
OCR (Optical Character Recognition) is a game changer for anyone who works with PDF documents. PDF files are notorious for being difficult to edit and search through. When you OCR a PDF, it ensures the text is scanned and extracted, making it fully searchable, editable, and accessible.
In this guide, we will compare various methods of OCR-ing PDFs to help you choose the best one that suits your requirements. We will discuss Adobe Acrobat, open-source tools, and AI-powered solutions. Additionally, we will answer common questions such as how to OCR a PDF on a Mac, make a PDF OCR searchable, and share tips on improving OCR accuracy.
Follow along to transform your PDF workflows.
1. Using Adobe Acrobat Pro to OCR a PDF
Adobe Acrobat Pro is considered the gold standard for PDF files. As an industry leader in PDF software, Adobe packs Acrobat Pro with advanced character recognition capabilities that easily handle complex documents.
You can OCR a document using Acrobat Pro in two ways:
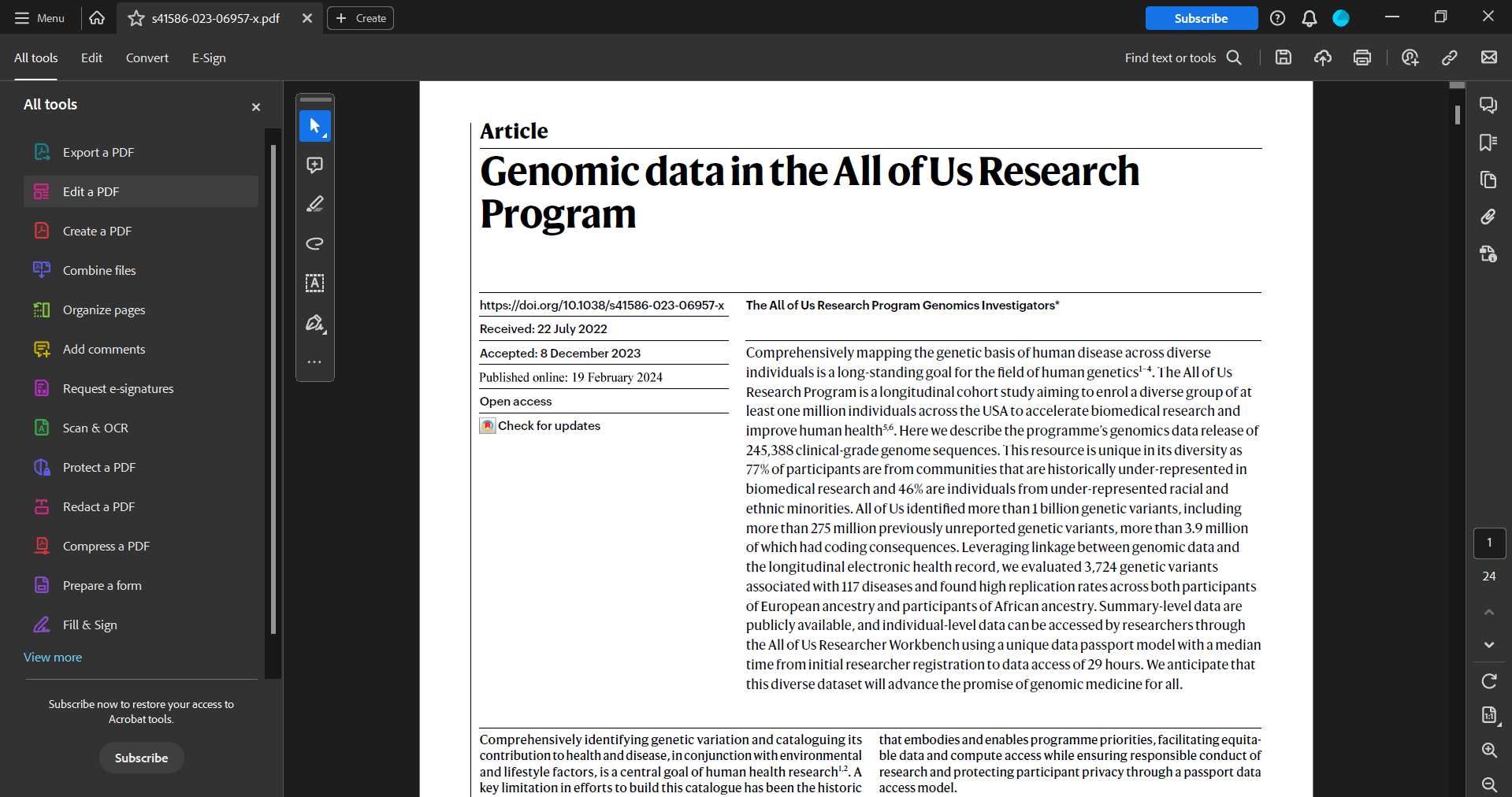
Method 1: Edit PDF
- Open the PDF file in Adobe Acrobat Pro.
- Click on "All Tools" in the toolbar.
- A menu will appear, listing all available tools. Click on "Edit PDF".
- Acrobat will automatically apply OCR and convert the text.
- The document is now fully editable and searchable. Change the font or add annotations as needed. You can also search the document using the Find tool.
Method 2: Scan and OCR
- Open Adobe Acrobat Pro.
- Click on "All Tools" in the toolbar.
- A menu will appear, listing all available tools. Click on "Scan and OCR".
- In the Scan and OCR tool, select the PDF file you want to OCR or scan a physical document directly using a connected scanner. A PDF OCR Scanner ensures accurate text extraction during this process.
- Click on "Enhance" if the JPG or PNG needs cleaning up. This will improve OCR accuracy.
- Click on "Recognize Text" to start the OCR process. Once complete, the PDF will become searchable and editable. You can now edit text.
Here's how you can merge PDF files.
The essential advantage of using Acrobat Pro is its advanced OCR tool, which can handle complex layouts, multi-column documents, low-resolution scans, and handwritten text with high accuracy. It is available on Windows, Mac, and Android devices, and you can also access these features online. Moreover, it is connected to your Adobe Mobile Scan app, allowing you to scan documents on the go and sync them to your Acrobat library.
However, you must be an Acrobat Pro subscriber to access the OCR capabilities. The subscription is priced at US$19.99/mo. In addition, while it allows you to upload multiple files, you'll have to OCR each file one by one manually. So, if you have many files to process, it can get tedious.
2. Using open-source tools to OCR a PDF
Open-source OCR tools like Tesseract offer a free alternative for converting PDFs into searchable, editable files. Although they may not be as full-featured as commercial solutions like Adobe Acrobat, they provide a decent level of accuracy for most use cases.
Tesseract is available for Windows, Mac, and Linux. You'll first need to install it on your computer to use it. Once installed, you can follow these steps to use Tesseract to OCR a PDF:
- Open the PDF file in a viewer or editor tool.
- Select the area or page you want to OCR and take a screenshot. Crop the image if necessary.
- Open Terminal to access Tesseract. If Tesseract is not found in Terminal, edit the environment variable path to direct to the Tesseract installation directory.
- Copy the path of the JPG or PNG file that you want to OCR. For example: "C:\Users\JohnDoe\Pictures\Screenshots\Screenshot 230844.png"
- Enter the following command in Terminal: "C:\Users\JohnDoe\Pictures\Screenshots>tesseract Screenshot 230844.png". This will run OCR on the image and convert any text it finds into an editable format.
- Once OCR is complete, Tesseract will generate a file containing all the extracted text.
- Open this file in any text editor to view and edit the OCR-ed content. You can also enter the command `--help` to get the complete list of Tesseract options if needed.
The critical advantage of Tesseract is that it is completely free and open source, so you don't need to pay any licensing fees. It works well on clean scans and typed documents.
However, it struggles with handwritten text, complex layouts, colored backgrounds, and low-resolution scans. If your documents are clean and typed, Tesseract offers a free solution for basic OCR needs.
You can improve Tesseract's accuracy by preprocessing scans before running OCR — adjusting brightness or contrast, applying filters, upscaling JPGs, and more.
3. Using Nanonets to OCR a PDF
Nanonets is an AI-based document processing solution that offers advanced OCR capabilities. Unlike Acrobat Pro or Tesseract, Nanonets is completely online and requires no installation. Whether you’re on Mac, Linux, or Windows, you can simply upload your PDFs and run OCR via Nanonets' intuitive web interface.
The app immediately starts processing your documents using state-of-the-art OCR algorithms. It can even process entire folders and hundreds of PDFs in one go.
Nanonets can handle everything from simple typed documents to complex layouts with handwritten annotations, colored backgrounds, graphs, and tables, using deep learning models to achieve high accuracy on all document types.
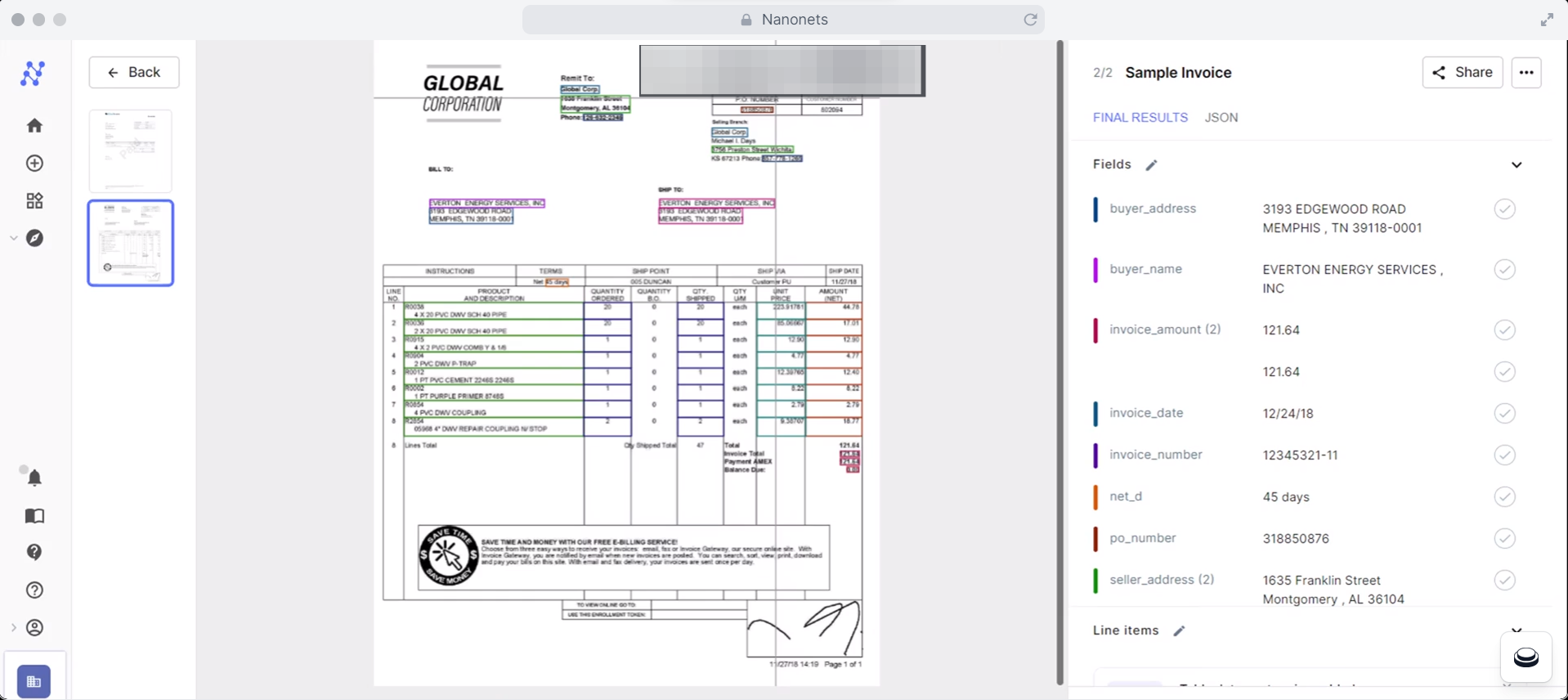
Here's how it works:
- Visit Nanonets.com and create a free account.
- Select an OCR model from Nanonets' wide range of pre-trained models for invoices, receipts, or purchase orders. You can also build a custom model tailored to your specific document types.
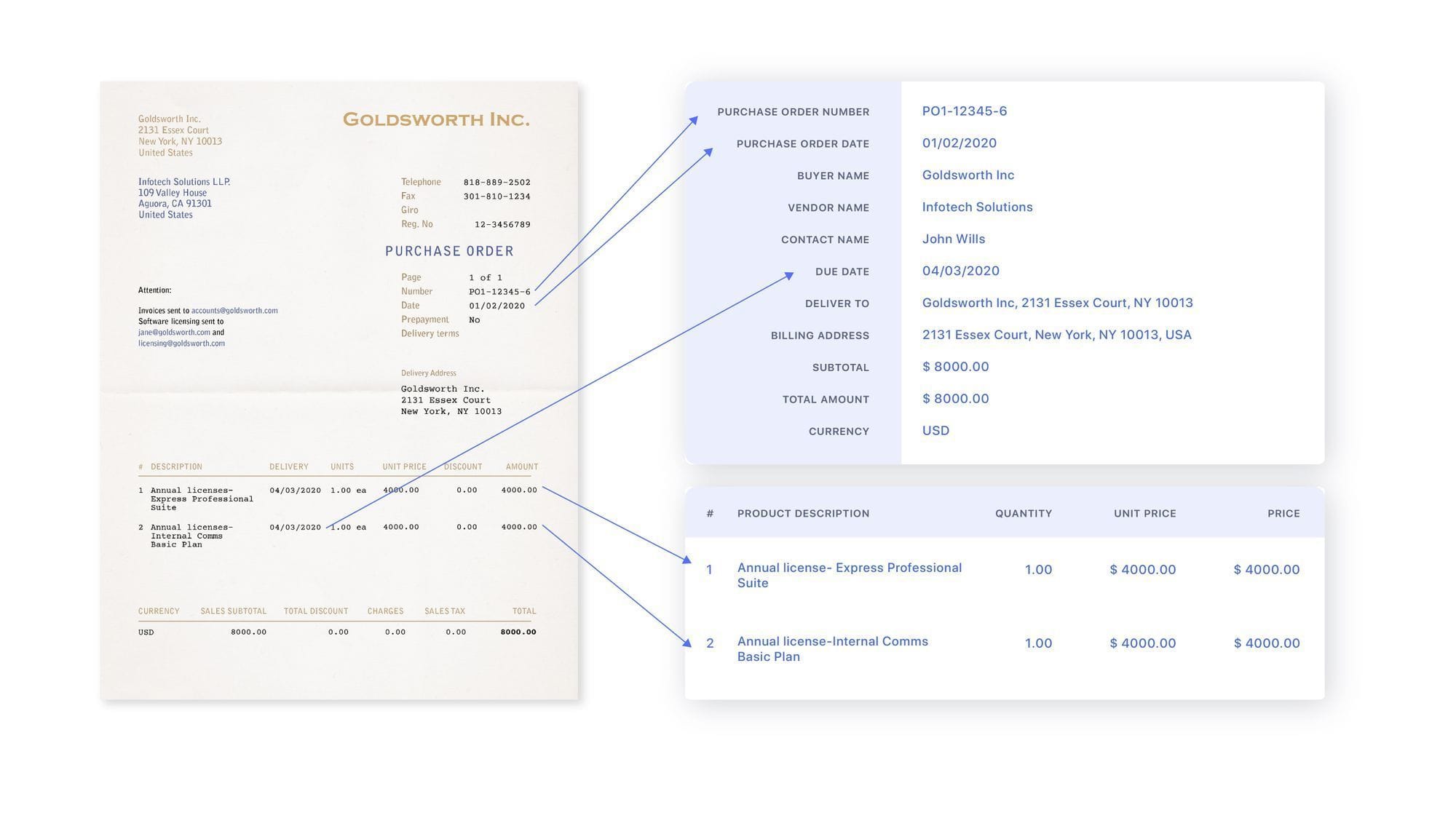
- Upload documents representing the different layouts and data fields you need to extract. Nanonets will analyze these samples to understand the structure of your documents.
- Define the key fields you want to capture, such as date, total amount, and table data. You can capture data in almost any format, including tables, text, JSON, or XML. Nanonets will automatically extract the data from your PDFs and output it in the required format.
- Once configured, upload your PDF documents that need to be OCR-ed. Nanonets will process the files using advanced OCR and intelligent data extraction algorithms to convert them into searchable, editable formats with structured data output.
- The extracted data is neatly organized and structured for you to ingest directly into other business systems without manual effort. You can export it as JSON, XML, or custom formats.
Nanonets offers a free version with up to 500 processing pages so that you can test it out at no cost. After that, it costs $0.3 per page for OCR.
Unlike other solutions, Nanonets is highly scalable. It can process thousands of pages per hour, ensuring that no matter the volume, your files get processed almost instantly.
You can set up webhooks to stream processed data to other apps or use Nanonets' developer APIs to build custom integrations.
How to improve the PDF OCR process
OCR technology, when implemented effectively, can save you time and resources. Imagine being able to reduce data entry time per field by 95%. Your team could focus on more meaningful tasks than mundane data entry.
Let's explore tips to improve the accuracy and effectiveness of your PDF OCR process:
1. Preprocess scans before OCR
If you are planning to scan the documents, you can adjust the brightness, contrast, and sharpness and apply filters or image enhancement techniques to reduce noise and improve clarity.
This will significantly boost OCR accuracy. Adobe's Scanner app comes with built-in image enhancement features. You can also use tools like PaperScan and NAPS2 to clean up scans. After these edits, you can save the edited images as PDFs before running OCR.
2. Set up validation workflows and approval hierarchies
Improve data quality by setting up validation rules for extracted data. For example, if the order number in a document doesn't have five digits, it is automatically rejected or flagged for manual review. This way, you can catch extraction errors and only approve valid data. You can also integrate your OCR system with databases to validate extracted data.
You can set up approval hierarchies where junior employees review data first, followed by senior employees for final sign-off. With automated notifications and live status updates, you can maintain transparency and avoid approval chasing, leading to faster document processing.
3. Build automated workflows
Imagine running a car rental and being able to automatically export customers' driver's license data to Salesforce or send invoice data to QuickBooks without any manual work. Not only will it optimize your PDF OCR but also downstream activities.
Integrating your OCR solution with business apps via APIs makes this automation possible. For example, with Nanonets, you simply set up triggers based on events like document processing completion, data extraction, or a new file upload. The integration will automatically export structured data from Nanonets to desired business systems—including QuickBooks, Xero, Zapier, Microsoft Dynamics, Zendesk, and many others—removing manual efforts and ensuring seamless data flow between systems.
4. Invest in advanced OCR tools with AI/ML capabilities
Unlike rules-based OCR, Machine Language and AI-based OCR tools are adaptive — continuously learning from human corrections and improving over time. For example, Nanonets offers a proprietary AI model trained on millions of documents, allowing it to handle complex and challenging layouts efficiently.

AI-powered OCR ensures that you can extract information from documents without losing context. It can handle different languages, monetary, legal, or measurement units. This level of intelligence is not possible with template-based or rules-driven extraction that relies on exact field locations.
5. Train the AI-OCR models
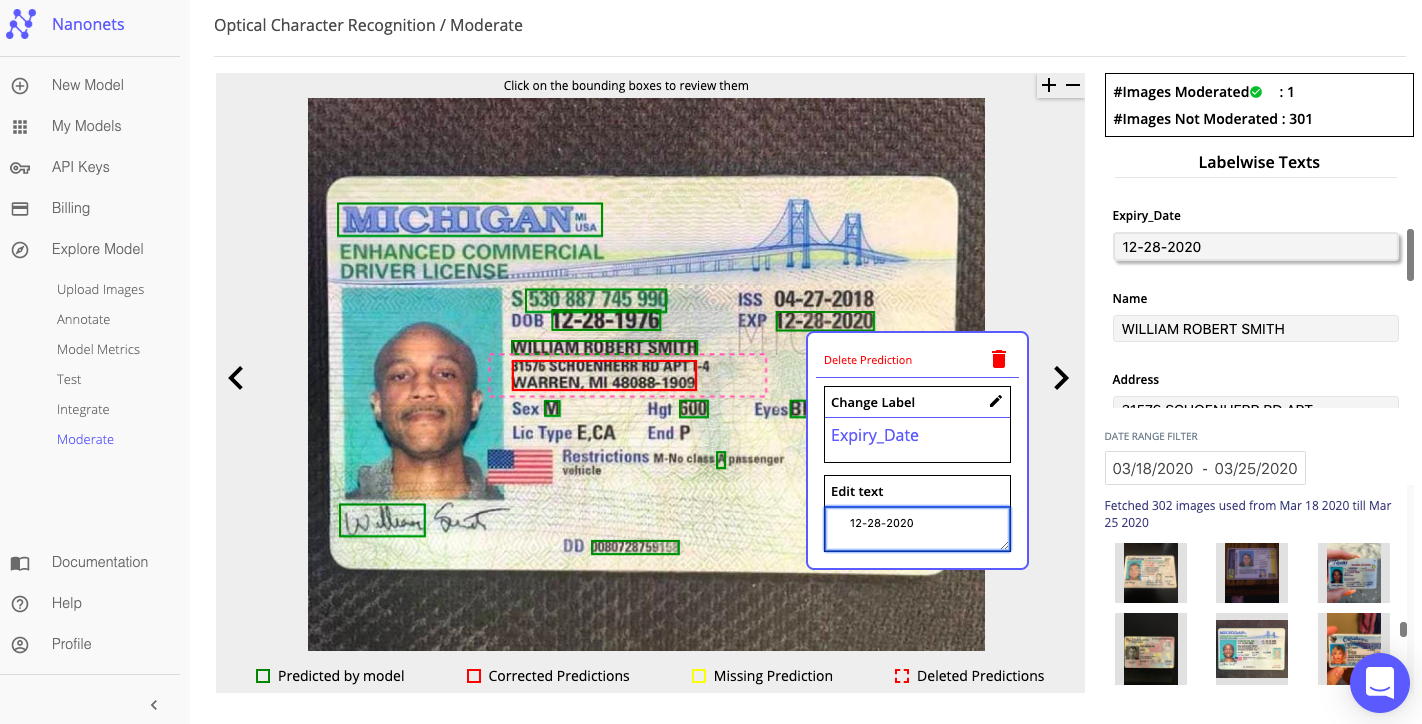
While AI-powered OCR solutions come with pre-trained models, training them further on your specific document types and layouts can boost accuracy even more. For example, Nanonets allows you to upload a sample set of documents representing the various templates, formats, and fields you want to capture.
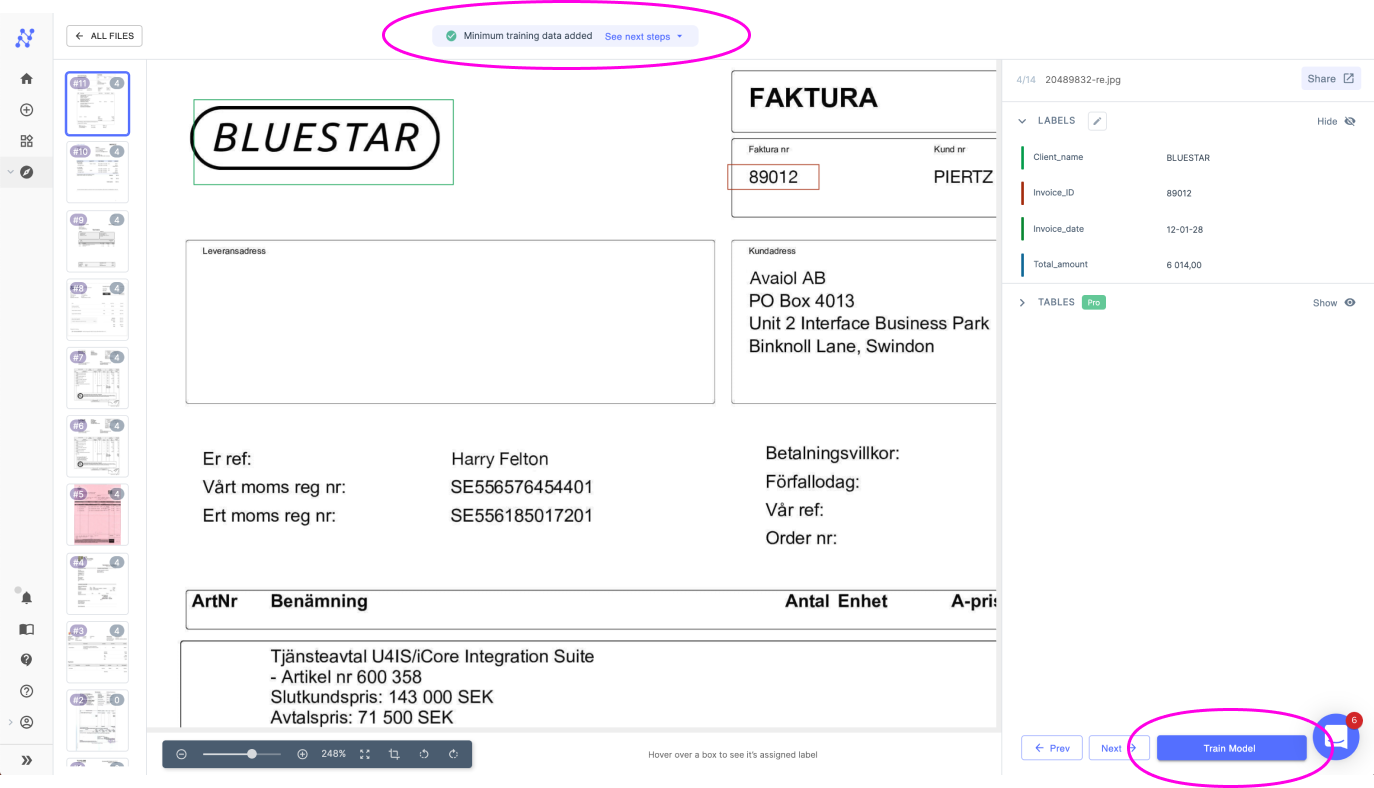
These samples help the model understand the structure of your documents and fine-tune the PDF OCR process. You can also provide feedback by correcting extraction errors identified during validation. This human-in-the-loop training continually enhances the AI model's performance.
6. Build custom OCR models when required
Sometimes, pre-trained models may not cover all the complexities in your documents. For instance, you may have industry-specific documents with unique fields and formats. In such cases, you can work with your OCR vendor to build custom AI models trained specifically on your documents.
With Nanonets, users can create custom models specific to their document types and fields to extract. They can upload sample documents and annotate them with the labels they want to extract. The AI then learns from these examples and is trained to recognize and extract the specified information. The system requires at least ten examples for each label to achieve optimal accuracy, and users can monitor the number of examples for each label and add more as needed.
How to get started with Nanonets PDF OCR
Nanonets makes it easy to get started with PDF OCR. Simply sign up for a free account on the Nanonets website. You don't need to provide a credit card.
Here is a guide to help you get started:
- Sign up for a free account: Visit Nanonets.com and sign up for a free account—no credit card required.
- Create or choose a model: You can build a custom OCR model for your specific document types or select from Nanonets' pre-trained models for invoices, receipts, and more.
- Set up auto-import: Forward emails or connect cloud storage to import new PDFs into Nanonets for continuous OCR processing automatically.
- Upload sample documents: Upload at least 10 sample documents representing various templates, formats, and data fields you want to extract. This will help train the AI model.
- Define fields to extract: Simply specify names for the critical data fields you want to extract from your documents, such as Date, Amount, Table Data, etc.
- Set up validations: Configure rules to validate extracted data and flag any errors for correction to ensure accuracy.
- Process your files: Upload your PDF documents. Nanonets will instantly process them with OCR and intelligent data extraction.
- Review and approve data: Check extracted data and approve valid entries. Maintain transparency with status updates.
- Export data to business systems: Once approved, seamlessly export structured data to your ERP, accounting, CRM, or other systems.
- Automate workflows: Set up triggers to stream data to apps when a document is processed or data is extracted.
Overall, Nanonets makes adding intelligent OCR capabilities to your document workflows quick and easy. The self-learning AI engine delivers high accuracy from the beginning while allowing customization to handle complex documents. Seamless integrations with business systems enable true end-to-end automation.
How to make a PDF searchable?
A searchable PDF can save time by allowing users to find specific words or phrases within a document. To search for specific words or phrases on Windows, simply press Ctrl+F, or on Mac, press Command+F.
There are a few methods to make a PDF searchable:
- Convert PDF to Word: Most online converters can extract the text into an editable Word document. Once in Word, the text is now searchable. Convert the Word file back into a PDF to retain searchability.
- Use Adobe Acrobat's built-in text recognition: Under the "Tools" menu, select "Recognize Text" and output as a searchable. Acrobat can recognize text appropriately without the need for conversion.
- Leverage advanced OCR engines: Open-source OCR software like Tesseract can accurately extract text from scanned documents. The output text file can then be searched.
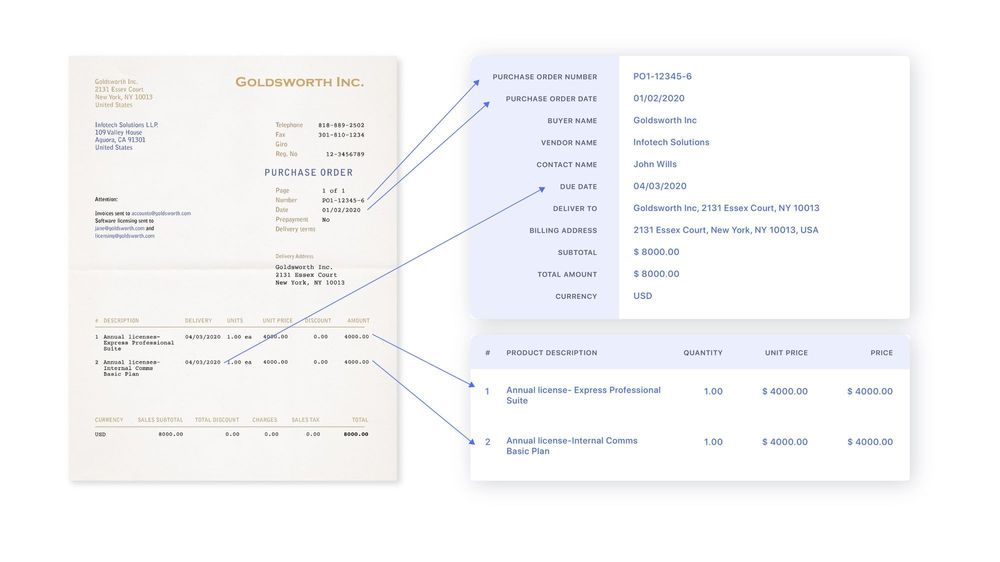
Nanonets provides an AI-powered document processing platform to make large volumes of PDFs searchable automatically. It uses deep learning algorithms for incredibly accurate text extraction without manual intervention. This saves enormous time by eliminating tedious OCR processing work. Users can instantly find keywords and phrases across multiple documents in their databases.
Wrapping up
Intelligent OCR and data extraction can help unlock tremendous value from document workflows. The key is choosing a solution like Nanonets that offers AI-powered OCR from the start and allows customization for specific needs.
With self-service capabilities to build custom models, accuracy and automation continuously improve even as your documents evolve. Ultimately, this ensures you can handle unstructured data at scale to drive productivity and growth.
PDF OCR FAQs
How can I OCR a PDF for free?
You can OCR a PDF for free using open-source tools like Tesseract. Simply install Tesseract, take a screenshot of the PDF, and run OCR via the command line. For more accurate results and advanced features, consider using AI-powered OCR solutions like Nanonets. Nanonets offers a free version and can handle complex layouts and large volumes with ease.
How do I enable OCR on a PDF?
To enable OCR on a PDF, open it in Adobe Acrobat Pro. Go to Tools > Enhance Scans > Recognize Text. Choose the pages and click Recognize Text. The PDF will become searchable and editable.
For a more automated solution, try Nanonets. Simply upload your PDFs, and Nanonets will OCR them and extract data into searchable formats. It's fast, accurate, can handle bulk processing, and requires no manual effort.
How do I convert PDF to OCR?
To convert a PDF to OCR format:
- Open the PDF in Adobe Acrobat Pro
- Go to Tools > Enhance Scans > Recognize Text
- Select the pages and language
- Click "Recognize Text" to run OCR
OCR is useful for:
- Digitizing scanned PDFs into editable formats
- Making PDF text searchable for quick reference
- Enabling text-to-speech for accessibility
- Extracting PDF text for use in other apps
- Translating PDF content to other languages
How to make PDF OCR searchable?
To make a PDF searchable, you need to run OCR (Optical Character Recognition) on it. OCR converts the text in a scanned PDF into machine-readable text, allowing you to search, copy, and edit the content.
- Adobe Acrobat Pro: Tools > Enhance Scans > Recognize Text
- Tesseract OCR: Take a screenshot, run the OCR command
- Nanonets: Upload PDF, extract data to searchable formats
Can Google OCR a PDF?
Google Drive cannot directly OCR PDFs. However, you can convert a PDF to a Google Doc, which makes the text searchable. Open the PDF in Drive, go to File > Download > Google Docs, and the text will be extracted. But this only extracts the raw text without any formatting or structure. For more advanced OCR with intelligent data extraction, you'll need a dedicated tool like Nanonets. It can handle complex PDF layouts, extract specific data fields, validate the extracted information, and export it to your business systems.