
Introduction
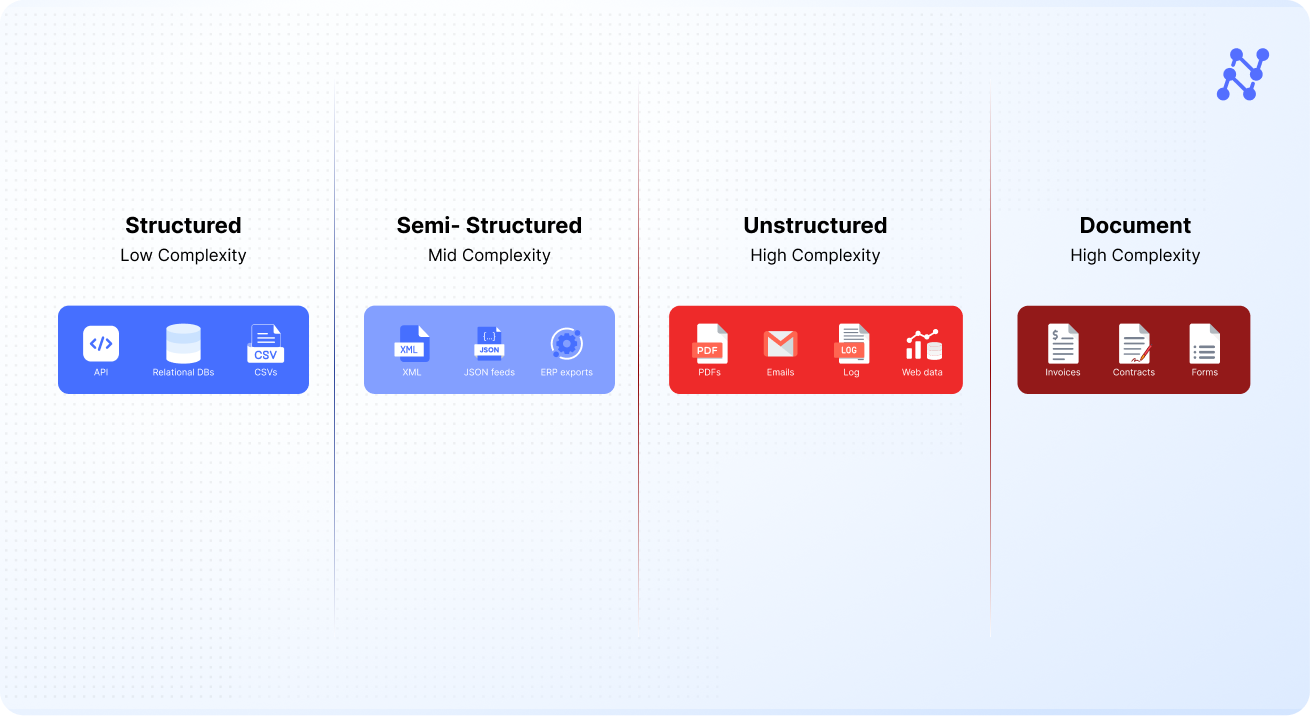
80–90% of enterprise data lives in unstructured documents — contracts, claims, medical records, and emails. Yet most organizations still rely on brittle templates or manual keying to make sense of it. Data sits on a spectrum — from clean, tabular formats to messy, free-form content. Documents represent the most complex and high-value end of this continuum.
Now picture this: a 60-page supplier contract lands in procurement’s inbox. Traditionally, analysts might spend two days combing through indemnity clauses, renewal terms, and non-standard provisions before routing obligations into a contract lifecycle management (CLM) system. With an Intelligent Document Processing (IDP) pipeline in place, the contract is parsed, key clauses are extracted, deviations are flagged, and obligations are pushed into the CLM system in under an hour. What was once manual, error-prone, and slow becomes near real-time, structured, and auditable.
IDP applies AI/ML—NLP, computer vision, and supervised/unsupervised learning—to enterprise documents. Unlike Automated Document Processing (ADP), which relies on rules and templates, IDP adapts to unseen layouts, interprets semantic context, and improves continuously through feedback loops. To understand IDP's role, think of it as the AI brain of document automation, working in concert with other tools: OCR provides the eyes, RPA the hands, and ADP the deterministic rules backbone.
This article takes you under the hood of how this brain works, the technologies it builds on, and why enterprises can no longer ignore it.
- If you’re looking for the rules/templates foundation layer, read our Automated Document Processing (ADP) guide.
- If you want the full discipline-level view of document processing, see our Document Processing deep dive.
IDP is not a one-size-fits-all silver bullet. The right approach depends on your document DNA. While ADP may be sufficient for high-volume, structured formats, IDP is the smarter long-term play for variable or unstructured documents. Before investing, evaluate your document landscape on three axes—type, variability, and velocity. This analysis will guide whether deterministic rules, adaptive intelligence, or a hybrid model is the best fit.
What Is Intelligent Document Processing?
At its core, Intelligent Document Processing (IDP) is the AI-driven transformation of documents into structured, validated, system-ready data. The lifecycle is consistent across industries:
Capture → Classify → Extract → Validate → Route → Learn
Unlike earlier generations of automation, IDP doesn’t stop at data capture. It layers in machine learning models, NLP, and human-in-the-loop feedback so each cycle improves accuracy.
One way to understand IDP is to place it in the automation stack alongside related tools:
- OCR = the eyes. Optical Character Recognition converts pixels into machine-readable text.
- RPA = the hands. Robotic Process Automation mimics keystrokes and clicks.
- ADP = the rules engine. Automated Document Processing relies on templates and deterministic rules.
- IDP = the brain. Machine learning models interpret structure, semantics, and context.
This framing matters because many enterprises conflate these tools. In practice, they are complementary, with IDP sitting at the intelligence layer that makes automation scalable beyond rigid templates.
Why Intelligent Document Processing Matters for IT, Solution Architects, and Data Scientists
- For IT leaders: IDP reduces the break/fix cycles that plague template-driven systems. No more firefighting every time a vendor tweaks an invoice format.
- For solution architects: IDP provides a flexible, API-first layer that scales across heterogeneous document types — without ballooning maintenance costs.
- For data scientists: IDP formalizes a learning loop. Confidence scores, active learning, and reviewer feedback are baked into production pipelines, turning noisy human corrections into structured training signals.
Key Terms to Know
- Confidence scores: Each extracted field carries a probability used for routing (auto-post vs review). Exact thresholds will be covered in a later section.
- Active learning: A method where human corrections are recycled into model training, reducing manual effort over time.
- Layout-aware transformers (e.g., LayoutLM): Deep learning models that combine text, position, and visual cues to parse complex layouts like invoices or forms. (LayoutLM paper →)
- OCR-free models (e.g., Donut): Newer approaches that bypass OCR altogether, directly parsing digital PDFs or images into structured outputs. (Donut paper →)
In short: IDP is not “smarter OCR” or “better RPA.” It is the AI/ML brain that interprets documents, enforces context, and scales automation into domains where templates collapse.
Next, we’ll look under the hood at the core technologies — from machine learning models to NLP, computer vision, and human-in-the-loop learning systems — that make IDP possible at enterprise scale.
Core Technologies Under the Hood
IDP isn’t a single model or API call. It's a layered architecture combining machine learning, NLP, computer vision, human feedback, and, increasingly, large language models (LLMs). Each piece plays a distinct role, and their orchestration is what enables IDP to scale across messy, high-volume enterprise document sets. To illustrate how these technologies work together, let's trace a single document—a complex customs declaration form with both typed and handwritten data, a nested table of goods, and a signature.
Machine Learning Models: The Foundation
Machine learning (ML) is the backbone of IDP. Unlike deterministic ADP systems, IDP relies on models that learn from data, adapt to new formats, and improve continuously.
- Supervised Learning: The most common approach. Models are trained on labeled samples—for our customs form, this would be a dataset with bounding boxes around "Port of Entry," "Value," and "Consignee." This enables a supervised model to recognize these fields with high accuracy on future, similar forms.
- Unsupervised/Self-Supervised Learning: Useful when labeled data is scarce. Models can cluster unlabeled documents by layout or content similarity, grouping all customs forms together before a human even has to label them.
- Layout-Aware Transformers: Models like LayoutLM are designed specifically for documents. They combine the extracted text with its spatial coordinates and visual cues. On our customs form, this model understands not just the words "Total Value," but also that they are located next to a specific box and above a line of numbers, ensuring correct data extraction even if the form layout varies slightly.
| Document Type | Recommended Tech | Rationale |
|---|---|---|
| Fixed-format invoices | Supervised ML + lightweight OCR | High throughput, low cost |
| Receipts / mobile captures | Layout-aware transformers | Robust to variable fonts, noise |
| Contracts | NLP-heavy + layout transformers | Captures clauses across pages |
Natural Language Processing (NLP): Understanding the Text
While ML handles structure, NLP gives IDP semantic understanding. This matters most when the content isn’t just numbers and boxes, but text-heavy narratives.
- Named Entity Recognition (NER): After the ML model identifies the goods table on the customs form, NER extracts specific entities like "Quantity" and "Description" from each line item.
- Semantic Similarity: If the form has a "Special Instructions" section with free-form text, NLP models can read it to detect clauses related to handling or transport risks, ensuring a human flag is raised if the language is complex.
- Multilingual Capabilities: For international forms, modern transformer models can process languages from Spanish to Arabic, ensuring a single IDP system can handle global documents without manual language switching.
Computer Vision (CV): Seeing the Details
Documents aren't always pristine PDFs. Scanned faxes, mobile uploads, and stamped forms introduce noise. CV layers in preprocessing and structure detection to stabilize downstream models.
- Pre-processing: If our customs form is a blurry fax, CV techniques like de-skewing and binarization clean up the image, making the text clearer for extraction.
- Structure Detection: CV models can precisely segment the form, identifying separate zones for the typed table, the handwritten signature, and any stamps, allowing specialized models to process each area correctly. This ensures the handwritten signature isn't misinterpreted as part of the typed data.
Human-in-the-Loop (HITL) + Active Learning: Continuous Improvement
Even the best models aren’t 100% accurate. HITL closes the gap by routing uncertain fields to human reviewers—and then using those corrections to improve the model. On our customs form, a very low confidence score on the handwritten signature could trigger an automatic escalation to a reviewer for verification. That correction then feeds back into the active learning system, helping the model get better at reading similar handwriting over time.
LLM Augmentation (Emerging Layer): The Final Semantic Layer
LLMs are the newest frontier, adding a layer of semantic depth. Once the customs form is processed, an LLM can provide a quick summary of the goods, highlight any unusual items, and even draft an email to the logistics team based on the extracted data. This is not a replacement for IDP, but an augmentation that provides deeper, more human-like interpretation.
How an IDP Workflow Actually Runs
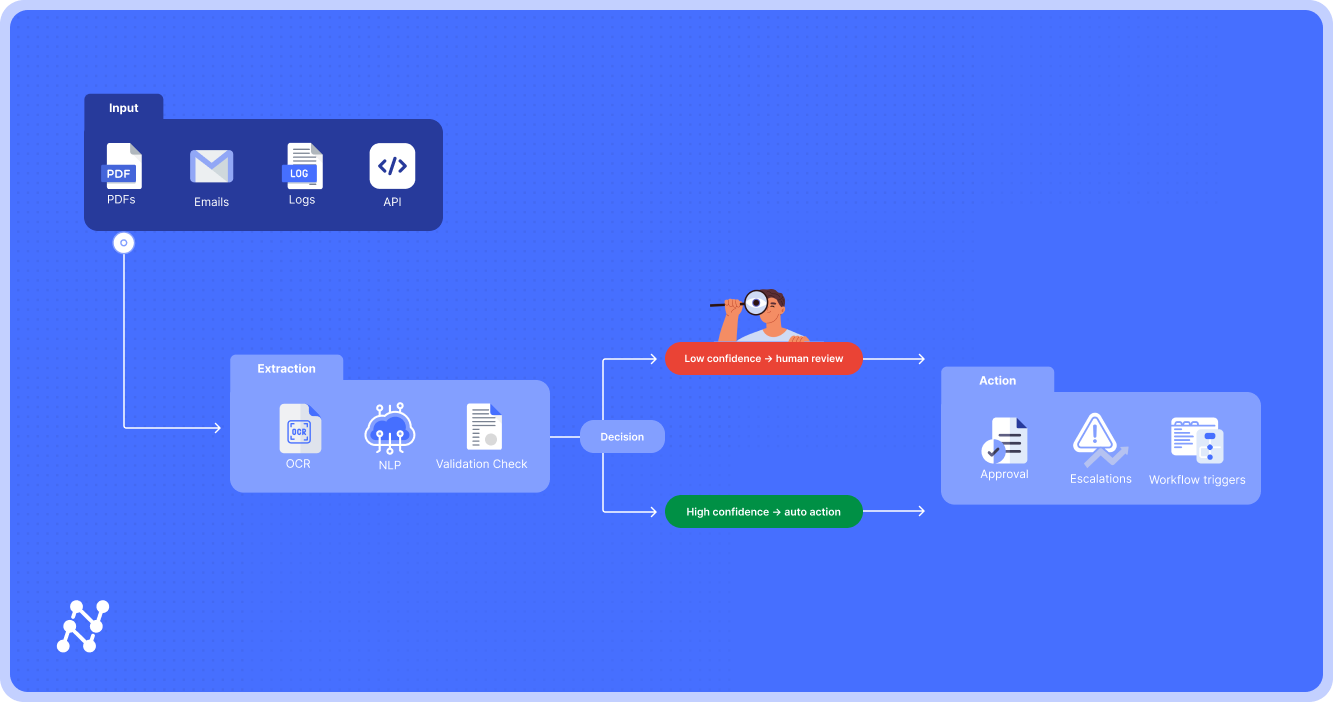
In practice, IDP isn’t a single “black box” AI—it’s a carefully orchestrated pipeline where machine learning, business rules, and human oversight interlock to deliver reliable outcomes.
Enterprises care less about model architecture and more about whether documents flow end-to-end without constant firefighting. That requires not only extraction accuracy but also governance, validations, and workflows that stand up to real-world volume, diversity, and compliance.
Below, we break down an IDP workflow step by step—with technical details for IT and data science, and operational benefits for finance, claims, and supply chain leaders.
Step 1. Ingestion Mesh — Getting Documents In Cleanly
- Channels supported: email attachments, SFTP batch drops, API/webhooks, customer/supplier portals, mobile capture apps.
- Pre-processing tasks: MIME normalization, duplicate detection, virus scanning, metadata tagging.
- Governance hooks: idempotency keys (avoid duplicates), retries with exponential backoff, DLQs (dead-letter queues) for failed documents.
- Personas impacted:
- IT → security, authentication (SSO, MFA).
- Ops → throughput, SLA monitoring.
- Architects → resilience under peak load.
Step 2. Classification — Knowing What You’re Looking At
- Techniques: hybrid classifiers blending layout features (form geometry) and semantic features (keywords, embeddings).
- Confidence thresholds: high-confidence classifications route straight to extraction; low-confidence cases trigger HITL review.
- Recovery actions:
- Mis-routed doc → auto-reclassification engine.
- Unknown doc type → tagged by reviewers, feeding active learning.
Step 3. Data Extraction — Pulling Fields and Structures
- Scope: key-value pairs (invoice number, claim ID), tabular data (line items, shipments), signatures, and stamps.
- Business rules: normalization of dates, tax percentages, currency formats; per-line item checks for totals.
- HITL UI: per-field confidence scores, color-coded, with keyboard-first navigation to minimize correction time.
Step 4. Validation & Business Rules — Enforcing Policy
- Cross-system checks:
- ERP: PO/invoice matching, vendor master validation.
- CRM: customer ID verification.
- HRIS: employee ID confirmation.
- Policy enforcement: dual-sign approvals for high-value invoices, segregation of duties (SoD), SOX audit logging.
- Tolerance rules: e.g., accept ±2% tax deviation, auto-flag >$10k transactions.
Persona lens:
- CFO → reduced duplicate payments, compliance assurance.
- COO → predictable throughput, fewer escalations.
- IT → integration stability via API-first design.
Step 5. Routing & Orchestration — Getting Clean Data to the Right Place
- Workflows supported:
- Finance → auto-post invoice to ERP.
- Insurance → open a claim in TPA system.
- Logistics → trigger customs clearance workflow.
- Integrations: API/webhooks preferred; RPA as fallback only when APIs are absent.
- Governance features: SLA timers on exception queues, escalation chains to approvers, Slack/Teams notifications for human action.
Step 6. Feedback Loop — Making the System Smarter Over Time
- Confidence funnel: ≥0.95 → auto-post; 0.80–0.94 → HITL review; <0.80 → escalate or reject. Granular thresholds can also be applied per field (e.g., stricter for invoice totals than for vendor addresses).
- Learning cycle: reviewer corrections are logged as training signals, feeding active learning pipelines.
- Ops guardrails: A/B testing new models before production rollout; regression monitoring to prevent accuracy drops.
An IDP workflow is not just AI—it’s a governed pipeline. It ingests documents from every channel, classifies them correctly, extracts fields with ML, validates against policies, routes to core systems, and continuously improves through feedback. This mix of machine learning, controls, and human review is what makes IDP scalable in messy, high-stakes enterprise environments.
IDP vs Other Approaches — Drawing the Right Boundaries
Intelligent Document Processing (IDP) isn’t a replacement for OCR, RPA, or Automated Document Processing (ADP). Instead, it acts as the orchestrator that makes them intelligent, complementing them by doing what they cannot: learning, generalizing, and interpreting documents beyond templates. The risk in many enterprise programs is assuming these tools are interchangeable—a category mistake that leads to brittle, expensive automation.
In this section, we'll clarify their distinct roles and illustrate what happens when those boundaries blur.
IDP vs. OCR
While OCR provides the foundational "eyes" by converting pixels to text, it remains blind to meaning or context. IDP builds on this text layer by adding structure and semantics. It uses machine learning and computer vision to understand that "12345" is not just text, but a specific invoice number linked to a vendor and due date. Without IDP, OCR-only systems collapse in variable environments like multi-vendor invoices.
IDP vs. RPA
RPA serves as the "hands," automating keystrokes and clicks to bridge legacy systems without APIs. It is fast to deploy but fragile when UIs change and fundamentally lacks an understanding of the data it's handling. Using RPA for document interpretation is a category mistake; IDP's role is to extract and validate the data, ensuring the RPA bot only pushes clean, enriched inputs into downstream systems.
IDP vs. Generic Automation (BPM)
Business Process Management (BPM) engines are the "traffic lights" of a workflow, orchestrating which tasks are routed where and when. They rely on fixed, static rules. IDP provides the adaptive "intelligence" inside these workflows by making sense of contracts, claims, or multilingual invoices before the BPM engine routes them. Without IDP, BPM routes unverified, "blind" data.
IDP with ADP
ADP (Automated Document Processing) provides the deterministic backbone, best suited for high-volume, low-variance documents like standardized forms. It ensures auditability and throughput stability. IDP handles the variability that would break ADP's templates, adapting to new invoice layouts and unstructured contracts. Both are required at enterprise scale: ADP for determinism and stability, IDP for managing ambiguity and adaptation.
Mistakes to Avoid in Document Automation
The most common mistake is assuming these tools are interchangeable. The wrong choice leads to costly, fragile solutions.
- Overinvesting in IDP for stable formats: If your invoices are from a single vendor, deterministic ADP rules will deliver faster ROI than ML-heavy IDP.
- Using RPA for interpretation: Let IDP handle meaning; RPA should only bridge systems without APIs.
- Treating OCR as a full solution: OCR captures text but doesn’t understand it, allowing errors to leak into core business systems.
✅ Rule of thumb: Map your document DNA first (volume, variability, velocity). Then decide what mix of OCR, RPA, ADP, BPM, and IDP fits best.
IDP in Practice: Real-World Use Cases & Business Outcomes
Intelligent Document Processing (IDP) proves its worth in the messy reality of contracts, invoices, claims, and patient records. What makes it enterprise-ready isn't just its extraction accuracy, but the way it enforces validations, triggers approvals, and integrates into downstream workflows to deliver measurable improvements in accuracy, scalability, compliance, and cost efficiency.
Unlike traditional OCR or ADP, IDP doesn't just digitize—it learns, validates, and scales across unstructured inputs, reducing exception overhead while strengthening governance. By contrast, template-based systems often plateau at around 70–80% field-level accuracy. IDP programs, however, consistently achieve 90–95%+ accuracy across diverse document sets once human-in-the-loop (HITL) feedback is embedded, with some benchmarks reporting up to ~99% accuracy in narrowly defined contexts. This accuracy is not static; IDP pipelines compound accuracy over time as corrections feed back into models.
The transformation is best seen in a side-by-side comparison of key operational metrics.
Benefits (Technology Outcomes)
| Metric | Before (ADP / Manual) | After (IDP-enabled) |
|---|---|---|
| Field-level accuracy | 70–80% (template-driven, brittle) | 90–95%+ (compounding via HITL feedback) |
| First-pass yield (FPY) | 50–60% documents flow through untouched | 80–90% documents auto-processed |
| Invoice processing cost | $11–$13 per invoice (manual/AP averages) | $2–$3 per invoice (IDP-enabled) |
| Cycle time | Days (manual routing & approvals) | Minutes → Hours (with validation + SLA timers) |
| Compliance | Audit trails fragmented; risky exception handling | Immutable event logs; per-field confidence scores |
Let's explore how this plays out across five key document families.
Contracts: Clause Extraction and Obligation Management
Contract processing is where static automation often breaks. A 60-page supplier agreement may contain indemnity clauses, renewal terms, or liability caps buried across sections and in inconsistent formats. With IDP, contracts are ingested from PDFs or scans, classified and parsed with layout-aware NLP, and validated for required clauses. Counterparties are checked against vendor masters, deviations beyond thresholds (e.g., indemnity >$1M) trigger escalations, and obligations flow seamlessly into the CLM. Non-standard language doesn't sit unnoticed—it triggers an alert to Legal Ops, while LLM summarization provides digestible clause reviews grounded in source text.
Outcome: Obligations are tracked on time, non-standard clauses are flagged instantly, and legal risk exposure is significantly lowered.
Financial Documents: Invoices, Bank Statements, and KYC
Finance is often the first domain where brittle automation hurts. Invoice formats vary, IBANs get miskeyed, and KYC packs contain multiple IDs. Here, IDP extracts totals and line items, but more importantly, it enforces finance policy: cross-checks invoices against POs and goods receipts, validates vendor data against master records, and screens KYC documents against sanctions lists. High-value invoices trigger dual approvals, while segregation-of-duties rules block conflicts. Clean invoices auto-post into ERP; mismatches flow into dispute queues. Industry research puts manual invoice handling around $11–$13 per invoice, while automation reduces this to ~$2–$3, yielding savings at scale. A Harvard Business School/BCG study found that AI tools boosted productivity by 12.2% and cut task time by 25.1% in knowledge work, mirroring what IDP delivers in document-heavy workflows.
Outcome: Cheaper invoices, faster closes, and stronger compliance—all backed by measurable ROI.
Insurance: FNOL Packets and Policy Documents
A single insurance claim might bundle a form, a policy document, and a medical report—each with unique formats. Where ADP thrives in finance/AP, IDP scales horizontally across domains like insurance, where document diversity is the rule, not the exception. IDP parses and classifies each document, validating coverage, checking ICD/CPT codes, and spotting red flags such as duplicate VINs. Low-value claims flow straight through, while high-value or suspicious ones route to adjusters or SIU. Structured data feeds actuaries for fraud analytics, while LLM summaries give adjusters quick narratives backed by IDP outputs.
Outcome: Faster claims triage, reduced leakage from fraud, and an improved policyholder experience.
Healthcare: Patient Records and Referrals
Healthcare documents combine messy inputs with strict compliance. Patient IDs and NPIs must match, consent forms must be present, and codes must align with payer policies. IDP parses scans and notes, flags missing consent forms, validates treatment codes, and routes prior-auth requests into payer systems. Every action is logged for HIPAA compliance. Handwriting models capture physician notes, while PHI redaction ensures safe downstream LLM use.
Outcome: Faster prior-auth approvals, lower clerical load, and regulatory compliance by design.
Logistics: Bills of Lading and Customs Documents
Global supply chains are document-heavy, and a single error in a bill of lading or customs declaration can cascade into detention and demurrage fees. These costs aren't theoretical: a container held at a port for missing or inconsistent paperwork can run hundreds of dollars per day in penalties. With IDP, logistics teams can automate classification and validation across multilingual shipping manifests, bills of lading, and customs forms. Data is cross-checked against tariff codes, carrier databases, and shipment records. Incomplete or mismatched documents are flagged before they reach customs clearance, reducing costly delays. Approvals are triggered for high-risk shipments (e.g., hazardous goods, dual-use exports) while compliant documents flow straight through.
Outcome: Faster clearance, fewer fines, improved visibility, and reduced working capital tied up in delayed shipments.
Why IDP Matters for IT, Solution Architects & Data Scientists
Intelligent Document Processing (IDP) isn’t just an operations win—it reshapes how IT leaders, solution architects, and data scientists design, run, and improve enterprise document workflows.
Each role faces different pressures: stability and security for IT, flexibility and time-to-change for architects, and model lifecycle rigor for data scientists. IDP matters because it unifies these priorities into a system that is both adaptable and governed.
| Role | Top Priorities | How IDP Helps | Risks Without IDP |
|---|---|---|---|
| IT Leaders | API-first integration, RBAC, audit logs, HA/DR, observability | Reduces reliance on fragile RPA, enforces compliance via immutable logs, scales predictably with infra sizing | Security gaps, brittle workflows, downtime under peak load |
| Solution Architects | Reusable patterns, fast onboarding of new doc types, orchestration flexibility | Provides pattern libraries, reduces template creation time, blends rules (ADP) with learning (IDP) | Weeks of rework for new docs, brittle workflows that collapse under variability |
| Data Scientists | Annotation strategy, active learning, drift detection, rollback safety | Focuses labeling effort via active learning, improves continuously, ensures safe deployments with rollback paths | Models degrade as formats drift, high labeling costs, ungoverned ML lifecycles |
For IT Leaders — Stability, Security, and Scale
IT leaders are tasked with building platforms that don’t just work today but scale reliably for tomorrow. In document-heavy enterprises, the question isn’t whether to automate—it’s how to do it without compromising security, compliance, and resilience.
- API-first integration: Modern IDP stacks expose clean APIs that plug directly into ERP, CRM, and content management systems, reducing reliance on brittle RPA scripts. When APIs are absent, RPA can still be used—but as a fallback, not the backbone.
- Security and governance: Role-based access control (RBAC) ensures sensitive data (like PII or PHI) is only visible to authorized users. Immutable audit logs track every extraction, correction, and approval, which is critical for compliance frameworks such as SOX, HIPAA, and GDPR.
- Infrastructure readiness: IDP brings workloads that are GPU-heavy in training but CPU-efficient at inference. IT must size infrastructure for peak throughput, provision high availability (HA), and disaster recovery (DR), and implement observability layers (metrics, traces, logs) to detect bottlenecks.
Bottom line for IT: IDP reduces fragility by minimizing RPA dependence, strengthens compliance through auditable pipelines, and scales predictably with the right infra sizing and observability in place.
For Solution Architects — Designing for Variability
Solution architects live in the space between business requirements and technical realities. Their mandate: design automation that adapts as document types evolve.
- Pattern libraries: IDP allows architects to define reusable ingestion, classification, validation, and routing patterns. Instead of one-off templates, they create modular building blocks that handle families of documents.
- Time-to-change: In rule-based systems, adding a new document type could take weeks of template design. With IDP, supervised models fine-tuned on annotated samples reduce onboarding to days. Active learning further accelerates this by letting models improve continuously with human feedback.
- Orchestration flexibility: Architects can embed business rules where determinism matters (e.g., approvals, segregation of duties) and let IDP handle variability where templates fail (e.g., new invoice layouts, contract clauses).
Bottom line for architects: IDP extends their toolkit from rigid rules to adaptive intelligence. This balance means fewer brittle workflows and faster responses to changing document ecosystems.
For Data Scientists — A Living ML System
Unlike static analytics projects, IDP systems are live ML ecosystems that must learn, improve, and be governed in production. Data scientists in IDP programs face a very different reality than in traditional model deployments.
- Annotation strategy: High-quality training data is the single most important factor for IDP accuracy. DS teams must balance annotation throughput with quality, often using weak supervision or active learning to maximize efficiency.
- Active learning queues: Instead of labeling documents at random, IDP systems prioritize “hard” cases (low-confidence, unseen layouts) for human review. This ensures model improvements where they matter most.
- MLOps lifecycle: IDP requires robust release and rollback strategies. Models must be evaluated offline on validation sets, then online with A/B testing to ensure accuracy doesn’t regress.
- Drift detection: Document formats evolve constantly—new vendors, new clause language, new healthcare forms. Continuous monitoring for distributional drift is mandatory to keep models performant over time.
Bottom line for DS teams: IDP is not a one-time deployment—it’s an evolving ML program. Success depends on strong annotation pipelines, active learning strategies, and mature MLOps practices.
The Balancing Act: IDP and ADP Together
Enterprises often fall into the trap of asking: “Should we use ADP or IDP?” The reality is that both are required at scale.
- ADP (Automated Document Processing) provides the deterministic backbone—rules, validations, and routing. It ensures compliance and repeatability.
- IDP (Intelligent Document Processing) provides the adaptive brain—machine learning that handles unstructured and variable formats.
“Without ADP’s determinism, IDP cannot scale. Without IDP’s intelligence, ADP collapses under variability.”
Each persona sees IDP differently: IT leaders focus on security and stability, architects on adaptability, and data scientists on continuous learning. But the convergence is clear: IDP is the ML brain that, combined with ADP’s rules backbone, makes enterprise automation both resilient and scalable.
Build vs Buy — A Technical Decision Lens
Once you’ve audited your document DNA and determined that IDP is the right fit, the next question is clear: do you build in-house models, buy a vendor platform, or pursue a hybrid approach? The right choice depends on how you balance control, time-to-value, and compliance against the realities of data labeling, model maintenance, and security posture.
When to Build — Control and Custom IP
Building your own IDP stack appeals to teams that value control and differentiation. By training custom models, you own the intellectual property, tune performance for domain-specific edge cases, and retain full visibility into the ML lifecycle.
But control comes at a cost:
- Data/labeling burden: High-quality labeled datasets are the bedrock of IDP performance. Building requires sustained investment in annotation pipelines, tooling, and workforce management.
- MLOps lifecycle: You inherit responsibility for versioning, rollback strategies, monitoring for drift, and refreshing models at a regular cadence (often quarterly or faster in dynamic domains).
- Compliance overhead: In regulated industries (finance, healthcare, insurance), self-built solutions must achieve certifications (SOC 2, HIPAA, ISO) and withstand audits—burdens usually absorbed by vendors.
Build makes sense for organizations with strong ML teams, unique document types (e.g., specialized underwriting packs), and strategic interest in owning IP.
When to Buy — Accelerators and Assurance
Buying from an IDP vendor provides speed and assurance. Modern platforms ship with pre-trained accelerators for common document families: invoices, POs, IDs, KYC documents, contracts. They typically arrive with:
- Certifications baked in: SOC 2, ISO, HIPAA compliance frameworks already validated.
- Connectors and APIs: Ready-made integrations for ERP (SAP, Oracle), CRM (Salesforce), and storage systems (SharePoint, S3).
- Support for HITL workflows: Configurable reviewer consoles, audit logs, and approval chains.
The trade-off is opacity and flexibility. Some platforms act as black boxes—you can’t see model internals or adapt training beyond predefined accelerators. For enterprises needing explainability, this can limit adoption.
Buy makes sense when you need rapid time-to-value, industry certifications, and coverage for common document types.
When to Go Hybrid — Best of Both Worlds
In practice, many enterprises end up with a hybrid model:
- Use vendor platforms for the 80% of documents that fit common accelerators.
- Build custom models for niche, high-value document families (e.g., loan origination packs, insurance bordereaux, patient referral bundles).
This approach reduces time-to-market while still letting internal data science teams apply domain-specific lift. Vendors increasingly support this model with bring-your-own-model (BYOM) options—where custom ML models can plug into their ingestion and workflow engines.
Hybrid makes sense when enterprises want vendor reliability without giving up control over specialized cases.
Decision Matrix — Build vs Buy vs Hybrid
| Criteria | Build | Buy | Hybrid |
|---|---|---|---|
| Time-to-value | Slow (months for data & infra) | Fast (weeks with pre-trained accelerators) | Moderate (weeks for core, months for custom) |
| Model ownership | Full control & IP | Vendor-owned, black-box risk | Split (vendor core + custom models) |
| Labeling overhead | High (manual + active learning required) | Low (pre-trained sets included) | Medium (low for standard docs, high for niche) |
| Change velocity | Fast for custom models, but resource heavy | Limited flexibility; vendor release cycles | Balanced—vendor updates core, teams adapt niche |
| Security posture | Custom certifications required; heavy burden | Certifications pre-included (SOC 2, ISO, HIPAA) | Mixed—vendor covers core; teams certify niche |
Practical Guidance
Most enterprises overestimate their capacity to sustain a pure-build approach. Data labeling, compliance, and MLOps burdens grow faster than expected. The most pragmatic path is usually:
- Start buy-first → leverage vendor accelerators for common documents.
- Prove value in 4–6 weeks with invoices, POs, or KYC packs.
- Extend with in-house models only where domain-specific lift matters
The Road Ahead for IDP — Future Directions & Practical Next Steps
Intelligent Document Processing (IDP) has matured into the AI/ML brain of enterprise document workflows. It complements ADP’s rules backbone and RPA’s execution bridge, but its next evolution goes further: adding semantic understanding, autonomous agents, and enterprise-grade governance.
The opportunity is huge—and organizations don’t need to wait to start benefiting.
From Capturing Fields to Understanding Meaning
For most of the last decade, IDP success was measured in terms of accuracy and throughput: how well could systems classify a document and extract key fields? That problem isn’t going away, but the bar is moving higher.
The new wave of IDP is about semantics, not just syntax. Large Language Models (LLMs) can now sit on top of structured IDP outputs to:
- Summarize long contracts into digestible risk reports.
- Flag unusual indemnity clauses or missing obligations.
- Turn unstructured patient notes into structured clinical codes plus a narrative summary.
Crucially, these insights can be grounded with RAG (retrieval-augmented generation) so that every AI-generated summary points back to original text. That’s not just useful—it’s essential for audits, legal review, and compliance-heavy industries.
From Rigid Workflows to Autonomous Agents
Today’s IDP systems route structured data into ERPs, CRMs, claims platforms, or TMS portals. Tomorrow, that’s just the beginning.
We’re entering the era of multi-agent orchestration, where AI agents consume IDP data and carry processes further on their own:
- Retriever agents fetch the right documents from repositories.
- Validator agents check against policies or risk thresholds.
- Executor agents perform actions in systems of record—posting entries, triggering payments, or updating claims.
Think of claims triage, accounts payable reconciliation, or customs clearance running agentically, with humans stepping in only for oversight or exception handling.
The Governance Imperative
But greater autonomy brings greater risk. As LLMs and agents enter document workflows, enterprises face questions about reliability, safety, and accountability.
Mitigating that risk requires new disciplines:
- Evaluation harnesses to stress-test workflows before release.
- Red-team prompting to uncover weaknesses in model behavior.
- Rate limiters and cost monitors to keep operations stable and predictable.
- Immutable audit trails to satisfy regulators and assure internal stakeholders.
The winning IDP programs will be those that combine innovation with governance—pushing toward new capabilities without sacrificing control.
What Enterprises Should Do Now
The future is exciting, but the real question for most leaders is: what should we do today?
The playbook is straightforward:
- Audit your document DNA. What types dominate your enterprise? How variable are they? What’s the velocity? This tells you whether ADP, IDP, or both are needed.
- Pick one family for a pilot. Invoices, contracts, claims—choose something high-volume and pain-heavy.
- Run a 4–6 week pilot. Track four metrics: accuracy (F1 score), first-pass yield, exception rate, and cycle time.
- Scale with intent. Expand to adjacent document types. Layer ADP for compliance, IDP for variability, and use RPA only where APIs aren’t available.
- Build future hooks. Even if you don’t deploy LLMs or agents today, design workflows that could accommodate them later. That way, you’re not re-architecting in two years.
The point isn’t to leap straight into futuristic agent-driven workflows—it’s to start measuring and capturing value now while preparing for what’s next.
FAQs
1. What do analyst firms say about the IDP market?
Analyst firms generally place Intelligent Document Processing (IDP) within the broader “intelligent automation” or “hyperautomation” stack alongside RPA, BPM/workflow, and analytics. While terminology varies (e.g., “document AI,” “content intelligence,” “intelligent automation platforms”), the consensus is that IDP provides the learning and interpretation layer that makes automation resilient when document formats vary.
They evaluate vendors on ingestion, classification, extraction, HITL review, workflow depth, platform qualities, and time-to-value. Enterprises should map their document DNA (volume, variability, velocity) against vendor strengths and validate via time-boxed pilots measuring F1, FPY, exception rates, and cycle times.
2. What is RAG (retrieval-augmented generation) in IDP, and how is it wired into the pipeline?
Retrieval-augmented generation (RAG) grounds LLM outputs in retrieved source documents, reducing hallucinations and ensuring traceability. In IDP pipelines, RAG sits after extraction to enable summaries and explanations that cite original text.
Typical flow:
- IDP extracts structured fields/tables with confidence scores.
- Text chunks + metadata (page, section, doc type) are embedded into a vector index.
- A retriever selects relevant chunks, which are appended to the LLM prompt.
- The LLM generates grounded outputs (summaries, risk flags, obligation lists) with citations.
- Outputs, retrieval sets, and model versions are logged for audit.
3. What risks come with LLMs in document workflows, and how do we mitigate them?
Key risks include hallucinations, data leakage, prompt injection, compliance gaps, cost/latency spikes, and explainability demands.
Mitigation strategies:
- Hallucinations: Use RAG grounding, “answer-from-context” prompting, factuality testing.
- Data leakage: Redact PII, enforce private deployments, encrypt retention.
- Prompt injection: Sanitize retrieved text, restrict tool calls, red-team for attacks.
- Compliance gaps: Log all prompts/outputs, enforce RBAC, pin model versions.
- Cost/latency: Use smaller models for routine tasks, cache embeddings, batch jobs.
- Explainability: Force LLMs to cite page/section; show retrieval set to reviewers.
Rule of thumb: Treat the LLM as a semantic assistant layered on IDP outputs, not the final authority.
4. How should enterprises measure IDP success?
IDP success should be measured across accuracy, throughput, cost, and governance:
- Accuracy: F1 score per field, exact match %, exception rate, confidence-based auto-post rate.
- Throughput: First-pass yield (FPY), cycle times (P50/P95), reviewer minutes per document.
- Cost: Cost per document including compute + human review, scalability at peak loads.
- Governance: Audit completeness, drift alerts resolved, rollback readiness.
Run a 4–6 week pilot to baseline these metrics, then monitor monthly. Success = higher F1/FPY, lower exceptions and cost/document, and stable auditability.
5. Can IDP handle handwriting reliably? What should we expect?
Yes—modern IDP platforms can handle handwriting, but reliability depends on scan quality, script, and language. Expect strong results on short structured fields (names, dates, amounts) if scans are clean (≥300 DPI).
Challenges arise with cursive scripts, noisy mobile captures, and non-Latin handwriting without domain-specific training.
Best practices include:
- Pre-process scans (de-skew, contrast boost).
- Zone handwriting separately from typed sections.
- Enforce field constraints (e.g., date formats).
- Apply confidence funnels (≥0.95 auto, 0.80–0.94 review, <0.80 escalate).
- Feed reviewer corrections back into training.
Expectation: Mixed-type documents can achieve 95%+ accuracy with HITL. Handwriting-heavy forms may still need selective review at first.