
Language models have fundamentally changed the way we interact with software now. Starting from simple applications like autocorrect and voice assistants, and taking it all the way to powering some of the world’s most prominent search and recommendation engines, their presence can be felt everywhere. If anyone did take a deeper dive into the underlying technology, the fundamental intuition behind language models is actually simpler to understand than one would expect.
In this article, I want to discuss the capabilities of language models trained on more than one language - or multilingual models. At Nanonets, we make extensive use of such multilingual models, and I wanted to write about a fascinating use case I stumbled upon by accident. A model was trained to extract structured data from Dutch documents, and was trained only on Dutch documents, but when I uploaded a French document, it was still able to extract all the information correctly. How did this happen?
Want to know how we can help you? You can either sign up for free, or schedule a call with us here
What are Language Models?
BERT, GPT-3, their abilities to generate text based comical scripts, and other applications have been all the rage in the last two years. The speed at which the complexity of language models has increased is incredible. Starting with one of the first language models, ELMo in 2018 which had 94 million parameters, today we have massive models like GPT-3, the Megatron - Turing NLG, with 175 billion and 530 billion parameters respectively. But what is a language model?
The technical definition to a language model is a probability distribution over a valid word sequence, but understanding what a language model is, is fairly intuitive. If we give an AI two example sentences, say
- The dog ate food
- The cat ate food
The AI understands that dogs and cats are something that can eat food. How does it learn what it means to eat, or what is food, or what a dog is? We provide similar examples of what happens when the words ate, eat, eaten or food, foodie, dog, puppy etc. appear in a similar fashion. Same goes for other words. Over time, if we provide the AI enough number of examples, overall, the AI becomes capable of understanding the rules to a language - or what we call grammar. It learns what is capable of eating, what it means to shine, what order of words would be grammatically correct, etc. It basically learns what sequence of words is most likely to be valid, or as the technical definition said, probability distribution of valid word sequences. The AI is capable of determining the probability so well, it almost feels like it understands the language, even though it may not explicitly understand the exact rules to it.
How does this thing work? - Word Embeddings
At the heart of AI is the ability to compare the distance between an output with a target response. If the target response was 3, but our answer was 2, we know the distance between them is 1, which we can use to correct the parameters of the model with so it answers questions more accurately. Sure, it is buried below a ton of calculus and non-convex optimization, but the fundamental idea here is to determine distance between our output, the correct answer, and then reduce the distance between them.
In the case of numbers, distance is simple to understand, it is simply the difference between two values. In the case of images, we can translate the image into a matrix of numbers by representing each pixel as intensity value of a given colour. For example, if we consider an image that is only black and white, each pixel is either 0 (for black) or 1 (for white). If we made this grayscale, each pixel could have a value between 0 - 255, with each number describing how gray the image is. If you want a colour image, you just take three such layers, one each for Red, Green, and Blue, or whatever colour scale you’re using. Distance, however, between output image and target image can still be measured as the sum of deviations per pixel.
But how do we compare two sentences? Can you tell me the distance between these two sentences?
With your many years of experience with the english language, you can possibly say that they are similar, but not entirely similar. This doesn’t bode well for a computer though, it needs numbers it can crunch.
In order to be able to compare and contrast sentences, and to derive meaningful relationships between them, we created word embeddings. What are word embeddings? They are basically vector based representations of words. Each word is assigned a vector of fixed dimensions, typically between 150-300, and these vectors are trained such that the distance, deviation etc. operations approximate the rules of language.
So if we were able to train word embeddings correctly, the embeddings for the words king and queen would have the same difference as between the words him and her since within the vector space, their relative positions would be the same. Tensorflow offers a very powerful visualisation tool for seeing how these vectors interact with each other in 3D space. While these vector operations might feel like mathematical sorcery, at the crux of it, it is all very logical. We are assuming that each word in the English language has a certain set of properties that it uses to interact with other words. We might not explicitly know what those are, so we just assign a random numerical value to each (each value of the vector) and try to estimate what these values might be such that if the vectors ever interact with each other, their interactions represent exactly what the language itself would. Turns out, this works exceedingly well.
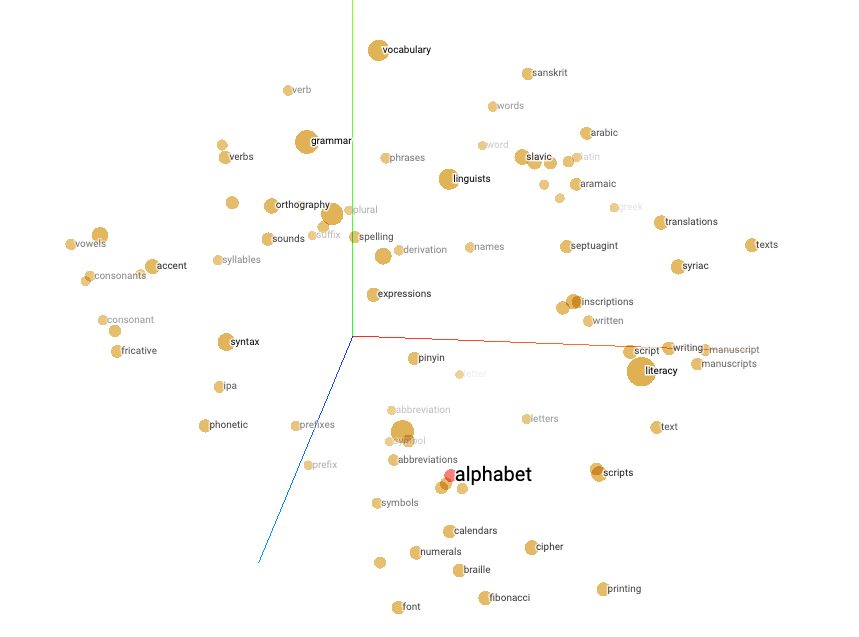
If you want to see for yourself how powerful these word embedding algorithms are, I have written down a Colab for you that uses the SBERT model to detect how similar two sentences are. For the above example in fig 1, it said the sentences were 87.7% similar, and if we want to dive deeper into why this number was found, we can always check the embeddings that the two sentences had.
So what are Multilingual Models?
Multilingual models are simply models that have been trained on more than one language. The noteworthy part about these models is that they capture relationships not only within any one language, but also between multiple languages. For instance, if I were to pass the word dog and the word hund (which is dog in German) to a multilingual model, it would know that the two words mean the same thing in different languages.

This happens because the word embeddings are being trained collectively, so the model doesn’t explicitly discriminate between different languages. It learns the rules to different languages at the same time, and therefore, also the correlations between them.
Obviously, the model also captures relationships between languages in terms of grammar, the above example was a relatively simple one. Even if passed sentences, or entire paragraphs written in different languages, the models are fairly accurately able to gauge how similar they are.
Multi-Lingual Models in Real World Document Processing
In one sentence, Nanonets extracts text based data from images and provides it in a structured format. For example, if you had an image or PDF of an invoice, and you wanted to find out the invoice number and seller address from it, all you need to do is upload it to Nanonets. Our AI based document processing platform will process the invoice, extract the required information, and return the values you need in any desired format, like JSON, CSV, etc.
It’s not a challenge when you have to process a few files each day, but many of our clients deal with more than ten thousand documents each month, and processing this manually is not humanly feasible, or economical. We use some fairly sophisticated deep learning to achieve this.
About a month back, one of our European leads were looking to process documents from across Europe, which meant that there would be several languages for the same data format. I knew for sure that our platform was capable of handling multiple languages, but I had never tried to handle multiple languages with one single model. In the past, we would usually train one model for each language, and that worked perfectly well, but I decided to venture into the unknown, only to find myself rather surprised at the outcome.

Under the hood, Nanonets uses several highly advanced multilingual language models. The text extracted from the various files is processed, and then analysed using these models, and then labels are assigned to different parts of the text based on the relative layout - but none of this is done manually, we have AI agents to achieve this.
We had only trained the model to understand documents written in Dutch, but when we uploaded documents in French that were previously unseen, the model was still able to accurately detect the labels. This was made possible because the multilingual model was able to capture the relationship between the text surrounding the label in both French, as well as Dutch, thereby reducing the need for language specific data and extra training.
This is a giant leap in how we have been doing things so far. Imagine a model that only needs to be trained in any one language, and automatically works for all other languages. It would eliminate the need for redundant annotations, the need for several man-hours worth of labour invested in training people to annotate in different languages, and reduce the barrier of entry for people who do not want to just use a model, and not have to train it over and over again. It just goes on to show that the impact of AI is not limited to theoretical research, but there are real world applications to it.
Limitations of MLMs and future scope
MLMs are still not perfect. They are exceedingly good for a lot of tasks, but on most tasks, unlike their vision based counterparts, they haven’t yet been able to reach human level performance. Tasks like Machine Dialogue Generation (generative chatbots) and Abstractive Summarization still remain active areas of research.
As stated before, MLMs are not deterministic, i.e. they do not have a fixed set of rules they live by, they process a large amount of data, and learn the closest approximation to what could be a real language. Obviously, this means that the model makes assumptions basis the data being provided, which cannot possibly cover the entirety of any language.
With that being said, they have definitely broken a lot of barriers, in particular in machine translation, advanced search engines, and question answering systems. Startups like Viable are using GPT-3 to extract semantic information from customer feedback. Google at one point used its own language model, BERT, to power its search engine - by far the most prominent Google product we have come across. There may be a ways to go, but language models have already come very far ahead.