Welcome to our guide of LlamaIndex!
In simple terms, LlamaIndex is a handy tool that acts as a bridge between your custom data and large language models (LLMs) like GPT-4 which are powerful models capable of understanding human-like text. Whether you have data stored in APIs, databases, or in PDFs, LlamaIndex makes it easy to bring that data into conversation with these smart machines. This bridge-building makes your data more accessible and usable, paving the way for creating powerful custom LLM applications and workflows.
While discussing LlamaIndex's power to bridge data and LLMs, it's worth noting how Nanonets takes this further with Workflows Automation. Imagine seamlessly integrating such smart capabilities into your daily operations, where AI assists not only in querying data but in automating repetitive tasks across all your apps and databases. With Nanonets, you can create and enhance workflows within minutes, adding AI-driven insights and even human validation where needed, making your systems more intelligent and efficient. Learn more about revolutionizing your workflows.
Understanding LlamaIndex
Initially known as GPT Index, LlamaIndex has evolved into an indispensable ally for developers. It's like a multi-tool that helps in various stages of working with data and Large Language Models -
- Firstly, it helps in 'ingesting' data, which means getting the data from its original source into the system.
- Secondly, it helps in 'structuring' that data, which means organizing it in a way that the language models can easily understand.
- Thirdly, it aids in 'retrieval', which means finding and fetching the right pieces of data when needed.
- Lastly, it simplifies 'integration', making it easier to meld your data with various application frameworks.
When we dive a little deeper into the mechanics of LlamaIndex, we find three main heroes doing the heavy lifting.
- The 'data connectors' are the diligent gatherers, fetching your data from wherever it resides, be it APIs, PDFs, databases, or external apps like Gmail, Notion, Airtable. For a deeper understanding of how these tools integrate with other systems, see our discussion on LangChain and Data Integration. Additionally, if you're considering different LLMs for tasks like document data extraction, understanding both ease of integration and accuracy is crucial.
- The 'data indexes' are the organized librarians, arranging your data neatly so that it's easily accessible.
- And the 'engines' are the translators (LLMs), making it possible to interact with your data using natural language and ultimately create applications and workflows.
In the next sections, we'll explore how to set up LlamaIndex and start using it to supercharge your applications with the power of large language models.
What's what in LlamaIndex
LlamaIndex is your go-to platform for creating robust applications powered by Large Language Models (LLMs) over your customized data. Be it a sophisticated Q&A system, an interactive chatbot, or intelligent agents, LlamaIndex lays down the foundation for your ventures into the realm of what is Retrieval Augmented Generation (RAG).
RAG mechanism amplifies the prowess of LLMs with the essence of your custom data. Components of an RAG application or workflow -
- Knowledge Base (Input): The knowledge base is like a library filled with useful information such as FAQs, manuals, and other relevant documents. When a question is asked, this is where the system looks to find the answer.
- Trigger/Query (Input): This is the spark that gets things going. Typically, it's a question or request from a customer that signals the system to spring into action.
- Task/Action (Output): After understanding the trigger or query, the system then performs a certain task to address it. For instance, if it's a question, the system will work on providing an answer, or if it's a request for a specific action, it will carry out that action accordingly.
Based on the context of our blog, we will need to implement the following two stages using Llamaindex to provide the two inputs to our RAG mechanism -
- Indexing Stage: Preparing a knowledge base.
- Querying Stage: Harnessing the knowledge base & the LLM to respond to your queries by generating the final output / performing the final task.
Let's take a closer look at these stages under the magnifying lens of LlamaIndex.
The Indexing Stage: Crafting the Knowledge Base
LlamaIndex equips you with a suite of tools to shape your knowledge base:
- Data Connectors: These entities, also known as Readers, ingest data from diverse sources and formats into a unified Document representation.
- Documents / Nodes: A Document is your container for data, whether it springs from a PDF, an API, or a database. A Node, on the other hand, is a snippet of a Document, enriched with metadata and relationships, paving the way for precise retrieval operations.
- Data Indexes: Post ingestion, LlamaIndex assists in arranging the data into a retrievable format. This process involves parsing, embedding, and metadata inference, and ultimately results in the creation of the knowledge base.
The Querying Stage: Engaging with Your Knowledge
In this phase, we fetch relevant context from the knowledge base as per your query, and blend it with the LLM's insights to generate a response or perform a task. (For practical examples of how to leverage LLMs in real-world scenarios, explore our blog on Leveraging LLMs to Streamline and Automate Your Workflows.) This not only provides the LLM with updated relevant knowledge but also prevents LLM hallucination. The core challenge here orbits around retrieval, orchestration, and reasoning across multiple knowledge bases.
LlamaIndex offers modular constructs to help you use it for Q&A, chatbots, or agent-driven applications.
These are the primary elements -
- Query Engines: These are your end-to-end conduits for querying your data, taking a natural language query and returning a response along with the referenced context.
- Chat Engines: They elevate the interaction to a conversational level, allowing back-and-forths with your data.
- Agents: Agents are your automated decision-makers, interacting with the world through a toolkit, and manoeuvring through tasks with a dynamic action plan rather than a fixed logic.
These are few common building blocks of the primary elements present in all of the elements discussed above -
- Retrievers: They dictate the technique of fetching relevant context from the knowledge base against a query. For example, Dense Retrieval against a vector index is a prevalent approach.
- Node Postprocessors: They refine the set of nodes through transformation, filtering, or re-ranking.
- Response Synthesizers: They channel the LLM to generate responses, blending the user query with retrieved text chunks.
As we venture into LlamaIndex now, we'll encounter and learn more about the above elements.
All the code examples discussed and the associated sample files used in the blog are present in this github repository.
 karan-nanonets
karan-nanonetsAutomate manual tasks and workflows with our AI-driven workflow builder, designed by Nanonets for you and your teams.
Installation and Setup
Before exploring the exciting features, let's first install LlamaIndex on your system. If you're familiar with Python, this will be easy. Use this command to install:
pip install llama-index
Then follow either of the two approaches below -
- By default, LlamaIndex uses OpenAI's gpt-3.5-turbo for creating text and text-embedding-ada-002 for fetching and embedding. You need an OpenAI API Key to use these. Get your API key for free by signing up on OpenAI's website. Then set your environment variable with the name OPENAI_API_KEY in your python file.
import os
os.environ["OPENAI_API_KEY"] = "your_api_key"- If you'd rather not use OpenAI, the system will switch to using LlamaCPP and llama2-chat-13B for creating text and BAAI/bge-small-en for fetching and embedding. These all work offline. To set up LlamaCPP, follow its setup guide here. This will need about 11.5GB of memory on both your CPU and GPU. Then, to use local embedding, install this:
pip install sentence-transformers
Creating Llamaindex Documents
Data connectors, also referred to as Readers, are essential components in LlamaIndex that facilitate the ingestion of data from various sources and formats, converting them into a simplified Document representation consisting of text and basic metadata.
LlamaHub is an open-source repository hosting data connectors which can be seamlessly integrated into any LlamaIndex application. All the connectors present here can be used as follows -
from llama_index import download_loader
GoogleDocsReader = download_loader('GoogleDocsReader')
loader = GoogleDocsReader()
documents = loader.load_data(document_ids=[...])For example, the above loader loads data from your Google Docs into Llamaindex Documents.
See the full list of data connectors here -

The variety of data connectors here is pretty exhaustive, some of which include:
- SimpleDirectoryReader: Supports a broad range of file types (.pdf, .jpg, .png, .docx, etc.) from a local file directory.
- NotionPageReader: Ingests data from Notion.
- SlackReader: Imports data from Slack.
- AirtableReader: Imports data from Airtable.
- ApifyActor: Capable of web crawling, scraping, text extraction, and file downloading.
How to find the right data connector?
- Identify the relevant data connector on Llamahub if it's not already present here
For example, let us try this on a couple of data sources.
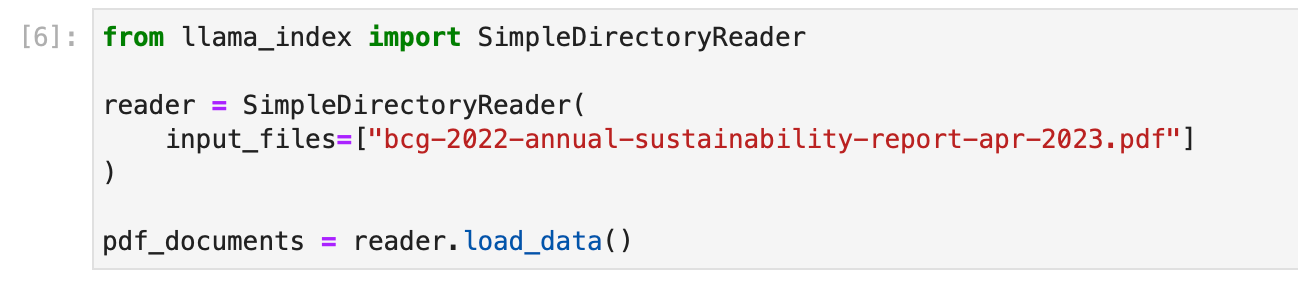
- PDF File : We use the SimpleDirectoryReader data connector for this. The given example below loads a BCG Annual Sustainability Report.
- Wikipedia Page : We search Llamahub and find a relevant connector for this.
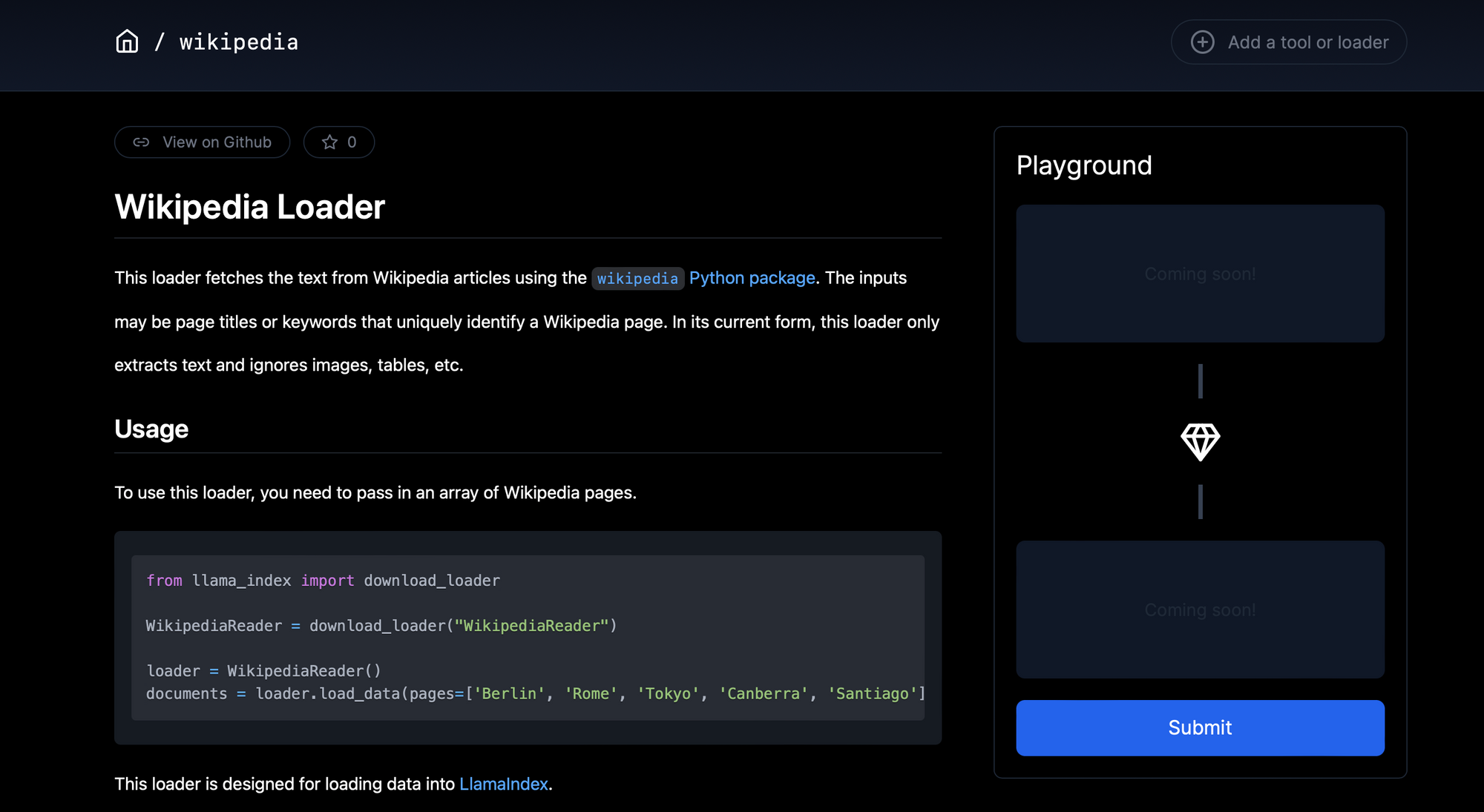
The given example below loads the wikipedia pages about a few countries from around the globe. Basically, the the top page that appears in the search results with each element of the list as a search query is ingested.

Automate manual tasks and workflows with our AI-driven workflow builder, designed by Nanonets for you and your teams.
Creating LlamaIndex Nodes
In LlamaIndex, once the data has been ingested and represented as Documents, there's an option to further process these Documents into Nodes. Nodes are more granular data entities that represent "chunks" of source Documents, which could be text chunks, images, or other types of data. They also carry metadata and relationship information with other nodes, which can be instrumental in building a more structured and relational index.
Basic
To parse Documents into Nodes, LlamaIndex provides NodeParser classes. These classes help in automatically transforming the content of Documents into Nodes, adhering to a specific structure that can be utilized further in index construction and querying.
Here's how you can use a SimpleNodeParser to parse your Documents into Nodes:
from llama_index.node_parser import SimpleNodeParser
# Assuming documents have already been loaded
# Initialize the parser
parser = SimpleNodeParser.from_defaults(chunk_size=1024, chunk_overlap=20)
# Parse documents into nodes
nodes = parser.get_nodes_from_documents(documents)
In this snippet, SimpleNodeParser.from_defaults() initializes a parser with default settings, and get_nodes_from_documents(documents) is used to parse the loaded Documents into Nodes.
Advanced
Various customization options include:
text_splitter(default: TokenTextSplitter)include_metadata(default: True)include_prev_next_rel(default: True)metadata_extractor(default: None)
Text Splitter Customization
Customize text splitter, using either SentenceSplitter, TokenTextSplitter, or CodeSplitter from llama_index.text_splitter. Examples:
SentenceSplitter:
import tiktoken
from llama_index.text_splitter import SentenceSplitter
text_splitter = SentenceSplitter(
separator=" ", chunk_size=1024, chunk_overlap=20,
paragraph_separator="\n\n\n", secondary_chunking_regex="[^,.;。]+[,.;。]?",
tokenizer=tiktoken.encoding_for_model("gpt-3.5-turbo").encode
)
node_parser = SimpleNodeParser.from_defaults(text_splitter=text_splitter)
TokenTextSplitter:
import tiktoken
from llama_index.text_splitter import TokenTextSplitter
text_splitter = TokenTextSplitter(
separator=" ", chunk_size=1024, chunk_overlap=20,
backup_separators=["\n"],
tokenizer=tiktoken.encoding_for_model("gpt-3.5-turbo").encode
)
node_parser = SimpleNodeParser.from_defaults(text_splitter=text_splitter)
CodeSplitter:
from llama_index.text_splitter import CodeSplitter
text_splitter = CodeSplitter(
language="python", chunk_lines=40, chunk_lines_overlap=15, max_chars=1500,
)
node_parser = SimpleNodeParser.from_defaults(text_splitter=text_splitter)
SentenceWindowNodeParser
For specific scope embeddings, utilize SentenceWindowNodeParser to split documents into individual sentences, also capturing surrounding sentence windows.
import nltk
from llama_index.node_parser import SentenceWindowNodeParser
node_parser = SentenceWindowNodeParser.from_defaults(
window_size=3, window_metadata_key="window", original_text_metadata_key="original_sentence"
)
Manual Node Creation
For more control, manually create Node objects and define attributes and relationships:
from llama_index.schema import TextNode, NodeRelationship, RelatedNodeInfo
# Create TextNode objects
node1 = TextNode(text="<text_chunk>", id_="<node_id>")
node2 = TextNode(text="<text_chunk>", id_="<node_id>")
# Define node relationships
node1.relationships[NodeRelationship.NEXT] = RelatedNodeInfo(node_id=node2.node_id)
node2.relationships[NodeRelationship.PREVIOUS] = RelatedNodeInfo(node_id=node1.node_id)
# Gather nodes
nodes = [node1, node2]
In this snippet, TextNode creates nodes with text content while NodeRelationship and RelatedNodeInfo define node relationships.
Let us create basic nodes for the PDF and Wikipedia page documents we have created.

Creating LlamaIndex Index
The core essence of LlamaIndex lies in its ability to build structured indices over ingested data, represented as either Documents or Nodes. This indexing facilitates efficient querying over the data. Let's delve into how to build indices with both Document and Node objects, and what happens under the hood during this process.
- Building Index from Documents
Here's how you can build an index directly from Documents using the VectorStoreIndex:
from llama_index import VectorStoreIndex
# Assuming docs is your list of Document objects
index = VectorStoreIndex.from_documents(docs)
Different types of indices in LlamaIndex handle data in distinct ways:
- Summary Index: Stores Nodes as a sequential chain, and during query time, all Nodes are loaded into the Response Synthesis module if no other query parameters are specified.
- Vector Store Index: Stores each Node and a corresponding embedding in a Vector Store, and queries involve fetching the top-k most similar Nodes.
- Tree Index: Builds a hierarchical tree from a set of Nodes, and queries involve traversing from root nodes down to leaf nodes.
- Keyword Table Index: Extracts keywords from each Node to build a mapping, and queries extract relevant keywords to fetch corresponding Nodes.
To choose your index, you should carefully evaluate the module guides here and make a choice here according to your use case.
Under the Hood:
- The Documents are parsed into Node objects, which are lightweight abstractions over text strings that additionally keep track of metadata and relationships.
- Index-specific computations are performed to add Node into the index data structure. For example:
- For a vector store index, an embedding model is called (either via API or locally) to compute embeddings for the Node objects.
- For a document summary index, an LLM (Language Model) is called to generate a summary.
Let us create an index for the PDF File using the above code.

- Building Index from Nodes
You can also build an index directly from Node objects, following the parsing of Documents into Nodes or manual Node creation:
from llama_index import VectorStoreIndex
# Assuming nodes is your list of Node objects
index = VectorStoreIndex(nodes)
Let us go ahead and create a VectorStoreIndex for the PDF nodes.

Let us now create a summary index for the Wikipedia nodes. We find the relevant index from the list of supported indices, and settle on the Document Summary Index.

We create the index with some customization as follows -
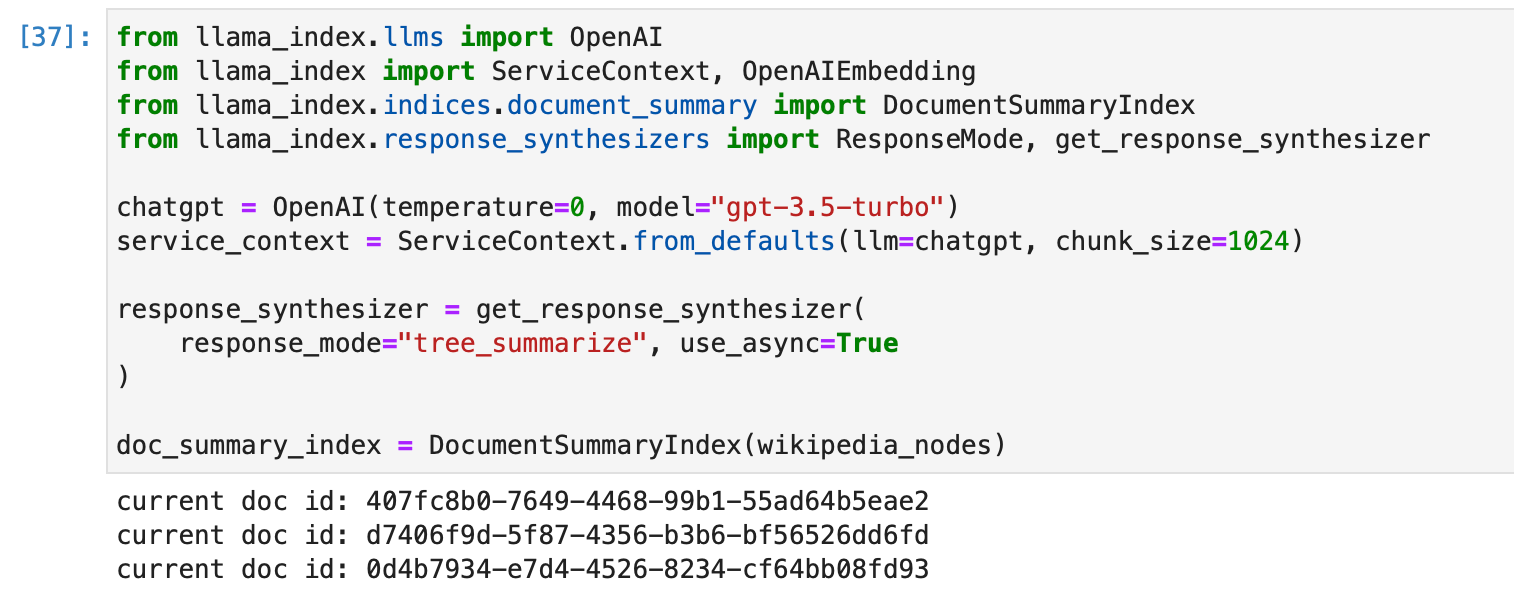
Storing an Index
LlamaIndex's storage capability is built for adaptability, especially when dealing with evolving data sources. This section outlines the functionalities provided for managing data storage, including customization and persistence features.
Persistence (Basic)
There might be instances where you might want to save the index for future use, and LlamaIndex makes this straightforward. With the persist() method, you can store data, and with the load_index_from_storage() method, you can retrieve data effortlessly.
# Persisting to disk
index.storage_context.persist(persist_dir="<persist_dir>")
# Loading from disk
from llama_index import StorageContext, load_index_from_storage
storage_context = StorageContext.from_defaults(persist_dir="<persist_dir>")
index = load_index_from_storage(storage_context)
For example, we can save the PDF index as follows -
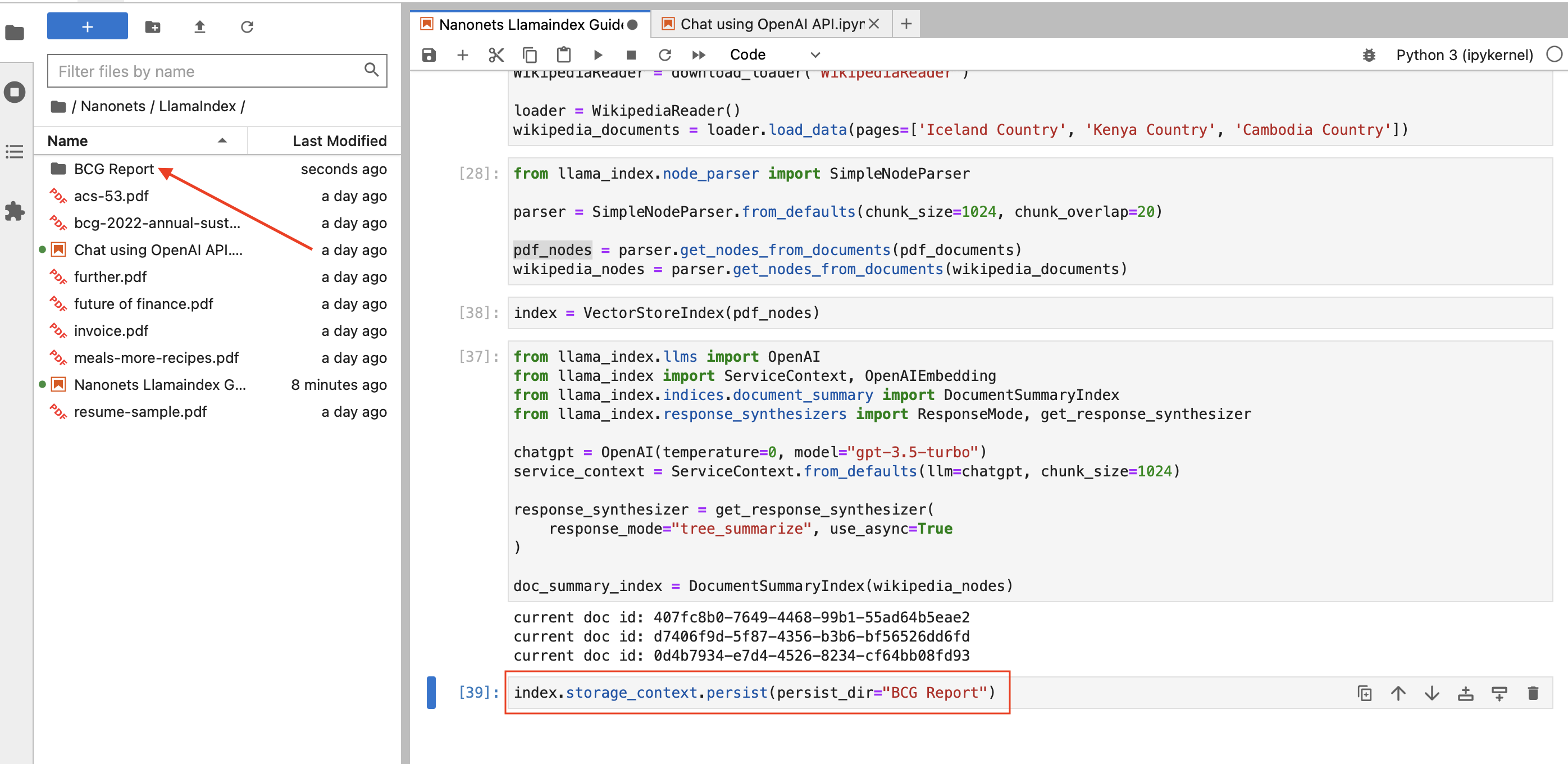
Storage Components (Advanced)
At its core, LlamaIndex provides more customizable storage components enabling users to specify where various data elements are stored. These components include:
- Document Stores: The repositories for storing ingested documents represented as Node objects.
- Index Stores: The places where index metadata are kept.
- Vector Stores: The storages for holding embedding vectors.
LlamaIndex is versatile in its storage backend support, with confirmed support for:
- Local filesystem (as seen in the basic persistence example)
- AWS S3
- Cloudflare R2
These backends are facilitated through the use of the fsspec library, which allows for a variety of storage backends.
For many vector stores, both data and index embeddings are stored together, eliminating the need for separate document or index stores. This arrangement also auto-handles data persistence, simplifying the process of building new indexes or reloading existing ones.
LlamaIndex has integrations with various vector stores that handle the entire index (vectors + text). Check the guide here.
Creating or reloading an index is illustrated below:
# build a new index
from llama_index import VectorStoreIndex, StorageContext
from llama_index.vector_stores import DeepLakeVectorStore
vector_store = DeepLakeVectorStore(dataset_path="<dataset_path>")
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_documents(documents, storage_context=storage_context)
# reload an existing index
index = VectorStoreIndex.from_vector_store(vector_store=vector_store)
To leverage storage abstractions, a StorageContext object needs to be defined, as shown below:
from llama_index.storage.docstore import SimpleDocumentStore
from llama_index.storage.index_store import SimpleIndexStore
from llama_index.vector_stores import SimpleVectorStore
from llama_index.storage import StorageContext
storage_context = StorageContext.from_defaults(
docstore=SimpleDocumentStore(),
vector_store=SimpleVectorStore(),
index_store=SimpleIndexStore(),
)
Learn more about storage and using custom storage elements here.
Using Index to Query Data
After having established a well-structured index using LlamaIndex, the next pivotal step is querying this index to extract meaningful insights or answers to specific inquiries. This segment elucidates the process and methods available for querying the data indexed in LlamaIndex.
Before diving into querying, ensure that you have a well-constructed index as discussed in the previous section. Your index could be built on documents or nodes, and could be a single index or composed of multiple indices.
High-Level Query API
LlamaIndex provides a high-level API that facilitates straightforward querying, ideal for common use cases.
# Assuming 'index' is your constructed index object
query_engine = index.as_query_engine()
response = query_engine.query("your_query")
print(response)
In this simplistic approach, the as_query_engine() method is utilized to create a query engine from your index, and the query() method to execute a query.
We can try this out on our PDF index -

By default, index.as_query_engine() creates a query engine with the specified default settings in LlamaIndex.
You can choose your own query engine based on your use case from the list here and use that to query your index.
For example, let us use a sub question query engine to tackle the problem of answering a complex query using multiple data sources. It first breaks down the complex query into sub questions for each relevant data source, then gather all the intermediate reponses and synthesizes a final response. We will use it on our Wikipedia index.
We will follow the sub question query engine documentation.
Let us import required libraries and set context variable to ensure we can print the subtasks undertaken by the query engine instead of just printing the final response.
import nest_asyncio
from llama_index import VectorStoreIndex, SimpleDirectoryReader
from llama_index.tools import QueryEngineTool, ToolMetadata
from llama_index.query_engine import SubQuestionQueryEngine
from llama_index.callbacks import CallbackManager, LlamaDebugHandler
from llama_index import ServiceContext
nest_asyncio.apply()
# We are using the LlamaDebugHandler to print the trace of the sub questions captured by the SUB_QUESTION callback event type
llama_debug = LlamaDebugHandler(print_trace_on_end=True)
callback_manager = CallbackManager([llama_debug])
service_context = ServiceContext.from_defaults(
callback_manager=callback_manager
)
We first create a basic vector index as instructed by the documentation.
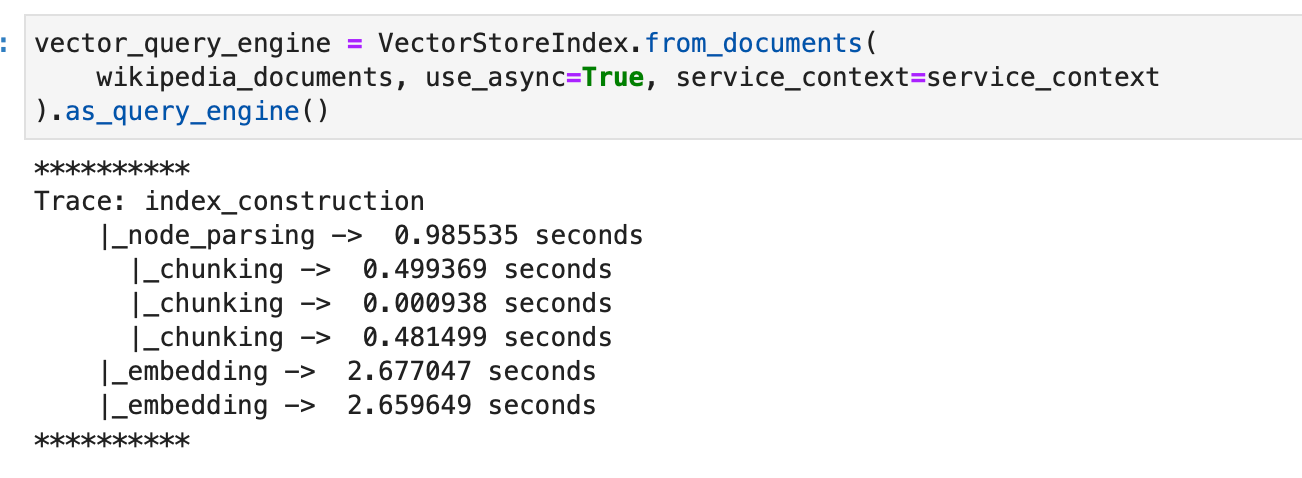
Now we create the sub question query engine.
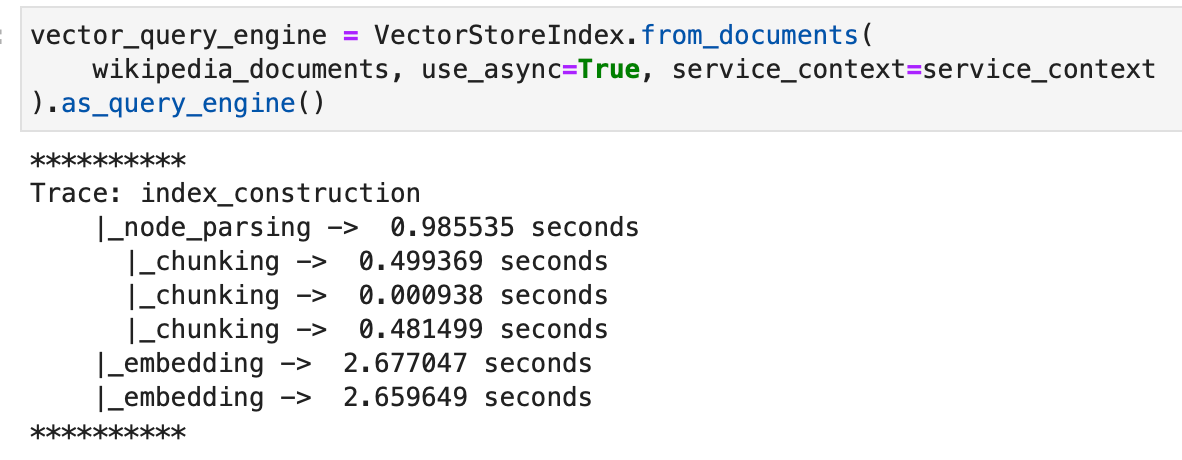
Now, querying and asking for the response traces the subquestions that the query engine internally computed to get to the final response.
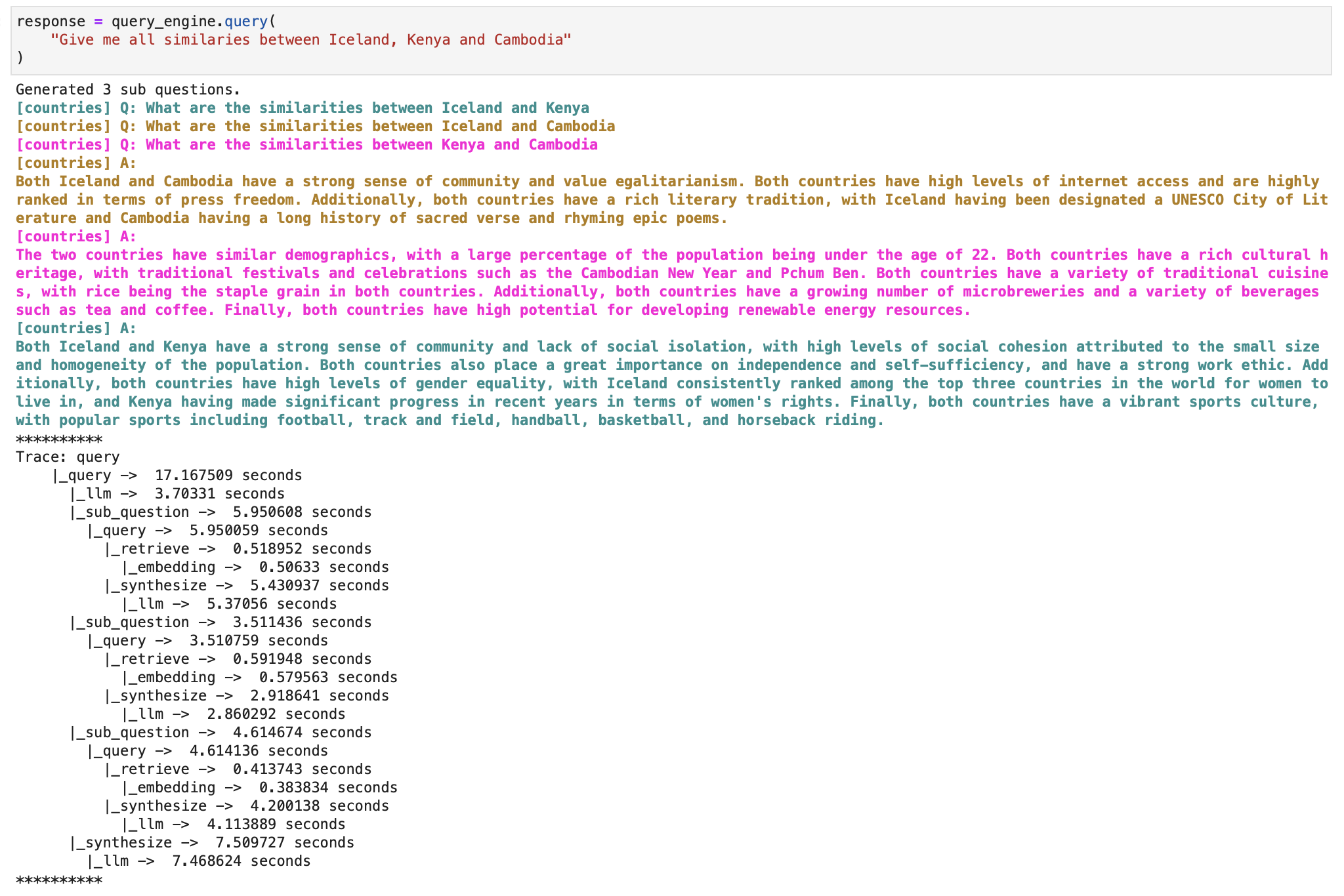
And the final response given by the engine can now be printed.

Automate manual tasks and workflows with our AI-driven workflow builder, designed by Nanonets for you and your teams.
Low-Level Composition API
For more granular control or advanced querying scenarios, the low-level composition API is available. This allows for customization at various stages of the query process.
Right at the start of this blog, we mentioned that there are three supplementary blocks within the query engine / chat engine / agent that can be configured while creating them -
Retrievers
They dictate the technique of fetching relevant context from the knowledge base against a query. For example, Dense Retrieval against a vector index is a prevalent approach.
Choose the right retriever from this list
Node Postprocessors
They refine the set of nodes through transformation, filtering, or re-ranking.
Summary of LlamaIndex Postprocessors:
- SimilarityPostprocessor:
- Removes nodes below a certain similarity score.
- Set threshold using
similarity_cutoff.
- KeywordNodePostprocessor:
- Filters nodes based on keyword inclusion or exclusion.
- Use
required_keywordsandexclude_keywords.
- MetadataReplacementPostProcessor:
- Replaces node content with data from its metadata.
- Works well with
SentenceWindowNodeParser.
- LongContextReorder:
- Addresses models' difficulty with extended contexts. It reorders nodes, which benefits situations where a large number of top results are essential.
- SentenceEmbeddingOptimizer:
- Removes irrelevant sentences based on embeddings.
- Choose either
percentile_cutofforthreshold_cutofffor relevance.
- CohereRerank:
- Uses the Cohere ReRank to reorder nodes, giving back the top N results.
- SentenceTransformerRerank:
- Uses sentence-transformer cross-encoders to reorder nodes, yielding the top N nodes.
- Various models available with different speed/accuracy trade-offs.
- LLMRerank:
- Uses an LLM to reorder nodes, providing a relevance score for each.
- FixedRecencyPostprocessor:
- Returns nodes sorted by date. Requires a date field in node metadata.
- EmbeddingRecencyPostprocessor:
- Ranks nodes by date, but also removes older similar nodes based on embedding similarity.
- TimeWeightedPostprocessor:
- Reranks nodes with a bias towards information not recently returned.
- PIINodePostprocessor (Beta):
- Removes personally identifiable information. Can utilize either a local LLM or a NER model.
- PrevNextNodePostprocessor (Beta):
- Based on node relationships, retrieves nodes that come before, after, or both in sequence.
- AutoPrevNextNodePostprocessor (Beta):
- Similar to the above, but lets the LLM decide the relationship direction.
Note: Many of these postprocessors come with detailed notebook guides for further instructions. Read them here.
Response Synthesizers
They channel the LLM to generate responses, blending the user query with retrieved text chunks.
Response synthesizers might sound fancy, but they're actually tools that help generate a reply or answer based on your question and some given text data. Let's break it down.
Imagine you have a bunch of pieces of text (like a pile of books). Now, you ask a question and want an answer based on those texts. The response synthesizer is like a librarian who goes through the texts, finds relevant information, and crafts a reply for you.
Think of the whole process in the query engine as a factory line:
- First, a machine pulls out relevant text pieces based on your question. We have already discussed this. (Retriever)
- Then, if needed, there's a step that might fine-tune these pieces. We have already discussed this. (Node Postprocessor)
- Finally, the response synthesizer takes these pieces and gives you a neatly crafted answer. (Response Synthesizer)
Response synthesizers come in various styles:
- Refine: This method goes through each text piece, refining the answer bit by bit.
- Compact: A shorter version of 'Refine.' It bunches the texts together, so there are fewer steps to refine.
- Tree Summarize: Imagine taking many small answers, combining them, and summarizing again until you have one main answer.
- Simple Summarize: Just cuts the text pieces to fit and gives a quick summary.
- No Text: This one doesn't give you an answer but tells you which text pieces it would have used.
- Accumulate: Think of this as getting a bunch of mini-answers for each text piece and then sticking them together.
- Compact Accumulate: A mixed bag of 'Compact' and 'Accumulate.'
If you're tech-savvy, you can even build your custom synthesizer. The primary job of any synthesizer is to take a question and some text pieces and give back a string of text as an answer.
Below is a basic structure that every response synthesizer should have. They should be able to take in a question and parts of text and then give back an answer.
class BaseSynthesizer(ABC):
"""Response builder class."""
def __init__(
self,
service_context: Optional[ServiceContext] = None,
streaming: bool = False,
) -> None:
"""Init params."""
self._service_context = service_context or ServiceContext.from_defaults()
self._callback_manager = self._service_context.callback_manager
self._streaming = streaming
@abstractmethod
def get_response(
self,
query_str: str,
text_chunks: Sequence[str],
**response_kwargs: Any,
) -> RESPONSE_TEXT_TYPE:
"""Get response."""
...
@abstractmethod
async def aget_response(
self,
query_str: str,
text_chunks: Sequence[str],
**response_kwargs: Any,
) -> RESPONSE_TEXT_TYPE:
"""Get response asynchronously."""
...
Using a response synthesizer directly (without the other steps we did in previous sections) is also possible and can be as simple as:
from llama_index import get_response_synthesizer
# Set up the synthesizer
my_synthesizer = get_response_synthesizer(response_mode="compact")
# Ask a question
response = my_synthesizer.synthesize("What is the meaning of life?", nodes=[...])
Using it in your index along with your configured retrievers and node postprocessors can be done as follows -
from llama_index import (
VectorStoreIndex,
get_response_synthesizer,
)
from llama_index.retrievers import VectorIndexRetriever
from llama_index.query_engine import RetrieverQueryEngine
from llama_index.indices.postprocessor import SimilarityPostprocessor
# Build index and configure retriever
index = VectorStoreIndex.from_documents(documents)
retriever = VectorIndexRetriever(
index=index,
similarity_top_k=2,
)
# Configure response synthesizer
response_synthesizer = get_response_synthesizer()
# Assemble query engine with postprocessors
query_engine = RetrieverQueryEngine(
retriever=retriever,
response_synthesizer=response_synthesizer,
node_postprocessors=[
SimilarityPostprocessor(similarity_cutoff=0.7)
]
)
# Execute the query
response = query_engine.query("your_query")
print(response)
In the snippet above, the VectorIndexRetriever, RetrieverQueryEngine, and SimilarityPostprocessor are utilized to construct a customized query engine. This example demonstrates a more controlled query process.
Parsing the Response
Post query, a Response object is returned which contains the response text and the sources of the response.
response = query_engine.query("<query_str>")
# Get response
print(str(response))
# Get sources
print(response.source_nodes)
print(response.get_formatted_sources())
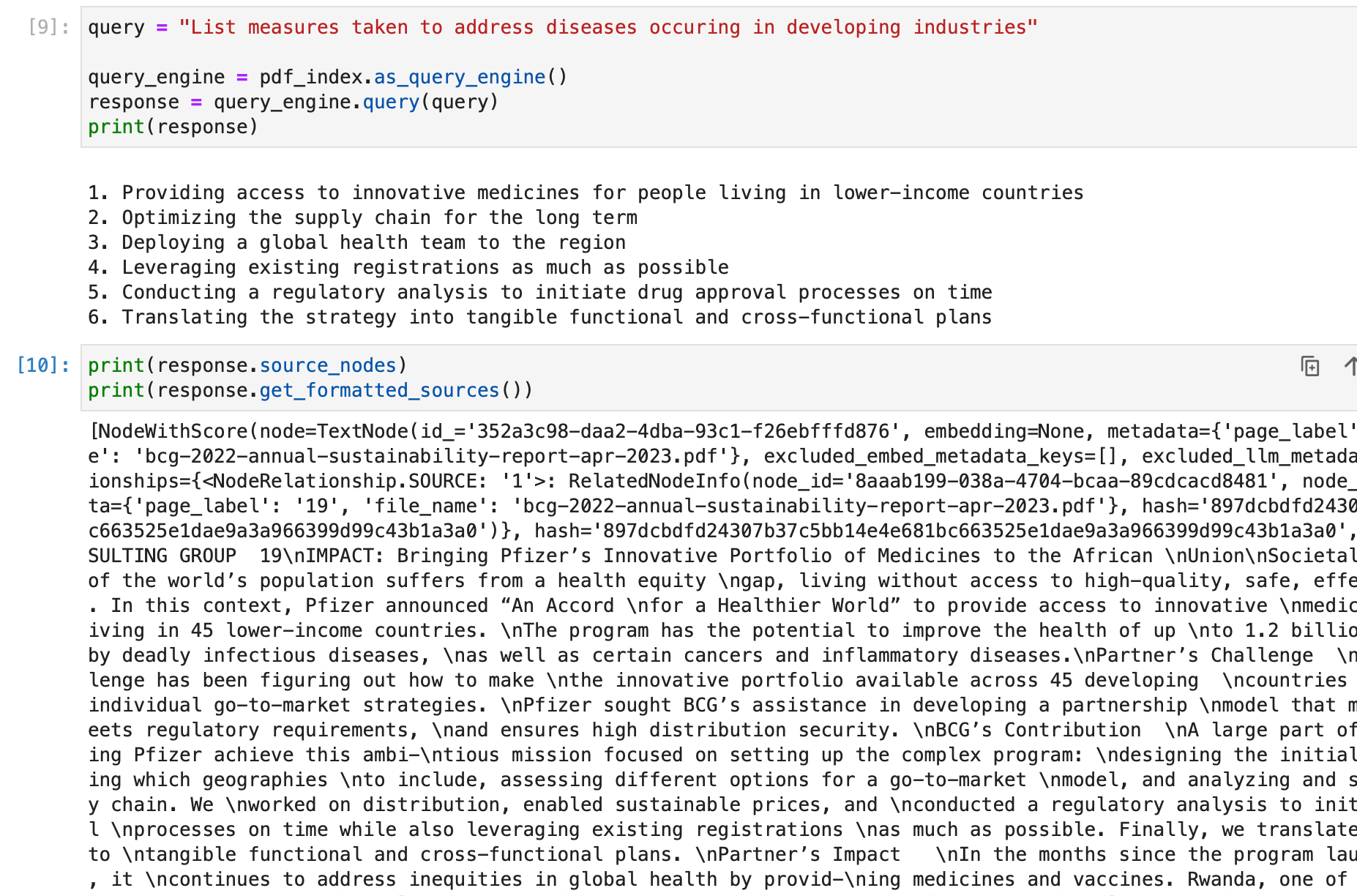
This structure allows for a detailed examination of the query output and the sources contributing to the response.
Structured Outputs
In today's data-driven world, structured data is pivotal for a streamlined workflow. LlamaIndex understands this and taps into the capabilities of Large Language Models (LLMs) to deliver structured results. Let's explore how.
Structured results aren't just a fancy way of presenting data; they are crucial for applications that depend on the precision and fixed structure of parsed values.
LLMs can give structured outputs in two ways:
Method 1 : Pydantic Programs
With function calling APIs, you get a naturally structured result, which then gets molded into the desired format, using Pydantic Programs. These nifty modules convert a prompt into a well-structured output using a Pydantic object. They can either call functions or use text completions along with output parsers. Plus, they gel well with search tools. LlamaIndex also offers ready-to-use Pydantic programs that change certain inputs into specific output types, like data tables.
Let us use the Pydantic Programs documentation to extract structured data about these countries from the unstructured Wikipedia articles.
We create our pydantic output object -

We then create our index using the wikipedia document objects.
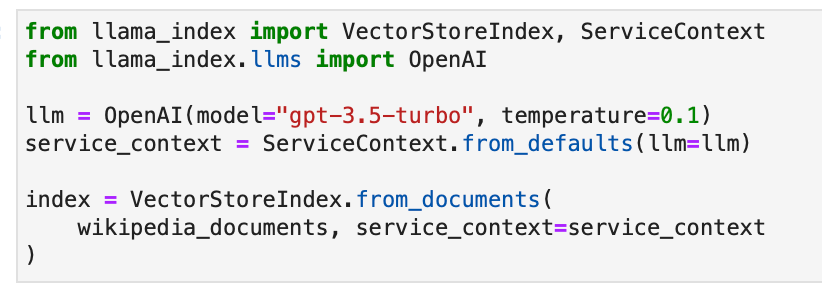
We initiate our query engine and specify the Pydantic output class.

We can now expect structured response from the query engine. Let us retrieve this information for the three countries.

Let us inspect the responses object now.
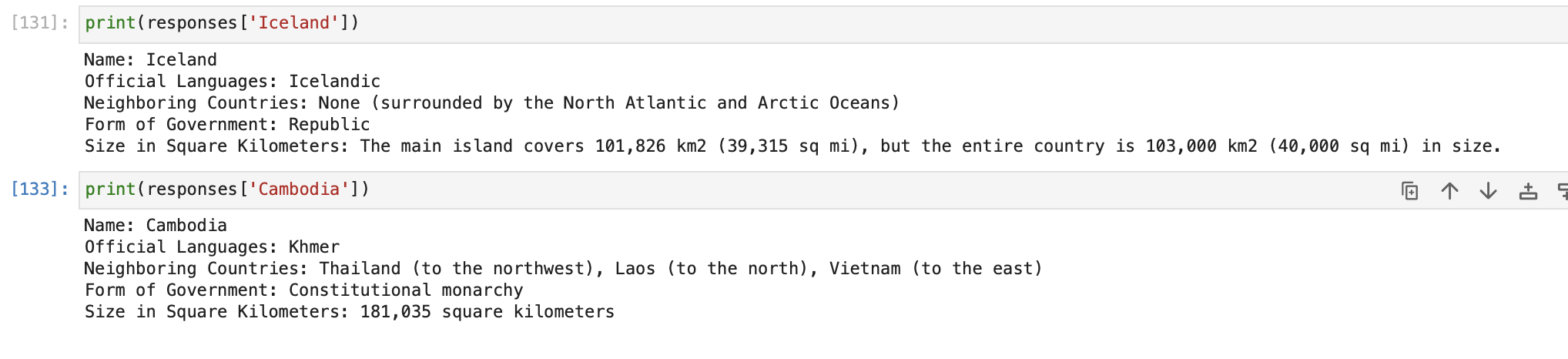
Remember, while any LLM can technically produce these structured outputs, integration outside of OpenAI LLMs is still a work in progress.
Method 2 : Output Parsers
We can also use generic completion APIs, where text prompts dictate inputs and outputs. Here, the output parser ensures the final product aligns with the desired structure, guiding the LLM before and after its task. This is done with the help of Output Parsers, which acts as gatekeepers just before the final response is generated. They sit before and after an LLM text response and ensure everything's in order.
However, if you're using LLM functions discussed above that already give structured outputs, you won't need these.
We will follow the Output Parsers documentation here.
Let us import the LangChain output parser now.

We now define the structured LLM and the response format as shown in the documentation.
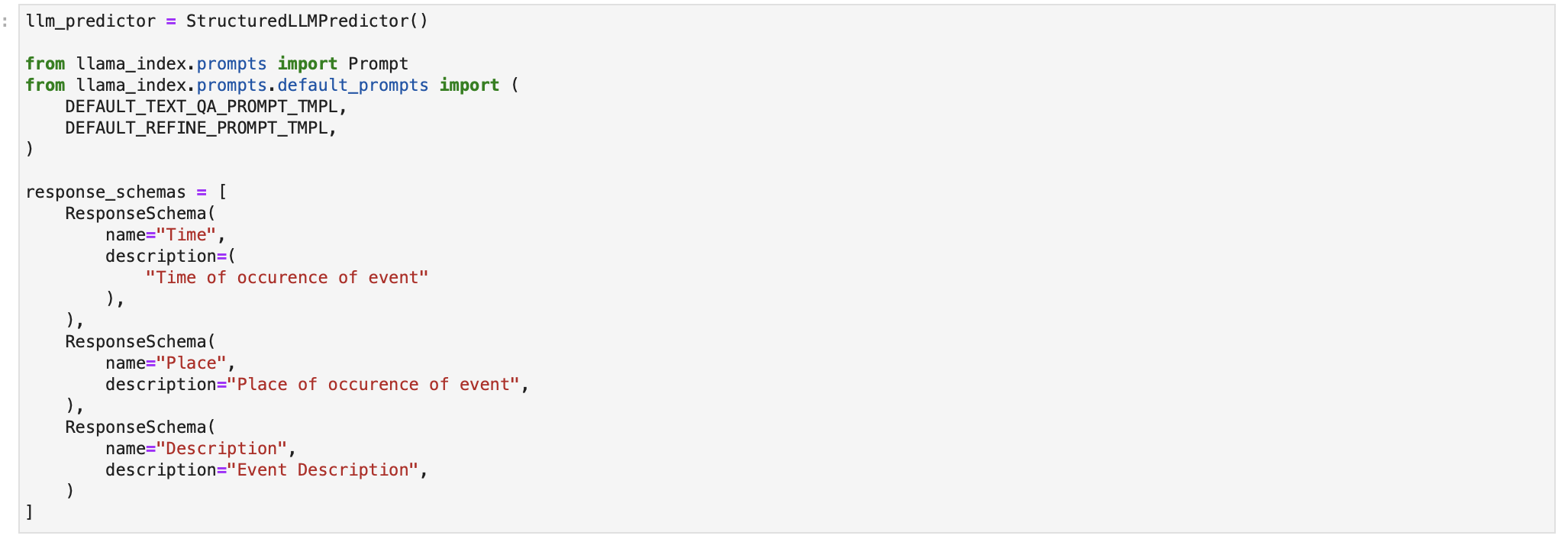
We define the output parser and it's query template using the response_schemas defined above.
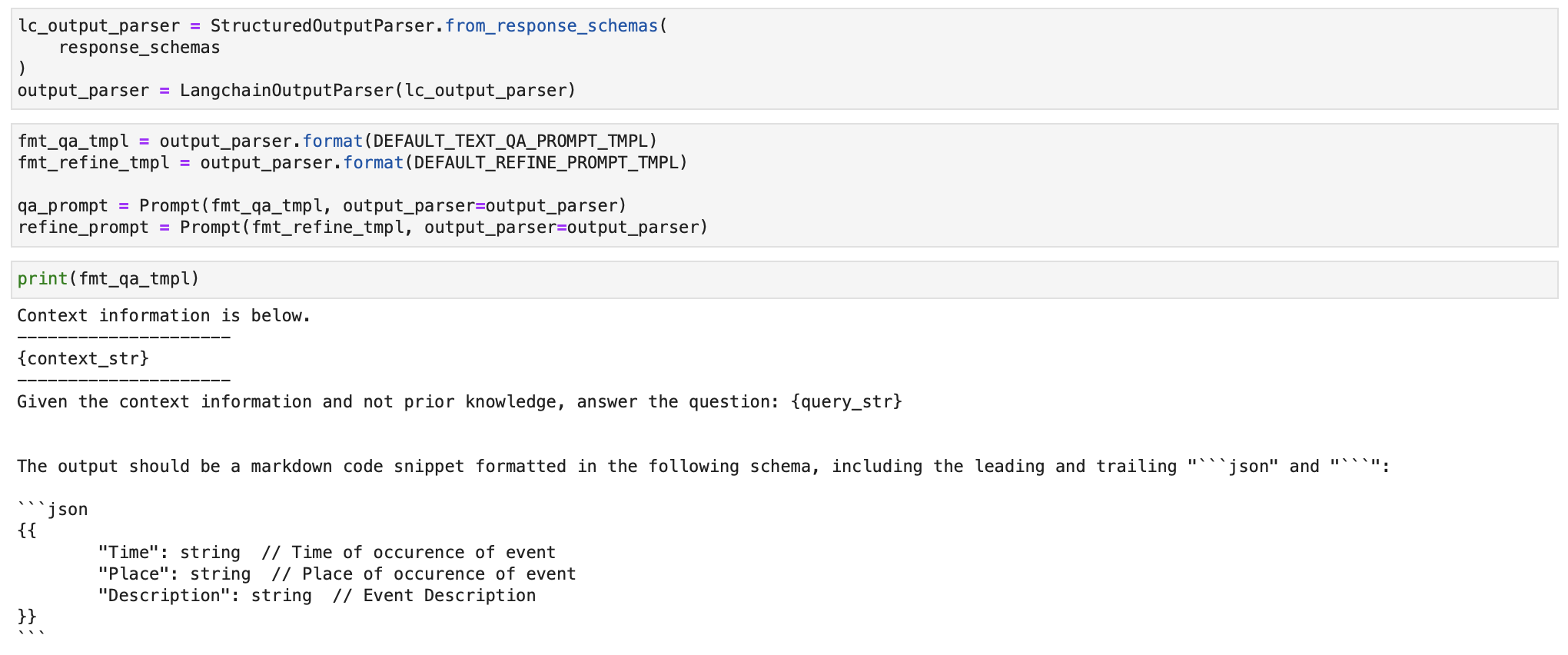
We define the query engine and pass the structured output parser template to it while creating it.

Running any query now fetches a structured json output!
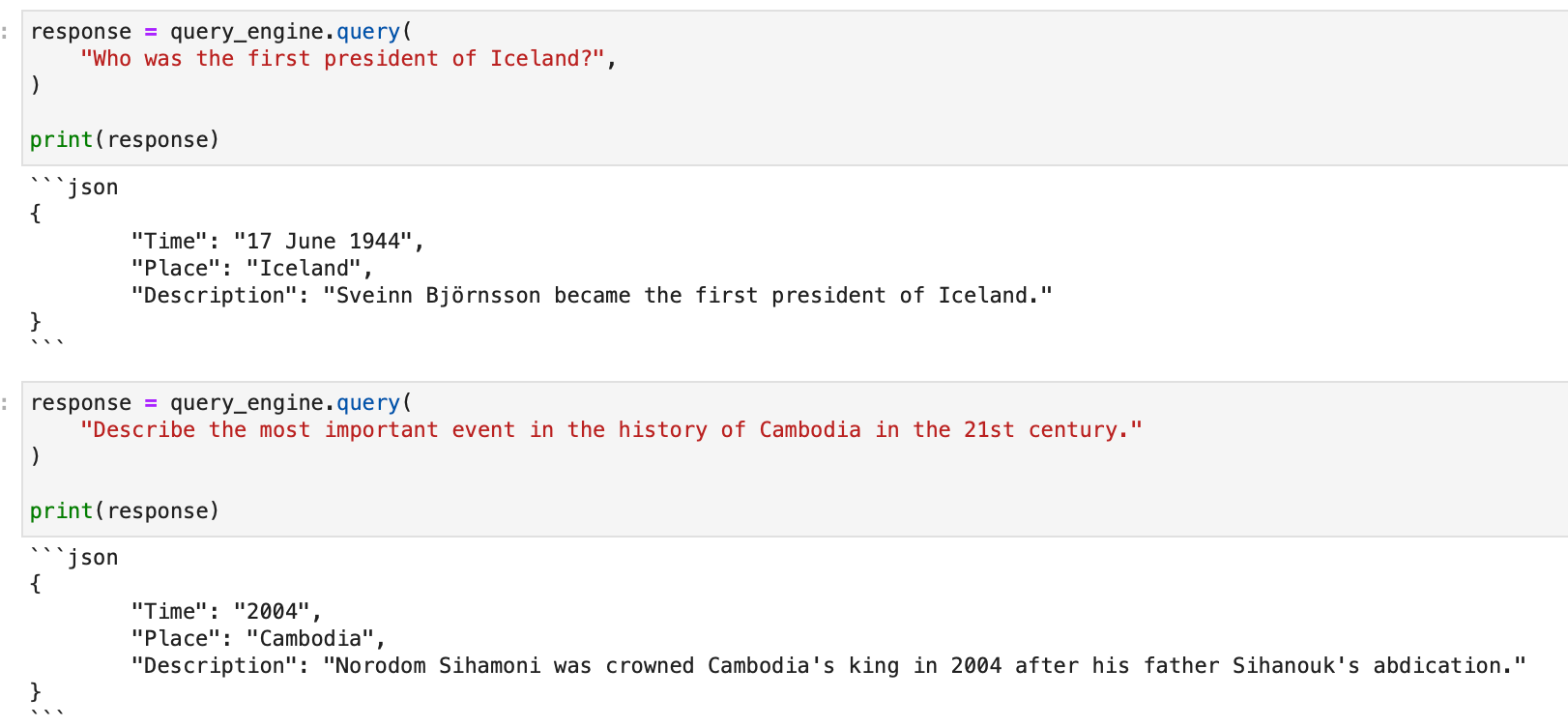
Structured outputs with LlamaIndex make parsing and downstream processes a breeze, ensuring you get the most out of your LLMs.
Automate manual tasks and workflows with our AI-driven workflow builder, designed by Nanonets for you and your teams.
Using Index to Chat with Data
Engaging in a conversation with your data takes querying a step further. LlamaIndex introduces the concept of a Chat Engine to facilitate a more interactive and contextual dialogue with your data. This section elaborates on setting up and utilizing the Chat Engine for a richer interaction with your indexed data.
Understanding the Chat Engine
A Chat Engine provides a high-level interface to have a back-and-forth conversation with your data, as opposed to a single question-answer interaction facilitated by the Query Engine. By maintaining a history of the conversation, the Chat Engine can provide answers that are contextually aware of previous interactions.
Tip: For standalone queries without conversation history, use Query Engine.
Getting Started with Chat Engine
Initiating a conversation is straightforward. Here’s how you can get started:
# Build a chat engine from the index
chat_engine = index.as_chat_engine()
# Start a conversation
response = chat_engine.chat("Tell me a joke.")
# For streaming responses
streaming_response = chat_engine.stream_chat("Tell me a joke.")
for token in streaming_response.response_gen:
print(token, end="")
For example, we can start a chat with our PDF document on the BCG Annual Sustainability Report as follows.
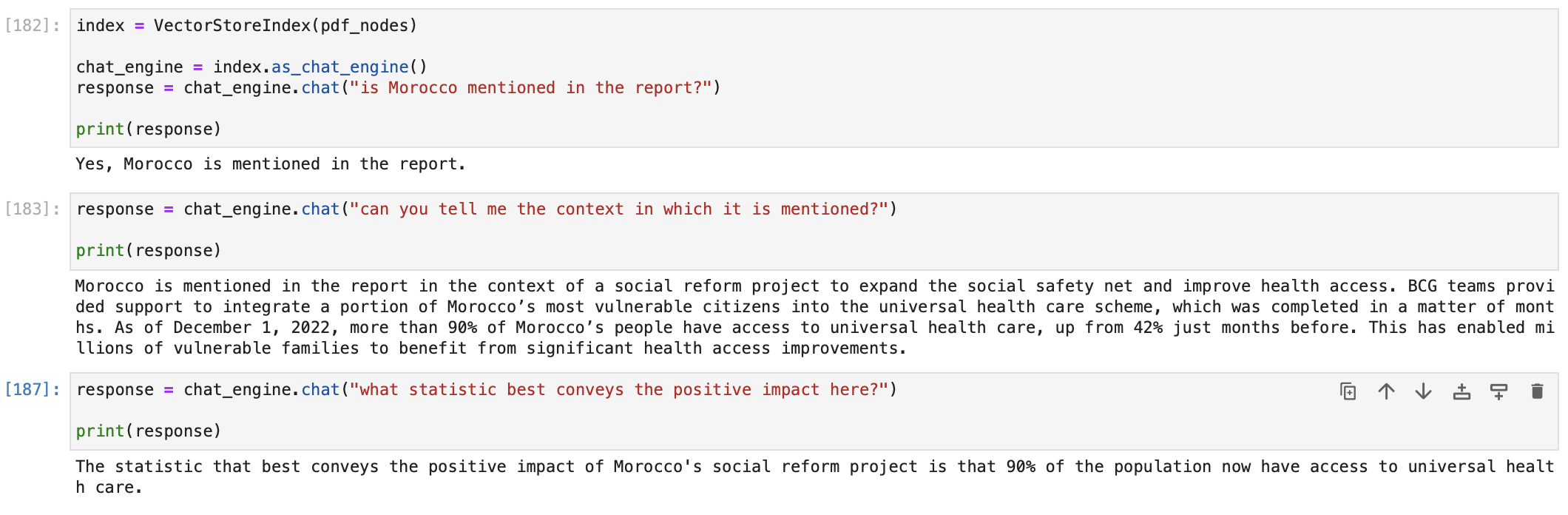
You can choose the chat engine based on your use case. LlamaIndex offers a range of chat engine implementations, catering to different needs and levels of sophistication. These engines are designed to facilitate conversations and interactions with users, each offering a unique set of features.
- SimpleChatEngine
The SimpleChatEngine is a basic chat mode that does not rely on a knowledge base. It provides a starting point for chatbot development. However, it might not handle complex queries well due to its lack of a knowledge base.
- ReAct Agent Mode
ReAct is an agent-based chat mode built on top of a query engine over your data. It follows a flexible approach where the agent decides whether to use the query engine tool to generate responses or not. This mode is versatile but highly dependent on the quality of the language model (LLM) and may require more control to ensure accurate responses. You can customize the LLM used in ReAct mode.
Implementation Example:
# Load data and build index
from llama_index import VectorStoreIndex, SimpleDirectoryReader, ServiceContext
from llama_index.llms import OpenAI
service_context = ServiceContext.from_defaults(llm=OpenAI())
data = SimpleDirectoryReader(input_dir="../data/paul_graham/").load_data()
index = VectorStoreIndex.from_documents(data, service_context=service_context)
# Configure chat engine
chat_engine = index.as_chat_engine(chat_mode="react", verbose=True)
# Chat with your data
response = chat_engine.chat("What did Paul Graham do in the summer of 1995?")
- OpenAI Agent Mode
OpenAI Agent Mode leverages OpenAI's powerful language models like GPT-3.5 Turbo. It's designed for general interactions and can perform specific functions like querying a knowledge base. It's particularly suitable for a wide range of chat applications.
Implementation Example:
# Load data and build index
from llama_index import VectorStoreIndex, SimpleDirectoryReader, ServiceContext
from llama_index.llms import OpenAI
service_context = ServiceContext.from_defaults(llm=OpenAI(model="gpt-3.5-turbo-0613"))
data = SimpleDirectoryReader(input_dir="../data/paul_graham/").load_data()
index = VectorStoreIndex.from_documents(data, service_context=service_context)
# Configure chat engine
chat_engine = index.as_chat_engine(chat_mode="openai", verbose=True)
# Chat with your data
response = chat_engine.chat("Hi")
- Context Mode
The ContextChatEngine is a simple chat mode built on top of a retriever over your data. It retrieves relevant text from the index based on the user's message, sets this retrieved text as context in the system prompt, and returns an answer. This mode is ideal for questions related to the knowledge base and general interactions.
Implementation Example:
# Load data and build index
from llama_index import VectorStoreIndex, SimpleDirectoryReader
data = SimpleDirectoryReader(input_dir="../data/paul_graham/").load_data()
index = VectorStoreIndex.from_documents(data)
# Configure chat engine
from llama_index.memory import ChatMemoryBuffer
memory = ChatMemoryBuffer.from_defaults(token_limit=1500)
chat_engine = index.as_chat_engine(
chat_mode="context",
memory=memory,
system_prompt=(
"You are a chatbot, able to have normal interactions, as well as talk"
" about an essay discussing Paul Graham's life."
),
)
# Chat with your data
response = chat_engine.chat("Hello!")
- Condense Question Mode
The Condense Question mode generates a standalone question from the conversation context and the last message. It then queries the query engine with this condensed question to provide a response. This mode is suitable for questions directly related to the knowledge base.
Implementation Example:
# Load data and build index
from llama_index import VectorStoreIndex, SimpleDirectoryReader
data = SimpleDirectoryReader(input_dir="../data/paul_graham/").load_data()
index = VectorStoreIndex.from_documents(data)
# Configure chat engine
chat_engine = index.as_chat_engine(chat_mode="condense_question", verbose=True)
# Chat with your data
response = chat_engine.chat("What did Paul Graham do after YC?")
Configuring the Chat Engine
Configuration of a Chat Engine is akin to that of a Query Engine. However, the Chat Engine offers different modes to tailor the conversation according to your needs.
- High-Level API
chat_engine = index.as_chat_engine(
chat_mode='condense_question',
verbose=True
)
Different chat modes are available:
best: Optimizes the chat engine for use with a ReAct data agent or an OpenAI data agent, depending on the LLM support.
context: Retrieves nodes from the index using every user message, inserting the retrieved text into the system prompt for more contextual responses.
condense_question: Rewrites the user message to be a query for the index based on the chat history.
simple: Direct chat with the LLM, without involving the query engine.
react: Forces a ReAct data agent.
openai: Forces an OpenAI data agent.
- Low-Level Composition API
For granular control, the low-level composition API allows explicit construction of the ChatEngine object:
from llama_index.prompts import PromptTemplate
from llama_index.llms import ChatMessage, MessageRole
# Custom prompt template
custom_prompt = PromptTemplate("""\
... (template content) ...
""")
# Custom chat history
custom_chat_history = [ ... ] # List of ChatMessage objects
# Query engine from index
query_engine = index.as_query_engine()
# Configuring the Chat Engine
chat_engine = CondenseQuestionChatEngine.from_defaults(
query_engine=query_engine,
condense_question_prompt=custom_prompt,
chat_history=custom_chat_history,
verbose=True
)
In this example, a custom prompt template and chat history are used to configure the CondenseQuestionChatEngine, providing a tailored chat experience.
Streaming Responses
To enable streaming of responses, simply use the stream_chat endpoint:
streaming_response = chat_engine.stream_chat("Tell me a joke.")
for token in streaming_response.response_gen:
print(token, end="")
This feature provides a way to receive and process the response tokens as they are generated, which can be beneficial in certain interactive or real-time scenarios.
Resetting the Chat History
To start a new conversation or to discard the current conversation history, use the reset method:
chat_engine.reset()
Interactive Chat REPL
For an interactive chat session, use the chat_repl method which provides a Read-Eval-Print Loop (REPL) for chatting:
chat_engine.chat_repl()
The Chat Engine in LlamaIndex extends the querying capability to a conversational paradigm, allowing for a more interactive and context-aware interaction with your data. Through various configurations and modes, you can tailor the conversation to suit your specific needs, whether it’s a simple chat or a more complex, context-driven dialogue.
Llamaindex Tools and Data Agents
LlamaIndex Data Agents take natural language as input, and perform actions instead of generating responses.
The essence of constructing proficient data agents lies in the art of tool abstractions.
But what exactly is a tool in this context? Think of Tools as API interfaces, tailored for agent interactions rather than human touchpoints.
Core Concepts:
- Tool: At its basic level, a Tool comes with a generic interface and some fundamental metadata like name, description, and function schema.
- Tool Spec: This dives deeper into the API details. It outlines a comprehensive service API specification, ready to be translated into an assortment of Tools.
There are different flavors of Tools available:
- FunctionTool: Transform any user-defined function into a Tool. Plus, it can smartly infer the function's schema.
- QueryEngineTool: Wraps around an existing query engine, and given our agent abstractions are derived from BaseQueryEngine, this tool can also embrace agents (which we will discuss later).
You can either custom design LlamaHub Tool Specs and Tools or effortlessly import them from the llama-hub package. Integrating them into agents is straightforward.
For an extensive collection of Tools and Tool Specs, make your way to LlamaHub.
Data Agents in LlamaIndex are powered by Language Learning Models (LLMs) and act as intelligent knowledge workers over your data, executing both "read" and "write" operations. They automate search and retrieval across diverse data types—unstructured, semi-structured, and structured. Unlike our query engines which only "read" from a static data source, Data Agents can dynamically ingest, modify, and interact with data across various tools. They can call external service APIs, process the returned data, and store it for future reference.
The two building blocks of Data Agents are:
- A Reasoning Loop: Dictates the agent's decision-making process on which tools to employ, their sequence, and the parameters for each tool call based on the input task.
- Tool Abstractions: A set of APIs or Tools that the agent interacts with to fetch information or alter states.
The type of reasoning loop depends on the agent; supported types include OpenAI Function agent and a ReAct agent (which operates across any chat/text completion endpoint).
Here's how to use an OpenAI Function API-based Data Agent:
from llama_index.agent import OpenAIAgent
from llama_index.llms import OpenAI
... # import and define tools
llm = OpenAI(model="gpt-3.5-turbo-0613")
agent = OpenAIAgent.from_tools(tools, llm=llm, verbose=True)
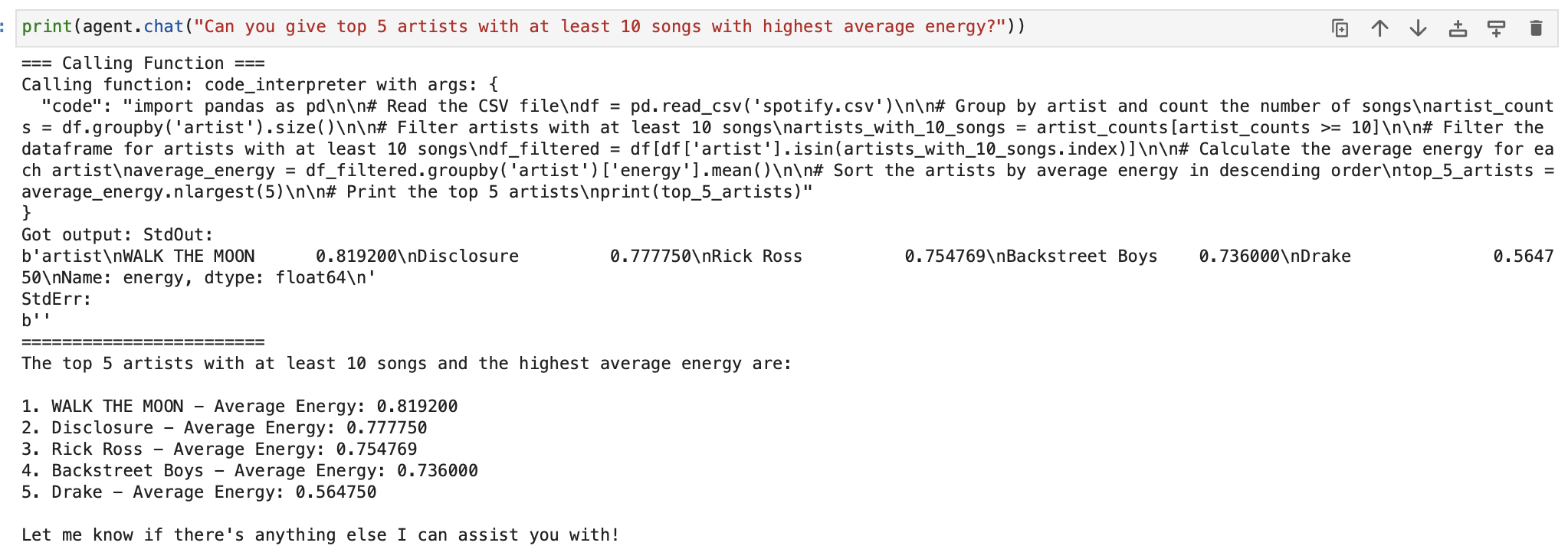
Now, let us go ahead and use the Code Interpreter tool available in LlamaHub to write and execute code directly by giving natural language instructions. We will use this Spotify dataset (which is a .csv file) and perform data analysis by making our agent execute python code to read and manipulate the data in pandas.
We first import the tool.

Let's start chatting.

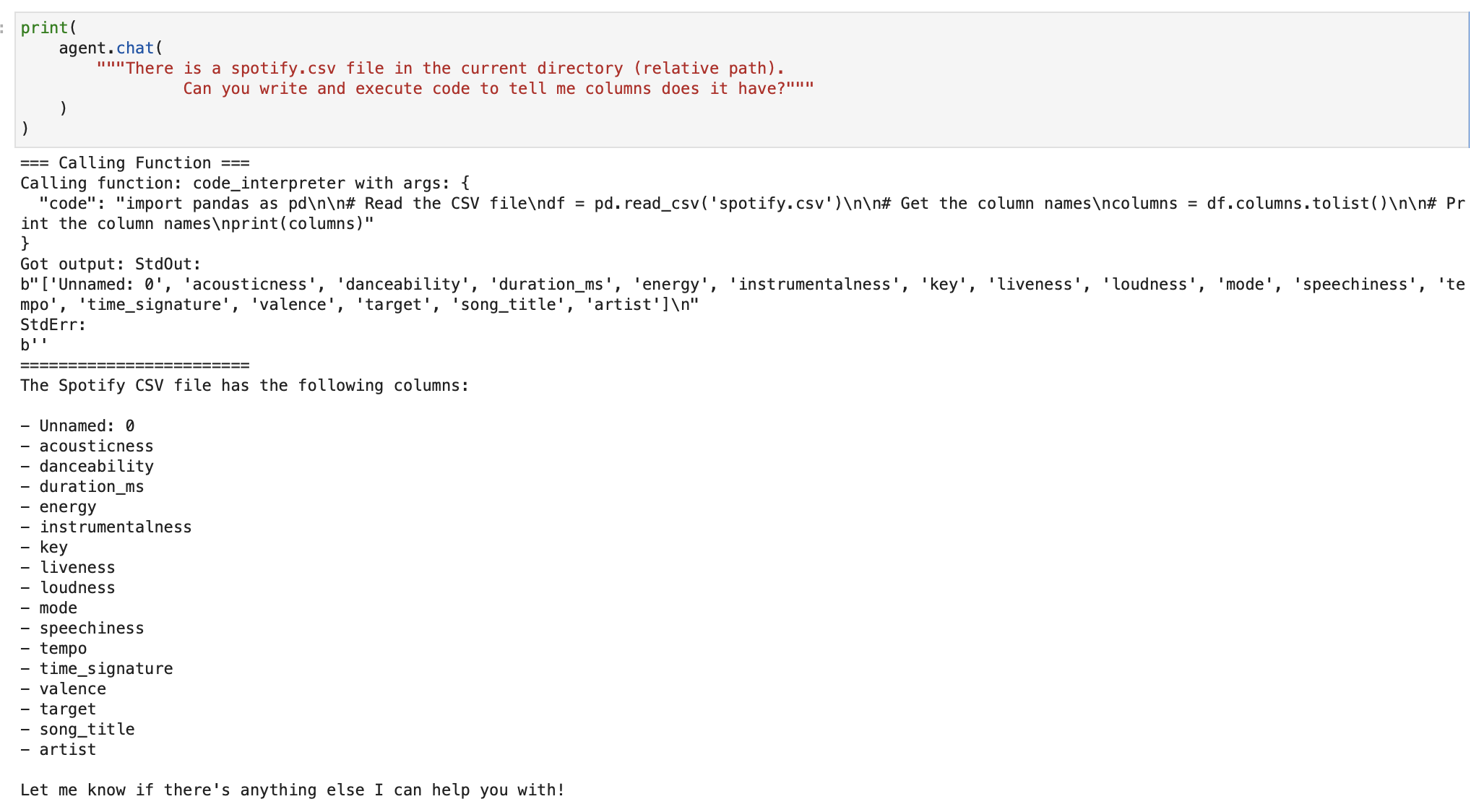
We first ask it to fetch the list of columns. Our agent executes python code and uses pandas to read the column names.
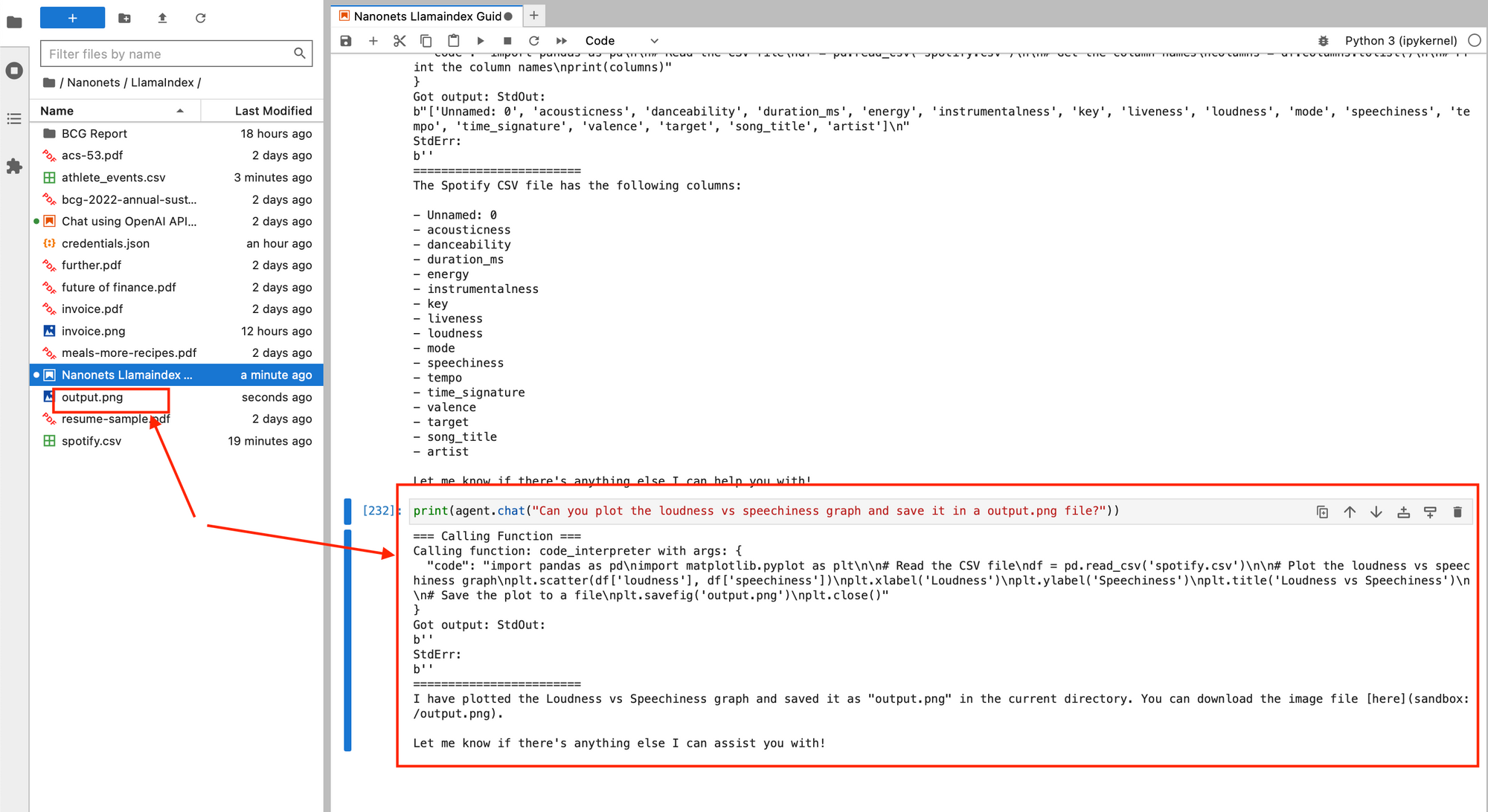
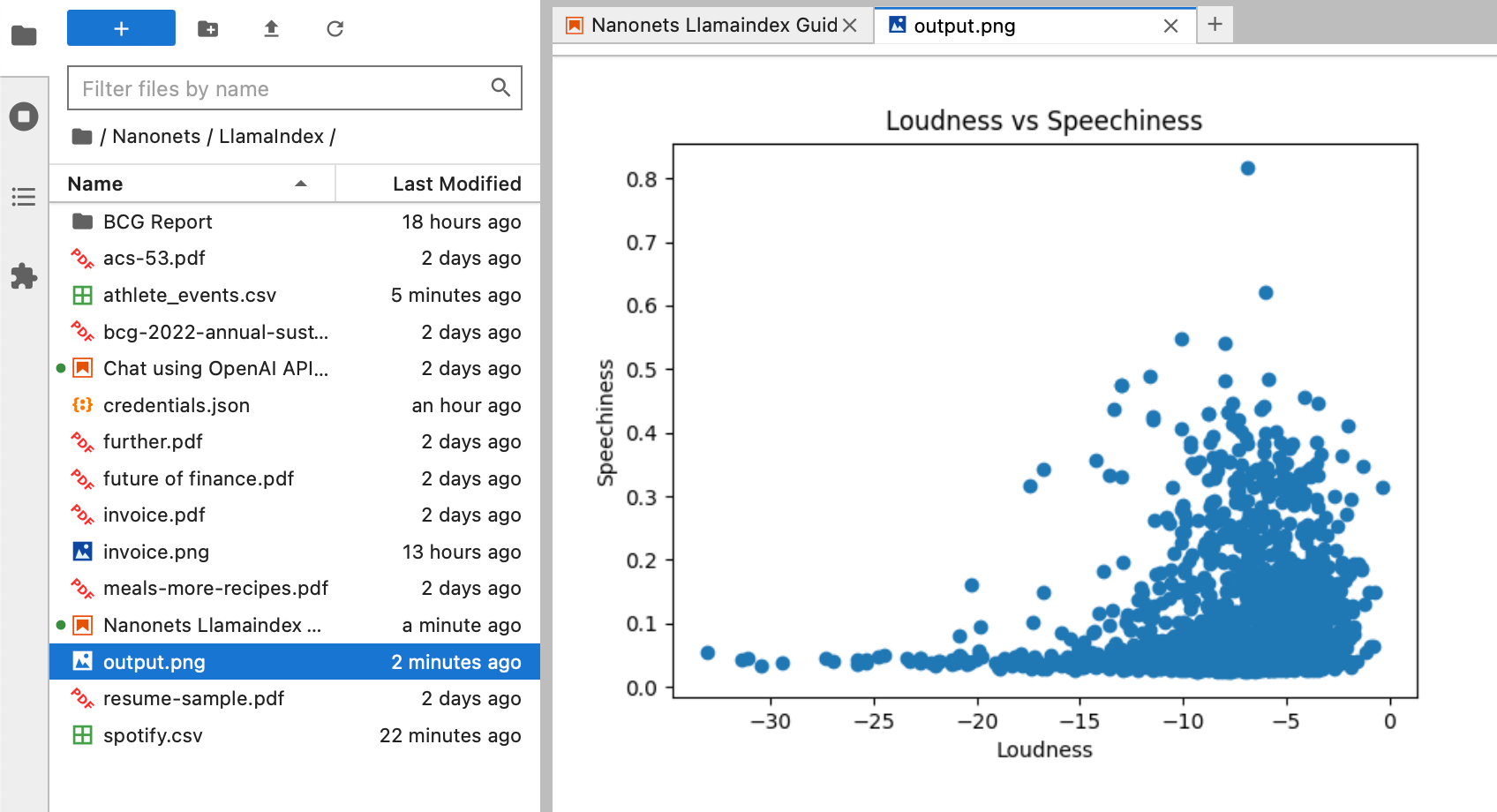
We now ask it to plot a graph of loudness vs 'speechiness' and save it in a output.png file on our system, all by just chatting with our agent.
We can perform EDA in detail as well.
Now, let us go ahead and use another tool to send emails from our Gmail account with an agent using natural language input.
We use the data connector with Hubspot from LlamaHub to fetch a structured list of leads which were created yesterday.

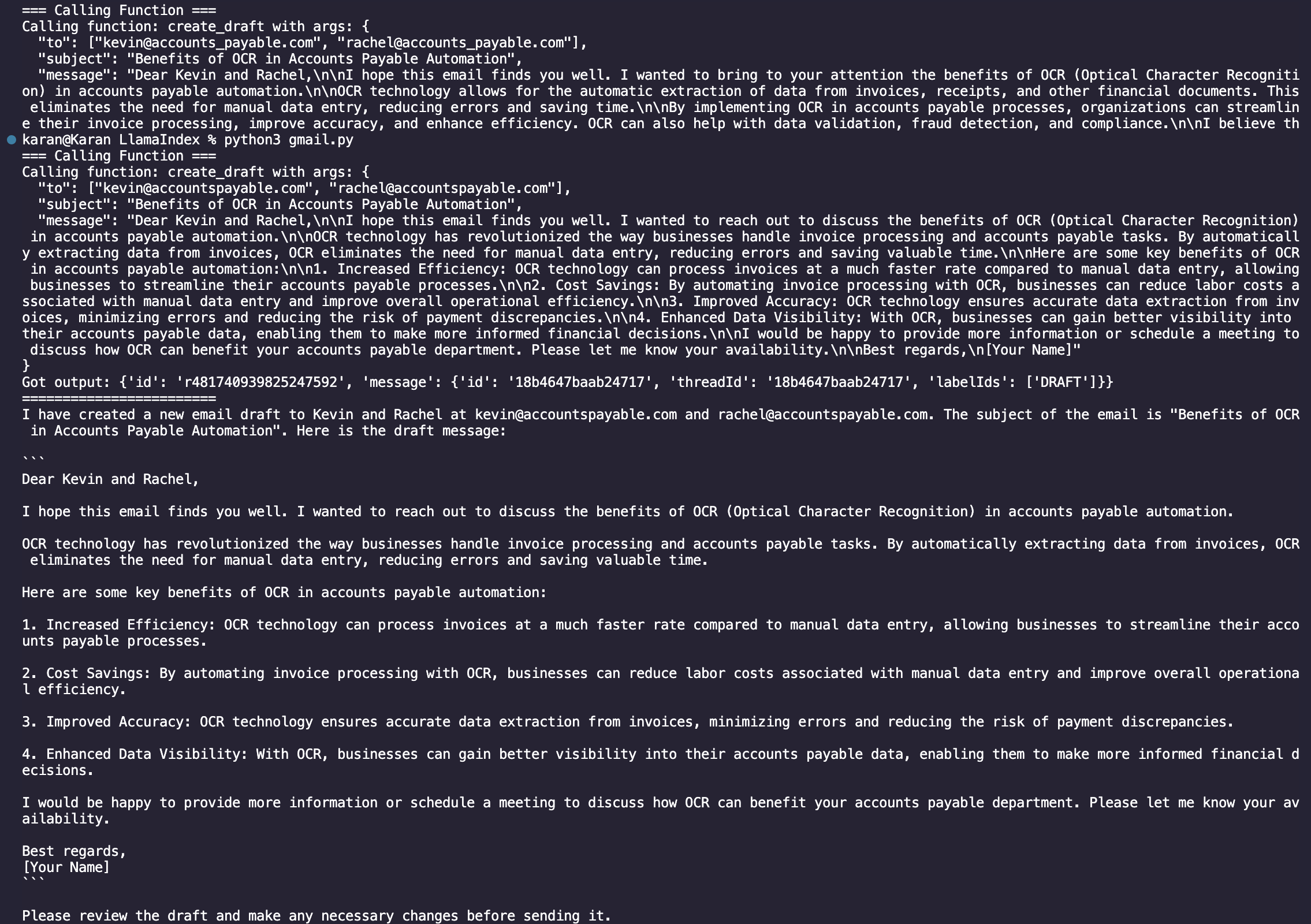
We now go to the GmailSpecTool Documentation in LlamaHub to create a Gmail Agent to write and send one day follow-up emails to these folks.
We start by creating a credentials.json file by following the documentation and add it to our working directory.
We then proceed to provide the email writing prompt.

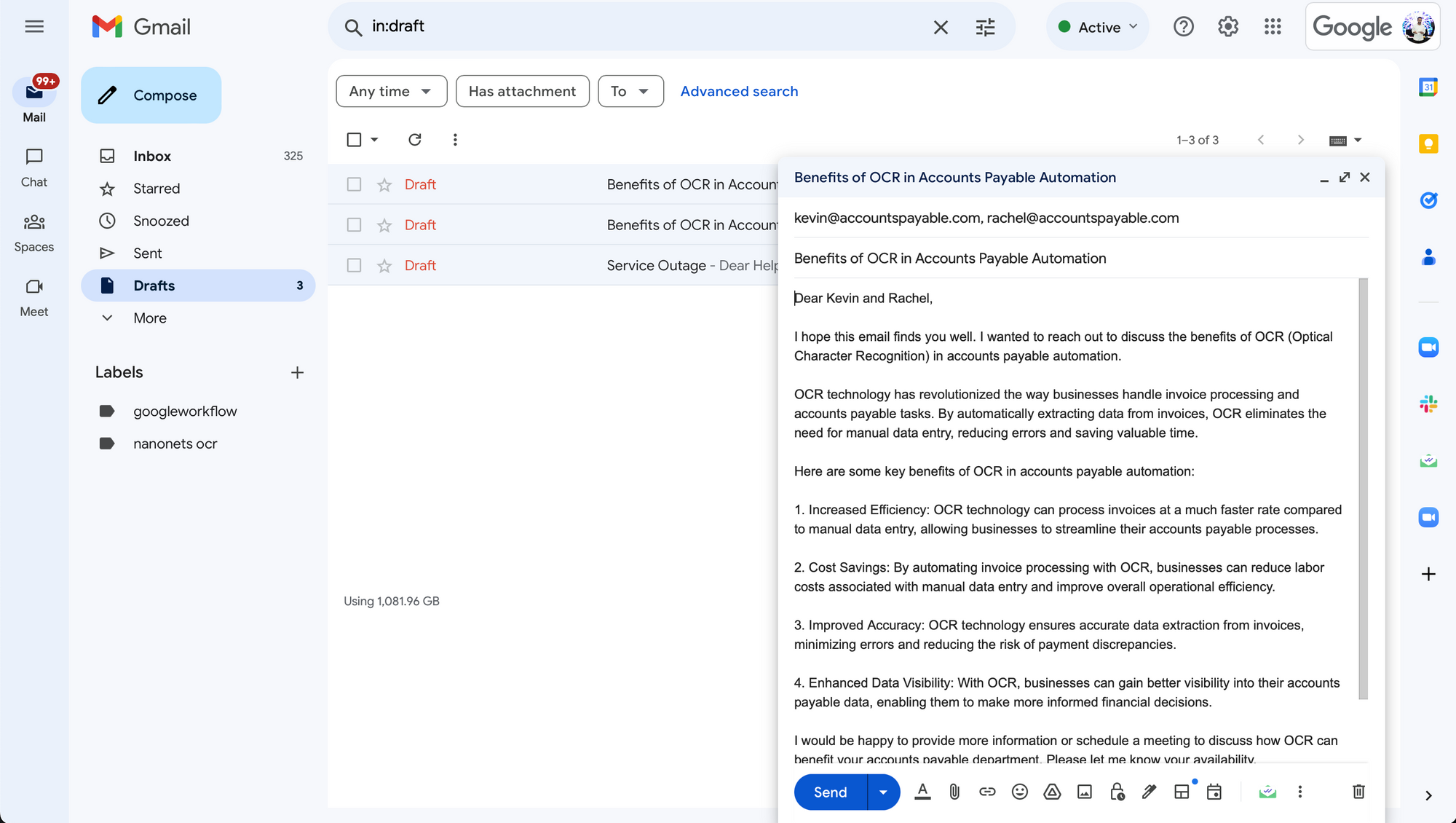
Upon running the code, we can see the execution chain writing the emails and saving them as drafts in your Gmail account.
When we visit our Gmail Draft box, we can see the draft that the agent created!
In fact, we could have also scheduled this script to run daily and instructed the Gmail agent to send these emails directly instead of saving them as drafts, resulting in a end-to-end fully automated workflow that -
- connects with hubspot daily to fetch yesterday's leads
- uses the domain from the email addresses to create personalized follow up emails
- sends the emails from your Gmail account directly.
Thus, in addition to querying and chatting with data, LlamaIndex can be also be used to fully execute tasks by interacting with applications and data sources.
And that's a wrap!
Automate manual tasks and workflows with our AI-driven workflow builder, designed by Nanonets for you and your teams.
Level up with Nanonets
LlamaIndex is a great tool to connect your data, irrespective of its format, with LLMs and harness their prowess to interact with it. We have seen how to use natural language with your data and apps in order to generate responses / perform tasks.
However, for businesses, using LlamaIndex for enterprise applications might pose a few problems -
- While LlamaHub is a great repository to find a large variety of data connectors, this list is still not exhaustive and misses out on providing connections with some of the major workspace apps.
- This trend is even more increasingly prevalent in the context of tools, which take natural language as input to perform tasks (write and send emails, create CRM entries, execute SQL queries and fetch results, and so on). This limits the number of supported apps and ways in which the agents can interact with them.
- Finetuning the configuration of each element of the LlamaIndex pipeline (retrievers, synthesizers, indices, and so on) is a cumbersome process. On top of that, identifying the best pipeline for a given dataset and task is time consuming and not always intuitive.
- Each task needs a unique implementation. There is no one-stop solution for connecting your data with LLMs.
- LlamaIndex fetches static data with data connectors, which is not updated with new data flowing into the source database.
Enter Nanonets Workflows!
Harnessing the Power of Workflow Automation: A Game-Changer for Modern Businesses
In today's fast-paced business environment, workflow automation stands out as a crucial innovation, offering a competitive edge to companies of all sizes. The integration of automated workflows into daily business operations is not just a trend; it's a strategic necessity. In addition to this, the advent of LLMs has opened even more opportunities for automation of manual tasks and processes.
Welcome to Nanonets Workflow Automation, where AI-driven technology empowers you and your team to automate manual tasks and construct efficient workflows in minutes. Utilize natural language to effortlessly create and manage workflows that seamlessly integrate with all your documents, apps, and databases.
Our platform offers not only seamless app integrations for unified workflows but also the ability to build and utilize custom Large Language Models Apps for sophisticated text writing and response posting within your apps. All the while ensuring data security remains our top priority, with strict adherence to GDPR, SOC 2, and HIPAA compliance standards.
To better understand the practical applications of Nanonets workflow automation, let's delve into some real-world examples.
- Automated Customer Support and Engagement Process
- Ticket Creation – Zendesk: The workflow is triggered when a customer submits a new support ticket in Zendesk, indicating they need assistance with a product or service.
- Ticket Update – Zendesk: After the ticket is created, an automated update is immediately logged in Zendesk to indicate that the ticket has been received and is being processed, providing the customer with a ticket number for reference.
- Information Retrieval – Nanonets Browsing: Concurrently, the Nanonets Browsing feature searches through all the knowledge base pages to find relevant information and possible solutions related to the customer's issue.
- Customer History Access – HubSpot: Simultaneously, HubSpot is queried to retrieve the customer's previous interaction records, purchase history, and any past tickets to provide context to the support team.
- Ticket Processing – Nanonets AI: With the relevant information and customer history at hand, Nanonets AI processes the ticket, categorizing the issue and suggesting potential solutions based on similar past cases.
- Notification – Slack: Finally, the responsible support team or individual is notified through Slack with a message containing the ticket details, customer history, and suggested solutions, prompting a swift and informed response.
- Automated Issue Resolution Process
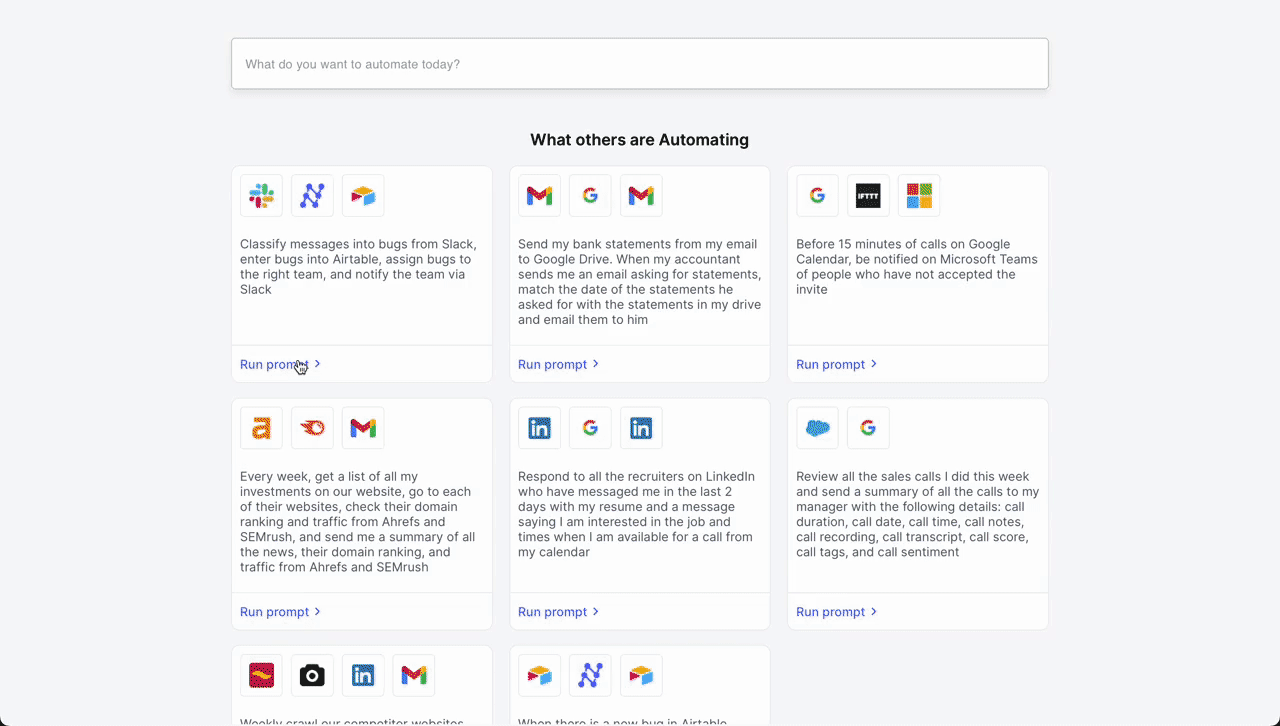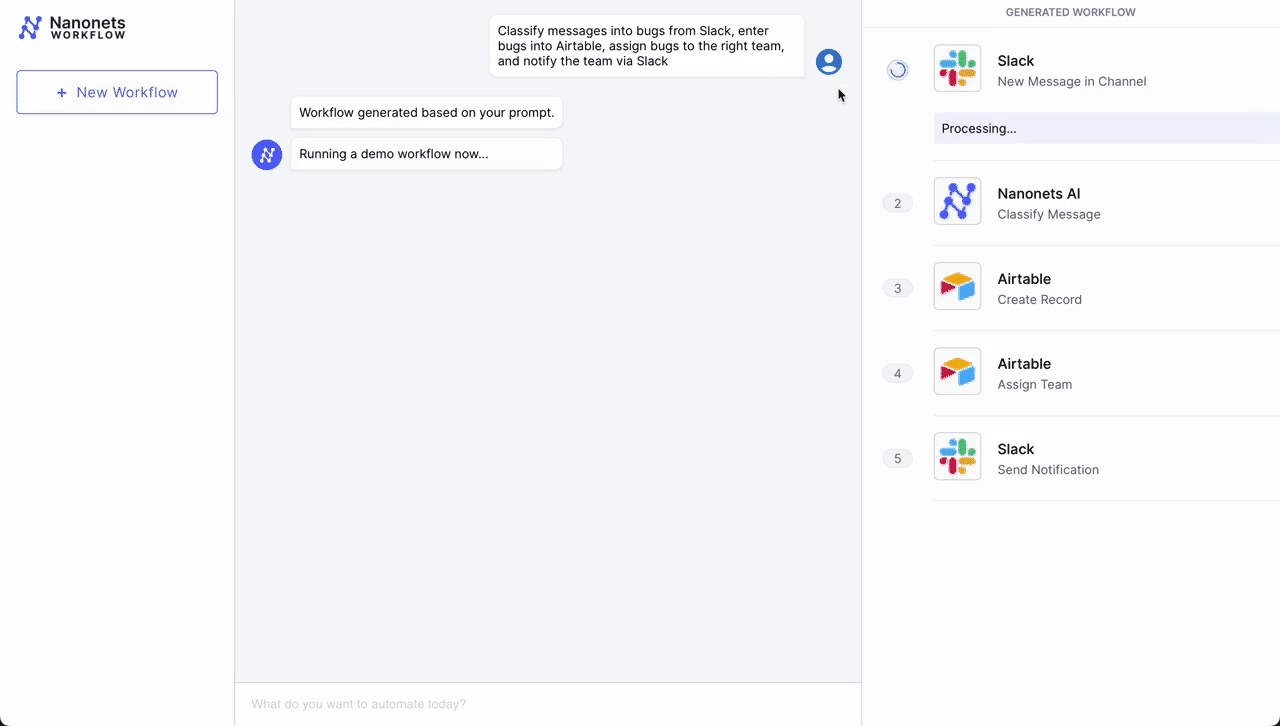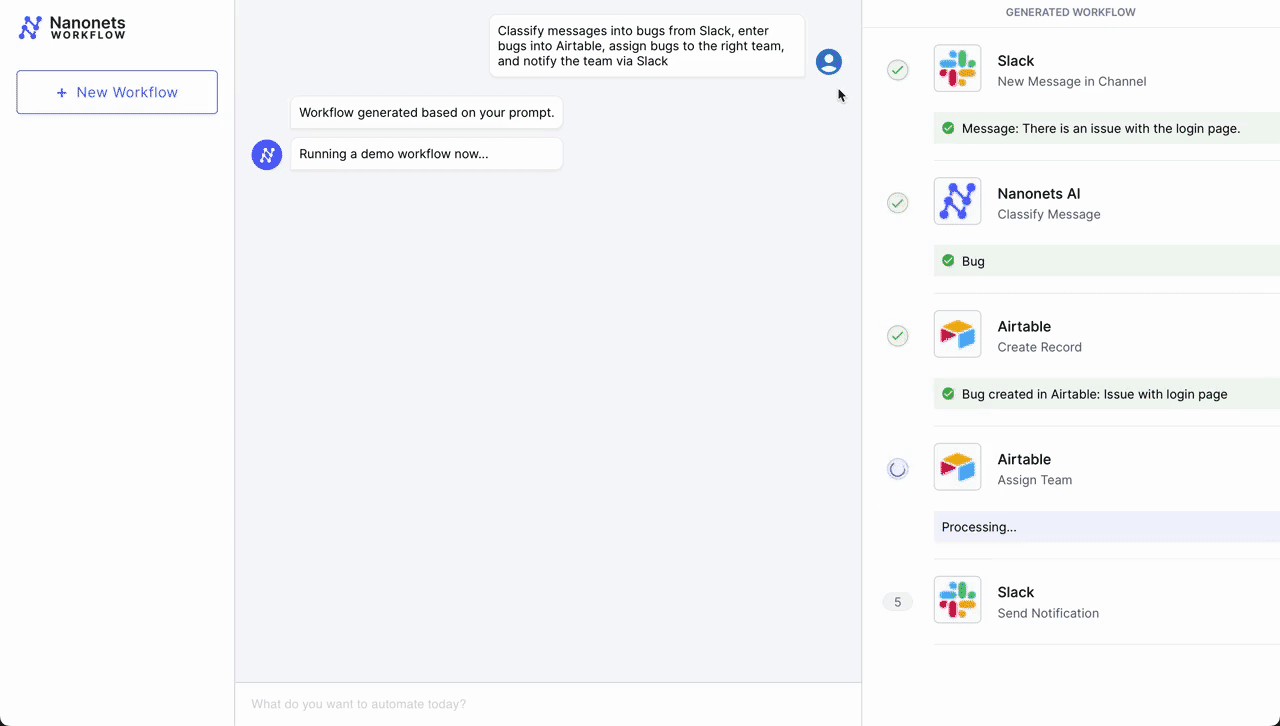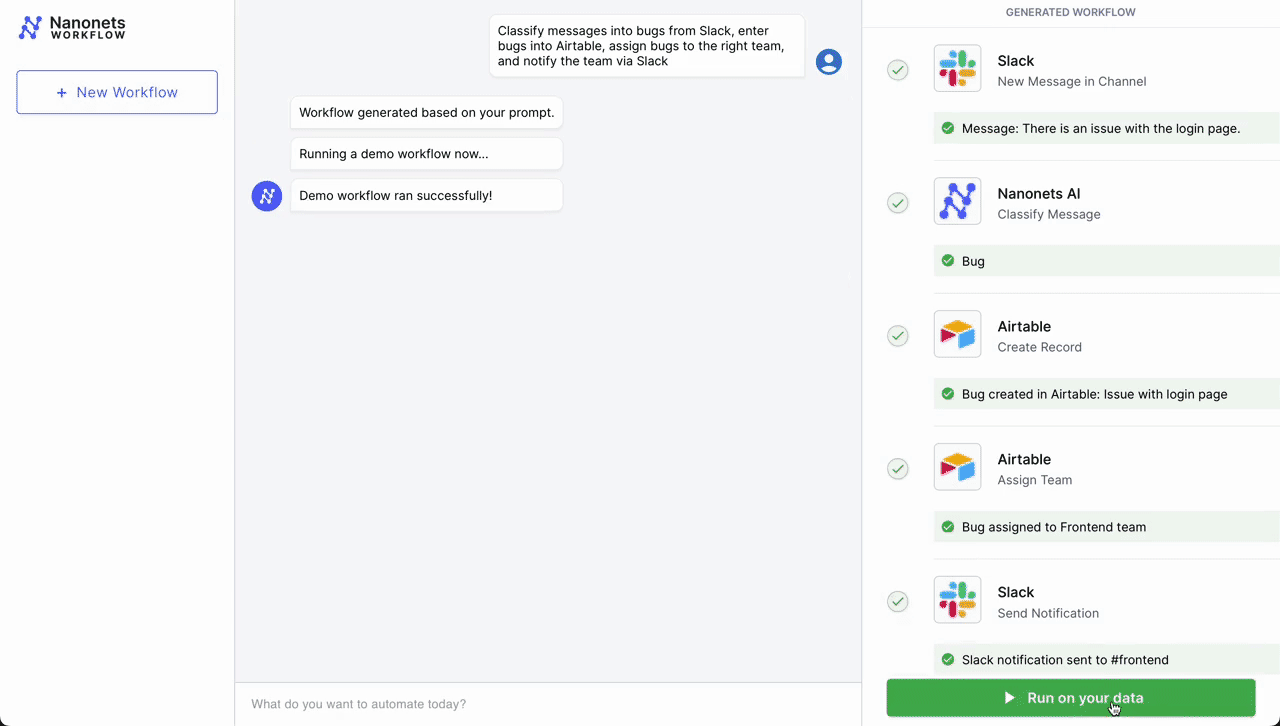
- Initial Trigger – Slack Message: The workflow begins when a customer service representative receives a new message in a dedicated channel on Slack, signaling a customer issue that needs to be addressed.
- Classification – Nanonets AI: Once the message is detected, Nanonets AI steps in to classify the message based on its content and past classification data (from Airtable records). Using LLMs, it classifies it as a bug along with determining urgency.
- Record Creation – Airtable: After classification, the workflow automatically creates a new record in Airtable, a cloud collaboration service. This record includes all relevant details from the customer's message, such as customer ID, issue category, and urgency level.
- Team Assignment – Airtable: With the record created, the Airtable system then assigns a team to handle the issue. Based on the classification done by Nanonets AI, the system selects the most appropriate team – tech support, billing, customer success, etc. – to take over the issue.
- Notification – Slack: Finally, the assigned team is notified through Slack. An automated message is sent to the team's channel, alerting them of the new issue, providing a direct link to the Airtable record, and prompting a timely response.
- Automated Meeting Scheduling Process
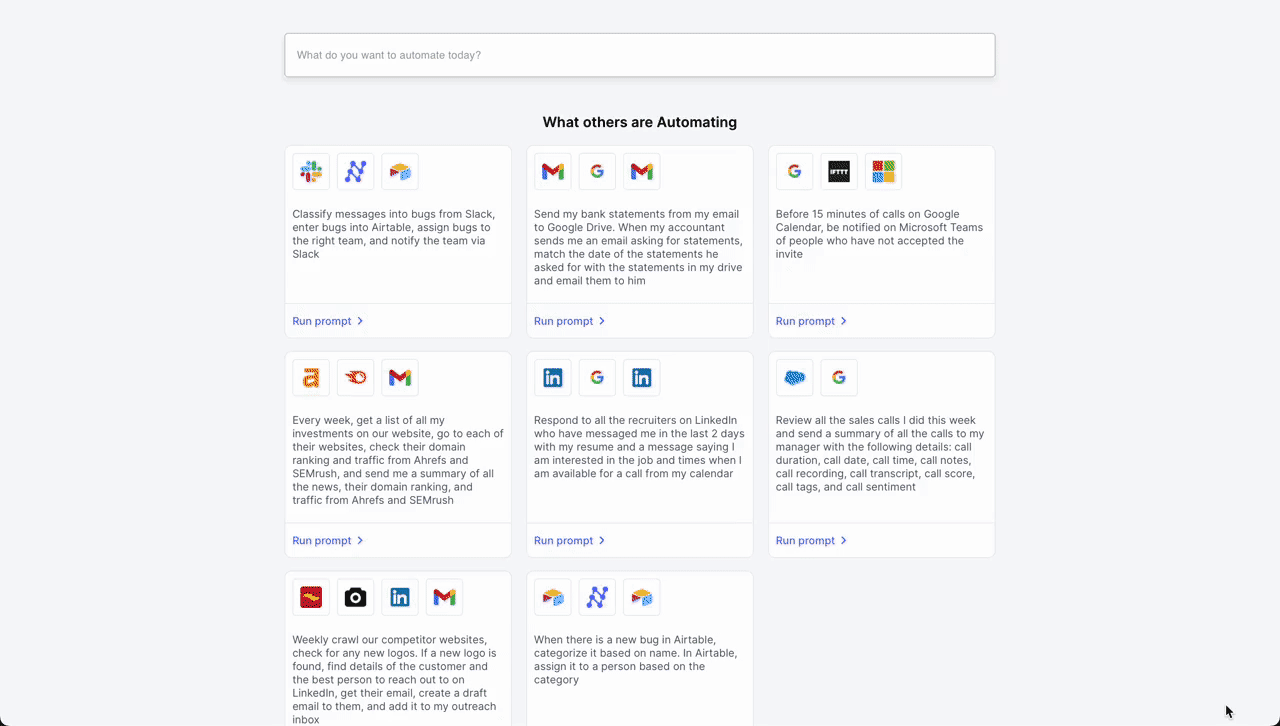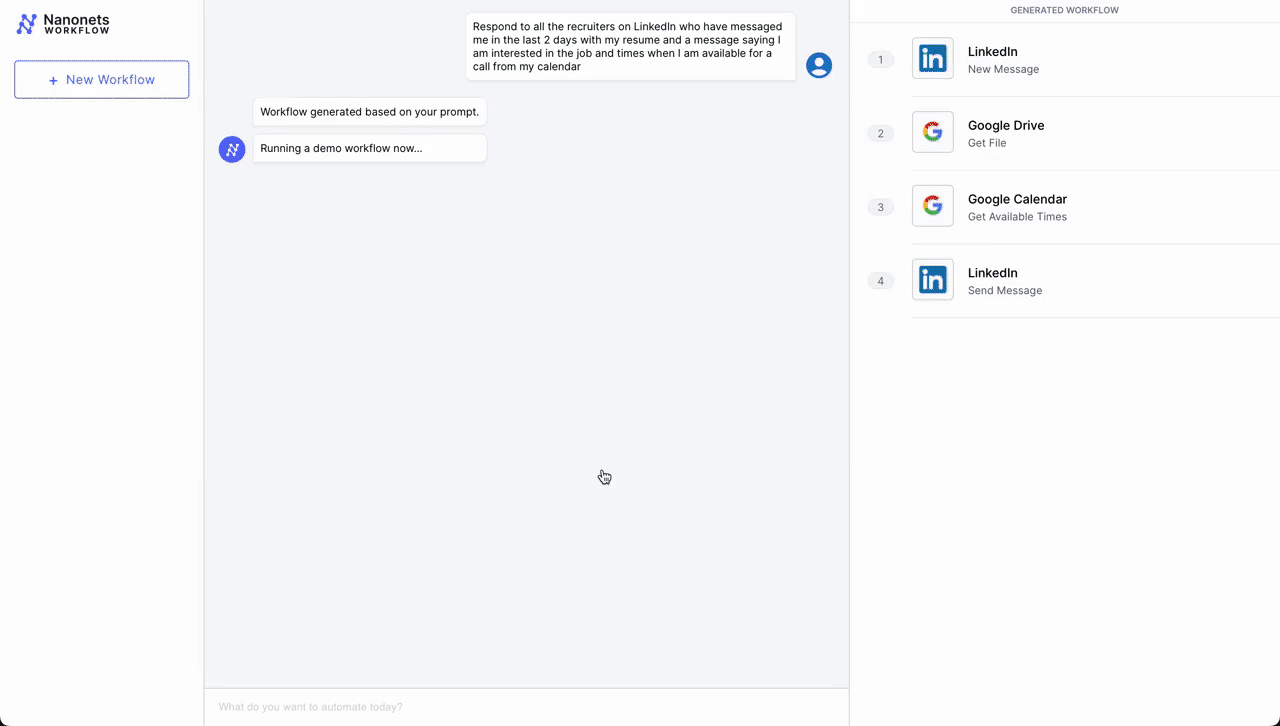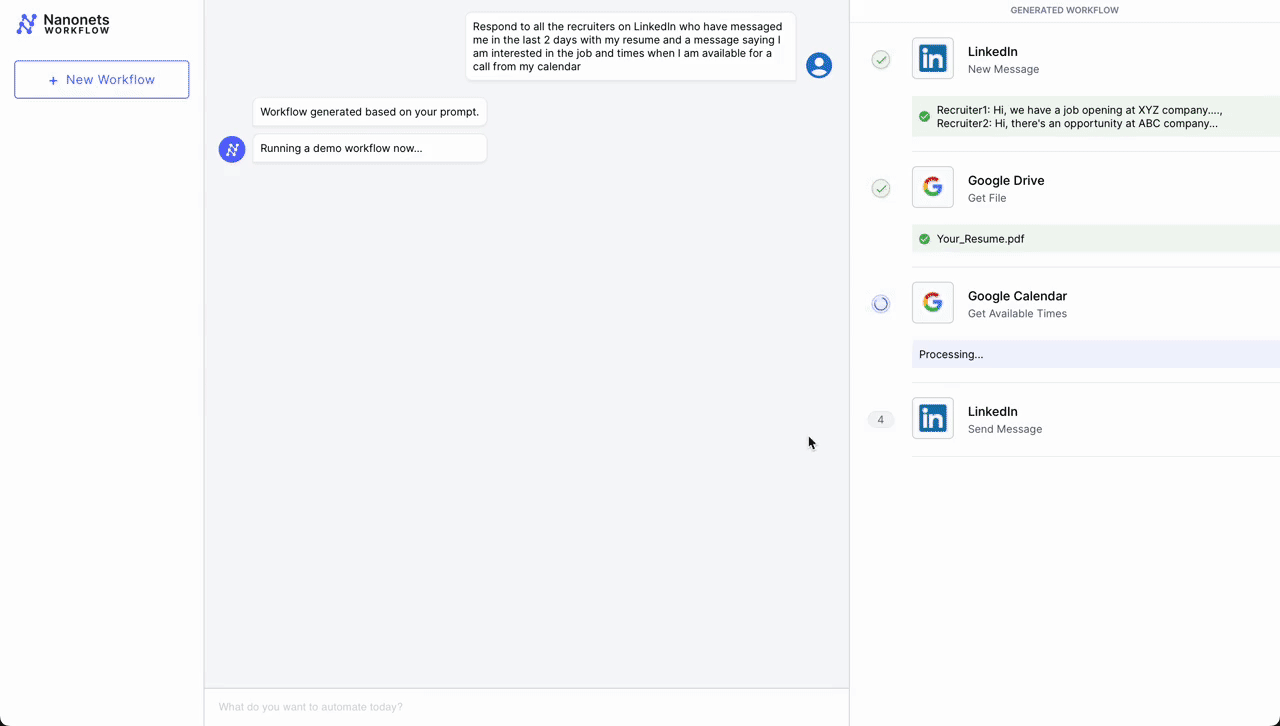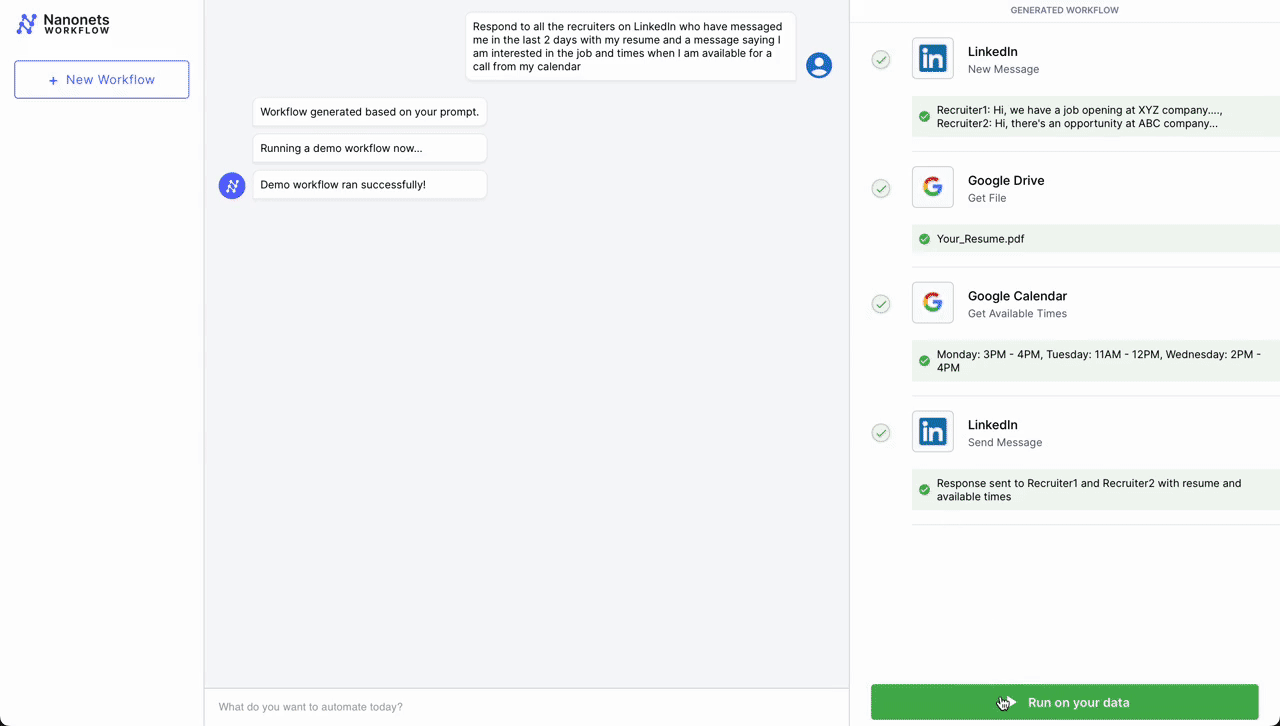
- Initial Contact – LinkedIn: The workflow is initiated when a professional connection sends a new message on LinkedIn expressing interest in scheduling a meeting. An LLM parses incoming messages and triggers the workflow if it deems the message as a request for a meeting from a potential job candidate.
- Document Retrieval – Google Drive: Following the initial contact, the workflow automation system retrieves a pre-prepared document from Google Drive that contains information about the meeting agenda, company overview, or any relevant briefing materials.
- Scheduling – Google Calendar: Next, the system interacts with Google Calendar to get available times for the meeting. It checks the calendar for open slots that align with business hours (based on the location parsed from LinkedIn profile) and previously set preferences for meetings.
- Confirmation Message as Reply – LinkedIn: Once a suitable time slot is found, the workflow automation system sends a message back through LinkedIn. This message includes the proposed time for the meeting, access to the document retrieved from Google Drive, and a request for confirmation or alternative suggestions.
- Invoice Processing in Accounts Payable
- Receipt of Invoice - Gmail: An invoice is received via email or uploaded to the system.
- Data Extraction - Nanonets OCR: The system leverages AI-based document processing to automatically extract relevant data (like vendor details, amounts, due dates).
- Data Verification - Quickbooks: The Nanonets workflow verifies the extracted invoice data against purchase orders and receipts.
- Approval Routing - Slack: The invoice is routed to the appropriate manager for approval based on predefined thresholds and rules.
- Payment Processing - Brex: Once approved, the system schedules the payment according to the vendor's terms and updates the finance records.
- Archiving - Quickbooks: The completed transaction is archived for future reference and audit trails.
- Internal Knowledge Base Assistance

- Initial Inquiry – Slack: A team member, Smith, inquires in the #chat-with-data Slack channel about customers experiencing issues with QuickBooks integration.
- Automated Data Aggregation - Nanonets Knowledge Base:
- Ticket Lookup - Zendesk: The Zendesk app in Slack automatically provides a summary of today's tickets, indicating that there are issues with exporting invoice data to QuickBooks for some customers.
- Slack Search - Slack: Simultaneously, the Slack app notifies the channel that team members Patrick and Rachel are actively discussing the resolution of the QuickBooks export bug in another channel, with a fix scheduled to go live at 4 PM.
- Ticket Tracking – JIRA: The JIRA app updates the channel about a ticket created by Emily titled "QuickBooks export failing for QB Desktop integrations," which helps track the status and resolution progress of the issue.
- Reference Documentation – Google Drive: The Drive app mentions the existence of a runbook for fixing bugs related to QuickBooks integrations, which can be referenced to understand the steps for troubleshooting and resolution.
- Ongoing Communication and Resolution Confirmation – Slack: As the conversation progresses, the Slack channel serves as a real-time forum for discussing updates, sharing findings from the runbook, and confirming the deployment of the bug fix. Team members use the channel to collaborate, share insights, and ask follow-up questions to ensure a comprehensive understanding of the issue and its resolution.
- Resolution Documentation and Knowledge Sharing: After the fix is implemented, team members update the internal documentation in Google Drive with new findings and any additional steps taken to resolve the issue. A summary of the incident, resolution, and any lessons learned are already shared in the Slack channel. Thus, the team’s internal knowledge base is automatically enhanced for future use.
The Future of Business Efficiency
Nanonets Workflows is a secure, multi-purpose workflow automation platform that automates your manual tasks and workflows. It offers an easy-to-use user interface, making it accessible for both individuals and organizations.
To get started, you can schedule a call with one of our AI experts, who can provide a personalized demo and trial of Nanonets Workflows tailored to your specific use case.
Once set up, you can use natural language to design and execute complex applications and workflows powered by LLMs, integrating seamlessly with your apps and data.

Supercharge your teams with Nanonets Workflows allowing them to focus on what truly matters.
Automate manual tasks and workflows with our AI-driven workflow builder, designed by Nanonets for you and your teams.
