Ever wished you could talk directly to a PDF and get the information you need without wading through pages of text? With the power of ChatGPT and Language Learning Models (LLMs), this is now a reality.
In this blog, we’ll show you exactly how to make it happen. From reading PDFs with ChatGPT to chatting with PDFs directly, we’ll guide you through it all. You’ll also learn how to automate repetitive PDF tasks using the ChatGPT API and even build your own PDF chatbot with a custom user interface.
Read About: Beginners Guide to ChatGPT
By the end of this guide, you’ll have the tools to streamline how you work with PDFs—saving time and boosting productivity in both your personal and professional life. Let’s dive in!
Introduction
In the complex and vast digital universe, PDFs have become the cornerstone of all documentation. They have permeated every corner of modern life, from corporate to personal environments. These digitized documents come in variations of complexity and size. From detailed invoices, handy bank statements, to job-winning resumes and intricate architectural plans, these ubiquitous file formats are a staple of our interconnected world.
As we embrace digitization, tools like PDF AI enable efficient extraction of key-value pairs in a single shot without prior training, making it easier than ever to access the valuable information contained within these documents.
Now that humanity has succeeded in digitising all forms of information that can be possibly thought of in PDFs, the new challenge that looms on the horizon is "Data-On-Demand" - making data not just digital, but also immediately and readily accessible at our fingertips.
Enter Language Learning Models (LLMs). With their potent algorithms and innate ability to comprehend human language, LLMs are the torchbearers that can illuminate the path towards achieving data-on-demand. They can facilitate real-time communication with your PDFs, translating the digital ink into interactive, meaningful conversations, and even enabling blazing fast document processing workflows.
History of Chatting with PDFs
Historically, "chatting" with PDFs was possible in a very limited capacity, using a combination of tools and techniques to extract, process, and retrieve information from PDF files.
- PyPDF2 Library in Python or PDF.js in JavaScript were used to extract text from PDF files.
- For scanned PDFs or PDFs containing images of text, OCR technology was used to recognize and extract the text, using tools like Tesseract.
- Once the text was extracted, traditional search algorithms were used to locate the information based on keywords or phrases.
- In many cases, regular expressions were used to match patterns in the extracted text to retrieve specific information.
- Libraries like NLTK, Spacy, or Stanford NLP were used to perform tasks such as tokenization, part-of-speech tagging, and named entity recognition on the extracted text to make sense of the content.
- Platforms like Dialogflow, IBM Watson, or Microsoft's LUIS were used to create conversational agents. However, these required substantial manual effort in training and maintaining the bots, and their ability to understand and process PDF content was limited.
In essence, engaging in conversation with PDFs was a cumbersome task before the rise of LLMs. It necessitated a blend of various tools for text extraction, search algorithms, pattern recognition, and linguistic processing. Despite the effort, the results were often limited, igniting the need for more advanced solutions like LLMs. Interestingly, a new technique known as Retrieval-Augmented Generation (RAG) has emerged as a powerful way to combine retrieval-based approaches with generative AI, making it an essential tool in document interaction.
Chatting with PDFs using LLMs
Chatting with PDFs using Language Learning Models (LLMs) has revolutionized the way we interact with documents. The new wave of LLMs have been trained on a massive corpus of text and can generate human-like responses to natural language queries. Users can simply input their queries in natural language, and the LLM will extract the relevant information from the PDF and provide a natural language response.
To understand more about the technology behind LLMs, go to Appendix I.
Looking to automate tasks involving PDFs in your daily life? Look no further! Try Nanonets' automated document workflows powered by LLMs and Generative AI today.
Chat with PDFs on ChatGPT Website
Chatting with PDFs is easy for ChatGPT Plus users. For others who do not have the ChatGPT Plus subscription, this is a tricky process with limitations. Let us discuss both cases.
For ChatGPT Plus Users
There are two ways we can do this. Let us discuss both.
Method I
In the first method, we are going to use a ChatGPT plugin to chat with our PDF. This method works for all kinds of scanned and digital PDF files. Let's get started.
Method II
OpenAI has also released the "Code Interpreter" feature for ChatGPT Plus users. While the first method discussed above is recommended for chatting with most PDFs, Code Interpreter can come in handy when our PDF contains a lot of tabular data. The reason is that "Code Interpreter" can write and execute Python code directly on the ChatGPT website's UI, which makes it suitable to use for performing Exploratory Data Analysis (EDA) and visualizations of data.
Let us learn how to use this feature.
Thus, this method is good for interacting with tabular data, performing EDA, creating visualizations, and in general working with statistics.
However, the first method definitely works better for interacting with textual data in PDF files.
You can use either method based on your needs.
Read About: Extract text from PDF using ChatGPT
For Other Users
Users without the ChatGPT Plus subscription need to convert the data present in PDFs to text before feeding it to ChatGPT. Note that this process is sometimes problematic because -
- You can only process small PDF files.
- It is manual and cumbersome.
Let us get started -
Thus, this method is for people who do not have the ChatGPT Plus subscription and still want to chat with PDFs using the ChatGPT website.
To summarize the above section -
- For one time tasks involving chatting with PDFs, purchasing a ChatGPT Plus subscription and using the above method works best.
- For one time tasks where people are looking to chat with PDF files without the ChatGPT Plus subscription,
- The above shown method works but has limitations. You can only process small PDF files. Besides, it is manual & cumbersome.
- You will be better off implementing the chat in Python code. (Go to Code Tutorial Section)
- For repetitive tasks which you are looking to automate, implementing the chat / interacting with the PDFs in Python code using ChatGPT API works best. (Go to Code Tutorial Section)
Best LLMs for Chatting with PDFs
We tried out the most advanced LLMs available and evaluated how they compared with each other. This section will summarize the findings.
To see a detailed analysis along with pros and cons of each LLM we tried out, go to Appendix II.
Summary
Let us summarize our learnings for six of the best LLMs currently available via API access -
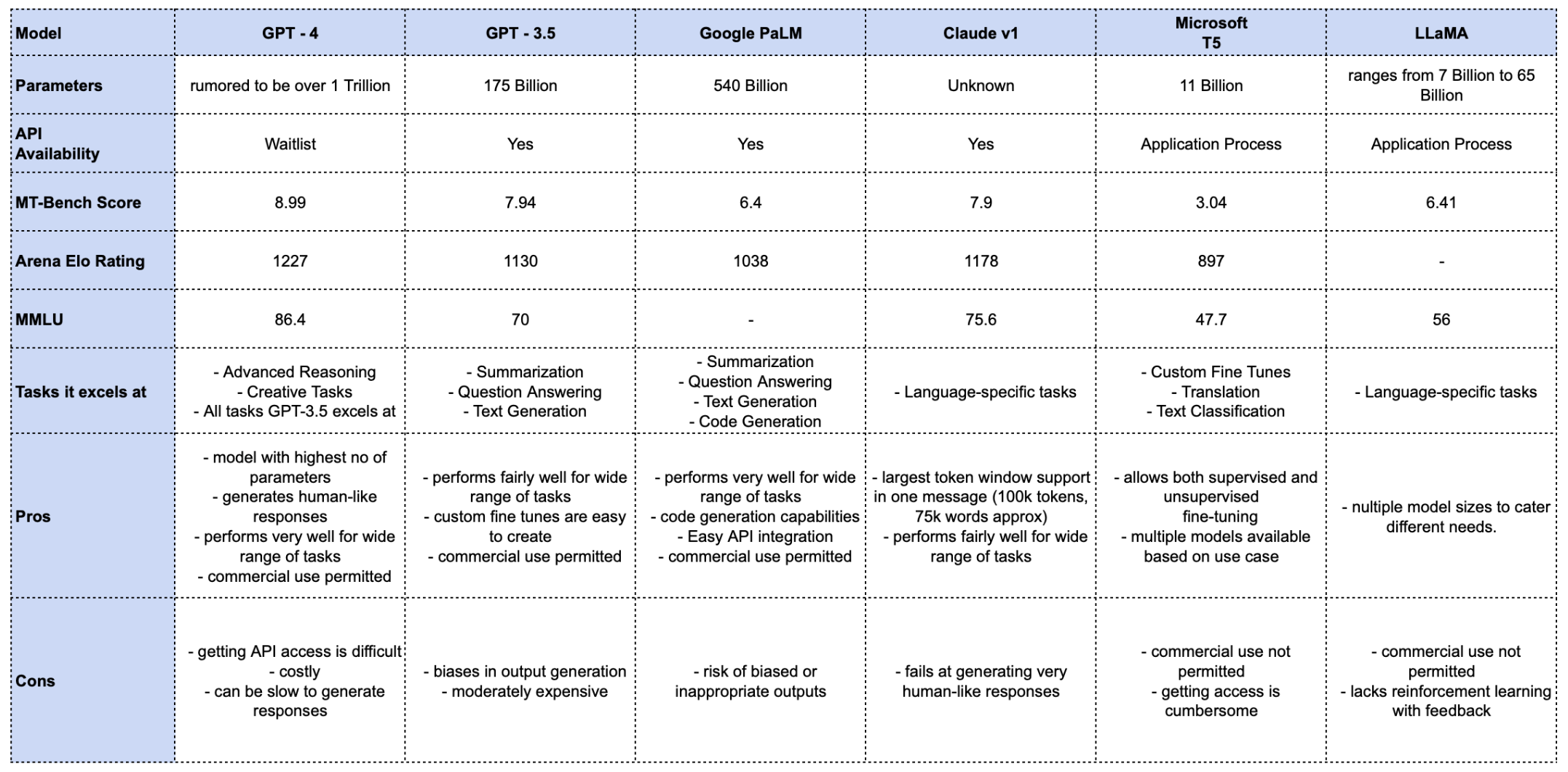
You can notice that we have also added quantitative benchmark scores of each LLM model for the following standard benchmarking tests -
- MT-bench (score): The MT-bench score is a performance measure reflecting a model's ability to generate accurate and high-quality translations.
- Arena Elo Rating: The Arena Elo Rating calculates a player's relative skill using game outcomes against other entities.
- MMLU: MMLU evaluates the distortion between synthesized and original signals, quantifying the performance and quality of synthesis systems.
Tip: You can actually head over to https://poe.com/ and test out some of the LLMs discussed above. Poe provides an interface similar to the ChatGPT website and allows you to chat with these LLMs.
If you're interested in exploring more about how different LLM APIs can be used specifically for document data extraction, you might find this guide on the best LLM APIs for document data extraction particularly useful. Here we compare Gemini, Claude, GPT and more for data extraction in a single step without the need for an intermediate step of reading document content. We evaluate their features and performance across different documents to find the best API for your needs.
LLMs recommended for chatting with PDFs
- GPT-4 : This model can be used for advanced tasks, or tasks where creative writing is required. It can easily outperform other LLMs at most other tasks as well, but is not recommended for every task as it is expensive and access is limited.
- GPT-3.5 : This model is supremely versatile and can be used for most tasks one might have. It is moderately priced and can be fine tuned. It's use in personal and professional tasks has already started and is growing at breakneck speed.
- Claude LLM : This model can be used where prompts that the user is sending are large in size, and the user wants to directly send these large chat messages / prompts directly without using any workarounds. The prompt size offered is 100k tokens, which can accommodate roughly 75k words in a single prompt.
Now that we have found the best models for chatting with PDFs, let us now learn how to start chatting with PDFs by following the Python code tutorial below.
Chat with PDFs using OpenAI API
Note : All the code and example files used in the tutorial hereon can be accessed from this Github repository.
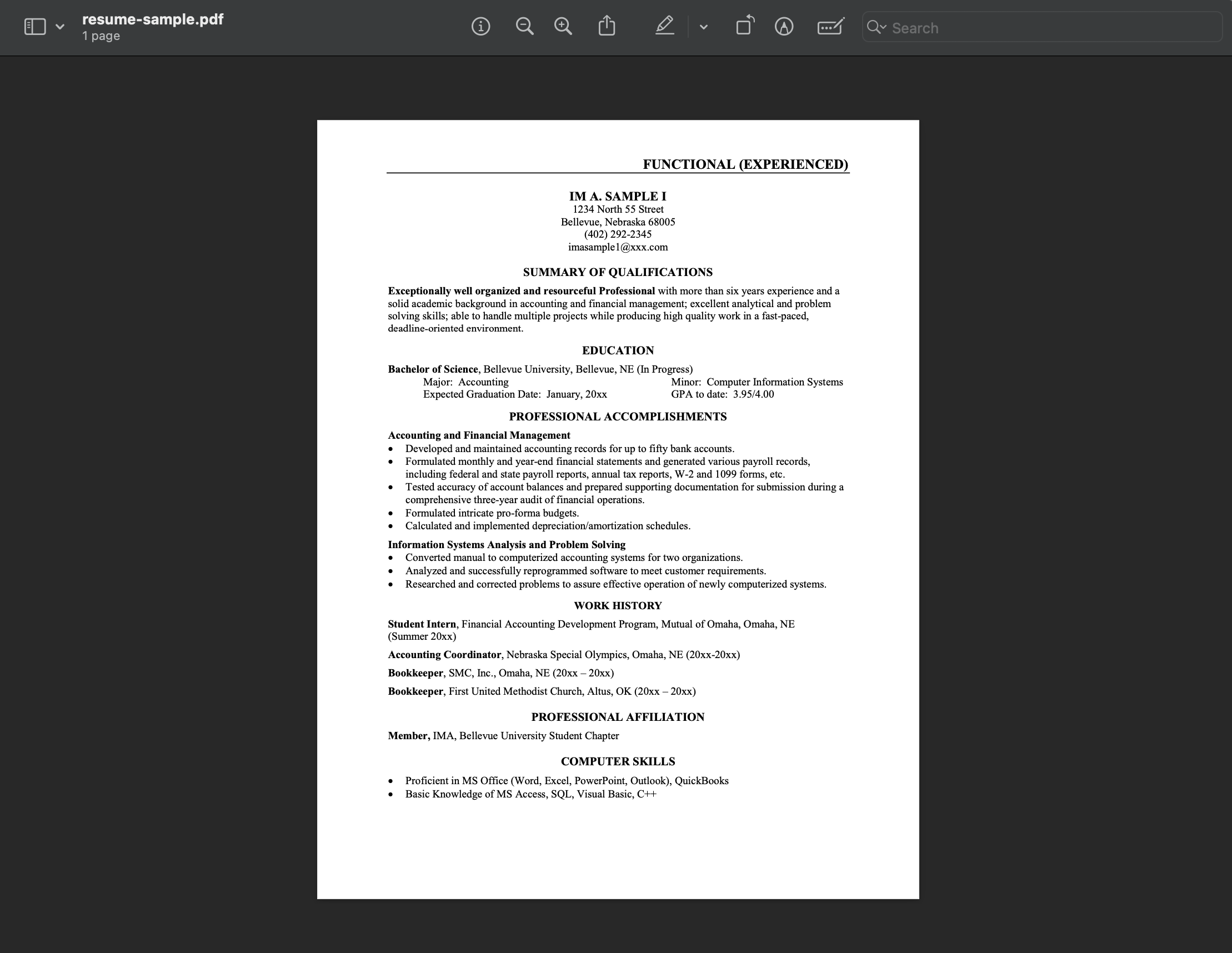
Let us now chat with our first PDF using OpenAI's GPT models. We are going to converse with a resume PDF to demonstrate this.
Note that this method fails for very large PDF files with lots of text. We will discuss how to remove this bottleneck in the section after this.
Step 1 : Get OpenAI API Key
Let us obtain an API key from OpenAI to access the GPT models via API calls -
Step 2 : Read the PDF
We follow different approaches based on whether the PDF is scanned or digital.
Let us discuss both.
Case 1 - When the PDF is digital
- We will use the PyPDF2 library for reading PDFs with digital text. We install the library using pip.
pip install PyPDF2- We read the contents of the PDF resume by executing below code.
import PyPDF2
pdf_file_obj = open('resume-sample.pdf', 'rb')
pdf_reader = PyPDF2.PdfFileReader(pdf_file_obj)
num_pages = pdf_reader.numPages
detected_text = ''
for page_num in range(num_pages):
page_obj = pdf_reader.getPage(page_num)
detected_text += page_obj.extractText() + '\n\n'
pdf_file_obj.close()
print(detected_text)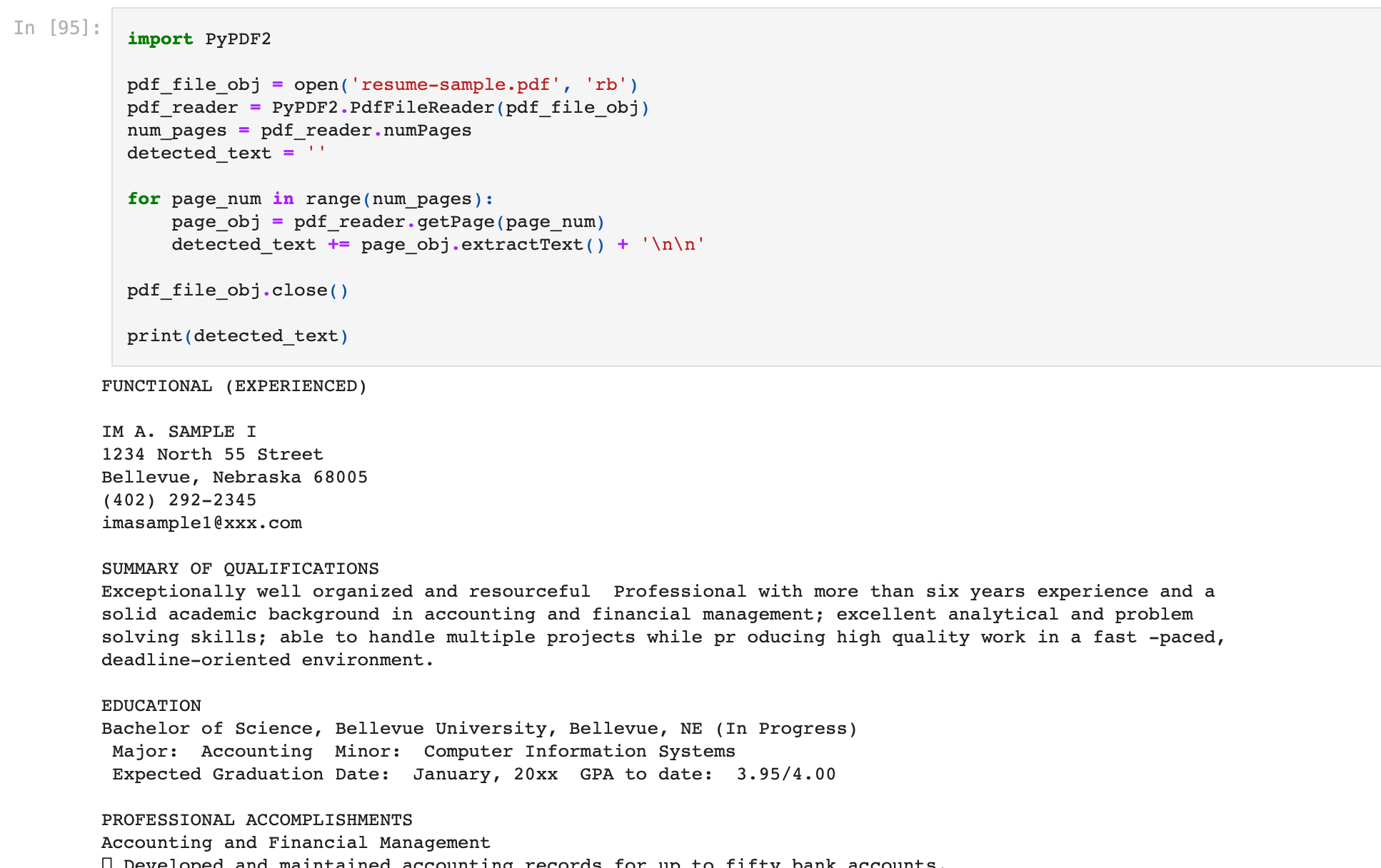
Case 2 - When the PDF is not digital
- We will first need to extract data from the PDF using Optical Character Recognition (OCR).
- We will use the Tesseract OCR engine for this purpose. It is open-source and maintained by Google. Installing the Tesseract OCR Engine is the first step here.
Windows - installation is easy with the precompiled binaries found here. Do not forget to edit “path” environment variable and add tesseract path.
Linux - can be installed with few commands.
Mac - The easiest way to install on Mac is using homebrew. Follow steps here.
- After the installation verify that everything is working by typing this command in the terminal or cmd:
tesseract --versionYou will see output similar to:
tesseract 5.1.0
leptonica-1.82.0
libgif 5.2.1 : libjpeg 9e : libpng 1.6.37 : libtiff 4.4.0 : zlib 1.2.11 : libwebp 1.2.2 : libopenjp2 2.5.0
Found NEON
Found libarchive 3.6.1 zlib/1.2.11 liblzma/5.2.5 bz2lib/1.0.8 liblz4/1.9.3 libzstd/1.5.2
Found libcurl/7.77.0 SecureTransport (LibreSSL/2.8.3) zlib/1.2.11 nghttp2/1.42.0- We now install the python wrapper for tesseract. You can install this using pip :
pip install pytesseract- Tesseract takes image formats as input, which means that we will be required to convert our PDF files to images before processing using OCR. The pdf2image library will help us achieve this. You can install this using pip.
pip install pdf2image- Now, we are good to go. Reading text from pdfs is now possible in few lines of python code.
import pdf2image
from PIL import Image
import pytesseract
image = pdf2image.convert_from_path('FILE_PATH')
for pagenumber, page in enumerate(image):
detected_text = pytesseract.image_to_string(page)
print(detected_text)
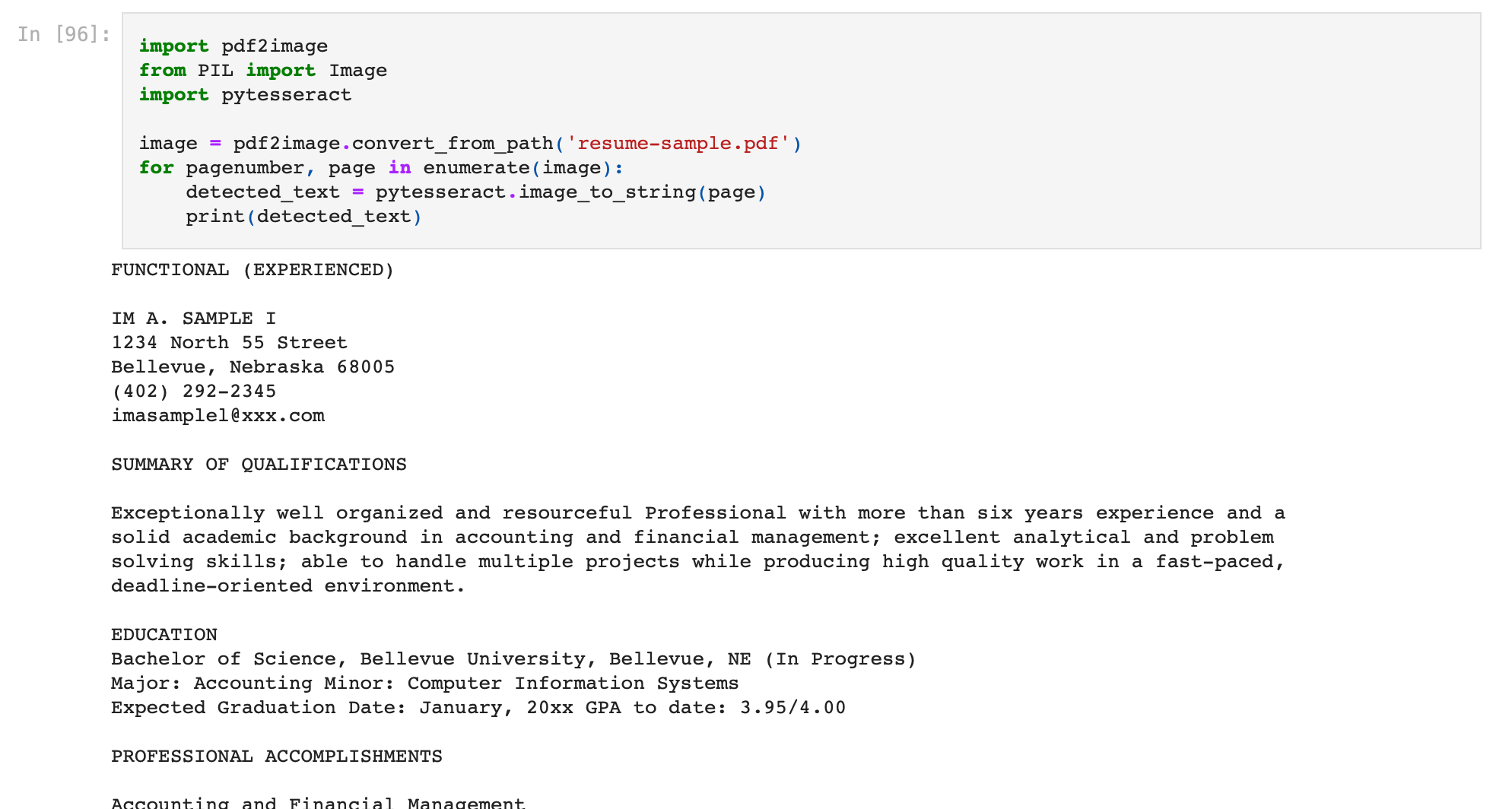
- Running the above python code snippet on the resume, we obtain the below output from the OCR engine.
Step 3 : First Chat with PDF
- Now that we have extracted the contents of the PDF in the detected_text variable, we can initiate our first chat.
- We are going to use OpenAI's python library. Install the library using pip.
pip install --upgrade openai- We import the os and openai library and define our OpenAI API key. This is the key we obtained in the step above.
import os
import openai
openai.api_key = '{Your OpenAI API Key}'- A basic request to an OpenAI model using the python library looks like this -
response = openai.ChatCompletion.create(
model=model_name,
messages=[
{"role": "system", "content": system_msg},
{"role": "user", "content": user_msg},
{"role": "assistant", "content": assistant_msg},
],
)
Let us understand the variables here -
system_msg messages describe the behavior of the AI assistant. These are background messages we send as part of the request to affect the tone and flavor of the response generated by the GPT model.
user_msg messages describe what you want the AI assistant to say. This is essentially the prompt we are sending to the model.
assistant_msg messages describe previous responses in the conversation. They enable us to have extended chats with PDFs while retaining conversation history. We'll cover how to do this below.
model_name specifies the GPT model to use.
Go to Appendix III to understand how to choose a GPT model here.
- Now that we understand how to send a message to the GPT model, let us ask the LLM to suggest jobs that this person will be suitable for based on his resume.
- We append our query - "give a list of jobs suitable for the above resume" to the extracted PDF text and send this as the user_msg. The detected_text variable already contains the data extracted from the PDF. We will simply append our query here.
query = 'give a list of jobs suitable for the above resume.'
user_msg = detected_text + '\n\n' + query
- We also add a relevant system_msg to refine the behavior of the AI assistant. In our case, a useful system message can be "You are a helpful career advisor."
system_msg = 'You are a helpful career advisor.'- We send the request to get our first response. Based on all the above points, we finally execute the code shown below -
import pdf2image
from PIL import Image
import pytesseract
import os
import openai
openai.api_key = "{Your OpenAI API Key}"
image = pdf2image.convert_from_path("FILE_PATH")
for pagenumber, page in enumerate(image):
detected_text = pytesseract.image_to_string(page)
print(detected_text)
query = "give a list of jobs suitable for the above resume."
user_msg = detected_text + "\n\n" + query
system_msg = "You are a helpful career advisor."
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": system_msg},
{"role": "user", "content": user_msg},
],
)
- Once the request is complete, the response object will contain the response from the LLM. We can view it by accessing the 'choices' attribute in the response object as follows -
print(response.choices[0].message.content)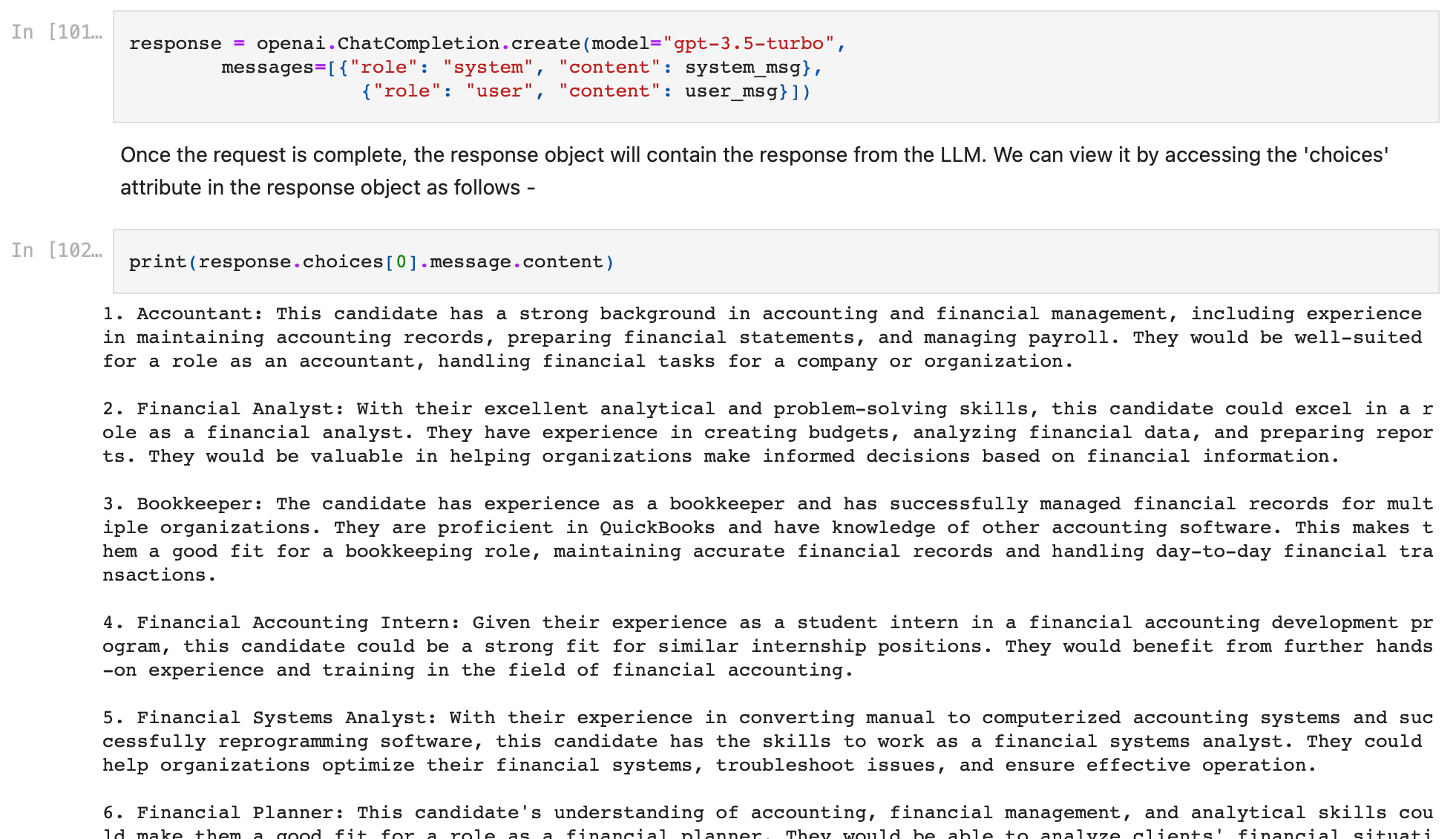
Voila, we have just had our first conversation with a PDF using GPT. The model has responded with a suggestion of 10 job roles that will be suitable based on the resume.
Step 4 : Continuing the Conversation
- Often, we would want to have conversations with the LLM which are more than just a pair of a single prompt and a single response. Let us now learn how to use our past conversation history to continue the conversation.
- This is where the assistant_msg variable introduced above comes into play. We create the assistant messages by using the values of the previous responses. The assistant_msg messages will basically assist the model in responding by providing past conversation history to provide context to the model.
To simplify the implementation, we define the following function for calling the OpenAI GPT API from now on -
def continue_chat(system_message, user_assistant_messages):
system_msg = [{"role": "system", "content": system_message}]
user_assistant_msgs = [
{"role": "assistant", "content": user_assistant_messages[i]} if i % 2
else {"role": "user", "content": user_assistant_messages[i]}
for i in range(len(user_assistant_messages))
]
allmsgs = system_msg + user_assistant_msgs
response = openai.ChatCompletion.create(model="gpt-3.5-turbo", messages=allmsgs)
return response["choices"][0]["message"]["content"]
The function accepts -
- system_message (string) : This acts as the system_msg
- user_assistant_messages (list) : This list contains user prompts and model responses in alternating order. This is also the order in which they occur in the conversation.
The function internally makes the API call to generate and return a new response based on the conversation history.
Let us now use this function to continue our previous conversation, and find out the highest paying jobs out of the ones recommended in the first response.
- We use the same system message (system_msg) used in previous call.
system_msg = 'You are a helpful career advisor.'- We create user_assistant_messages list.
user_msg1 = user_msg
model_response1 = response["choices"][0]["message"]["content"]
user_msg2 = 'based on the suggestions, choose the 3 jobs with highest average salary'
user_assistant_msgs = [user_msg1, model_response1, user_msg2]
Note that we used the original prompt as the first user message (user_msg1), the response to that prompt as the first model response message (model_response1), and our new prompt as the second user message (user_msg2).
Finally, we add them to the user_assistant_messages list in order of their occurrence in the conversation.
- Finally we call the continue_chat() function to get the next response in the conversation.
response = continue_chat(system_msg, user_assistant_msgs)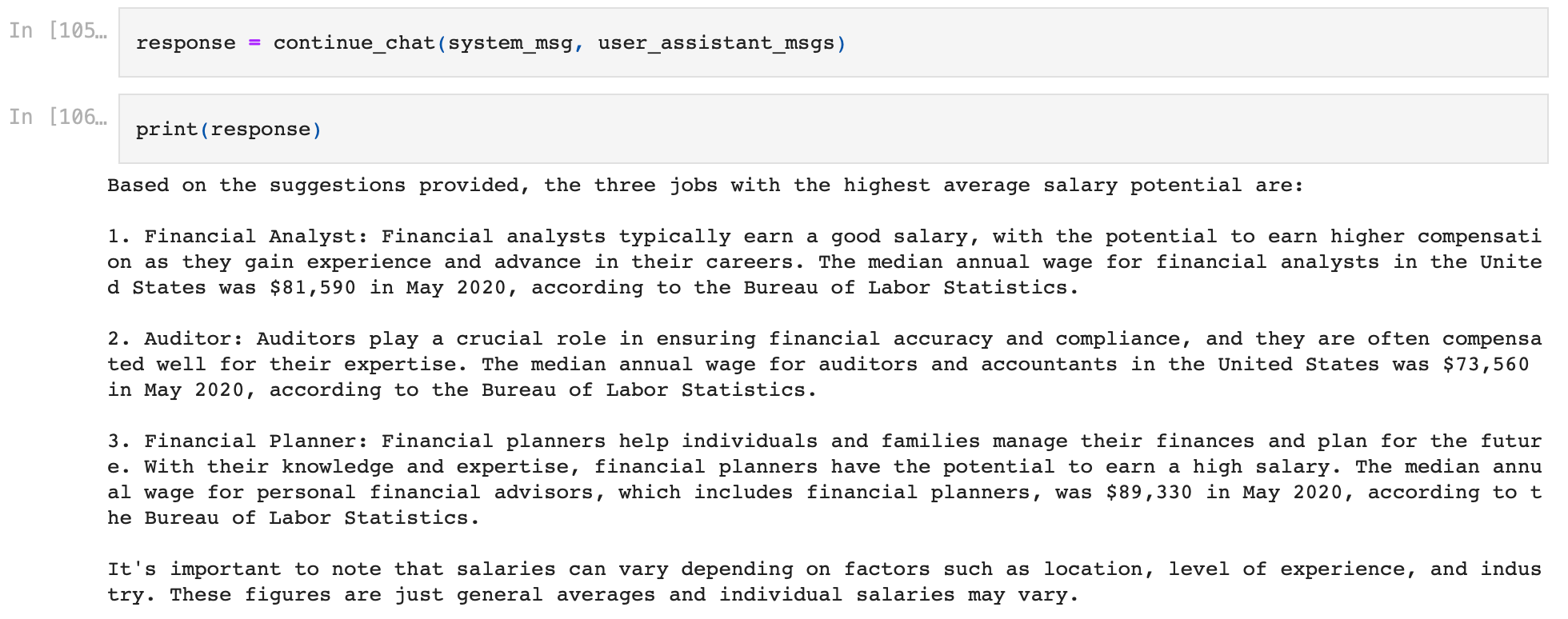
The model answers based on the context gained by knowing the conversation history, and was able to create an excellent response which answers the query perfectly!
You can use the continue_chat() function to further converse with the model by iteratively adding the conversation history to the user_assistant_messages list in order in which the messages and responses appeared in the conversation, enabling long to and fro conversations with PDF files.
Chat with Large PDFs using ChatGPT API and LangChain
The code tutorial shown above fails for very large PDFs. Let us illustrate this with an example. We will try to chat with BCG's "2022 Annual Sustainability Report", a large PDF published by the Boston Consulting Group (BCG) on their general impact in the industry. We execute the code shown below -
import PyPDF2
pdf_file_obj = open('bcg-2022-annual-sustainability-report-apr-2023.pdf', 'rb')
pdf_reader = PyPDF2.PdfFileReader(pdf_file_obj)
num_pages = pdf_reader.numPages
detected_text = ''
for page_num in range(num_pages):
page_obj = pdf_reader.getPage(page_num)
detected_text += page_obj.extractText() + '\n\n'
pdf_file_obj.close()
print(len(detected_text))
We can see that the PDF is super large, and the length of the detected_text string variable is roughly 250k.
Let us now try chatting with the PDF -
system_msg = ""
query = """
summarize this PDF in 500 words.
"""
user_msg = detected_text + "\n\n" + query
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": system_msg},
{"role": "user", "content": user_msg},
],
)We get the following error message saying that we have hit the prompt length threshold.
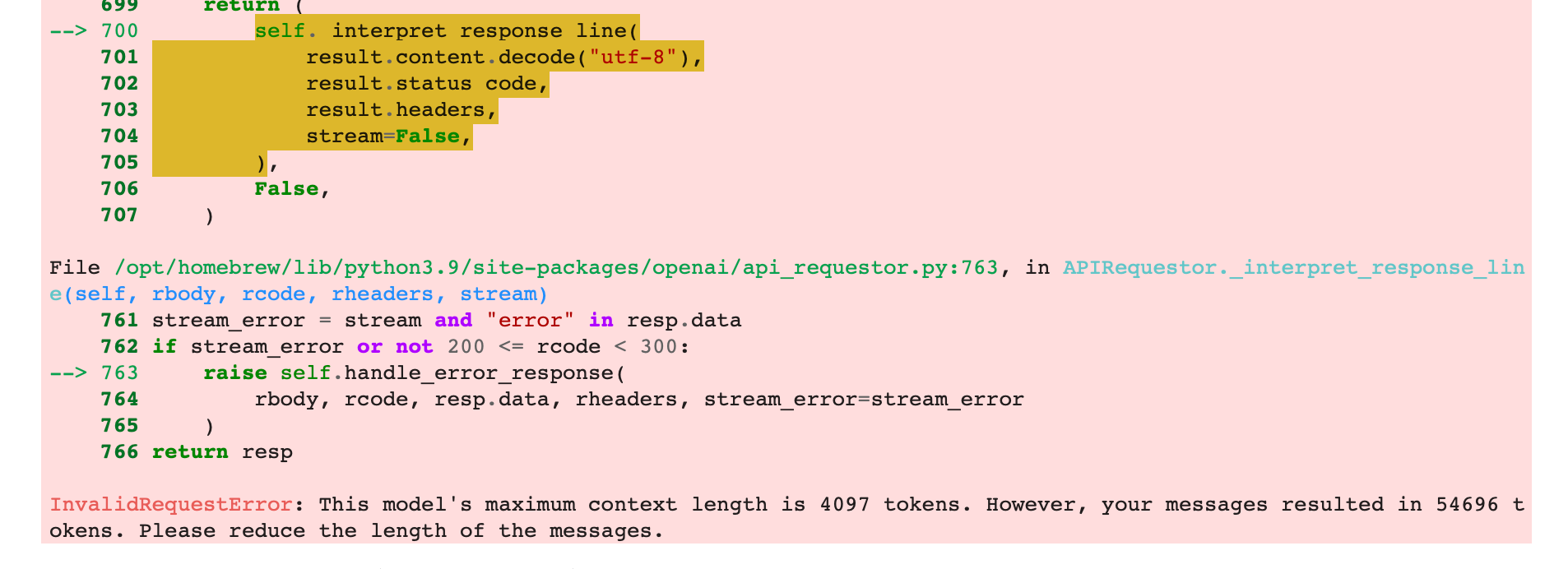
This happens because for large PDFs with lots of text, the request payload we send to OpenAI becomes too large, and OpenAI returns an error saying that we have hit the prompt length threshold.
Let us now learn how to remove this bottleneck using LangChain Tutorial
- Enter LangChain. LangChain is an innovative technology that functions as a bridge - linking large language models (LLMs) with practical applications like Python programming, PDFs, CSV files, or databases.
- We install the required modules using pip.
pip install langchain openai pypdf faiss-cpu- We import the required dependencies.
from langchain.document_loaders import PyPDFLoader
from langchain.vectorstores import FAISS
from langchain.chat_models import ChatOpenAI
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains import RetrievalQA, ConversationalRetrievalChain
import os- We load the PDF using PyPDF.
import PyPDF2
pdf_file_obj = open('bcg-2022-annual-sustainability-report-apr-2023.pdf', 'rb')
pdf_reader = PyPDF2.PdfFileReader(pdf_file_obj)
num_pages = pdf_reader.numPages
detected_text = ''
for page_num in range(num_pages):
page_obj = pdf_reader.getPage(page_num)
detected_text += page_obj.extractText() + '\n\n'
pdf_file_obj.close()- We will perform chunking and split the text using LangChain text splitters.
Our choice is the RecursiveCharacterTextSplitter since it's designed to maintain the integrity of paragraphs by adjusting the length of the chunks to avoid unnecessary splits wherever possible.
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
texts = text_splitter.create_documents([detected_text])The above code will split the text into "chunks". The length of the 'texts' variable gives us the number of pages / chunks into which the text has been split.
- We create a vector database using the chunks. We will save it the database for future use as well.
Based on your use case, you can choose the correct vector database to use from this documentation.
We choose the FAISS vector store - It's both efficient and user-friendly. Plus, it saves vectors directly onto the file system / hard drive.
directory = 'index_store'
vector_index = FAISS.from_documents(texts, OpenAIEmbeddings())
vector_index.save_local(directory)The database index gets stored with the file name 'index_store'.
- We now load the database. Using the database, we configure a retriever and then create a chat object. This chat object (qa_interface) will be used to chat with the PDF.
vector_index = FAISS.load_local('index_store', OpenAIEmbeddings())
retriever = vector_index.as_retriever(search_type="similarity", search_kwargs={"k":6})
qa_interface = RetrievalQA.from_chain_type(llm=ChatOpenAI(), chain_type="stuff", retriever=retriever, return_source_documents=True)- We can now start chatting with the PDF. Let us ask the PDF to list measures taken to address diseases occurring in developing industries.
response = qa_interface("List measures taken to address diseases occuring in developing industries")Based on the above example, full code we executed is as follows -
from langchain.document_loaders import PyPDFLoader
from langchain.vectorstores import FAISS
from langchain.chat_models import ChatOpenAI
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains import RetrievalQA, ConversationalRetrievalChain
import os
import PyPDF2
pdf_file_obj = open("bcg-2022-annual-sustainability-report-apr-2023.pdf", "rb")
pdf_reader = PyPDF2.PdfFileReader(pdf_file_obj)
num_pages = pdf_reader.numPages
detected_text = ""
for page_num in range(num_pages):
page_obj = pdf_reader.getPage(page_num)
detected_text += page_obj.extractText() + "\n\n"
pdf_file_obj.close()
os.environ["OPENAI_API_KEY"] = "Your OpenAI API Key"
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
texts = text_splitter.create_documents([detected_text])
directory = "index_store"
vector_index = FAISS.from_documents(texts, OpenAIEmbeddings())
vector_index.save_local(directory)
vector_index = FAISS.load_local("index_store", OpenAIEmbeddings())
retriever = vector_index.as_retriever(search_type="similarity", search_kwargs={"k": 6})
qa_interface = RetrievalQA.from_chain_type(
llm=ChatOpenAI(),
chain_type="stuff",
retriever=retriever,
return_source_documents=True,
)
response = qa_interface(
"List measures taken to address diseases occuring in developing industries"
)
print(response["result"])- The result addresses our query and gives an excellent response!

- So far, we've used the RetrievalQA chain, a LangChain type for pulling document pieces from a vector store and asking one question about them. But, sometimes we need to have a full conversation about a document, including referring to topics we've already talked about.
- Thankfully, LangChain has us covered. To make this possible, our system needs a memory or conversation history. Instead of the RetrievalQA chain, we'll use the ConversationalRetrievalChain.
conv_interface = ConversationalRetrievalChain.from_llm(ChatOpenAI(temperature=0), retriever=retriever)
- Let's ask the PDF to reveal the context in which Morocco is mentioned in the report.
chat_history = []
query = "in what context is Morocco mentioned in the report?"
result = conv_interface({"question": query, "chat_history": chat_history})
print(result["answer"])'chat_history' parameter is a list containing past conversation history. For the first message, this list will be empty.
'question' parameter is used to send our message.
The overall code for conversational chatting with large PDFs looks this this -
from langchain.document_loaders import PyPDFLoader
from langchain.vectorstores import FAISS
from langchain.chat_models import ChatOpenAI
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains import RetrievalQA, ConversationalRetrievalChain
import os
import PyPDF2
pdf_file_obj = open("bcg-2022-annual-sustainability-report-apr-2023.pdf", "rb")
pdf_reader = PyPDF2.PdfFileReader(pdf_file_obj)
num_pages = pdf_reader.numPages
detected_text = ""
for page_num in range(num_pages):
page_obj = pdf_reader.getPage(page_num)
detected_text += page_obj.extractText() + "\n\n"
pdf_file_obj.close()
os.environ["OPENAI_API_KEY"] = "Your OpenAI API Key"
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
texts = text_splitter.create_documents([detected_text])
directory = "index_store"
vector_index = FAISS.from_documents(texts, OpenAIEmbeddings())
vector_index.save_local(directory)
vector_index = FAISS.load_local("index_store", OpenAIEmbeddings())
retriever = vector_index.as_retriever(search_type="similarity", search_kwargs={"k": 6})
qa_interface = RetrievalQA.from_chain_type(
llm=ChatOpenAI(),
chain_type="stuff",
retriever=retriever,
return_source_documents=True,
)
response = qa_interface(
"List measures taken to address diseases occuring in developing industries"
)
print(response["result"])- The result summarizes Morocco's mention in the report.

- Let us now continue the conversation by updating the chat_history variable and ask the PDF to give some statistics around this.
We append the messages in order of appearance in the conversation. We first append our initial message followed by the first response.
chat_history.append((query, result["answer"]))We now add our new question along with the updated chat_history to continue the conversation.
query = "give some statistics around this."
result = conv_interface({"question": query, "chat_history": chat_history})
print(result["answer"])- The result uses the context gained by knowing the conversation history, and provides another great response!
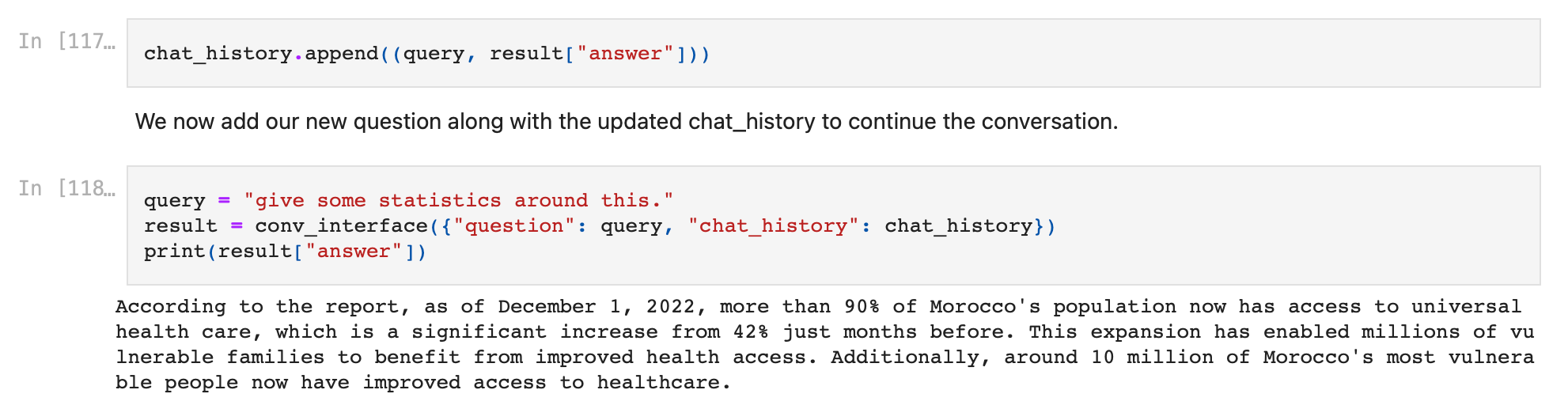
We can keep updating the chat_history variable and further continue our conversation using this method.
Build PDF Automations using ChatGPT
The number of people using ChatGPT API to automate everyday personal and professional tasks involving PDFs is increasing at breakneck speed everyday.
These automations replace repetitive PDF tasks we do everyday and even create automated document workflows, enabling everyone to save time and focus on things which reallly matter.
Let us walk through examples of these automations and learn how they can be created and deployed.
Automation 1 - Document Data Extraction
GPT-3.5 is excellent at extracting data from documents. Let us try to extract data from the below invoice using it.
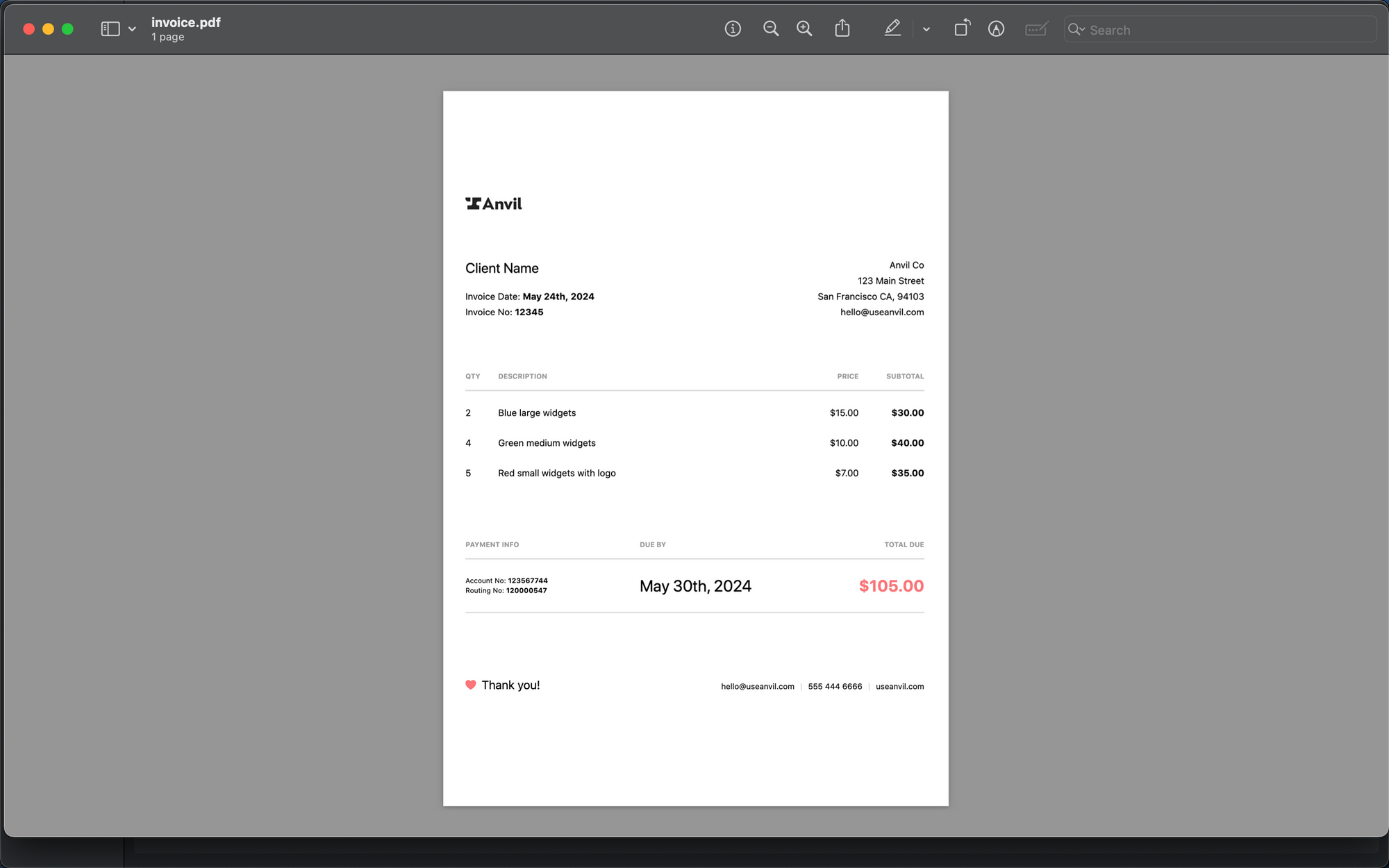
We are going to extract the following fields in JSON format - invoice_date, invoice_number, seller_name, seller_address, total_amount, and each line item present in the invoice.
Let us create a query, which when appended with the invoice PDF and sent to OpenAI's API, returns the structured json which we can further read and process in python.
Query -
extract data from above invoice and return only the json containing the following - invoice_date, invoice_number, seller_name, seller_address, total_amount, and each line item present in the invoice.
json=
The complete code looks like this -
import os
import openai
openai.api_key = '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'
import pdf2image
from PIL import Image
import pytesseract
image = pdf2image.convert_from_path('invoice.pdf')
for pagenumber, page in enumerate(image):
detected_text = pytesseract.image_to_string(page)
system_msg = 'You are an invoice processing solution.'
query = '''
extract data from above invoice and return only the json containing the following -
invoice_date, invoice_number, seller_name, seller_address, total_amount, and each line item present in the invoice.
json=
'''
user_msg = detected_text + '\n\n' + query
response = openai.ChatCompletion.create(model="gpt-3.5-turbo",
messages=[{"role": "system", "content": system_msg},
{"role": "user", "content": user_msg}])
print(response.choices[0].message.content)Upon execution, the response given is a perfectly structured json which has extracted the required text from the document!
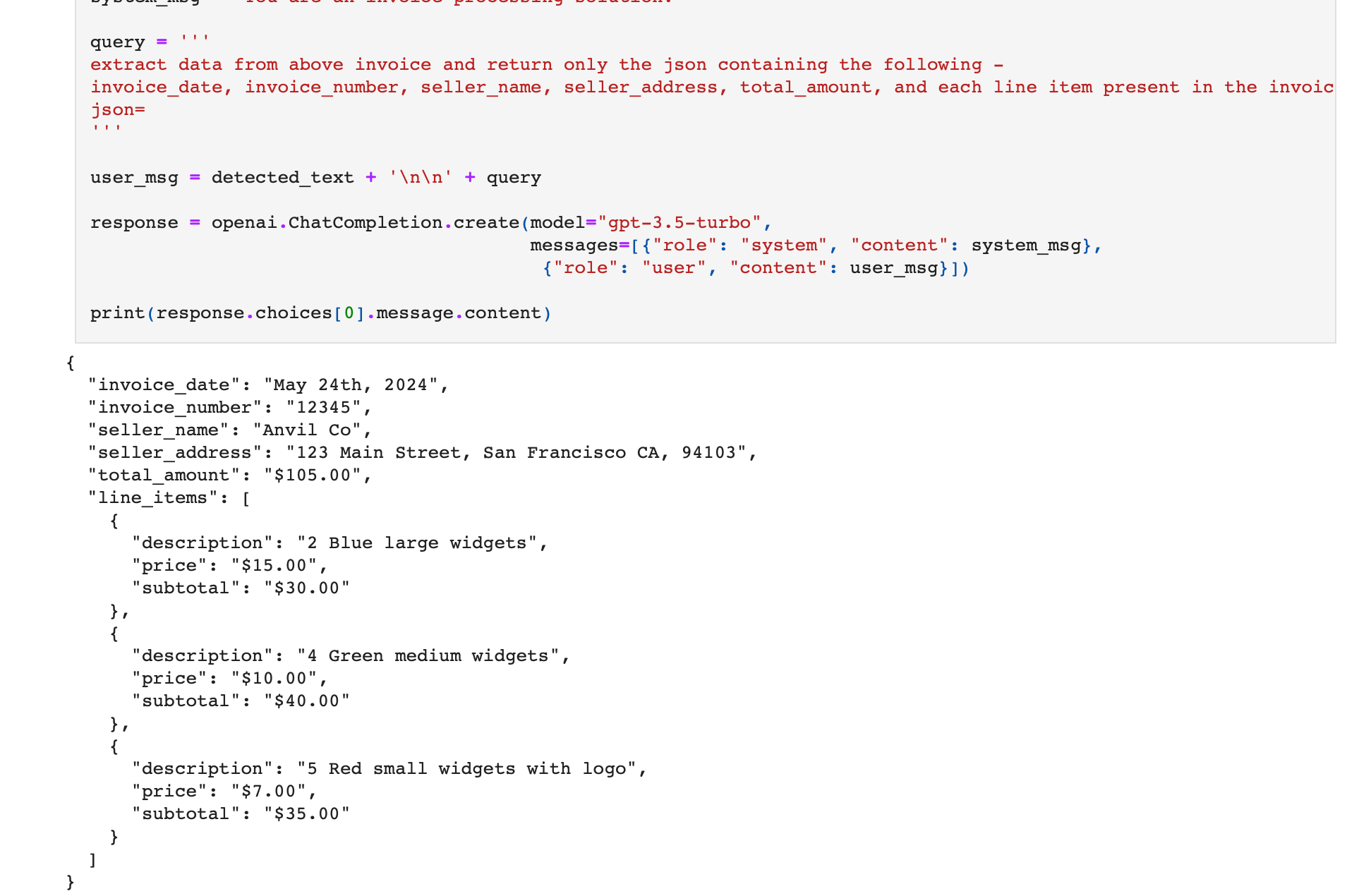
The json here is essentially a json dump - it is a text string which is in the correct json format, but is not a json variable yet.
Let us convert this response to a json variable, which happens by adding just one line of code.
invoice_json = json.loads(response["choices"][0]["message"]["content"])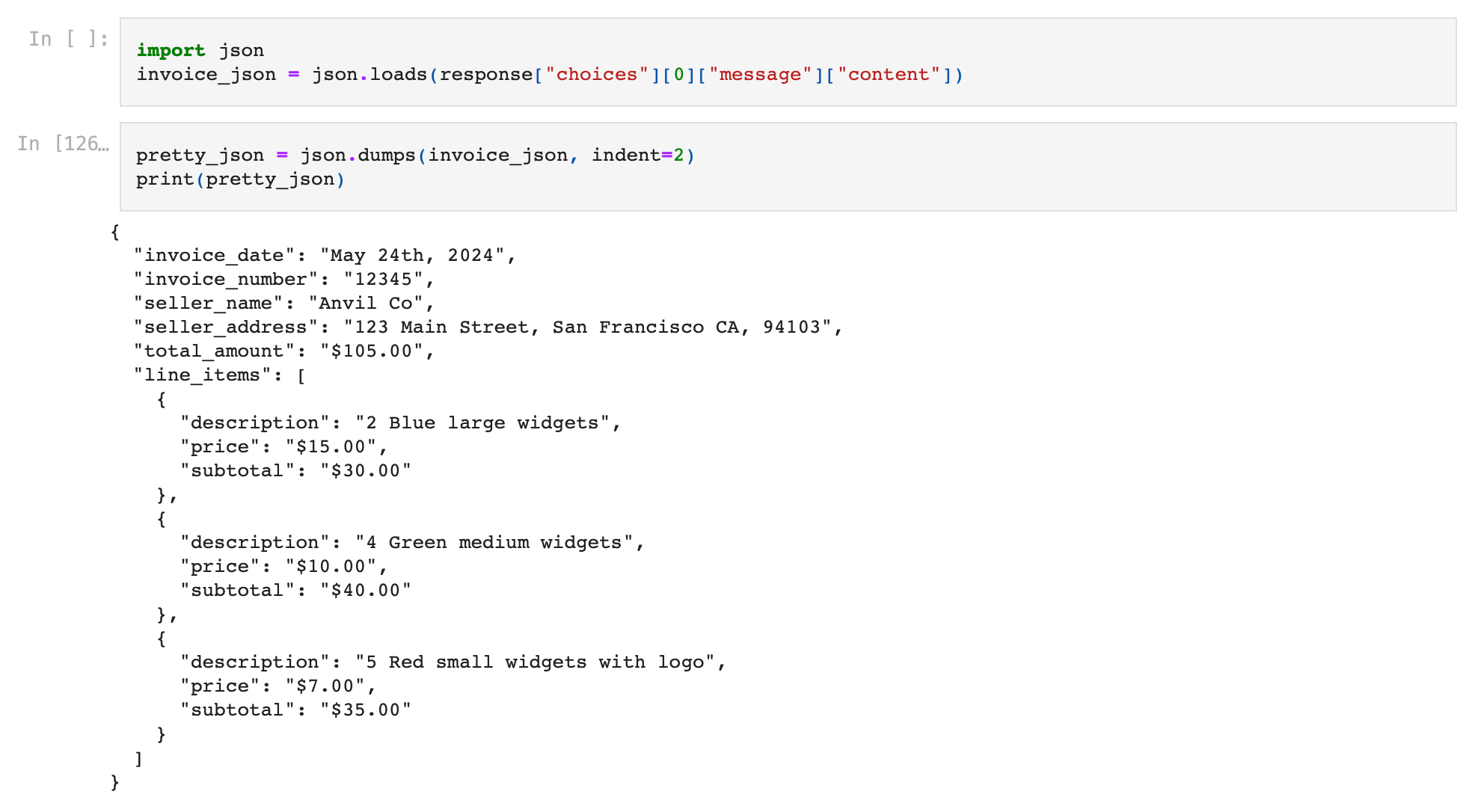
Now that we have achieved data extraction from invoices, we can actually go on and fully automate the invoice processing workflow - automatically ingest incoming invoices, extract data from them using ChatGPT, and export the extracted data to our software / database / ERP of choice. We will talk about how to deploy these automations in the section after this.
Automation 2 - Document Classification
In many cases, we are bombarded with PDF documents for various purposes and have to open each and every one of them to know what purpose they serve.
Let us consider an example. Say we have a lot of files which are either invoices or receipts. We want to classify and sort these documents based on their type.
Doing this is easy using GPT API.
We create simple python functions to do this.
import shutil
import os
import openai
openai.api_key = "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"
def list_files_only(directory_path):
if os.path.isdir(directory_path):
file_list = [
f
for f in os.listdir(directory_path)
if os.path.isfile(os.path.join(directory_path, f))
]
file_list = [file for file in file_list if ".pdf" in file]
return file_list
else:
return f"{directory_path} is not a directory"
def classify(file_name):
image = pdf2image.convert_from_path(file_name)
for pagenumber, page in enumerate(image):
detected_text = pytesseract.image_to_string(page)
system_msg = "You are an accounts payable expert."
query = """
Classify this document and return one of these two document types as response - [Invoices, Receipts]
Return only the document type in the response.
Document Type =
"""
user_msg = detected_text + "\n\n" + query
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": system_msg},
{"role": "user", "content": user_msg},
],
)
return response["choices"][0]["message"]["content"]
def move_file(current_path, new_folder):
if os.path.isfile(current_path) and os.path.isdir(new_folder):
file_name = os.path.basename(current_path)
new_path = os.path.join(new_folder, file_name)
shutil.move(current_path, new_path)
print(f"File moved to {new_path}")
- list_files_only() : This function gets all the files from our folder containing invoices and receipts. It returns the list of all PDF files.
- classify() : This function extracts text from a PDF file, applies the GPT API query to classify the document between invoices and receipts, returns the document type.
- move_file() : This function moves a file to a new folder.
We now create two folders labelled 'Invoices' and 'Receipts'.
Let us execute the code now to classify these files and sort them into separate folders based on the document type.
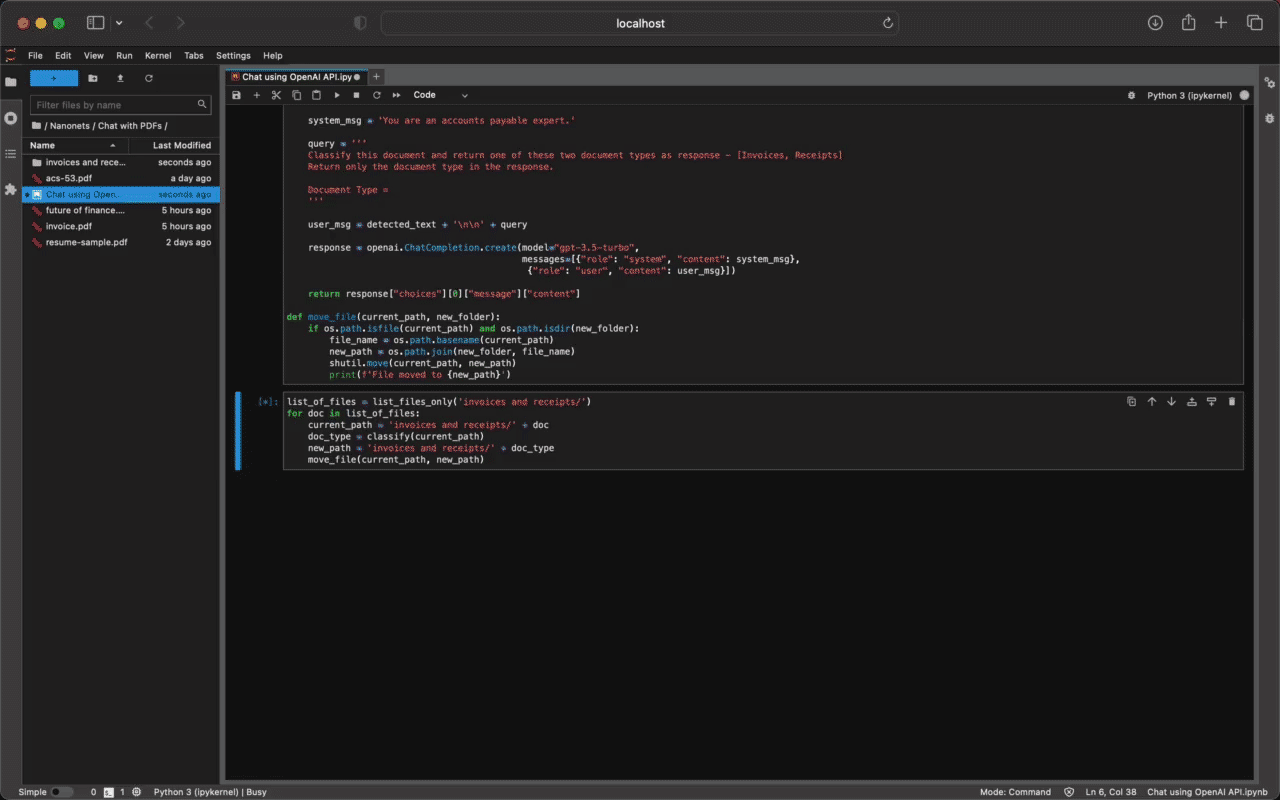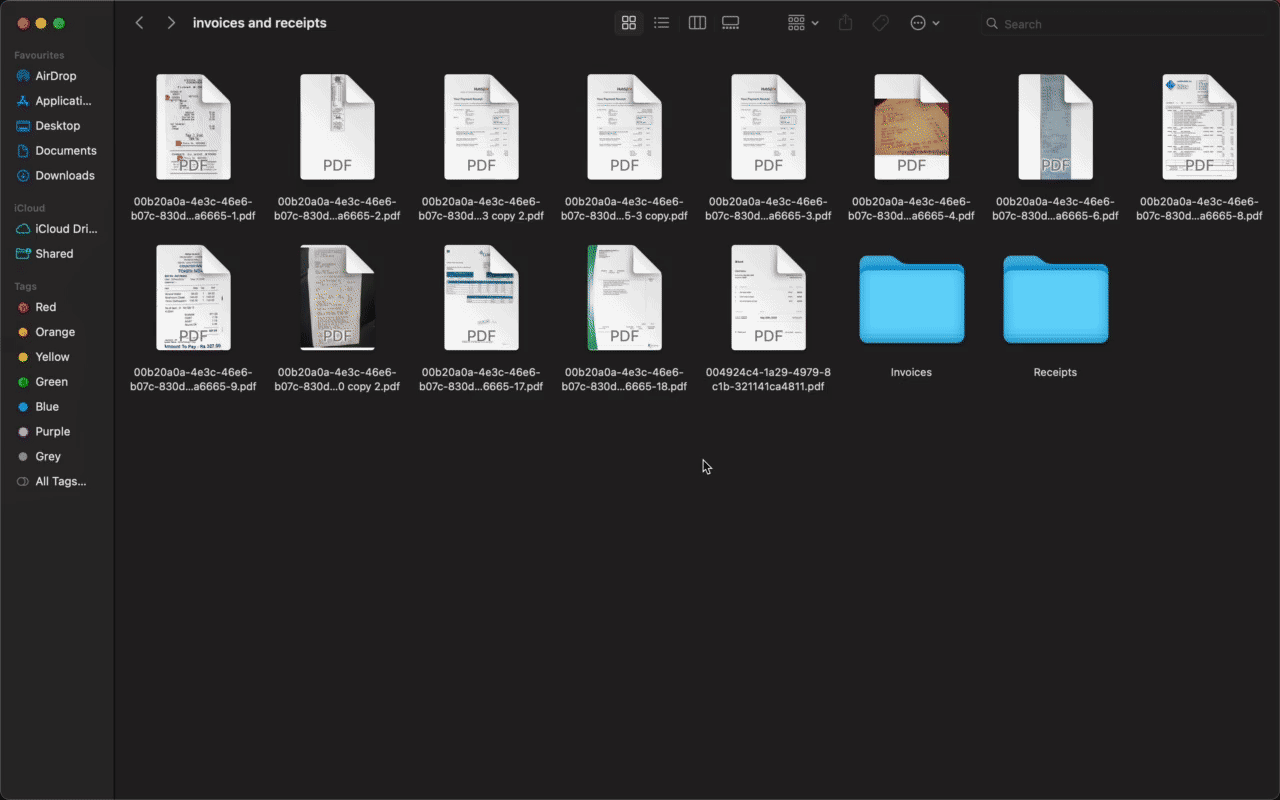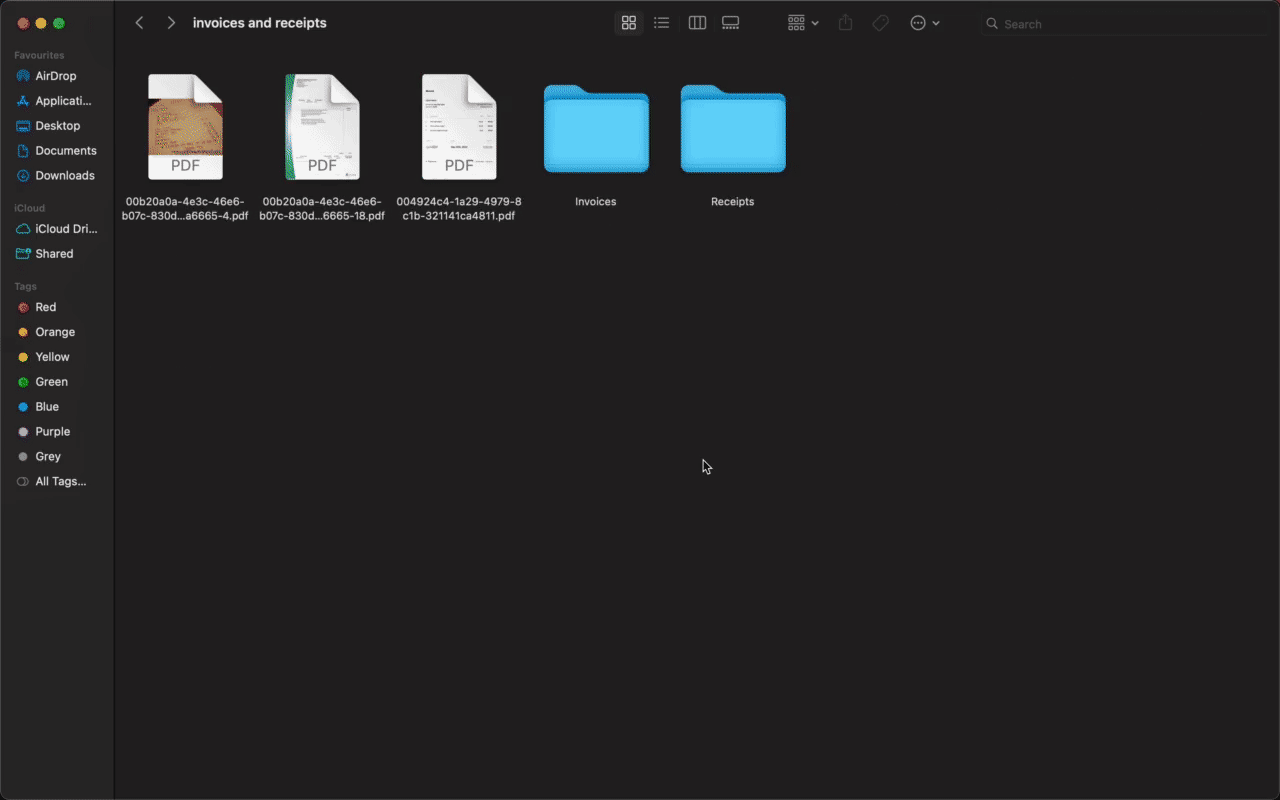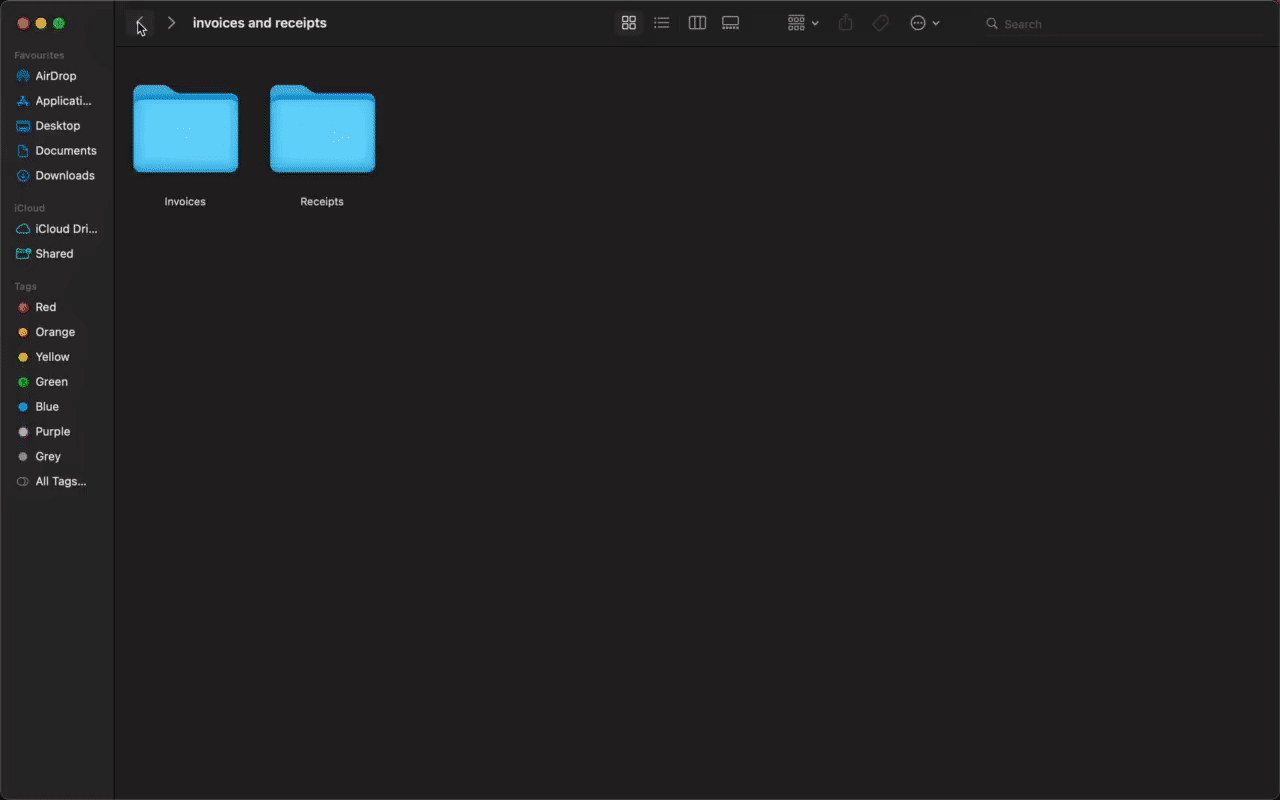
list_of_files = list_files_only('invoices and receipts/')
for doc in list_of_files:
current_path = 'invoices and receipts/' + doc
doc_type = classify(current_path)
new_path = 'invoices and receipts/' + doc_type
move_file(current_path, new_path)Upon execution, the code sorts these files perfectly!
Automation 3 - Recipe Recommender
We can even feed our favorite cookbooks to GPT API, and ask it to give recipe recommendations based on our inputs. Let us look at an example. We use the Brakes' Meals n More recipe cookbook, and talk to it using LangChain. Let us ask it to give recommendations based on the ingredients we have at home.
This is what the code might look like -
from langchain.document_loaders import PyPDFLoader
from langchain.vectorstores import FAISS
from langchain.chat_models import ChatOpenAI
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains import RetrievalQA, ConversationalRetrievalChain
import os
import PyPDF2
pdf_file_obj = open("meals-more-recipes.pdf", "rb")
pdf_reader = PyPDF2.PdfFileReader(pdf_file_obj)
num_pages = pdf_reader.numPages
detected_text = ""
for page_num in range(num_pages):
page_obj = pdf_reader.getPage(page_num)
detected_text += page_obj.extractText() + "\n\n"
pdf_file_obj.close()
os.environ["OPENAI_API_KEY"] = "Your OpenAI API Key"
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
texts = text_splitter.create_documents([detected_text])
directory = "index_store"
vector_index = FAISS.from_documents(texts, OpenAIEmbeddings())
vector_index.save_local(directory)
vector_index = FAISS.load_local("index_store", OpenAIEmbeddings())
retriever = vector_index.as_retriever(search_type="similarity", search_kwargs={"k": 6})
qa_interface = RetrievalQA.from_chain_type(
llm=ChatOpenAI(),
chain_type="stuff",
retriever=retriever,
return_source_documents=True,
)
response = qa_interface(
"""
I have a lot of broccoli and tomatoes at home.
Recommend recipe for some meal I can make at home using these.
"""
)
print(response["result"])Upon execution, the PDF recommends a recipe for a meal that can be prepared using the mentioned ingredients!
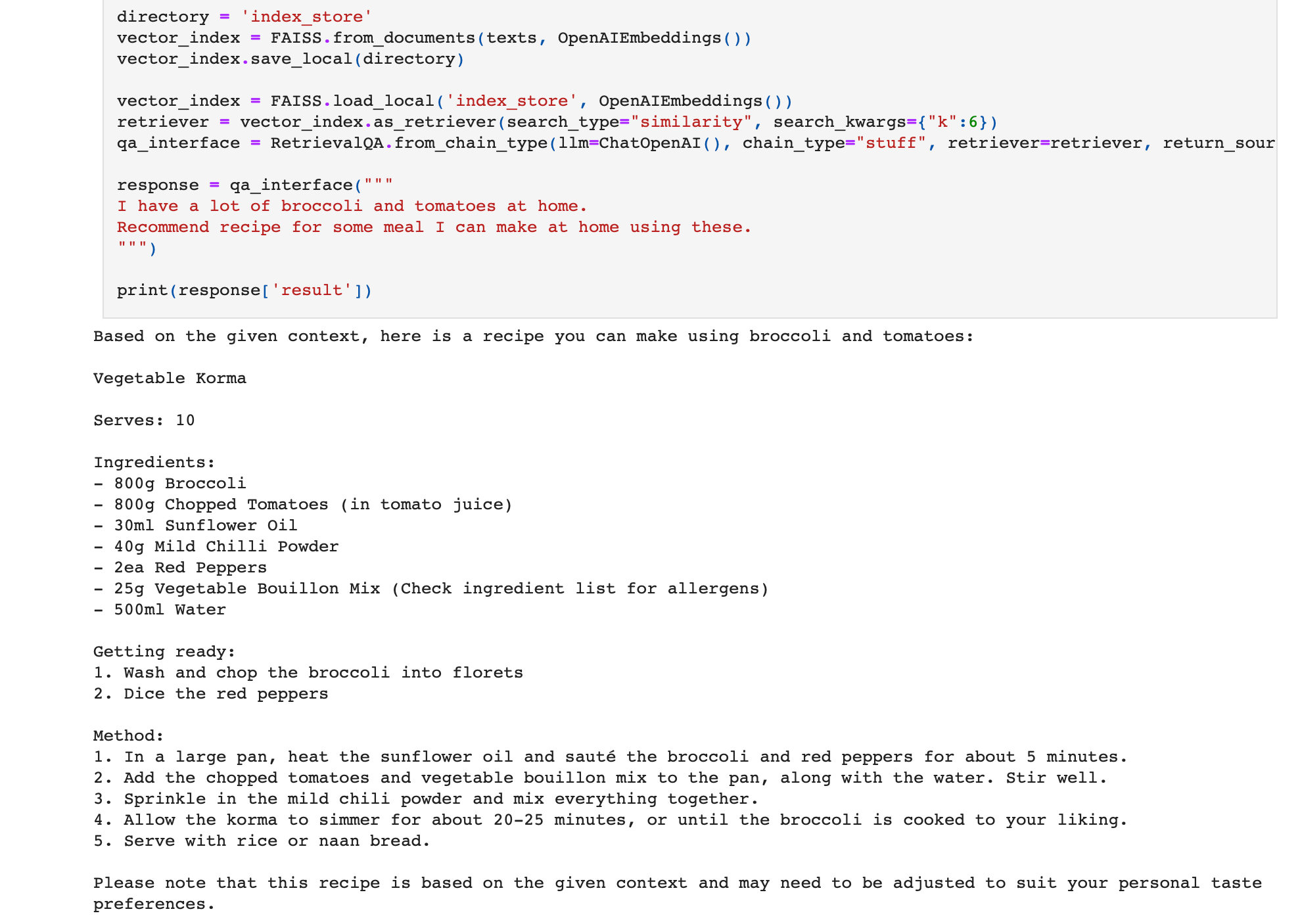
Automation 4 - Automated Question Paper Creator
You can feed textbooks and automate creation of complete question papers and tests using GPT API. The LLM can even generate the marking scheme for you!
We use the textbook Advanced High-School Mathematics by David B. Surowski and ask the LLM to create a question paper with a marking scheme for a particular chapter in the textbook.
We execute the below code -
from langchain.document_loaders import PyPDFLoader
from langchain.vectorstores import FAISS
from langchain.chat_models import ChatOpenAI
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains import RetrievalQA, ConversationalRetrievalChain
import os
import PyPDF2
pdf_file_obj = open('further.pdf', 'rb')
pdf_reader = PyPDF2.PdfFileReader(pdf_file_obj)
num_pages = pdf_reader.numPages
detected_text = ''
for page_num in range(num_pages):
page_obj = pdf_reader.getPage(page_num)
detected_text += page_obj.extractText() + '\n\n'
pdf_file_obj.close()
os.environ["OPENAI_API_KEY"] = 'Your OpenAI API Key'
os.environ["OPENAI_API_KEY"] = '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'
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
texts = text_splitter.create_documents([detected_text])
directory = 'index_store'
vector_index = FAISS.from_documents(texts, OpenAIEmbeddings())
vector_index.save_local(directory)
vector_index = FAISS.load_local('index_store', OpenAIEmbeddings())
retriever = vector_index.as_retriever(search_type="similarity", search_kwargs={"k":6})
qa_interface = RetrievalQA.from_chain_type(llm=ChatOpenAI(), chain_type="stuff", retriever=retriever, return_source_documents=True)
response = qa_interface("""
list 5 questions of 20 marks total of varying difficuly and weightage based on the topic "Euclidian Geometry"
""")
print(response['result'])The LLM reads the PDF textbook and create the question paper for us!
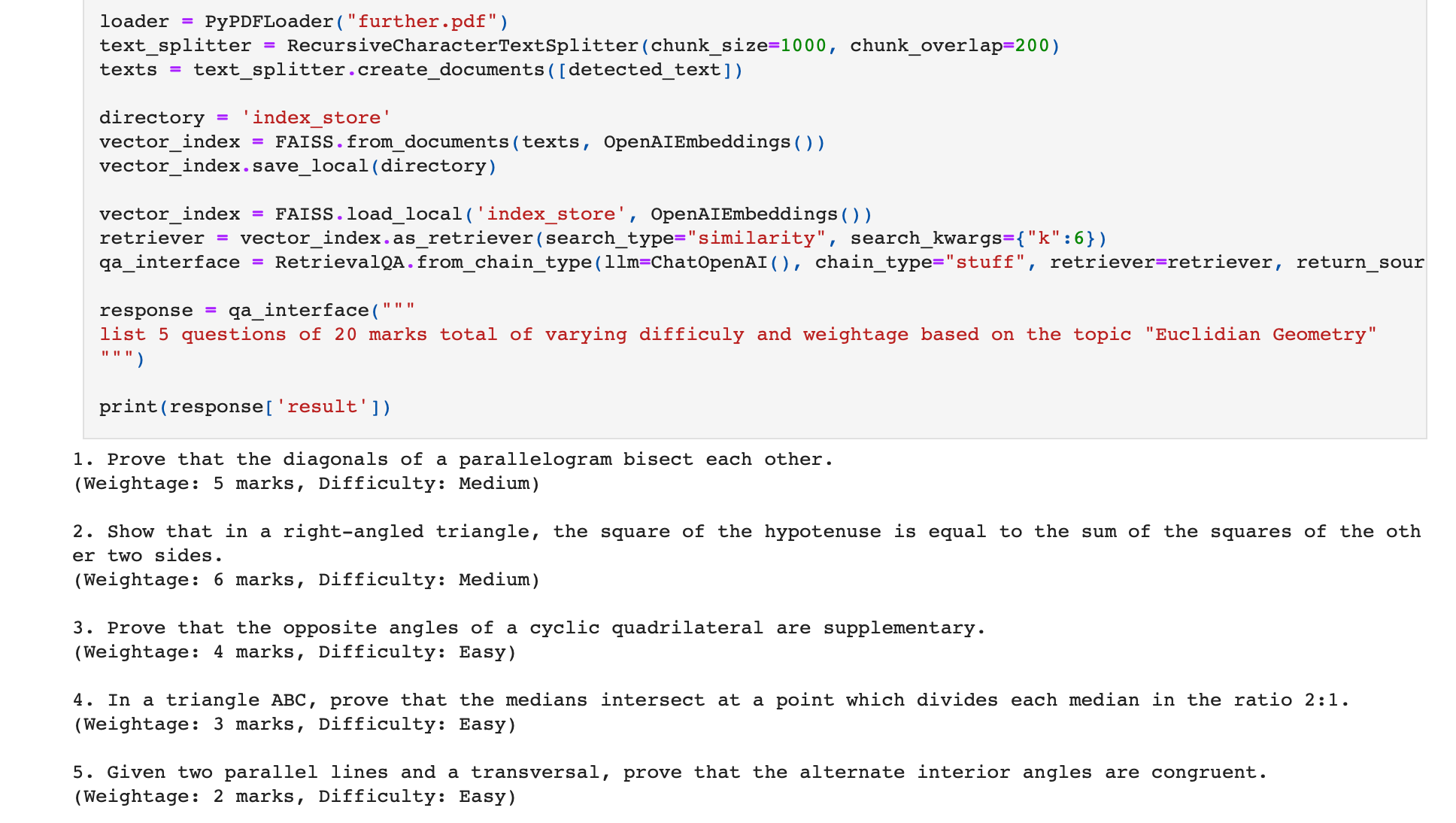
How to Deploy these Automations?
Choosing how and where to build this will vary depending on the scale of automation, time and budget constraints, import and export integrations required etc.
Scenario I - Low Scale / Simple Tasks
You can use no-code workflow automation software like Zapier and Make.
These platforms allow you to create automated workflows and exchange data between applications based on triggers and actions, directly from their no-code platform without needing to write any code whatsoever.
If you want to use Zapier/Make and their OpenAI GPT integration for creating automated document workflows, we strongly recommend watching this Youtube tutorial on how to set these automations up in these no-code platforms.
For example, you can create a workflow to run as follows -
- Use Zapier's Gmail integration to run the workflow whenever a new email with a PDF invoice attachment comes in your Gmail.
- Use Zapier's Nanonets OCR integration to Extract Text from PDF invoice.
- Use Zapier's OpenAI GPT Integration to send a request along with the extracted data and configure it to return structured data from invoice.
- Use Zapier's Google Sheets integration to populate the response data obtained as the response from the GPT model in a Google Sheet.
- Use Zapier's Quickbooks Accounting Software integration to populate the same GPT response data in Quickbooks.
Here, the Gmail, Google Sheets and Quickbooks integration are already pre-created by Zapier. Even the OpenAI GPT API call is pre-built and ready to use.
Pros -
- saves time and resources required to create external app integrations.
- workflow automation software like Zapier/Make are increasingly offering advanced flexibility and actions in workflows these days.
Cons -
- these automation implementations cannot scale properly.
- they do not offer the level of customization required to do more complex tasks.
Scenario II - Low Scale, Complex Tasks
You can start by creating an API service to handle the GPT task of interacting with the PDF. The API should be able to accept requests with PDF payloads, execute the GPT task, and return the GPT response (directly or after post-processing) as the response of the API service. Basically, define the GPT function and other parameters (model, prompt, system_msg etc.) in your API service according to your use case. Learn how to create your own API service here.
Tip: If you want higher level of customization but are not scaling your automation in terms of volume, you can use cloud serverless functions like AWS Lambda, Google Cloud Functions etc. in place of building your own API service.
For importing and exporting data to other applications - you can still use no-code workflow automation software like Zapier and Make. This is possible by using custom API calls in Zapier or Make. Learn how to use custom API calls in Zapier here. These platforms combine inter-application data flow functionalities with the ability to send custom API calls to your API service.
For implementing the same example workflow -
- Use Zapier's Gmail integration to run the workflow whenever a new email with a PDF invoice attachment comes in your Gmail.
- Use Zapier's Nanonets OCR integration to Extract Text from PDF invoice.
- Use Zapier's Custom Webhooks or Zapier's Custom Post Requests integration to send a request to your API service with the extracted data from invoice.
- Your API service receives the request and returns structured data of invoice. Learn how to create your own API service here.
- Use Zapier's Google Sheets integration to populate the response data obtained as the response from the GPT model in a Google Sheet.
- Use Zapier's Quickbooks Accounting Software integration to populate the same GPT response data in Quickbooks.
Our job here becomes only to create the API service which handles the GPT task of interacting with the PDF, saving us time which would have gone in creating other cumbersome integrations with different apps for importing and exporting documents and data.
Pros -
- saves time by offering ready to use external integrations.
- flexibility to perform complex tasks as it is your own API service.
Cons -
- these automation implementations cannot scale properly.
- they fail for tasks where advanced interactions with external apps is needed.
Scenario III - Large Scale, Complex Tasks
The best way to implement these kinds of automations is to create your own API service which handles the automation end-to-end.
For implementing the same example workflow -
- Use Gmail API to create a service that fetches new emails with invoice PDFs every hour.
- Use Nanonets API to extract text from PDF invoice.
- Use OpenAI GPT API to output structured data from invoice upon inputting the extracted text.
- Use Google Sheets API to populate the structured data obtained as the response from the GPT model in a Google Sheet.
- Use Quickbooks Accounting Software API to populate the same GPT response data in Quickbooks.
Basically, you would create and deploy the above functionalities in your own API service. Learn how to create your own API service here.
Pros -
- high level of customization possible.
- execution of complex workflows becomes possible.
- you can create commercial apps and sell them.
Cons -
- these implementations will take time and resources to build.
Build a PDF Chatbot with UI
In this section, we are going to explore how to deploy a PDF chatbot with a user interface (UI) on a webpage. Instead of building one from scratch, we are going to use a template to simplify this process.
Let us get started -
- Clone this Github repo.
 anpigon
anpigon- Let us now install the required dependencies. Go inside the cloned repo folder in your terminal and install using yarn by typing the following command.
yarn install
- Open the cloned repo folder in your code editor. Create a .env file with the following contents -
OPENAI_API_KEY=Your_OpenAI_API_Key
OPENAI_CHAT_MODEL=gpt-3.5-turbo
ANSWER_LANGUAGE=en-US- It is now time to create the vector store for our PDFs. Add all PDFs you want to use in the PDF chatbot to the 'docs' folder present inside the cloned repo folder. We are going to ingest two classic texts of fiction by Mark Twain - Tom Sawyer and Huckleberry Finn, and will try extracting common writing themes from them.
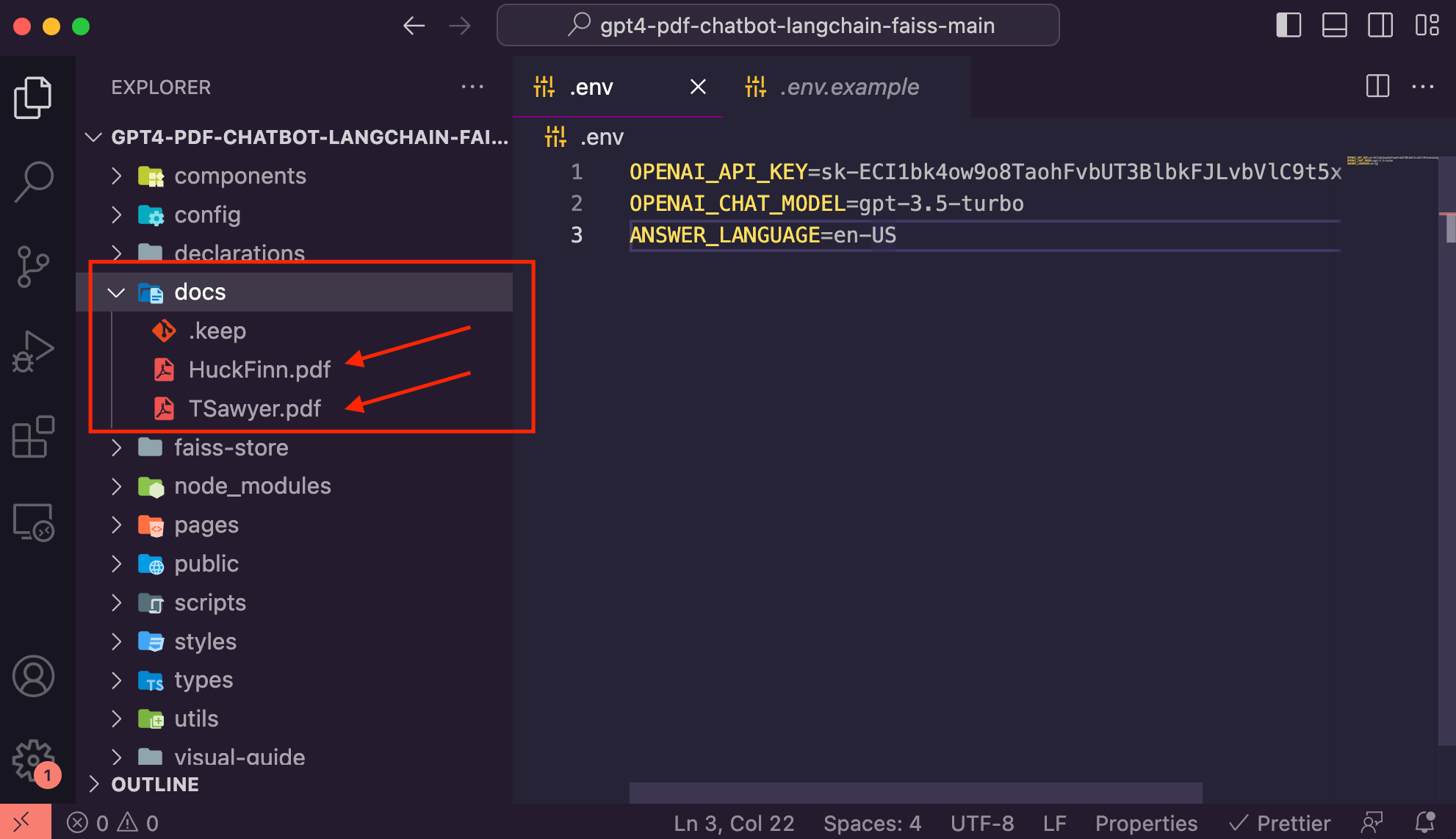
- Once you have added the docs, you can create the vector store by running the following command in the cloned repo folder in your terminal -
npm run ingest
- Once this completes, your vector db will be ready to use from the user interface (UI). To build the app, run the following command in the cloned repo folder in your terminal -
npm run build
- Your app is now ready. Run your app using the following command in the cloned repo folder in your terminal -
npm run start
- Your app is now running at http://localhost:3000. Let us ask it to give similarities between Tom Sawyer and Huckleberry Finn.
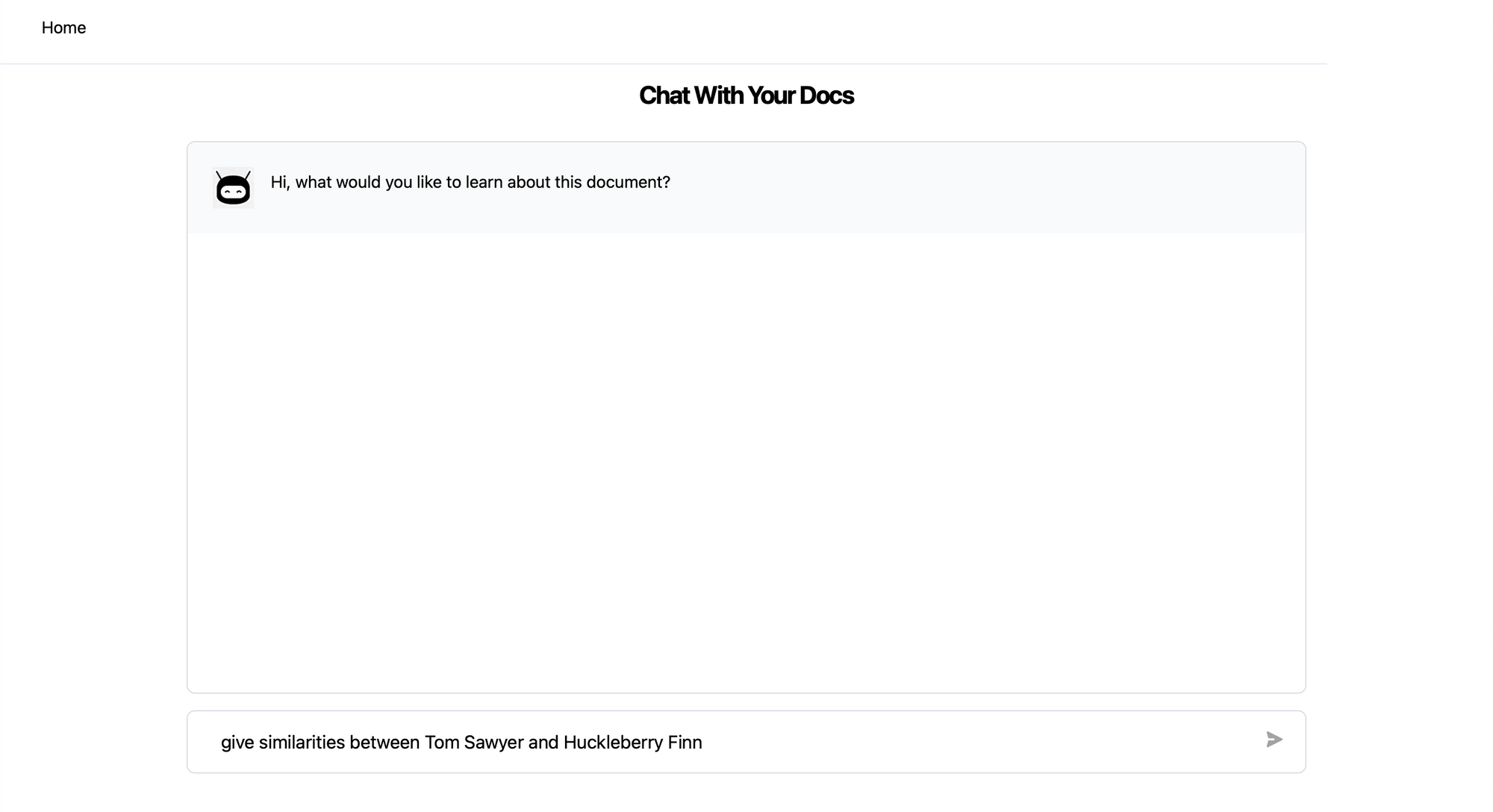
- The app provides a response discussing similarities in how the two characters are written.
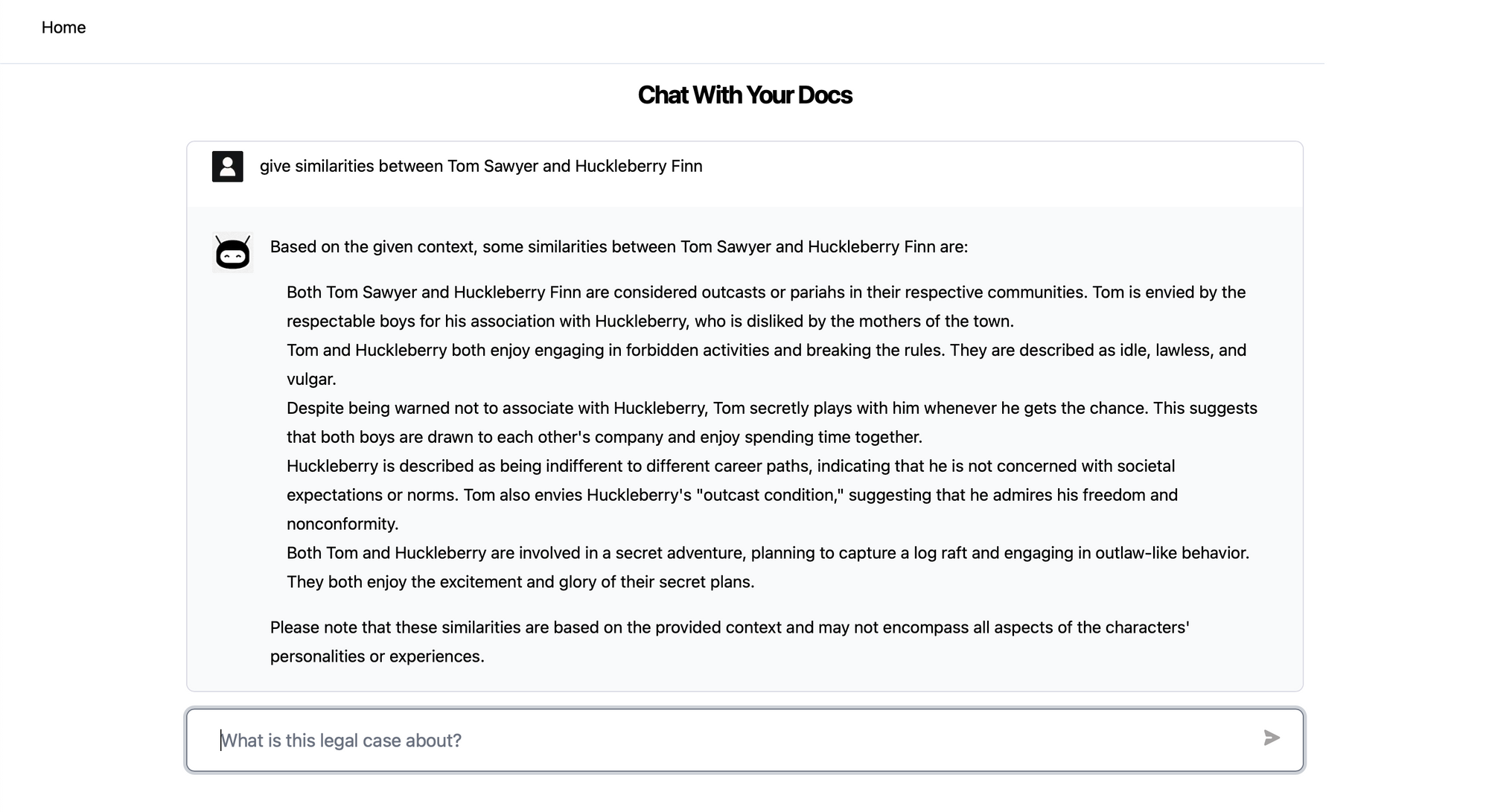
- The app also provides sections from the source content which are relevant for the question and subsequently used in generating the answer.
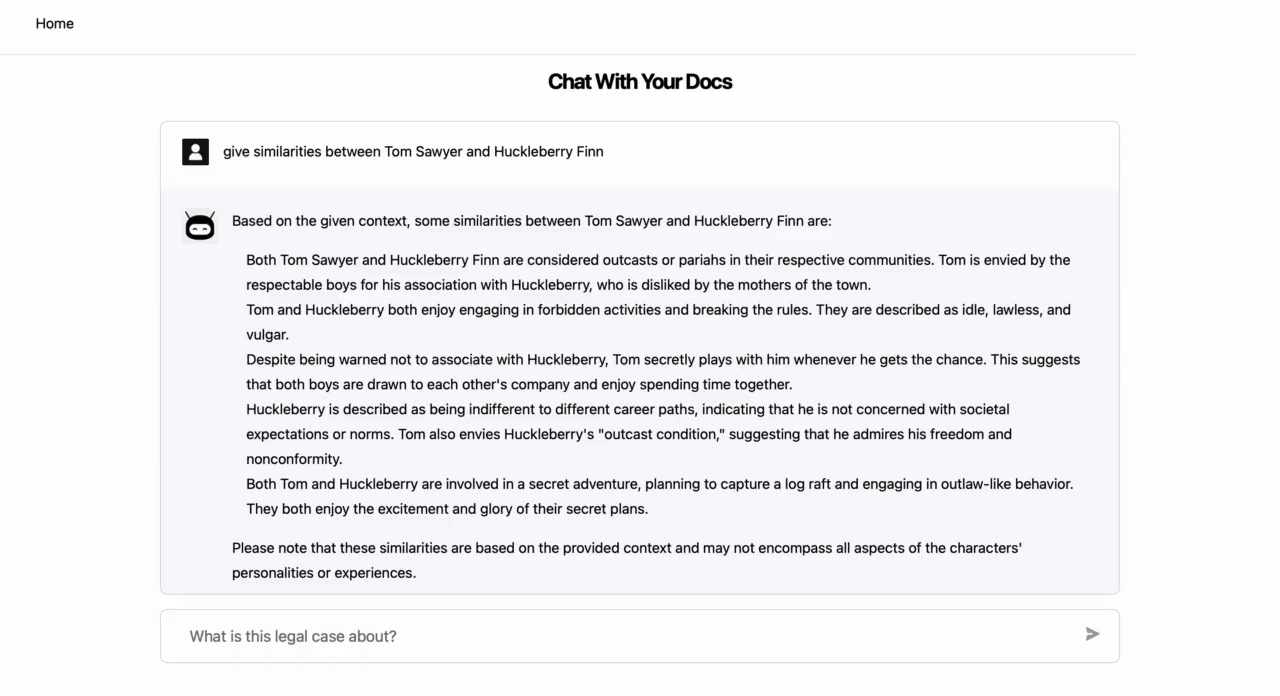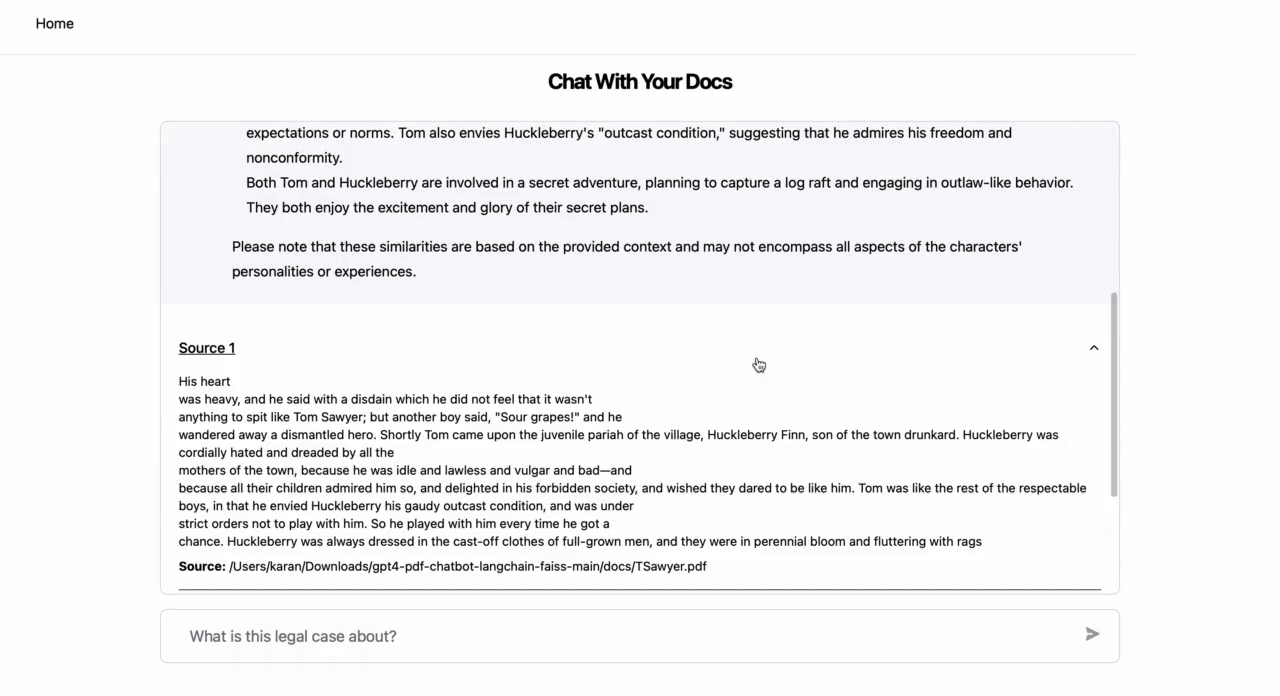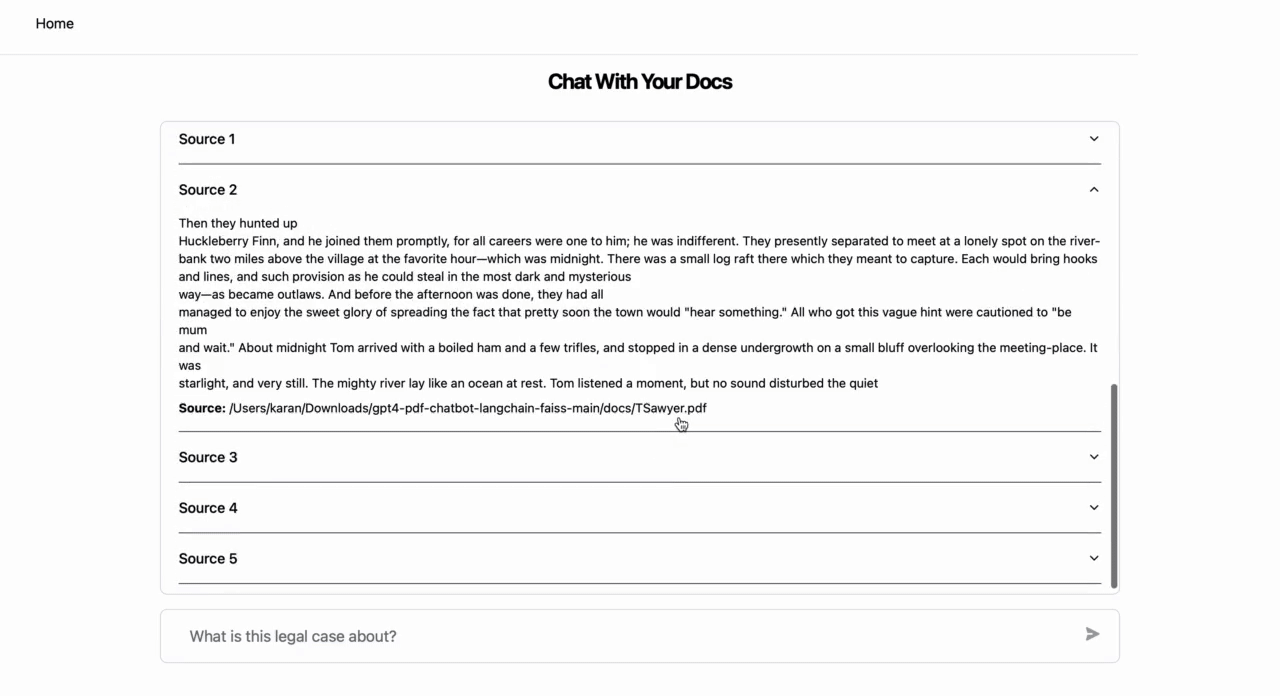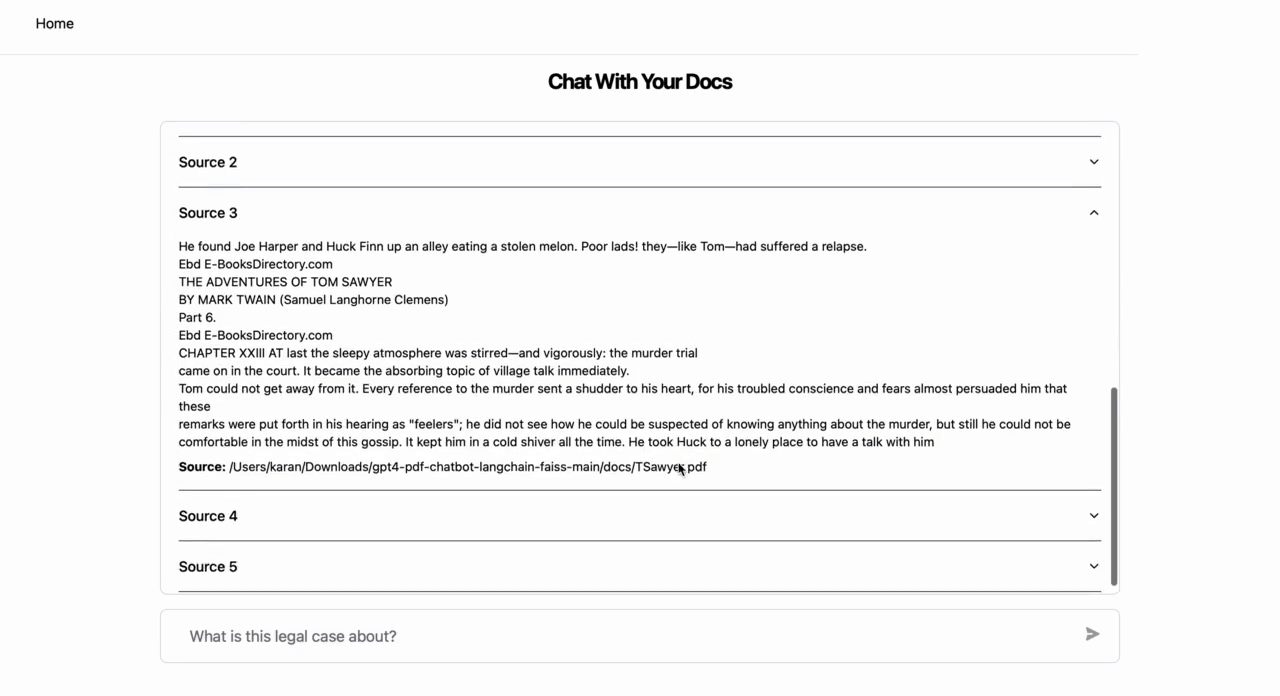
You can also repurpose the code base to create a general PDF chatbot, where the user interface (UI) first ingests your PDFs via the UI and then provides a chat modal for chatting with the uploaded PDF set.
Chatting with PDFs: A Game-changer for Individuals and Businesses
As we immerse ourselves deeper into the digital age, it becomes essential to explore more intuitive and efficient ways to interact with our data. The ability to chat with PDFs using Language Learning Models (LLMs) is a revolutionary step in how we access and utilize information. In this section, we explore the transformative impact of this technology and how it's streamlining operations, improving productivity, and making our lives easier, one PDF at a time.
For Businesses
In the high-paced world of businesses, every second counts. Often, professionals and business processes require instant access to specific data from a sea of documents. Manual reading is becoming increasingly inconvenient due to constraints of time and resources, and that's where what LLMs enable us to do - chat with PDFs - becomes revolutionary.
Imagine a scenario in a busy accounting department. The company receives hundreds of invoices in PDF format from various vendors each day. Each of these invoices must be processed and matched against corresponding purchase orders and receipts. Chatting with PDFs can streamline this process. Simply ask the LLM to extract the relevant details from the invoice, receipt & purchase order - vendor details, dates, prices, amounts, quantities etc. It will go through the PDFs, find the required information, and match the invoice to the receipt and the purchase order in a matter of seconds, with instant and accurate mismatch detection.
Other business workflows can also benefit -
- Customer Success: Rapidly fetch specific product or service details from extensive usage documentation and user manuals to provide prompt customer support.
- Contract Review: Legal departments can benefit from the ability to chat with contracts saved in PDF format. A query about a specific clause or term can return an instant response, making the lengthy contract review process faster and more manageable.
- Regulatory Compliance: LLMs can effortlessly sift through regulatory paperwork, highlight the important points, and ensure the business is always compliant.
Even beyond these conventional business workflows, chatting with PDFs has the potential to revolutionize other aspects of business operations.
- Sales Knowledge Base: A salesperson can quickly pull out the necessary product details, comparisons, or historical sales data to conduct sales calls effectively, all powered by an LLM that "reads" the company's PDF resources in real time.
- Market Research: An analyst could chat with a PDF report to quickly extract specific market trends, saving time on browsing entire sections.
For Individuals
In the sphere of personal and individual professional life, the ability to chat with PDFs is no less transformational. As we navigate through our digital lives, we are continually bombarded with PDFs of all shapes and sizes - it could be a bank statement, an eBook, a research paper, or a user manual. LLMs can help us cut through this digital clutter and get right to the information we seek.
Let's delve into how LLMs can empower individuals:
- Personal Finances: Imagine having to comb through several months of bank statements and credit card bills to understand your spending patterns or to prepare a budget. With an LLM, you can simply ask questions like "What were my total expenses in June?", "How much did I spend on groceries in the last quarter?", or "What were the biggest transactions last month?". The LLM can quickly parse through the PDF statements and provide the answers you need, saving you time and effort.
- Educational Resources: Students and self-learners can benefit enormously from this technology. It is not uncommon for a student to have numerous PDF textbooks and supplementary reading materials. An LLM can help extract specific information, summarize chapters, or even generate questions for revision, making studying more efficient and engaging.
- Research Papers: For researchers and academicians, sifting through a deluge of research papers to find relevant information can be a daunting task. An LLM can be a powerful tool here - you can ask it to find specific methodologies, results, or discussions from a collection of research papers saved as PDFs.
- Professional Development: Individuals can also utilize LLMs in their professional lives. For example, a software developer might need to understand a specific function from a long API documentation saved as a PDF. Instead of manually searching the document, they can ask the LLM directly, saving precious time and effort.
- User Manuals: Understanding complex user manuals, be it a new software or a kitchen appliance, can be a tedious process. With an LLM, you can directly ask questions and get the relevant steps or precautions from the manual, making the process of learning new tools and appliances much smoother.
- Healthcare Documents: Navigating healthcare paperwork can be a stressful process, especially during a health crisis. With an LLM, one can easily chat with their healthcare documents to understand insurance coverage, claims process, or even medication instructions.
In conclusion, the potential applications of LLMs in our personal and individual professional lives are vast and revolutionary. By making our interactions with PDFs more conversational and responsive, LLMs can help us manage our digital lives more efficiently and effectively. Whether it's managing personal finances, enhancing learning, or navigating complex documentation, the ability to chat with PDFs is a powerful tool for the modern individual.
Chat with PDFs using Nanonets
We at Nanonets have created our own LLMs which are specifically tailored for interacting with documents, and they facilitate the creation of all kinds of automated document workflows for our clients. You can even chat with your PDFs using our AI, enabling seamless interaction with your documents in real time.
We have recently released our 'zero-shot' extraction model which allows you to interact with and extract data from any document without the use of any training data. Instead of training a model, you can simply indicate the names of the fields you want to interact with or extract from your document along with a description / definition of the field and our models powered by LLMs take care of the rest.
Here is a sneak peak of how you can start executing tasks involving documents using the power of Generative AI & our in-house LLMs within seconds -
On top of that, our document workflows offer ready to use functionalities and integrations like -
- importing documents from your choice of software / database / ERP.
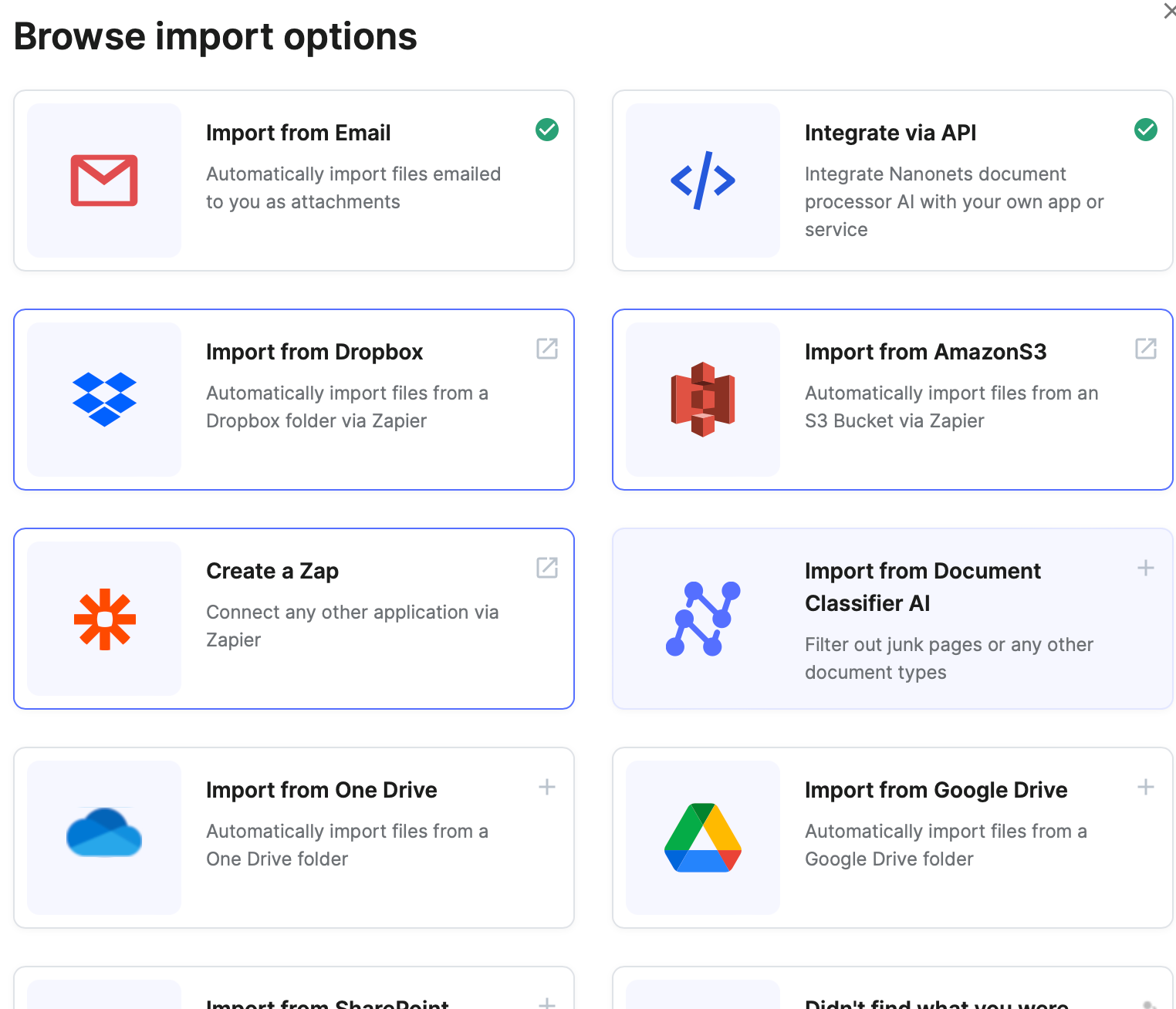
- creating automated validation checks.
- setting up automated or manual approval processes.
- exporting documents and data to your choice of software / database / ERP after the workflow has run.
All this opens up infinite possibilties for automating any personal or professional tasks involving PDFs in your daily life within minutes.
In summary, chatting with PDFs using LLMs has immense potential to transform and automate any document-driven task. Nanonets provides the tools along with a super user-friendly interface to realize this potential by enabling the creation of automated document workflows within seconds, seamlessly integrating with systems you already use via our vast number of integrations. Our zero-shot capabilities allow you to chat, interact and extract data from documents without any training data, empowering non-experts to unlock the value locked within PDFs.
The ability to have a conversation with your documents and extract the insights you need instantly will redefine how we work with information. LLMs remove the friction inherent in accessing PDF data, leading to increased productivity, reduced costs and greater organizational efficiency. Harnessing these technologies will be crucial as the volume of PDFs and unstructured data continues to explode.
We are headed towards an era of 'Data-On-Demand' - where all the information we need is readily available to us as and when we need it, unleashing untold possibilities for individuals, businesses and society as a whole. Go ahead and start automating your document workflows today - Nanonets is here to enable your journey towards 'Data-On-Demand' , one PDF at a time!
Appendix
Appendix 1 - Technology behind LLMs
Language Learning Models (LLMs), like OpenAI's GPT-4, utilize an advanced form of artificial intelligence known as Transformer-based deep learning. This method employs a specific neural network architecture, known as a Transformer, which is exceptional at understanding context within language. This understanding is driven by a mechanism called "attention", which evaluates and adjusts the influence of various words on each other.
Let us go through the key points of building an LLM -
- Transformers: Introduced in the paper "Attention is All You Need", Transformers use an "attention" mechanism to understand the context and interrelationships of words in a sentence.
- Unsupervised Learning: The model is trained with unsupervised learning, meaning it's fed an extensive amount of text data (such as books, articles, websites) and it learns by predicting the next word in a sentence. The model then self-adjusts based on the error between its prediction and the actual word. After billions of predictions, the model significantly improves its understanding of language context, semantics, and factual knowledge embedded in the training data.
Example of Learning Process:
For instance, the model often encounters sentences like:
"The sum of 2 and 3 is 5."
"When you add 7 and 3, you get 10."
These sentences establish a pattern: when certain numerical values are followed by phrases like "sum of" or "add," the next word is often a number that represents the sum of the mentioned values.
Now, given a new input: "The sum of 6 and 4 is," the model would predict the next word as: "10."
- Understanding vs Pattern Recognition: It's important to note that the model might not truly understand the concept of addition in the same way humans do; it's just very good at recognizing patterns from its training.
- Fine-Tuning: The pre-training phase is followed by a process of fine-tuning. This supervised learning phase involves further training the model on specific tasks like question answering or text completion. In this stage, the model refines its general language understanding skills to perform more specialized tasks.
- Optimization: The model uses backpropagation and gradient descent to optimize its millions of parameters, iteratively improving its predictions.
The culmination of these processes results in an AI system capable of generating human-like text, with an impressive understanding of the context of a conversation or a piece of text.
Appendix 2 - Comparison of LLM Models
We tried out the most advanced LLMs available and evaluated how they compared with each other. Let us take a look -
GPT-4
GPT-4 is the latest model made available under OpenAI's roster of LLMs. It has been trained using publicly available data and reinforcement learning with human feedback. This training approach enables GPT-4 to generate, edit, and iterate on both creative and technical writing tasks, making it versatile in tasks such as composing songs, writing code, and even aiding in learning.
Pros:
- The model has the large number of parameters (rumored to be more that 1 Trillion), making it extremely powerful and capable of performing complex tasks.
- It can generate human-like responses to natural language queries, making it ideal for conversational applications.
- It performs a wide range of tasks, including language translation, summarization, and question answering with ease.
- It has advanced reasoning capabilities.
- It can perform creative tasks well.
- Commercial Use is permitted.
Cons:
- API availability is limited, and can only be obtained via a waitlist.
- The model is expensive to use, with high costs per API call.
- It can be slow to generate responses, especially for longer inputs.
GPT-3.5
OpenAI's GPT-3.5, an evolution of the GPT-3 model, is an advanced language model with superior parsing abilities. It emulates human instruction-following closely and also employs a large knowledge base to respond to queries.
Pros:
- GPT-3.5 is a significant improvement over GPT-3, a gigantic language model trained on internet data, possessing over 175 billion machine learning parameters.
- GPT-3 has already found commercial usage in content automation and customer experience enhancement.
- The versatile API allows for the seamless integration of GPT-3.5 into developers' applications.
- The vast parameter count facilitates the generation of high-quality text that is virtually indistinguishable from human writing.
- The model has been trained on a variety of datasets and has undergone supervised testing and reinforcement stages to fine-tune its performance.
- Custom Fine Tunes are easy to implement, allowing developers to create custom variations of the model for specific purposes.
Cons:
- Biases in output generation present a potential issue, and developers need to be cognizant of these when using GPT-3.5.
- The model is moderately expensive to use, with high costs per API call.
Google PaLM
PaLM (Parsing, Lexing, and Modeling) is a sophisticated AI language model developed by Google, sharing parallels with models by OpenAI and Meta in offering potent text generation capabilities. Owing to its broad utility in several text generation tasks, PaLM stands as a versatile instrument in the domain of natural language processing.
Pros:
- Developers can harness the power of the PaLM API, offering an easy-to-use interface for embedding PaLM into applications and services.
- The API works very well for examination and understanding of potentially harmful scripts, efficient detection of malicious activities, and execution of tasks such as word completion and code generation.
- Commercial utilization of PaLM is enabled.
- PaLM's key strength lies in its ability to manage a multitude of tasks. Its versatility is appealing for developers and personal users alike.
- Trained on an enormous dataset of text and code, PaLM delivers accurate and contextually relevant results.
Cons:
- One potential downside is the risk of biased or inappropriate outputs. If the training data contains bias or inappropriate content, it may reflect in the generated output. Developers using PaLM need to be wary of these potential biases and take appropriate mitigation steps.
- The exact details regarding PaLM's training process remain undisclosed.
- Performance is worse compared to advanced OpenAI GPT models.
Claude LLM v1
Anthropic's Claude LLM is an innovative language model that's been fine-tuned to help users generate high-quality content across a variety of uses. Due to its advanced capabilities and user-friendly interface, it has become a preferred tool for businesses, content creators, and professionals.
Anthropic also became the first company to offer 100k tokens as the largest context window in its Claude-instant-100k model. Basically, you can load close to 75,000 words in a single chat message, something which is not directly possible via the other LLMs discussed.
Pros:
- Largest context window size. Basically offers largest prompt length (length of one chat message) support out of all listed LLMs.
- The model ensures high-quality results by producing coherent and contextually relevant content.
- Claude LLM's ability to be used for a broad range of content types makes it adaptable to various business needs.
Cons:
- Despite its ability to produce impressive content, it might lack the creative spark and personal touch that other LLMs emulate.
- The quality of the output heavily depends on the prompt provided by the user; a well-crafted prompt results in better content.
Microsoft T5
Microsoft T5 is an advanced natural language processing model introduced by Microsoft, which is built around the encoder-decoder architecture and leverages the text-to-text format for addressing a broad spectrum of NLP tasks. The model, trained through a combination of supervised and unsupervised learning methods, presents supervised learning through downstream task training from benchmarks, and self-supervised learning through the use of corrupted tokens.
Pros:
- The model comes in multiple versions including T5v1.1, mT5, byT5, UL2, Flan-T5, Flan-UL2, and UMT5, offering varying capabilities to users.
- It allows fine-tuning in both supervised and unsupervised manners utilizing teacher forcing.
- The model is highly versatile and can be employed for a multitude of tasks, such as translation, summarization, and text classification.
- It offers an API for developers, allowing businesses to integrate the model into their applications and services to leverage its capabilities.
- The reputation and support of Microsoft ensure reliable and continuous development and updates.
Cons:
- Commercial use of the model might necessitate appropriate licensing and adherence to Microsoft's terms and conditions.
- The performance and quality of responses generated by T5 can vary depending on the specific use case and dataset.
- Fine-tuning T5 requires substantial expertise and domain-specific knowledge.
- The associated cost of using T5 and the required computational resources may present challenges for certain businesses.
LLaMA
Meta AI's FAIR team developed LLaMA, a language model intended for research use in fields such as natural language processing and artificial intelligence. It was trained over a three-month period and is available in various sizes.
You need to apply for permission to use the model here.
Pros:
- Multiple model sizes cater to different research needs.
- Provides good performance across various tasks due to diverse training sources (CCNet [67%], C4 [15%], GitHub [4.5%], Wikipedia [4.5%], Books [4.5%], ArXiv [2.5%], Stack Exchange[2%]).
- Can perform language-specific tasks with varying effectiveness.
Cons:
- Lacks reinforcement learning with human feedback, which can lead to generation of toxic or offensive content.
- Non-commercial license limits its applicability outside research.
- Access requires permission, potentially limiting availability.
StableLM
StableLM, by Stability AI, is an open-source language model suite with 3 billion and 7 billion parameter versions, and larger models (up to 65 billion parameters) are under development. Its training is based on a new experimental dataset built on The Pile.
Pros:
- Can generate both text and code, making it applicable across a range of applications.
- High transparency and scalability due to its open-source nature.
- Trained on a diverse dataset, The Pile, contributing to a wide capability range.
Cons:
- Still in the alpha version, meaning it may have stability and performance issues.
- The model's size demands significant RAM, limiting its usability on some platforms.
- Released under a non-commercial license, limiting its use to research only.
Dolly
Dolly, a language model created by Databricks, has been trained on their machine learning platform. It's derived from EleutherAI’s Pythia-12b and fine-tuned on a dataset of instruction/response records generated by Databricks employees.
Pros:
- Licensed for commercial use, expanding its potential applications.
- Available on Hugging Face, making it accessible for easy use.
Cons:
- Not a state-of-the-art model, and can struggle with complex prompts and problems.
- Large model size requires significant RAM, making it hard to load on some platforms.
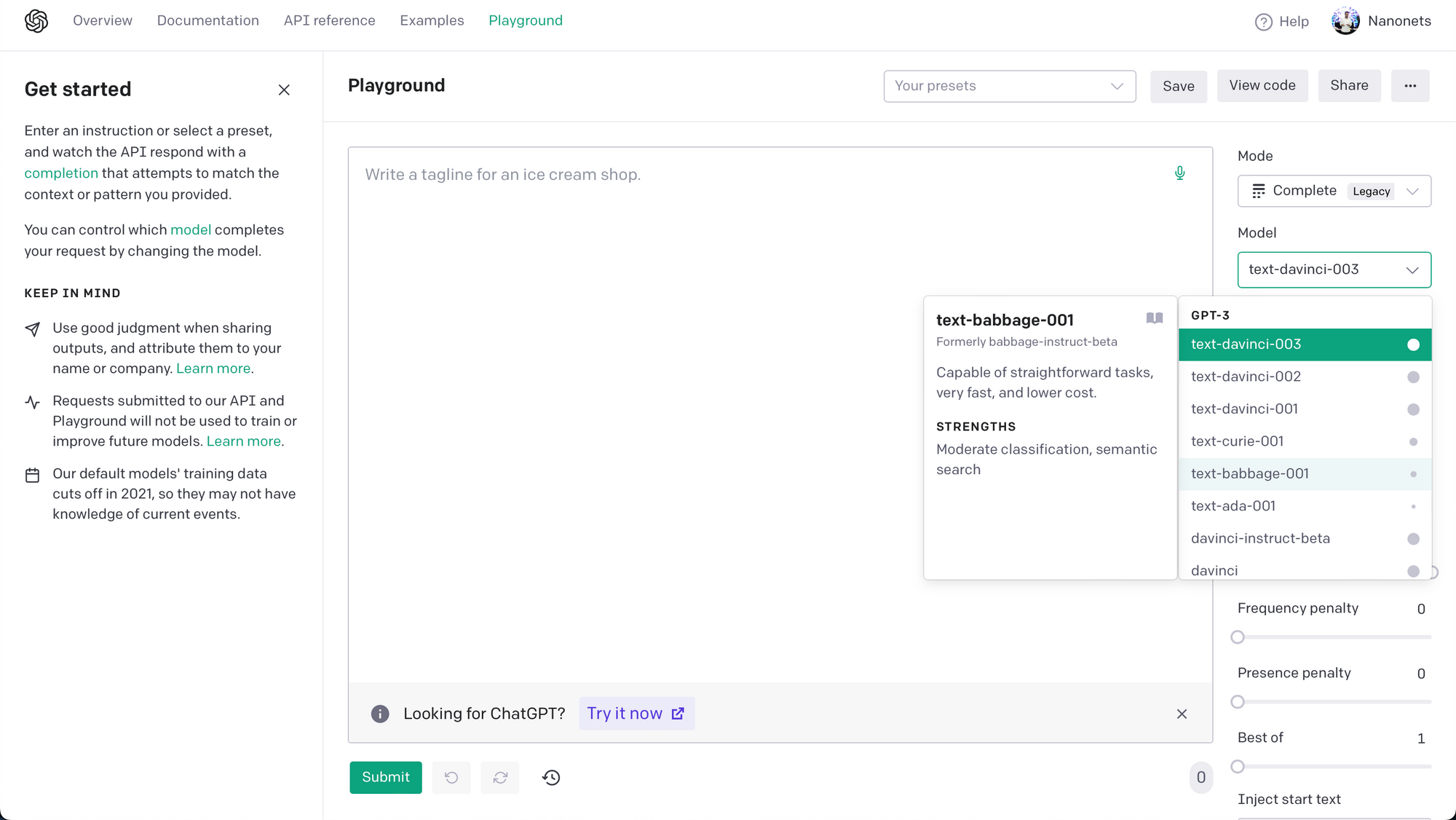
Appendix 3 - How to choose a GPT model?
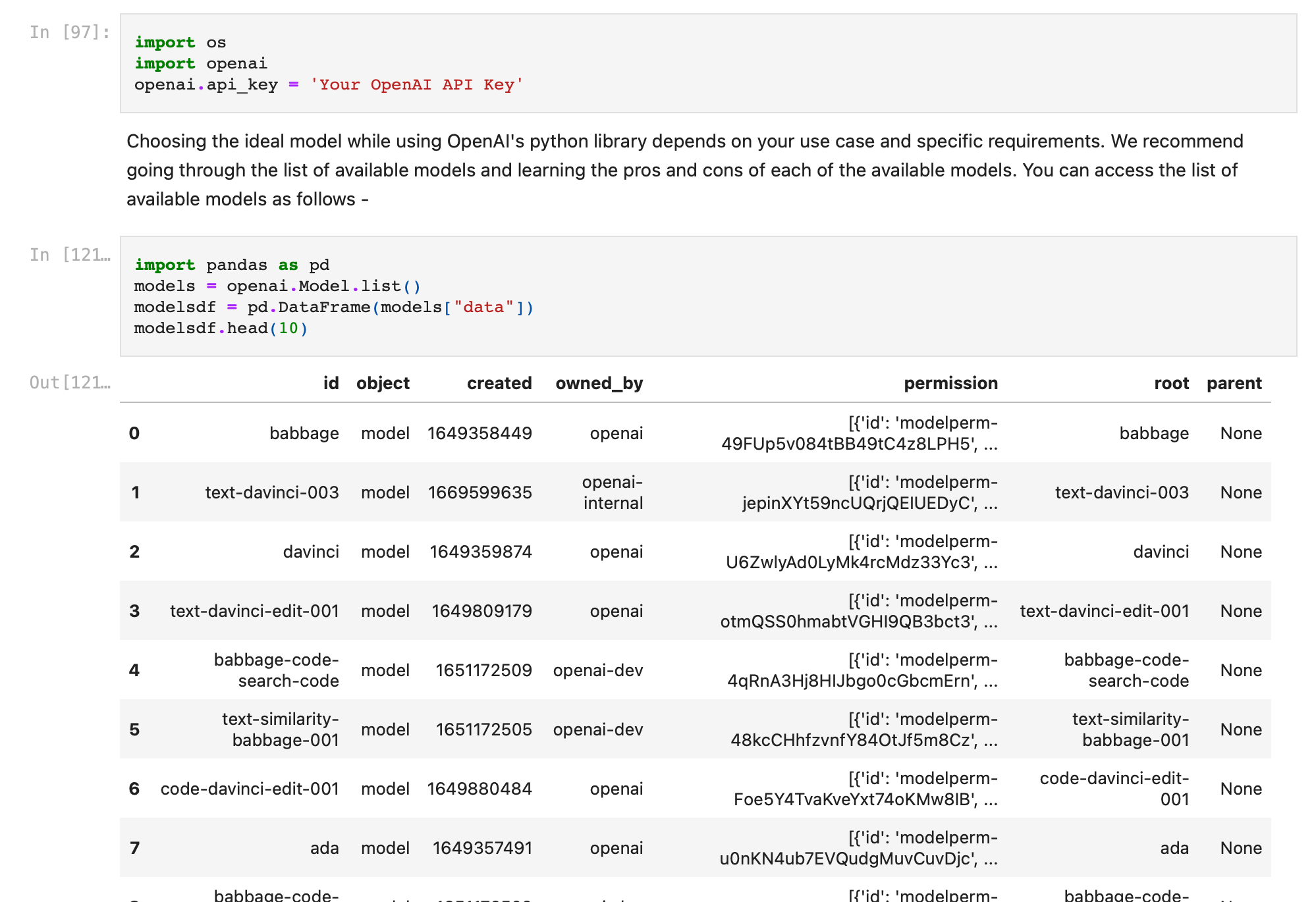
Choosing the ideal model while using OpenAI's python library depends on your use case and specific requirements. We recommend going through the list of available models and learning the pros and cons of each of the available models. You can access the list of available models as follows -
import pandas as pd
models = openai.Model.list()
modelsdf = pd.DataFrame(models["data"])
print(modelsdf)
A quick summary of OpenAI's model families (GPT-4, GPT-3, Codex, Content Filtering) -
-> GPT-4 is the latest model, capable of replacing other models for almost all tasks. Getting access is hard right now, and is possible by joining their waitlist. Cost is also high for using this model.
-> GPT-3, Codex, and Content Filtering models are cheaper, ready-to-use models that serve specific purposes, and can be used in place of GPT-4 models accordingly.
-> GPT-3 excels in text completion, insertion, and editing. It includes DaVinci, Curie, Babbage, and Ada series -
- GPT-3.5 is the most capable and expensive model here. It is recommended for fine tunes and excels at almost all kinds of tasks.
- DaVinci is suitable for understanding complex intentions and summarizing information for specific audiences. It works fairly well for fine tunes.
- Curie excels at sentiment analysis and text classification.
- Babbage and Ada models are ideal for straightforward tasks.
-> Codex models are adept at code completion, editing, and insertion. Two models are currently offered: Davinci and Cushman -
- Davinci is more capable.
- Cushman is faster.
-> Content Filtering models are used to detect and filter sensitive or potentially harmful content.
OpenAI Playground is an effective platform for testing and comparing different models.