
If you are tired of spending hours copying tables from PDFs, you’re not alone.
While PDFs are great for reading, they can be a nightmare when extracting tabular data. Whether it’s financial reports, invoices, healthcare bills, or research papers, extracting tables accurately and quickly can feel impossible.
But it doesn’t have to be. From simple tools like MS Excel to advanced solutions like AI-based IDP tools, there are multiple ways to extract tables efficiently and save hours of effort. Below is a quick summary to help you jump straight to your preferred method:
| Method | Summary | Key Benefit |
|---|---|---|
| Using MS-Excel | Extract tables with Excel's built-in PDF import feature. | Simple and user-friendly for basic tables. |
| Online PDF Converters | Upload your PDFs to online tools for quick table extraction. | Fast and requires no software installation. |
| Python Library | Use Camelot to programmatically extract complex tables. | Ideal for multi-page and intricate tables. |
| Tabula | A Java-based tool with a Python wrapper for table extraction. | High accuracy with structured PDFs. |
| Large Language Models (LLMs) | Leverage GPT-4 via UI or API for context-aware table extraction. | Extremely accurate and versatile. |
| AI-based IDP Tools | Intelligent Document Processing tools like Nanonets. | Fully automated, scalable, and secure. |
Several methods are available for extracting tables from PDFs, each with its own advantages and use cases. In this section, we will examine the six best methods for conversion in detail.
1. Using MS-Excel (Power Query)
Microsoft Excel is a widely used tool that you may already be familiar with. Excel’s recent versions offer a built-in feature, Get Data (commonly known as Power Query), to import data from PDFs.
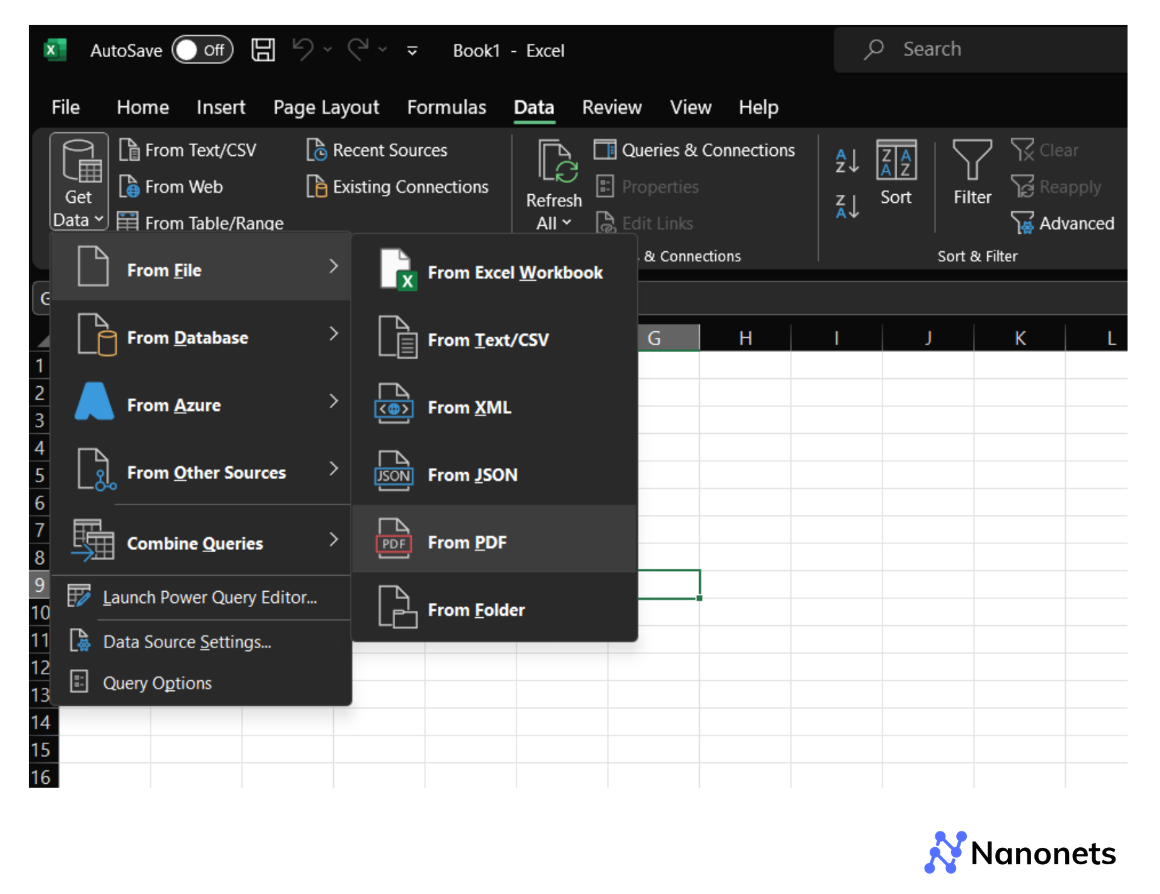
Here’s how you can use it to extract tables from a PDF:
Step 1: Navigate to the Data tab in an Excel Workbook.
Step 2: Select Get Data, then choose From File and then, From PDF.
Step 3: Excel will analyze the document and let you select which table to import.
This feature works well for simple tables but may struggle with complex layouts.
1. Easy to use and accessible to most users.
2. Ideal for simple tables or when quick extraction is needed.
1. Limited control over the extraction process.
2. Formatting issues may occur with split tables or complex tables.
2. Using online PDF to table converters
Online converters are another quick and easy option for extracting tables from PDFs. These tools, such as Smallpdf, PDF2Go, and PDFTables, allow you to upload a PDF and download the extracted table in Excel or CSV format.
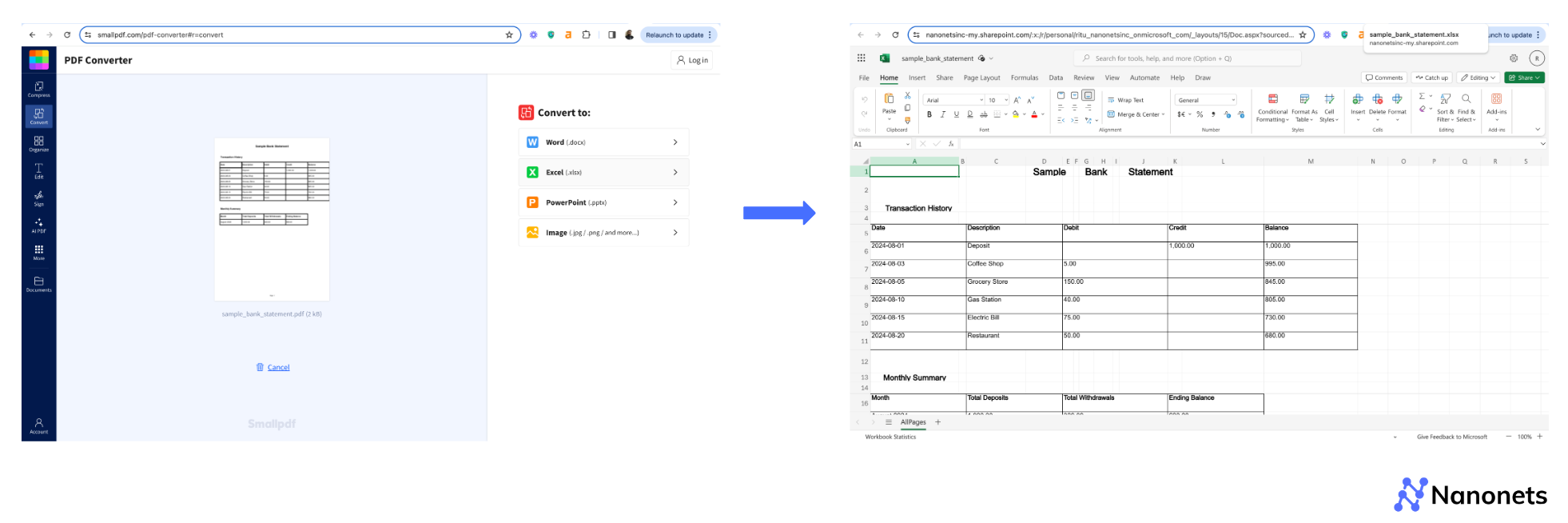
We will not cover all these tools in this section, but we will examine a general process one can follow for conversion. It is illustrated below with an example image.
Step 1: Visit the online converter’s website (for example: Smallpdf.com)
Step 2: Upload the PDF containing the table
Step 3: Select the output format (Excel or CSV)
Step 4: Download the converted file
1. No installation required; accessible from any device with an internet connection.
2. Some converters offer free usage for small files.
1. Limited usage on free plans.
2. May not be secure for sensitive data, as you’re uploading files to a third-party server.
3. Quality of extraction varies; complex tables may not convert well.
3. Using a Python library (Camelot)
You can also use Python to extract PDF tables. We are taking an example of Camelot, which is a Python library.
We will break down the code into snippets and provide a detailed explanation for each part. At the end, you'll also find a unified code with a `main` function to download.
Step 1: Install necessary packages
Before starting, you need to install Camelot and Excalibur if they aren't already installed.
pip install camelot-py[cv] excalibur-pyStep 2: Import necessary libraries
First, import the necessary libraries that will be used for PDF extraction as well as manipulating tabular data.
import camelot
import pandas as pdStep 3: Extract tables from the PDF using Camelot
Camelot is a Python library that makes it easy to extract tables from PDF files. You can choose between two extraction flavours: `stream` and `lattice`. Here, we'll use `lattice` because it works well with tables that have clearly defined lines.
def extract_tables_from_pdf(pdf_path):
# Read the PDF file and extract tables using Camelot
tables = camelot.read_pdf(pdf_path, pages='all', flavor='lattice')
# Checking if tables were extracted successfully
if tables:
print(f"Found {tables.n} tables in the PDF.")
else:
print("No tables found in the PDF.")
return tablesStep 4: Display extracted tables
The display_tables function iterates over the extracted tables and prints each one to the console using pandasDataFrame's to_string method for better formatting.
def display_tables(tables):
"""
Displays the extracted tables in the console.
Args:
tables (camelot.core.TableList): A list of tables extracted by Camelot.
"""
for i, table in enumerate(tables):
print(f"\nTable {i + 1}:")
print(table.df.to_string(index=False))Unified code:
Now, let's combine the code snippets into a single script with a main function that handles the entire process from reading a PDF to displaying the tables.
Run the script with your PDF file path specified in the `pdf_path` variable. This script will extract all tables from the PDF.
1. Python Integration: Camelot is a Python library, which means it integrates seamlessly with other Python data manipulation tools like pandas. This allows for automated and programmatically controlled workflows.
2. Two extraction methods (Flavours): Camelot offers two different methods for extracting tables—lattice (for tables with visible lines) and stream (for tables without visible lines). This makes it versatile for handling various table formats.
3. Handles complex tables: Camelot can effectively handle multi-page PDFs and tables with complex structures, including those with merged cells, multiple headers, or different column widths.
4. Output flexibility: It provides outputs in multiple formats, including CSV, JSON, and pandas DataFrames, making it easy for conversion and manipulation.
5. Open Source: Camelot is open-source, meaning it's free to use and has an active community for support and development.
1. Installation dependencies: Requires dependencies like Ghostscript and Tkinter, which can be cumbersome to install and configure, especially on non-Linux systems.
2. Accuracy depends on table structure: Camelot's extraction accuracy heavily depends on the PDF’s table formatting. It may struggle with poorly formatted tables or those with minimal or inconsistent borders.
3. Performance: Camelot can be slower compared to some other tools when processing large PDFs or extracting multiple tables.
4. Limited support for scanned PDFs: Camelot does not natively support OCR (Optical Character Recognition). For scanned PDFs, an OCR tool must be used in conjunction with Camelot, which adds another layer of complexity.
4. Using Tabula (Java-based tool with a Python wrapper)
Tabula is another popular tool for extracting tables from PDFs. Unlike Camelot, Tabula is a Java-based tool, but it can still be integrated with Python using the `tabula-py` library, which provides a Python wrapper around Tabula.
We will break down the process into detailed steps and provide a unified code with a `main` function that can be downloaded.
Step 1: Install necessary packages
Before starting, you need to install `tabula-py` and `pandas` if they aren't already installed. You should also have Java installed on your system since Tabula is a Java-based tool.
pip install tabula-py pandasStep 2: Import necessary libraries
First, import the necessary libraries that will be used for PDF extraction and Excel writing.
import tabula
import pandas as pdStep 3: Extract tables from the PDF using Tabula
Tabula is a tool designed specifically for extracting tables from PDFs. It can work in both GUI and command-line modes. When using it in Python, you can use `tabula.read_pdf()` to extract tables.
Here’s how you can extract tables from a PDF using Tabula:
def extract_tables_from_pdf(pdf_path):
"""
Extracts tables from a PDF file using Tabula.
Args:
pdf_path (str): The file path of the PDF.
Returns:
tables (list of pandas.DataFrame): A list of DataFrames extracted by Tabula.
"""
# Read the PDF file and extract tables using Tabula
tables = tabula.read_pdf(pdf_path, pages='all', multiple_tables=True)
# Checking if tables were extracted successfully
if tables:
print(f"Found {len(tables)} tables in the PDF.")
else:
print("No tables found in the PDF.")
return tablesStep 4: Display the extracted tables
The display_tables function iterates over the list of DataFrames and prints each one to the console using the to_stringmethod for a readable tabular format.
def display_tables(tables):
"""
Displays the extracted tables in the console.
Args:
tables (list of pandas.DataFrame): A list of DataFrames extracted by Tabula.
"""
for i, table in enumerate(tables):
print(f"\nTable {i + 1}:")
print(table.to_string(index=False))If needed, pandas DataFrames can be converted to formats like Excel, CSV, Markdown, or JSON for manipulation and processing.
Unified code:
Now, let's combine the code snippets into a single script with a main function that handles the entire process, from reading a PDF to extracting and displaying tables from it.
Run the script with your PDF file path specified in the `pdf_path` variable. This script will extract all tables from the PDF and display them.
1. Java-based tool: Tabula works across different operating systems because it is Java-based. It does not require complex installations or dependencies.
2. Supports multiple table extraction: It can extract multiple tables from a single page and handle multi-page PDFs effectively.
3. Simple command-line and GUI: Tabula provides both a command-line interface and a GUI, making it accessible for both programmers and non-programmers.
4. Good accuracy for structured PDFs: Tabula is effective at extracting tables from PDFs that are well-structured with clear lines and borders.
5. Python integration via tabula-py: Tabula can be easily integrated with Python using the `tabula-py` wrapper, allowing for automated workflows.
1. Requires Java installation: Since Tabula is Java-based, you must have Java installed on your system, which can be an additional step for some users.
2. Limited to Tabular data: Tabula is specifically designed for table extraction. It does not handle text extraction or other PDF content types effectively.
3. Less effective for scanned PDFs: Like Camelot, Tabula struggles with scanned PDFs without OCR. You need an additional OCR tool to convert scanned images to text before extraction.
4. Performance on large PDFs: Tabula can become slow or memory-intensive when processing very large PDFs or PDFs with many pages and tables.
5. Less control over table detection: Compared to some other tools, Tabula may have less granular control over how tables are detected, especially if the table structure is not clear.
5. Using Large Language Models (LLMs)
While Python-based tools such as Camelot and Tabula can be effective for extracting tables from PDFs, they require coding skills and are often limited in their scalability and flexibility. An alternative approach that leverages more advanced technology involves using Large Language Models (LLMs) for table extraction.
We will focus on using GPT-4 in two different methods:
- Using the GPT UI
- Using the GPT API
Method 1: Using the user interface
For this method, we will utilise GPT-4's user interface to convert a PDF document containing tables into an Excel spreadsheet. This method is ideal for users who prefer a more straightforward, no-code solution.
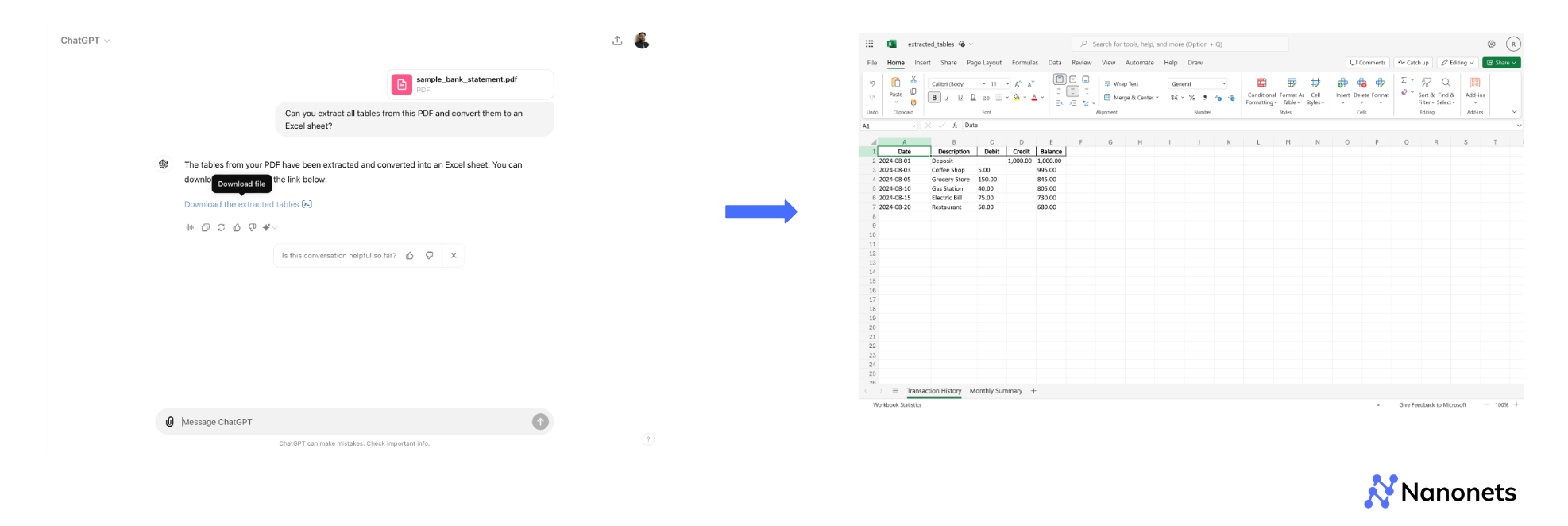
Step 1: Visit the GPT-4 user interface at chat.openai.com and log into your account.
Step 2: In the prompt section, upload the PDF file you want to convert and type a specific prompt to guide GPT-4 in extracting the tables.
Example prompts:
"Can you extract all tables from this PDF and convert them to an Excel sheet?"
Method 2: Using the GPT API
For a more automated and scalable solution, you can use the GPT API to extract data from a PDF programmatically.
Step 1: Install the necessary libraries, including `openai` for interacting with the GPT API, `PyPDF2` for PDF extraction, and `pandas` for handling Excel operations.
pip install openai PyPDF2 pandas
Step 2: We’ll use PyPDF2 to extract the text from each page of the PDF. This extracted text will be processed to identify and extract tables.
import PyPDF2
def extract_text_from_pdf(pdf_path):
"""
Extracts text from a PDF file using PyPDF2.
Args:
pdf_path (str): The path to the PDF file.
Returns:
str: The extracted text content.
"""
with open(pdf_path, 'rb') as file:
reader = PyPDF2.PdfReader(file)
text = ""
for page in reader.pages:
text += page.extract_text()
return text
Step 3: Create a detailed prompt instructing GPT-4 to identify and extract tables from the provided text. The tables will be returned as structured text (e.g., CSV-like format).
import openai
def extract_tables_from_text(text):
"""
Extracts tables from the provided text using GPT-4.
Args:
text (str): The extracted text content.
Returns:
str: The extracted tables in text format.
"""
prompt = (
"Please extract all tables from the following text. "
"Format them as CSV-like structures with columns and rows clearly defined:\n\n"
f"{text}"
)
response = openai.Completion.create(
model="gpt-4",
prompt=prompt,
max_tokens=2000,
temperature=0.5
)
return response.choices[0].text.strip()
Step 4: Once the tables are extracted using GPT-4, they can be displayed, processed, or saved for further use.
def display_extracted_tables(extracted_tables):
"""
Displays the extracted tables.
Args:
extracted_tables (str): The extracted tables in text format.
"""
print("Extracted Tables:")
print(extracted_tables)
Unified code:
Needless to say, you will need to replace "your_openai_api_key" with an actual value. Post that, you can run the script to parse tables from PDFs using GPT API.
1. Highly accurate and context-aware: LLMs like GPT-4 can understand complex instructions and provide more accurate data extraction from PDFs with varied formats.
2. No-code and low-code options: Using the user interface requires no coding skills, and even the API method involves minimal coding, making it accessible for non-programmers.
3. Scalability: The API-based approach allows for scaling the extraction process across multiple documents and formats.
1. Complex prompt engineering: Crafting effective prompts can be challenging and might require several iterations to achieve the desired results.
2. Cost: Depending on usage, API calls to GPT-4 can incur costs, which might not be ideal for all users.
3. Output reliability: The quality of the output depends on the prompt and model's interpretation, which might not always meet expectations.
4. Limited control over extraction: Unlike traditional programming methods, using GPT-4 gives less direct control over how data is extracted and formatted.
By following these steps, you can effectively leverage LLMs to automate the process of extracting tables from PDFs and converting them into a CSV-like format which can be directly displayed or converted into other desirable formats. This process offers a modern alternative to traditional programming approaches.
6. Using AI-based IDP tools

Until now, we have looked at 5 different methods of extracting tabular data from PDFs to Excel. All of them present unique challenges.
The final approach that acts as the ultimate solution for building a scalable, robust process for converting tabular data from PDFs to a more accessible format is leveraging Intelligent Document Processing (IDP) tools.
These tools, often described as AI tools to extract data from PDFs, come with built-in OCR functionality. These tools are adept at recognizing complex tabular structures, whether multiple tables of varied formats split across pages or nested tables with multiple line items.
They have advanced algorithms powered by generative-AI which can handle inconsistent cell formatting. What is more is that they offer post-processing options where you can perform formatting operations, such as, adding/removing characters, looking up against external tables or databases, in-app.
Not just that, they completely automate end-to-end workflows, including, importing PDF files, extracting tables, post-processing as discussed above, approval routing to verify accuracy and finally exporting to other software, all in one application.
We will be looking at one-such tool today, Nanonets, which provides a one-size-fits-all solution for handling the most complex tabular PDFs.

So, how do I get started?
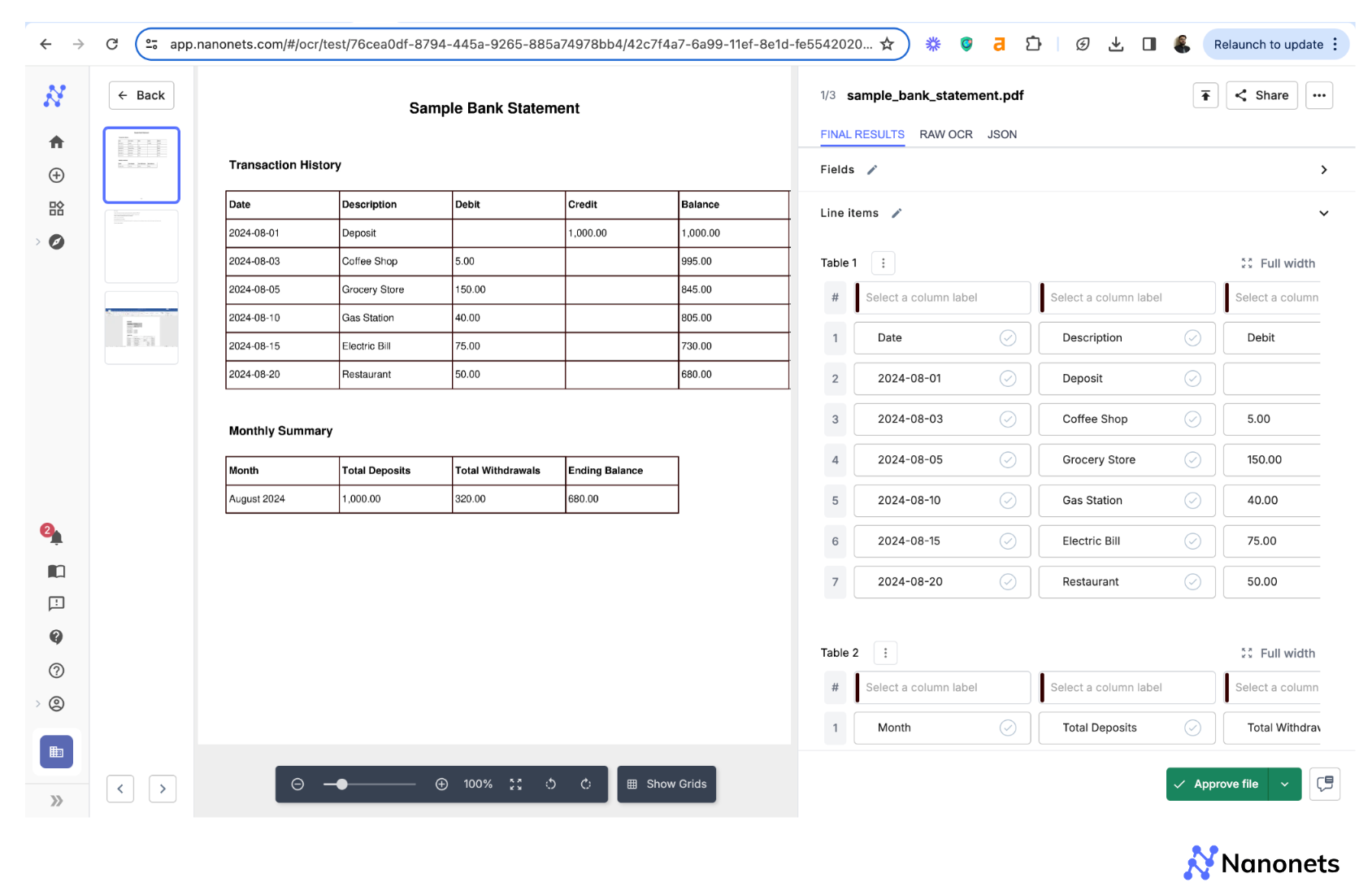
Step 1: Visit app.nanonets.com. Sign up and log into your account.
Step 2: Click on “New Workflow” on the left panel and select “Pre-trained Tables Extractor.”
Step 3: Upload your PDF files and allow some time for processing.
Step 4: Once processed, you can click on the file to review the extracted data. Once satisfied, go back to the File Upload Screen, select the file and click on the “Download Extracted Data” button at the lower left corner of your screen. You can select the desired format in advanced settings on the dialog box that appears.
1. Fully automated, no-code solution for extracting tables from PDFs.
2. Supports structured extraction for complex tables, including custom column headers, split tables or nested tables with multiple line-items.
3. Compatible with both scanned and digital PDFs.
4. Provides post-processing formatting options, including lookup against external sources and adding rows or columns based on the lookup.
5. Provides approval steps where a human can verify the accuracy of extraction.
6. Provides full control over output with pre-configured Excel and database mapping features.
Now that we've discussed all the different methods to extract tables from a PDF, let's try to understand what is so different about PDFs that make it so challenging in the first place:
Why is table extraction from PDFs a huge challenge?
PDFs are immutable which means they cannot be modified or searched for specific data points. This renders the age-old trusty method of simply copying and pasting tables useless, even without taking into account its inefficiency.
But that’s barely scratching the surface when it comes to challenges of handling tabular data extraction from PDFs. So what are these challenges? Let’s take a look:
1. Split tables across pages
Tables spanning multiple pages often have repeated headers or misaligned columns, making it difficult to reconstruct the complete table structure and maintain data integrity during extraction.
Financial statements like balance sheets, cash flow statements, or even individual bank statements often have this problem of multiple tables that are occasionally split across pages, making it challenging to reconstruct complete financial data for investment analysis.
2. Inconsistent cell formatting
Varying font styles, sizes, and colours within a single table can be confusing leading to misinterpretation of data hierarchies and relationships between cells.
Legal contracts, especially in real estate, often use varied formatting for clauses and sub-clauses within tables, hindering automated extraction of key terms and conditions for contract management systems.
3. Non-standard table structures
PDFs may contain nested tables, merged cells, or footnotes that can be challenging when it comes to correctly identifing table boundaries and cell contents.
For instance, technical product catalogs across industries often use unconventional table layouts with hierarchical groupings, icons, and multi-line descriptions, challenging automated systems to correctly parse specifications, pricing, and inventory data for e-commerce platforms or procurement systems.
4. Background patterns and watermarks
Decorative elements or security features like watermarks can interfere with table detection and text recognition, resulting in incomplete or inaccurate data extraction.
Bank statements and financial records often include security watermarks that interfere with OCR accuracy, complicating the extraction of transaction data for personal finance management tools or auditing processes.
Besides these common challenges, poor scan quality in scanned PDFs or data that isn’t explicitly delineated into rows and columns can also present additional roadblocks.
Final word
Choosing the right method or tool can make all the difference and save you hours of manual efforts. Whether you opt for simple solutions like MS Excel, advanced programming libraries like Camelot or Tabula, or scalable AI-powered tools like Nanonets, the key is finding what works best for your specific needs.
So, ready to tackle table extraction like a pro? Start with the method that suits your workflow, and watch how easily you can reclaim those lost hours.
