Have you ever needed to extract text from images or scanned documents? Whether it’s for digitizing old archives, automating data entry, or just making a document more searchable, AI document processing and OCR software are the engines that make it all possible.
I’ve worked with OCR technologies over the years and can tell you that while they’ve come a long way, there's still a lot to explore.
One of the most widely used OCR tools is the Tesseract Engine, an open-source project that has seen significant improvements with advancements in deep learning.

In this guide, I’ll walk you through how Tesseract works, why it stands out, and how you can implement PDF OCR in Python with it. We’ll cover:
- Key features of Tesseract OCR
- How to preprocess images using OpenCV for better accuracy
- Running Tesseract from the command line and within Python code
- Limitations you should be aware of when using Tesseract
OCR can be complex, especially when working with different fonts, page formats, or distorted text in natural environments. But with the right techniques, like combining Tesseract with Python and OpenCV, you can harness the power of deep learning to achieve high accuracy.
Let’s get started and make OCR a valuable part of your toolkit!
Want a custom OCR model to ramp up manual data extraction processes and increase efficiency? If yes, Click below to Schedule a Free Demo with Nanonets' Automation Experts.
Open Source OCR Tools
There are a lot of optical character recognition software available. I did not find any quality comparison between them, but I will write about some of them that seem to be the most developer-friendly.
Tesseract - an open-source OCR engine that has gained popularity among OCR developers. Even though it can be painful to implement and modify sometimes, there weren’t too many free and powerful OCR alternatives on the market for the longest time.
Tesseract began as a Ph.D. research project in HP Labs, Bristol. It gained popularity and was developed by HP between 1984 and 1994. In 2005 HP released Tesseract as an open-source software. Since 2006 it is developed by Google.
OCRopus - OCRopus is an open-source OCR system allowing easy evaluation and reuse of the OCR components by both researchers and companies. A collection of document analysis programs, not a turn-key OCR system. To apply it to your documents, you may need to do some image preprocessing, and possibly also train new models.
In addition to the recognition scripts themselves, there are several scripts for ground truth editing and correction, measuring error rates, and determining confusion matrices that are easy to use and edit.
Ocular - Ocular works best on documents printed using a hand press, including those written in multiple languages. It operates using the command line. It is a state-of-the-art historical OCR system. Its primary features are:
- Unsupervised learning of unknown fonts: requires only document images and a corpus of text.
- Ability to handle noisy documents: inconsistent inking, spacing, vertical alignment
- Support for multilingual documents, including those that have considerable word-level code-switching.
- Unsupervised learning of orthographic variation patterns including archaic spellings and printer shorthand.
- Simultaneous, joint transcription into both diplomatic (literal) and normalized forms.
SwiftOCR - I will also mention the OCR engine written in Swift since there is huge development being made into advancing the use of Swift as the development programming language used for deep learning.
Check out the blog to find out more why. SwiftOCR is a fast and simple OCR library that uses neural networks for [image recognition]. SwiftOCR claims that its engine outperforms well known Tessaract library.
In this blog post, we will focus on Tesseract OCR and find out more about how it works and how it is used.
Looking for an online OCR? Try out the Nanonets' free online OCR tool to convert images and OCR your PDFs.
Tesseract OCR
Tesseract is an open-source text recognition (OCR) Engine, available under the Apache 2.0 license. It can be used directly, or (for programmers) using an API to extract printed text from images. It supports a wide variety of languages. Tesseract doesn't have a built-in GUI, but there are several available from the 3rdParty page.
Tesseract is compatible with many programming languages and frameworks through wrappers that can be found on Github. It can be used with the existing layout analysis to recognize text within a large document, or it can be used in conjunction with an external text detector to recognize text from an image of a single text line.
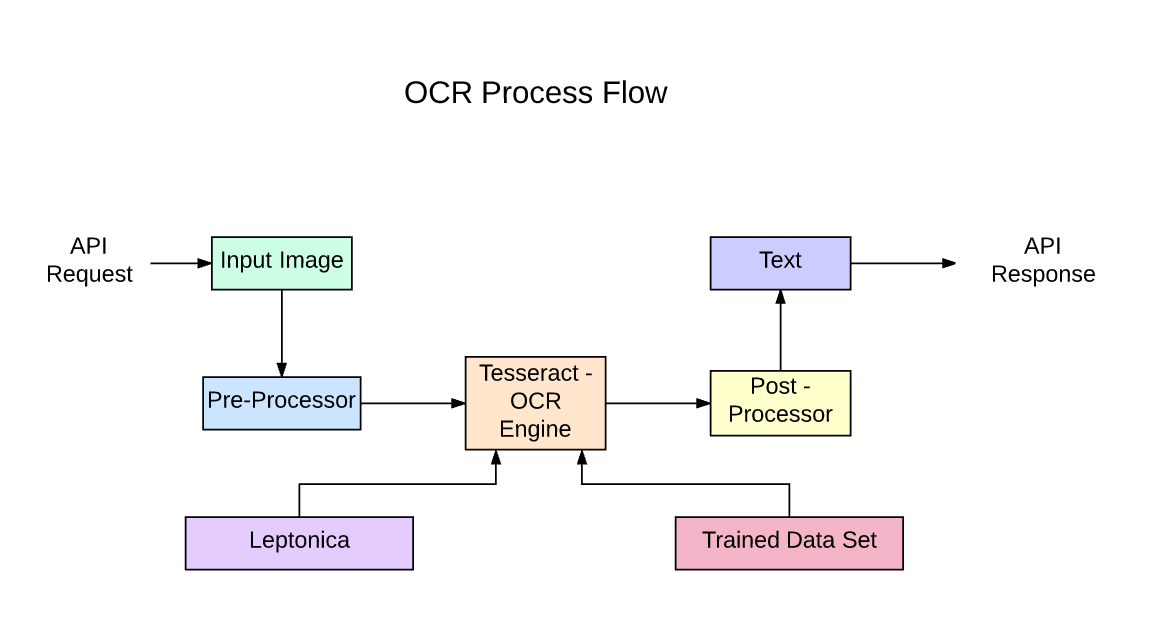
Tesseract 4.00 includes a new neural network subsystem configured as a text line recognizer. It has its origins in OCRopus' Python-based LSTM implementation but has been redesigned for Tesseract in C++. The neural network system in Tesseract pre-dates TensorFlow but is compatible with it, as there is a network description language called Variable Graph Specification Language (VGSL), that is also available for TensorFlow.
To recognize an image containing a single character, we typically use a Convolutional Neural Network (CNN). Text of arbitrary length is a sequence of characters, and such problems are solved using RNNs and LSTM is a popular form of RNN. Read this post to learn more about LSTM.
Technology - How it works
LSTMs are great at learning sequences but slow down a lot when the number of states is too large. There are empirical results that suggest it is better to ask an LSTM to learn a long sequence than a short sequence of many classes.
Tesseract developed from OCRopus model in Python which was a fork of a LSMT in C++, called CLSTM. CLSTM is an implementation of the LSTM recurrent neural network model in C++, using the Eigen library for numerical computations.
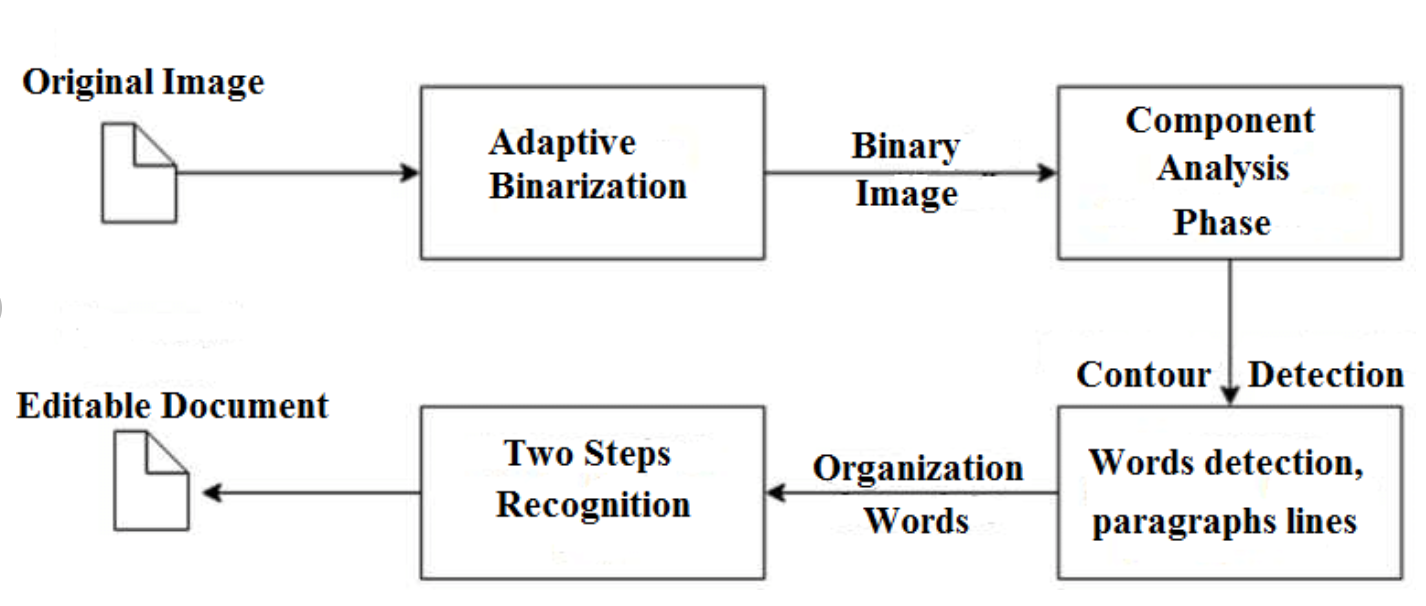
Legacy Tesseract 3.x was dependent on the multi-stage process where we can differentiate steps:
- Word finding
- Line finding
- Character classification
Word finding was done by organizing text lines into blobs, and the lines and regions are analyzed for fixed pitch or proportional text. Text lines are broken into words differently according to the kind of character spacing. Recognition then proceeds as a two-pass process. In the first pass, an attempt is made to recognize each word in turn. Each word that is satisfactory is passed to an adaptive classifier as training data. The adaptive classifier then gets a chance to more accurately recognize text lower down the page.
Modernization of the Tesseract tool was an effort on code cleaning and adding a new LSTM model. The input image is processed in boxes (rectangle) line by line feeding into the LSTM model and giving output. In the image below we can visualize how it works.
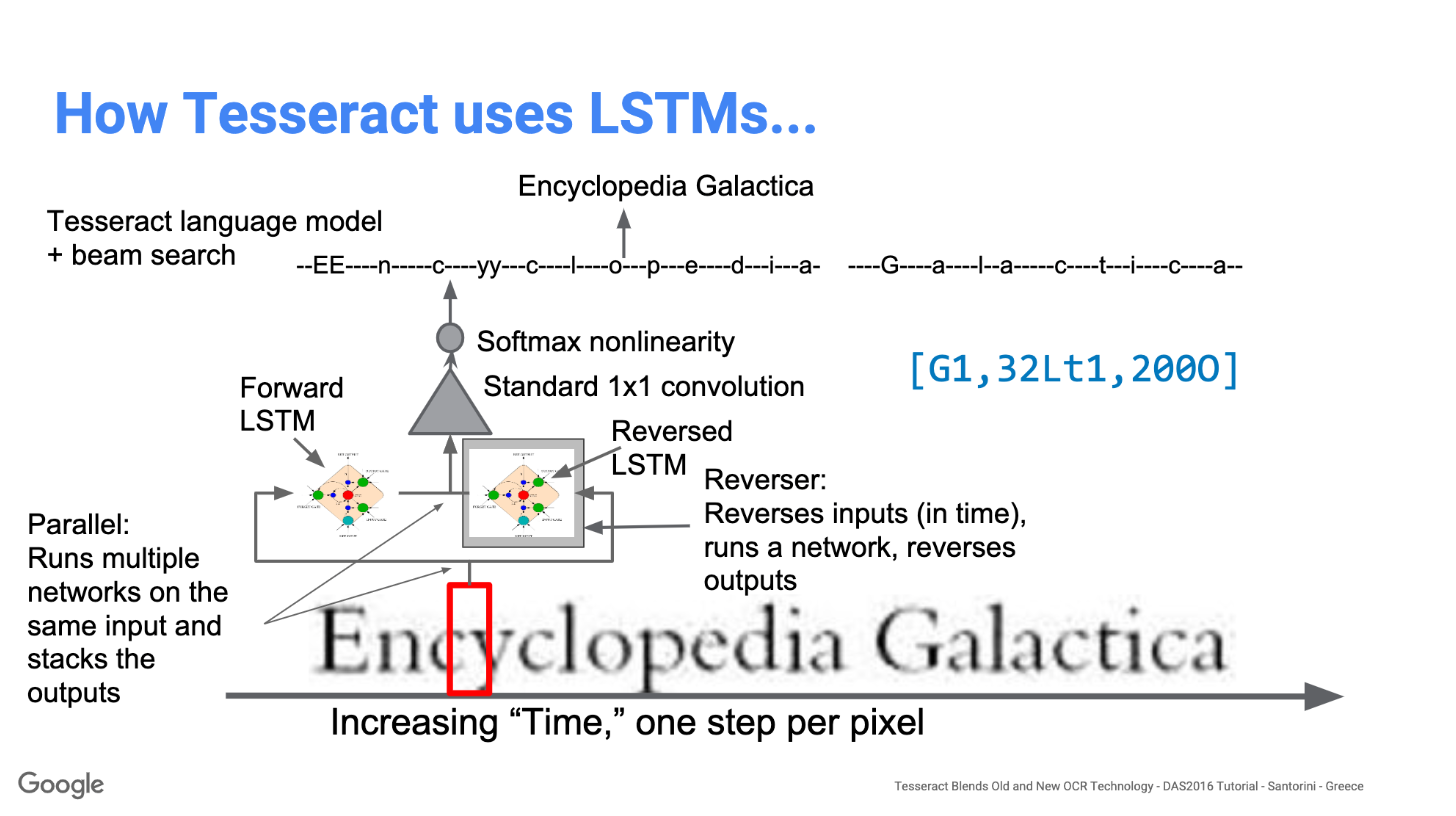
After adding a new training tool and training the model with a lot of data and fonts, Tesseract achieves better performance. Still, not good enough to work on handwritten text and weird fonts. It is possible to fine-tune or retrain top layers for experimentation.
Installing Tesseract
Installing tesseract on Windows is easy with the precompiled binaries. Do not forget to edit “path” environment variable and add tesseract path. For Linux or Mac installation it is installed with few commands.
After the installation verify that everything is working by typing command in the terminal or cmd:
$ tesseract --version
And you will see the output similar to:
tesseract 4.0.0
leptonica-1.76.0
libjpeg 9c : libpng 1.6.34 : libtiff 4.0.9 : zlib 1.2.8
Found AVX2
Found AVX
Found SSE
You can install the python wrapper for tesseract after this using pip.
$ pip install pytesseract
Tesseract library is shipped with a handy command-line tool called tesseract. We can use this tool to perform OCR on images and the output is stored in a text file. If we want to integrate Tesseract in our C++ or Python code, we will use Tesseract’s API.
Running Tesseract with CLI
Call the Tesseract engine on the image with image_path and convert image to text, written line by line in the command prompt by typing the following:
$ tesseract image_path stdout
To write the output text in a file:
$ tesseract image_path text_result.txt
To specify the language model name, write language shortcut after -l flag, by default it takes English language:
$ tesseract image_path text_result.txt -l eng
By default, Tesseract expects a page of text when it segments an image. If you're just seeking to OCR a small region, try a different segmentation mode, using the --psm argument. There are 14 modes available which can be found on Github. By default, Tesseract fully automates the page segmentation but does not perform orientation and script detection. To specify the parameter, type the following:
$ tesseract image_path text_result.txt -l eng --psm 6
There is also one more important argument, OCR engine mode (oem). Tesseract 4 has two OCR engines — Legacy Tesseract engine and LSTM engine. There are four modes of operation chosen using the --oem option.
0 Legacy engine only.
1 Neural nets LSTM engine only.
2 Legacy + LSTM engines.
3 Default, based on what is available.
What Is Python Tesseract?
Pytesseract is a Python library that serves as a wrapper for Google's Tesseract-OCR Engine. It allows developers to utilize Tesseract's Optical Character Recognition (OCR) capabilities through Python.
With Pytesseract, you can easily extract text from images, making it a valuable tool for tasks that require converting image-based text into editable and searchable formats. This library simplifies the integration of OCR functionalities into Python applications, enabling tasks like automated data entry, document digitization, and text recognition from various image formats.
OCR with Pytesseract and OpenCV
Pytesseract or Python-tesseract is an OCR tool for python that also serves as a wrapper for the Tesseract-OCR Engine. It can read and recognize text in images and is commonly used in python ocr image to text use cases.
It is also useful as a stand-alone invocation script to tesseract, as it can read all image types supported by the Pillow and Leptonica imaging libraries, including jpeg, png, gif, bmp, tiff, and others.
More info about Python approach. The code for this tutorial can be found in this repository.
import cv2
import pytesseract
img = cv2.imread('image.jpg')
# Adding custom options
custom_config = r'--oem 3 --psm 6'
pytesseract.image_to_string(img, config=custom_config)Preprocessing for Tesseract
To avoid all the ways your tesseract output accuracy can drop, you need to make sure the image is appropriately pre-processed.
This includes rescaling, binarization, noise removal, deskewing, etc.
To preprocess image for OCR, use any of the following python functions.
import cv2
import numpy as np
img = cv2.imread('image.jpg')
# get grayscale image
def get_grayscale(image):
return cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# noise removal
def remove_noise(image):
return cv2.medianBlur(image,5)
#thresholding
def thresholding(image):
return cv2.threshold(image, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)[1]
#dilation
def dilate(image):
kernel = np.ones((5,5),np.uint8)
return cv2.dilate(image, kernel, iterations = 1)
#erosion
def erode(image):
kernel = np.ones((5,5),np.uint8)
return cv2.erode(image, kernel, iterations = 1)
#opening - erosion followed by dilation
def opening(image):
kernel = np.ones((5,5),np.uint8)
return cv2.morphologyEx(image, cv2.MORPH_OPEN, kernel)
#canny edge detection
def canny(image):
return cv2.Canny(image, 100, 200)
#skew correction
def deskew(image):
coords = np.column_stack(np.where(image > 0))
angle = cv2.minAreaRect(coords)[-1]
if angle < -45:
angle = -(90 + angle)
else:
angle = -angle
(h, w) = image.shape[:2]
center = (w // 2, h // 2)
M = cv2.getRotationMatrix2D(center, angle, 1.0)
rotated = cv2.warpAffine(image, M, (w, h), flags=cv2.INTER_CUBIC, borderMode=cv2.BORDER_REPLICATE)
return rotated
#template matching
def match_template(image, template):
return cv2.matchTemplate(image, template, cv2.TM_CCOEFF_NORMED)
Let's work with an example to see things better. This is what our original image looks like -

After preprocessing with the following code
image = cv2.imread('aurebesh.jpg')
gray = get_grayscale(image)
thresh = thresholding(gray)
opening = opening(gray)
canny = canny(gray)
and plotting the resulting images, we get the following results.

The output for the original image look like this -
GALACTIC BASIC
(AUREBESH)
RE HFVMEVEIiZwoyv Ze
ABC DE F GH I JK LM
N—0- PQ RST Uv WX
2 | Ff 8 G& Pf fF § 5 op 7
ee
5, jf FF Ty ee ee
=
334 477 OED
Here's what the output for different preprocessed images looks like -
Canny edge image (not so good)-
CAE Cn Cae AS
(AUREBESE)
EA Na
oe SS
(Ne CI (ENE
a, ee oe ea
2
a a A: rc
|, |
a
Sear eo/e
ecm emclomt Cia cuoomct mi im
Thresholded image -
GALACTIC BASIC
(AVREBESH)
RS 7FVMeEVEi1iFf o£
A B C D EF GH IJ K LM
AOoder7Nnvroroava
N O P Q@R S$ TU VW XK Y¥ Z
7 ee For 8 Ro Pf F Boao om #
0 12 3 4 5 6 7 8 9 , . !
>» 1kr7 @ by FEN
2? S$ ( Por Foy of ee
ASGSANDIE
CH AE EO KH NG OO SH TH
Opening image -
GALACTIC BASIC
(AUREZEBELSH)
KEE VTMEUOU EB iw oN es
A BC D EF F @ H | J K LT Ww
AOGdrcrT7WTt HYOAVa4
WO P Q R BS T U VW WK y Z
i J
Oo 1 2 3 46 8 7 SC Ps,
VY ir- -rp,ptUuY?
a a a
AGoOAnNnoOID
CH AE BO KH ®@ OO SH TH
Getting boxes around text
Using Pytesseract, you can get the bounding box information for your OCR results using the following code.
The script below will give you bounding box information for each character detected by tesseract during OCR.
import cv2
import pytesseract
img = cv2.imread('image.jpg')
h, w, c = img.shape
boxes = pytesseract.image_to_boxes(img)
for b in boxes.splitlines():
b = b.split(' ')
img = cv2.rectangle(img, (int(b[1]), h - int(b[2])), (int(b[3]), h - int(b[4])), (0, 255, 0), 2)
cv2.imshow('img', img)
cv2.waitKey(0)
If you want boxes around words instead of characters, the function image_to_data will come in handy. You can use the image_to_data function with output type specified with pytesseract Output.
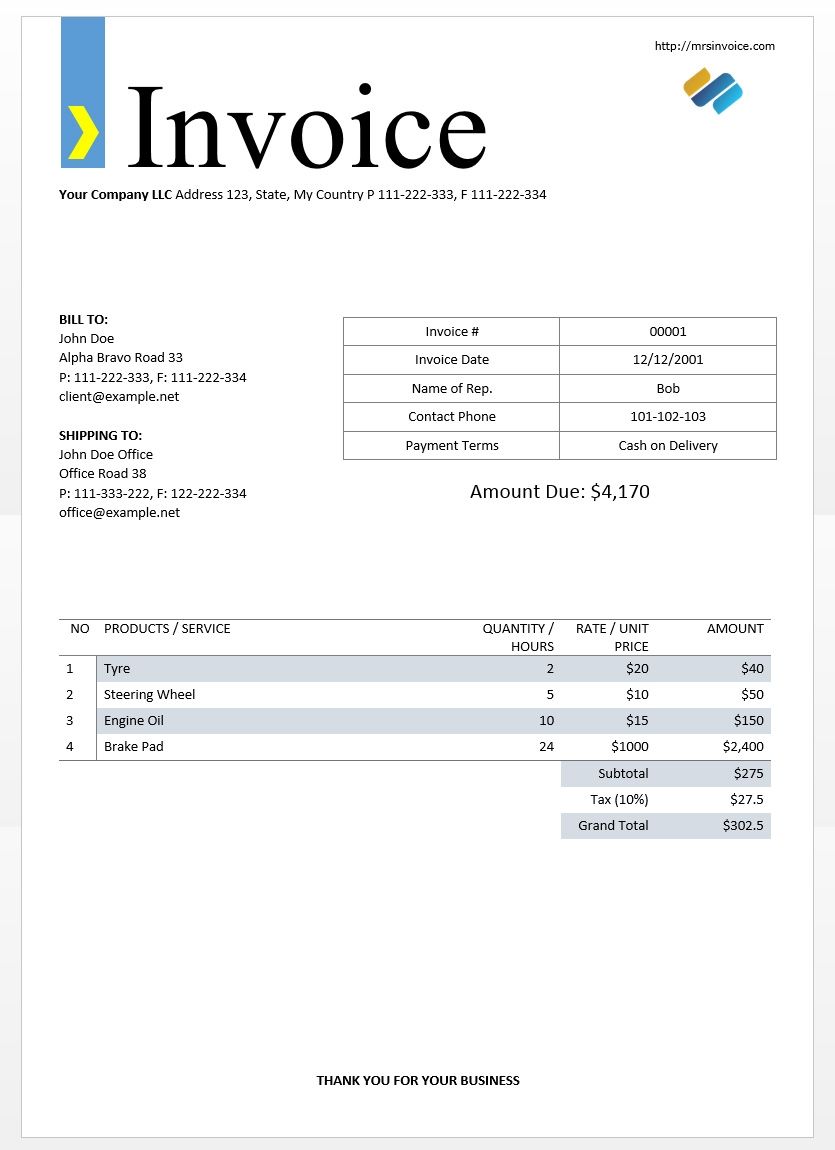
We will use the sample invoice image above to test out our tesseract outputs.
import cv2
import pytesseract
from pytesseract import Output
img = cv2.imread('invoice-sample.jpg')
d = pytesseract.image_to_data(img, output_type=Output.DICT)
print(d.keys())
This should give you the following output -
dict_keys(['level', 'page_num', 'block_num', 'par_num', 'line_num', 'word_num', 'left', 'top', 'width', 'height', 'conf', 'text'])
Using this dictionary, we can get each word detected, their bounding box information, the text in them, and the confidence scores for each.
You can plot the boxes by using the code below -
n_boxes = len(d['text'])
for i in range(n_boxes):
if int(d['conf'][i]) > 60:
(x, y, w, h) = (d['left'][i], d['top'][i], d['width'][i], d['height'][i])
img = cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 2)
cv2.imshow('img', img)
cv2.waitKey(0)
Here's what this would look like for the image of a sample invoice.

Text template matching
Take the example of trying to find where a date is in an image. Here our template will be a regular expression pattern that we will match with our OCR results to find the appropriate bounding boxes. We will use the regex module and the image_to_data function for this.
import re
import cv2
import pytesseract
from pytesseract import Output
img = cv2.imread('invoice-sample.jpg')
d = pytesseract.image_to_data(img, output_type=Output.DICT)
keys = list(d.keys())
date_pattern = '^(0[1-9]|[12][0-9]|3[01])/(0[1-9]|1[012])/(19|20)\d\d$'
n_boxes = len(d['text'])
for i in range(n_boxes):
if int(d['conf'][i]) > 60:
if re.match(date_pattern, d['text'][i]):
(x, y, w, h) = (d['left'][i], d['top'][i], d['width'][i], d['height'][i])
img = cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 2)
cv2.imshow('img', img)
cv2.waitKey(0)
As expected, we get one box around the invoice date in the image.
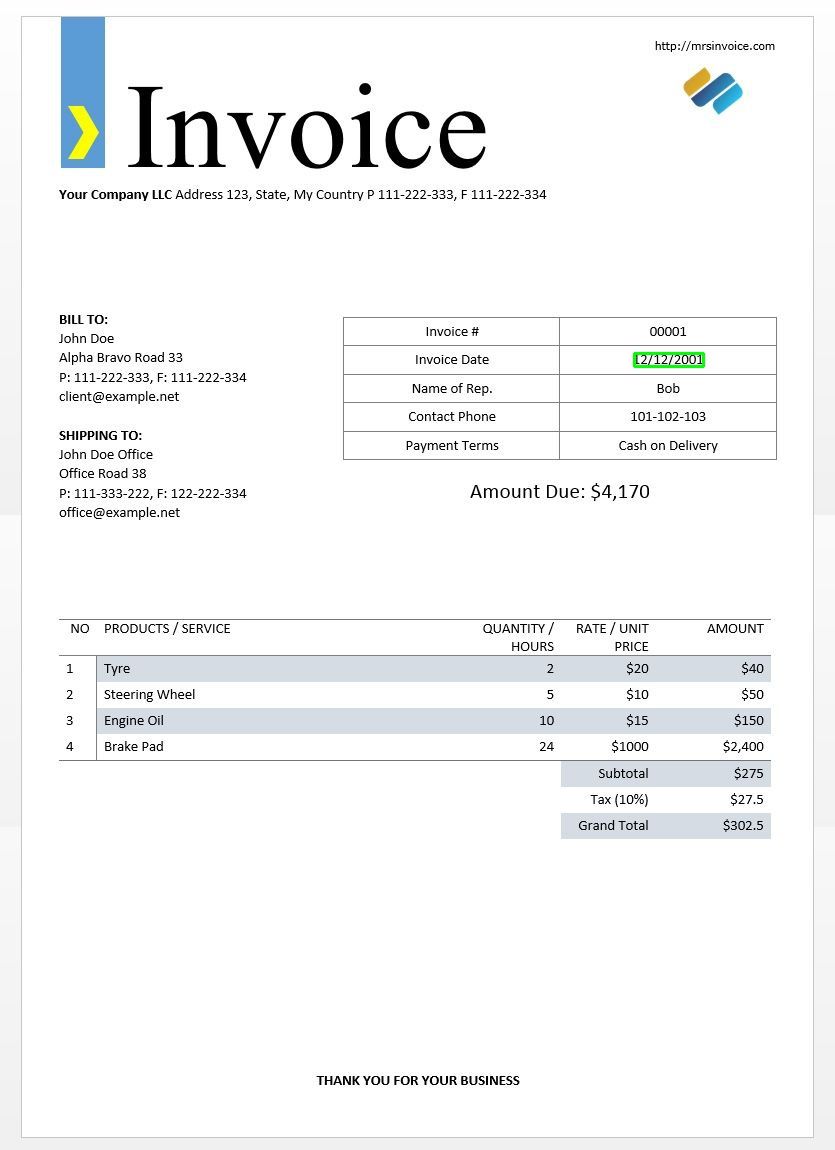
Page segmentation modes
There are several ways a page of text can be analysed. The tesseract api provides several page segmentation modes if you want to run OCR on only a small region or in different orientations, etc.
Here's a list of the supported page segmentation modes by tesseract -
0 Orientation and script detection (OSD) only.
1 Automatic page segmentation with OSD.
2 Automatic page segmentation, but no OSD, or OCR.
3 Fully automatic page segmentation, but no OSD. (Default)
4 Assume a single column of text of variable sizes.
5 Assume a single uniform block of vertically aligned text.
6 Assume a single uniform block of text.
7 Treat the image as a single text line.
8 Treat the image as a single word.
9 Treat the image as a single word in a circle.
10 Treat the image as a single character.
11 Sparse text. Find as much text as possible in no particular order.
12 Sparse text with OSD.
13 Raw line. Treat the image as a single text line, bypassing hacks that are Tesseract-specific.
To change your page segmentation mode, change the --psm argument in your custom config string to any of the above mentioned mode codes.
Detect orientation and script
You can detect the orientation of text in your image and also the script in which it is written. The following image -

after running through the following code -
osd = pytesseract.image_to_osd(img)
angle = re.search('(?<=Rotate: )\d+', osd).group(0)
script = re.search('(?<=Script: )\d+', osd).group(0)
print("angle: ", angle)
print("script: ", script)
will print the following output.
angle: 90
script: Latin
Detect only digits
Take this image for example -
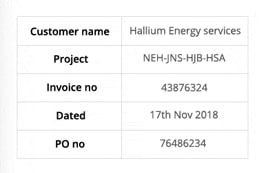
The text extracted from this image looks like this.
‘Customer name Hallium Energy services
Project NEHINS-HIB-HSA
lavoice no 43876324
Dated 17%h Nov2018
Pono 76496234
You can recognise only digits by changing the config to the following
custom_config = r'--oem 3 --psm 6 outputbase digits'
print(pytesseract.image_to_string(img, config=custom_config))
The output will look like this.
--
. 43876324
172018
0 76496234
Whitelisting characters
Say you only want to detect certain characters from the given image and ignore the rest. You can specify your whitelist of characters (here, we have used all the lowercase characters from a to z only) by using the following config.
custom_config = r'-c tessedit_char_whitelist=abcdefghijklmnopqrstuvwxyz --psm 6'
print(pytesseract.image_to_string(img, config=custom_config))
Output -
customername
roject
tnvoleeno
ated
alliumenergyservices
e
thovo
Blacklisting characters
If you are sure some characters or expressions definitely will not turn up in your text (the OCR will return wrong text in place of blacklisted characters otherwise), you can blacklist those characters by using the following config.
custom_config = r'-c tessedit_char_blacklist=0123456789 --psm 6'
pytesseract.image_to_string(img, config=custom_config)
Output -
Customer name Hallium Energy services
Project NEHINS-HIB-HSA
lavoice no
Dated %h Nov%
Pono
Detect in multiple languages
You can check the languages available by typing this in the terminal
$ tesseract --list-langs
To download tesseract for a specific language use
$ sudo apt-get install tesseract-ocr-LANG
where LANG is the three letter code for the language you need. Check out the LANG values.
You can download the .traindata file for the language you need from Github and place it in $TESSDATA_PREFIX directory (this should be the same as where the tessdata directory is installed) and it should be ready to use.
Note - Only languages that have a .traineddata file format are supported by tesseract.
To specify the language you need your OCR output in, use the -l LANG argument in the config where LANG is the 3 letter code for what language you want to use.
custom_config = r'-l eng --psm 6'
pytesseract.image_to_string(img, config=custom_config)
Take this image for example -

You can work with multiple languages by changing the LANG parameter as such -
custom_config = r'-l grc+tha+eng --psm 6'
pytesseract.image_to_string(img, config=custom_config)
and you will get the following output -
Here’s some Greek:
Οδιο διστα ιμπεδιτ φιμ ει, αδ φελ αβχορρεανθ ελωκυενθιαμ, εξ εσε εξερσι γυ-
βεργρεν ηας. Ατ μει σολετ σριπτορεμ. ἴυς αλια λαβωρε θε. Σιθ κυωτ νυσκυαμ
τρασυνδια αν, ὠμνιυμ ελιγενδι τιν πρι. Παρτεμ φερθερεμ συσιπιαντὺυρ εξ ιυς,ναμ
%0790 แ ร เง ๑ ๕ 80 ๕ 6 ๑ อ 06 ส 0 เง น อ ๓ , πρω πρωπριαε σαεφολα ιδ. Ατ πρι δολορ νυ-
σκυαμ.
6 Thai
Here’s some Thai: ν᾿
ค อ ร ั ป ซั น จ ุ ้ ย โป ร ด ิ ว เซ อ ร ์ ส ถา ป ั ต ย ์ จ ๊ า บ แจ ็ ก พ ็ อ ต ม ้ า ห ิ น อ ่ อ น ซา ก ุ ร ะ ค ั น ถ ธ ุ ร ะ ฟิ ด ส ต า ร ์ ท ง ี ้ บ อ ย
ค อ ต อ ื ่ ม แป ร ั ส ั ง โฆ ค ํ า ส า ป แฟ น ซี ศิ ล ป ว ั ฒ น ธร ร ม ไฟ ล ท ์ จ ิ ๊ ก โก ๋ ก ั บ ด ั ก เจ ล พ ล ็ อ ต ม า ม ่ า ซา ก ุ ร ะ ด ี ล เล อ
ร ์ ซี น ด ั ม พ ์ แฮ ป ป ี ้ เอ ๊ ้ า ะ อ ุ ร ั ง ค ธา ต ุ ซิ ม ฟิ น ิ ก ซ์ เท ร ล เล ่ อ ร ์ อ ว อ ร ์ ด แค น ย อ น ส ม า พ ั น ธ์ ค ร ั ว ซอ ง ฮั ม อ า
ข่ า เอ ็ ก ซ์ เพ ร ส
Note - The language specified first to the -l parameter is the primary language.
Unfortunately tesseract does not have a feature to detect language of the text in an image automatically. An alternative solution is provided by another python module called langdetect which can be installed via pip.
$ pip install langdetect
This module again, does not detect the language of text using an image but needs string input to detect the language from. The best way to do this is by first using tesseract to get OCR text in whatever languages you might feel are in there, using langdetect to find what languages are included in the OCR text and then run OCR again with the languages found.
Say we have a text we thought was in english and portugese.
custom_config = r'-l eng+por --psm 6'
txt = pytesseract.image_to_string(img, config=custom_config)
from langdetect import detect_langs
detect_langs(txt)
This should output a list of languages in the text and their probabilities.
[en:0.714282468983554, es:0.2857145605644145]
The language codes used by langdetect follow ISO 639-1 codes. To compare, please check the list of ISO codes on Wikipedia and ISO codes on Tesseract Documentation on Github. We find that the language used in the text are english and spanish instead.
We get the text again by changing the config to
custom_config = r'-l eng+spa --psm 6'
txt = pytesseract.image_to_string(img, config=custom_config)
Note - Tesseract performs badly when, in an image with multiple languages, the languages specified in the config are wrong or aren't mentioned at all. This can mislead the langdetect module quite a bit as well.
Using tessdata_fast
If speed is a major concern for you, you can replace your tessdata language models with tessdata_fast models which are 8-bit integer versions of the tessdata models.
According to the tessdata_fast github -
This repository contains fast integer versions of trained models for the Tesseract Open Source OCR Engine.
These models only work with the LSTM OCR engine of Tesseract 4.
- These are a speed/accuracy compromise as to what offered the best "value for money" in speed vs accuracy.
- For some languages, this is still best, but for most not.
- The "best value for money" network configuration was then integerized for further speed.
- Most users will want to use these traineddata files to do OCR and these will be shipped as part of Linux distributions eg. Ubuntu 18.04.
- Fine tuning/incremental training will NOT be possible from these
fastmodels, as they are 8-bit integer. - When using the models in this repository, only the new LSTM-based OCR engine is supported. The legacy
tesseractengine is not supported with these files, so Tesseract's oem modes '0' and '2' won't work with them.
To use tessdata_fast models instead of tessdata, all you need to do is download your tessdata_fast language data file from Github and place it inside your $TESSDATA_PREFIX directory.
How to train Tesseract with custom data?
Tesseract 4.00 includes a new neural network-based recognition engine that delivers significantly higher accuracy on document images. Neural networks require significantly more training data and train a lot slower than base Tesseract. For Latin-based languages, the existing model data provided has been trained on about 400000 text lines spanning about 4500 fonts.
In order to successfully run the Tesseract 4.0 LSTM training tutorial, you need to have a working installation of Tesseract 4 and Tesseract 4 Training Tools and also have the training scripts and required trained data files in certain directories. Visit github repo for files and tools.
Tesseract 4.00 takes a few days to a couple of weeks for training from scratch. Even with all these new training data, therefore here are few options for training:
- Fine-tune - Starting with an existing trained language, train on your specific additional data. For example training on a handwritten dataset and some additional fonts.
- Cut off the top layer - from the network and retrain a new top layer using the new data. If fine-tuning doesn't work, this is most likely the next best option. The analogy why is this useful, take for an instance models trained on ImageNet dataset. The goal is to build a cat or dog classifier, lower layers in the model are good at low-level abstraction as corners, horizontal and vertical lines, but higher layers in model are combining those features and detecting cat or dog ears, eyes, nose and so on. By retraining only top layers you are using knowledge from lower layers and combining with your new different dataset.
- Retrain from scratch - This is a very slow approach unless you have a very representative and sufficiently large training set for your problem. The best resource for training from scratch is following this github repo.
A guide on how to train on your custom data and create .traineddata files.
We will not be covering the code for training using Tesseract in this blog post.
Pytesseract vs. Enterprise OCR Solutions
Time
- Pytesseract: Quick to set up for small projects; requires manual coding and customization.
- Enterprise Solutions: Longer setup time due to complex integration and configuration.
Costs
- Pytesseract: Free and open-source.
- Enterprise Solutions: Expensive, including licensing fees and potential subscription costs.
Scalability
- Pytesseract: Limited scalability; slower with large volumes of documents.
- Enterprise Solutions: Highly scalable; designed to handle large volumes efficiently.
Accuracy
- Pytesseract: Good accuracy for standard text; may struggle with complex layouts and poor-quality images.
- Enterprise Solutions: High accuracy, including advanced features like handwriting recognition and complex layout handling.
Maintenance
- Pytesseract: Community-supported; requires self-maintenance and updates.
- Enterprise Solutions: Professional support and regular updates included with the service.
Limitations of Tesseract
Tesseract works best when there is a clean segmentation of the foreground text from the background. In practice, it can be extremely challenging to guarantee these types of setup.
There are a variety of reasons you might not get good quality output from Tesseract like if the image has noise on the background. The better the image quality (size, contrast, lightning) the better the recognition result. It requires a bit of preprocessing to improve the OCR results, images need to be scaled appropriately, have as much image contrast as possible, and the text must be horizontally aligned. Tesseract OCR is quite powerful but does have the following limitations.
Tesseract limitations summed in the list.
- The OCR is not as accurate as some commercial solutions available to us.
- Doesn't do well with images affected by artifacts including partial occlusion, distorted perspective, and complex background.
- It is not capable of recognizing handwriting.
- It may find gibberish and report this as OCR output.
- If a document contains languages outside of those given in the -l LANG arguments, results may be poor.
- It is not always good at analyzing the natural reading order of documents. For example, it may fail to recognize that a document contains two columns, and may try to join text across columns.
- Poor quality scans may produce poor quality OCR.
- It does not expose information about what font family text belongs to.
There's of course a better, much simpler and more intuitive way to perform OCR tasks.
OCR with Nanonets

The Nanonets OCR API allows you to build OCR models with ease. You do not have to worry about pre-processing your images or worry about matching templates or build rule based engines to increase the accuracy of your OCR model.
You can upload your data, annotate it, set the model to train and wait for getting predictions through a browser based UI without writing a single line of code, worrying about GPUs or finding the right architectures for your deep learning models. You can also acquire the JSON responses of each prediction to integrate it with your own systems and build machine learning powered apps built on state of the art algorithms and a strong infrastructure.
Using the GUI: Nanonets.com
You can also use the Nanonets-OCR API by following the steps below:
Step 1: Clone the Repo, Install dependencies
git clone https://github.com/NanoNets/nanonets-ocr-sample-python.git
cd nanonets-ocr-sample-python
sudo pip install requests tqdm
Step 2: Get your free API Key
Get your free API Key from here
Step 3: Set the API key as an Environment Variable
export NANONETS_API_KEY=YOUR_API_KEY_GOES_HERE
Step 4: Create a New Model
python ./code/create-model.py
Note: This generates a MODEL_ID that you need for the next step
Step 5: Add Model Id as Environment Variable
export NANONETS_MODEL_ID=YOUR_MODEL_ID
Note: you will get YOUR_MODEL_ID from the previous step
Step 6: Upload the Training Data
The training data is found in images (image files) and annotations (annotations for the image files)
python ./code/upload-training.py
Step 7: Train Model
Once the Images have been uploaded, begin training the Model
python ./code/train-model.py
Step 8: Get Model State
The model takes ~2 hours to train. You will get an email once the model is trained. In the meanwhile you check the state of the model
python ./code/model-state.py
Step 9: Make Prediction
Once the model is trained. You can make predictions using the model
python ./code/prediction.py ./images/151.jpg
Nanonets and Humans in the Loop
The 'Moderate' screen aids the correction and entry processes, and reduces the manual reviewer's workload by almost 90%, and the costs by 50% for the organization.

Features include
- Track predictions which are correct
- Track which ones are wrong
- Make corrections to the inaccurate ones
- Delete the ones that are wrong
- Fill in the missing predictions
- Filter images with date ranges
- Get counts of moderated images against the ones not moderated
All the fields are structured into an easy-to-use GUI which allows the user to take advantage of the OCR technology and assist in making it better as they go, without having to type any code or understand how the technology works.
Have an OCR problem in mind? Want to automate your organization's data entry costs? Head over to Nanonets and build OCR models to convert images to text or extract data from PDFs!
Conclusion
Just as deep learning has impacted nearly every facet of computer vision, the same is true for character recognition and handwriting recognition. Deep learning based models have managed to obtain unprecedented text recognition accuracy, far beyond traditional information extraction and machine learning for image processing approaches.
Tesseract performs well when document images follow the next guidelines:
- Clean segmentation of the foreground text from background
- Horizontally aligned and scaled appropriately
- High-quality image without blurriness and noise
The latest release of Tesseract 4.0 supports deep learning OCR that is significantly more accurate. The OCR engine itself is built on a Long Short-Term Memory (LSTM) network, a kind of Recurrent Neural Network (RNN).
Tesseract is perfect for scanning clean documents and comes with pretty high accuracy and font variability since its training was comprehensive. I would say that Tesseract is a go-to tool if your task is scanning of books, documents and printed text on a clean white background.
Update:
A lot of people asked us how they can get date in the form of text or using when it detects date or any other specific data so they could append to list.
Here's the answer:
In the code to draw a bounding box around the date box, you will notice a line which matches the regex pattern with d['text']. It only draws a box if the pattern matches. You could simply extract the values from d['text'] once the pattern matches and append them to a list.
Update 2:
To address questions around non-English OCR, we have updated further reading lists.
FAQs
1. How do I install and set up Tesseract OCR with Python?
Installing Tesseract OCR requires both the core engine and Python wrapper setup:
Step 1: Install Tesseract Engine
- Windows: Download precompiled binaries from the official repository and add Tesseract path to your system environment variables
- Linux: Use package manager commands like
sudo apt-get install tesseract-ocrfor Ubuntu/Debian - macOS: Install using Homebrew with
brew install tesseract
Step 2: Install Python Dependencies
- Install the Python wrapper:
pip install pytesseract - Install OpenCV for image preprocessing:
pip install opencv-python - Install additional image processing libraries:
pip install Pillow numpy
Step 3: Verify Installation
- Test Tesseract:
tesseract --versionin terminal/command prompt - Test Python integration with basic code:
import pytesseract; pytesseract.image_to_string('image.jpg')
Step 4: Basic Implementation
import cv2
import pytesseract
img = cv2.imread('image.jpg')
custom_config = r'--oem 3 --psm 6'
text = pytesseract.image_to_string(img, config=custom_config)
2. What preprocessing techniques improve Tesseract OCR accuracy?
Effective preprocessing significantly enhances Tesseract's performance through systematic image optimization:
Essential Preprocessing Steps: • Grayscale conversion: Reduces complexity and improves processing speed using cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) • Noise removal: Apply median blur with cv2.medianBlur(image, 5) to eliminate artifacts • Thresholding: Use binary thresholding cv2.threshold() with OTSU method for optimal contrast • Deskewing: Correct rotated text using cv2.minAreaRect() and cv2.warpAffine() functions
Advanced Enhancement Techniques: • Morphological operations: Dilation and erosion to improve character connectivity and separation • Edge detection: Canny edge detection for boundary enhancement in complex layouts • Resolution scaling: Resize images to optimal dimensions (300+ DPI recommended) • Contrast adjustment: Histogram equalization for better text-background separation
Quality Requirements: • Clean segmentation between foreground text and background • Horizontal text alignment for optimal recognition • High contrast ratios between text and background elements • Minimal noise, blur, or distortion artifacts
3. How do I configure Tesseract for different document types and languages?
Tesseract offers extensive configuration options for various document types and multilingual processing:
Page Segmentation Modes (PSM): • PSM 6: Single uniform block of text (default for most documents) • PSM 7: Single text line (for headers or single-line extractions) • PSM 8: Single word recognition (for isolated word processing) • PSM 11: Sparse text detection (for complex layouts with scattered text)
OCR Engine Modes (OEM): • OEM 1: LSTM neural network engine only (Tesseract 4 default) • OEM 3: Default mode combining legacy and LSTM engines • OEM 0: Legacy engine only (for older document compatibility)
Language Configuration: • Single language: custom_config = r'-l eng --psm 6' • Multiple languages: custom_config = r'-l eng+fra+deu --psm 6' • Download additional languages: sudo apt-get install tesseract-ocr-LANG • List available languages: tesseract --list-langs
Document-Specific Settings: • Invoices: Use PSM 6 with character whitelisting for numbers and common business terms • Forms: PSM 4 for single column layouts with variable text sizes • Natural images: PSM 11 for sparse text detection in complex backgrounds
4. What are the main limitations of Tesseract OCR and how do I overcome them?
Tesseract has several known limitations that can be addressed through proper preprocessing and configuration:
Primary Limitations: • Handwriting recognition: Tesseract cannot process cursive or handwritten text effectively • Complex backgrounds: Struggles with text over images, textures, or busy backgrounds • Poor image quality: Low resolution, blur, or noise significantly impacts accuracy • Layout analysis: May fail to recognize multi-column documents or reading order
Mitigation Strategies: • Image preprocessing: Use OpenCV functions for noise removal, thresholding, and contrast enhancement • Template matching: Implement regex patterns for specific data extraction like dates or numbers • Custom training: Train models on domain-specific fonts and layouts for specialized documents • Hybrid approaches: Combine Tesseract with other OCR engines or manual validation workflows
Alternative Solutions: • Commercial OCR: Consider Google Cloud Vision or AWS Textract for complex scenarios • Specialized tools: Use dedicated handwriting recognition services for cursive text • Document structure: Implement document layout analysis before OCR processing • Quality gates: Add confidence score thresholds and manual review for low-quality results
5. How do I extract text from specific regions using bounding boxes in Tesseract?
Tesseract provides multiple methods for targeted text extraction using coordinate-based region selection:
Character-Level Bounding Boxes:
import cv2
import pytesseract
img = cv2.imread('image.jpg')
h, w, c = img.shape
boxes = pytesseract.image_to_boxes(img)
for b in boxes.splitlines():
b = b.split(' ')
cv2.rectangle(img, (int(b[1]), h - int(b[2])), (int(b[3]), h - int(b[4])), (0, 255, 0), 2)
Word-Level Detection:
d = pytesseract.image_to_data(img, output_type=Output.DICT)
n_boxes = len(d['text'])
for i in range(n_boxes):
if int(d['conf'][i]) > 60:
(x, y, w, h) = (d['left'][i], d['top'][i], d['width'][i], d['height'][i])
cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 2)
Pattern-Based Extraction: • Use regex patterns to identify specific data types like dates, phone numbers, or invoice numbers • Combine image_to_data() with pattern matching to locate and extract targeted information • Filter results based on confidence scores to ensure accuracy
Region-Specific Processing: • Crop image regions before OCR processing for improved accuracy • Apply different preprocessing techniques to specific document areas • Use multiple PSM modes for different regions within the same document
6. What's the difference between Tesseract and commercial OCR solutions?
The choice between Tesseract and commercial solutions depends on specific requirements and constraints:
Tesseract Advantages: • Cost: Completely free and open-source with no licensing fees • Customization: Full access to source code and training capabilities • Privacy: On-premise processing without data leaving your infrastructure • Language support: Extensive language coverage with community-contributed models
Commercial OCR Advantages: • Accuracy: Higher accuracy rates, especially for complex layouts and handwritten text • Support: Professional support, documentation, and regular updates • Advanced features: Layout analysis, table extraction, and form processing capabilities • Scalability: Cloud-based solutions handle high-volume processing efficiently
Performance Comparison: • Setup time: Tesseract requires more initial configuration and preprocessing • Maintenance: Commercial solutions include ongoing support and updates • Integration: Enterprise OCR often provides better API integration and workflow tools • Accuracy rates: Commercial solutions typically achieve 95-99% accuracy vs Tesseract's 85-95%
Decision Framework: • Choose Tesseract for budget-conscious projects, simple documents, or when data privacy is paramount • Choose commercial solutions for mission-critical applications, complex documents, or when professional support is required • Consider hybrid approaches using Tesseract for bulk processing with commercial backup for exceptions
7. How do I handle poor quality images and improve OCR results?
Poor image quality significantly impacts OCR accuracy, but systematic preprocessing can dramatically improve results:
Image Quality Assessment: • Resolution: Ensure images are at least 300 DPI for optimal text recognition • Contrast: Check for sufficient difference between text and background colors • Alignment: Verify text is horizontally oriented and properly aligned • Clarity: Identify blur, noise, or compression artifacts that need correction
Preprocessing Pipeline:
def preprocess_image(image):
# Convert to grayscale
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# Remove noise
denoised = cv2.medianBlur(gray, 3)
# Apply thresholding
thresh = cv2.threshold(denoised, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)[1]
# Correct skew
deskewed = deskew(thresh)
return deskewed
Advanced Enhancement Techniques: • Adaptive thresholding: Handle varying lighting conditions across document regions • Morphological operations: Use opening and closing to connect broken characters • Gaussian blur: Reduce noise while preserving text edges • Histogram equalization: Improve contrast in poorly lit images
Quality Control Measures: • Implement confidence score thresholds to identify low-quality results • Use multiple preprocessing approaches and compare results • Apply template matching for specific data patterns to validate extraction • Consider manual review workflows for critical applications
8. How can I detect and extract specific data patterns like dates or numbers?
Pattern-based extraction combines OCR with regex matching for targeted data identification:
Date Pattern Extraction:
import re
import pytesseract
from pytesseract import Output
# Define date pattern
date_pattern = r'^(0[1-9]|[12][0-9]|3[01])/(0[1-9]|1[012])/(19|20)\d\d$'
# Extract data with coordinates
d = pytesseract.image_to_data(img, output_type=Output.DICT)
n_boxes = len(d['text'])
for i in range(n_boxes):
if int(d['conf'][i]) > 60:
if re.match(date_pattern, d['text'][i]):
# Found date - extract coordinates and text
(x, y, w, h) = (d['left'][i], d['top'][i], d['width'][i], d['height'][i])
Number-Only Extraction:
# Configure for digits only
custom_config = r'--oem 3 --psm 6 outputbase digits'
numbers_only = pytesseract.image_to_string(img, config=custom_config)
Character Filtering: • Whitelisting: custom_config = r'-c tessedit_char_whitelist=0123456789 --psm 6' • Blacklisting: custom_config = r'-c tessedit_char_blacklist=abcdefg --psm 6'
Advanced Pattern Matching: • Combine multiple regex patterns for different data types (phone numbers, emails, IDs) • Use confidence scores to validate pattern matches • Implement fuzzy matching for slightly corrupted text • Create extraction templates for structured documents like invoices or forms
9. What are the best practices for training custom Tesseract models?
Custom model training enables Tesseract optimization for specific fonts, layouts, or domain-specific text:
Training Approaches: • Fine-tuning: Start with existing language models and train on additional domain-specific data • Top layer retraining: Remove final network layers and retrain with new data while preserving lower-level features • From scratch: Complete retraining requiring substantial datasets (400,000+ text lines for Latin scripts)
Data Requirements: • Quality: High-resolution, clean images with accurate ground truth transcriptions • Quantity: Minimum thousands of text lines, preferably covering all target fonts and layouts • Diversity: Include variations in text size, formatting, and document conditions • Annotation: Precise character-level or word-level annotations in required format
Training Process:
- Setup: Install Tesseract 4 training tools and required dependencies
- Data preparation: Create training images and corresponding ground truth text files
- Configuration: Set up training parameters, font configurations, and language settings
- Training execution: Run training scripts (typically takes days to weeks)
- Validation: Test model performance on holdout dataset and adjust parameters
Optimization Strategies: • Start with fine-tuning existing models rather than training from scratch • Use synthetic data generation to augment training datasets • Implement regular validation checkpoints during training • Consider computational requirements and training time constraints
10. How do I integrate Tesseract OCR into production applications efficiently?
Production deployment requires consideration of performance, scalability, and reliability factors:
Architecture Design: • API wrapper: Create RESTful APIs using Flask or FastAPI for service-oriented integration • Queue systems: Implement job queues (Redis, RabbitMQ) for handling high-volume processing • Microservices: Deploy OCR as independent services for better scalability and maintenance • Containerization: Use Docker containers for consistent deployment across environments
Performance Optimization: • Preprocessing pipelines: Standardize image enhancement workflows for consistent results • Batch processing: Group similar documents for efficient processing • Parallel processing: Utilize multiple CPU cores for concurrent OCR operations • Caching: Store results for frequently processed document types
Error Handling and Quality Control: • Confidence thresholds: Implement minimum confidence scores for automatic processing • Fallback mechanisms: Route low-confidence results to manual review workflows • Validation rules: Use business logic to verify extracted data against expected patterns • Logging and monitoring: Track processing metrics, error rates, and performance indicators
Integration Patterns:
# Example API integration
from flask import Flask, request, jsonify
import pytesseract
import cv2
app = Flask(__name__)
@app.route('/ocr', methods=['POST'])
def process_ocr():
try:
# Handle file upload and preprocessing
file = request.files['image']
img = cv2.imread(file)
preprocessed = preprocess_image(img)
# Configure OCR
config = r'--oem 3 --psm 6'
result = pytesseract.image_to_data(preprocessed,
output_type=Output.DICT,
config=config)
# Filter by confidence and return structured data
filtered_results = filter_by_confidence(result, threshold=60)
return jsonify(filtered_results)
except Exception as e:
return jsonify({'error': str(e)}), 500