
Looking to export information from PDFs using an OCR Scanner solution? Try Nanonets™ advanced AI-based PDF OCR Scanner to extract and organize information from PDFs automatically.
The Need for PDF OCR Scanners...
Today, most businesses have gone paperless for information transfer and transactions; people depend on technologies that scan documents from printed and handwritten material. However, scanning or digitalizing hard-copy files requires efficient and accurate technology with a consistent information format. Therefore, most individuals, organizations, and corporates widely use PDF documents to digitally create, store, and share information. It is because PDF documents are usually well structured, consistent, secure, and can be easily handled on different devices.

On the other hand, there are some disadvantages with PDF documents, mainly with the editing of the document. It's not possible to directly edit your PDF file for free. We'll need to use software like Adobe Acrobat to acquire the "editing" function. Furthermore, if the information inside the PDF is unstructured, say we have tables, images, scanned text, then it's even harder to search or manually digitize everything.
This is where PDF document scanners are utilized; It's usually a piece of software that'll help scan the contents of a PDF document and store it in a desirable, editable, and a more structured format.
In this blog, we'll look at working with PDF scanners and learn the different methods of building an in-house PDF scanner that can help automate information extraction from documents using OCR and Deep Learning. We'll also look at some of the online PDF scanner tools to utilize for document management workflows. Below is the table of contents.
- Some Use-cases for PDF Document Scanning
- PDF Scanner Software for Electronic Documents
- PDF Scanning for Non - Electronic Documents
- Workflows for Scanning PDFs with OCR
- Enter Nanonets: Cloud-based PDF Scanning Solution
Looking for a PDF OCR Scanner to extract information from PDFs? Give Nanonets™ a spin for higher accuracy, greater flexibility, post-processing, and a broad set of integrations!
Some Use-cases for PDF Document Scanning
In this section, we'll look at some of the common use-cases where PDF document scanners can automate general information gathering that we see in everyday life. First, let's look at different types of scanned PDFs.
- Image PDFs: These PDFs are also referred to as non-electronically generated PDFs. In this type, we see more content hard-coded as images. This is the case when you have a hard copy document scanned into a PDF file.
- Searchable Scanned PDFs: This type of scanned PDF document may have hidden text behind the image, these are also referred to as electronically generated PDFs.
- Mixed Scanned PDFs: This type of scanned PDF can include scanned images and electronically generated PDF elements.
In most cases, Optical Character Recognition (OCR) is utilized for scanning documents. Using OCR is much more efficient and less error-prone as they are well trained and have achieved state-of-the-art performance in several areas of research like Computer Vision and Deep Learning.
Optical Character Recognition (OCR) helps to extract data from scanned documents and returns editable data.
Now, let’s dive into some of the most common use cases.
Tax Auditing
Many individuals, organizations, and businesses go through various PDF documents to grab crucial tax profiling and auditing information. They need to frequently search for particular expenses, which is time-consuming and less efficient when the documents are not digitized. Also, sometimes they might end- up erring with the wrong estimation when there’s an error in manual data entry.
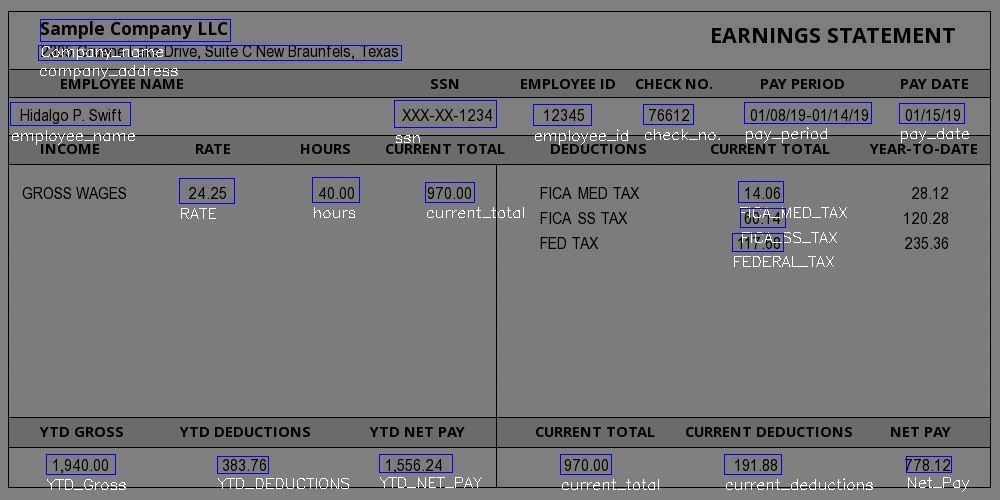
For tasks like these, a PDF scanner can be much more convenient. These will help us convert all the crucial information into an editable format to make things much more accessible. Not just that, PDF OCR scanners can also extract complex regions of PDFs such as tables into the desired format with which expenses for tax-related documentation can be more manageable.
Invoice Information Extraction
Invoices are everywhere; companies need to save invoices and store them for future reference for every transaction. These are mostly shared sent via emails captured through devices.
Therefore, a PDF OCR scanner can help extract meaningful information like invoice id, date, seller name, invoice total, and tax information to further store in a more readable format. The extracted data can also be exported into formats such as spreadsheets, JSON. Here's a screenshot of how information from PDF invoices can be extracted using PDF scanners.

However, there are some complexities involved in extracting data from PDF invoices as they are mostly unstructured. This is where deep learning algorithms are used to perform PDF data extraction, turning the unstructured format into a more readable format.
Recruitment / Hiring Process
Finding the right talent is always hard. HR teams spend lots of time studying profiles and resumes of people during this process. However, intelligent solutions like PDF OCR scanners can be utilized for resume parsing and automatic validation tasks. This will help extract all the crucial information like years of experience, leadership qualities and can rank the profile by understanding the data. Additionally, NLP (Natural Language Processing) is leveraged as a post-processing step for increasing the accuracy of the output of the OCR PDF scanner.

Document Analysis and Reporting (Ex. Medical Documents)
PDF scanners are also utilized for document analysis and reporting. This process involves extracting text using PDF scanners and performing qualitative research in which documents are interpreted by the researcher to give voice and meaning to an assessment topic. Since PDF documents are complex and not generic, different algorithms and techniques like table extraction, image super-resolution, text classification, and analysis are also utilised.

In the next section, let’s look at the working of PDF Scanner Software for Electronic Documents.
Looking for a PDF OCR Scanner to extract information from PDFs? Give Nanonets™ a spin for higher accuracy, greater flexibility, post-processing, and a broad set of integrations!
PDF Scanner Software for Electronic Documents
PDF documents are generated in two ways, electronic PDF and non-electronic PDFs. Electronic copies are usually exported from software like Microsoft Word, Google Docs, or Adobe Acrobat. Building a PDF scanner for this type is straightforward; we can either use a programming library and create one from scratch or use any free online service. Now let’s look at some popular libraries and frameworks for performing PDF scanning and text-extracting tasks with Python and Java.
PyPDF2: PyPDF2 is a popular Python-based library that can extract text from electronically generated PDFs. Using this framework, we can also perform different operations such as rotating, merging, splitting pages in a PDF. Following is a simple code snippet that can act as a PDF scanner using PyPDF2.
import PyPDF2
pdfFileObj = open('example.pdf', 'rb')
pdfReader = PyPDF2.PdfFileReader(pdfFileObj)
print(pdfReader.numPages)
pageObj = pdfReader.getPage(0)
print(pageObj.extractText())
pdfFileObj.close()
Let's decode the steps in the above program. Firstly, we import the PyPDF2 library using the import function. We use the open method and read a PDF file by sending the parameter read as rb. The PdfFileReader is used to read the PDF as a pdf reader object. We can print the number of pages in the PDF using the numPages method on the pdf object. Next, we use the getPage method to read the page as an object in a variable. Lastly, We use an extract text method that scans the page's contents and stores editable text.
pdfrw: pdfrw is a lightweight python based library that can help scan electronic PDFs. Apart from scanning the PDF document, some other operations include subsetting, merging, rotating, modifying metadata, etc. Here’s a simple example that can scan PDFs.
>>> from pdfrw import PdfReader
>>> x = PdfReader('source.pdf')
>>> x.keys()
['/Info', '/Size', '/Root']
>>> x.Info
{'/Producer': '(cairo 1.8.6 (http://cairographics.org))',
'/Creator': '(cairo 1.8.6 (http://cairographics.org))'}
>>> x.Root.keys()
['/Type', '/Pages']Reading PDF files in Java: Java comes with powerful inbuilt classes which can be utilised to read and write PDFs. Now, we’ll look at an example in which we’ll be using the PDFTextStripper class to scan an electronic PDF document.
import java.io.File;
import java.io.IOException;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.text.PDFTextStripper;
public class PdfToConsole {
public static void main(String args[]) throws IOException {
//Loading an existing document
File file = new File("D://Sample.pdf");
PDDocument document = PDDocument.load(file);
//Instantiate PDFTextStripper class
PDFTextStripper pdfStripper = new PDFTextStripper();
//Retrieving text from PDF document
String text = pdfStripper.getText(document);
System.out.println(text);
//Closing the document
document.close();
}
}In the above example, first, we import all the necessary libraries. Next, inside the main class, we load the PDF document using the File class. This file is now passed into the PDFTextStripper class to use all the operations on the PDFs. Lastly, we’ll use the getText method, which usually scans the entire PDF and returns a string object.
In the next section, we’ll look at how PDF documents can be scanned for non-electronic documents.
Looking for a PDF OCR Scanner to extract information from PDFs? Give Nanonets™ a spin for higher accuracy, greater flexibility, post-processing, and a broad set of integrations!
PDF Scanning for Non-Electronic Documents
The non-electronically generated PDFs are scanned images of text that are inherently inaccessible as the document's content are of images and not searchable text. Because of this, traditional PDF scanners cannot read or extract the words, and operations such as select, edit, resize, reflow text, or changing colors cannot be performed; additionally, authors cannot even manipulate the PDF for accessibility.

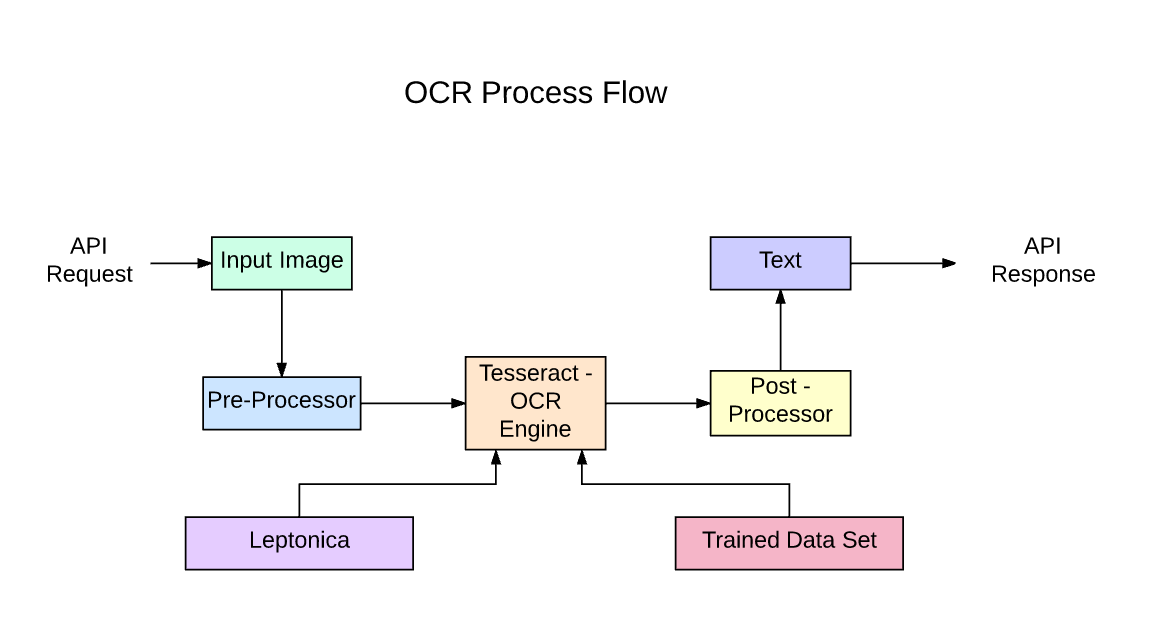
This is where OCR (Optical Character Recognition) techniques are widely utilized to scan PDFs. These are highly efficient and can extract data from PDFs using AI. However, we’ll also need to perform some additional steps such as pre-processing, named entity recognition, and many more to achieve state-of-the-art performance. Now, let’s look at the working of OCR for scanning PDFs.
Typically, performing OCR involves three phases to convert documents into editable text. The first phase is usually preprocessing; here, the OCR attempts to make the text in the document clearer and easy to read. It does this by identifying entities of PDFs such as text, images, tables, headings and isolating them. With this, it makes sure that the lines and alignment of text are smoothed out.

In the second phase, the OCR individually isolates each character from the text based on the space between them. This allows the program to process each character and recognize that a grouping of characters makes up a word. After the characters are identified, the bounding boxes are drawn around the character and identified with the coordinates. This will help in precisely locating the text in the given PDF.
The last stage is the trickiest one. Once the OCR program knows what constitutes a character that it must recognize, it’s time to figure out its character to assign the corresponding metadata to it. Simple OCR software backchecks the characters with standard fonts from a library to recognize if they match, and the data can be assigned. However, more sophisticated techniques are required for the text that doesn’t match any recognizable fonts in a library, such as uncommon fonts or handwritten text.
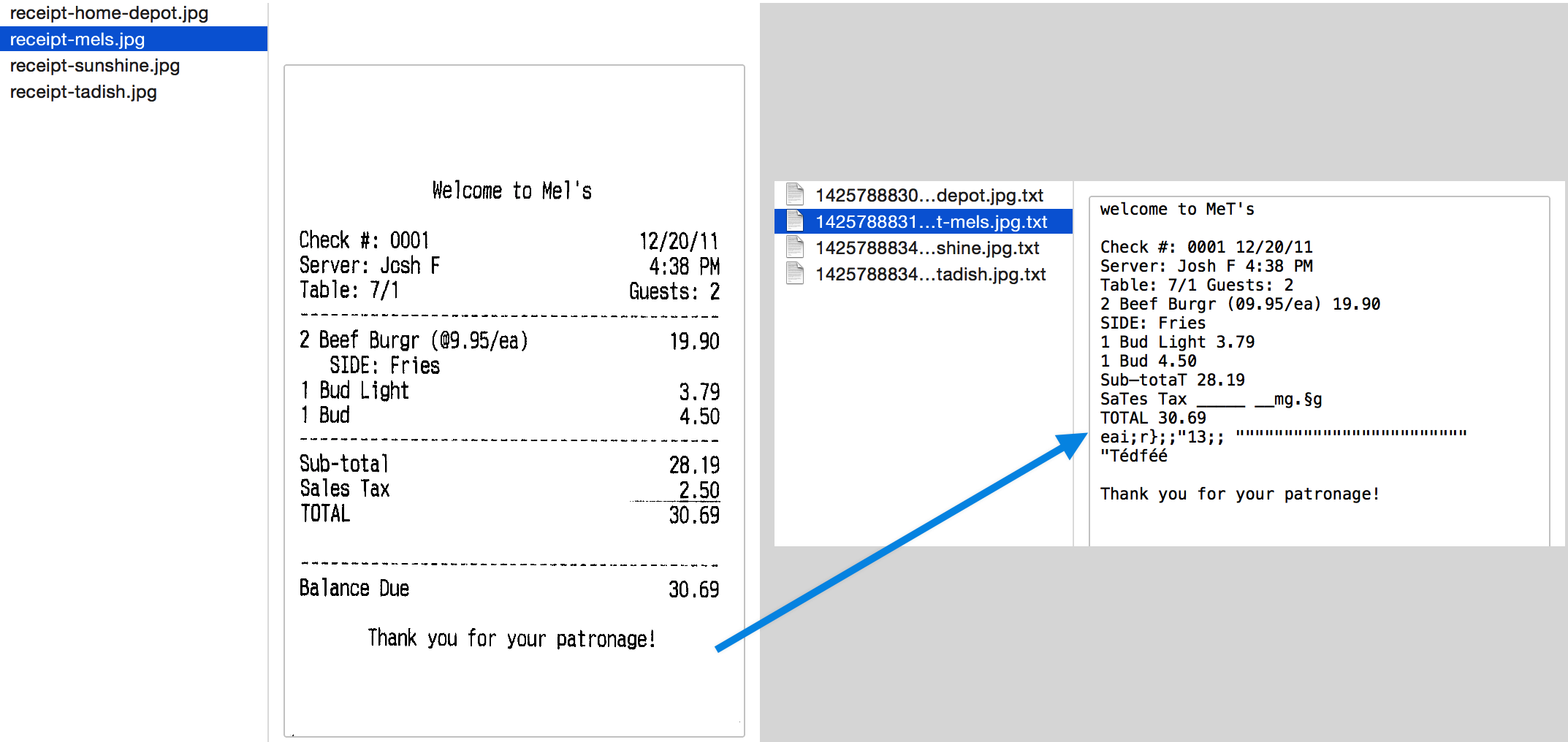
Now we’ll look at an example using py-tesseract that can perform OCR on PDF data.
Py-tesseract is one of the most popular open-source tools that is used to perform OCR. It’s developed from and maintained by folks from Google. Today, Tesseract is one of the highly accurate OCR tools that’s available in multiple languages. However, to use Tesseract OCR on PDF documents, we will need to perform some pre-processing steps. Firstly, we’ll need to convert the page content of PDF into an image and then pass it into the tesseract framework.
Following is the Python code showing the same.
Step1: Import necessary libraries
We’ll be using three libraries, PIL, pytesseract and pdf2image. Here, using pdf2image we first convert the contents of PDF into images and load it into tesseract using PIL.
from PIL import Image
import pytesseract
import sys
from pdf2image import convert_from_path
import osStep2: Load the PDF and convert images into JPEG files
In this step, we’ll be loading the PDF file into a variable and reading all the pages using the convert_from_path function. Next, we iterate on every page and export it into a JPEG image.
PDF_file = "d.pdf"
pages = convert_from_path(PDF_file, 500)
image_counter = 1
for page in pages:
filename = "page_"+str(image_counter)+".jpg"
page.save(filename, 'JPEG')
image_counter = image_counter + 1
filelimit = image_counter-1Step 3: Reading the images using Tesseract
In the last step, we create a new text file to store all the scanned data from PDF. Here, we iterate on every Image using the image name and load it using the Image.open() method from PIL. Next, we convert the image into text using the image_to_string function from pytesseract. Lastly, we export the extracted text into the created text file.
outfile = "out_text.txt"
f = open(outfile, "a")
# Iterate from 1 to total number of pages
for i in range(1, filelimit + 1):
filename = "page_"+str(i)+".jpg"
text = str(((pytesseract.image_to_string(Image.open(filename)))))
text = text.replace('-\n', '')
f.write(text)
f.close()In this way, we’ll be using OCR to scan PDFs that are non-electronically generated documents. However, this is a straightforward process. In some cases, there might be complex tables, templates where OCR may not perform well. To solve this, we’ll need to use complex algorithms such as named entity recognition or CNNs to extract particular regions to scan PDFs. In the next section, let’s look at a workflow to build an ideal PDF document scanner with OCR and deep learning techniques.
Looking for a PDF OCR Scanner to extract information from PDFs? Give Nanonets™ a spin for higher accuracy, greater flexibility, post-processing, and a broad set of integrations!
Workflows for Scanning PDFs with OCR
Building a state-of-the-art PDF document requires expertise in computer vision and deep learning. However, in this section, we'll look at some steps that'll help you get started on building an ideal PDF document scanner.
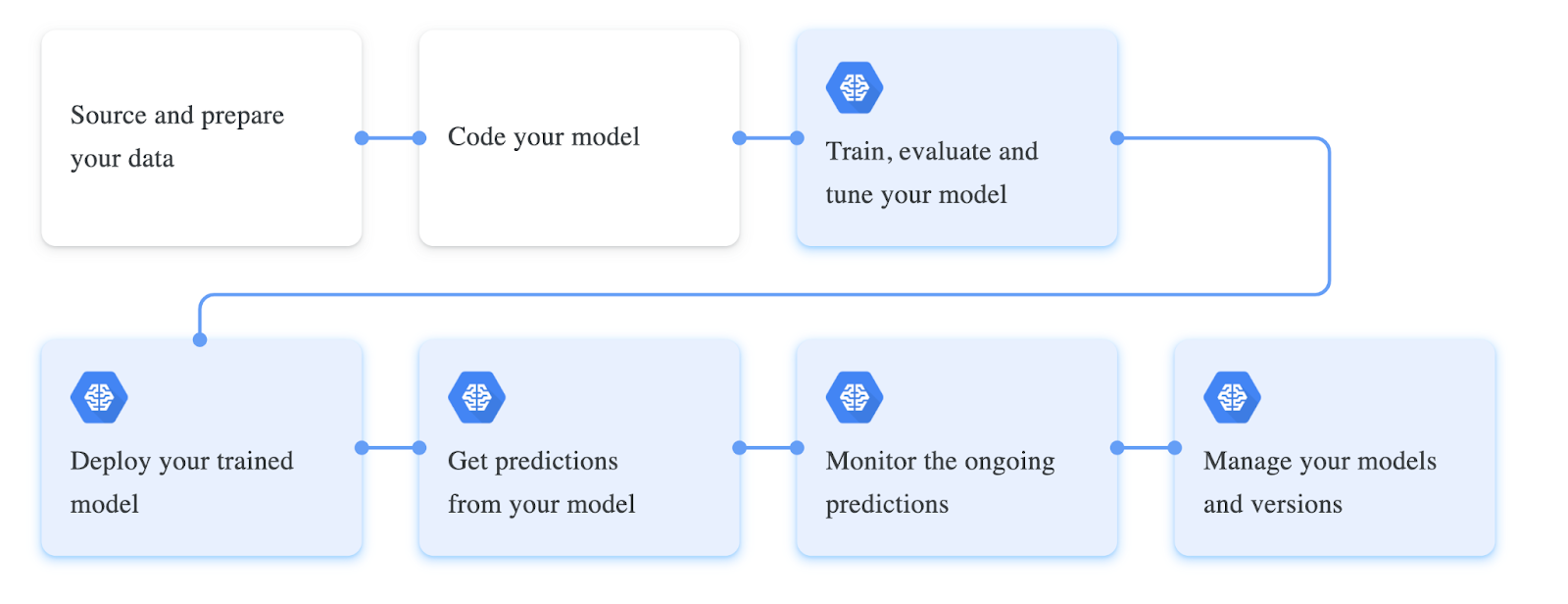
Let’s dive right into it!
Data Curation and Pre-Processing: Data is usually curated from various sources, say emails, downloads, cloud storage, storage disks, messages, and many more. It's essential to bring everything (PDFs of different templates, formats, fonts, etc.) into one place as it'll help the PDF document scanner be robust across all the documents. After the data is curated, we'll need to store all the PDFs in a particular naming format. It would be easy for us to train this data using a deep learning algorithm with respective annotations. Lastly, we'll need to convert PDFs' contents into images to load them into the algorithm.
Data Loading: After the images are curated, the next step is to annotate particular regions of images you need to extract. For example, say you're using invoices, we can pick all the crucial entities such as invoice_id, invoice_total, tables, etc. This process is usually done with an annotation tool. After the data is annotated, we'll be loading the data into a specific format. Additionally, we'll also perform additional processing such as cropping images, enhancing them, and normalizing for a deep learning algorithm to be more accurate.
OCR and Deep Learning Model Training: This is the heart of the PDF OCR scanner, here we’ll be training a deep learning model (mostly with CNNs) to understand and extract all the necessary information from the unstructured data. We need not build everything from scratch, and we could either use pre-trained deep learning models/weights or build one on top of it. Here are some of the most popular techniques that are widely used for scanning information and information extraction.
- CUTIE: Learning to Understand Documents with Convolutional Universal Text Information Extractor
- Named Entity Recognition on CoNLL 2003 (English)
- Key Information Extraction From Documents: Evaluation And Generator
- Deep Reader: Information extraction from Document images via relation extraction and Natural Language
If you choose to utilise these models, we’ll need to fine-tune them and also update them based on our datasets. The other way is to utilize the pre-trained models and fine-tuning them based on our data. For Information Extraction from text, in particular, BERT models are widely used.
Looking for a PDF OCR Scanner to extract information from PDFs? Give Nanonets™ a spin for higher accuracy, greater flexibility, post-processing, and a broad set of integrations!
Enter Nanonets™: Cloud-based PDF Scanning Solution
In this section, we’ll look at how Nanonets can help us perform PDF document scanning in a more customizable and easier way.
Nanonets™ is a cloud-based OCR that can help automate your manual data entry using AI. We’ll have a dashboard where we can build/train our OCR models on our own data and export them in the form of JSON/CSV or any desired format. Here are some of the advantages of using Nanonets as a PDF document scanner.
- Custom Rules: We have an option to add custom rules where we can choose particular fields on our documents to extract. For example, if your business documents have 100 fields and you just want to extract around 30 fields, Nanonets™ can help you do that by just selecting the necessary fields on the model. This applies to all the documents.
- Post-processing: On Nanonets™, you can also post-process your data after extraction. For example, if there are any errors in the extracted data, you can write some scripts to clean the extracted data and export it into the desired format.
- Fraud Checks: If there is any financial or confidential data in our documents, Nanonets™ models can also perform fraud checks. It basically looks for edited/blurred text from the scanned documents and notifies the administrators. Duplicate documents or information can also be identified through these models.
- Table Extraction: One decisive advantage of using Nanonets™ as our PDF to JSON converter is that it can also pick out tables for us with the highest accuracy and export the data as nested JSON even for complex tables. Therefore, we need not work on Key-Value Pair extraction and Table extraction separately; everything gets done in one shot.
- Extract from Poorly Scanned Images: Nanonets™ models will be able to extract text from scanned PDFs even if the images are of low-resolution or oriented with a slight angle using powerful deep learning techniques.
Update: Added more info based on queries from readers