
In the AI space, where technological development is happening at a rapid pace, Retrieval Augmented Generation, or RAG, is a game-changer. But what is RAG, and why does it hold such importance in the present AI and natural language processing (NLP) world?
Before answering that question, let's briefly talk about Large Language Models (LLMs). LLMs, like GPT-3, are AI bots that can generate coherent and relevant text. They learn from the massive amount of text data they read. We all know the ultimate chatbot, ChatGPT, which we have all used to send a mail or two. RAG enhances LLMs by making them more accurate and relevant. RAG steps up the game for LLMs by adding a retrieval step. The easiest way to think of it is like having both a very large library and a very skillful writer in your hands. You interact with RAG by asking it a question; it then utilizes its access to a rich database to mine relevant information and pieces together a coherent and detailed answer with this information. Overall, you get a two-in-one response because it contains both correct data and is full of details. What makes RAG unique? By combining retrieval and generation, RAG models significantly improve the quality of answers AI can provide in many disciplines. Here are some examples:
- Customer Support: Ever been frustrated with a chatbot that gives vague answers? RAG can provide precise and context-aware responses, making customer interactions smoother and more satisfying.
- Healthcare: Think of a doctor accessing up-to-date medical literature in seconds. RAG can quickly retrieve and summarize relevant research, aiding in better medical decisions.
- Insurance: Processing claims can be complex and time-consuming. RAG can swiftly gather and analyze necessary documents and information, streamlining claims processing and improving accuracy
These examples highlight how RAG is transforming industries by enhancing the accuracy and relevance of AI-generated content.
In this blog, we'll dive deeper into the workings of RAG, explore its benefits, and look at real-world applications. We’ll also discuss the challenges it faces and potential areas for future development. By the end, you'll have a solid understanding of Retrieval-Augmented Generation and its transformative potential in the world of AI and NLP. Let's get started!
Looking to build a RAG app tailored to your needs? We've implemented solutions for our customers and can do the same for you. Book a call with us today!
Understanding Retrieval-Augmented Generation
Retrieval-Augmented Generation (RAG) is a smart approach in AI to improve the accuracy and credibility of Generative AI and LLM models by bringing together two key techniques: retrieving information and generating text. Let’s break down how this works and why it’s so valuable.
What is RAG and How Does It Work?
Think of RAG as your personal research assistant. Imagine you’re writing an essay and need to include accurate, up-to-date information. Instead of relying on your memory alone, you use a tool that first looks up the latest facts from a huge library of sources and then writes a detailed answer based on that information. This is what RAG does—it finds the most relevant information and uses it to create well-informed responses. For a more interactive approach, check out how our ChatPDF tool can assist you with chatting directly with your PDF documents.
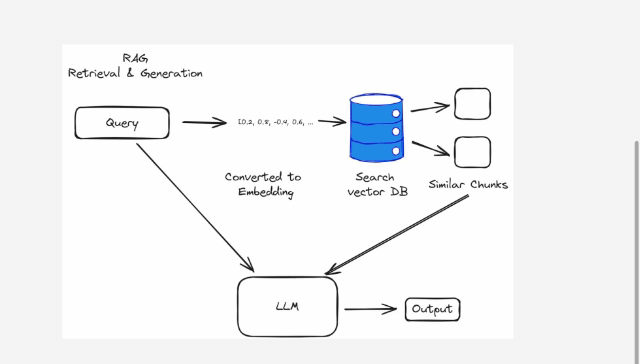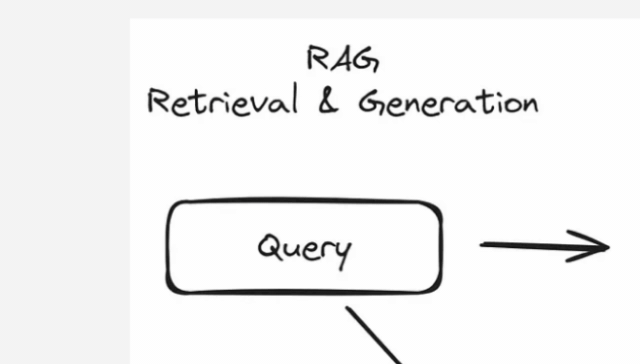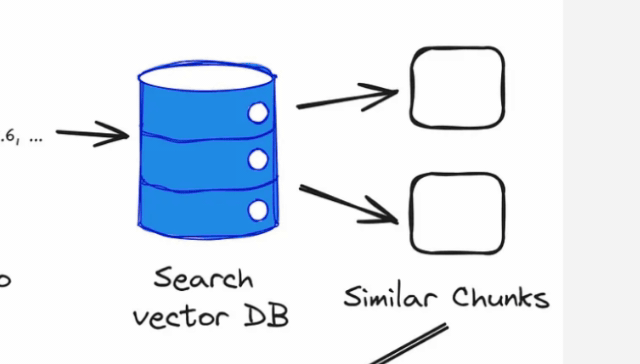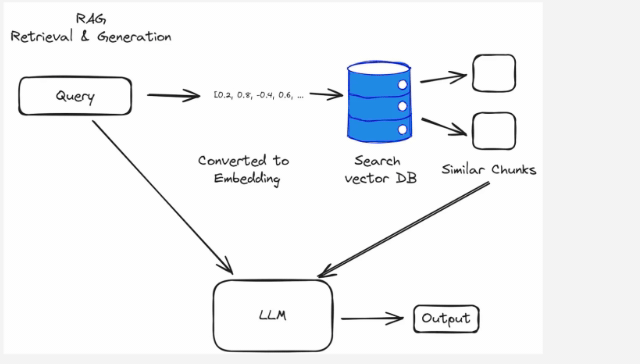
How Retrieval and Generation Work Together
- Retrieval: First, RAG searches through a vast amount of data to find pieces of information that are most relevant to the question or topic. For example, if you ask about the latest smartphone features, RAG will pull in the most recent articles and reviews about smartphones. This retrieval process often utilizes embeddings and vector databases. Embeddings are numerical representations of data that capture semantic meanings, making it easier to compare and retrieve relevant information from large datasets. Vector databases store these embeddings, allowing the system to efficiently search through vast amounts of information and find the most relevant pieces based on similarity. You can learn more about advanced techniques and tools in document data extraction, including the best LLM APIs for these purposes here
- Generation: After retrieving this information, RAG uses a text generation model that relies on deep learning techniques to create a response. The generative model takes the retrieved data and crafts a response that is easy to understand and relevant. So, if you’re looking for information on new phone features, RAG will not only pull the latest data but also explain it in a clear and concise manner.
You might have some questions about how the retrieval step operates and its implications for the overall system. Let’s address a few common doubts:
- Is the Data Static or Dynamic? The data that RAG retrieves can be either static or dynamic. Static data sources remain unchanged over time, while dynamic sources are frequently updated. Understanding the nature of your data sources helps in configuring the retrieval system to ensure it provides the most relevant information. For dynamic data, embeddings and vector databases are regularly updated to reflect new information and trends.
- Who Decides What Data to Retrieve? The retrieval process is configured by developers and data scientists. They select the data sources and define the retrieval mechanisms based on the needs of the application. This configuration determines how the system searches and ranks the information. Developers may also use open-source tools and frameworks to enhance retrieval capabilities, leveraging community-driven improvements and innovations.
- How Is Static Data Kept Up-to-Date? Although static data doesn’t change frequently, it still requires periodic updates. This can be done through re-indexing the data or manual updates to ensure that the retrieved information remains relevant and accurate. Regular re-indexing can involve updating embeddings in the vector database to reflect any changes or additions to the static dataset.
- How Does Static Data Differ from Training Data? Static data used in retrieval is separate from the training data. While training data helps the model learn and generate responses, static data enhances these responses with up-to-date information during the retrieval phase. Training data helps the model learn how to generate clear and relevant responses, while static data keeps the information up-to-date and accurate.
It’s like having a knowledgeable friend who’s always up-to-date and knows how to explain things in a way that makes sense.
What problems does RAG solve
RAG represents a significant leap forward in AI for several reasons. Before RAG, Generative AI models generated responses based on the data they had seen during their training phase. It was like having a friend who was really good at trivia but only knew facts from a few years ago. If you asked them about the latest trends or recent news, they might give you outdated or incomplete information. For example, if you needed information about the latest smartphone release, they could only tell you about phones from previous years, missing out on the newest features and specs.
RAG changes the game by combining the best of both worlds—retrieving up-to-date information and generating responses based on that information. This way, you get answers that are not only accurate but also current and relevant. Let’s talk about why RAG is a big deal in the AI world:
- Enhanced Accuracy: RAG improves the accuracy of AI-generated responses by pulling in specific, up-to-date information before generating text. This reduces errors and ensures that the information provided is precise and reliable.
- Increased Relevance: By using the latest information from its retrieval component, RAG ensures that the responses are relevant and timely. This is particularly important in fast-moving fields like technology and finance, where staying current is crucial.
- Better Context Understanding: RAG can generate responses that make sense in the given context by utilizing relevant data. For example, it can tailor explanations to fit the needs of a student asking about a specific homework problem.
- Reducing AI Hallucinations: AI hallucinations occur when models generate content that sounds plausible but is factually incorrect or nonsensical. Since RAG relies on retrieving factual information from a database, it helps mitigate this problem, leading to more reliable and accurate responses.
Here’s a simple comparison to show how RAG stands out from traditional generative models:
| Feature | Traditional Generative Models | Retrieval-Augmented Generation (RAG) |
|---|---|---|
| Information Source | Generates text based on training data alone | Retrieves up-to-date information from a large database |
| Accuracy | May produce errors or outdated info | Provides precise and current information |
| Relevance | Depends on the model's training | Uses relevant data to ensure answers are timely and useful |
| Context Understanding | May lack context-specific details | Uses retrieved data to generate context-aware responses |
| Handling AI Hallucinations | Prone to generating incorrect or nonsensical content | Reduces errors by using factual information from retrieval |
In summary, RAG combines retrieval and generation to create AI responses that are accurate, relevant, and contextually appropriate, while also reducing the likelihood of generating incorrect information. Think of it as having a super-smart friend who’s always up-to-date and can explain things clearly. Really convenient, right?
Technical Overview of Retrieval-Augmented Generation (RAG)
In this section, we’ll be diving into the technical aspects of RAG, focusing on its core components, architecture, and implementation.
Key Components of RAG
- Retrieval Models
- BM25: This model improves the effectiveness of search by ranking documents based on term frequency and document length, making it a powerful tool for retrieving relevant information from large datasets.
- Dense Retrieval: Uses advanced neural network and deep learning techniques to understand and retrieve information based on semantic meaning rather than just keywords. This approach, powered by models like BERT, enhances the relevance of the retrieved content.
- Generative Models
- GPT-3: Known for its ability to produce highly coherent and contextually appropriate text. It generates responses based on the input it receives, leveraging its extensive training data.
- T5: Converts various NLP tasks into a text-to-text format, which allows it to handle a broad range of text generation tasks effectively.
There are other such models that are available which offer unique strengths and are also widely used in various applications.
How RAG Works: Step-by-Step Flow
- User Input: The process begins when a user submits a query or request.
- Retrieval Phase:
- Search: The retrieval model (e.g., BM25 or Dense Retrieval) searches through a large dataset to find documents relevant to the query.
- Selection: The most pertinent documents are selected from the search results.
- Generation Phase:
- Input Processing: The selected documents are passed to the generative model (e.g., GPT-3 or T5).
- Response Generation: The generative model creates a coherent response based on the retrieved information and the user’s query.
- Output: The final response is delivered to the user, combining the retrieved data with the generative model’s capabilities.
RAG Architecture
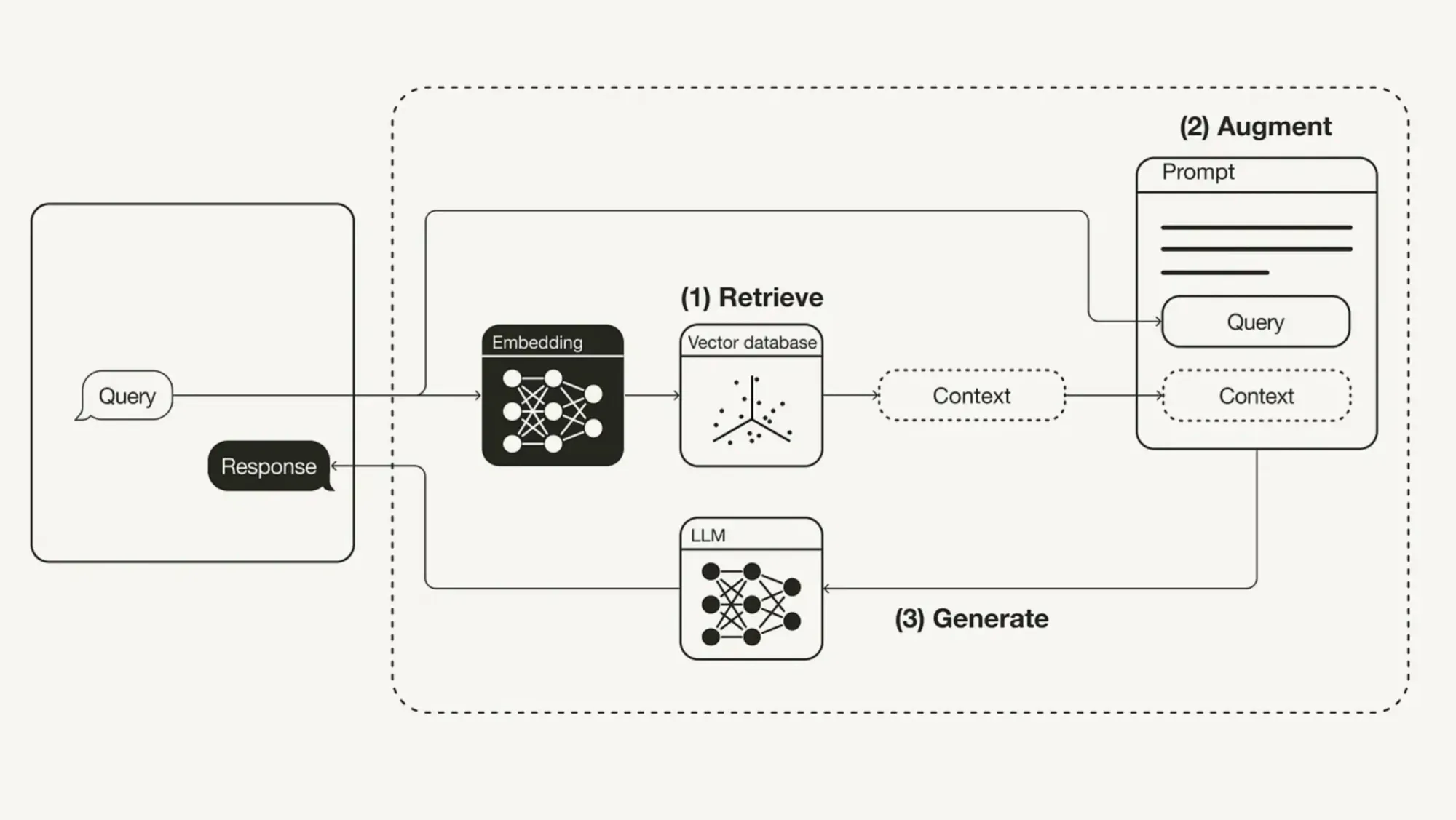
Data flows from the input query to the retrieval component, which extracts relevant information. This data is then passed to the generation component, which creates the final output, ensuring that the response is both accurate and contextually relevant.
Implementing RAG
For practical implementation:
- Hugging Face Transformers: A robust library that simplifies the use of pre-trained models for both retrieval and generation tasks. It provides user-friendly tools and APIs to build and integrate RAG systems efficiently. Additionally, you can find various repositories and resources related to RAG on platforms like GitHub for further customization and implementation guidance.
- LangChain: Another valuable tool for implementing RAG systems. LangChain provides an easy way to manage the interactions between retrieval and generation components, enabling more seamless integration and enhanced functionality for applications utilizing RAG.
Applications of Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) isn’t just a fancy term—it’s a transformative technology with practical applications across various fields. Let’s dive into how RAG is making a difference in different industries and some real-world examples that showcase its potential and AI applications.
Industry-Specific Applications
Customer Support
Imagine chatting with a support bot that actually understands your problem and gives you spot-on answers. RAG enhances customer support by pulling in precise information from vast databases, allowing chatbots to provide more accurate and contextually relevant responses. No more vague answers or repeated searches; just quick, helpful solutions.
Content Creation
Content creators know the struggle of finding just the right information quickly. RAG helps by generating content that is not only contextually accurate but also relevant to current trends. Whether it’s drafting blog posts, creating marketing copy, or writing reports, RAG assists in producing high-quality, targeted content efficiently.
Healthcare
In healthcare, timely and accurate information can be a game-changer. RAG can assist doctors and medical professionals by retrieving and summarizing the latest research and treatment guidelines. . This makes RAG highly effective in domain-specific fields like medicine, where staying updated with the latest advancements is crucial.
Education Think of RAG as a supercharged tutor. It can tailor educational content to each student’s needs by retrieving relevant information and generating explanations that match their learning style. From personalized tutoring sessions to interactive learning materials, RAG makes education more engaging and effective.
Implementing a RAG App is one option. Another is getting on a call with us so we can help create a tailored solution for your RAG needs. Discover how Nanonets can automate customer support workflows using custom AI and RAG models.
Automate your customer support using Nanonets' RAG models
Use Cases
Automated FAQ Generation
Ever visited a website with a comprehensive FAQ section that seemed to answer every possible question? RAG can automate the creation of these FAQs by analyzing a knowledge base and generating accurate responses to common questions. This saves time and ensures that users get consistent, reliable information.
Document Management
Managing a vast array of documents within an enterprise can be daunting. RAG systems can automatically categorize, summarize, and tag documents, making it easier for employees to find and utilize the information they need. This enhances productivity and ensures that critical documents are accessible when needed.
Financial Data Analysis
In the financial sector, RAG can be used to sift through financial reports, market analyses, and economic data. It can generate summaries and insights that help financial analysts and advisors make informed investment decisions and provide accurate recommendations to clients.
Research Assistance
Researchers often spend hours sifting through data to find relevant information. RAG can streamline this process by retrieving and summarizing research papers and articles, helping researchers quickly gather insights and stay focused on their core work.
Best Practices and Challenges in Implementing RAG
In this final section, we’ll look at the best practices for implementing Retrieval-Augmented Generation (RAG) effectively and discuss some of the challenges you might face.
Best Practices
- Data Quality
Ensuring high-quality data for retrieval is crucial. Poor-quality data leads to poor-quality responses. Always use clean, well-organized data to feed into your retrieval models. Think of it as cooking—you can’t make a great dish with bad ingredients. - Model Training
Training your retrieval and generative models effectively is key to getting the best results. Use a diverse and extensive dataset to train your models so they can handle a wide range of queries. Regularly update the training data to keep the models current. - Evaluation and Fine-Tuning
Regularly evaluate the performance of your RAG models and fine-tune them as necessary. Use metrics like precision, recall, and F1 score to gauge accuracy and relevance. Fine-tuning helps in ironing out any inconsistencies and improving overall performance.
Challenges
- Handling Large Datasets
Managing and retrieving data from large datasets can be challenging. Efficient indexing and retrieval techniques are essential to ensure quick and accurate responses. An analogy here can be finding a book in a massive library—you need a good catalog system. - Contextual Relevance
Ensuring that the generated responses are contextually relevant and accurate is another challenge. Sometimes, the models might generate responses that are off the mark. Continuous monitoring and tweaking are necessary to maintain relevance. - Computational Resources
RAG models, especially those utilizing deep learning, require significant computational resources, which can be expensive and demanding. Efficient resource management and optimization techniques are essential to keep the system running smoothly without breaking the bank.
Conclusion
Recap of Key Points: We’ve explored the fundamentals of RAG, its technical overview, applications, and best practices and challenges in implementation. RAG’s ability to combine retrieval and generation makes it a powerful tool in enhancing the accuracy and relevance of AI-generated content.
The future of RAG is bright, with ongoing research and development promising even more advanced models and techniques. As RAG continues to evolve, we can expect even more accurate and contextually aware AI systems.
Found the blog informative? Have a specific use case for building a RAG solution? Our experts at Nanonets can help you craft a tailored and efficient solution. Schedule a call with us today to get started!