
The struggle to copy content from a PDF file is real. Whether you're trying to extract a table, text, or an image, you think you've got it all, hit copy, and then when you try to paste it, you find that only half made it, or the formatting is messed up. Frustrating, right?
With the right tools and techniques, copy-pasting can be easy. This quick guide will walk you through different methods for copying and pasting text, images, tables, and other data from PDF files while retaining formatting.
 →
→

PDF → Excel in seconds!
▼
PDF → Excel in seconds!
Extract any data field from PDFs and auto-populate them to Excel with ease.
1. Copy and paste text from PDFs
You may need to copy text from PDFs for academic purposes, content creation, legal reasons, or simply for reference. Let’s look at a few ways you can copy text from structured or unstructured PDFs:
a. Use Adobe Acrobat Reader’s Select tool
Adobe Acrobat Reader is one of the most popular PDF viewers available. If you don’t want to install additional software or sign up for something new, use Acrobat Reader’s built-in text selection tool.
Follow these steps to get started:
- Open your PDF in Adobe Acrobat Reader.
- Click the "Select Tool" button (arrow icon) in the toolbar to highlight text in the PDF.
- Click and drag to select the text. You can choose across multiple pages if necessary.
- Highlight the text, right-click, select "Copy", or use Ctrl+C on Windows or Command+C on Mac.
- Paste the text using Ctrl+V or Cmd+V.
This method is ideal for simple PDFs. You can manually copy the content in segments and paste it into your target document. Acrobat Reader preserves the formatting well, unlike other readers.
Acrobat Reader struggles with complex PDFs — those with multiple columns and images mixed with text, tables, and text on colored backgrounds. The copied text may lose formatting and be pasted as plain text, requiring manual cleanup or editing later.
It may not be ideal for bulk text extraction from PDFs. For instance, processing vendor contracts and extracting key terms and clauses from hundreds of PDFs can be tedious and time-consuming. Scanned pages are even more difficult to copy text from.
Overall, Acrobat Reader's built-in copy text feature works well for quickly grabbing a few lines or paragraphs from a PDF.

b. Open the PDF in Microsoft Word or Google Docs
Microsoft Word and Google Docs allow you to open, edit, and extract text from PDF files. Here's how you can leverage these tools:
Using Microsoft Word:
- Open MS Word on your desktop.
- File > Open > Browse and select your PDF.
- Word will convert the PDF into an editable document.
- You can now freely copy and paste text from this document.
The benefit of using Word is that it tries to retain formatting such as fonts, colors, and positioning. However, it works best for text-heavy PDFs without much formatting complexity. Scanned documents may not convert well.
Using Google Docs:
- Upload your PDF to Google Drive.
- Right-click on the File and select "Open with Google Docs."
- The content will be imported into a new Google Doc.
- Select and copy text as needed.
Google Docs can extract text from scanned documents using its integrated OCR capabilities. However, formatting often gets lost, making it best for getting raw text from PDFs.
Both tools allow quick and straightforward extraction of text from PDFs. However, they cannot guarantee perfectly formatted conversions, especially when dealing with complex files. Missing characters, jumbled sentences, and formatting issues are familiar in the converted document, necessitating manual cleanup before the text can be reused. Additionally, this approach is impractical for extracting text from hundreds of pages.
c. Upload the file to an online converter
There are many free online PDF-to-text converters available that simplify extraction from PDFs. These tools convert your PDF to a format, such as TXT or DOC, allowing you to copy the content easily.
Some of the popular online OCR tools include:
- Make Searchable PDFs Online
- PDF to Text Converter
- Simply PDF
- Smallpdf
- PDFgear
- PDFforge
- PDFMiner
- Nitro Pro
- Cometdocs
- iSkysoft PDF Converter Pro
Here are the typical steps when using an online PDF extractor:
- Go to the tool's website.
- Click "Select File" or "Upload" to choose your PDF.
- Set the output format to TXT, DOC/DOCX, or other formats.
- Click "Convert" to start the conversion.
- Download the converted file to your computer.
- Open the text file and copy and paste as needed.
Most online converters offer some basic usage for free. However, certain advanced features and increased limits may require a paid subscription. Additionally, be mindful of privacy policies before uploading sensitive data.
While convenient, these tools can falter with complex layouts in PDFs. They use traditional OCR technology to extract text, so they struggle with non-standard fonts, multi-column layouts, images mixed with text, tables, and colored backgrounds.
The extracted text often loses its original formatting and needs to be corrected manually, which can be time-consuming and inefficient for bulk processing contracts, reports, and statements.

2. Copy and paste images from PDFs
You may want to extract a chart or sketch from a PDF for use in your own documents and presentations. Here are a few ways to copy images from PDF files while retaining quality:
a. Use a screenshot tool to snip the PDF
Screenshot tools can be pretty handy if you want to extract a specific part of a PDF page as an image.
Here are the typical steps when using screenshot tools:
- Open the PDF file and go to the page with the image.
- Launch your screenshot tool, such as Snagit, Greenshot, or Windows built-in tool.
- Take a screenshot of the portion you want to copy.
- The screenshot will be saved to your computer.
- Open the screenshot in an image editor if you need to crop or further edit it.
Screenshot tools provide an easy way to capture images from PDFs when you don't need to extract the entire page. You can take screenshots of specific charts, diagrams, logos, or other graphic elements.
However, this method can be tedious if you need to extract multiple images from a large PDF, and it doesn't retain text searchability since you're capturing the picture, not the underlying text.
b. Use Acrobat Pro’s Snapshot tool
If you are an Acrobat Pro user, you can use its Snapshot tool to copy images from PDFs.
Here's how to use it:
- Open your PDF in Acrobat Pro.
- Click and drag to select the page area containing the image you want to extract.
- Click the right mouse button to open a drop-down menu.
- Select "Take a Snapshot"
- The Snapshot tool copies the selected area of the PDF page to your clipboard as an image. You can paste this into any image editing or document software using CTRL+V.
The Snapshot tool is handy for quickly grabbing PDF document charts, diagrams, sketches, or other visual elements. Moreover, you can export the captured image in formats like JPG, PNG, and more.
If you click on images in PDFs, the tool will allow you to extract them directly. Moreover, there is a ‘recognize text’ option that runs OCR on the selected region, which can help extract text from scanned documents or images inside PDFs.
The Snapshot tool effectively copies specific parts of a PDF page while retaining the formatting and visuals. However, it requires access to the paid Acrobat Pro subscription, priced at US$19.99/mo.
Another limitation is that the Snapshot tool works on one page at a time, which can become tedious if you need to extract multiple images from a scanned PDF or if you have to process hundreds of files in one go.
c. Convert PDF pages to image files
If you need to extract all images from a PDF document, converting PDF pages into image files can be helpful. Online converters like Smallpdf, IlovePDF, and PDF2Go allow bulk conversion of PDF pages to image formats like JPG, PNG, and TIFF.
Follow these steps:
- Upload your PDF to an online converter tool like PDF2JPG.
- Choose JPG or PNG as the output format.
- Select the pages you want to convert to images.
- Click on "Convert" to start PDF to image extraction.
- Download the ZIP folder containing images of each page selected.
- Open the image files and copy them as needed.
Text from the PDF may be lost when converting to images, making this approach suitable primarily for extracting charts, diagrams, photos, and other graphical elements from PDFs rather than text.
Converting PDF pages to images can be tedious, especially if you must process hundreds of pages simultaneously. Online tools often limit the number of pages you can convert. Moreover, managing separate image files can quickly become disorganized.
While suitable for quickly grabbing a few charts or photos from short PDFs, this approach has limitations when extracting images in bulk from long documents or eBooks.
3. Copy and paste data from PDFs
If you need to extract specific data, like numeric values or tabulated information, from a PDF, you'll want to leverage particular tools designed for data extraction. Here are a few effective methods:
a. Use Excel’s Get Data tool to extract data
Do you want to copy data from a bunch of PDFs? MS Excel’s Get Data feature works wonders. It can automatically extract tables and data from PDF files into Excel spreadsheets.

Follow these simple steps:
- Open Excel and go to the Data tab.
- Click Get Data > From File> PDF.
- Select the PDF file(s) you wish to import data from. Excel will automatically detect and extract tables from the document(s).
- The Import Data dialog box displays a preview of the data. Choose the table(s) you wish to import and click Load.
- The extracted PDF data will be inserted into the spreadsheet as a table, allowing for data analysis.
The data extraction works well for textual PDFs. Users can select a table or multiple tables to import from one or more PDF files. Excel can intelligently separate the data into rows and columns. It also allows users to add filters or transform the imported data within Excel. This makes it easy to quickly get usable data out of PDFs into Excel for further analysis and dashboarding.
Excel struggles to extract data from scanned documents or PDFs with complex layouts, such as columns or images. It performs optimally with textual PDFs with clearly defined data tables and grid-like layouts. When your PDF data is neatly organized in tables, utilizing Excel can save you a significant amount of manual copying, pasting, and reformatting work.
You will need more advanced data extraction capabilities for unstructured data locked in scanned documents or complex reports.

b. Use open-source PDF data extraction tools
Open-source libraries such as Tabula and Excalibur provide helpful options for extracting data tables from PDF files. These data extraction tools can detect tables, split them into rows and columns, and export the data into CSV, Markdown, JSON, or Excel files.
Generally, the workflow would look like this:
- Download and install the open-source software on your computer.
- Import the PDF.
- Snip the rows and columns of the table you wish to extract.
- Click on the 'Preview & Export Extracted Data' button.
- Verify the data in the preview; if it looks good, click 'Export'.
- Choose your preferred format (CSV or XLS) and save the File.
- Open the saved File in Excel, copy the required cells, and paste them into your Excel spreadsheet.
While open-source PDF extraction tools offer more advanced capabilities than Excel's built-in option, they may require more manual effort to set up and process each document. You may need to be more tech-savvy to use these tools effectively.
These tools are most effective for extracting tabular data from clean PDF layouts that don't have much text or graphics surrounding the tables. However, they may struggle with scanned documents or unstructured data in complex reports or statements.
 →
→

Seamless data flow is just a step away.
▼
Seamless data flow is just a step away.
Connect with over 5,000 apps via Zapier, APIs, and webhooks and automatically route data extracted from PDFs to your business apps, eliminating manual data entry—no coding required.
Automate PDF content extraction with Nanonets
Nanonets is an AI-powered document processing platform with advanced OCR and automation capabilities, enabling accurate extraction of text, images, and data from PDFs and scanned documents.

The key capabilities
It can handle complex layouts with multiple text columns, images, tables, and other elements accurately. Nanonets leverages machine learning (ML) and natural language processing (NLP) to "see" and "understand" document structures. This enables text and data extraction with context, maintaining the correct reading order and data relationships.
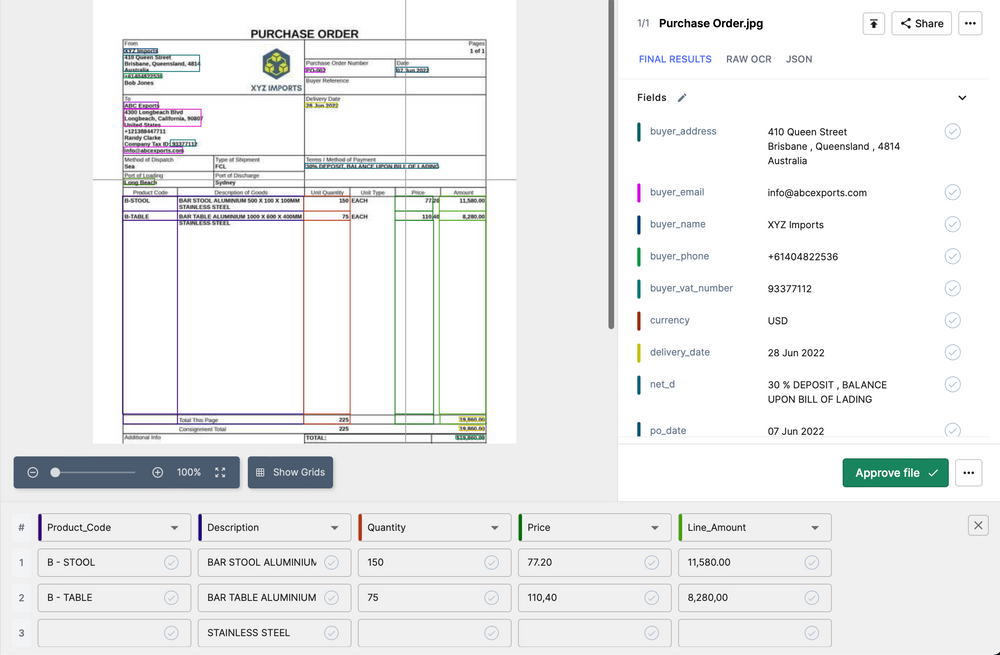
Nanonets can automatically extract data from PDF files, including text, tables, images, QR codes, barcodes, and other elements from PDFs and scanned documents, such as invoices, statements, ID cards, questionnaires, and more. Its advanced OCR and AI capabilities enable the platform to capture structured and unstructured data effortlessly.
Unlike traditional tools, it doesn’t just capture information. You can establish predefined validation rules and approval hierarchies to ensure the extracted data is accurate and compliant with your business needs before it is added to your systems. This helps eliminate costly errors and exceptions in downstream business processes.
Nanonets seamlessly integrates with popular business systems through REST APIs, Zapier, or webhooks, enabling the automatic ingestion of files into the platform and the export of extracted data to other applications, thus eliminating the need for manual sorting, classification, renaming, or data entry.
Once the apps are connected and the workflow is set up, the extraction and ingestion of data from PDFs and scanned documents can run on autopilot. This frees your employees from mundane document processing tasks, allowing them to focus on value-added work.
An example
Suppose you run a recruitment firm processing hundreds of PDFs daily. Your team manually extracts names, email addresses, phone numbers, skills, and experience from resumes and applications. With Nanonets, you can create an automated pipeline to OCR PDFs and extract structured data from resumes at scale. The platform comprehends resume layouts and extracts accurate data fields, allowing for rapid processing of high volumes of documents with minimal manual intervention.
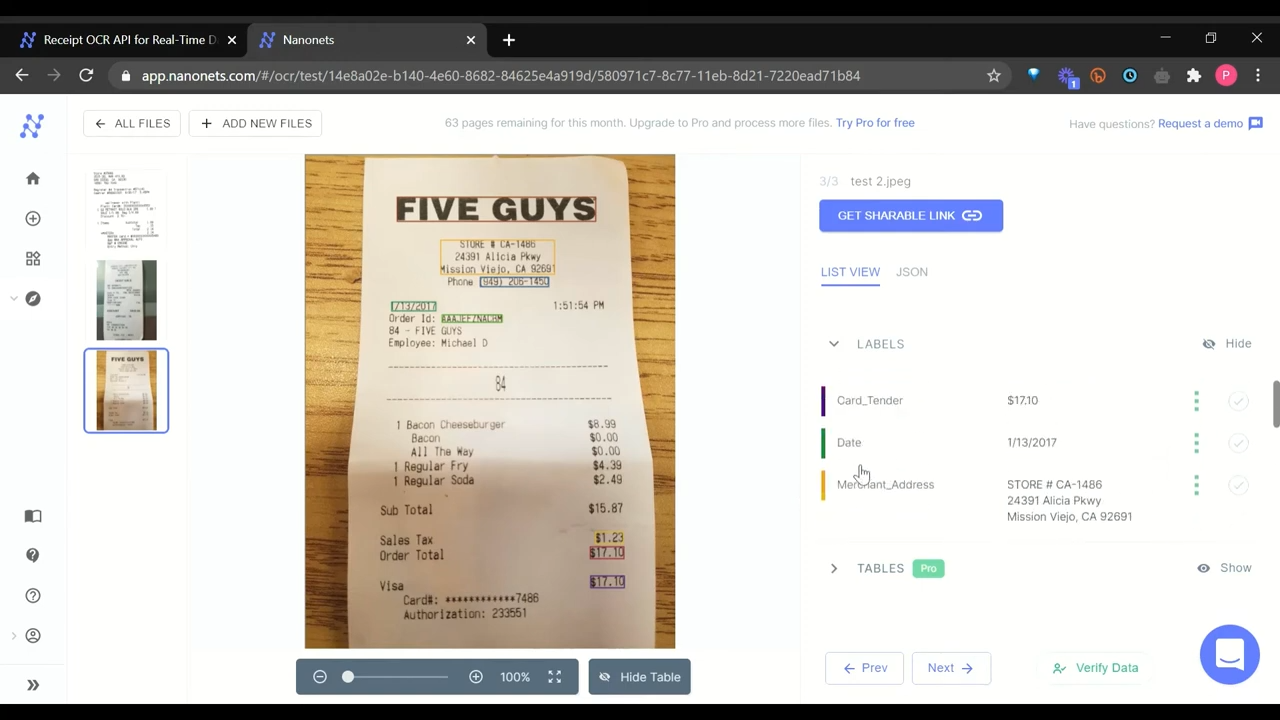
You can set up auto-import of documents from Gmail, Google Drive, OneDrive, and Dropbox. Integrations with tools such as Microsoft Dynamics, QuickBooks, and Xero allow you to automatically route extracted data to your business systems. It also integrates with the popular workflow automation platform Zapier, connecting over 5,000 apps.
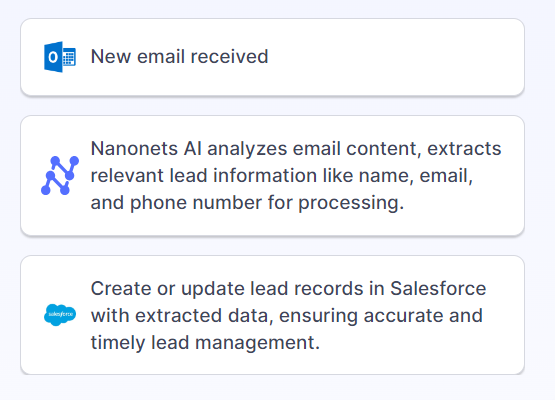
For example, you can create an automated parsing workflow that uses OCR to extract names, emails, and phone numbers from PDF resumes uploaded to your Google Drive, and then imports these contacts into a Google Sheet. This workflow can utilize Zapier to add these contacts to your CRM and assign tasks to HR representatives to follow up with high-potential candidates.
It can process documents in various currencies, languages, layouts, and formats without losing context. The AI learns from training data and manual interventions to improve accuracy.
How to get started?
Upload a sample set of 5-10 documents, annotate the text you wish to extract, and Nanonets will automatically build a custom AI model tailored to your documents. It can process thousands of pages per month, maintaining an accuracy rate of 95%.
The pricing for Nanonets is usage-based, allowing you to start small and scale up as your needs grow. The first 500 pages are free, and you’ll have access to three AI models, enabling you to test Nanonets on multiple document types before committing.
Final thoughts
Copying and pasting from PDFs doesn't have to be a chore. You can simplify and streamline the process with the right tools and techniques.
The best approach depends on your specific needs and documents. Assess your PDFs' complexity, workflow needs, data privacy policies, and more. Finding the solution that checks all the boxes for your situation is critical to long-term efficiency. The goal is to eliminate the manual drudgery of copying PDF text. Whether you handle a few documents a month or process thousands of pages daily, solutions exist to make your life easier.

Scale your PDF data extraction effortlessly!
▼
Scale your PDF data extraction effortlessly!
See how Nanonets can help you effortlessly scale your PDF data extraction processes and handle growing volumes with ease. Book a demo to discover the scalability!