
Last week, I visited a local government office to renew a permit. While waiting in the line, I noticed something that made me wince slightly. A rather tired-looking clerk behind the counter was manually copying data from every PDF form into Excel spreadsheets.
I could've gone over and showed them a better way, but my social anxiety kicked in (fellow introverts, you know the feeling) and that was that. But as someone who's spent years helping organizations automate their PDF workflows, I couldn't help but calculate the hours being wasted — each form taking 3-4 minutes, multiplied by hundreds per day. 🤯
So, instead of being that awkward tech person interrupting their work, I thought I'd just write this quick guide, sharing three PDF to Excel data extraction methods that I've personally tested.
Starting with the simplest (and free) approach..
Method 1: Import data from PDF to Excel directly in Microsoft Excel
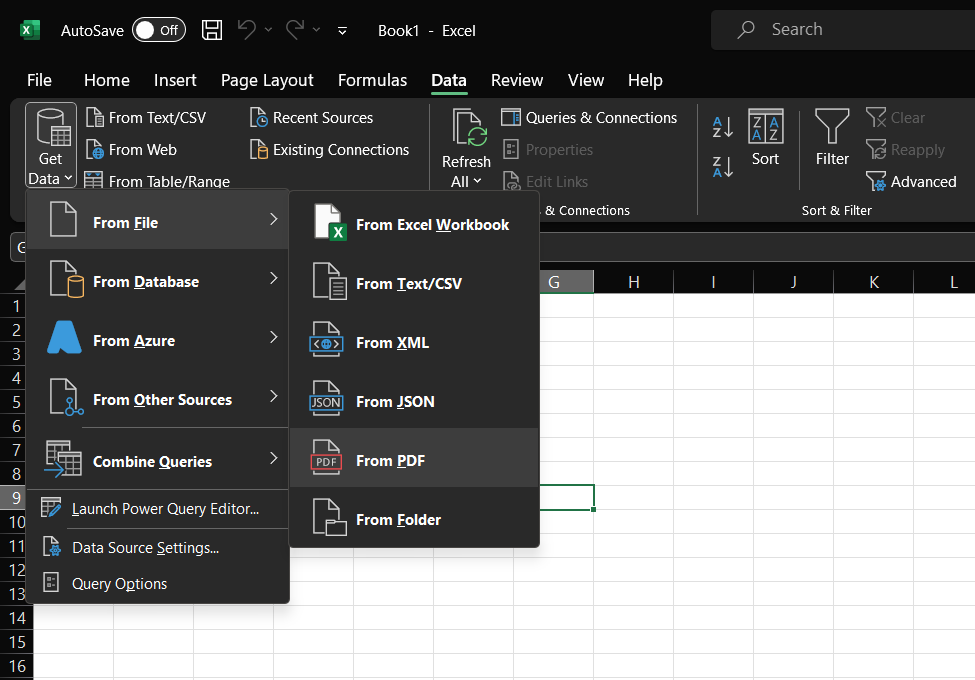
Now, if you don’t want to bother with any additional software, Excel's built-in PDF import feature can handle basic conversions. It's not perfect, but it can turn a 3-hour task into a 15-minute one.
Here's how it works:
- Open an Excel sheet.
- Click the Data tab >> Get Data drop-down >> From File > From PDF.
- Select your PDF file & click Open.
- You'll now see a Navigator pane displaying the tables & pages in your PDF, along with a preview.
- Select the tables you wish to import & click Load to view the data directly in the Excel sheet or to see the Import dialog box, select Load > Load To.
If you want more control, just click Transform Data instead of Load. It opens up the table in Power Query Editor. This is where you can clean up those messy headers, fix data types, remove unwanted columns, and merge or split columns. Essentially, it can help make your imported data more usable.
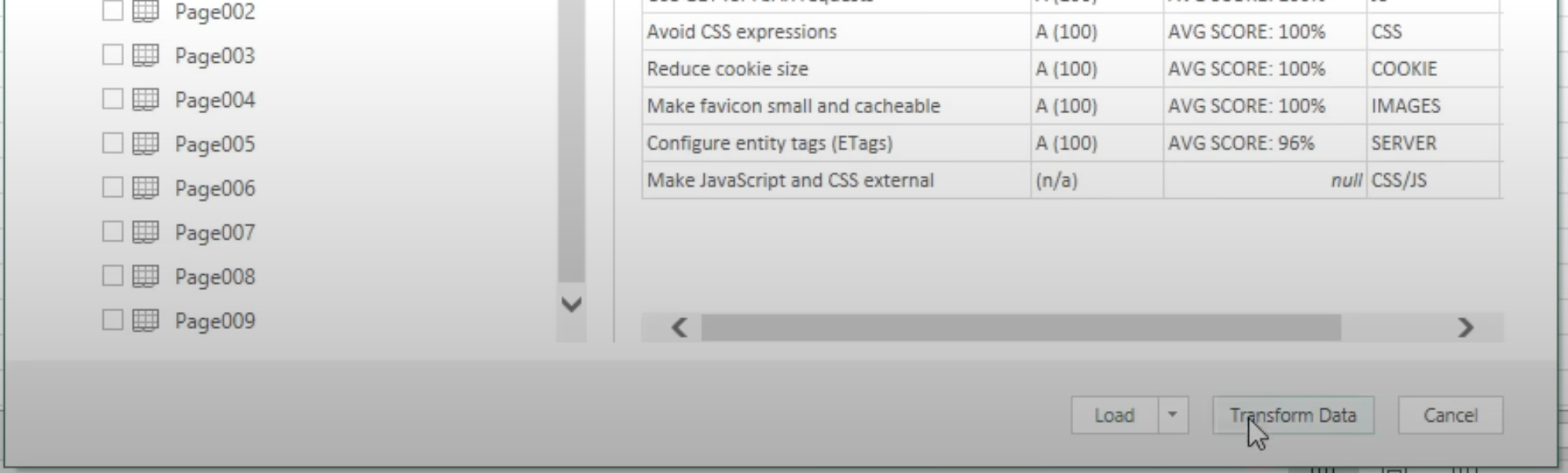
Pro tip: I've found this works best with simple, well-formatted PDFs. Excel sometimes messes up the formatting on multi-page tables. If this happens, try importing one page at a time.
If your PDF has complex tables or scanned content, you might want to skip to Method 2.
Method 2: Export PDF data to Excel using Adobe Acrobat
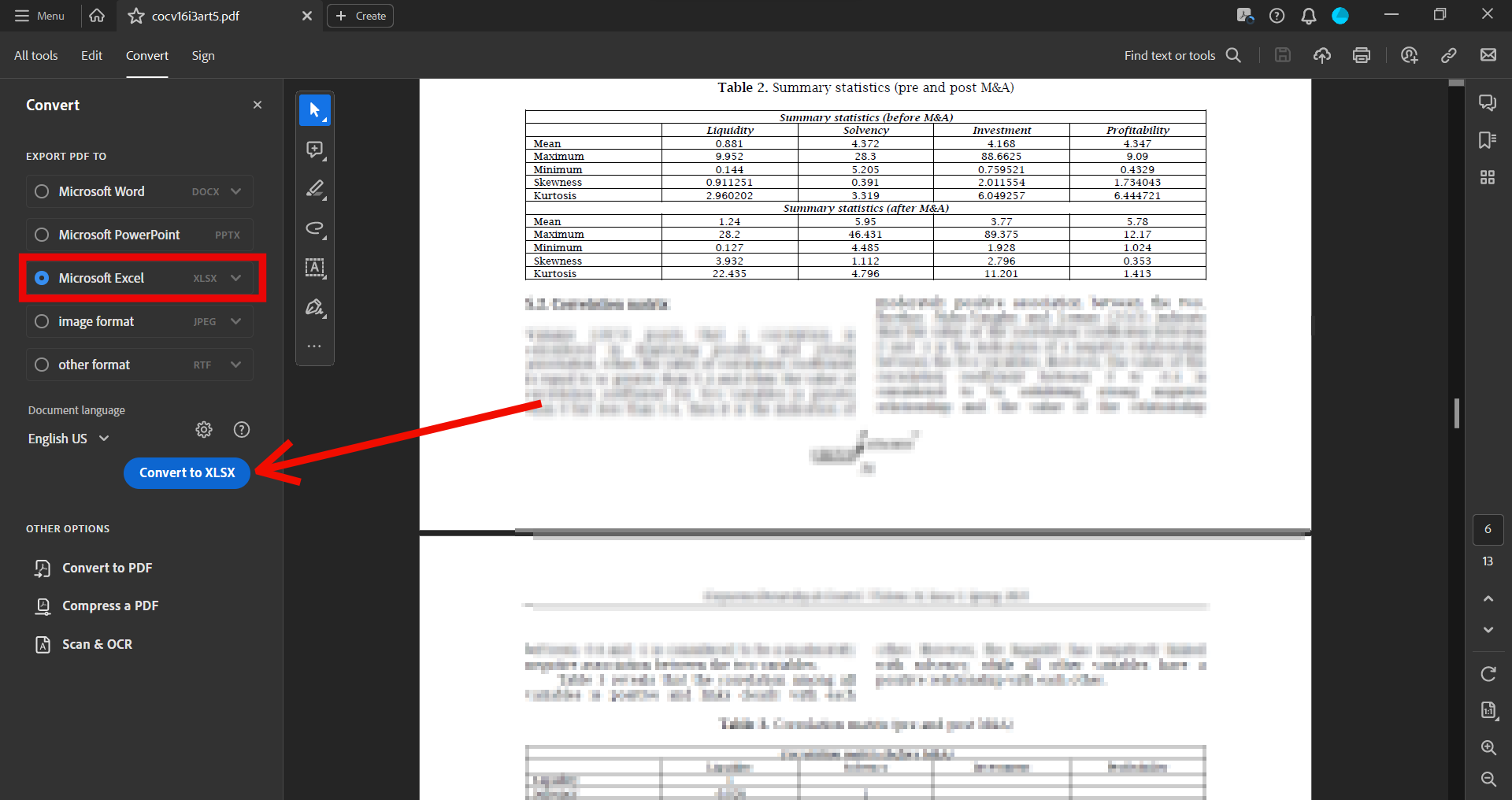
If you work with PDFs, chances are you may already have Adobe Acrobat installed on your computer. Its familiar interface and built-in conversion tools make it a convenient next step when Excel's basic import falls short. While it requires a Pro subscription to unlock the export features, you won't need to learn any new software or install additional tools.
Here's how it works:
- Open your PDF file in Acrobat
- Click on the Export PDF tool in the right pane
- Choose spreadsheet as your export format >> select Microsoft Excel Workbook
- Click Export (if your PDF is scanned, Acrobat will automatically run text recognition)
- Name your Excel file and hit Save
The best part about Acrobat is its OCR technology. It can handle scanned documents much better than Excel's built-in tool.
Pro tip: Acrobat works best when your PDF is properly scanned — try to ensure your documents are scanned straight and with good contrast. The biggest limitation is that it exports everything in the PDF, so you can't selectively choose specific data points or tables. Neither does it support batch processing of multiple PDFs at once. So, if you've occasional PDF conversions that need to processed one at a time, Acrobat is a solid choice.
If you're processing large volumes of PDFs daily, you might want to check out Method 3 for a more automated approach.
Method 3 - Automate PDF to Excel data extraction workflows with Nanonets
Full disclosure: I work at Nanonets, so I might be a bit biased here. But after seeing countless organizations struggle with PDF data extraction, I've become convinced that automation is essential for high-volume PDF processing. Let me explain why, and you can decide if it makes sense for your situation.
David Alldian, Business Analyst at Brown Strauss
Our AI-powered document processing platform can handle what traditional PDF converters can't:
- Complex table structures and layouts
- Scanned documents through advanced OCR
- Multi-page PDFs with varying formats
- Documents in any language
Here's how it works:
- Set up an automatic import of PDF files/data from incoming emails, cloud storage services, support tickets, and just about any data source.
- Extract data from PDFs using AI accurately with our advanced AI extractors that don’t rely on predefined templates but understand each document contextually.
- Define rules to identify potential errors, flag specific entries for manual review, or enhance your extracted/missing data.
- Export as clean structured data in formats such as XLS, CSV, or XML, or export into your CRM, WMS, or database directly!
The best part? Unlike the manual methods we discussed earlier, you can process hundreds of PDFs simultaneously. Plus, the AI learns from any corrections, so it gets smarter over time.
Pro tip: Start with a small batch to help the AI understand your specific document formats. This builds accuracy from day one.
Of course, automation isn't for everyone. If you're only dealing with occasional PDFs, Methods 1 or 2 might be more suitable. But if you're processing volumes of documents (like that clerk I mentioned), automation could save your team hundreds of hours of manual work.
I wrote this guide with that clerk in the government office and everyone else in mind who spends countless hours copying and reformatting PDF data instead of doing meaningful work. Whether you choose the quick Excel import, stick with trusty Adobe, or dive into automation, the key is finding what works for your specific situation. We've all been there, and it doesn't have to be this way.
Wondering how AI-powered workflows can help you?