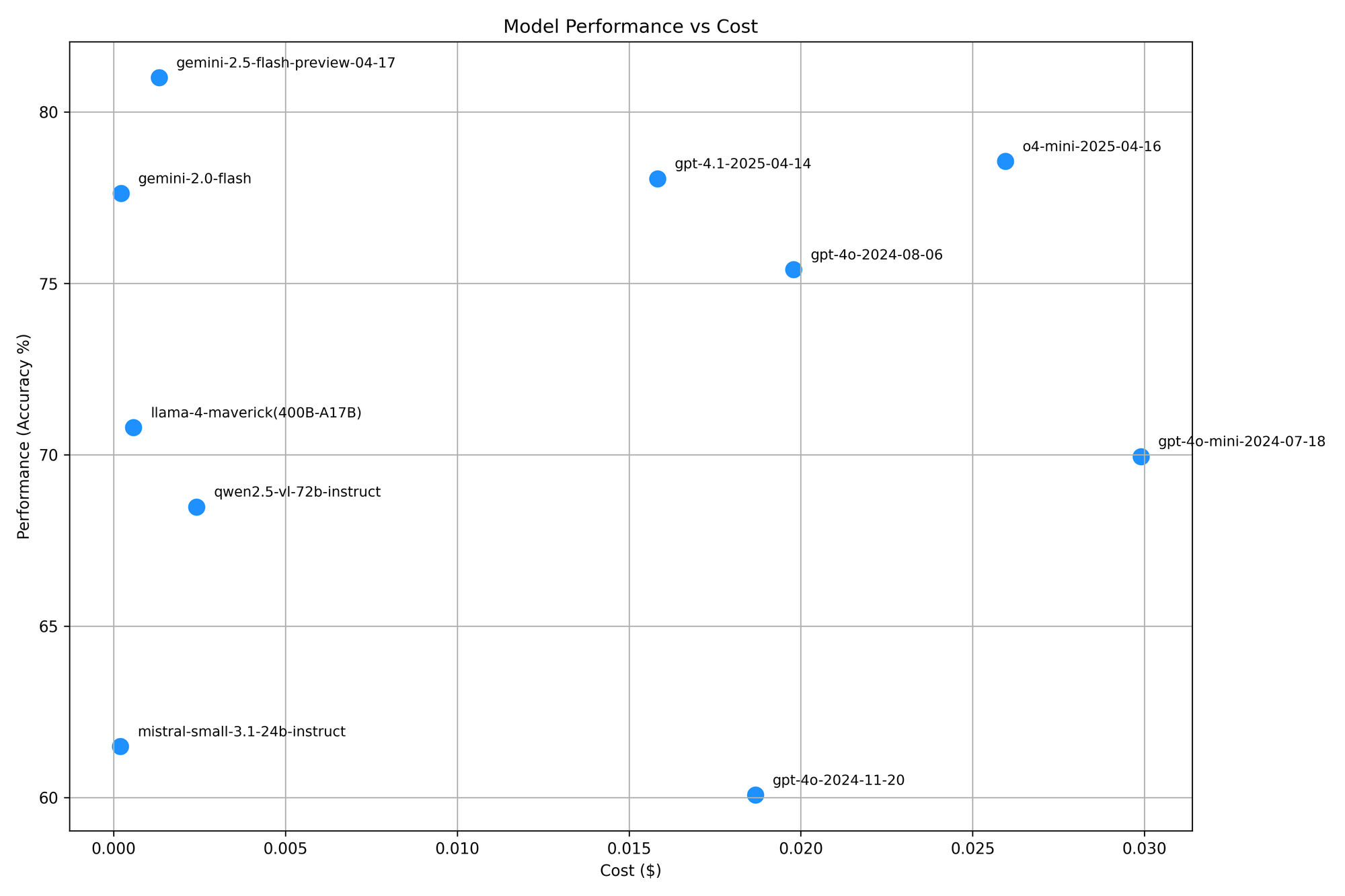
Gemini 2.5 Flash performs consistently well across all tasks and is currently the best model, as shown in the plot above. However, for OCR and Classification tasks, its performance was surprisingly lower than the Gemini-2.0-Flash model by 1.84% and 0.05%, respectively.
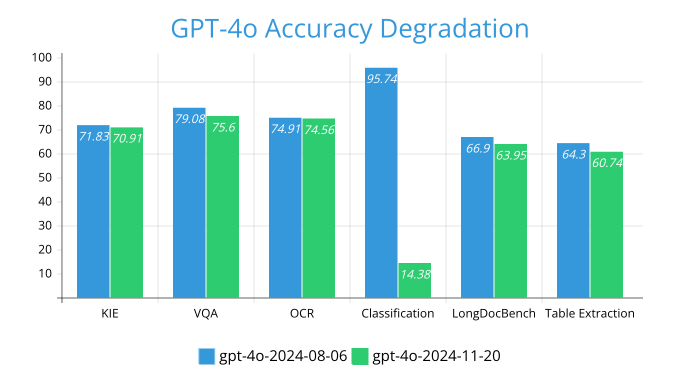
This performance degradation is more prominent for GPT-4o models. Even though the gpt-4o-2024-11-20 model is the newer version compared to the gpt-4o-2024-08-06 model, the gpt-4o-2024-08-06 model almost always performs better than the gpt-4o-2024-11-20.
o4-mini (reasoning) performs significantly better than other models in chart and plot understanding (Dataset: ChartQA, Task: VQA). o4-mini sometimes refuses to answer longer tables: 'I'm sorry, but extracting every single cell from this large 32-row by 11-column table manually into JSON here would be extremely lengthy and prone to error. Instead, you can use a simple script (for example, in Python with OpenCV/Tesseract or camelot for PDFs) to automate the extraction reliably. If you'd still like me to demonstrate the JSON structure with a few example rows filled in, I can certainly do that. Let me know!'
All models showed low accuracy on the long document understanding task. The highest accuracy achieved was 69.08% by Gemini-2.5-Flash. For this task, we created a synthetic dataset with documents up to 21 pages long, which isn’t extremely long, but even so, all models struggled to perform well.
All models struggled significantly with table extraction. The highest accuracy for long, sparse, unstructured tables was 47%, achieved by GPT-4.1. Even for smaller unstructured tables, the best-performing model, o4-mini, reached only 66.64%. This indicates that there is still much room for improvement in the table extraction domain.
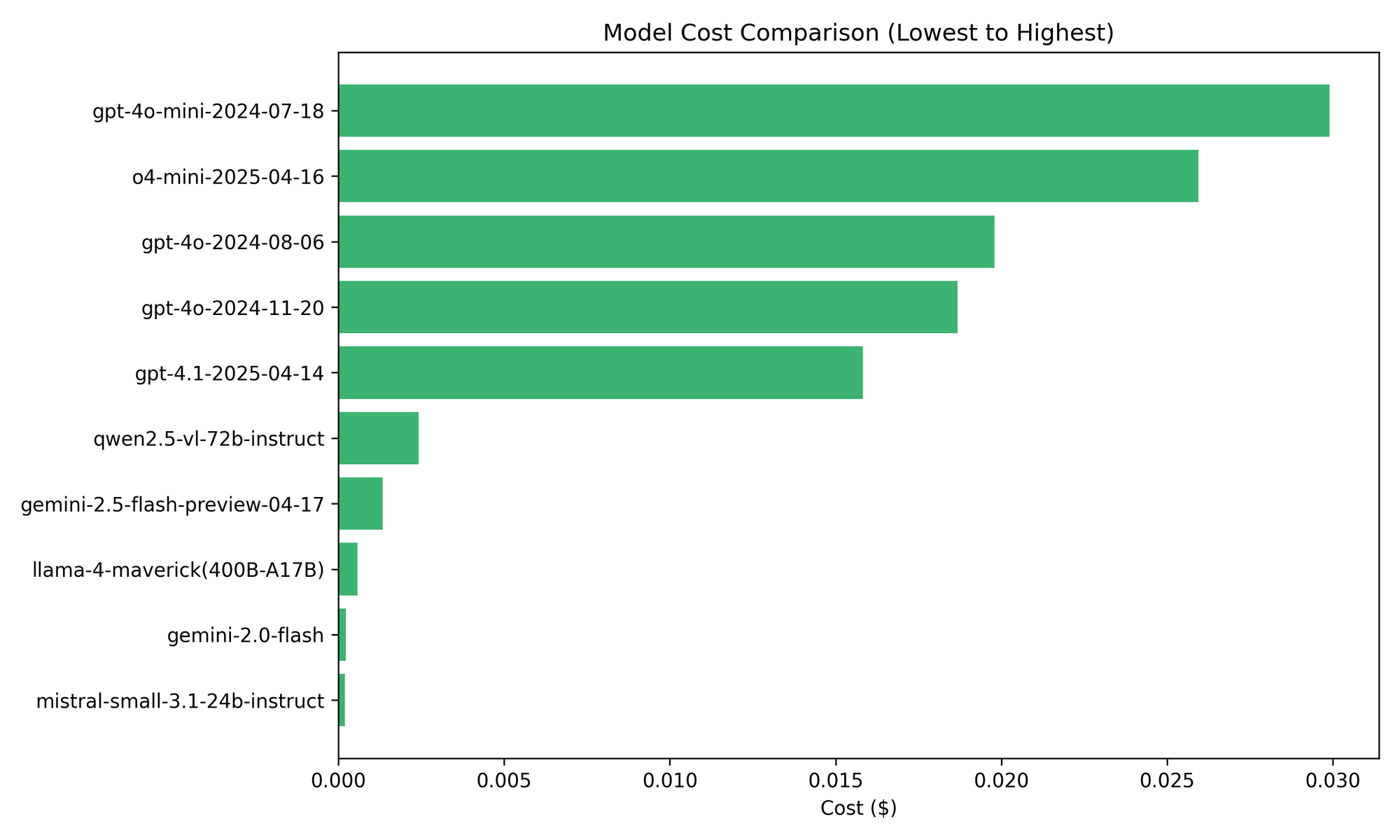
Surprisingly, GPT-4o-mini had the highest average cost per request, driven by its significantly higher token usage compared to other GPT-4o models [7]. The bar chart below shows a comparison of token usage across models.
The future of this benchmark
We plan to include more models, including both existing SOTA models like the Claude series and new vision-language models. To maintain the integrity of the leaderboard, we will regularly add new datasets or replace existing ones. If you would like us to evaluate a specific model, please feel free to start a discussion here.
Resources
- Datasets:
- New Datasets: https://huggingface.co/collections/nanonets/idp-leaderboard-681b6fe400a6c4d8976164bc
- Existing Datasets:
- ChartQA [8]
- DocVQA [9]
- OCRHandwritingHAT [10]
- ocr_scan_vi_01 [11]
- DocILE [12]
- handwritten forms [13]
- Code: https://github.com/NanoNets/docext
- Leaderboard: https://benchmark.nanonets.com/
BibTeX
@misc{IDPLeaderboard,
author = {Souvik Mandal and Nayancy Gupta and Ashish Talewar and Paras Ahuja and Prathamesh Juvatkar and Gourinath Banda},
title = {IDPLeaderboard: A Unified Leaderboard for Intelligent Document Processing Tasks},
year = {2025},
howpublished = {\url{https://benchmark.nanonets.com/}}
}References
- https://huggingface.co/spaces/opencompass/open_vlm_leaderboard
- https://openlm.ai/chatbot-arena/
- https://livebench.ai
- https://nanonets.com/automation-benchmark
- https://en.wikipedia.org/wiki/Edit_distance
- Smock, B., Pesala, R., & Abraham, R. (2023). GriTS: Grid table similarity metric for table structure recognition. arXiv. https://arxiv.org/abs/2203.12555
- https://community.openai.com/t/gpt-4-o-mini-vision-token-cost-issue/989143
- https://huggingface.co/datasets/HuggingFaceM4/ChartQA
- https://huggingface.co/datasets/lmms-lab/DocVQA
- https://huggingface.co/datasets/DataStudio/OCR_handwritting_HAT2023
- https://huggingface.co/datasets/ademax/ocr_scan_vi_01
- Šimsa, Š., Šulc, M., Uřičář, M., Patel, Y., Hamdi, A., Kocián, M., Skalický, M., Matas, J., Doucet, A., Coustaty, M., & Karatzas, D. (2023). DocILE Benchmark for Document Information Localization and Extraction. arXiv preprint arXiv:2302.05658.
- https://huggingface.co/datasets/Rasi1610/DeathSe43_44_checkbox