

Vision Language Models (VLMs) are set to become ubiquitous, sparking a surge of tools that can address day-to-day visual challenges.
As we enter this "golden age" of VLMs, it becomes mission-critical for businesses to quickly evaluate the best available options.
This is especially important in scenarios like data extraction, where dozens of models are launched each quarter and there are multitudes of documents types to test them on. To make informed decisions, it's essential to understand the factors that differentiate a good VLM from a great one.
In this article, we will cover:
- an Introduction to VLMs: A brief overview of what Vision Language Models are, how they function, and their role in solving visual problems.
- VLMs for Document Data Extraction: An explanation on what we mean by data extraction with VLMs.
- Models for Evaluation: List of models we have chosen for evaluation, both open and closed source.
- Document Datasets for Evaluation: The datasets that will be used to evaluate the VLMs, emphasizing their relevance to real-world use cases like data extraction.
- Evaluation Methodology: The methodology used to assess the VLMs, including the prompt for each dataset and choice of fields for evaluation.
- Metrics: The key metrics used to measure the models' performance.
- Model Discussion: A brief snippet to call a VLM in python followed by the observed statistics, pros and cons of each model.
- Evaluation Results: Provide a detailed breakdown of how each model performed on the datasets, along with insights on which models excelled and which fell short.
- Key Takeaways: Conclude by summarizing the important factors businesses should consider when selecting a VLM for their specific requirements, highlighting performance, scalability, and reliability.
By the end of this article, you'll have a clear understanding of how to evaluate VLMs effectively and choose the best option for your use case.
Introduction to VLMs
A Vision-Language Model (VLM) integrates both visual and textual information to understand and generate outputs based on multimodal inputs. On scale, these are very much like LLMs. Here's a brief overview of VLMs -
VLMs take two types of inputs:
- Image: An image or a sequence of images.
- Text: A natural language description or question.
VLM Architectures:
- VLMs typically combine a vision model (e.g., CNNs, Vision Transformers) to process the image and a language model (e.g., Transformers) to process the text.
- These models are often fused or integrated through attention mechanisms or cross-modal encoders to jointly understand the visual and textual inputs.
VLM Training:
- VLMs are trained on large datasets containing paired images and text (e.g., captions, descriptions) using various objectives like image-text matching, masked language modeling, or image captioning.
- They may also be fine-tuned on specific tasks, such as image classification with textual prompts, visual question answering, or image generation from text.
VLM Applications:
- Visual Question Answering (VQA): Answering questions based on image content.
- Image Captioning: Generating textual descriptions of images.
- Multimodal Retrieval: Searching for relevant images based on a text query and vice versa.
- Visual Grounding: Associating specific textual elements with parts of an image.
Examples of VLMs:
- CLIP: Matches images and text by learning shared embeddings.
- LLaVA: Combines vision and language models for advanced understanding, including detailed image descriptions and reasoning.
VLMs for Document Data Extraction
VLMs have become essential for document data extraction. While large language models (LLMs) can handle this task to some extent, they often struggle due to a lack of spatial understanding. See this article for an analysis of LLMs for data extraction for closed source models.
With the rapid growth in VLMs, we are now entering a “golden age” for these models. VLMs can answer simple questions like “What is the invoice number in this document?” or tackle complex queries such as "give me every field in the current invoice as a single json along with the table data in the markdown format", thereby helping the user to extract detailed information from documents. In this blog, we’ll explore three closed-source and three open-source models across a couple of datasets to assess the current landscape and guide you in selecting the right VLM.
Open Source Models
We picked the following top performing models in VLMs based on their place in DocVQA, OCRBench and other benchmarks.
- Qwen2-VL-2B is one among a series of models that were trained on extremely large volume and high quality data. Covering over 29 languages the models were trained with a focus on diversity and resilience of system prompts.
- MiniCPM, according to the paper has - "strong performance, surpassing GPT-4V-1106, Gemini Pro, and Claude 3 on OpenCompass, with excellent OCR capability, high-resolution image perception, low hallucination rates, multilingual support for 30+ languages, and efficient mobile deployment."
- Bunny is family of models that focus on using data optimization and dataset condensation to train smaller yet more effective multimodal models without sacrificing performance.
Another reason we picked these models, is because these are some of the best models that can fit on a consumer GPU with 24GB VRAM.
Closed Source Models
For closed-source models, we selected GPT4oMini, Claude3.5, and Gemini1.5 to compare them with open-source models and evaluate how their open-source counterparts perform relative to them.
Datasets for Benchmarking
DocVQA, OCRBench, and XFUND are significant benchmarks for evaluating VLM performance across diverse domains but have limitations due to their focus on a single question per image. For document data extraction, it’s crucial to shift towards traditional datasets that include fields and table information. Although FUNSD offers a starting point, it handles information in a non-standardized manner, with each image having a unique set of questions, making it less suitable for consistent, standardized testing. Therefore, an alternative dataset that standardizes information handling and one which supports multiple questions per image is needed for more reliable evaluation in document data extraction tasks.
This is why we are going to use SROIE and CORD datasets which are simplistic in nature. The number of fields and table items is small and diverse enough for first cut validation.
SROIE - Scanned Receipt OCR and Information Extraction
SROIE is another representative dataset that effectively emulates the process of recognizing text from scanned receipts and extracting key information. It serves as a valuable gateway dataset, highlighting the critical roles in many document analysis applications with significant commercial potential.
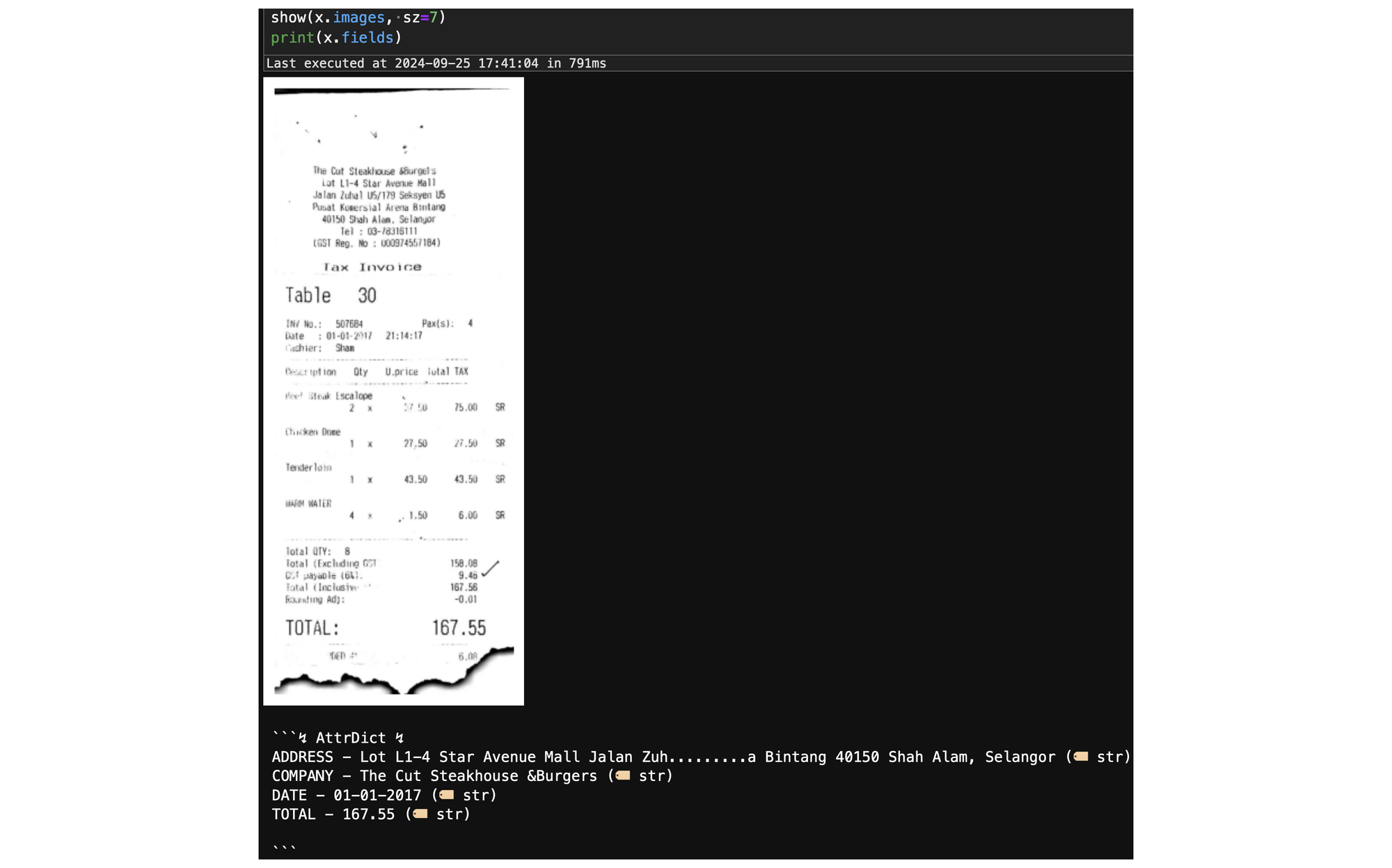
Specifically - We are going use the dataset from Task-3 - Key Information Extraction from Scanned Receipts, extracting the following four fields
- ADDRESS
- COMPANY
- DATE
- TOTAL
For all the VLMs we are going to send in the image of a receipt and ask the question -
"What are the ADDRESS,COMPANY,DATE,TOTAL in the given image. Give me as a json"
Prompt to extract the four fields from SROIE
There are ≈ 300 images in the test dataset and we are going to evaluate only on the first 100 of them.
CORD - Consolidated Receipt Dataset
This dataset is another well-representative example for information extraction, offering a variety of fields, including table fields, making it ideal for testing both field and table data extraction on a simple dataset. While there are more fields than listed below, we selected a subset that appears in at least 50% of the images.

Following are the fields being extracted -
- total_price
- cashprice
- changeprice
- subtotal_price
- tax_price
Like in SROIE, we will only consider a field accurate if it is a perfect match with ground truth.
The table fields are -
- nm - name of the item
- price - total price of all items combined
- cnt - quantity of the item
- unitprice - price of a single item
The names are somewhat obscure because that's how CORD has the ground truth labels.
Extract the following data from given image -
For tables I need a json of list of
dictionaries of following keys per dict (one dict per line)
'nm', # name of the item
'price', # total price of all the items combined
'cnt', # quantity of the item
'unitprice' # price of a single igem
For sub-total I need a single json of
{'subtotal_price', 'tax_price'}
For total I need a single json of
{'total_price', 'cashprice', 'changeprice'}
the final output should look like and must be JSON parsable
{
"menu": [
{"nm": ..., "price": ..., "cnt": ..., "unitprice": ...}
...
],
"subtotal": {"subtotal_price": ..., "tax_price": ...},
"total": {"total_price": ..., "cashprice": ..., "changeprice": ...}
}
If a field is missing,
simply omit the key from the dictionary. Do not infer.
Return only those values that are present in the image.
this applies to highlevel keys as well, i.e., menu, subtotal and totalPrompt to extract fields and table data from CORD dataset
We will be using the GRITS metric to compare the prediction tables with ground truth tables. GRITS returns a Precision, Recall and F-Score for every pair of tables, indicative of how many cells were perfectly predicted/missed/hallucinated.
- A low recall in GRITS indicates that the model is not able clearly identify what is in the image.
- A low precision indicates that the model is hallucinating, i.e., making up predictions which do not exist in the image.
Summary of Experiments
Here are the datasets and models being used -
| Datasets | Models |
|---|---|
| CORD (test split 100 images) | Qwen2 |
| SROIE (test split 100 images) | MiniCPM |
| Bunny | |
| ChatGPT-4o-Mini | |
| Claude 3.5 Sonnet | |
| Gemini Flash 1.5 |
And here we are presenting form-fields and the table-fields for both the datasets. The column indicates the metric used for each field.
| exact-match | table-precision (grits) | table-recall (grits) | table-fscore (grits) | |
|---|---|---|---|---|
| SROIE | ADDRESS | |||
| COMPANY | ||||
| DATE | ||||
| TOTAL | ||||
| CORD | total_price | |||
| cashprice | ||||
| changeprice | ||||
| subtotal_price | ||||
| tax_price | ||||
| nm | nm | nm | ||
| price | price | price | ||
| cnt | cnt | cnt | ||
| template | template | template |
Note that grits only returns precision, recall and fscore for a single (table-truth, table-prediction) pair, by aggregating results of all the columns in the table, i.e,. we'll not have a metric corresponding to each table column.
Code
Due to the repetitive nature of our task—i.e., running each VLM on the SROIE and CORD datasets—there's no point in showing every step. We will provide only the core VLM prediction code below, helping the reader to easily use the snippets for their own evaluations. In each section below, apart from the code, we will also have a short discussion on the qualitative performance as well as the apparent pros and cons of each model.
ChatGPT-4o-Mini
ChatGPT-4o-Mini is a closed-source variant of GPT-4, designed to deliver high performance with reduced computational resources, making it suitable for lightweight applications.
class GPT4oMini(VLM):
def __init__(self):
super().__init__()
from openai import OpenAI
self.client = OpenAI(os.environ.get('OPENAI_API_KEY'))
def predict(self, image, prompt, *, image_size=None, **kwargs):
img_b64_str, image_type = self.path_2_b64(image, image_size)
response = self.client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": prompt},
{
"type": "image_url",
"image_url": {"url": f"data:image/{image_type};base64,{img_b64_str}"},
},
],
}
],
)
return response.to_json()
@staticmethod
def get_raw_output(pred):
pred = json.loads(pred)
pred = pred['choices'][0]['message']['content']
return pred
Discussion
- Price per token - 0.15 $/1M (input) and 0.6 $/1M (output) - pricing details
- Average Prediction Time - 5.3s
- Total Amount spent for evaluation - 1.11 $
Pros - Overall, the accuracies were on par with Claude and Gemini but never ahead of them.
Cons - The prediction time was the slowest compared to all the models except Qwen2.
Gemini 1.5 Flash
Gemini 1.5 Flash is a high-performance vision-language model designed for fast and efficient multimodal tasks, leveraging a streamlined architecture for improved processing speed. It offers strong capabilities in visual understanding and reasoning, making it suitable for applications requiring quick predictions with minimal latency.
class Gemini(VLM):
def __init__(self, token=None):
super().__init__()
import google.generativeai as genai
genai.configure(api_key=token or os.environ.get('GEMINI_API_KEY'))
self.model = genai.GenerativeModel("gemini-1.5-flash")
def predict(self, image, prompt, **kwargs):
if isinstance(image, (str, P)):
image = readPIL(image)
assert isinstance(image, Image.Image), f'Received image of type {type(image)}'
response = self.model.generate_content([prompt, image])
# used to be response.text
return json.dumps(response.to_dict())
@staticmethod
def get_raw_output(pred):
pred = json.loads(pred)
pred = pred['candidates'][0]['content']['parts'][0]['text']
return pred
Discussion
- Gemini model refused to predict on a few images raising safety as concern. This happened on about 5% of the images in SROIE dataset.
- Price per token - 0.075 $/1M (input tokens) and 0.3 $/1M (output tokens) - pricing details
- Average Prediction Time - 3s
- Total Amount spent for evaluation - 0.00 $ (Gemini offers a Free Tier)
Pros - Overall the accuracies were a close second with Claude. Gemini was remarkable for its prediction speed, having the least hallucinations among the VLMs, i.e., the model was predicting exactly what was present in the image without any modifications. Finally a free tier was available for evaluating the model making the cost next to none, but on limited data only.
Cons - Model refuses to process certain images, which is unpredictable and not desirable at times.
Claude 3.5
class Claude_35(VLM):
def __init__(self, token=None):
super().__init__()
import anthropic
self.client = anthropic.Anthropic(api_key=token or os.environ['CLAUDE_API_KEY'])
def predict(self, image, prompt, max_tokens=1024, image_data=None):
image_data, image_type = self.path_2_b64(image)
message = self.client.messages.create(
model="claude-3-5-sonnet-20240620",
max_tokens=max_tokens,
messages = [
dict(role='user', content=[
dict(type='image', source=dict(type='base64', media_type=image_type, data=image_data)),
dict(type='text', text=prompt)
])
]
)
return message.to_json()
@staticmethod
def get_raw_output(pred):
pred = json.loads(pred)
pred = pred['content'][0]['text']
return pred
Discussion
- There are known issues with Claude, where it refuses to predict when it thinks there's copyright content - see the results section here for an example. No such issues occurred in our case.
- Price per token - 3 $/1M (input tokens) and 15 $/1M (output tokens) - pricing details
- Average Prediction Time - 4 s
- Total Amount spent for evaluation - 1.33$
Pros - Claude had the best performance across most of the fields and datasets.
Cons - Third slowest in prediction speed, Claude also has the disadvantage of being one of the costliest option among the VLMs. It also refuses to make some predictions, sometimes due to apparent copyright concerns.
QWEN2
class Qwen2(VLM):
def __init__(self):
super().__init__()
from transformers import Qwen2VLForConditionalGeneration, AutoTokenizer, AutoProcessor
# default: Load the model on the available device(s)
self.model = Qwen2VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen2-VL-2B-Instruct", torch_dtype="auto", device_map="auto"
)
min_pixels = 256*28*28
max_pixels = 1280*28*28
self.processor = AutoProcessor.from_pretrained("Qwen/Qwen2-VL-2B-Instruct", min_pixels=min_pixels, max_pixels=max_pixels)
def predict(self, image, prompt, max_new_tokens=1024):
from qwen_vl_utils import process_vision_info
img_b64_str, image_type = self.path_2_b64(image)
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": f"data:{image_type};base64,{img_b64_str}"
},
{"type": "text", "text": prompt},
],
}
]
# Preparation for inference
text = self.processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = self.processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# Inference: Generation of the output
generated_ids = self.model.generate(**inputs, max_new_tokens=max_new_tokens)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = self.processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
return output_text[0]
@staticmethod
def get_raw_output(pred):
return pred
Discussion
- Average Prediction Time - 8.73s
- GPU Memory Consumed - 6GB
- Total Amount spent for evaluation - 0.25$
(Assuming we used a machine of cost 0.5$ per hour.
The number of predictions were 200 - 100 each for SROIE and CORD)
Pros - The overall accuracies were the best among the three open VLMs. It consumed the least amount of VRAM among the 3 internal models, and this helps one to set up multiple workers on a consumer GPU, parallelizing multiple predictions at once.
Cons - The predictions were slowest among all, but this can be optimized with techniques such as flash-attention.
Bunny
class Bunny(VLM):
def __init__(self):
super().__init__()
import transformers, warnings
from transformers import AutoModelForCausalLM, AutoTokenizer
transformers.logging.set_verbosity_error()
transformers.logging.disable_progress_bar()
warnings.filterwarnings('ignore')
self.device = 'cuda' # or cpu
torch.set_default_device(self.device)
# create model
self.model = AutoModelForCausalLM.from_pretrained(
'BAAI/Bunny-v1_1-Llama-3-8B-V',
torch_dtype=torch.float16, # float32 for cpu
device_map=self.device,
trust_remote_code=True)
self.tokenizer = AutoTokenizer.from_pretrained(
'BAAI/Bunny-v1_1-Llama-3-8B-V',
trust_remote_code=True)
def predict(self, image, prompt):
# text prompt
text = f"A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: <image>\n{prompt} ASSISTANT:"
text_chunks = [self.tokenizer(chunk).input_ids for chunk in text.split('<image>')]
input_ids = torch.tensor(
text_chunks[0] + [-200] + text_chunks[1][1:],
dtype=torch.long
).unsqueeze(0).to(self.device)
# image, sample images can be found in images folder
if isinstance(image, (str,P)):
image = Image.open(image)
assert isinstance(image, PIL.Image.Image)
image_tensor = self.model.process_images(
[image],
self.model.config
).to(dtype=self.model.dtype, device=self.device)
# generate
output_ids = self.model.generate(
input_ids,
images=image_tensor,
max_new_tokens=100,
use_cache=True,
repetition_penalty=1.0 # increase this to avoid chattering
)[0]
output_text = self.tokenizer.decode(
output_ids[input_ids.shape[1]:],
skip_special_tokens=True
).strip()
return output_text
@staticmethod
def get_raw_output(pred):
return pred
Discussion
- Average Prediction Time - 3.37s
- GPU Memory Consumed - 18GB
- Total Amount spent for evaluation - 0.01$
(Same assumptions as those made in Qwen)
Pros - The predictions on some fields were leaps and bounds ahead of any other VLMs including closed models. One of the fastest among all VLM prediction times.
Cons - Predictions can vary significantly, from highly accurate to very poor across fields and datasets, depending on the input, making it unreliable as a general-purpose VLM. This can be alleviated by fine tuning on your own datasets.
MiniCPM-V2.6
class MiniCPM(VLM):
def __init__(self):
super().__init__()
from transformers import AutoModel, AutoTokenizer
model_id = 'openbmb/MiniCPM-V-2_6'
self.device = "cuda:0" if torch.cuda.is_available() else "cpu"
self.torch_dtype = torch.bfloat16 if torch.cuda.is_available() else torch.float32
self.model = AutoModel.from_pretrained(
model_id, trust_remote_code=True,
attn_implementation='sdpa', torch_dtype=self.torch_dtype
).to(self.device)
self.tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
def predict(self, image, prompt):
if isinstance(image, (P, str)):
image = Image.open(image).convert('RGB')
assert isinstance(image, PIL.Image.Image)
msgs = [{'role': 'user', 'content': [image, prompt]}]
res = self.model.chat(
image=None,
msgs=msgs,
tokenizer=self.tokenizer
)
return res
@staticmethod
def get_raw_output(pred):
return pred
Discussion
- Average Prediction Time - 5s
- GPU Memory Consumed - 20GB
- Total Amount spent for evaluation - 0.14$
(Same assumption as the one made in Qwen)
Pros - Results were reliable and consistent across both the datasets
Cons - High prediction time and GPU memory consumption. Need additional optimizations to bring down latency and footprint.
Aggregate Results
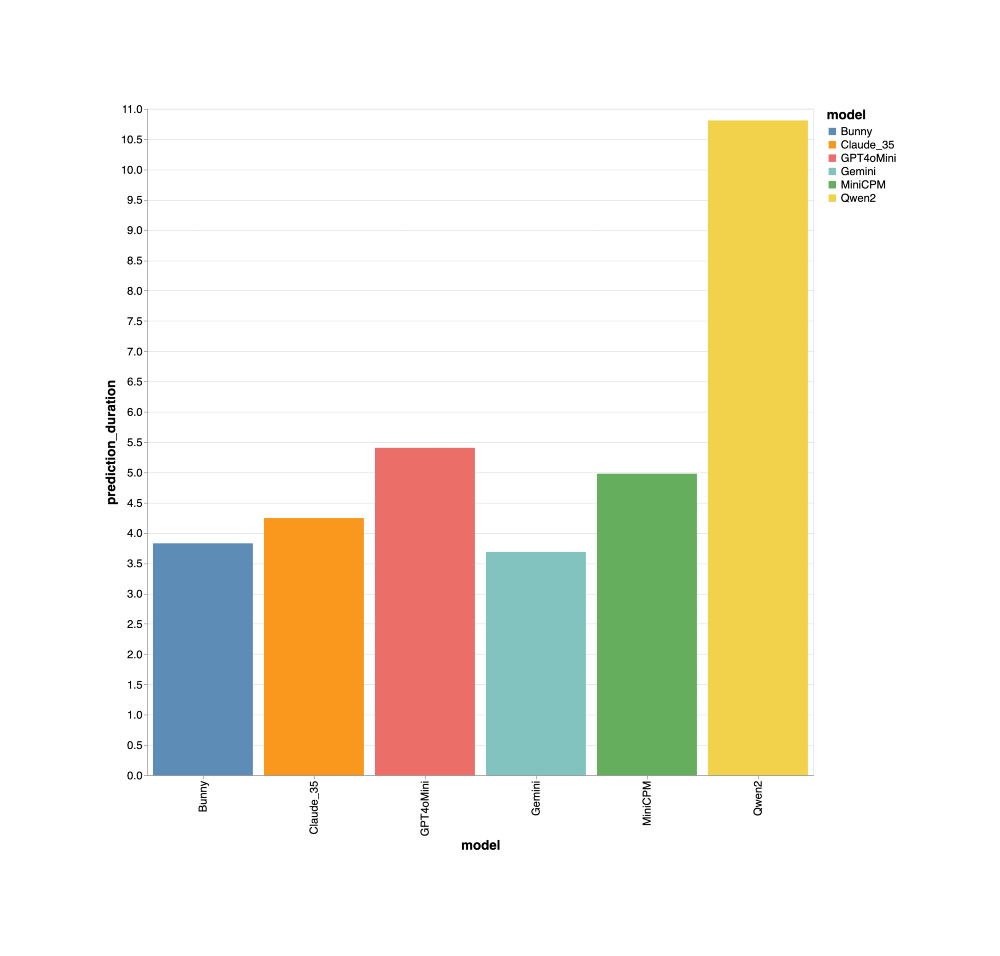
Prediction Time
We used vanilla models and APIs out of the box for our predictions. All the models were in similar ballpark range of 3 to 6s with Qwen as the exception.
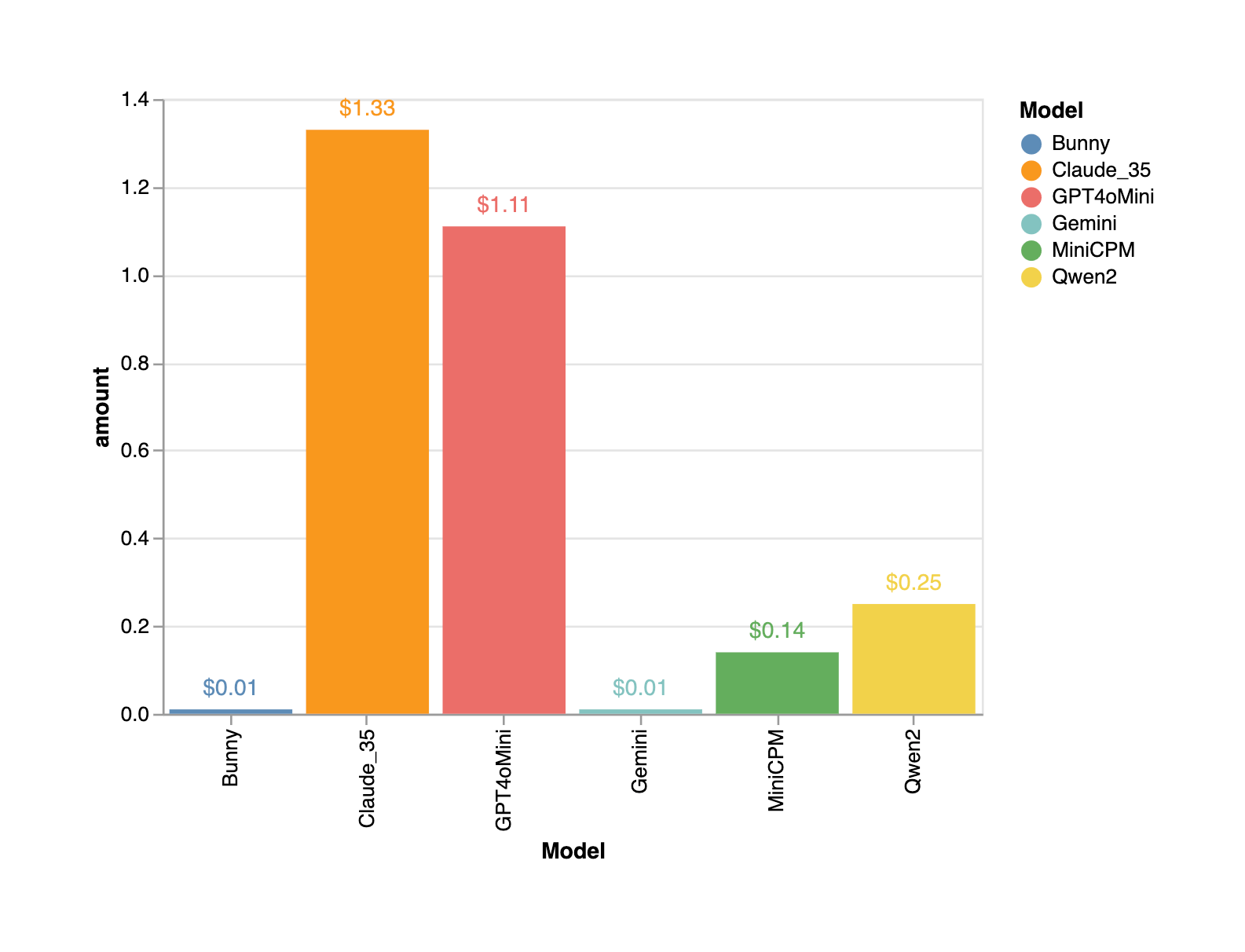
Prediction Cost
All the open source models along with Gemini (free tier) were cost effective for making predictions on all 200 images (100 CORD and 100 SROIE).
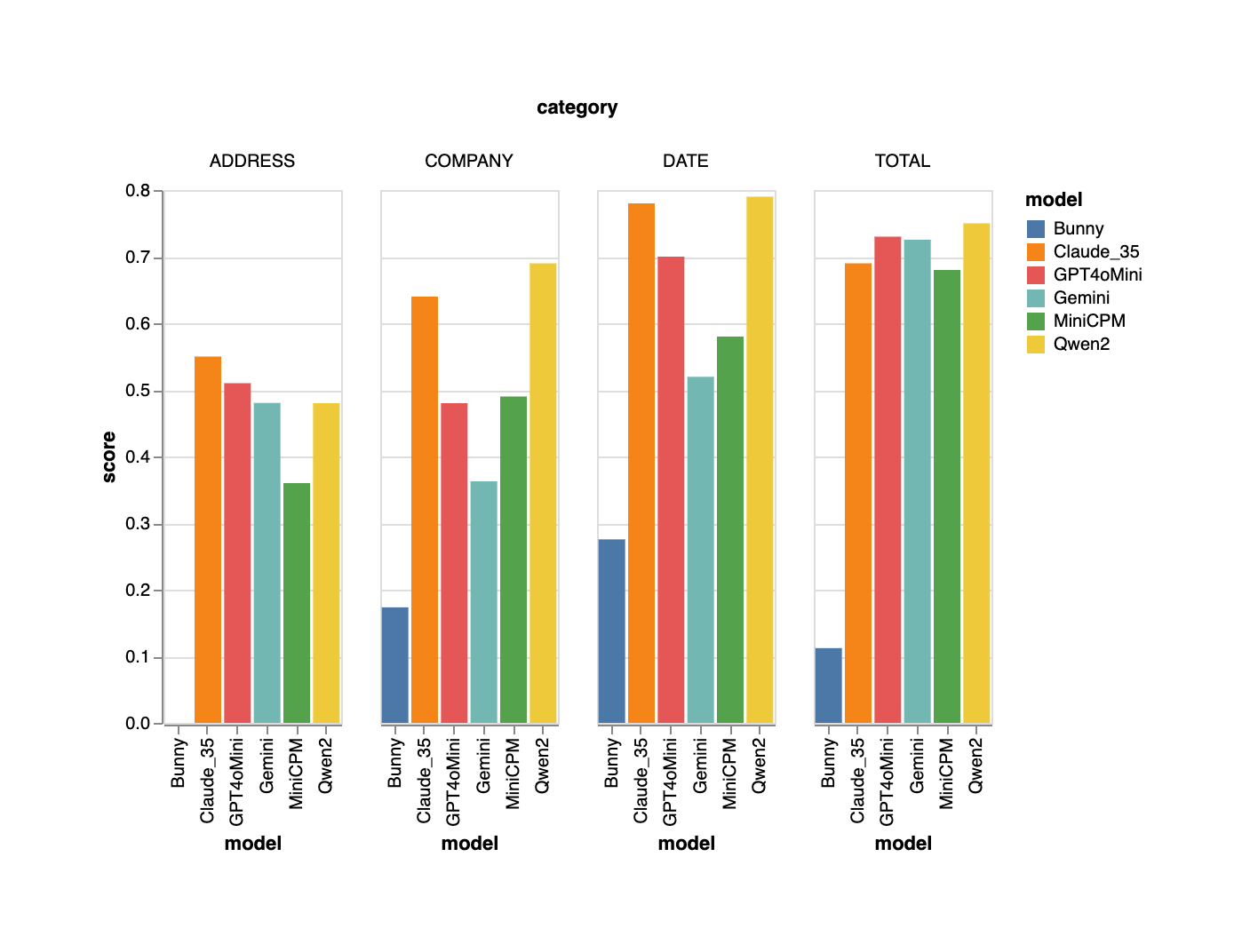
SROIE
Keep in mind that, this is a relatively simple dataset. Despite its simplicity none of the models were perfect in any of the fields. Qwen was the best by a good margin. In manual inspections, the author has observed a few ground truth errors and this implies that the actual accuracies will be somewhat higher than what are being reported.
Also, this graph clearly shows that open-source models are quickly closing the gap with proprietary models, particularly for simple, everyday use cases.
Field Metrics
CORD
There is a slight increase in complexity from SROIE in a few ways
- The content is more packed and each image has more information in general.
- There are more fields to be predicted
- There's table prediction
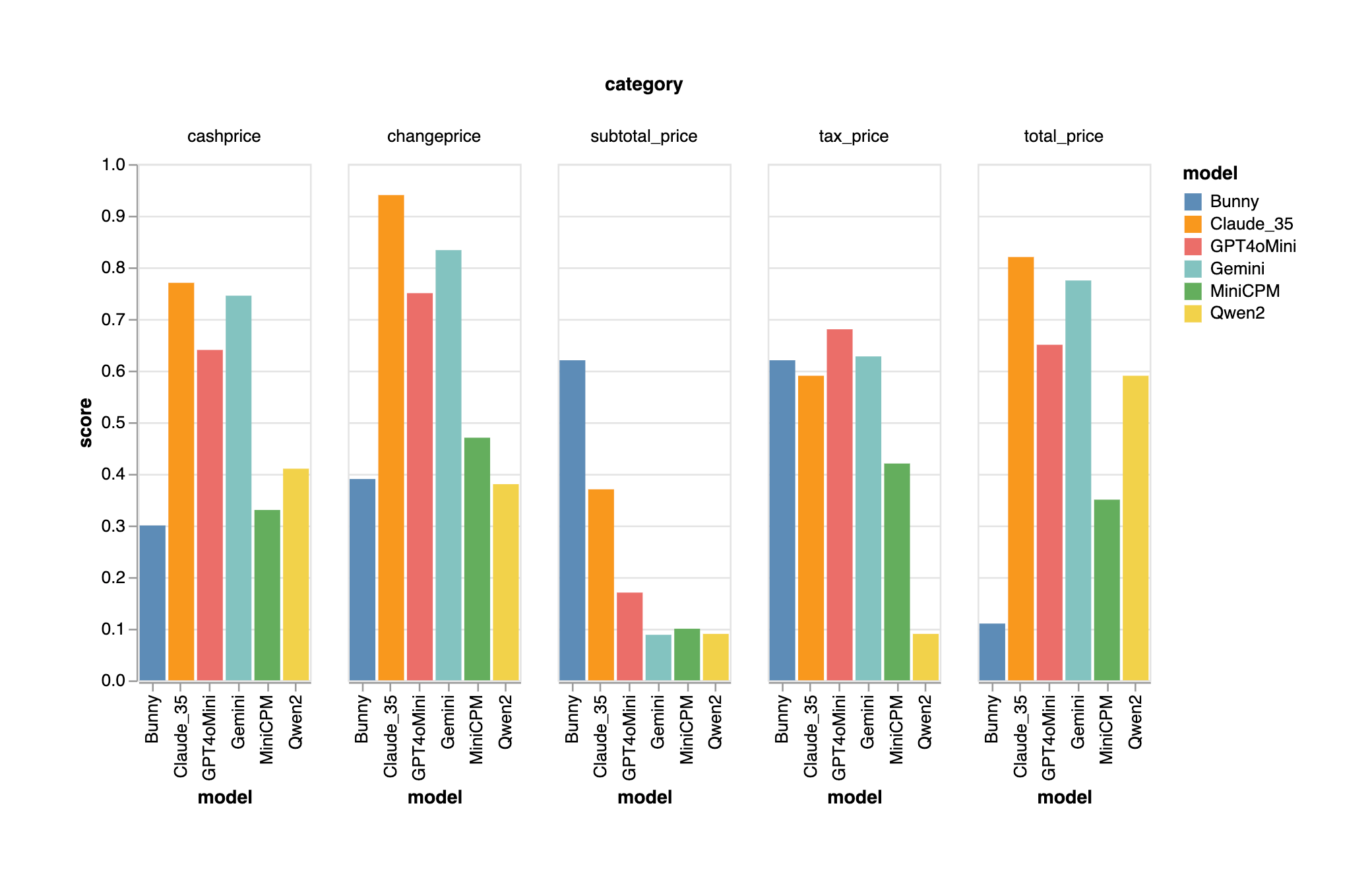
The Open Source VLMs are clearly showing their limitation in this dataset. Claude 3.5 is out performing the rest. Bunny is a curious case where the subtotal_price accuracy way ahead of others.
Field Metrics
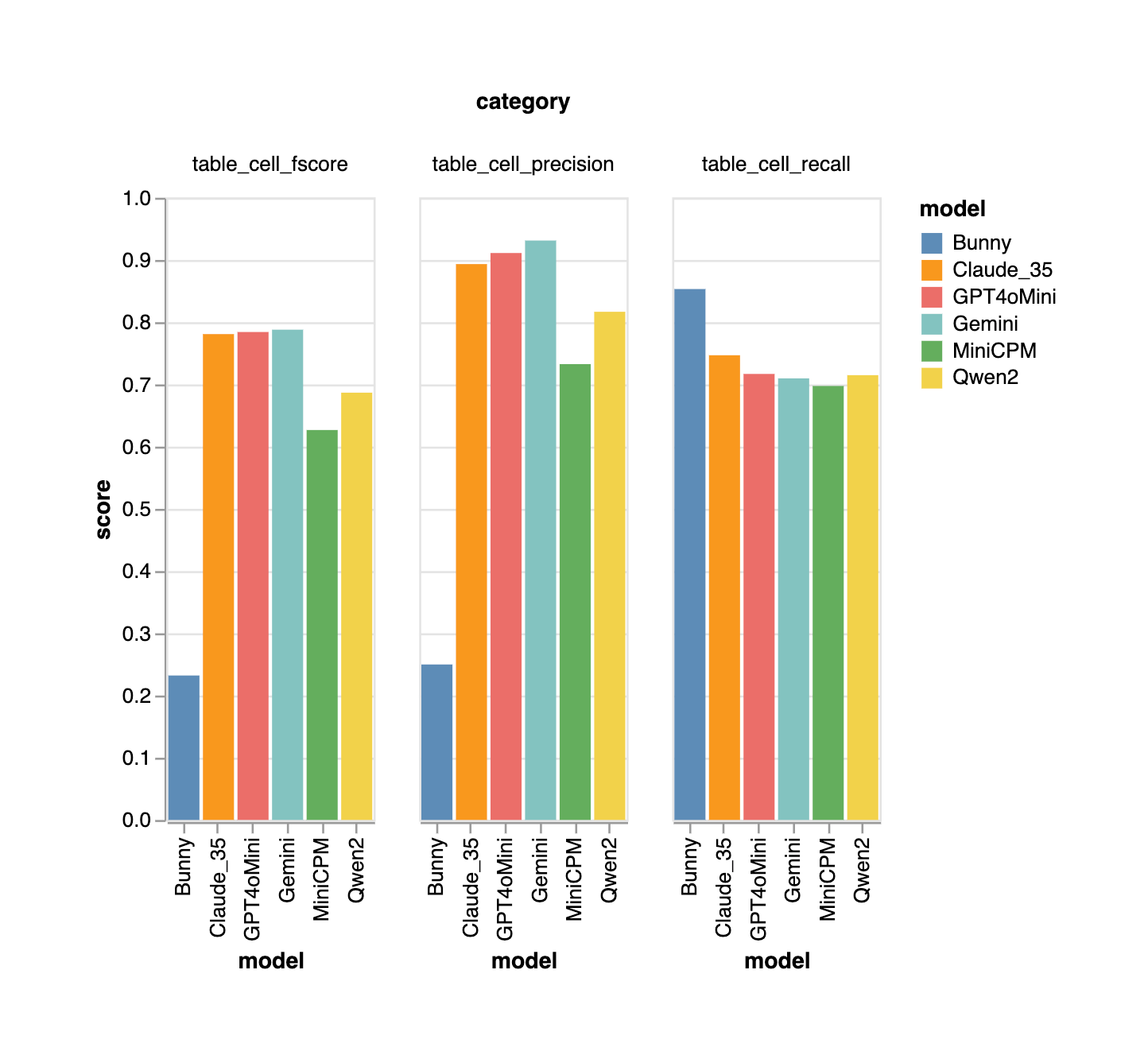
We also see the same for table metrics. Bunny's high recall suggests that it's able to read the OCR content properly but the low precision is indicative of it's limited reasoning capacity, leading to it returning random hallucinated data.
Table Metrics
All VLMs are in a similar ball park with closed source models edging out on open source variants in the precision score, indicating that these open source models are susceptible to hallucination and need to be further fine tuned to gain benefits.
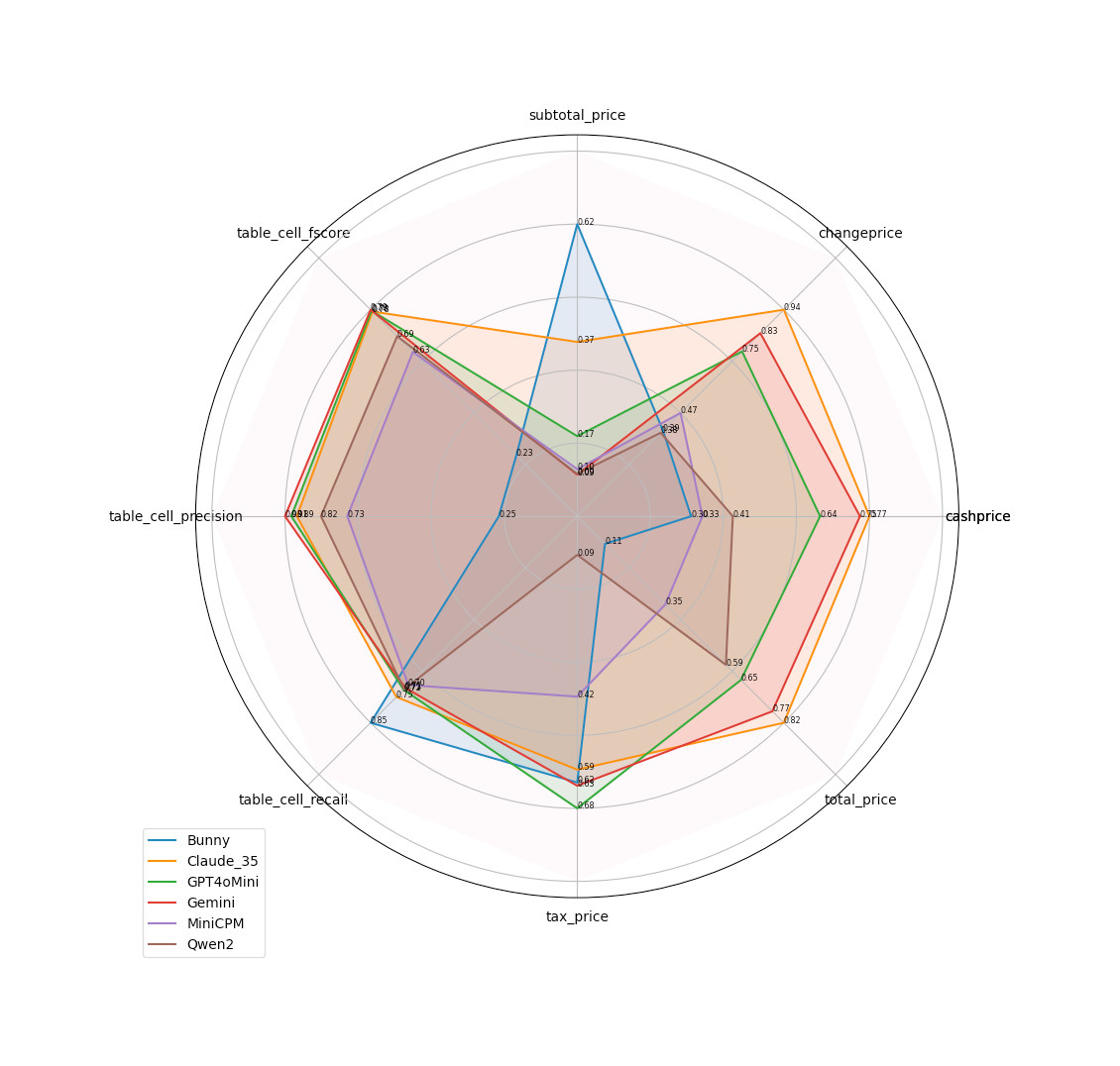
The same field and table metrics can be summarized using a spider/radar chart to give a holistic view of all the VLMs across all the fields in one glance.
Conclusion
We discussed what a VLM is to begin with and understood its importance in data extraction on documents. We went through 6 VLMs on 2 data extraction datasets to assess them for accuracies across table and fields. Each VLM was put through the same set of images and prompts so as to make reliable apples to apples comparisons.
Overall, we can conclude that Qwen is the best option for open source models while Gemini's free tier is the most cost effective option for short term.
There are pros and cons of each model and it's important to keep the following in mind before evaluating VLMs for data extraction on your own dataset.
- Prompts need to be carefully evaluated for maximum efficiency and minimal hallucination.
- Error Analysis will provide ideas on how to tweak the prompts and fix the ground truth issues. For example the below response from an VLM indicates that there's a possibility of VLM returning several jsons and it's important to ask for a single json in the prompt.
{
"menu": [
{"nm": "BLACK SAKURA", "price": 45.455, "cnt": 1, "unitprice": 45.455},
{"nm": "COOKIE DOH SAUCES", "price": 0, "cnt": 1, "unitprice": 0},
{"nm": "NATA DE COCO", "price": 0, "cnt": 1, "unitprice": 0}
]
}
```
For sub-total:
```json
{
"subtotal_price": 45.455,
"tax_price": 4.545
}
```
For total:
```json
{
"total_price": 50000,
"cashprice": 50000,
"changeprice": 0
}
```
So, the final output should be:
```json
{
"menu": [
{"nm": "BLACK SAKURA", "price": 45.455, "cnt": 1, "unitprice": 45.455},
{"nm": "COOKIE DOH SAUCES", "price": 0, "cnt": 1, "unitprice": 0},
{"nm": "NATA DE COCO", "price": 0, "cnt": 1, "unitprice": 0}
],
"subtotal": {
"subtotal_price": 45.455,
"tax_price": 4.545
},
"total": {
"total_price": 50000,
"cashprice": 50000,
"changeprice": 0
}
}
```
Sample result from MiniCPM where it gave a different json for each field group, thereby wasting precious tokens and compute.
- One can argue that evaluating the right prompt in itself can become a benchmarking task, but this should be taken up after zeroing on a good model.
- As seen in Bunny's precision in table metrics chart, poor prompts may lead to hallucinations. This is a waste of both time and cost since every hallucinated token generated is a penny wasted.
- Speaking of pennies, closed source models cannot be compared with each other on price per token. Each model's definition of a token is different. Ultimately what matters is the amount spent on prediction of a fixed number of images with the same set of prompts.
- The price for open source models is the price of the machine being used in question. One can compute the cost of a VLM by multiplying the average time in seconds per prediction and cost of the machine in dollars per second to arrive at dollars per prediction assuming 100% occupancy by the GPU. This way it is easy to compare the costs of closed source models with open source models.
- One more important consideration during evaluation is caching of inputs and outputs. It's tempting for a data scientist to store the results as a list of strings in a text file or as a json. But it's better to use a dedicated database. Proper caching gives the business several benefits
- Avoid repetition of VLM calls on same (vlm, image, prompt) combination thereby saving on API and GPU costs.
- Allowing several developers collaborate on a single source of truth
- Allowing developers to access all past experiments any time.
- Helping with auto-resume functionality during down times and when switching between machines.
- Compute API/GPU prices after predictions take place. This is possible when caching includes number of prompt tokens and time taken for prediction.
- Helping with regression analysis on newly trained VLMs, ensuring that new models' predictions are actually better than old versions.
- When latency of an open source model is not satisfactory, it is important to optimize it using techniques such as quantization, flash attention, xformer, rope scaling, multipacking, liger kernel etc. It's easier to use standard libraries such as huggingface to get such features out of the box.
- Note that we have tried only with very small VLMs with the constraint of being able to predict with 24GB VRAM or less. Based on requirements and budget, one can switch to medium and larger variants. For example we have used Qwen's Qwen2-VL-2B-Instruct for testing but there are also 7B and 72B variants which are guaranteed to give better results at the cost of more compute resources.
- Ultimately what matters is the accuracy across any model, closed or open. A good metric function should be the final arbiter to influence your choice of VLM for that business need.