
You've likely encountered key-value pairs (KVPs) more often than you might realize. In a dictionary, a word is the key and its definition is the value. On an invoice, "Total Amount Due" is the key, and the final figure is the value. This simple, universal structure is everywhere in business, from forms and contracts to patient records and shipping manifests.
The fundamental challenge is that this data is rarely presented in a clean, structured table. Instead, it's often buried in unstructured or semi-structured documents, sometimes with inconsistent layouts or even handwritten entries. Manually extracting this information is an exercise in frustration—a slow, error-prone, and mind-numbing task that makes us question why we're still doing it in the age of AI.
In this guide, we'll explore key-value pair extraction from its wide-ranging applications to cutting-edge techniques. We'll provide an overview of KVP extraction use cases, help you understand traditional methods and their limitations, explore how deep learning is revolutionizing the field, and guide you through building your own extraction system.
Understanding Key-Value Pair Extraction (KVPE)
At its core, a key-value pair is a fundamental data item comprising two intrinsically linked elements: a key and a value. The key serves as a unique identifier or attribute (for example, "Invoice Number"), while the value corresponds to the associated data (for example, "INV-12345"). This pairing is essentially a set of two data items where the value corresponds to the key, and the key is marked as the unique identifier.
Automatically extracting KVPs is crucial for improving the efficiency of business document processing, significantly reducing human labor, and transforming raw, unorganized data into structured formats suitable for analysis, decision-making, and automated processing workflows. Many business documents, such as invoices, contracts, and forms, are inherently semi-structured or unstructured. KVP extraction identifies explicit or implicit relationships between data points within these documents.
By converting these relationships into "key-value" pairs, the unstructured content is given a standardized, machine-readable structure. This structuring is the critical intermediate step that bridges the gap between raw document content and its usability for automated processing, analytics, and integration with other systems. It serves as the foundation of automated data extraction workflows. KVP extraction isn't just about pulling data; it's about imposing order and meaning on chaotic information, making it the bedrock for intelligent automation and data-driven decision-making.
Common applications of KVP extraction
KVPs are ubiquitous across various document types and industries, demonstrating the versatility and applicability of KVP extraction:
- Invoices: Fields like Invoice Number, Date, Total Amounts, Taxes, Vendor Name, and PO Number are extracted as key-value pairs
- Passports: Key-value pairs include Country Code, Date of Birth, Nationality, Passport Number, Issuing Authority, and Gender
- Forms: Information such as Name, Age, University, Shipping Address, and Billing Address are identified and extracted as KVPs
- Medical and insurance documents: Patient IDs, claim numbers, and diagnosis codes are critical KVPs
- Contracts and legal documents: Client names, agreement dates, and key terms are extracted for legal analysis and compliance
A nuanced aspect of modern KVPE systems is their ability to identify keys even when their associated value is absent. For instance, if a "Middle Name" field on a form is left blank, a sophisticated KVPE system can still recognize "Middle Name" as a key, indicating an optional or unprovided field. This capability demonstrates an understanding beyond the mere presence of data, allowing for more complete and accurate data models, even when dealing with incomplete inputs.
| Document Type | Industry | Key Examples | Value Examples |
|---|---|---|---|
| Invoice | Finance | Invoice Number, Date, Total Amount, Vendor Name, PO Number | INV-2024-001, 2024-03-15, $1,250.00, ABC Corp, PO-9988 |
| Passport | Travel | Country Code, Date of Birth, Nationality, Passport Number, Gender | USA, 1985-07-20, American, P1234567, Female |
| Contract | Legal | Client Name, Agreement Date, Effective Date, Termination Clause | John Doe, 2023-10-01, 2023-10-15, "Either party may terminate..." |
| Medical Claim | Healthcare | Patient ID, Claim Number, Diagnosis Code, Service Date | PID-9876, C-54321, ICD-10: R51, 2024-01-20 |
| Purchase Order | Procurement | PO Number, Item Description, Quantity, Unit Price, Delivery Date | PO-9988, Laptop Computer, 10, $800.00, 2024-04-01 |
| Bank Statement | Finance | Account Number, Statement Date, Opening Balance, Transaction Date, Amount | 123456789, 2024-02-29, $5,000.00, 2024-02-28, -$50.00 |
How KVP Extraction works
Key-Value Pair (KVP) extraction typically involves a sophisticated combination of Optical Character Recognition (OCR), Natural Language Processing (NLP), and Computer Vision techniques. The process is multi-staged and highly refined:
- Preprocessing: Documents are first cleaned and enhanced to improve recognition accuracy. This includes tasks such as noise reduction, skew correction, and contrast enhancement, which are essential for handling noisy or low-quality scans.
- Text extraction (OCR): Once preprocessed, OCR technology converts scanned images or PDFs into machine-readable text. Modern OCR systems utilize advanced machine learning and deep learning techniques to achieve highly accurate text conversion.
- Key-Value detection: This is the core of KVP extraction, where AI-based methods identify the linked pairs. Advanced AI models, including those leveraging deep learning, are trained to understand the visual layout and semantic relationships within documents. They can identify where a "key" (like "Invoice Number") is located and accurately link it to its "value" (like "INV-12345"), even if the document's layout changes from one vendor to another. This shift to contextual intelligence makes solutions far more robust and scalable, capable of handling the vast diversity of real-world documents without constant manual re-templating. Techniques like Named-Entity Recognition (NER) help classify entities (e.g., a person's name, address) in unstructured text, while object detection uses bounding boxes to interpret document layouts and extract specific details.
- Data structuring: Once identified, the extracted key-value pairs are stored in a structured format, such as JSON or CSV. This structured output is critical for seamless integration with downstream systems and automation workflows.
- Post-processing validation: A comprehensive pipeline is often integrated to validate and refine the extracted information, ensuring accuracy and consistency before the data is utilized.
The challenges of manual document processing
Understanding the challenges posed by manual document processing offers a strong rationale for adopting advanced intelligent document processing (IDP) solutions, particularly those focused on KVPE.
a. Operational and financial drain
Manual document processing is a significant drain on operational efficiency and financial resources:
- High costs and time consumption: Manual invoice processing costs $15-$40 per invoice and takes days to weeks, consuming significant employee time. Labor costs constitute 60-80% of these expenses.
- Human errors: Manual data entry has a 1-4% error rate (100-400 errors per 10,000 entries), leading to typos, incorrect amounts, and duplicate invoices. Correcting each error can cost up to $53.
- Workforce burnout: Repetitive tasks lead to employee disengagement and turnover, hindering focus on strategic work.
- Lack of standardization: Manual methods result in inconsistent formatting and high risk of data duplication.
b. Technical hurdles
Beyond the human element, data extraction projects frequently encounter significant technical challenges:
- Data quality issues: Raw data often has missing values, inaccuracies, and inconsistencies, leading to flawed analysis. Data duplication inflates metrics.
- API rate limits and performance: High API call volumes can impact application responsiveness and cause throttling. Large data volumes lead to performance degradation and scalability issues.
- Integration difficulties: Ensuring compatibility and synchronization across disparate systems (CRMs, ERPs, cloud storage) is complex, leading to data inconsistencies.
- Unstructured data complexity: Extracting information from free-form text and images is difficult without advanced NLP and image processing.
c. Legal and compliance complexities
Handling sensitive data within document processing workflows requires careful management:
- Data privacy risks: Non-compliance with regulations like GDPR (Europe), CCPA (US), and HIPAA (US healthcare) can lead to significant penalties and reputational damage.
- Fraud vulnerability: Manual processes lack built-in security, increasing risk of fake invoices, duplicate payments, and unauthorized transactions.
- Regulatory hurdles: Procurement faces strict tax laws and compliance standards; misaligned automation tools risk penalties.
d. Sector-specific pain points
Legal and Contracts:
- Complex language and variability: Manual review is tedious, error-prone, and struggles with varied contract templates, leading to missed obligations and delays.
- Contextual misunderstanding: Different sections and draft versions can lead to information being taken out of context.
- Inefficient workflows: Manual review increases turnaround time and sales cycles, costing businesses millions.
- Lack of visibility and tracking: Contracts scattered across various tools make locating the latest version and tracking obligations difficult.
Procurement:
- Resistance to change: Employees resist automation due to fear of job loss or new workflows; 70% of digital transformations fail due to this resistance.
- System integration issues: Procurement leaders often cite integration as a top challenge, leading to data mismatches and workflow disruptions..
- Poor data quality: Outdated or inconsistent records cost businesses an average of $12.9 million annually.
- Lack of customization: One-size-fits-all tools slow down operations; professionals often find inflexible software detrimental.
How Deep Learning revolutionizes KVPE
Deep learning represents one of the most significant advances in machine learning in recent decades. Unlike traditional computer science approaches, where we design systems with explicit rules, deep learning relies on neural networks that learn patterns from input-output examples and can generalize to unseen data.

Understanding Neural Networks
At the heart of deep learning lies the neural network—a complex web of interconnected nodes inspired by the biological function of the human brain. The network consists of multiple layers:
- Input layer: This is where your document enters the system. Whether it's a scanned invoice, a handwritten form, or a digital PDF, the input layer processes the raw data
- Hidden layers: These are the brain's powerhouse. Multiple layers work together to identify features, recognize patterns, and make sense of the document's structure
- Output layer: This is where the extraction happens. The system produces the extracted key-value pairs, neatly organized and ready for use
As GPU capabilities and memory capacity have dramatically advanced, deep learning has become the preferred strategy for computer vision tasks. One of the most important neural network architectures used today is the Convolutional Neural Network (CNN). CNNs use convolutional kernels that slide through images to extract features, often accompanied by traditional network layers to perform tasks such as image classification or object detection.
Modern OCR with Deep Learning
Recent OCR techniques have incorporated deep learning models to achieve higher accuracy. The Tesseract OCR engine, maintained by Google, is a prime example of utilizing Long Short-Term Memory (LSTM) networks.
What is LSTM?
An LSTM is a particular family of neural networks applied primarily to sequence inputs. Here's why it's transformative for key-value pair extraction:
- Sequential Data Processing: LSTMs excel at handling sequential data, reading documents the way humans would—understanding context and predicting what might come next
- Context Awareness: In OCR, previously detected letters help predict subsequent ones. For example, if "D" and "o" are detected, "g" is more likely to follow than "y"
Tesseract's modern architecture
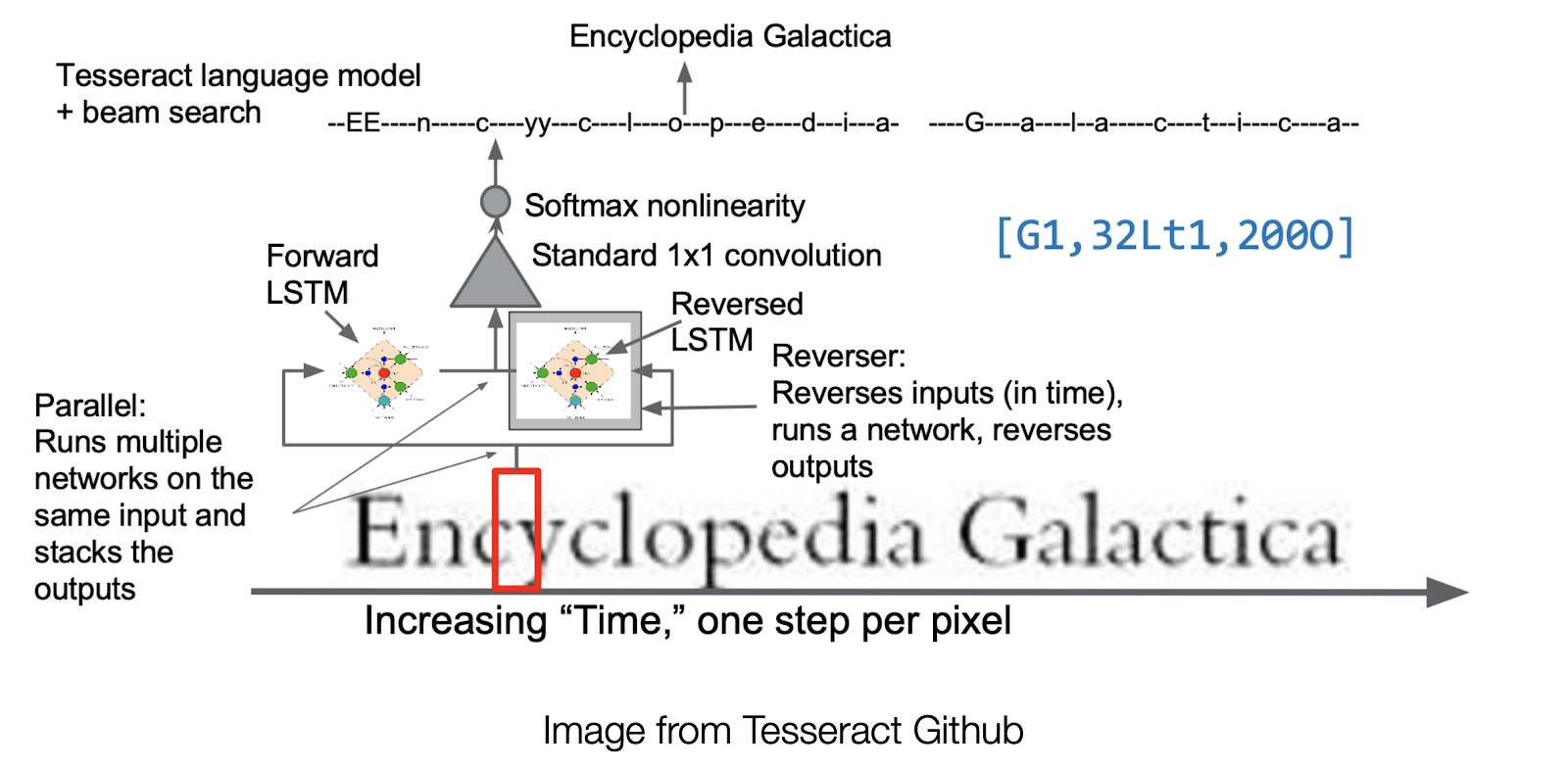
The current Tesseract engine (version 5.5.0 as of November 2024) employs a sophisticated architecture where image patches are processed through both forward and backward LSTM networks, followed by convolutional layers for final character recognition. This bidirectional approach significantly improves accuracy by considering both past and future context when recognizing each character.
The improved architecture increases the accuracy and robustness of OCR, making it easier to convert multiple different types of texts into structured, electronic documents. These machine-readable outputs are much easier to organize for subsequent KVP extraction.
Advanced document understanding
Beyond traditional OCR improvements, deep learning has enabled entirely new approaches to document understanding. Modern systems can recognize not just text, but also document structure, layout patterns, and semantic relationships between different document elements.
These systems attempt to tackle the ongoing problem of insufficient information retrieval when extracting only words and text by also identifying visual entities such as lines, tables, and boxes within scanned documents. Advanced preprocessing techniques include:
- Image denoising: Generative adversarial networks (GANs) generate clean versions of noisy input images
- Document classification: Convolutional Siamese networks classify documents into templates by computing similarity scores
- Handwritten text recognition: Encoder-decoder architectures map handwritten text into character sequences
Modern document AI systems can detect comprehensive sets of entities from images, including page lines, text blocks, lines within text blocks, and various types of boxes and form fields. This multi-level understanding enables more accurate and complete KVP extraction.
Building your own KVP extraction system
Let's apply our theoretical knowledge to a practical problem. We'll focus on extracting company, address, and price fields from invoices—a common yet challenging scenario for businesses of all sizes.
Required libraries and setup
To perform KVP extraction, we need an OCR library and image processing capabilities. We'll use OpenCV for image processing and PyTesseract as a wrapper for the Google Tesseract engine.
pip install opencv-python pytesseract tensorflow pandas numpy
import cv2
import pytesseract
import pandas as pd
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense, Embedding
import re
import json
Image preprocessing pipeline
def preprocess_image(image_path):
"""
Preprocess image for optimal text extraction
"""
# Read the image
image = cv2.imread(image_path)
# Convert to grayscale
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# Apply dilation and erosion to remove noise
kernel = np.ones((1, 1), np.uint8)
image = cv2.dilate(gray, kernel, iterations=1)
image = cv2.erode(image, kernel, iterations=1)
# Apply blur to smooth the image
image = cv2.medianBlur(image, 3)
# Threshold the image
_, thresh = cv2.threshold(image, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
return thresh
def extract_text_with_coordinates(image):
"""
Extract text along with bounding box coordinates
"""
# Use pytesseract to get detailed information
data = pytesseract.image_to_data(image, output_type=pytesseract.Output.DICT)
text_blocks = []
for i in range(len(data['text'])):
if int(data['conf'][i]) > 60: # Filter low confidence text
text_blocks.append({
'text': data['text'][i],
'left': data['left'][i],
'top': data['top'][i],
'width': data['width'][i],
'height': data['height'][i],
'confidence': data['conf'][i]
})
return text_blocks
LSTM-Based KVP Extraction Model
class KVPExtractor:
def __init__(self):
self.model = None
self.label_encoder = {
'company': 0,
'address': 1,
'total': 2,
'date': 3,
'other': 4
}
self.reverse_encoder = {v: k for k, v in self.label_encoder.items()}
def build_model(self, vocab_size, max_length):
"""
Build LSTM model for sequence classification
"""
model = Sequential([
Embedding(vocab_size, 128, input_length=max_length),
LSTM(128, return_sequences=True),
LSTM(64),
Dense(32, activation='relu'),
Dense(len(self.label_encoder), activation='softmax')
])
model.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
self.model = model
return model
def extract_kvp_from_text(self, text_blocks):
"""
Extract key-value pairs from text blocks using pattern matching and ML
"""
extracted_kvps = {}
# Combine all text
full_text = ' '.join([block['text'] for block in text_blocks])
# Pattern-based extraction for common fields
patterns = {
'total': r'(?:total|amount due|grand total)[\s:$]*([0-9,]+\.?[0-9]*)',
'date': r'(?:date|invoice date)[\s:]*([0-9]{1,2}[/-][0-9]{1,2}[/-][0-9]{2,4})',
'company': r'^([A-Za-z\s&,.]+)(?=\n|\r|$)',
'address': r'([0-9]+\s+[A-Za-z\s,]+[A-Za-z]{2}\s+[0-9]{5})'
}
for key, pattern in patterns.items():
match = re.search(pattern, full_text, re.IGNORECASE | re.MULTILINE)
if match:
extracted_kvps[key] = match.group(1).strip()
return extracted_kvps
def process_invoice(image_path):
"""
Complete pipeline for invoice processing
"""
# Preprocess image
processed_image = preprocess_image(image_path)
# Extract text with coordinates
text_blocks = extract_text_with_coordinates(processed_image)
# Initialize KVP extractor
extractor = KVPExtractor()
# Extract key-value pairs
kvps = extractor.extract_kvp_from_text(text_blocks)
return kvps
# Example usage
if __name__ == "__main__":
invoice_path = "sample_invoice.jpg"
extracted_data = process_invoice(invoice_path)
print("Extracted Key-Value Pairs:")
for key, value in extracted_data.items():
print(f"{key.title()}: {value}")
This implementation provides a foundation that you can extend with more sophisticated pattern matching, better ML models, and training on your specific document types.
How AI and LLMs are transforming KVP extraction
Generative AI, particularly Large Language Models (LLMs), has revolutionized KVPE. These advanced AI systems can extract and classify information with remarkable accuracy, often "out-of-the-box" without extensive prior training. This means faster setup and lower costs for businesses while learning to adapt to diverse document layouts with high precision.
Multimodal capabilities
Multimodal LLMs, such as Google's Gemini 2.5 Pro and OpenAI's GPT-5 (released August 2025), represent a significant leap forward. They can process a wide variety of inputs, including text, images, and even video, as prompts. This enables them to understand the full document context, similar to how humans read documents, rather than just isolated pieces of it.
This capability allows for complex reasoning across different data types and significantly simplifies the developer experience by relying on prompts rather than complex fine-tuning. The shift toward end-to-end multimodal processing is gradually replacing traditional OCR + transformer pipelines in many enterprise applications.
Modern KVP extraction approaches
A modern KVP extraction engine goes beyond simply reading text; it understands context, layout, and semantic relationships. These systems are built on deep learning architectures that examine entire documents holistically, considering layout, font sizes, spatial relationships, and subtle visual cues.
When considering an AI-powered solution, look for platforms that offer a variety of model types:
- Pre-trained Models: Ready-to-use for common documents like invoices and receipts, trained on millions of files to extract key information instantly.
- Custom Models: Allow you to teach the AI to recognize and label any piece of information from any document, even unique document types or different languages.
- Zero-shot Models: Intelligent enough to extract data with no initial training, relying on clear, effective descriptions or prompts for each label.
- Instant Learning Models: Learn from every correction you make, rapidly adjusting to new data and feedback without waiting for full re-training cycles.
The core components of modern IDP
Modern intelligent document processing systems integrate various advanced technologies, combining OCR, computer vision, NLP, and machine learning to automate document data processing. The typical process flow involves:
- Document ingestion: Documents are ingested in various formats (images, scanned PDFs, digital documents).
- OCR and data extraction: OCR extracts text while IDP systems understand context, layout, and semantics to identify key data elements.
- Key-Value Pair identification and structuring: Advanced algorithms precisely identify and link keys with their corresponding values, structuring output into machine-readable formats.
- Learning and adaptation: The system continuously refines its understanding of document types and data extraction patterns.
- Integration with business processes: Extracted data is seamlessly integrated into existing business processes and applications.
This level of adaptability is what allowed PayGround to cut their medical bill processing time from 3 minutes to just 10 seconds, enabling a successful marketing campaign and a better customer experience.
~ Dennis Elder, Director of Product at PayGround
Best practices and optimization techniques
Implementing an effective key-value pair extraction system requires optimizing for accuracy, efficiency, and scalability:
Data preparation
- Clean your images: Remove noise, correct skew, and enhance contrast before processing
- Standardize formats: Convert all documents to consistent formats to improve processing reliability
- Quality validation: Implement pre-processing quality checks to identify problematic documents early
Model optimization
- Create custom dictionaries: Build lists of expected keys for specific document types to improve recognition
- Use regular expressions: Design patterns to catch common value formats (dates, currency, phone numbers)
- Implement validation rules: Set up checks to ensure extracted values make logical sense
System performance
- Parallel processing: Distribute extraction tasks across multiple cores or machines
- Implement caching: Store frequently accessed data to reduce processing time
- Load balancing: Distribute workload across multiple processing instances
Continuous improvement
- Feedback loops: Allow users to correct errors, feeding this data back into your system
- Regular model updates: Retrain on new data to improve accuracy over time
- A/B Testing: Test different extraction approaches to optimize performance
Security and compliance
- Encrypt sensitive data: Protect extracted information, especially when dealing with personal or financial details
- Implement access controls: Ensure only authorized personnel can access extracted data
- Audit trails: Maintain logs of extraction activities for compliance and debugging
Practical steps for implementing automated workflows with KVPE
Implementing AI-driven KVPE might sound daunting, but with platforms like Nanonets, we've made it remarkably straightforward. We understand you're tired of hassles, and we've engineered our solution to be the reliable workhorse you need. Our intuitive, no-code platform allows you to:
- Define your needs: Easily identify the key-value pairs you need to extract from your specific documents (invoices, contracts, forms, etc.).
- Upload and train (or use pre-trained!): Simply upload sample documents. For common types, our pre-trained models are ready to go. For unique documents, our no-code retraining feature lets you quickly teach the AI by annotating directly on the dashboard – no coding required.
- Automate your workflow: Set up triggers (e.g., new email attachment) and actions (e.g., extract data, validate, send to ERP). Nanonets handles the heavy lifting, ensuring data flows seamlessly into your existing systems.
- Monitor and refine: Our platform provides insights into extraction accuracy, allowing for continuous improvement with minimal effort.
This streamlined approach enables you to automate complex document processing without being hindered by technical complexities.
KVP extraction FAQs
1. What exactly is a key-value pair in document processing?
A key-value pair (KVP) is a fundamental data structure consisting of two linked elements: a unique identifier (the key) and its associated information (the value). Think of it like a label and its content—on an invoice, "Invoice Number" is the key and "INV-12345" is the value; on a passport, "Date of Birth" is the key and "1985-07-20" is the value. This structure is universal across business documents, forms, contracts, and government documents, making it the foundation for organizing and extracting meaningful information from unstructured text.
2. What accuracy can I expect from KVP extraction systems?
Accuracy varies significantly based on document quality and complexity: high-quality structured documents achieve 95-99% accuracy with modern AI-powered systems, semi-structured documents reach 85-95%, while poor quality scans or handwritten text typically achieve 60-85% accuracy. Key factors affecting accuracy include image resolution (300+ DPI recommended), document contrast, font clarity, and whether the system has been trained on similar document types. Most enterprise implementations aim for 90%+ accuracy on their primary document types through proper system selection and training.
3. What are the typical cost savings from implementing KVP extraction?
Organizations typically see substantial ROI with 80-95% faster processing than manual entry, reducing cost per document from $15-40 to $1-3 through automation. Manual data entry error rates drop from 1-4% to 0.1-0.5% with AI systems, while processing volume can increase 10-100x with the same resources. Companies report saving thousands of employee hours annually—for example, some organizations reduce processing time from 3 minutes to 10 seconds per document, allowing staff to focus on higher-value strategic tasks instead of repetitive data entry.
4. How is key-value pair extraction different from regular OCR?
Traditional OCR simply converts text in images to digital text without understanding relationships, while KVP extraction goes several steps further by understanding context, identifying relationships between keys and values, performing semantic analysis to recognize data types (dates, currency, names), and organizing information into structured, machine-readable formats like JSON or CSV. Modern AI-powered KVP systems use machine learning to adapt to document variations and handle multiple document types without requiring templates, whereas traditional OCR relies on rigid rules and struggles with format changes.
5. How long does it take to implement a KVP extraction system?
Implementation timelines depend on complexity: pre-built solutions typically require 2-6 weeks for basic setup and integration, custom solutions need 3-6 months for development and training, while enterprise implementations take 6-12 months including full integration, training, and rollout. Proof-of-concept projects can be completed in 1-2 weeks to validate feasibility. Factors affecting timeline include document variety, integration requirements with existing systems, data volume needed for training, and organizational readiness for change management.
6. What are the most common implementation challenges?
The most frequent challenges include data quality issues (poor scan quality, inconsistent formats, missing information), integration complexity with existing ERP and CRM systems, change management hurdles involving user adoption and workflow changes, balancing automation rates with acceptable error levels, and ensuring scalability for volume growth and new document types. Organizations also commonly struggle with setting realistic accuracy expectations and managing the transition from manual processes, requiring careful planning for staff training and workflow redesign.
7. What happens when the system makes extraction errors?
Modern KVP systems include comprehensive error-handling through confidence scoring (each extraction receives a 0-100% confidence level), human-in-the-loop validation that flags low-confidence extractions for manual review, exception handling for unexpected formats, continuous learning from corrections to improve future accuracy, and validation rules that check business logic (ensuring dates are valid, currencies properly formatted). This multi-layered approach ensures that errors are caught and corrected while the system learns from mistakes to prevent similar issues in the future.
8. How do modern AI systems handle handwritten documents?
Modern systems use advanced deep learning models specifically trained for handwriting recognition, achieving 95%+ accuracy with printed text, 70-85% with clear handwriting, and 40-70% with poor handwriting that often requires human verification. These systems can differentiate between printed and handwritten sections within the same document and apply appropriate recognition techniques. Best practices for handwritten documents include using high-contrast ink (black on white), ensuring clear writing, scanning at 300+ DPI resolution, and implementing human review workflows for low-confidence extractions.
9. What should I look for when selecting a KVP extraction vendor?
Key evaluation criteria include accuracy performance tested with your specific document types, scalability to handle current and projected volumes, integration capabilities through APIs and connectors for existing systems, vendor expertise in your industry and use cases, security certifications relevant to your compliance requirements, transparent pricing that scales with usage, and a strong technology roadmap showing investment in AI advancement. Additionally, evaluate training and support quality, implementation timeline commitments, and the vendor's track record with similar organizations in your industry.
10. How can I evaluate if KVP extraction is right for my organization?
Consider document volume (processing 50+ documents monthly typically justifies automation), current processing costs versus automation costs, error tolerance for critical processes, document complexity (structured documents are easier to automate), and growth trajectory for future volume increases. Calculate your baseline by documenting current labor costs, processing time, and error rates, then compare against vendor projections. Most vendors offer pilot programs or proof-of-concept trials to test effectiveness with your specific documents before making a full commitment, allowing you to validate ROI assumptions with real data.