I think AI is akin to building a rocket ship. You need a huge engine and a lot of fuel. If you have a large engine and a tiny amount of fuel, you won’t make it to orbit. If you have a tiny engine and a ton of fuel, you can’t even lift off. To build a rocket you need a huge engine and a lot of fuel.The analogy to deep learning is that the rocket engine is the deep learning models and the fuel is the huge amounts of data we can feed to these algorithms.
— Andrew Ng
There has been a recent surge in popularity of Deep Learning, achieving state of the art performance in various tasks like Language Translation, playing Strategy Games and Self Driving Cars requiring millions of data points. One common barrier for using deep learning to solve problems is the amount of data needed to train a model. The requirement of large data arises because of the large number of parameters in the model that machines have to learn.
A few examples of number of parameters in these recent models are:

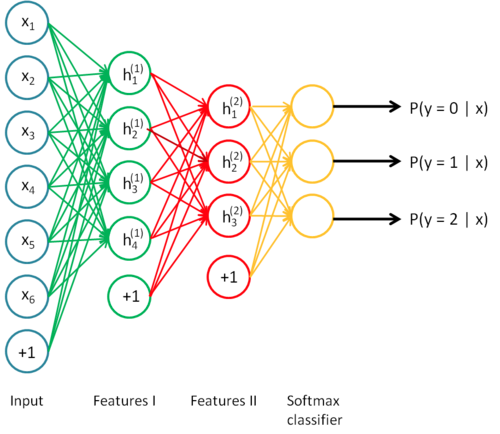
Neural Networks aka Deep Learning are layered structures which can be stacked together (think LEGO)
Deep Learning is nothing but Large Neural networks, they can be thought of as a flow chart where data comes in from one side and inference/knowledge comes out the other. You can also break the neural network, pull it apart and take the inference out from wherever you please. You might get nothing meaningful but you can do it nonetheless eg Google DeepDream
Size(Model) ∝ Size(Data) ∝ Complexity(Problem)
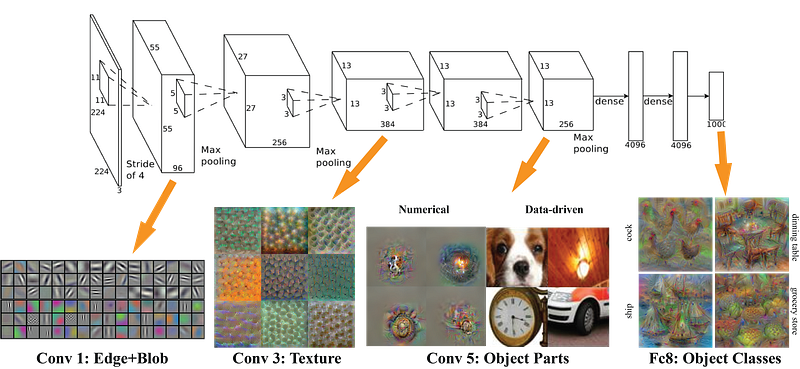
There is an interesting almost linear relationship in the amount of data required and the size of the model. Basic reasoning is that your model should be large enough to capture relations in your data (eg textures and shapes in images, grammar in text and phonemes in speech) along with specifics of your problem (eg number of categories). Early layers of the model capture high level relations between the different parts of the input (like edges and patterns). Later layers capture information that helps make the final decision; usually information that can help discriminate between the desired outputs. Therefore if the complexity of the problem is high (like Image Classification) the number of parameters and the amount of data required is also very large.
Transfer Learning to the Rescue!
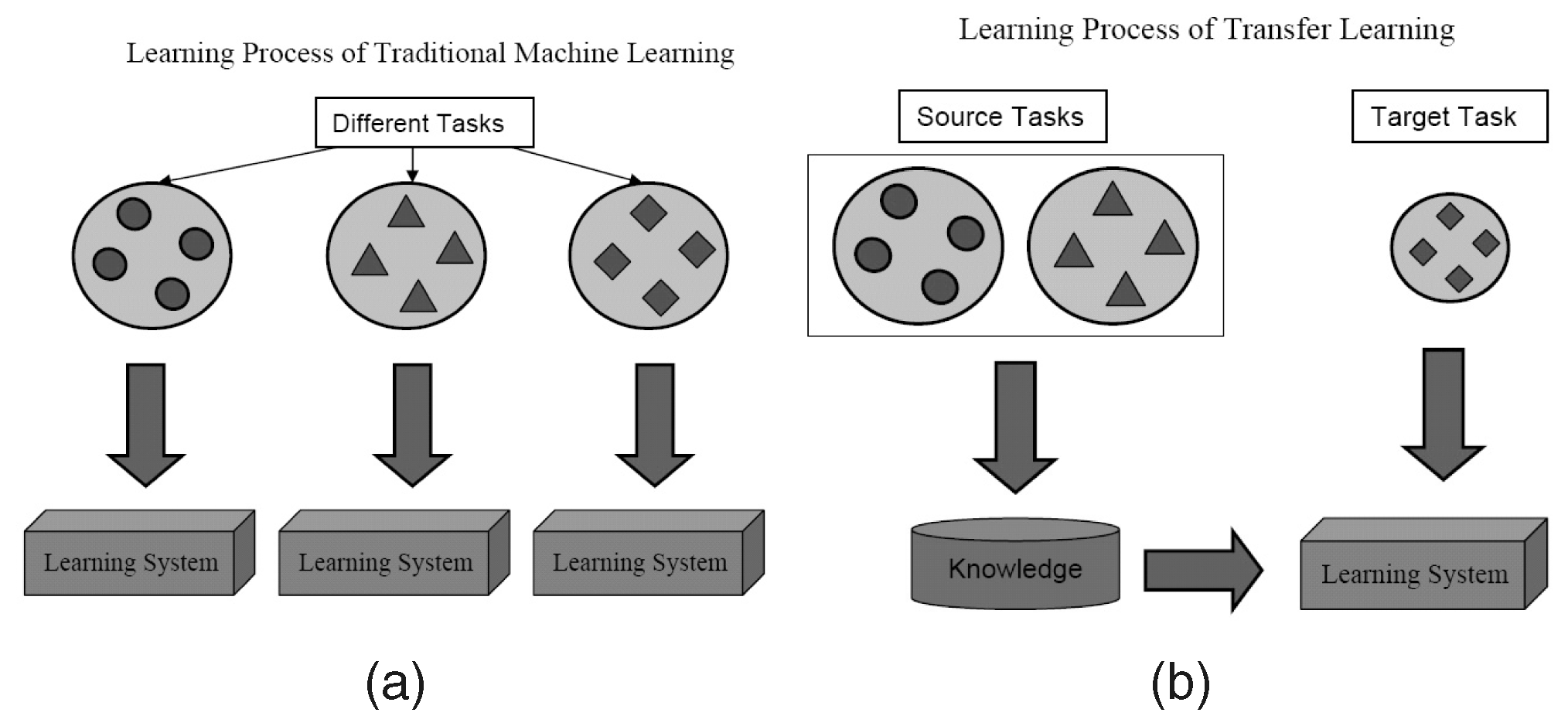
When working on a problem specific to your domain, often the amount of data needed to build models of this size is impossible to find. However models trained on one task capture relations in the data type and can easily be reused for different problems in the same domain. This technique is referred to as Transfer Learning.
Transfer Learning is like the best kept secret that nobody is trying to keep. Everybody in the industry knows about it but nobody outside does.
Referring to Awesome — Most Cited Deep Learning Papers for the top papers in Deep Learning, More than 50% of the papers use some form of Transfer Learning or Pretraining. Transfer Learning becomes more and more applicable for people with limited resources (data and compute) unfortunately the idea has not been socialised nearly enough as it should. The people who need it the most don’t know about it yet.
If Deep Learning is the holy grail and data is the gate keeper, transfer learning is the key.
With transfer learning, we can take a pretrained model, which was trained on a large readily available dataset (trained on a completely different task, with the same input but different output). Then try to find layers which output reusable features. We use the output of that layer as input features to train a much smaller network that requires a smaller number of parameters. This smaller network only needs to learn the relations for your specific problem having already learnt about patterns in the data from the pretrained model.This way a model trained to detect Cats can be reused to Reproduce the work of Van Gogh
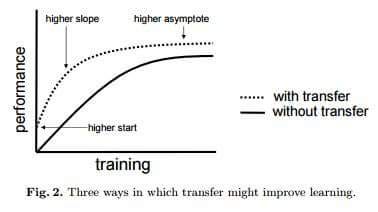
Another major advantage of using transfer learning is how well the model generalizes. Larger models tend to overfit (ie modeling the data more than the underlying phenomenon) the data and don’t work as well when you test it out on unseen data. Since transfer learning allows the model to see different types of data its learning underlying rules of the world better.
Think of overfitting as memorizing as opposed to learning. — James Faghmous
Data Reduction because of Transfer Learning
Let’s say you want to end the debate of blue and black vs. white and gold dress. You start collecting images of verified blue black dresses and white gold dresses. To build an accurate model on your own like the one mentioned above (with 140M parameters!!), to train this model you will need to find 1.2M images which is an impossible task. So you give transfer learning a shot.Calculating the number of parameters needed to train for this problem using transfer learning:
No of parameters = [Size(inputs) + 1] * [Size(outputs) + 1]
No of parameters = [2048+1]*[1+1]
No of parameters = 4098 parameters
We see a reduction in number of parameters from 1.4*10⁸ to 4*10³ which is 5 orders of magnitude. So we should be fine collecting less than hundred images of dresses. Phew!
If your impatient and can’t wait to find out the actual color of the dress, scroll down to the bottom and see how to build the model for dresses yourself.
A step by step guide to Transfer Learning — Using a Toy Example for Sentiment Analysis
In this Toy example we have 72 Movie Reviews
- 62 have no assigned sentiment, these will be used to pretrain the model
- 8 have sentiment assigned to it, these will be use to train the model
- 2 have sentiment assigned to it, these will be used to test the models
Since we only have 8 labelled sentences (sentences that have sentiment associated with them) we first pretrain the model to just predict context. If we trained a model on just the 8 sentences it gives a 50% accuracy (50% is as good as flipping a coin to predict).
To solve this problem we will use transfer learning, first training a model on 62 sentences. We then use a part of the first model and train a sentiment classifier on top of it. Training on the 8 sentences it produces 100% accuracy when testing on the remaining 2.
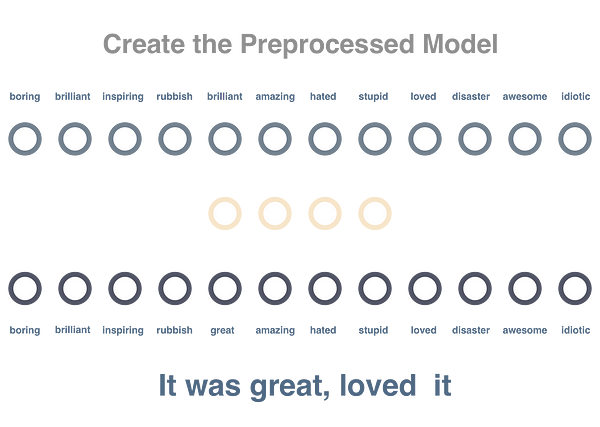
Step 1
We will train a net to model the relationship between words. We pass a word found in a sentence and try to predict the words that occur in the same sentence. Here in code, embedding matrix has size of vocabulary x embedding_size which stores a vector representation of each word (We are using size 4 here).
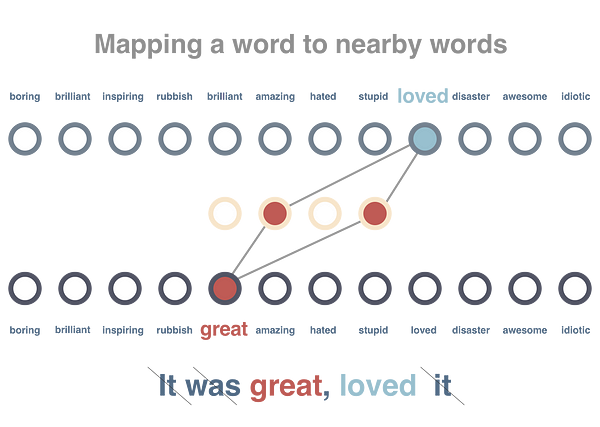
Step 2
We will train this graph such that words occurring in similar context should get similar vector representations. We will preprocess these sentences by removing stop words and tokenizing them. We pass a single word at a time and try to minimize distance of its own vector to surrounding words and increase the distance to a few random words not in its context.
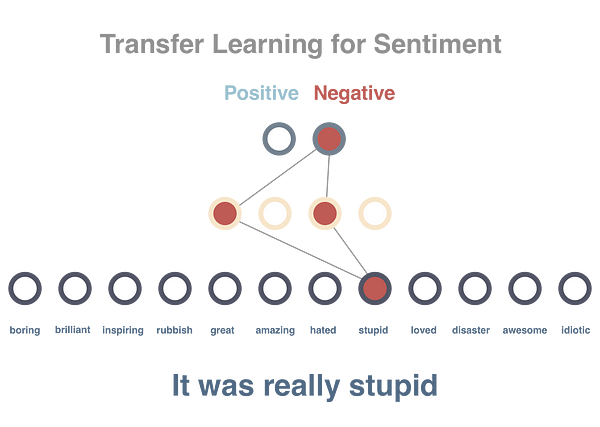
Step 3
Now we will try to predict the sentiment of a sentence. Where we have 10 (8 training + 2 test) sentences labelled positive and negative. Since the previous model already has vectors learned for all the words and the vectors have property of numerically representing context of word this will make predicting sentiment easier.Instead of using sentences directly, we set the vector of the sentence to the average of all out its words (in actually tasks we would use something like an LSTM instead). The sentence vector will be passed as an input and the output will be score of being positive or negative. We will use one hidden layer in between and train model on our labelled sentences. As you can see, only on 10 examples of each, we have achieved 100% test accuracy using this model.
Even though this is a toy example we can see the very significant accuracy improvement going from 50% -> 100 using Transfer Learning. To see the entire example and code check here:
https://gist.github.com/prats226/9fffe8ba08e378e3d027610921c51a78
Some Real Examples of Transfer Learning
In Images:
Image Enhancement, Style Transfer, Object Detection, Skin Cancer Detection.
In Text:
Zero Shot Translation, Sentiment Classification
Difficulty implementing Transfer Learning
Even though it takes less data to build a model it requires significantly more expertise to make it work. If you look at the example above, just count the number of hard coded parameters and imagine having to play around with them till the model worked. This makes actual usage of transfer learning tough.
Some of the issues with transfer learning are listed below:
- Finding a large dataset to pretrain on
- Deciding which model to use for pretraining
- Difficult to debug which of the two models is not working
- Not knowing how much additional data is enough to train the model
- Difficulty in deciding where to stop using the pretrained model
- Deciding the numer of layers and number of parameters in the model used on top of the pretrained model
- Hosting and serving the combined models
- Updating the pretrained model when more data or better techniques becomes available
Finding a data scientist is hard. Finding people who understand who a data scientist is, is equally hard. — Krzysztof Zawadzki
NanoNets make Transfer Learning easier
Having personally experienced these problems we set out to solve them by building an easy to use cloud based Deep Learning service that uses Transfer Learning. It contains a set of pre-trained models that have been trained on millions of parameters. You upload your own data (or search the web for data), it selects the best model to use for your task, creates a new NanoNet on top of the existing pretrained model and fits the NanoNet to your data.
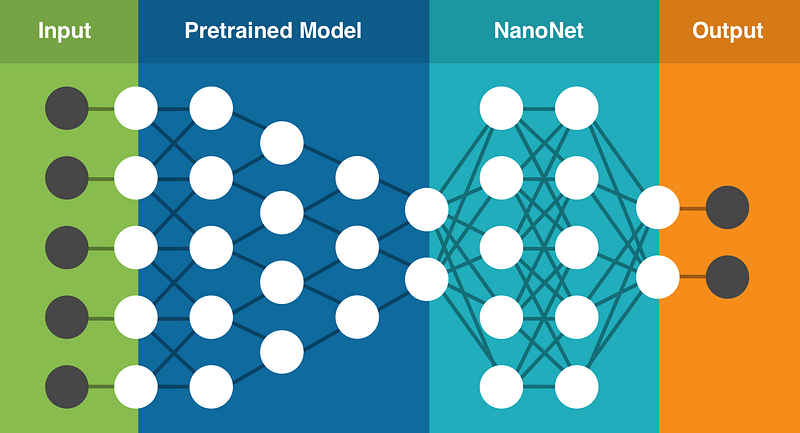
Building your first NanoNet (Image Classification)
- Select the categories you want to work with here
2. With one click we Search the Web and build a model (you can also Upload Your own Images)

3. Solve the Mystery of the Blue vs Gold Dress (Once the model is ready we give you an easy to use web interface to upload a test image as well as a language agnostic API)

Get started building your first NanoNet at nanonets.com
Further Reading
Update:
Added more reading material that covers different approaches used in dealing with limited data when it comes to deep learning.