
Amazon Textract is AWS's machine learning service that reads and processes documents automatically. It does more than just turn images into text like basic OCR tools. You can use it to pull data from forms and tables, process both typed and handwritten text, work with PDFs and scanned images, and handle multilingual document processing. It even comes with ready-to-use tools for specific documents like invoices, IDs, and lending paperwork.
Our analysis of real-world implementations revealed Textract's clear strengths and limitations. It excels at processing structured financial documents and forms within the AWS ecosystem. The pricing starts at $1.50 per 1,000 pages for basic text extraction, scaling up for specialized document types like invoices or lending documents. On the other hand, he platform falls short when it comes to:
2. Costs that scale poorly for large volumes
3. Complex document layouts and non-standard formatting
4. Table extraction with advanced formatting
5. Setup requiring AWS expertise and ongoing maintenance
Let's look at the top Textract alternatives to help you pick the right tool for your document processing needs.
A quick comparison of Amazon Textract alternatives
| Sr No. | Product | Main feature | G2 rating | Free trial | Pricing | Total score* |
|---|---|---|---|---|---|---|
| 1 | Amazon Textract | AWS-native document processing | 4.4/5 | No | Pay-as-you-go ($1.50 per 1,000 pages) | 43.4 |
| 2 | Nanonets | End-to-end automation with 98% accuracy | 4.8/5 | Yes (500 pages) | Pay-as-you-go, First 500 pages free | 46.5 |
| 3 | Rossum | Cognitive data capture | 4.4/5 | No | Custom pricing | 43.8 |
| 4 | Docparser | Rule-based extraction | 4.6/5 | Yes | Starts at $39/month | 44.0 |
| 5 | Azure DI | Enterprise integration | 4.5/5 | Yes | Pay-as-you-go | 43.2 |
| 6 | Google Cloud Document AI | ML-powered processing | 4.2/5 | Yes | Pay-as-you-go | 43.2 |
| 7 | ABBYY FlexiCapture | Advanced OCR capabilities | 4.1/5 | No | Starts at $4,150 (one-time) | 44.3 |
| 8 | Tungsten Capture | High-volume document scanning | 4.3/5 | Yes | Custom pricing | 43.0 |
| 9 | Laserfiche | Enterprise content management | 4.7/5 | Yes | Starts at $50/user/year | 43.9 |
| 10 | Hyperscience | Human-in-loop workflows | 4.6/5 | No | Custom pricing | 46.3 |
(*Refer to scoring methodology at the bottom)
Now, let's examine each alternative in detail to understand their specific strengths, limitations, and ideal use cases. We'll analyze how they compare to Textract and help you determine which solution best fits your document processing needs.
1. Nanonets
Nanonets is an AI based document processing platform that goes beyond basic OCR to provide end-to-end automation. Unlike Textract's template-based approach, we use deep learning to understand document context and adapt to new layouts automatically. Our platform combines OCR, natural language processing, and machine learning to handle everything from data extraction to workflow automation.
1. Intelligent document classification and routing
2. Automated data validation and error checking
3. Custom model training with as few as 10 samples
4. Pre-built models for invoices, receipts, IDs
5. Multi-stage approval workflows
6. Database matching for data verification
7. Automated export to accounting systems
8. Webhook and API integrations
9. Built-in human verification tools
| Pros of Nanonets | Cons of Nanonets |
|---|---|
| Template-free processing with self-learning models | Higher cost for low volumes |
| Supports 40+ languages | UI can be overwhelming at first |
| Pre-trained models for common documents | Learning curve for complex workflows |
| Extensive integration capabilities | |
| Strong workflow automation capabilities | |
| Built-in verification and approval flows | |
| Robust API documentation and support | |
| Regular model improvements from corrections |
Pricing: Free tier available for first 500 pages. Pro plan starts at $999/month for 10,000 pages.
Best suited for: Mid to large organizations in finance, healthcare, logistics, and manufacturing sectors processing varied document types.
How does Nanonets compare to Amazon Textract?
Parameter | Nanonets | Amazon Textract |
|---|---|---|
Ease of Use | 9.3 | 8.9 |
Ease of Setup | 9.1 | 8.9 |
Quality of Support | 9.4 | 8.6 |
Meets Requirements | 9.1 | 8.8 |
Product Direction (% positive) | 9.6 | 8.2 |
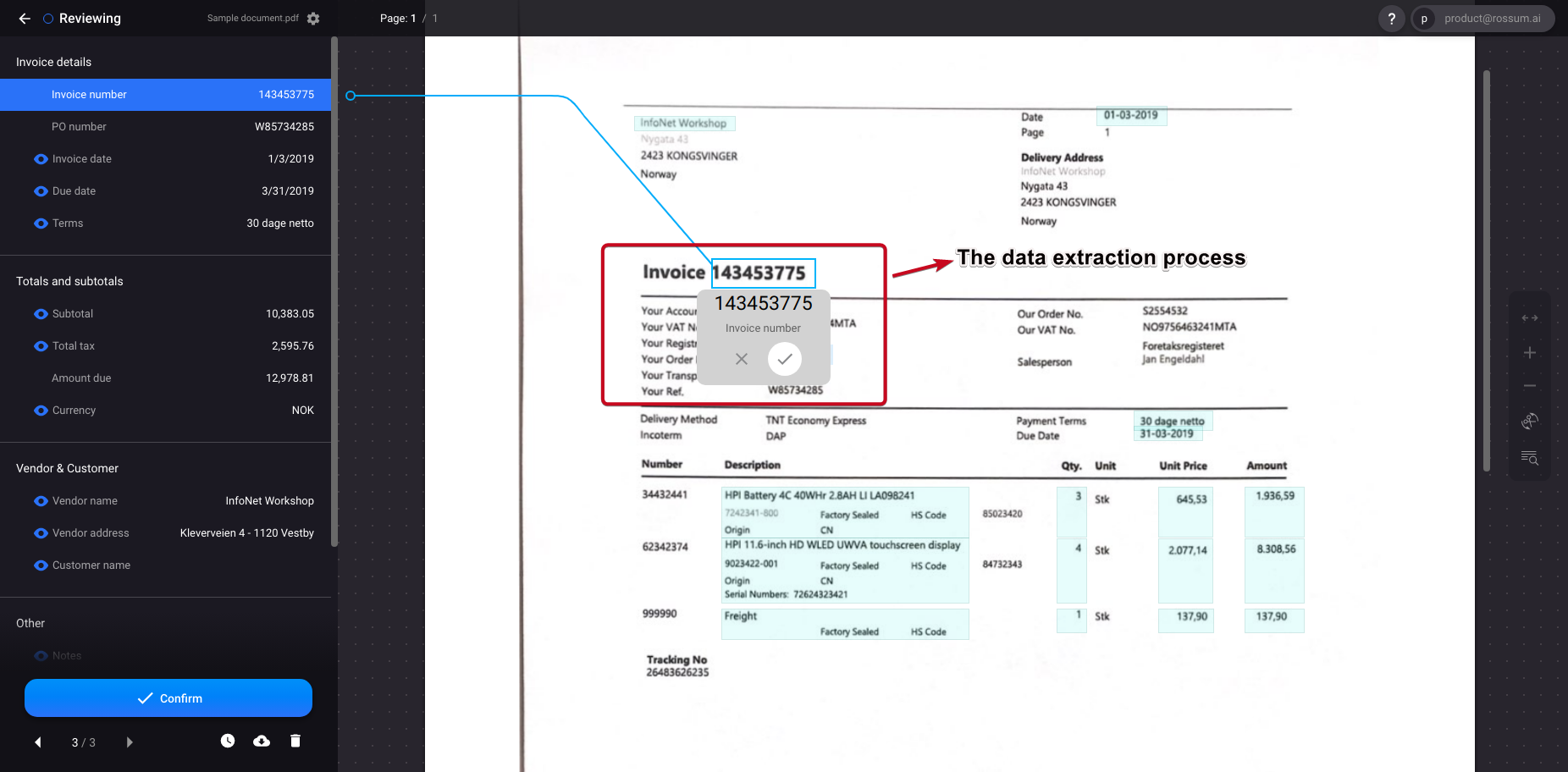
2. Rossum
{kind=link}
Rossum's approach to document processing involves using cognitive data capture instead of traditional template-based extraction. The platform combines AI-powered understanding with extensive workflow automation to handle the entire document lifecycle - from receiving to processing to integration with business systems.
Read About: Rossum Alternatives and Competitors
1. Cognitive data capture without templates
2. Multi-channel document receiving
3. Built-in exception handling workflow
4. Extensive validation rules engine
5. Enterprise-grade integrations
6. Custom field validation
7. ISO 27001 and SOC 2 certified
8. Two-way communication for exceptions
| Pros of Rossum | Cons of Rossum |
|---|---|
| No templates needed for new layouts | Higher cost for low volumes |
| Better handling of complex documents | System glitches during updates |
| Strong enterprise-grade support | Slower processing of large PDFs |
| Built-in exception management | Steeper learning curve initially |
| Extensive validation capabilities | Complex API for tax structures |
| Regular AI improvements | Limited Excel support |
| Flexible customization options | |
| Robust security compliance |
Pricing: Enterprise-focused pricing with custom quotes based on volume. Includes SLA guarantees and dedicated support.
Best suited for: Organizations across manufacturing, retail, and financial services that need comprehensive document automation. Rossum particularly excels in AP departments and shared service centers processing varied vendor documents.
How does Rossum compare to Amazon Textract?
Parameter | Rossum | Amazon Textract |
|---|---|---|
Ease of Use | 8.5 | 8.9 |
Ease of Setup | 8.0 | 8.9 |
Quality of Support | 9.2 | 8.6 |
Meets Requirements | 8.3 | 8.8 |
Product Direction (% positive) | 9.8 | 8.2 |
3. Docparser
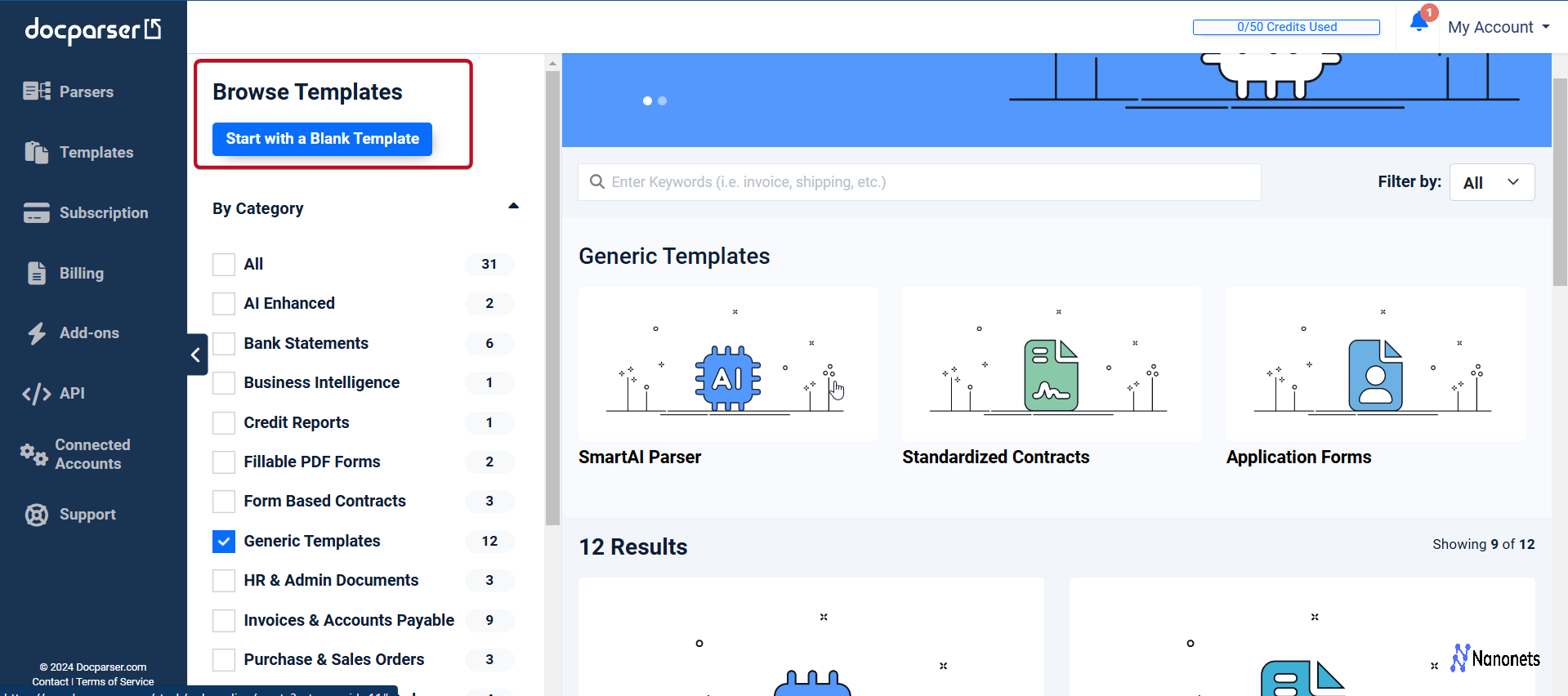
Docparser offers a rule-based approach using zonal OCR technology. While Textract uses machine learning to understand documents, Docparser lets you define exactly how and where to extract data using customizable parsing rules.
1. Customizable zonal OCR extraction
2. Advanced table parsing capabilities
3. Smart document routing system
4. Pre-built parsing templates
5. Automated data formatting
6. Multi-format document support
7. Extensive API access
| Pros of Docparser | Cons of Docparser |
|---|---|
| More precise extraction control | Requires manual rule setup |
| Better with consistent layouts | Limited AI capabilities |
| Stronger table extraction | Learning curve for setup |
| More affordable for low volumes | One language at a time |
| Simpler integration options | Template maintenance needed |
| Quick processing speed | Not ideal for varied layouts |
| Excellent customer support | |
| Clear pricing structure |
Pricing: Transparent tiered pricing starting at $39/month for 100 documents. Business plan at $159/month for 1,000 documents. Enterprise plans available.
Best suited for: Small to mid-sized businesses processing consistent document formats, especially in finance and operations.
How does Docparser compare to Amazon Textract?
Parameter | Docparser | Amazon Textract |
|---|---|---|
Ease of Use | 9.0 | 8.9 |
Ease of Setup | 8.8 | 8.9 |
Quality of Support | 8.9 | 8.6 |
Meets Requirements | 8.7 | 8.8 |
Product Direction (% positive) | 8.5 | 8.2 |
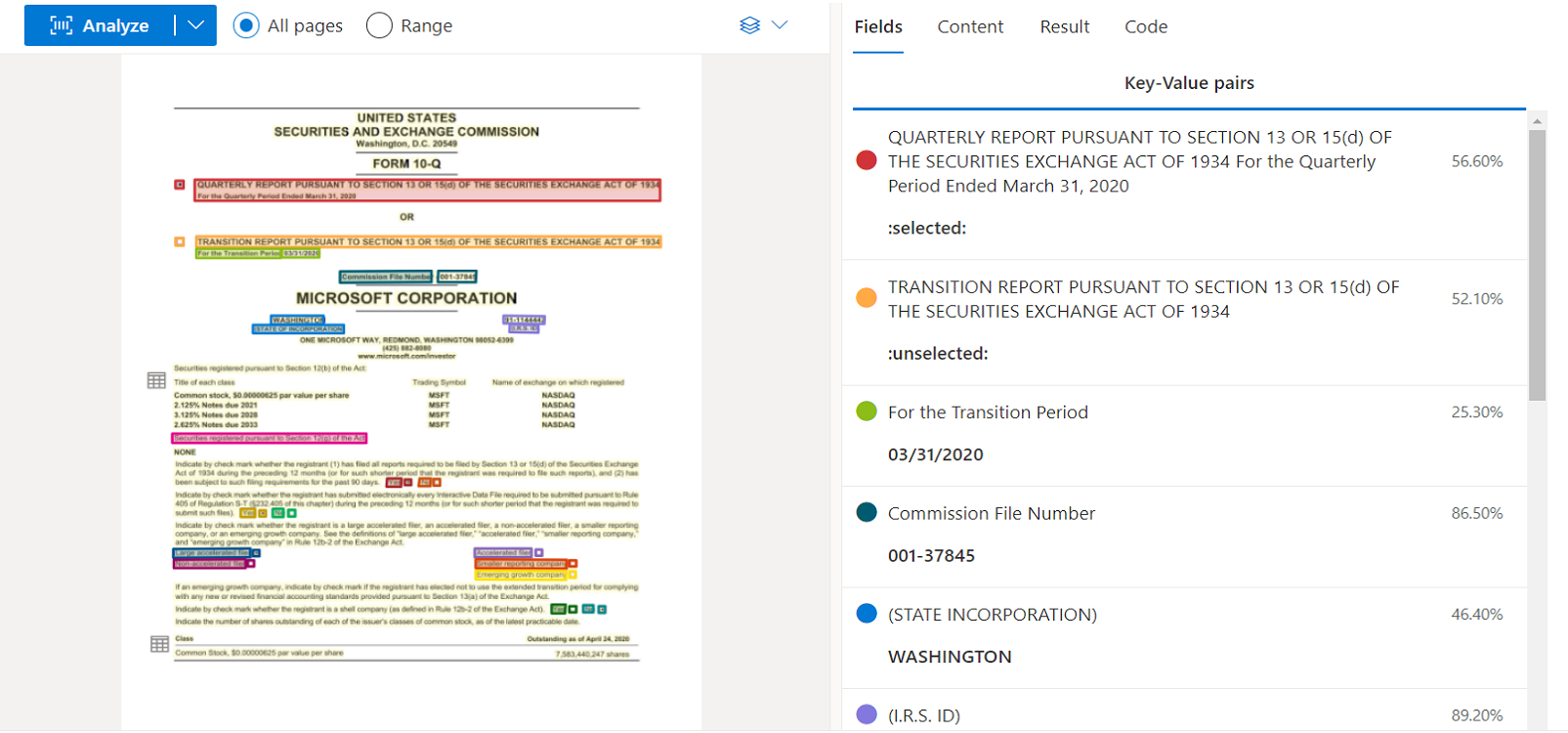
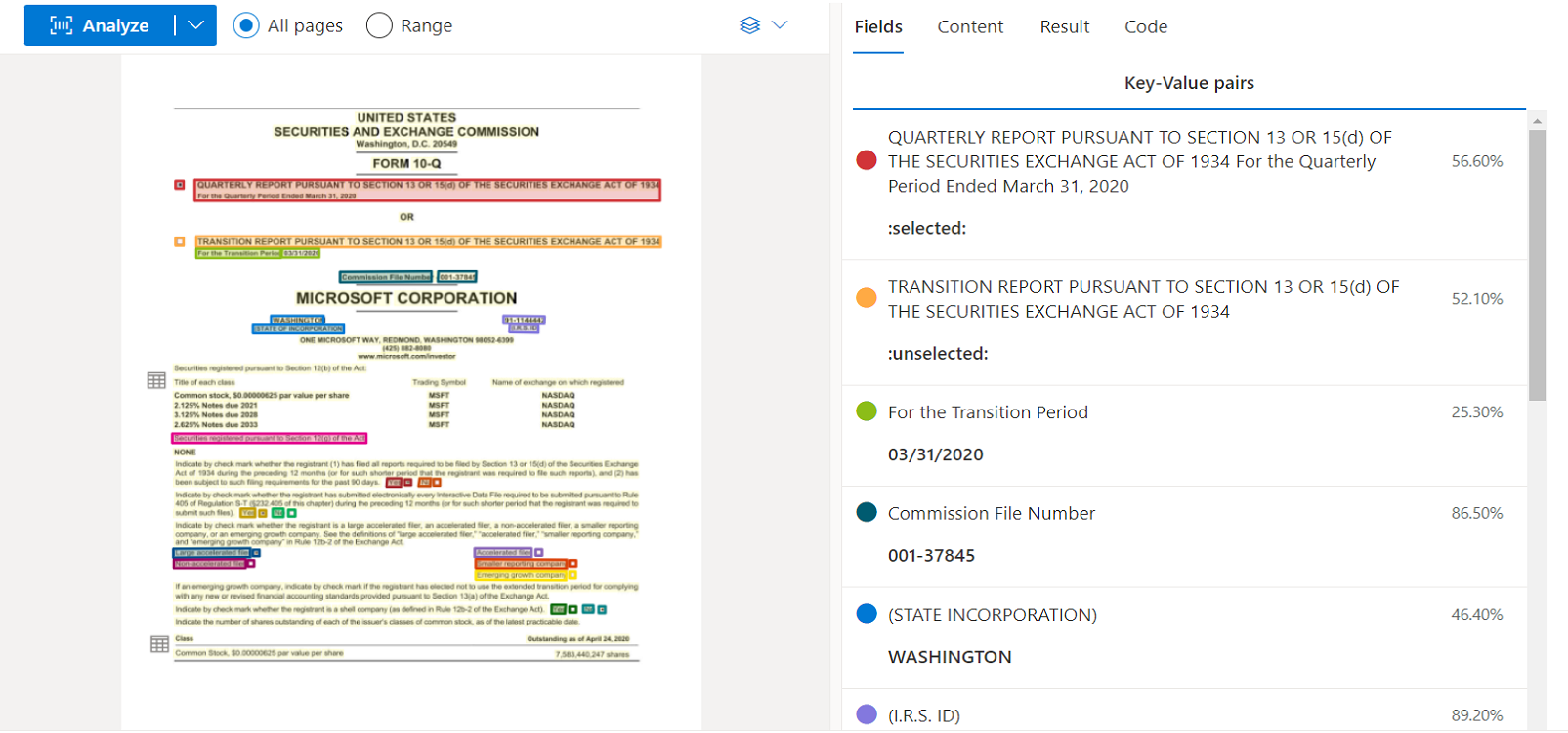
4. Azure AI Document Intelligence
{kind=link}
Azure AI Document Intelligence is part of Microsoft's cloud platform, Azure, which provides over 200 cloud services for businesses. It represents Microsoft's enterprise-focused approach to document processing, offering processing capabilities that run both in the cloud and on your own servers. You can deploy it through containers that suit your specific data storage and processing location requirements.
1. General document analysis (read/layout)
2. Pre-built business document models
3. Custom neural model training
4. Document classification
5. Container-based deployment
6. Azure service integration
7. Built-in validation rules
8. Multi-language support
9. Human review workflows
| Pros of Azure DI | Cons of Azure DI |
|---|---|
| On-premises deployment option | Complex initial configuration |
| Pre-built business models | Requires technical expertise |
| Strong Azure integration | Learning curve for advanced features |
| Custom neural models | Updates can cause disruptions |
| Document classification | Cost management complexity |
| Container support | Documentation gaps |
| Enterprise security | |
| Multiple deployment choices |
Pricing: Pay-as-you-go based on pages processed. Free tier includes 500 pages monthly. Enterprise pricing available for high volumes.
Best suited for: Enterprises across healthcare, finance, and government sectors that need to process documents in the cloud and on their servers.
How does Azure Form Recognizer compare to Amazon Textract?
Parameter | Azure DI | Amazon Textract |
|---|---|---|
Ease of Use | 8.5 | 8.9 |
Ease of Setup | 8.0 | 8.9 |
Quality of Support | 8.5 | 8.6 |
Meets Requirements | 9.0 | 8.8 |
Product Direction (% positive) | 9.2 | 8.2 |
5. Google Cloud Document AI
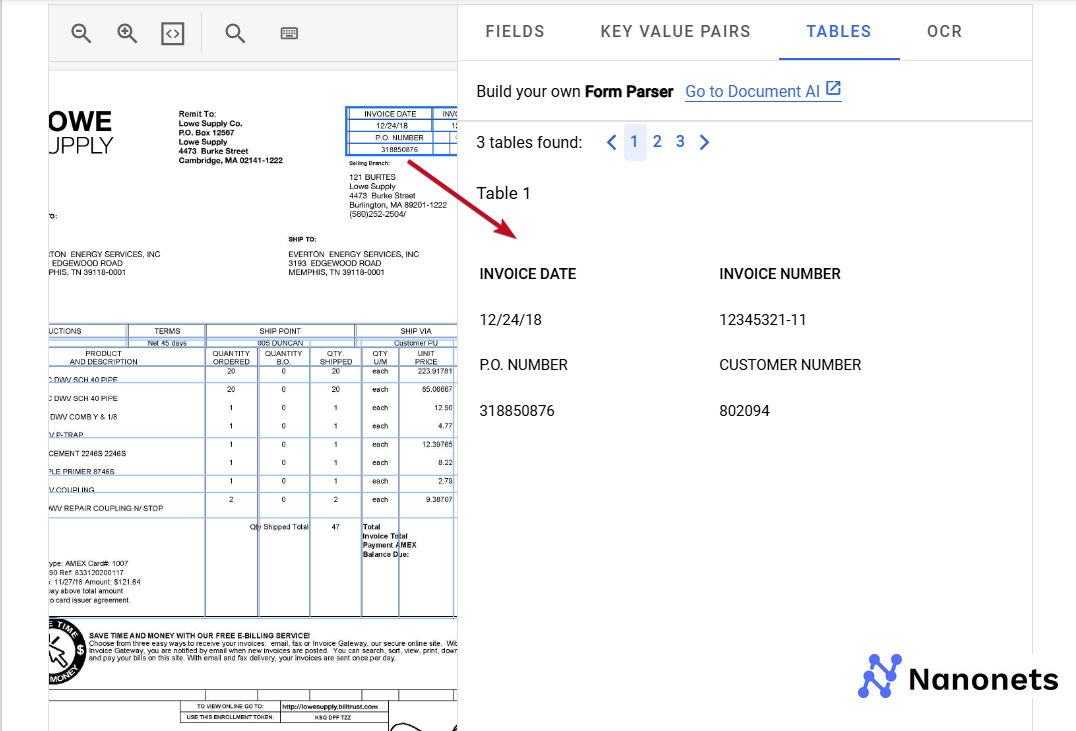
Document AI represents Google's enterprise approach to document processing. Part of the company's cloud division, it combines OCR, natural language processing, and machine learning to transform unstructured documents into actionable data. It provides an end-to-end platform for document processing, analysis, and storage.
1. General document processors (OCR, splitter, parser)
2. Pre-built business processors
3. Document AI Workbench for custom models
4. Document AI Warehouse for storage
5. Human-in-loop review capabilities
6. Integrated processing console
7. Multi-language support
8. Batch processing limitations
9. API-first architecture
| Pros of Document AI | Cons of Document AI |
|---|---|
| Extensive pre-built processors | Limited batch processing |
| Strong ML/AI capabilities | Complex pricing structure |
| Integrated storage solution | Requires technical expertise |
| Human review workflows | Higher learning curve |
| Google Cloud integration | Enterprise-focused pricing |
| Regular model improvements | Documentation gaps |
| Strong OCR accuracy | |
| Flexible deployment |
Pricing: Pay-as-you-go based on document processing volume. Free tier available for testing. Enterprise pricing available for high volumes.
Best suited for: Enterprises processing varied document types at scale, especially those that require complex analysis. If an integration with Google Cloud makes sense to your business.
How does Google Cloud Document AI compare to Amazon Textract?
Parameter | Google Cloud Document AI | Amazon Textract |
|---|---|---|
Ease of Use | 8.7 | 8.9 |
Ease of Setup | 8.5 | 8.9 |
Quality of Support | 8.0 | 8.6 |
Meets Requirements | 8.8 | 8.8 |
Product Direction (% positive) | 9.2 | 8.2 |
6. ABBYY FlexiCapture
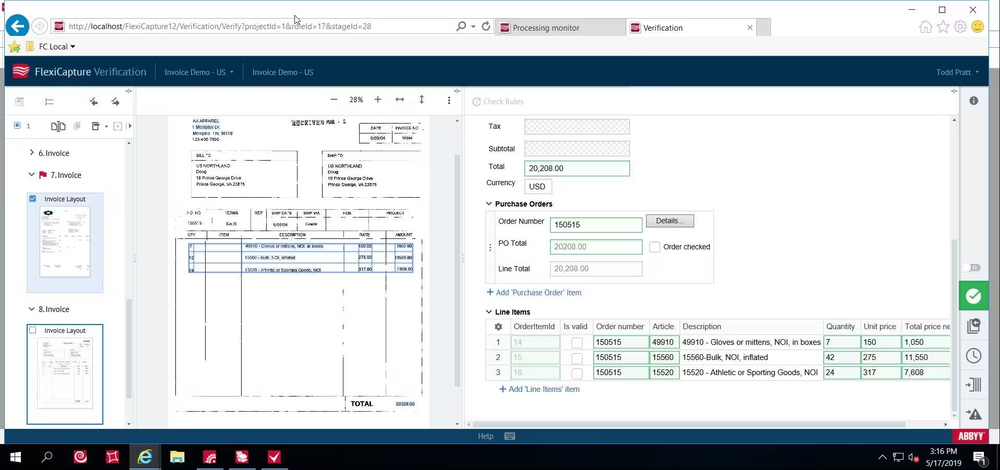
ABBYY FlexiCapture is a powerful intelligent document processing platform that automates the capture, classification, and data extraction from a wide variety of document types and formats. Unlike Textract's cloud-only model, FlexiCapture offers both on-premises and cloud deployment options, making it suitable for organizations with strict data security and compliance requirements.
Read More: ABBYY FlexiCapture Alternatives and Competitors
1. Advanced OCR for structured and unstructured documents
2. AI-based data capture and extraction
3. Intelligent document classification and separation
4. Scalable batch processing for high volumes
5. Customizable business rules and validation
6. Multi-channel input (scanner, email, fax, mobile)
7. Seamless integration with BPM, RPA, and ECM systems
8. Flexible deployment options (on-premises, cloud, hybrid)
9. Multi-language support
| Pros of FlexiCapture | Cons of FlexiCapture |
|---|---|
| Highly accurate data extraction | Complex setup and configuration |
| Handles diverse document formats | Steep learning curve |
| Scalable for high-volume processing | Higher upfront investment |
| Robust integration capabilities | Requires specialized IT skills to maintain |
| Flexible deployment options | |
| Strong compliance and security features |
Pricing: Based on the number of pages processed annually, with the cost per page decreasing as volume increases. On-premises and cloud-based pricing models are available, with on-premises requiring a higher upfront investment but lower ongoing costs. Exact pricing is not publicly disclosed.
Best suited for: Enterprises and organizations with high-volume document processing needs and strict compliance requirements, like healthcare, finance, and government.
How does ABBYY FlexiCapture compare to Amazon Textract?
Parameter | ABBYY FlexiCapture | Amazon Textract |
|---|---|---|
Ease of Use | 8.8 | 8.9 |
Ease of Setup | 8.0 | 8.9 |
Quality of Support | 8.5 | 8.6 |
Meets Requirements | 9.0 | 8.8 |
Product Direction (% positive) | 10.0 | 8.2 |
7. Tungsten Capture (formerly Kofax Capture)
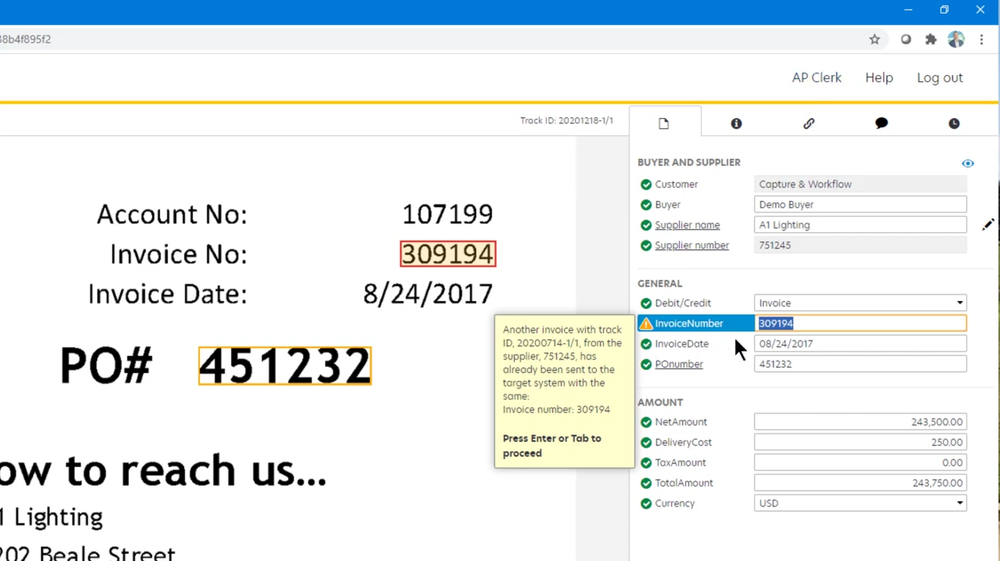
Tungsten Capture is a document scanning and data extraction solution that automates the conversion of paper documents into digital data. It focuses on high-volume document scanning, OCR, and data capture.
Read About: Kofax Alternatives and Competitors
1. Advanced document scanning and image processing
2. Intelligent document separation and classification
3. Automated data extraction using OCR and ICR
4. VRS (VirtualReScan) technology for image enhancement
5. Integration with other Tungsten Modules for advanced data extraction
6. Support for a wide range of scanners and multi-function devices
7. Scalable architecture for high-volume processing
8. Batch processing and workflow automation capabilities
9. Centralized administration and monitoring
| Pros of Tungsten Capture | Cons of Tungsten Capture |
|---|---|
| Highly accurate OCR and data extraction | Complex setup and configuration |
| Handles diverse document types and formats | Steep learning curve |
| Powerful image enhancement with VRS | Higher upfront costs |
| Scalable for high-volume processing | Requires on-premises infrastructure |
| Extensive customization options | Limited out-of-the-box integrations |
| Mature and proven technology | Older user interface design |
Pricing: Pricing is based on the number of pages scanned annually, with volume discounts available. Additional costs may apply for add-on modules, professional services, and maintenance. Exact pricing is not publicly disclosed, but it typically involves a significant upfront investment and ongoing maintenance fees.
Best suited for: Organizations with high-volume, centralized document scanning requirements, such as shared service centers, BPOs, and large enterprises with dedicated scanning departments.
How does Tungsten Capture compare to Amazon Textract?
Parameter | Tungsten Capture | Amazon Textract |
|---|---|---|
Ease of Use | 8.5 | 8.9 |
Ease of Setup | 8.0 | 8.9 |
Quality of Support | 8.7 | 8.6 |
Meets Requirements | 8.8 | 8.8 |
Product Direction (% positive) | 9.0 | 8.2 |
8. Laserfiche
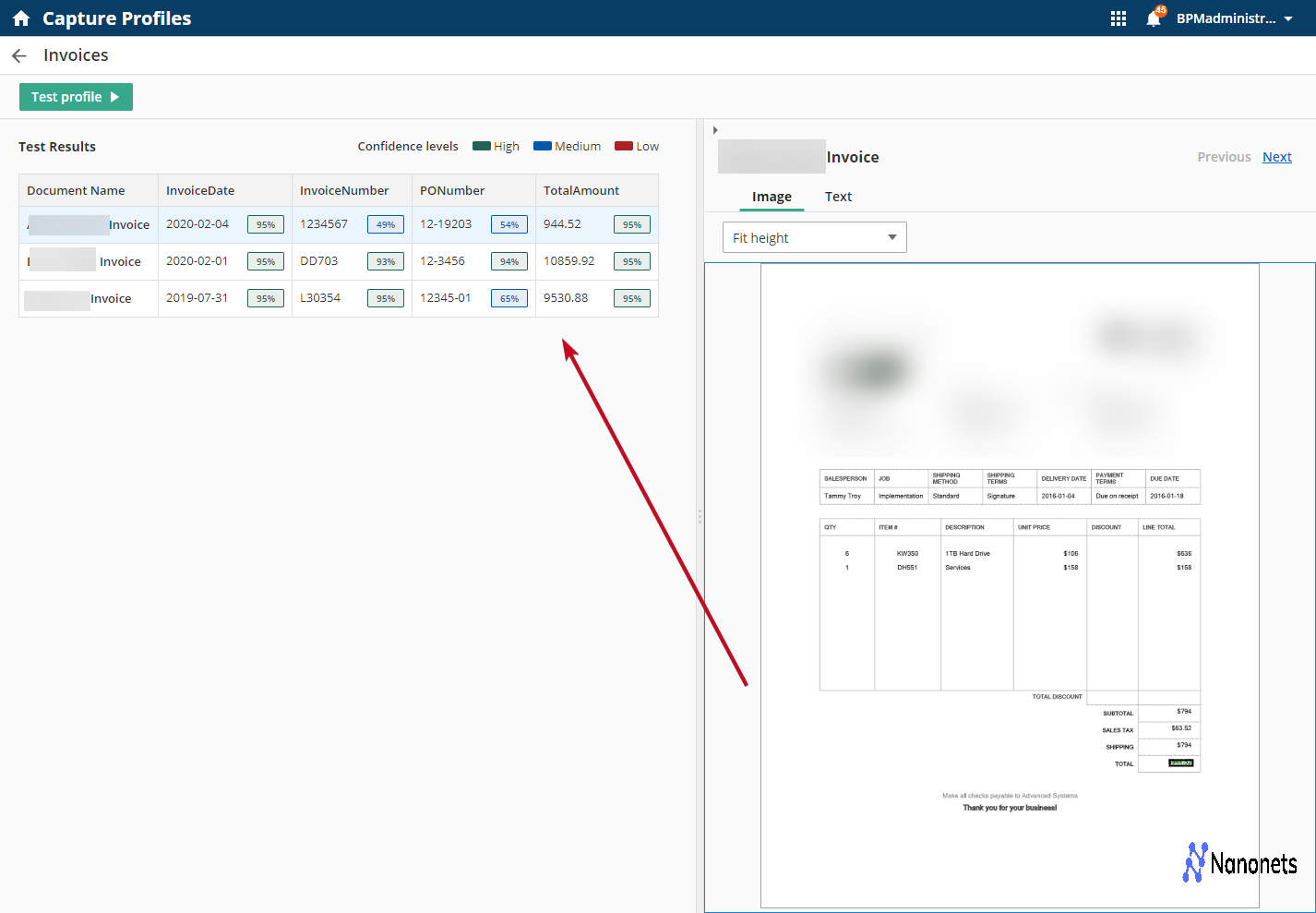
Laserfiche is a comprehensive enterprise content management (ECM) and business process automation platform that includes robust document capture and processing capabilities. It offers an end-to-end solution that combines intelligent document capture, secure storage, workflow automation, and records management.
1. Intelligent document capture and classification
2. Workflow designer for process automation
3. Electronic forms and digital signatures
4. Document management and version control
5. Records management and retention policies
6. Secure document storage and access control
7. Mobile document capture and access
8. Various integration options and APIs
| Pros | Cons |
|---|---|
| Comprehensive content management | Higher upfront costs |
| Powerful workflow automation | Steeper learning curve |
| Strong security and compliance | Requires IT resources to implement and maintain |
| Highly customizable and extensible | May require professional services for complex implementations |
| Scalable for enterprise deployments | |
| Deep integration with business systems |
Pricing: Offers both on-premises and cloud-based deployment options, with pricing based on the number of users and specific modules required. You can get a free trial for its cloud-based solution.
Best suited for: Organizations across industries, particularly those with complex document management and compliance requirements, such as government agencies, educational institutions, financial services firms, and healthcare providers.
How does Laserfiche compare to Amazon Textract?
Parameter | Laserfiche | Amazon Textract |
|---|---|---|
Ease of Use | 8.8 | 8.9 |
Ease of Setup | 8.0 | 8.9 |
Quality of Support | 8.9 | 8.6 |
Meets Requirements | 9.0 | 8.8 |
Product Direction (% positive) | 9.2 | 8.2 |
9. Hyperscience
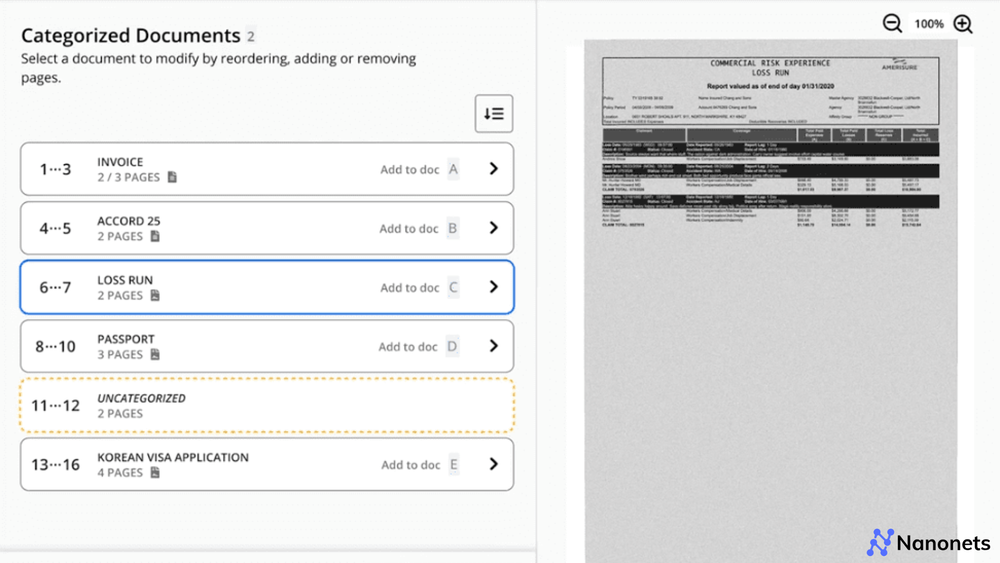
Hyperscience is an intelligent document processing platform that combines AI, ML, and human-in-the-loop workflows to automate data extraction, classification, and validation. It offers an end-to-end solution that handles complex, variable, and low-quality documents with high accuracy and automation rates.
Read About: Hyperscience Alternatives and Competitors
1. AI-powered data extraction and classification
2. Support for structured, semi-structured, and unstructured documents
3. ICR for handwritten text and low-quality images
4. Human-in-the-loop workflows for exception handling and validation
5. Customizable workflows and integration with existing systems
6. Continuous learning and model improvement
7. Secure and compliant infrastructure
| Pros of Hyperscience | Cons of Hyperscience |
|---|---|
| High accuracy and automation rates | Higher cost compared to standalone solutions |
| Handles complex, variable, and low-quality documents | Longer initial setup and configuration |
| Human-in-the-loop workflows for exception handling | May require significant training data for custom models |
| Integration with enterprise systems | |
| Continuous learning and improvement | |
| Dedicated customer success team and support |
Pricing: Offers custom pricing.
Best suited for: Enterprises with complex, high-volume document processing needs, particularly those dealing with variable, unstructured, or low-quality documents. Industries such as financial services, insurance, healthcare, and government may be able to automate claims processing, account opening, and invoice processing, with high accuracy and efficiency.
How does Hyperscience compare to Amazon Textract?
Parameter | Hyperscience | Amazon Textract |
|---|---|---|
Ease of Use | 9.3 | 8.9 |
Ease of Setup | 9.0 | 8.9 |
Quality of Support | 9.1 | 8.6 |
Meets Requirements | 9.1 | 8.8 |
Product Direction (% positive) | 9.8 | 8.2 |
How to choose the best Amazon Textract alternative?
At Nanonets, we process millions of documents monthly for over 500 enterprises, including 35% of Fortune 500 companies. This gives us unique insights into what works (and what doesn't) in document processing. We've seen firsthand how businesses struggle to find the right document processing solution, especially when evaluating Amazon Textract alternatives.
For the purpose of this comparison, we evaluated Textract alternatives based on:
- Real performance data from processing millions of documents
- Direct feedback from enterprise clients who switched platforms
- Independent user reviews from G2, Capterra, Gartner, and TrustRadius
- Hands-on testing by our document processing experts
Scoring methodology*
We've evaluated each alternative across five key parameters that matter most to organizations switching from Textract:
- Ease of use: How quickly teams can start using the tool without extensive AWS expertise
- Ease of setup: Implementation effort, especially compared to Textract's AWS-centric setup
- Quality of support: Availability and responsiveness of support, a common pain point with Textract
- Meets requirements: Ability to handle document processing needs beyond Textract's capabilities
- Product direction: Continuous improvement and feature development pace
| Product | Ease of Use | Ease of Setup | Quality of Support | Meets Requirements | Product Direction | Total Score |
|---|---|---|---|---|---|---|
| Amazon Textract | 8.9 | 8.9 | 8.6 | 8.8 | 8.2 | 43.4 |
| Nanonets | 9.3 | 9.1 | 9.4 | 9.1 | 9.6 | 46.5 |
| Rossum | 8.5 | 8.0 | 9.2 | 8.3 | 9.8 | 43.8 |
| Docparser | 9.0 | 8.8 | 8.9 | 8.7 | 8.5 | 44.0 |
| Azure DI | 8.5 | 8.0 | 8.5 | 9.0 | 9.2 | 43.2 |
| Google Cloud Document AI | 8.7 | 8.5 | 8.0 | 8.8 | 9.2 | 43.2 |
| ABBYY FlexiCapture | 8.8 | 8.0 | 8.5 | 9.0 | 10.0 | 44.3 |
| Tungsten Capture | 8.5 | 8.0 | 8.7 | 8.8 | 9.0 | 43.0 |
| Laserfiche | 8.8 | 8.0 | 8.9 | 9.0 | 9.2 | 43.9 |
| Hyperscience | 9.3 | 9.0 | 9.1 | 9.1 | 9.8 | 46.3 |
Key decision factors
Based on common challenges organizations face with Textract, consider these aspects:
Document complexity requirements
- Do you need better handwriting recognition than Textract offers?
- Are you processing complex tables or forms?
- Do you need to handle multiple languages effectively?
AWS dependency considerations
- How tightly integrated are you with AWS services?
- Would a cloud-agnostic solution offer more flexibility?
- Do you need on-premises deployment options?
Cost structure preferences
- Is Textract's per-page pricing model working for your volume?
- Do you need more predictable pricing?
- What's your monthly document processing volume?
Integration needs
- Beyond AWS services, what systems need to connect?
- Do you need pre-built connectors to common business tools?
- How important is API flexibility?
Automation requirements
- Do you need workflow automation capabilities?
- Is batch processing important for your use case?
- Do you require human-in-the-loop features?
- Feature sets and capabilities may have changed
- Pricing models might differ from what's listed
- Performance metrics could vary based on your specific use case
- Integration options may have expanded
- New features may have been added
We recommend reaching out to vendors directly for the most current information and testing any solution thoroughly with your actual documents before making a decision.
While commercial solutions offer comprehensive features and support, organizations with technical resources or financial constrainst may also consider open-source alternatives for document processing.
Tesseract OCR, maintained by Google, is one of the most established open-source OCR engines available. Another option is EasyOCR, which offers a Python library for OCR with support for handwriting recognition and multiple languages.
However, unlike the commercial alternatives discussed above, open-source solutions typically require significant technical expertise to implement and maintain and often need additional development work to match features like form field extraction, table analysis, and workflow automation that come standard with commercial platforms.
FAQs
What is the difference between ABBYY and Textract?
ABBYY FlexiCapture is a comprehensive document processing platform that includes advanced OCR, workflow automation, and enterprise integration capabilities. It offers both cloud and on-premises deployment options. Amazon Textract, in comparison, is a cloud-only service focused specifically on data extraction and document analysis, integrated with AWS services.
What is the difference between OCR and Textract?
OCR (Optical Character Recognition) is a technology that converts images of text into machine-readable text. Amazon Textract goes beyond basic OCR by using machine learning to not only recognize text but also understand document structure, extract form fields, and analyze tables automatically. While OCR simply converts text, Textract provides structured data output and understanding of document relationships.
What is Textract in AWS?
Amazon Textract is a machine learning service that automatically extracts text, handwriting, and data from scanned documents. It's part of AWS's AI services, designed to process documents at scale without manual intervention. The service can identify and extract data from forms and tables while maintaining the original document's structure and relationships.
Can Textract extract images?
Textract processes images to extract text and data from them, but it doesn't extract images themselves. It can analyze images containing documents, forms, tables, and handwritten text, but its purpose is to extract textual information and data rather than image content.