
Introduction
Retrieval Augmented Generation, or RAG, is a mechanism that helps large language models (LLMs) like GPT become more useful and knowledgeable by pulling in information from a store of useful data, much like fetching a book from a library. Here’s how retrieval augmented generation makes magic with simple AI workflows:
- Knowledge Base (Input): Think of this as a big library full of useful stuff—FAQs, manuals, documents, etc. When a question pops up, this is where the system looks for answers.
- Trigger/Query (Input): This is the starting point. Usually, it's a question or a request from a user that tells the system, “Hey, I need you to do something!”
- Task/Action (Output): Once the system gets the trigger, it swings into action. If it’s a question, it digs up an answer. If it’s a request to do something, it gets that thing done.
Now, let’s break down the retrieval augmented generation mechanism into simple steps:
- Retrieval: First off, when a question or request comes in, RAG scours through the Knowledge Base to find relevant info.
- Augmentation: Next, it takes this info and mixes it up with the original question or request. This is like adding more detail to the basic request to make sure the system understands it fully.
- Generation: Lastly, with all this rich info at hand, it feeds it into a large language model which then crafts a well-informed response or performs the required action.
So, in a nutshell, RAG is like having a smart assistant that first looks up useful info, blends it with the question at hand, and then either gives out a well-rounded answer or performs a task as needed. This way, with RAG, your AI system isn’t just shooting in the dark; it has a solid base of information to work from, making it more reliable and helpful.
What problem do they solve?
Bridging the Knowledge Gap
Generative AI, powered by LLMs, is proficient at spawning text responses based on a colossal amount of data it was trained on. While this training enables the creation of readable and detailed text, the static nature of the training data is a critical limitation. The information within the model becomes outdated over time, and in a dynamic scenario like a corporate chatbot, the absence of real-time or organization-specific data can lead to incorrect or misleading responses. This scenario is detrimental as it undermines the user's trust in the technology, posing a significant challenge especially in customer-centric or mission-critical applications.
Retrieval Augmented Generation
Retrieval Augmented Generation comes to the rescue by melding the generative capabilities of LLMs with real-time, targeted information retrieval, without altering the underlying model. This fusion allows the AI system to provide responses that are not only contextually apt but also based on the most current data. For instance, in a sports league scenario, while an LLM could provide generic information about the sport or teams, RAG empowers the AI to deliver real-time updates about recent games or player injuries by accessing external data sources like databases, news feeds, or even the league's own data repositories.
Data that stays up-to-date
The essence of RAG lies in its ability to augment the LLM with fresh, domain-specific data. The continual updating of the knowledge repository in RAG is a cost-effective way to ensure the generative AI remains current. Moreover, it provides a layer of context that a generalized LLM lacks, thereby enhancing the quality of responses. The ability to identify, correct, or delete incorrect information within the RAG’s knowledge repository further adds to its appeal, ensuring a self-correcting mechanism for more accurate information retrieval.
Examples of RAG Workflows
In the evolving realm of artificial intelligence, Retrieval-Augmented Generation (RAG) is making a substantial impact across various business sectors by significantly enhancing the capabilities of Large Language Models (LLMs). Let us look at a few examples to get a sense of how RAG workflows automate tasks -
- Internal Team Knowledge Retrieval and Sharing:
- Scenario: A multinational corporation with a diversified portfolio of projects often faces challenges in efficiently sharing knowledge and insights across its teams. To alleviate this, the company implements a RAG-augmented platform to streamline internal knowledge retrieval and sharing.
- Workflow:
- Retrieval:
- Example Query: A project manager inquires, "Have we worked on any projects related to renewable energy in the past three years?"
- The RAG mechanism instantly searches through the internal databases, past project reports, and any other relevant repositories to retrieve information regarding the company's involvement in renewable energy projects over the specified period.
- Augmentation:
- The retrieved data includes project titles, key personnel, final deliverables, and the outcomes of each project.
- It may also fetch links to any relevant communications, presentations, or documents that were shared internally during the course of these projects.
- Generation:
- Example Answer: The system generates a comprehensive response:
"Yes, over the past three years, we have engaged in three major renewable energy projects. Project 'Solar Innovations' was led by Sarah Johnson from the Sustainability Team and concluded in December 2021 with the development of a solar-powered charging station prototype. Project 'Wind Energy Efficiency' headed by Mark D'Souza, aimed at enhancing wind turbine efficiency and was completed in June 2022. Lastly, 'Renewable Energy Policy Advocacy' was a cross-departmental initiative which concluded in September 2022, creating a policy proposal for promoting renewable energy adoption within local communities. Relevant documents, reports, and presentations can be accessed through the links provided."
- Example Answer: The system generates a comprehensive response:
- Retrieval:
- Automated Marketing Campaigns:
- Scenario: A digital marketing agency implements RAG to automate the creation and deployment of marketing campaigns based on real-time market trends and consumer behavior.
- Workflow:
- Retrieval: Whenever a new lead comes into the system, the RAG mechanism fetches relevant details of the lead and their organization and triggers the start of the workflow.
- Augmentation: It combines this data with the client’s marketing objectives, brand guidelines, and target demographics.
- Task Execution: The system autonomously designs and deploys a tailored marketing campaign across various digital channels to capitalize on the identified trend, tracking the campaign’s performance in real-time for possible adjustments.
- Legal Research and Case Preparation:
- Scenario: A law firm integrates RAG to expedite legal research and case preparation.
- Workflow:
- Retrieval: On input about a new case, it pulls up relevant legal precedents, statutes, and recent judgements.
- Augmentation: It correlates this data with the case details.
- Generation: The system drafts a preliminary case brief, significantly reducing the time attorneys spend on preliminary research.
- Customer Service Enhancement:
- Scenario: A telecommunications company implements a RAG-augmented chatbot to handle customer queries regarding plan details, billing, and troubleshooting common issues.
- Workflow:
- Retrieval: On receiving a query about a specific plan's data allowance, the system references the latest plans and offers from its database.
- Augmentation: It combines this retrieved information with the customer’s current plan details (from the customer profile) and the original query.
- Generation: The system generates a tailored response, explaining the data allowance differences between the customer’s current plan and the queried plan.
- Inventory Management and Reordering:
- Scenario: An e-commerce company employs a RAG-augmented system to manage inventory and automatically reorder products when stock levels fall below a predetermined threshold.
- Workflow:
- Retrieval: When a product's stock reaches a low level, the system checks the sales history, seasonal demand fluctuations, and current market trends from its database.
- Augmentation: Combining the retrieved data with the product's reorder frequency, lead times, and supplier details, it determines the optimal quantity to reorder.
- Task Execution: The system then interfaces with the company's procurement software to automatically place a purchase order with the supplier, ensuring that the e-commerce platform never runs out of popular products.
- Employee Onboarding and IT Setup:
- Scenario: A multinational corporation uses a RAG-powered system to streamline the onboarding process for new employees, ensuring that all IT requirements are set up before the employee's first day.
- Workflow:
- Retrieval: Upon receiving details of a new hire, the system consults the HR database to determine the employee's role, department, and location.
- Augmentation: It correlates this information with the company's IT policies, determining the software, hardware, and access permissions the new employee will need.
- Task Execution: The system then communicates with the IT department's ticketing system, automatically generating tickets to set up a new workstation, install necessary software, and grant appropriate system access. This ensures that when the new employee starts, their workstation is ready, and they can immediately dive into their responsibilities.
These examples underscore the versatility and practical benefits of employing retrieval augmented generation in addressing complex, real-time business challenges across a myriad of domains.
Automate manual tasks and workflows with our AI-driven workflow builder, designed by Nanonets for you and your teams.
How to build your own RAG Workflows?
Process of Building an RAG Workflow
The process of building a Retrieval Augmented Generation (RAG) workflow can be broken down into several key steps. These steps can be categorized into three main processes: ingestion, retrieval, and generation, as well as some additional preparation:
1. Preparation:
- Knowledge Base Preparation: Prepare a data repository or a knowledge base by ingesting data from various sources - apps, documents, databases. This data should be formatted to allow efficient searchability, which basically means that this data should be formatted into a unified 'Document' object representation.
2. Ingestion Process:
- Vector Database Setup: Utilize Vector Databases as knowledge bases, employing various indexing algorithms to organize high-dimensional vectors, enabling fast and robust querying ability.
- Data Extraction: Extract data from these documents.
- Data Chunking: Break down documents into chunks of data sections.
- Data Embedding: Transform these chunks into embeddings using an embeddings model like the one provided by OpenAI.
- Develop a mechanism to ingest your user query. This can be a user interface or an API-based workflow.
3. Retrieval Process:
- Query Embedding: Get the data embedding for the user query.
- Chunk Retrieval: Perform a hybrid search to find the most relevant stored chunks in the Vector Database based on the query embedding.
- Content Pulling: Pull the most relevant content from your knowledge base into your prompt as context.
4. Generation Process:
- Prompt Generation: Combine the retrieved information with the original query to form a prompt. Now, you can perform -
- Response Generation: Send the combined prompt text to the LLM (Large Language Model) to generate a well-informed response.
- Task Execution: Send the combined prompt text to your LLM data agent which will infer the correct task to perform based on your query and perform it. For example, you can create a Gmail data agent and then prompt it to "send promotional emails to recent Hubspot leads" and the data agent will -
- fetch recent leads from Hubspot.
- use your knowledge base to get relevant info regarding leads. Your knowledge base can ingest data from multiple data sources - LinkedIn, Lead Enrichment APIs, and so on.
- curate personalized promotional emails for each lead.
- send these emails using your email provider / email campaign manager.
5. Configuration and Optimization:
- Customization: Customize the workflow to fit specific requirements, which might include adjusting the ingestion flow, such as preprocessing, chunking, and selecting the embedding model.
- Optimization: Implement optimization strategies to improve the quality of retrieval and reduce the token count to process, which could lead to performance and cost optimization at scale.
Implementing One Yourself
Implementing a Retrieval Augmented Generation (RAG) workflow is a complex task that involves numerous steps and a good understanding of the underlying algorithms and systems. Below are the highlighted challenges and steps to overcome them for those looking to implement a RAG workflow:
Challenges in building your own RAG workflow:
- Novelty and Lack of Established Practices: RAG is a relatively new technology, first proposed in 2020, and developers are still figuring out the best practices for implementing its information retrieval mechanisms in generative AI.
- Cost: Implementing RAG will be more expensive than using a Large Language Model (LLM) alone. However, it's less costly than frequently retraining the LLM.
- Data Structuring: Determining how to best model structured and unstructured data within the knowledge library and vector database is a key challenge.
- Incremental Data Feeding: Developing processes for incrementally feeding data into the RAG system is crucial.
- Handling Inaccuracies: Putting processes in place to handle reports of inaccuracies and to correct or delete those information sources in the RAG system is necessary.
Automate manual tasks and workflows with our AI-driven workflow builder, designed by Nanonets for you and your teams.
How to get started with creating your own RAG Workflow:
Implementing a RAG workflow requires a blend of technical knowledge, the right tools, and continuous learning and optimization to ensure its effectiveness and efficiency in meeting your objectives. For those looking to implement RAG workflows themselves, we have curated a list of comprehensive hands-on guides that walk you through the implementation processes in detail -
- Nanonets tutorial on building RAG workflows using Llamaindex.
- Medium tutorial on building a chatbot with GPT and LLMs.
- Introducting Llamaindex Data Agents.
- Scalable RAG applications on GCP with Serverless architecture.
- AWS tutorial on deploying tool-using LLM agents using AWS SageMaker.
- Streamlit tutorial on building a chatbot with custom data sources.
- LangChain Agents: Simply Explained!
- Building a LangChain Custom Medical Agent with Memory.
Each of the tutorials comes with a unique approach or platform to achieve the desired implementation on the specified topics.
If you are looking to delve into building your own RAG workflows, we recommend checking out all of the articles listed above to get a holistic sense required to get started with your journey.
Implement RAG Workflows using ML Platforms
While the allure of constructing a Retrieval Augmented Generation (RAG) workflow from the ground up offers a certain sense of accomplishment and customization, it's undeniably a complex endeavor. Recognizing the intricacies and challenges, several businesses have stepped forward, offering specialized platforms and services to simplify this process. Leveraging these platforms can not only save valuable time and resources but also ensure that the implementation is based on industry best practices and is optimized for performance.
For organizations or individuals who may not have the bandwidth or expertise to build a RAG system from scratch, these ML platforms present a viable solution. By opting for these platforms, one can:
- Bypass the Technical Complexities: Avoid the intricate steps of data structuring, embedding, and retrieval processes. These platforms often come with pre-built solutions and frameworks tailored for RAG workflows.
- Leverage Expertise: Benefit from the expertise of professionals who have a deep understanding of RAG systems and have already addressed many of the challenges associated with its implementation.
- Scalability: These platforms are often designed with scalability in mind, ensuring that as your data grows or your requirements change, the system can adapt without a complete overhaul.
- Cost-Effectiveness: While there's an associated cost with using a platform, it might prove to be more cost-effective in the long run, especially when considering the costs of troubleshooting, optimization, and potential re-implementations.
Let us take a look at platforms offering RAG workflow creation capabilities.
Nanonets
Nanonets offers secure AI assistants, chatbots, and RAG workflows powered by your company's data. It enables real-time data synchronization between various data sources, facilitating comprehensive information retrieval for teams. The platform allows the creation of chatbots along with deployment of complex workflows through natural language, powered by Large Language Models (LLMs). It also provides data connectors to read and write data in your apps, and the ability to utilize LLM agents to directly perform actions on external apps.
Nanonets AI Assistant Product Page
AWS Generative AI
AWS offers a variety of services and tools under its Generative AI umbrella to cater to different business needs. It provides access to a wide range of industry-leading foundation models from various providers through Amazon Bedrock. Users can customize these foundation models with their own data to build more personalized and differentiated experiences. AWS emphasizes security and privacy, ensuring data protection when customizing foundation models. It also highlights cost-effective infrastructure for scaling generative AI, with options such as AWS Trainium, AWS Inferentia, and NVIDIA GPUs to achieve the best price performance. Moreover, AWS facilitates the building, training, and deploying of foundation models on Amazon SageMaker, extending the power of foundation models to a user's specific use cases.
AWS Generative AI Product Page
Generative AI on Google Cloud
Google Cloud's Generative AI provides a robust suite of tools for developing AI models, enhancing search, and enabling AI-driven conversations. It excels in sentiment analysis, language processing, speech technologies, and automated document management. Additionally, it can create RAG workflows and LLM agents, catering to diverse business requirements with a multilingual approach, making it a comprehensive solution for various enterprise needs.
Oracle Generative AI
Oracle's Generative AI (OCI Generative AI) is tailored for enterprises, offering superior models combined with excellent data management, AI infrastructure, and business applications. It allows refining models using user's own data without sharing it with large language model providers or other customers, thus ensuring security and privacy. The platform enables the deployment of models on dedicated AI clusters for predictable performance and pricing. OCI Generative AI provides various use cases like text summarization, copy generation, chatbot creation, stylistic conversion, text classification, and data searching, addressing a spectrum of enterprise needs. It processes user's input, which can include natural language, input/output examples, and instructions, to generate, summarize, transform, extract information, or classify text based on user requests, sending back a response in the specified format.
Cloudera
In the realm of Generative AI, Cloudera emerges as a trustworthy ally for enterprises. Their open data lakehouse, accessible on both public and private clouds, is a cornerstone. They offer a gamut of data services aiding the entire data lifecycle journey, from the edge to AI. Their capabilities extend to real-time data streaming, data storage and analysis in open lakehouses, and the deployment and monitoring of machine learning models via the Cloudera Data Platform. Significantly, Cloudera enables the crafting of Retrieval Augmented Generation workflows, melding a powerful combination of retrieval and generation capabilities for enhanced AI applications.
Glean
Glean employs AI to enhance workplace search and knowledge discovery. It leverages vector search and deep learning-based large language models for semantic understanding of queries, continuously improving search relevance. It also offers a Generative AI assistant for answering queries and summarizing information across documents, tickets, and more. The platform provides personalized search results and suggests information based on user activity and trends, besides facilitating easy setup and integration with over 100 connectors to various apps.
Landbot
Landbot offers a suite of tools for creating conversational experiences. It facilitates the generation of leads, customer engagement, and support via chatbots on websites or WhatsApp. Users can design, deploy, and scale chatbots with a no-code builder, and integrate them with popular platforms like Slack and Messenger. It also provides various templates for different use cases like lead generation, customer support, and product promotion
Chatbase
Chatbase provides a platform for customizing ChatGPT to align with a brand’s personality and website appearance. It allows for lead collection, daily conversation summaries, and integration with other tools like Zapier, Slack, and Messenger. The platform is designed to offer a personalized chatbot experience for businesses.
Scale AI
Scale AI addresses the data bottleneck in AI application development by offering fine-tuning and RLHF for adapting foundation models to specific business needs. It integrates or partners with leading AI models, enabling enterprises to incorporate their data for strategic differentiation. Coupled with the ability to create RAG workflows and LLM agents, Scale AI provides a full-stack generative AI platform for accelerated AI application development.
Shakudo - LLM Solutions
Shakudo offers a unified solution for deploying Large Language Models (LLMs), managing vector databases, and establishing robust data pipelines. It streamlines the transition from local demos to production-grade LLM services with real-time monitoring and automated orchestration. The platform supports flexible Generative AI operations, high-throughput vector databases, and provides a variety of specialized LLMOps tools, enhancing the functional richness of existing tech stacks.
Shakundo RAG Workflows Product Page
Each platform/business mentioned has its own set of unique features and capabilities, and could be explored further to understand how they could be leveraged for connecting enterprise data and implementing RAG workflows.
Automate manual tasks and workflows with our AI-driven workflow builder, designed by Nanonets for you and your teams.
Retrieval Augmented Generation with Nanonets
In the realm of augmenting language models to deliver more precise and insightful responses, Retrieval Augmented Generation (RAG) stands as a pivotal mechanism. This intricate process elevates the reliability and usefulness of AI systems, ensuring they aren’t merely operating in an information vacuum and enables you to create smart LLM applications and workflows.
How to do this?
Enter Nanonets Workflows!
Harnessing the Power of Workflow Automation: A Game-Changer for Modern Businesses
In today's fast-paced business environment, workflow automation stands out as a crucial innovation, offering a competitive edge to companies of all sizes. The integration of automated workflows into daily business operations is not just a trend; it's a strategic necessity. In addition to this, the advent of LLMs has opened even more opportunities for automation of manual tasks and processes.
Welcome to Nanonets Workflow Automation, where AI-driven technology empowers you and your team to automate manual tasks and construct efficient workflows in minutes. Utilize natural language to effortlessly create and manage workflows that seamlessly integrate with all your documents, apps, and databases.
Our platform offers not only seamless app integrations for unified workflows but also the ability to build and utilize custom Large Language Models Apps for sophisticated text writing and response posting within your apps. All the while ensuring data security remains our top priority, with strict adherence to GDPR, SOC 2, and HIPAA compliance standards.
To better understand the practical applications of Nanonets workflow automation, let's delve into some real-world examples.
- Automated Customer Support and Engagement Process
- Ticket Creation – Zendesk: The workflow is triggered when a customer submits a new support ticket in Zendesk, indicating they need assistance with a product or service.
- Ticket Update – Zendesk: After the ticket is created, an automated update is immediately logged in Zendesk to indicate that the ticket has been received and is being processed, providing the customer with a ticket number for reference.
- Information Retrieval – Nanonets Browsing: Concurrently, the Nanonets Browsing feature searches through all the knowledge base pages to find relevant information and possible solutions related to the customer's issue.
- Customer History Access – HubSpot: Simultaneously, HubSpot is queried to retrieve the customer's previous interaction records, purchase history, and any past tickets to provide context to the support team.
- Ticket Processing – Nanonets AI: With the relevant information and customer history at hand, Nanonets AI processes the ticket, categorizing the issue and suggesting potential solutions based on similar past cases.
- Notification – Slack: Finally, the responsible support team or individual is notified through Slack with a message containing the ticket details, customer history, and suggested solutions, prompting a swift and informed response.
- Automated Issue Resolution Process
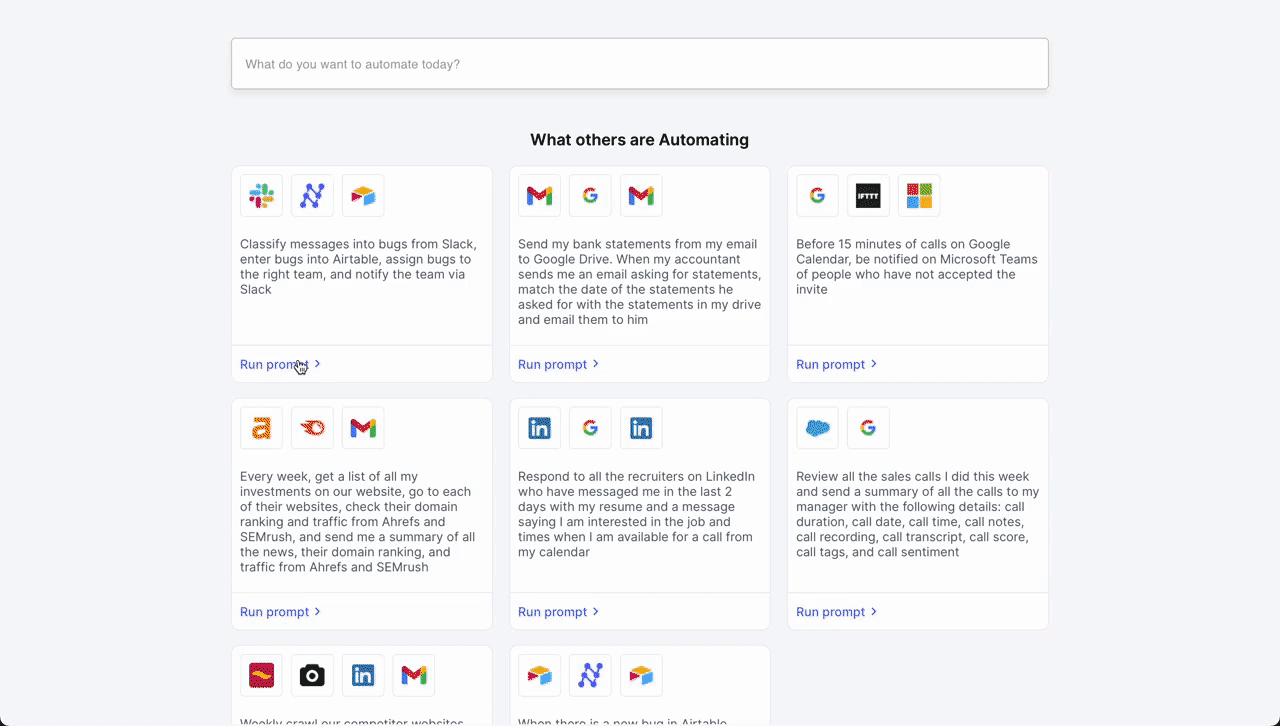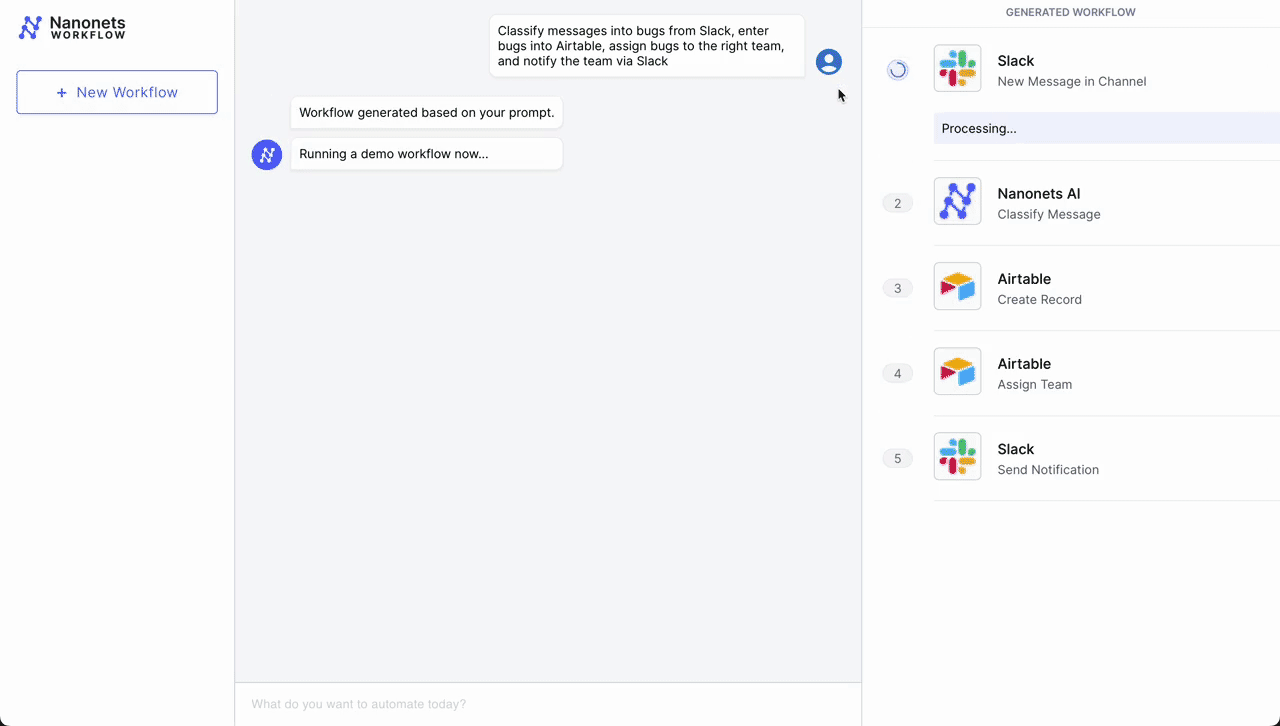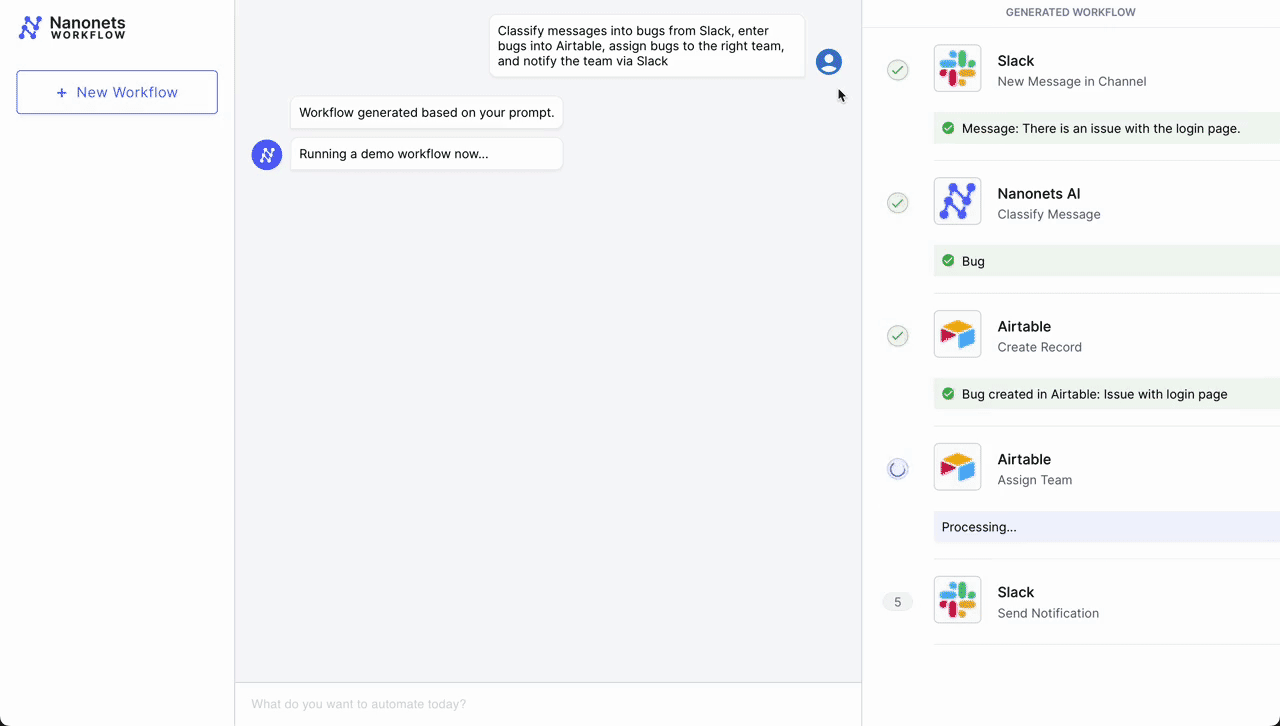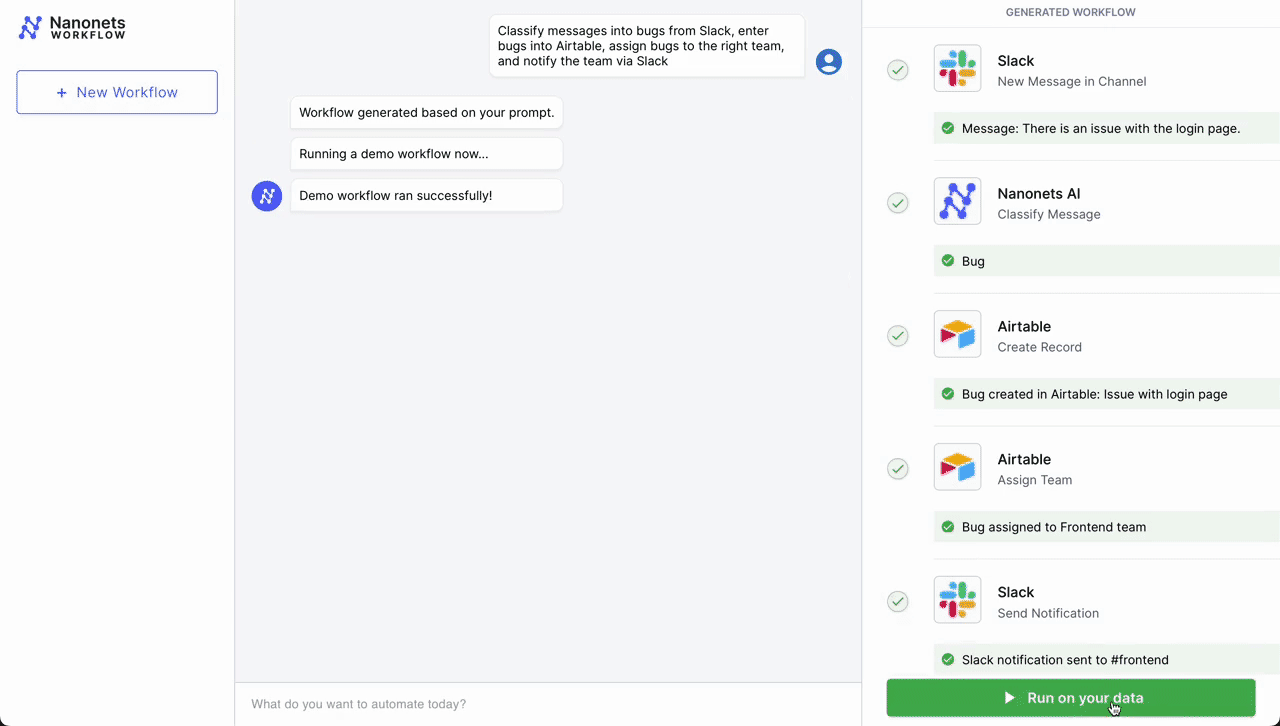
- Initial Trigger – Slack Message: The workflow begins when a customer service representative receives a new message in a dedicated channel on Slack, signaling a customer issue that needs to be addressed.
- Classification – Nanonets AI: Once the message is detected, Nanonets AI steps in to classify the message based on its content and past classification data (from Airtable records). Using LLMs, it classifies it as a bug along with determining urgency.
- Record Creation – Airtable: After classification, the workflow automatically creates a new record in Airtable, a cloud collaboration service. This record includes all relevant details from the customer's message, such as customer ID, issue category, and urgency level.
- Team Assignment – Airtable: With the record created, the Airtable system then assigns a team to handle the issue. Based on the classification done by Nanonets AI, the system selects the most appropriate team – tech support, billing, customer success, etc. – to take over the issue.
- Notification – Slack: Finally, the assigned team is notified through Slack. An automated message is sent to the team's channel, alerting them of the new issue, providing a direct link to the Airtable record, and prompting a timely response.
- Automated Meeting Scheduling Process
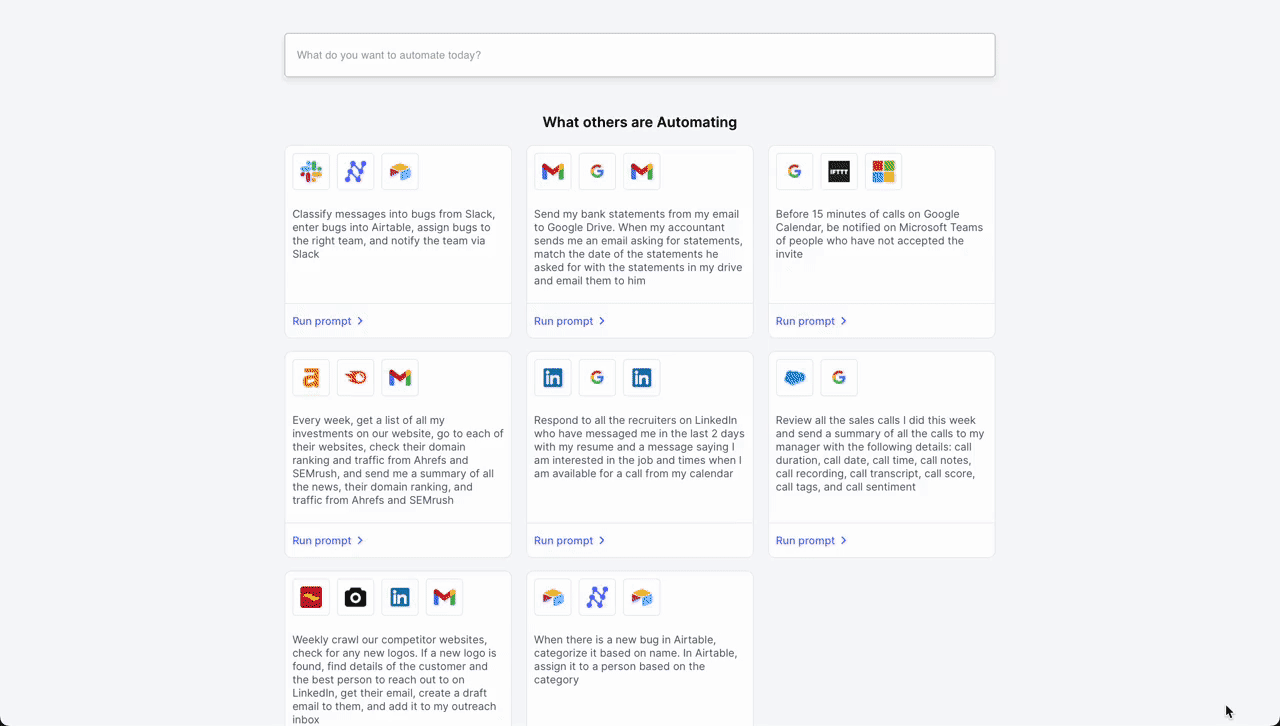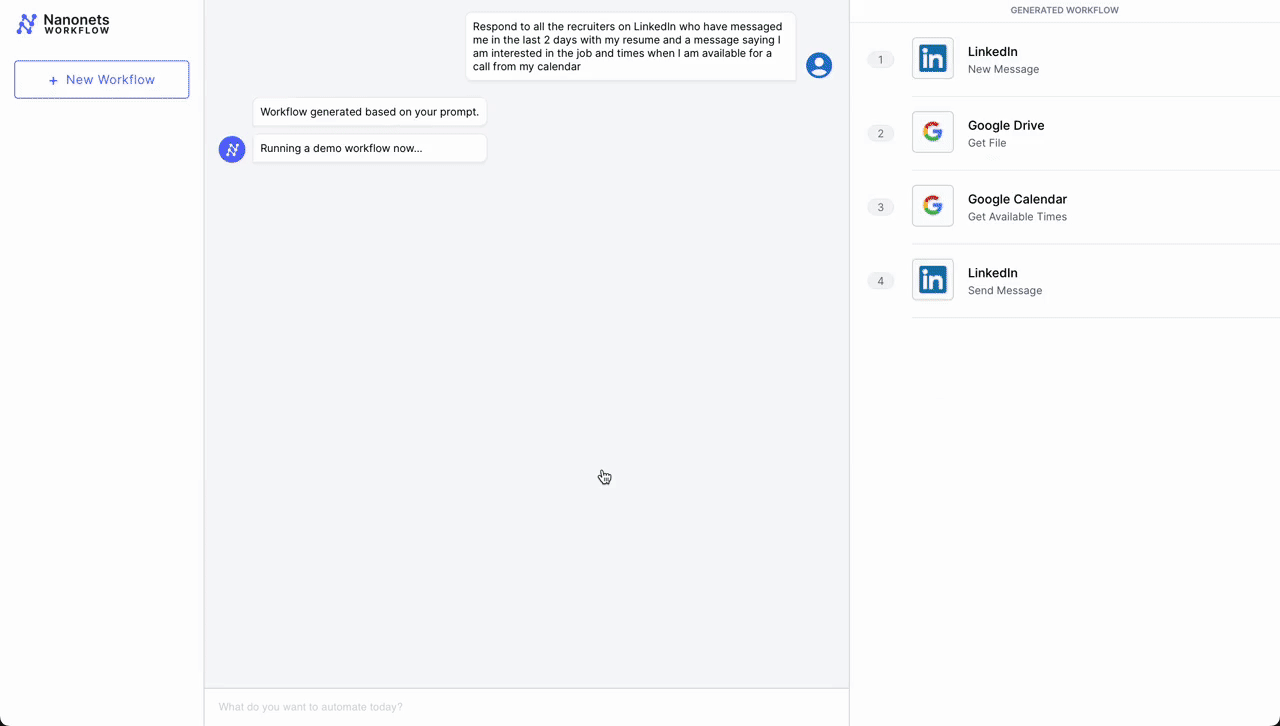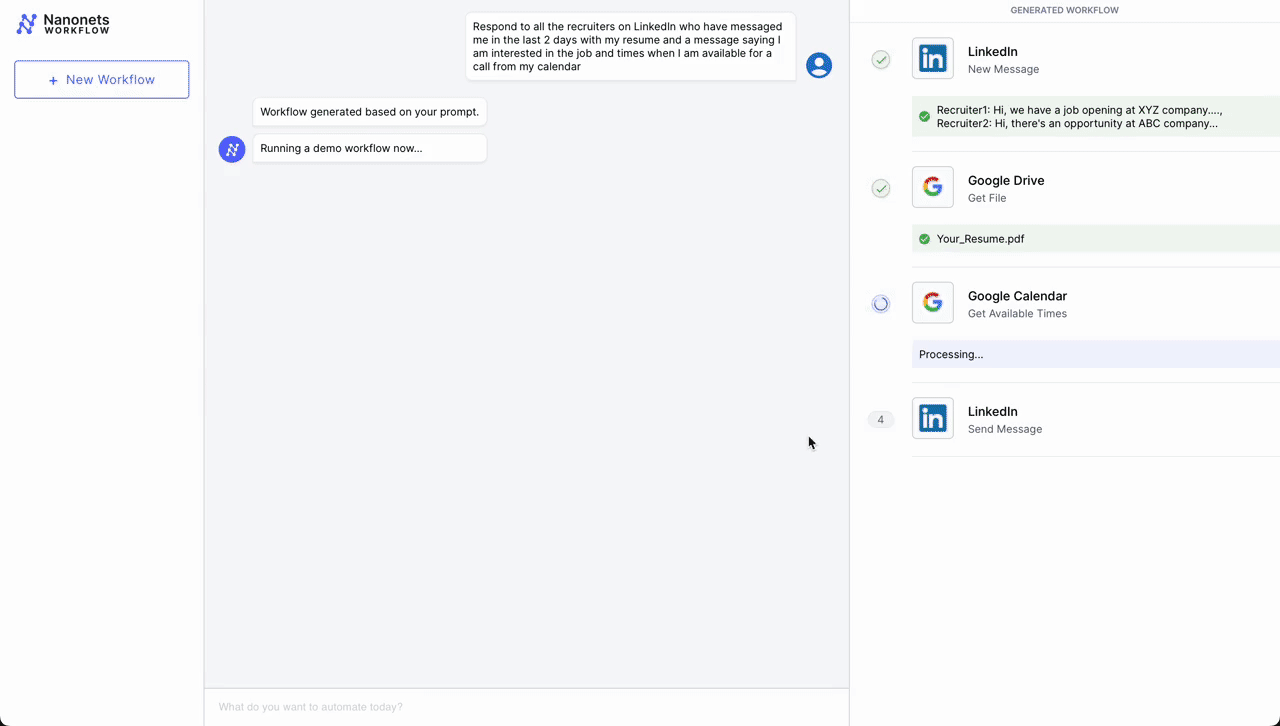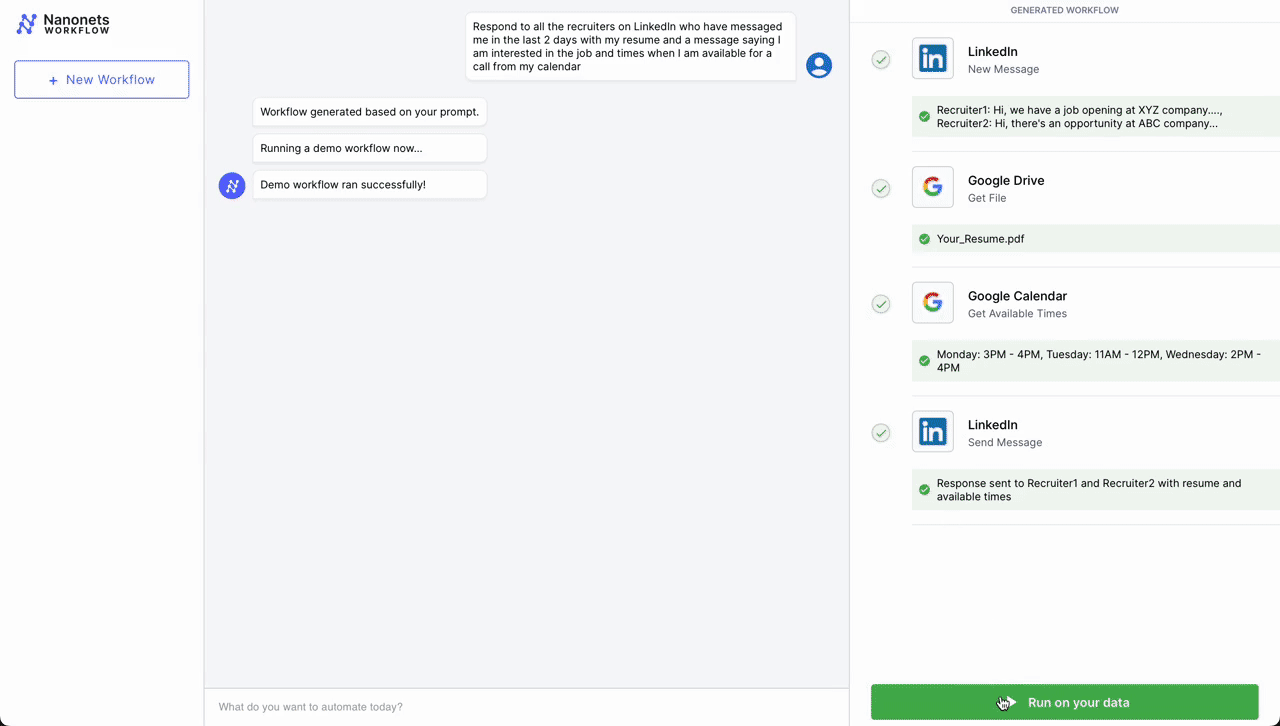
- Initial Contact – LinkedIn: The workflow is initiated when a professional connection sends a new message on LinkedIn expressing interest in scheduling a meeting. An LLM parses incoming messages and triggers the workflow if it deems the message as a request for a meeting from a potential job candidate.
- Document Retrieval – Google Drive: Following the initial contact, the workflow automation system retrieves a pre-prepared document from Google Drive that contains information about the meeting agenda, company overview, or any relevant briefing materials.
- Scheduling – Google Calendar: Next, the system interacts with Google Calendar to get available times for the meeting. It checks the calendar for open slots that align with business hours (based on the location parsed from LinkedIn profile) and previously set preferences for meetings.
- Confirmation Message as Reply – LinkedIn: Once a suitable time slot is found, the workflow automation system sends a message back through LinkedIn. This message includes the proposed time for the meeting, access to the document retrieved from Google Drive, and a request for confirmation or alternative suggestions.
- Invoice Processing in Accounts Payable
- Receipt of Invoice - Gmail: An invoice is received via email or uploaded to the system.
- Data Extraction - Nanonets OCR: The system automatically extracts relevant data (like vendor details, amounts, due dates).
- Data Verification - Quickbooks: The Nanonets workflow verifies the extracted data against purchase orders and receipts.
- Approval Routing - Slack: The invoice is routed to the appropriate manager for approval based on predefined thresholds and rules.
- Payment Processing - Brex: Once approved, the system schedules the payment according to the vendor's terms and updates the finance records.
- Archiving - Quickbooks: The completed transaction is archived for future reference and audit trails.
- Internal Knowledge Base Assistance

- Initial Inquiry – Slack: A team member, Smith, inquires in the #chat-with-data Slack channel about customers experiencing issues with QuickBooks integration.
- Automated Data Aggregation - Nanonets Knowledge Base:
- Ticket Lookup - Zendesk: The Zendesk app in Slack automatically provides a summary of today's tickets, indicating that there are issues with exporting invoice data to QuickBooks for some customers.
- Slack Search - Slack: Simultaneously, the Slack app notifies the channel that team members Patrick and Rachel are actively discussing the resolution of the QuickBooks export bug in another channel, with a fix scheduled to go live at 4 PM.
- Ticket Tracking – JIRA: The JIRA app updates the channel about a ticket created by Emily titled "QuickBooks export failing for QB Desktop integrations," which helps track the status and resolution progress of the issue.
- Reference Documentation – Google Drive: The Drive app mentions the existence of a runbook for fixing bugs related to QuickBooks integrations, which can be referenced to understand the steps for troubleshooting and resolution.
- Ongoing Communication and Resolution Confirmation – Slack: As the conversation progresses, the Slack channel serves as a real-time forum for discussing updates, sharing findings from the runbook, and confirming the deployment of the bug fix. Team members use the channel to collaborate, share insights, and ask follow-up questions to ensure a comprehensive understanding of the issue and its resolution.
- Resolution Documentation and Knowledge Sharing: After the fix is implemented, team members update the internal documentation in Google Drive with new findings and any additional steps taken to resolve the issue. A summary of the incident, resolution, and any lessons learned are already shared in the Slack channel. Thus, the team’s internal knowledge base is automatically enhanced for future use.
The Future of Business Efficiency
Nanonets Workflows is a secure, multi-purpose workflow automation platform that automates your manual tasks and workflows. It offers an easy-to-use user interface, making it accessible for both individuals and organizations.
To get started, you can schedule a call with one of our AI experts, who can provide a personalized demo and trial of Nanonets Workflows tailored to your specific use case.
Once set up, you can use natural language to design and execute complex applications and workflows powered by LLMs, integrating seamlessly with your apps and data.

Supercharge your teams with Nanonets Workflows allowing them to focus on what truly matters.
Automate manual tasks and workflows with our AI-driven workflow builder, designed by Nanonets for you and your teams.