
Building on its simplicity, Excel table has been the most predominant way of storing any structured data digitally, and its impact may far exceed what we anticipated: individuals use it to keep track of their daily spending; researchers use it to keep track of experimental data; corporations leverage it for survey processing, statistical analysis and more. Tables are convenient not only because of the presentation clarity, but also due to the significant amount of operations Excel provides to make all kinds of computation easier.
Nevertheless, despite the capability of tables to process all kinds of data, the task of entering data into tables from various mediums remains a tedious and error prone task. The problem is deeply rooted in the fact that table cells from printed and handwritten documents are not directly understandable nor detectable by programs -- computer vision and image processing methods must be applied for proper retrieval of table cells from either PDFs or scanned images.
This article discusses in detail the importance of table cell extraction using concrete examples, followed by an in-depth tutorial on the individual steps to achieve table cell extraction from numerous data in highly accurate ways, and finally with a comparison of existing solutions in the market that offer these out of the box.
Why Table Cell Extraction?
As mentioned previously, tables are extremely crucial to a major part of our daily job or routine. However, what exactly are some use cases of table cell extraction? This section describes some daunting tasks from a business point of view and why table cell extraction is handy in alleviating the difficulties in such scenarios.

Electrical Record Transfer
Individuals move to new regions, countries, or opt to new services all the time. When they do so, they would need to transfer the identical data from previous systems to the new service provider. As different firms have different styles of tabular forms keeping track of data, the transferring process ultimately involves an inevitable process of re-typing all the information that had already once existed in table forms. Therefore, an automated method picking out tables and matching them to the current system will be beneficial to all the three parties (previous service provider, current service provider, and the client) involved.

Survey Collection and Statistical Computation
Whether it is the government or NGOs gathering information from the public, or private firms collecting reports for analysis, surveys are the most frequently-used ways to collect data. However, many times surveys could be handwritten, and the tables could potentially be filled in then scanned onto computers when sent back to the issuing party. Table cell extraction could therefore minimize the manual effort required to key in those data and companies can then use statistical computations to infer valuable information from those surveys.

Payment Reconciliation
Payment reconciliation is the process of cross-validating statements and invoices with the accounting of a firm to prevent any fraudulent financial events. Reconciliation might be more straightforward for smaller firms when their clients and cash flows come from a limited number of sources, but the errors and the effort required may increase exponentially as the size of businesses grow and cash flows become much more indirect. Automated methods in extracting tables from printed spreadsheets and invoices is a big leap in reducing human efforts and expediting the process.
Looking to extract tables from PDFs, images, etc,. and obtain information present in specific cells? Try Nanonets that detects individual cells in tables in any format and extract specific information.
Table Cell Detection Technology
Table cell detection from images can be divided into two sub-tasks: table border and cell detection followed by content extraction. This section discusses both the traditional and state-of-the-art approaches for both these tasks.
Border and Cell Detection
Table extraction can be simplified with borders and cell extraction from lines. The approach may not be as straightforward as it sounds, however. When documents are scanned as images into computers, they are stored as merely groups of pixels containing colors. The task turns into a problem of processing the image to detect where the boundaries and the subsequent cells are located within the image (document).
- Traditional Approach: In traditional computer vision and image processing, the most used method for line detection is through convolutions, which is essentially using a sliding window of pixels (kernels) and convolute (multiply) with patches of images such that only the lines and edges are left. Since lines and borders are perhaps the easiest to detect, using standard kernels would most likely succeed if the document is scanned well. However, if the document is scanned poorly with distortion and noises, chances are pre-designed weights of kernels might work less well and therefore the traditional approach is barely used solely nowadays.
- State-of-the-art Approach: With the advancement of deep learning, we have now upgraded traditional convolutions with convolutional neural networks (CNNs). Instead of directly telling the program what the kernel filter weights should be, we allow networks to learn them based on the ground truth answers. With hundreds of convolutions, it is much easier for the network to extract the borders and then the table cells even when the conditions are suboptimal.
Content Extraction
Getting the location of the cell isn’t the only task for table cell detection, one must also extract the words/numbers within for the extraction process to be complete. We refer to the concept of converting pixels of letters to machine-encoding text as optical character recognition (OCR).
- Traditional Approach: Before deep learning, traditional OCR was performed with four main steps:
- Collect a database of known characters.
- Use photo sensors to gather and separate characters from scanned documents.
- Compare the attributes from the characters retrieved from the sensor and from the database.
- Find the characters with the highest similarities from the dataset as the machine-encoded text.
Again, this approach is effective only with clear and well-scanned documents. Rule-based attribute comparison hinders performance under worse situations. In addition, the association of one letter to another is not considered in this method, and so the extracted words may likely not make any sense at all.
- State-of-the-art Approach: Similar to table border and cell extraction, deep OCRs also use convolutions. The main difference between the two models is that OCRs also incorporate long short-term memories (LSTMs), a learning mechanism that takes in previous predictions as inputs for the next prediction so that the letters make more sense with each other and are more likely to be predicted with each other via this approach. Recent techniques have also slowly shifted from LSTMs to transformers, where attention of each letter against each other is computed. The new mechanism has shown to outperform LSTMs in many language processing tasks.
Tutorials
PDF Conversion
To perform any table cell detection, we must first be able to extract the raw image data. This is more difficult when the file is in PDF. Therefore, the first step would be to convert all printed documents in .pdf format into usable image formats. Luckily, this is very easy to perform with Python by using the pdf2image library, which can be installed via the following code:
pip install pdf2imageThe library can be used as the following:
from pdf2image import convert_from_path, convert_from_bytes
from pdf2image.exceptions import (
PDFInfoNotInstalledError,
PDFPageCountError,
PDFSyntaxError
)
images = convert_from_path('example.pdf')
images = convert_from_bytes(open('example.pdf','rb').read())where the 'example.pdf' can either be read directly from path or from byte formats.
For more information on the code, you can refer to the official documentation in https://pypi.org/project/pdf2image/
Table Cell Detection using openCV
After converting, the next step will be to detect lines in search for something that looks like a table. The simplest way to do so will be to directly use line detections developed by pre-existing tools from libraries such as openCV. This requires some trial and errors regarding image processing, but all the documentations are well recorded on their official website. To use it simply install it with:
pip install opencv-pythonContent Extraction via Google Vision API
With the bounding box of table cells estabilished, we then refer to the Google Vision API for OCR retrieval. Google vision API are benefitted from the massive crowdsourcing owing to their vast customer base. Therefore, instead of training your personal OCR, using their services may have much higher accuracies.
The entire Google Vision API is simple to setup, one may refer to its official guidance.
The following is the code for OCR Retrieval:
def detect_document(path):
"""Detects document features in an image."""
from google.cloud import vision
import io
client = vision.ImageAnnotatorClient()
with io.open(path, 'rb') as image_file:
content = image_file.read()
image = vision.Image(content=content)
response = client.document_text_detection(image=image)
for page in response.full_text_annotation.pages:
for block in page.blocks:
print('\nBlock confidence: {}\n'.format(block.confidence))
for paragraph in block.paragraphs:
print('Paragraph confidence: {}'.format(
paragraph.confidence))
for word in paragraph.words:
word_text = ''.join([
symbol.text for symbol in word.symbols
])
print('Word text: {} (confidence: {})'.format(
word_text, word.confidence))
for symbol in word.symbols:
print('\tSymbol: {} (confidence: {})'.format(
symbol.text, symbol.confidence))
if response.error.message:
raise Exception(
'{}\nFor more info on error messages, check: '
'https://cloud.google.com/apis/design/errors'.format(
response.error.message))Note that document_text_detection is one of the functions they offered that specialises in very condensed texts that appears mostly in PDFs. If your PDF has words somewhat more scarce, it may be better to use their other text detection function which focuses more on in-the-wild images. More codes regarding the usage of Google API can be retrieved here: https://cloud.google.com/vision; you may also refer to codes in other languages (e.g., Java) if you are more familiar with them.
There are also other OCR services/APIs from Amazon and Microsoft, and you can always use the PyTesseract library to train on your model for specific purposes.
Solutions in the Market
With a growing demand for table cell extraction and OCR techniques, large firms (e.g., Google, Amazon) utilize their large datasets to train highly accurate models for such tasks. Smaller niche solutions have also focused on training and providing customized services for these traditionally labour-intensive tasks. The following are a some solutions from different providers:
*Side Note: There are multiple OCR services that are targeted towards tasks such as images-in-the wild. Since our focus is on table cells, we assume the targeted images are mostly scanned documents in a fairly well-done manner.
- Amazon API: Besides Google API, Amazon is also a strong competitor in this space. The AWS crowdsourcing techniques provide them competitive advantages in accuracy in terms of border extraction. The tesseract engine also provides state-of-the-art results in OCR.
- Online PDF Readers: Besides the priced solutions of Google and Amazon, there are also multiple online options to automatically detect tables (e.g., Docsumo). These methods however have accuracies with less reliability compared to APIs generated by big companies.
- Nanonets -- With a highly skillful deep learning team, Nanonets Table Extraction is completely template and rule independent. Therefore, not only can Nanonets work on specific types of PDFs, it could also be applied onto any document types for text or table retrieval. Tasks such as extracting tables are also built-in, allowing flexible yet highly accurate retrieval from all types of documents.
Nanonets - Entire Table in a Click
Nanonet’s automated AI system provides on par, or even better results than tech giants due to the range of data the models are exposed to. Given a PDF, Nanonets can easily detect not just single cells, but the entire formats of multiple tables in the matter of seconds. The following is a very simple tutorial on how to perform table cell detection in the most straightforward way on Nanonets.
Step 1.
Go to nanonets.com and register/log in.
Step 2.
After registration, go to the “Choose to get started” area, where all the pre-built extractors are made and click on the “Tables” tab for the extractor designed for extracting tabular data.
Step 3.

After a few seconds, the extract data page will pop up saying it is ready. Upload the file for extraction.
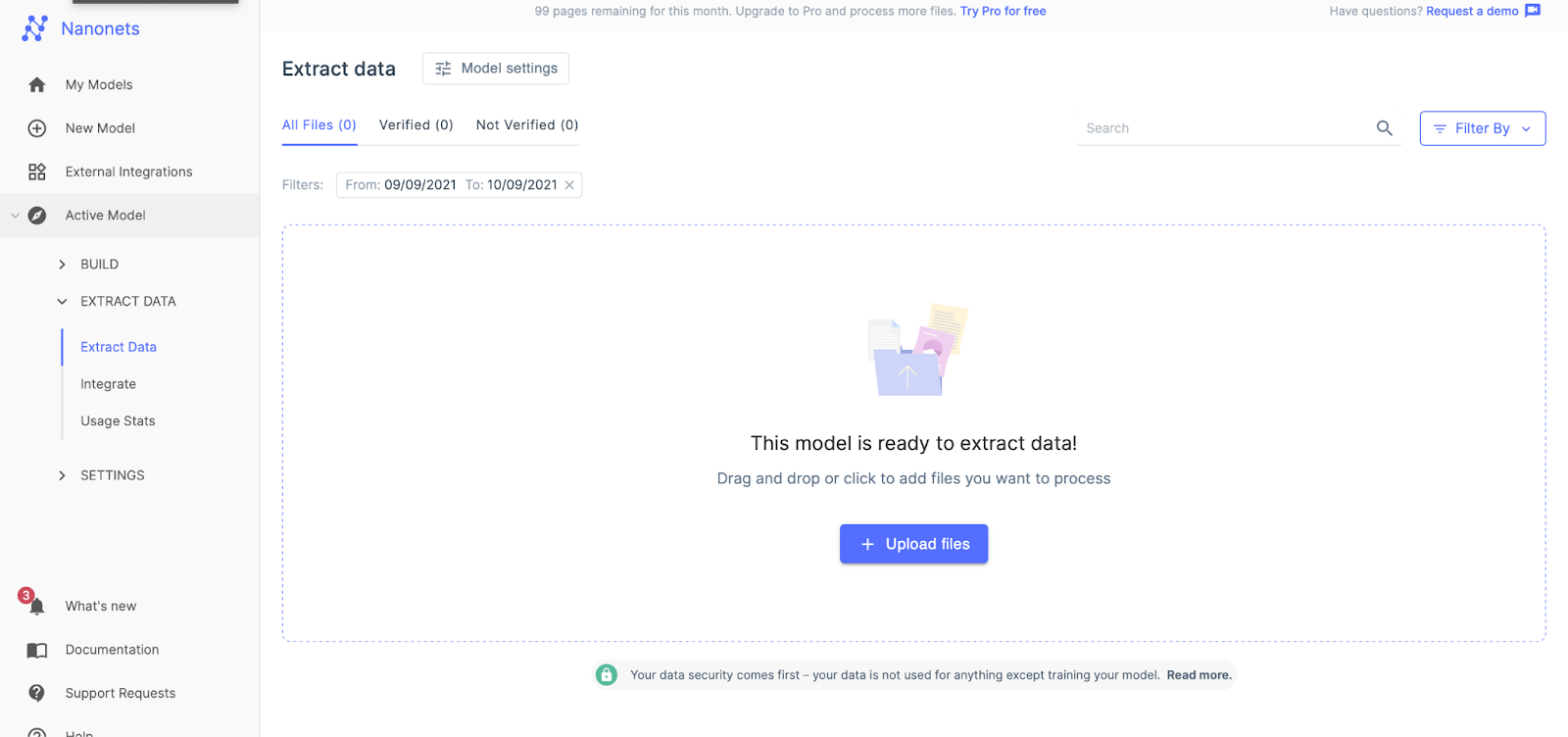
Step 4.
After processing, Nanonets can properly extract all the tabular information accurately, even skipping the empty spaces! The data can also be put into JSON for downloading and further computation.
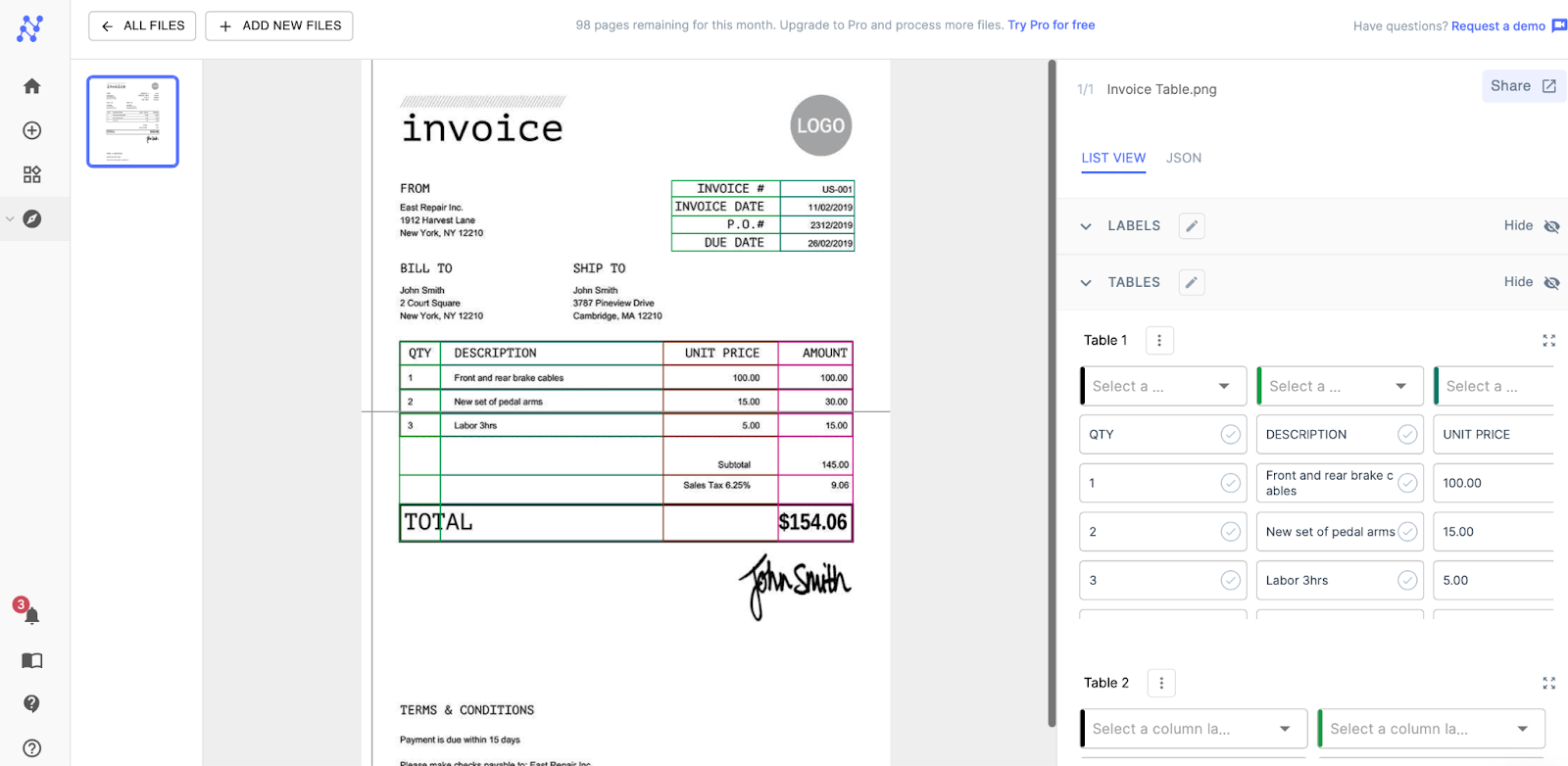
Conclusion
The trend of digitalization is taking place in every industry, and converting scanned documents into machine-interpretable encodings is an important aspect of such transformation. Hopefully this article presents an in-depth overview of how some of the simple data extraction tasks from tables are performed while highlighting some novel technologies that have immense potential for more difficult image processing tasks.