

This blog examines Amazon's AWS Textract, a fully managed machine learning service that automatically extracts printed text, handwriting, tables, and other data from scanned documents.
We'll speak about our own experience of using Textract, it's pros and cons and usecases.
What is AWS Textract
Amazon Textract is a machine learning (ML) service that automatically extracts text, handwriting, layout elements, and data from scanned documents. It goes beyond simple optical character recognition (OCR) to identify, understand, and extract specific data from documents.
Today, many companies manually extract data from scanned documents such as PDFs, images, tables, and forms or through simple OCR software that requires manual configuration (which often must be updated when the form changes). To overcome these manual and expensive processes, Textract uses ML to read and process any document, accurately extracting text, handwriting, tables, and other data without manual effort.
You can use one of their trained or custom features to quickly automate document processing, whether automating loan processing or extracting information from invoices and receipts. Textract allows you to customize our pre-trained features to meet the document processing needs specific to your business.
Textract can extract the data in minutes instead of hours or days.
Use cases of AWS Textract
General Use cases
Information Extraction on AWS Textract
Not just typed text, AWS Textract also identifies handwritten texts in the documents. This makes information extraction more valuable, as in some cases, handwritten text is more complicated to extract than typed ones. Now let’s see some of the everyday use cases for using Textract:
Read About: Amazon Textract Alternatives for Data Extraction
Robust and Normalised Data Capture
Amazon Textract enables text and tabular data extraction from various documents, such as financial documents, research reports, and medical notes. However, these are not custom-made APIs, but they learn from a vast amount of data every day, and with this continuous learning, extracting unstructured and structured data from your document will be much easier.

Key-Value Pair Extraction
Key-value pair extraction has become a common problem for document processing, but with Amazon Textract, this can be easily solved. We can build pipelines for key-value pair extraction using Textract, which automates document processing, from scanning documents to pushing data to Excel sheets, etc.
Creating an intelligent search index
Amazon Textract enables you to create libraries of text detected in image and PDF files.
Using intelligent text extraction for Natural Language Processing (NLP)
Amazon Textract enables you to extract text into words and lines. It also groups text by table cells if Amazon Textract document table analysis is enabled. Amazon Textract provides you with control over how text is grouped as input for NLP.
We shall discuss some industry-specific use cases across industries and document types of AWS Textract
Industry Use cases
Below are some of the document types across industries that can be processed using AWS Textract:
| Document | Industry | How Textract Can Be Used | Potential Accuracy |
|---|---|---|---|
| Invoices | Accounting, Finance | Automatically extract line items, totals, payment terms, and other key data to streamline accounts payable and receivable processes. | High (90-95%) |
| Contracts | Legal, Business Services | Identify and extract critical clauses, dates, signatures, and other contractual information to aid in contract review and compliance. | Medium (80-90%) |
| Patient Records | Healthcare | Digitize handwritten notes, lab results, and other medical documentation to create structured electronic health records. | Medium (80-90%) |
| Resumes | Human Resources | Parse resumes to screen candidates, extract relevant skills and experience, and populate applicant tracking systems. | High (90-95%) |
| Tax Forms | Tax, Accounting | Automatically fill out tax forms by extracting data from source documents like W-2s and 1099s. | High (90-95%) |
| Loan Applications | Financial Services | Streamline loan processing by extracting applicant information, financial statements, and supporting documents. | Medium (80-90%) |
| Purchase Orders | Supply Chain, Procurement | Automatically capture order details, quantities, and pricing to improve inventory management and procurement workflows. | High (90-95%) |
| Business Reports | Consulting, Analytics | Extract data from tables, charts, and other document components to feed into business intelligence and reporting systems. | Medium (80-90%) |
Limitations of AWS Textract
While powerful, AWS Textract does have some limitations:
Inability to Extract Custom Fields: There could be multiple data fields in a given invoice, such as Invoice ID, Due Date, Transaction Date, etc. These fields are standard in most invoices. But if we want to extract a custom field from an invoice, say, GST number or bank information, Textract needs to do a better job.
Integrations with upstream and downstream providers: Textract allows you to integrate easily with different providers. For example, we'll have to build an RPA pipeline with a third-party service; finding appropriate plugins that suit Textract would be challenging.
Ability to define table headers: Textract doesn't allow you to define table headers for table extraction tasks. Therefore, searching for or finding a particular column or table in a given document would be difficult.
No Fraud Checks: Modern OCRs can now find if a given document is original or fake by validating dates and finding pixelated regions. AWS Textract doesn’t come with this; its only job is to pick all the text from an uploaded document.
No Vertical Text Extraction: Some documents have invoice numbers or addresses in vertical alignment. AWS currently only supports horizontal text extraction with a slight in-plane rotation.
Language Limit: Amazon Textract supports English, Spanish, German, French, Italian, and Portuguese text detection. Amazon Textract will not return the language detected in its output.
Everything’s Cloud: Any document processed with Textract goes into the cloud and only supports a few regions. More information here. However, some companies might not be interested in taking their documents to the cloud for reasons like confidentiality or legal requirements. Still, unfortunately, AWS Textract does not support any on-premise deployment for document processing.
Retraining: If our accuracy is low on information extraction tasks for a set of documents, Textract doesn't allow us to retrain them. To resolve this, we'll have to reinvest in a human review workflow, where an operator must manually verify and annotate wrongly extracted values, which is time-consuming.
How AWS Textract Works?
In this section, we'll discuss how AWS Textract works. We know that strong AI and ML algorithms are behind it; however, there aren't any open-source models to dive into the specifics. However, I'll try to decode the workings by summarising the documentation that can be found here. Let’s get started!
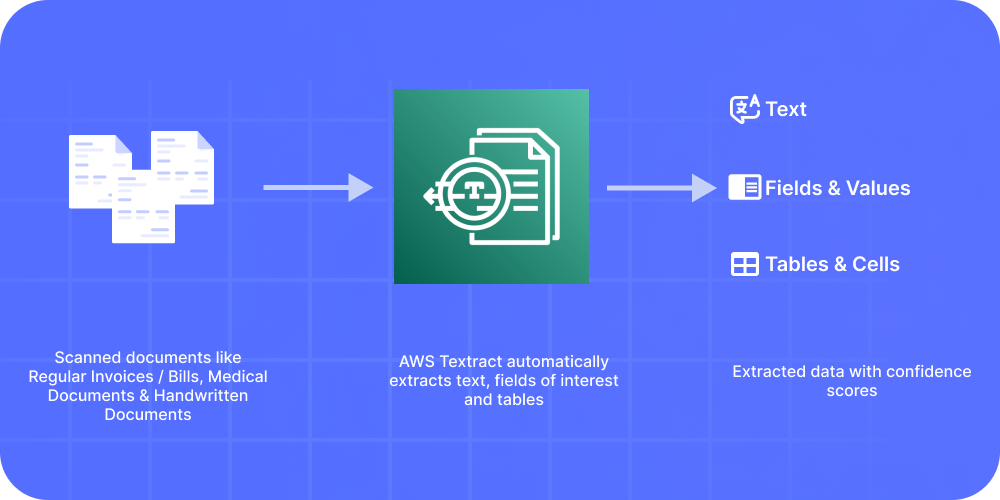
Firstly, whenever a new or scanned document is sent into Textract, it creates a list of block objects for all the detected text. For example, say an invoice consists of a hundred words today, and AWS makes a hundred block objects for all the words in the invoice. These blocks contain information about a detected item, where it's located, and the confidence that Amazon Textract has in the accuracy of the processing.
Usually, most of the documents are made of the following blocks:
- Page
- Lines and words of text
- Form data (Key-value pairs)
- Tables and Cells
- Selection elements
Below is an example and the block data structure of AWS Textract:
{
"Blocks":[
{
"Geometry": {
"BoundingBox": {
"Width": 1.0,
"Top": 0.0,
"Left": 0.0,
"Height": 1.0
},
"Polygon": [
{
"Y": 0.0,
"X": 0.0
},
{
"Y": 0.0,
"X": 1.0
},
{
"Y": 1.0,
"X": 1.0
},
{
"Y": 1.0,
"X": 0.0
}
]
},
"Relationships": [
{
"Type": "CHILD",
"Ids": [
"2602b0a6-20e3-4e6e-9e46-3be57fd0844b",
"82aedd57-187f-43dd-9eb1-4f312ca30042",
"52be1777-53f7-42f6-a7cf-6d09bdc15a30",
"7ca7caa6-00ef-4cda-b1aa-5571dfed1a7c"
]
}
],
"BlockType": "PAGE",
"Id": "8136b2dc-37c1-4300-a9da-6ed8b276ea97"
}.....
],
"DocumentMetadata": {
"Pages": 1
}
}
However, the content inside the blocks changes based on the operation we call. For the text detection operation, the blocks return the pages, lines, and words of detected text. If we’re using the document analysis operations the blocks will return the detected pages, key-value pairs, tables, selection elements, and text.
Pre-requisites of AWS Textract
You need to have an AWS account to access AWS Textract.
If you do not have an AWS account, follow these steps to create one:
- Create Root Credentials - In the Root user email address, enter your email address, edit the AWS account name, and then choose Verify email address. An AWS verification email with a verification code is sent to this address.
- Enter your Root user password and Confirm the root user password, then choose 'Continue.'
- Add Contact Details—Select 'Personal' or 'Business'. Both personal and business accounts have the same features and functions.
- Enter your personal or business information. For business AWS accounts, it's best to enter the company phone number rather than a personal cell phone number. If you configure a root account with an individual email address or personal phone number, your account might be insecure.
- Add Payment Method—$2 or the equivalent in your currency will be charged when you add a credit card to AWS.
- Verify Phone Number—For an added layer of security, you will receive a code on your mobile number.
- Select support tier - You have Free tier to enterprise tier support options.
- Finish Setup & Login
Textract to extract tables from PDF
Extracting tables from PDFs, specifically documents like payslips, bank statements are a recurring use case for businesses. You can accomplish this without any code on AWS
- You can log in to the console and search for AWS Textract.
- AWS Textract will open up.
- They have recently introduced a layout UI for easier extraction and display of extracted details.
- You can upload a PDF
- Textract will analyze and extract details
- Note: Textract UI is limited to 11 pages and 5MB on PDFs. Their APIs have more significant limits.
You can also download results in a CSV file, allowing easier import into sheets, etc., for further analysis.
Textract also has an incredible feature called Queries, which allows you to get questions like “What is the YTD Gross Pay?” and other questions answered based on the document uploaded.
Textract to extract tables from images
AWS Textract has alternative models for expenses, documents, and other everyday use cases. These models improve data extraction accuracy.
The data can be downloaded from the website in CSV and JSON format.
This CSV/JSON can be used by scripts in Python, etc., for further automation and analysis. This is one of the limitations of AWS Textract that it doesn’t facilitate integrations and modification of data.
Textract Python API
Amazon Textract API can be utilized in various programming languages. In this section, we'll look at a code block of key-value extraction using Textract with Python. Check out the docs here for more information on language and API support.
AWS Lambda can trigger code with images and files hosted in S3 buckets.
This code snippet exemplifies how we can perform key-value pair extraction on documents utilizing Textract’s Python API. We must also configure API keys on the AWS dashboard to get this working. Now let’s dive into the code snippet,
Firstly, we import all the necessary packages to push documents to AWS and process the extracted text.
import boto3
import sys
import re
import json
Next, we have a function named get_kv_map. We use boto3 to communicate with the Amazon Textract API, upload the document, and fetch the block response. We now get all the key-value pairs by checking the 'BlockType' and returning them to dictionaries.
def get_kv_map(file_name):
with open(file_name, 'rb') as file:
img_test = file.read()
bytes_test = bytearray(img_test)
print('Image loaded', file_name)
# process using image bytes
client = boto3.client('textract')
response = client.analyze_document(Document={'Bytes': bytes_test}, FeatureTypes=['FORMS'])
# Get the text blocks
blocks=response['Blocks']
# get key and value maps
key_map = {}
value_map = {}
block_map = {}
for block in blocks:
block_id = block['Id']
block_map[block_id] = block
if block['BlockType'] == "KEY_VALUE_SET":
if 'KEY' in block['EntityTypes']:
key_map[block_id] = block
else:
value_map[block_id] = block
return key_map, value_map, block_map
After that, we have a function that uses the block items to get the relationship between the extracted key-value pairs. This function associates the keys and values in the document using the relationships present in the block information (JSON).
def get_kv_relationship(key_map, value_map, block_map):
kvs = {}
for block_id, key_block in key_map.items():
value_block = find_value_block(key_block, value_map)
key = get_text(key_block, block_map)
val = get_text(value_block, block_map)
kvs[key] = val
return kvs
def find_value_block(key_block, value_map):
for relationship in key_block['Relationships']:
if relationship['Type'] == 'VALUE':
for value_id in relationship['Ids']:
value_block = value_map[value_id]
return value_block
Lastly, we return the text present in the saved key-value pairs.
def get_text(result, blocks_map):
text = ''
if 'Relationships' in result:
for relationship in result['Relationships']:
if relationship['Type'] == 'CHILD':
for child_id in relationship['Ids']:
word = blocks_map[child_id]
if word['BlockType'] == 'WORD':
text += word['Text'] + ' '
if word['BlockType'] == 'SELECTION_ELEMENT':
if word['SelectionStatus'] == 'SELECTED':
text += 'X'
return text
def print_kvs(kvs):
for key, value in kvs.items():
print(key, ":", value)
def search_value(kvs, search_key):
for key, value in kvs.items():
if re.search(search_key, key, re.IGNORECASE):
return value
def main(file_name):
key_map, value_map, block_map = get_kv_map(file_name)
# Get Key Value relationship
kvs = get_kv_relationship(key_map, value_map, block_map)
print("\n\n== FOUND KEY : VALUE pairs ===\n")
print_kvs(kvs)
# Start searching a key value
while input('\n Do you want to search a value for a key? (enter "n" for exit) ') != 'n':
search_key = input('\n Enter a search key:')
print('The value is:', search_value(kvs, search_key))
if __name__ == "__main__":
file_name = sys.argv[1]
main(file_name)
This way, we can use the AWS Textract API to perform different information extraction tasks. The functions/approaches are similar to those of most programming languages. We can customize the strategy based on our use cases using the APIs.
Conclusion
We hope this review of AWS Textract has been helpful as you consider different solutions for data extraction/text recognition from your documents.
AWS Textract offers powerful document analysis capabilities, making automating data extraction from various document types easier. While it has some limitations, its ability to understand document structure and extract meaningful data makes it a valuable tool for businesses to streamline their document processing workflows.
As machine learning technologies advance, we can expect AWS Textract to become even more accurate and versatile, further revolutionizing how we interact with and extract value from our documents.
There are reports that AWS Textract is on lights-on mode, with no further developments expected rapidly.
This could also mean, for better and continually improving OCR and related workflows, you could look at solutions like Nanonets
FAQs
How Accurate is AWS Textract?
Textract achieves high accuracy (90-95%) for structured documents like invoices and forms, and medium accuracy (80-90%) for more complex documents like contracts and medical records. The service's ability to maintain document structure helps improve overall accuracy compared to traditional OCR.
How Much Does AWS Textract Cost?
Pricing is based on the number of pages or images processed, with a free tier available. Costs vary depending on the features used, so it's important to consider your document volume and complexity.
How Does AWS Textract Compare to Other Document Processing Solutions?
Compared to traditional OCR, Textract offers more advanced capabilities in understanding document structure and relationships, making it more suitable for complex document processing tasks. It's also tightly integrated with other AWS services.