
Have you ever tried to extract data from PDF documents? It can be a real pain to do this manually.
Often, when I extract data from PDFs manually by copying some text/data and pasting it on a document editor, I lose the original formatting - especially when dealing with data in the form of tables!
Online converters or data extractors that I've tried do a slightly better job at maintaining the original formatting. But they are not ideal when all I need is a couple of specific data points within a particular PDF.
In this article I cover 6 methods that I've used and tested extensively for extracting data from a wide variety of PDF documents.
Why Extract Data from PDFs?
Before diving into the methods, it's important to understand why extracting data from PDFs is important. PDFs are commonly used for:
- Invoices and receipts in accounting: Extracting data accurately is crucial for keeping financial records in order.
- Contracts and legal documents: Analyzing specific clauses or details is easier with automated extraction.
- Research papers: Data tables or references often need to be pulled out for further study.
- Forms and questionnaires: Collecting and organizing responses manually can lead to mistakes.
In each of these cases, manual extraction is slow and error-prone, making automated tools a smart choice for saving time and ensuring accuracy. Let's explore the different methods for extracting data from PDFs.
6 ways to extract data from PDFs
Here are 6 different ways to extract data from PDF in an increasing order of efficiency and accuracy:
- Manual Data Extraction
- Using Python Libraries
- Online PDF Converters
- Using Large Language Models (LLMs)
- GenAI-Based Data Extraction (Nanonets)
Manual Data Extraction
When it comes to extracting data from PDFs, one of the most straightforward approaches is the copy-paste method. This is as simple as it sounds:
- Open each PDF file
- Select a portion of data or text on a particular page or set of pages
- Copy the selected information
- Paste the copied information on a DOC, XLS or CSV file
Using Python Libraries
For developers and data professionals, Python libraries offer a powerful way to extract text from PDFs using Python with precision and flexibility. Libraries like PyPDF2, pdfminer, and PyMuPDF at text extraction, while Tabula-py specializes in handling tables. These tools allow you to create custom scripts according to your specific needs, making them ideal for automating large-scale data extraction tasks. Whether you're processing hundreds of documents or need to extract specific data points, these libraries give you the control to fine-tune the extraction process.
For example, here’s a simple script using PyPDF2 to extract text from a PDF:
import PyPDF2
# Open the PDF file in binary mode
with open('example.pdf', 'rb') as file:
# Create a PDF reader object
reader = PyPDF2.PdfReader(file)
# Iterate through each page in the PDF
for page in reader.pages:
# Extract and print the text from the current page
print(page.extract_text())Code Explanation:
with open('example.pdf', 'rb') as file: This line opens the PDF file in binary mode ('rb'). Thewithstatement ensures that the file is properly closed after processing.reader = PyPDF2.PdfReader(file): This creates a PDF reader object that allows you to interact with the PDF content.for page in reader.pages: This loop iterates through each page in the PDF.print(page.extract_text()): This line extracts the text from each page and prints it to the console.
This approach is particularly valuable for automating repetitive tasks or handling large volumes of data. However, it requires a solid understanding of programming, and the setup can be more complex than other methods.
Online PDF converters
Online PDF converters like Smallpdf, PDF2Go, and Zamzar provide a user-friendly and efficient way to convert your PDFs into various formats such as Word, Excel, or plain text. The process is straightforward:
- Upload your PDF file to the chosen tool
- Select your desired output format
- Download the converted file
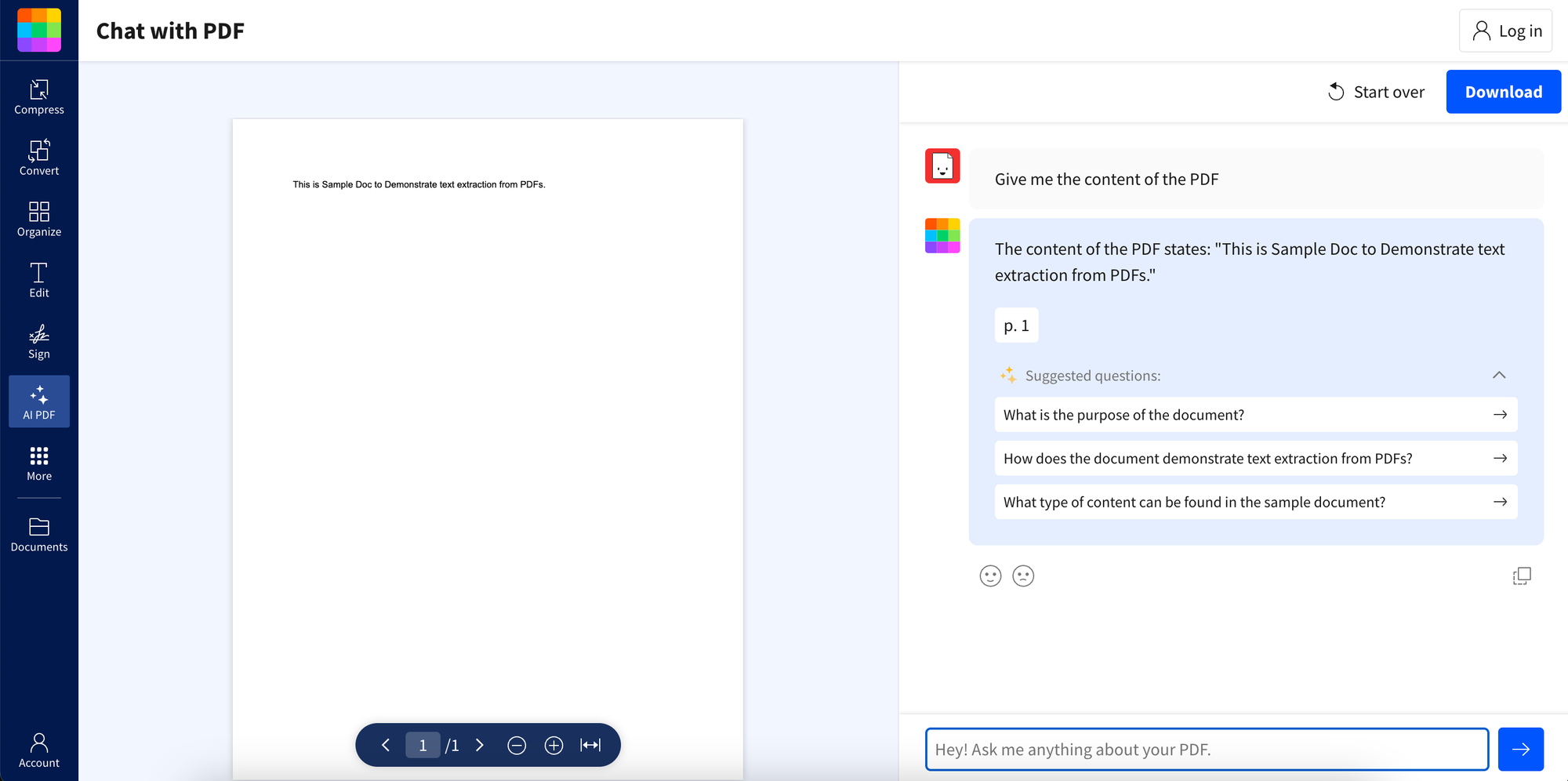
These tools are particularly appealing for their convenience. They eliminate the need for installing additional software, making them accessible from any device with an internet connection. This means you can quickly convert PDFs on the go, without the hassle of software setup or updates.
Some other top PDF converters include Adobe, PDFtoExcel, Simply PDF, Nitro Pro, Cometdocs and iSkysoft PDF Converter Pro.
Optical Character Recognition (OCR)
Optical Character Recognition (OCR) is a powerful technology that converts scanned images of text into machine-readable data. By analyzing printed or handwritten text in images, OCR allows you to transform static, physical documents into editable, searchable, and digital formats.
With tools like Tesseract, Adobe Acrobat’s OCR, and various online services, OCR makes extracting text from scanned documents straightforward. These tools can handle a range of documents, from old paper records to recent scans, enabling you to work with previously non-editable content.
Here are the steps to extract text from PDF using Tesseract.
Step 1: Convert PDF pages to Image
We’ll use the pdf2image library to convert each page of the PDF into an image, making it easier to handle with image processing tools.
from pdf2image import convert_from_path
# Replace 'Sample PDF.pdf' with the path to your PDF file
pdf_file = 'Sample PDF.pdf'
pages = convert_from_path(pdf_file)Here, convert_from_path from pdf2image turns each PDF page into an image object, ready for the next steps in our workflow.
Step 2: Image Preprocessing
With our PDF pages converted to images, we can address potential issues like skewed or rotated pages through preprocessing. This step involves correcting the image orientation to ensure better text extraction results.
Step 3: Running OCR with Pytesseract
Now, it’s time to extract text from our images using OCR. We’ll leverage pytesseract, a Python wrapper for the Tesseract OCR engine, to convert images to text.
import pytesseract
def extract_text_from_image(image):
text = pytesseract.image_to_string(image)
return textThe extract_text_from_image function utilizes pytesseract to read and extract text from each image, turning visual data into searchable, editable text.
Step 4: Compiling Extracted Text
Finally, we’ll compile the text extracted from all pages into a single list. This step involves iterating through each page, preprocessing the images, and then extracting and collecting the text.
# Create a list to store extracted text from all pages
extracted_text = []
for page in pages:
# Extract text using OCR
text = extract_text_from_image(pages)
extracted_text.append(text)This above converts PDF content into editable text, combining image conversion, preprocessing, and OCR to handle diverse document formats and layouts effectively.
Extracting Data Using Large Language Models (LLMs)
The advent of Large Language Models (LLMs) like GPT-4 and Gemini 2.0 has revolutionized how we approach data extraction from PDFs, particularly in dealing with unstructured data or when context understanding is required.
LLMs and other LLM based AI tools can be fine-tuned to extract specific types of data from PDFs by understanding the context. For instance, a model like GPT-4 can be trained to identify and extract relevant information from legal contracts, such as party names, dates, and obligations.
Extract Text from PDF Using ChatGPT UI
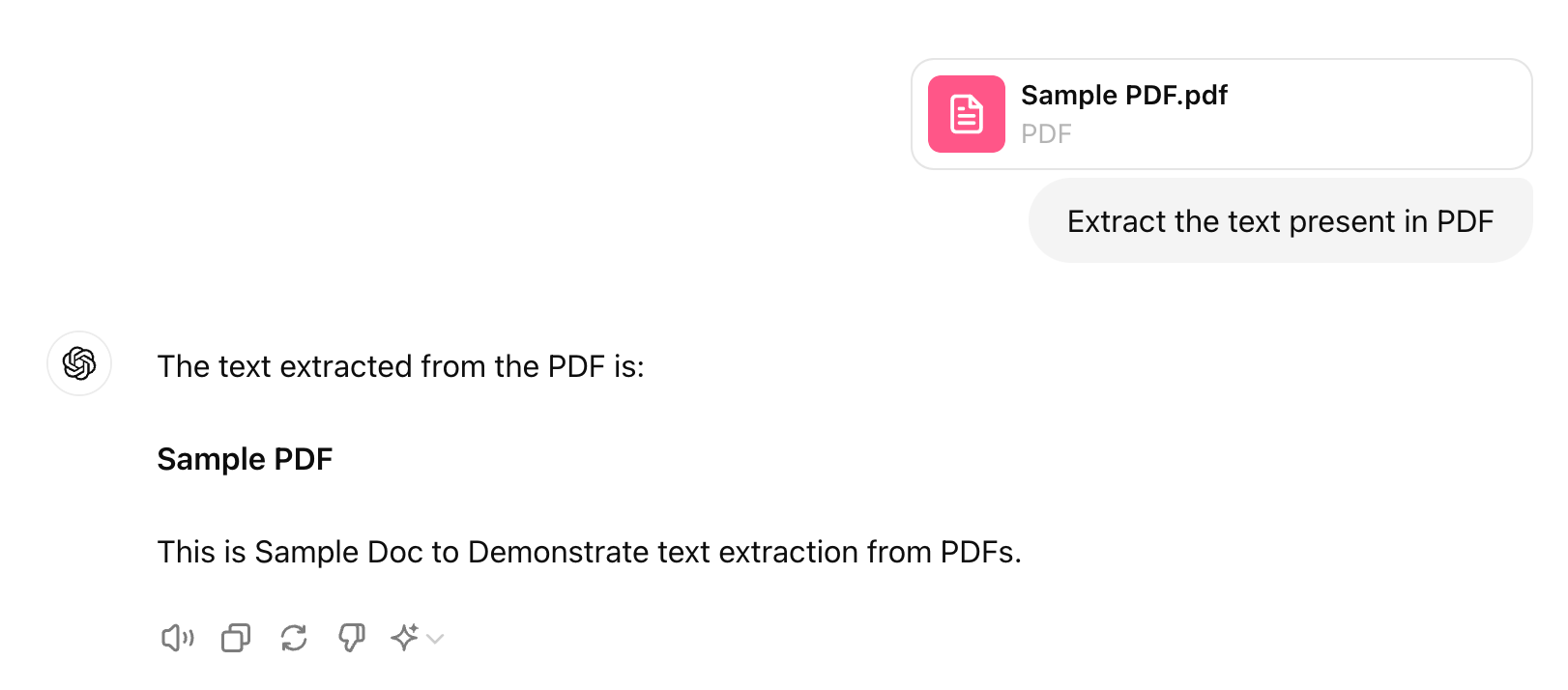
Let's take an example file Sample PDF.pdf and extract text from PDF using GPT UI. Below are the steps:
- Upload your PDF file as an attachment to GPT prompt
- Give the prompt to extract text from the file
- GPT will pull out the text from the document
Extract Text from PDF Using ChatGPT API
With the recent advancements in GPT-4, OpenAI's vision API now supports text extraction from images, providing a powerful tool for handling PDF content. To extract text from a PDF using the ChatGPT API, follow these steps:
Step 1: Convert PDF to Images
To start, you need to convert the PDF pages into images. This transformation allows the GPT-4 vision API to process and analyze the content.
from pdf2image import convert_from_path
# Replace with the path to your PDF file
pdf_file = 'Sample PDF.pdf'
pages = convert_from_path(pdf_file)Step 2: Prepare the GPT-4 Vision API
Initialize the OpenAI client to interact with the GPT-4 vision model. This model is capable of analyzing images and extracting text.
from openai import OpenAI
# Initialize OpenAI client
client = OpenAI()Step 3: Extract Text Using GPT-4 Vision API
Send each image to the GPT-4 vision API to extract text content. The API processes the image and returns the text.
def extract_text_with_gpt4(image_path):
with open(image_path, 'rb') as image_file:
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "Give me all the text content from the file"},
{
"type": "image_url",
"image_url": {
"url": image_path,
},
},
],
}
],
)
return response.choices[0].message['content']Step 4: Compile and Review Extracted Text
For each page image, save the image and use the API to extract and compile the text. Print or store the results as needed.
for i, page in enumerate(pages):
image_path = f'page_{i+1}.png'
page.save(image_path, 'PNG') # Save page as an image file
text = extract_text_with_gpt4(image_path) # Extract text using GPT-4
print(f"Text from page {i+1}:")
print(text)
print("-" * 40) # Separator between pagesRead About: Extract text from PDF using ChatGPT
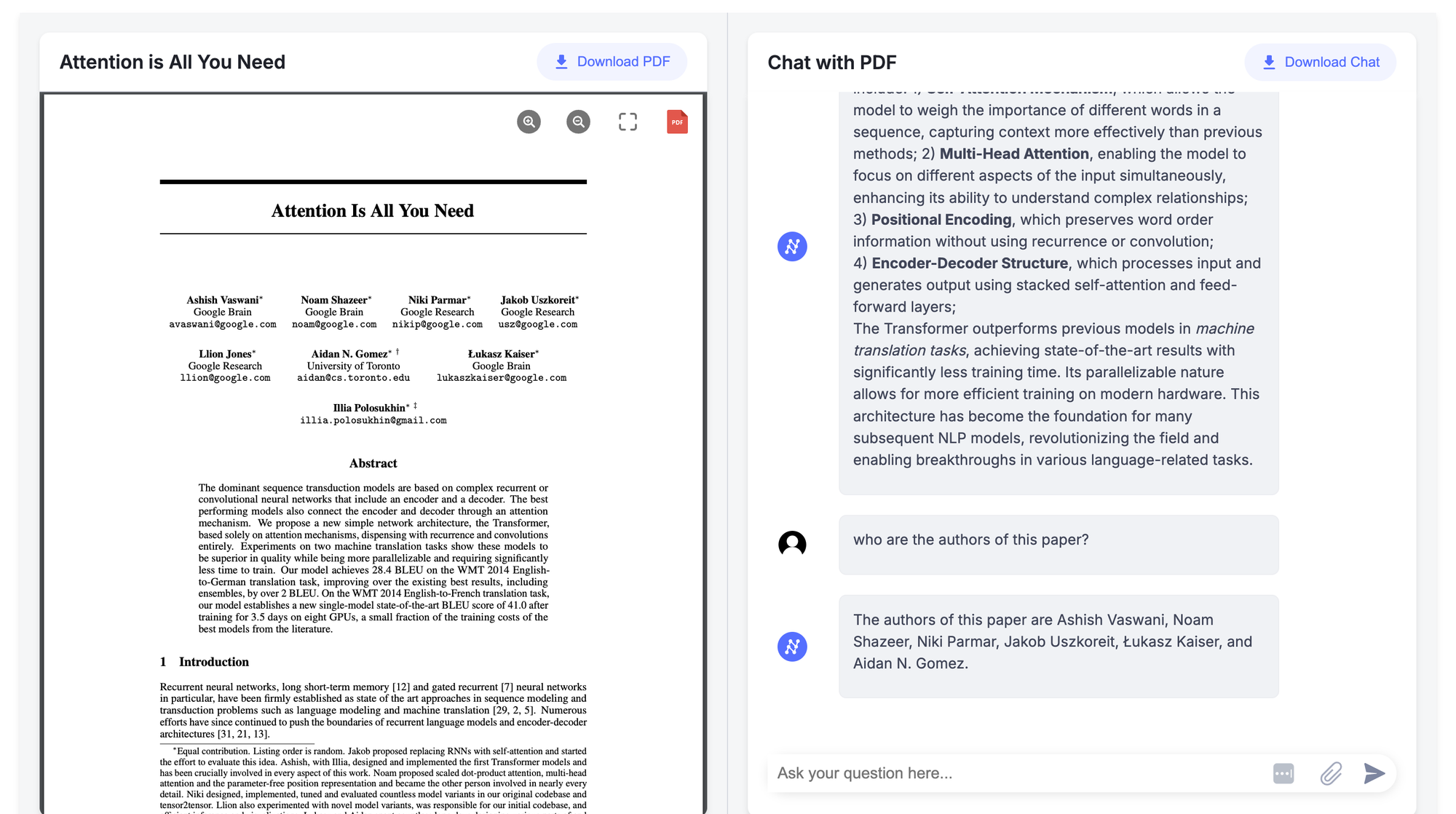
Extract Text, Insights, and Interact with PDFs Using Nanonets' Chat PDF
Another straightforward way to extract text is by using PDF chat tools that utilize their own language models. These tools allow you not only to extract text but also to interact with your PDFs. The responses you receive are based on the document's context, making your interactions more meaningful and efficient. If you're interested, give Nanonets' Chat PDF a try.
Intelligent Document Processing (Nanonets)
GenAI-driven data extraction solutions offer a sophisticated way to handle complex PDF data with precision and speed. These intelligent document processing solutions combine advanced OCR with artificial intelligence and machine learning to automate and enhance PDF data extraction, delivering exceptional accuracy and efficiency.
Some of the most popular PDF data extractor AIs include Nanonets, Google Document AI, AWS Textract, and many other AI-powered OCR software. They are dependable, efficient, extremely fast, competitively priced, secure & scalable. They can also handle scanned documents as well as native PDF files and are not bound by any templates or fixed document formats.
AI to extract data from PDF is becoming a standard for processing and extracting valuable insights from documents. Some of the most popular PDF data extractor AIs include Nanonets, Google Document AI, AWS Textract, and many other AI-powered OCR software. They are dependable, efficient, extremely fast, competitively priced, secure & scalable. They can also handle scanned documents as well as native PDF files and are not bound by any templates or fixed document formats.
Nanonets is at the forefront of this technology, offering a powerful AI-driven PDF data extraction tool. Unlike traditional methods, Nanonets allows you to describe the data you need in natural language, streamlining the extraction process without requiring any training. Simply define your data fields, upload your documents, and let Nanonets handle the rest.
Here’s a demo of Nanonets in action:
Nanonets Zero Training Document AI
Why Choose Nanonets?
- Automate document processing workflows effortlessly.
- Reduce manual data entry time and costs by up to 80%.
- Extract relevant data from any document type automatically.
Ideal for apps that require document uploads or staff reviewing documents, Nanonets adapts to various business needs, including processing invoices, receipts, and more. Explore Nanonets and transform your data extraction processes.
Find out how Nanonets' use cases can apply to your product.
Challenges in PDF Data Extraction
Despite the availability of various tools and techniques, PDF data extraction can still be challenging due to:
- Complex layouts: PDFs with non-linear text flow, embedded images, or multi-column layouts can confuse basic extraction tools.
- Inconsistent formatting: Variations in how information is presented across different PDFs can complicate automated extraction.
- Security features: Password-protected or encrypted PDFs require additional steps before data extraction can commence.
Final Thoughts
Extracting data from PDFs is a critical task across various industries, and the methods available today range from simple programming libraries to advanced AI-driven solutions. By understanding the strengths and limitations of each approach, you can choose the right tool for your specific needs, ensuring efficient and accurate data extraction. Whether you're a developer, a data analyst, or a business professional, mastering these techniques will empower you to unlock the valuable information stored within PDFs.