
In today's data-driven world, forms are everywhere, and form data extraction has become crucial. These documents collect information efficiently but often require manual processing. That's where intelligent document processing (IDP) comes in.
IDP leverages OCR, AI, and ML to automate form processing, making data extraction faster and more accurate than traditional methods. It's not always straightforward — complex layouts and designs can make it challenging. But with the right tools, you can extract data from online and offline forms effectively and with fewer errors.
Take PDF forms, for example. They're great for collecting contact info, but extracting that data can be tricky and expensive. Extraction tools solve this, allowing you to easily import names, emails, and other details into formats like Excel, CSV, JSON, and other structured data formats.
This blog post will explore different scenarios and techniques for extracting data from forms using OCR and Deep Learning.
This is a subset of automated data extraction workflows applied to forms.
What is Form Data Extraction?
Form data extraction transforms raw form data into actionable insights. This intelligent process doesn't just read forms; it understands them. It uses advanced algorithms to identify, capture, and categorize information from various form types.

Key components include:
- Optical Character Recognition (OCR): Converts images of text into machine-readable text.
- Intelligent Character Recognition (ICR): Recognizes handwritten characters.
- Natural Language Processing (NLP): Understands the context and meaning of extracted text.
- Machine Learning: Improves accuracy over time by learning from new data.
These technologies work together to extract data and understand it. In healthcare, for example, an AI-powered extraction tool can process patient intake forms, distinguishing between symptoms, medications, and medical history. It can flag potential drug interactions or alert staff to critical information, all while accurately populating the hospital's database.
Read About: Data Extraction from SEC Forms
Types of Forms and Data That Can Be Extracted
Form data extraction can be applied to a wide variety of document types. It's versatile and adaptable to numerous industries and document types. Here are some common examples:
- Invoices and Receipts: Businesses can automatically extract total amounts, item details, dates, and vendor information, streamlining their accounts payable processes.
- Applications and Surveys: HR departments and market researchers can quickly capture personal information, preferences, and responses to questions.
- Medical Forms: Healthcare providers can efficiently extract data from medical reports, medical history, and insurance information, improving patient care and billing accuracy.
- Legal Documents: Law firms can identify key clauses, dates, and parties involved in contracts or agreements, saving valuable time in document review.
- Financial Statements: Banks and financial institutions can extract account numbers, transaction details, and balances, enhancing their analysis and reporting capabilities.
- Tax Forms: Accounting firms can capture income details, deductions, and tax calculations, speeding up tax preparation processes.
- Employment Records: HR departments can extract employee information, job details, and performance data, facilitating better workforce management.
- Shipping and Logistics Forms: Logistics companies can capture order details, addresses, and tracking information, optimizing their supply chain operations.
The data extracted can include text (both typed and handwritten), numbers, dates, checkbox selections, signatures, and even barcodes or QR codes. Modern automated form processing systems can handle both structured forms with fixed layouts and semi-structured documents where information appears in varying locations.
This wide applicability makes form data extraction so valuable across industries. But with such diversity comes challenges, which we'll explore next.
Read More: How to Automate Data Extraction from Contracts?
What Makes Form Data Extraction Challenging?
Data extraction presents a fascinating challenge. For one, it is an image recognition problem, but it also has to consider the text that may be present in the image and the layout of the form. This complexity makes building an algorithm more complex.
In this section, we'll explore the common hurdles faced when building form data extraction algorithms:
- Data Diversity: Forms come in countless layouts and designs. Extraction tools must handle various fonts, languages, and structures, making it difficult to create a one-size-fits-all solution.
- Lack of Training Data: Deep learning algorithms rely on vast amounts of data to achieve state-of-the-art performance. Finding consistent and reliable datasets is crucial for any form of data extraction software or tool. For example, when dealing with multiple form templates, these algorithms should understand a wide range of forms, requiring training on a robust dataset.
- Handling Fonts, Languages, and Layouts: The variety of typefaces, designs, and templates can make accurate recognition challenging. It's important to limit the font collection to a particular language and type for smoother processing. In multilingual cases, juggling characters from multiple languages needs careful preparation.

- Orientation and Skew: Scanned images can appear skewed, which can reduce the accuracy of the model. Techniques like Projection Profile methods or Fourier Transformation can help address this issue. Although orientation and skewness might seem like simple mistakes, they can significantly impact the model's accuracy when dealing with large volumes of forms.

- Data Security: When extracting data from various sources, it's crucial to be aware of security measures. Otherwise, you risk compromising sensitive information. This is particularly important when working with ETL scripts and online APIs for data extraction.
- Table Extraction: Extracting data from tables within forms can be complex. Ideally, a form extraction algorithm should handle both form-data and table data efficiently. This often requires separate algorithms, which can increase computational costs.

- Post Processing and Exporting Output: The extracted data often requires further processing to filter results into a more structured format. Organizations may need to rely on third-party integrations or develop APIs to automate this process, which can be time-consuming.

By addressing these challenges, intelligent document processing systems can significantly improve the accuracy and efficiency of form data extraction, turning complex documents into valuable, actionable data.
Benefits of Automated Form Data Extraction
Now imagine if you could easily process mortgage applications, tax forms, and medical records, each with its unique structure, without needing to create separate rules for each format.
Within seconds, all the relevant data—names, addresses, financial details, medical information—is extracted, organized into a structured format, and populated into your database. That’s what automated form processing can help achive.
Let's look at its other key benefits:
- Increased Efficiency: Process hundreds of forms in minutes, not hours. Reallocate staff to high-value tasks like data analysis or customer service.
- Improved Accuracy: Reduce data errors by eliminating manual entry. Ensure critical information like patient data or financial figures is captured correctly.
- Cost Savings: Cut data processing costs significantly. Eliminate expenses related to paper storage and manual data entry.
- Enhanced Data Accessibility: Instantly retrieve specific information from thousands of forms. Enable real-time reporting and faster decision-making.
- Scalability: Handle sudden spikes of forms without hiring temporary staff. Process 10 or 10,000 forms with the same system and similar turnaround times.
- Improved Compliance: Maintain consistent data handling across all forms. Generate audit trails automatically for regulatory compliance.
- Better Customer Experience: Reduce wait times for form-dependent processes like loan approvals or insurance claims from days to hours.
- Environmental Impact: Decrease paper usage significantly. Reduce physical storage needs and associated costs.
- Integration Capabilities: Automatically populate CRM, ERP, or other business systems with extracted data. Eliminate manual data transfer between systems.
These benefits demonstrate how automated form processing can transform document handling from a bottleneck into a strategic advantage.
Handling Different Types of Form Data
Every form presents unique challenges for data extraction, from handwritten entries to intricate table structures. Let's explore four real-world scenarios that showcase how advanced extraction techniques tackle challenges like handwriting, checkboxes, changing layouts, and complex tables.
Scenario #1: Handwritten Recognition for Offline Forms
Offline forms are common in daily life. Manually digitalizing these forms can be hectic and expensive, which is why deep learning algorithms are needed. Handwritten documents are particularly challenging due to the complexity of handwritten characters.
Data recognition algorithms learn to read and interpret handwritten text. This process, often referred to as handwriting to text conversion, involves scanning images of handwritten words and converting them into data that can be processed and analyzed. The algorithm creates a character map based on strokes and recognizes corresponding letters to extract the text.

Scenario #2: Checkbox Identification on Forms
Checkbox forms are used to gather information from users in input fields. They're common in lists and tables requiring users to select one or more items. Modern algorithms can automate the data extraction process, even from checkboxes, through checkbox detection.
The primary goal is to identify input regions using computer vision techniques. These involve identifying lines (horizontal and vertical), applying filters, contours, and detecting edges on the images. After the input region is identified, it's easier to extract the checkbox contents, whether marked or unmarked.

Scenario #3: Layout Changes of the form from time to time
Form layouts can change depending on the type and context. Therefore, it's essential to build an algorithm that can handle multiple unstructured documents and intelligently extract content based on form labels.
One popular technique is the use of Graph Convolutional Networks (GCNs). GCNs ensure that neuron activations are data-driven, making them suitable for recognizing patterns in diverse form layouts.
Scenario #4: Table Cell Detection
Some forms consist of table cells, which are rectangular areas inside a table where data is stored. An ideal extraction algorithm should identify all types of cells (headers, rows, or columns) and their boundaries to extract data from them.
Popular techniques for table extraction include Stream and Lattice algorithms, which can help detect lines, shapes, and polygons using simple isomorphic operations on images.
These scenarios highlight the diverse challenges in form data extraction. Each task demands advanced algorithms and flexible solutions. As technology progresses, we're developing more efficient and accurate extraction processes. Ultimately, the goal here is to build intelligent systems that can handle any document type, layout, or format, seamlessly extracting valuable information.
The Evolution of Form Data Extraction Solutions
Form data extraction has its origins in the pre-computer era of manual form processing. As technology advanced, so did our ability to handle forms more efficiently.
Today, we see a version of the form data extraction software that is highly accurate and fast and delivers the data in a highly organized and structured manner. Now, let's briefly discuss different types of form data extraction techniques.
- Rule-based From Data Extraction: This technique automatically extracts data from particular template forms. It works by examining fields on the page and deciding which to extract based on surrounding text, labels, and other contextual clues. These algorithms are usually developed and automated using ETL scripts or web scraping. However, when they are tested on unseen data, they fail entirely.
- Template Matching for Digital Images: While similar to rule-based extraction, template matching takes a more visual approach to data extraction. It uses predefined visual templates to locate and extract data from forms with fixed layouts. This is effective for processing highly similar forms, such as standardized applications or surveys. However, it requires careful template creation and regular maintenance.
- Form Data Extraction using OCR: OCR is a go-to solution for any form of data extraction problem. It works by reading each pixel of an image with text and comparing it to corresponding letters. However, OCR can face challenges with handwritten text or complex layouts. For example, when the notes are close together or overlap, such as "a" and "e." Therefore, these may not work when we are extracting offline forms.
- NER for Form Data Extraction: It identifies and classifies predefined entities in text. It's useful for extracting information from forms where people input names, addresses, comments, etc. Modern NER models leverage pre-trained models for information extraction tasks.

- Deep Learning for Form Data Extraction: Recent advances in deep learning have led to breakthrough results, with models achieving top performance in various formats. Training deep neural networks on large datasets enables them to understand complex patterns and connections, such as identifying entities like names, emails, and IDs from image-form labels. However, building a highly accurate model requires significant expertise and experimentation.
Building on these deep learning advancements, Intelligent Document Processing (IDP) has emerged as a comprehensive approach to form data extraction. IDP combines OCR, AI, and ML to automate form processing, making intelligent data extraction faster and more accurate than traditional methods.
It can handle both structured and unstructured documents, adapt to various layouts, and continuously improve its performance through machine learning. For businesses dealing with diverse document types, IDP offers a scalable solution that can significantly streamline document-heavy processes.
Form Data Extraction Using OCRs
There are many different libraries available for extracting data from forms. But what if you want to extract data from an image of a form? This is where Tesseract OCR (Optical Character Recognition) comes in.
Tesseract is an open-source OCR engine developed by HP. Using Tesseract OCR, you can convert scanned documents such as paper invoices, receipts, and checks into searchable, editable digital files. It's available in several languages and can recognize characters in various image formats. Tesseract is typically used in combination with other libraries to process images to extract text.
Want to try it out yourself? Here's how:
- Install Tesseract on your local machine.
- Choose between Tesseract CLI or Python bindings for running the OCR.
- If using Python, consider Python-tesseract, a wrapper for Google's Tesseract-OCR Engine.
Python-tesseract can read all image types supported by the Pillow and Leptonica imaging libraries, including jpeg, png, gif, bmp, tiff, and others. You can easily use it as a stand-alone invocation script to Tesseract if needed.
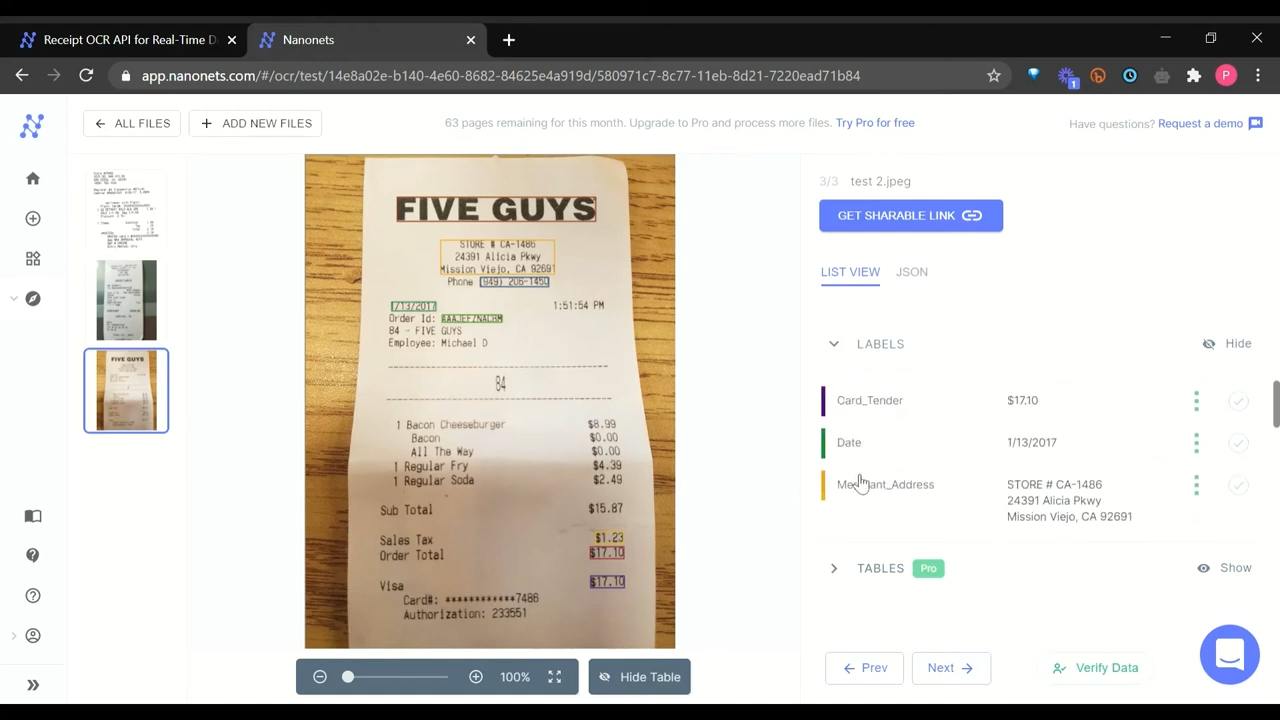
Let's take a practical example. Say you have a receipt containing form data. Here's how you can identify the location of the text using Computer Vision and Tesseract:
import pytesseract
from pytesseract import Output
import cv2
img = cv2.imread('receipt.jpg')
d = pytesseract.image_to_data(img, output_type=Output.DICT)
n_boxes = len(d['level'])
for i in range(n_boxes):
(x, y, w, h) = (d['left'][i], d['top'][i], d['width'][i], d['height'][i])
img = cv2.rectangle(img, (x, y), (x + w, y + h), (0, 0, 255), 2)
cv2.imshow(img,'img')
Here, in the output, as we can see, the program was able to identify all the text inside the form. Now, let’s apply OCR to this to extract all the information. We can simply do this by using the image_to_string function in Python.
extracted_text = pytesseract.image_to_string(img, lang = 'deu')
Output:
Berghotel
Grosse Scheidegg
3818 Grindelwald
Familie R.Müller
Rech.Nr. 4572 30.07.2007/13:29: 17
Bar Tisch 7/01
2xLatte Macchiato &ä 4.50 CHF 9,00
1xGloki a 5.00 CH 5.00
1xSchweinschnitzel ä 22.00 CHF 22.00
IxChässpätz 1 a 18.50 CHF 18.50
Total: CHF 54.50
Incl. 7.6% MwSt 54.50 CHF: 3.85
Entspricht in Euro 36.33 EUR
Es bediente Sie: Ursula
MwSt Nr. : 430 234
Tel.: 033 853 67 16
Fax.: 033 853 67 19
E-mail: grossescheidegs@b luewin. Ch
Here we’re able to extract all the information from the form. However, in most cases, using just OCR will not help as the data extracted will be completely unstructured. Therefore, users rely on key-value pair extraction on forms, which can only identify specific entities such as ID, Dates, Tax Amount, etc.
This is only possible with deep learning. In the next section, let’s look at how we can leverage different deep-learning techniques to build information extraction algorithms.
Read About: Best Practices for Deep Learning
Solving Form Data Extraction Using Deep Learning
Let's explore three cutting-edge deep learning approaches to form data extraction: Graph Convolutional Networks (GCNs), LayoutLM, and Form2Seq. We'll break down how these techniques work and why they're more effective at handling real-world form processing challenges than traditional approaches.
1. Graph Convolution for Multimodal Information Extraction from Visually Rich Documents
Graph Convolutional Networks (Graph CNNs) are a class of deep convolutional neural networks (CNNs) capable of effectively learning highly non-linear features in graph data structures while preserving node and edge structure. They can take graph data structures as input and generate 'feature maps' for nodes and edges. The resulting features can be used for graph classification, clustering, or community detection.
GCNs provide a powerful solution to extracting information from large, visually rich documents like invoices and receipts. To process these, each image must be transformed into a graph comprised of nodes and edges. Any word on the image is represented by its own node; visualization of the rest of the data is encoded in the node's feature vector.

This model first encodes each text segment in the document into graph embedding. Doing so captures the visual and textual context surrounding each text element, along with its position or location within a block of text. It then combines these graphs with text embeddings to create an overall representation of the document's structure and its content.
The model learns to assign higher weights on texts that are likely to be entities based on their locations relative to one another and the context in which they appear within a larger block of readers. Finally, it applies a standard BiLSTM-CRF model for entity extraction. The results show that this algorithm outperforms the baseline model (BiLSTM-CRF) by a wide margin.
2. LayoutLM: Pre-training of Text and Layout for Document Image Understanding
The architecture of the LayoutLM model is heavily inspired by BERT and incorporates image embeddings from a Faster R-CNN. LayoutLM input embeddings are generated as a combination of text and position embeddings, then combined with the image embeddings generated by the Faster R-CNN model.
Masked Visual-Language Models and Multi-Label Document Classification are primarily used as pretraining tasks for LayoutLM. The LayoutLM model is valuable, dynamic, and strong enough for any job requiring layout understanding, such as form/receipt extraction, document image classification, or even visual question answering.
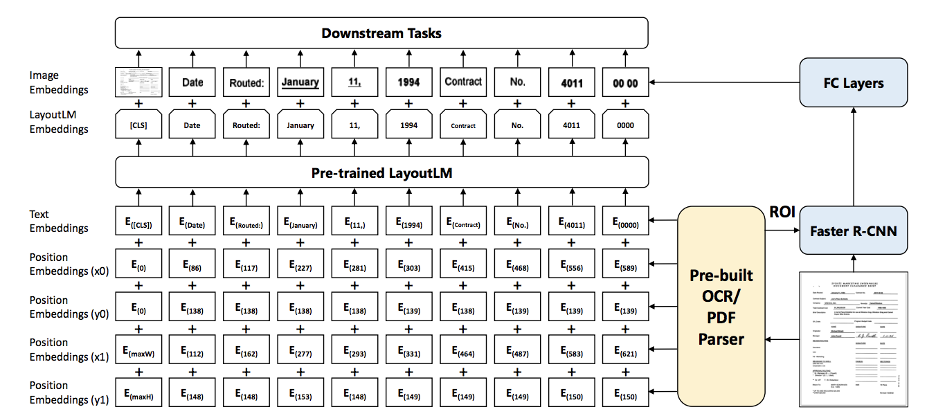
The LayoutLM model was trained on the IIT-CDIP Test Collection 1.0, which includes over 6 million documents and more than 11 million scanned document images totalling over 12GB of data. This model has substantially outperformed several state-of-the-art pre-trained models in form understanding, receipt understanding, and scanned document image classification tasks.
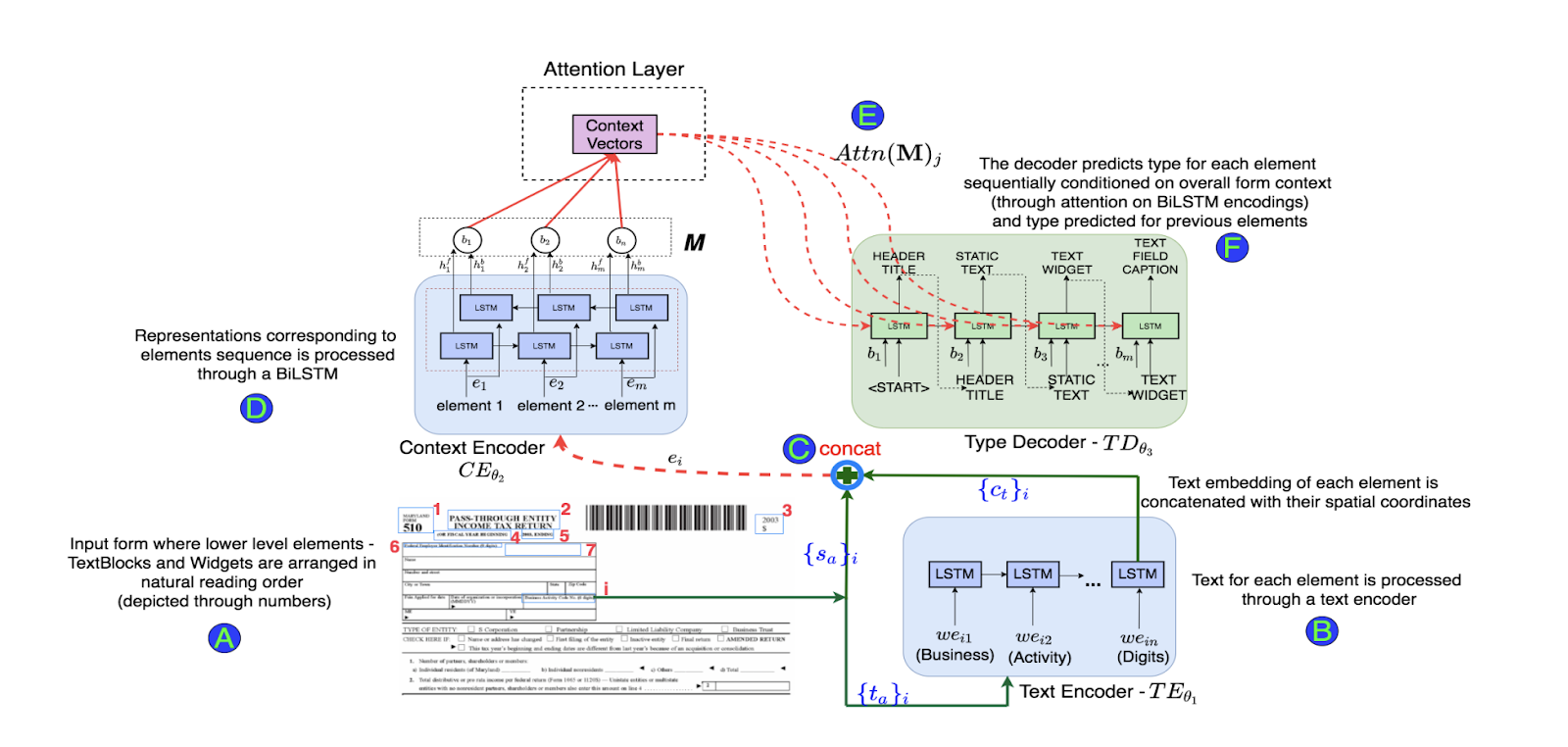
3. Form2Seq: A Framework for Higher-Order Form Structure Extraction
Form2Seq is a framework that focuses on extracting structures from input text using positional sequences. Unlike traditional seq2seq frameworks, Form2Seq leverages relative spatial positions of the structures, rather than their order.
In this method, first, we classify low-level elements that will allow for better processing and organization. There are 10 types of forms, such as field captions, list items, and so on. Next, we group lower-level elements, such as Text Fields and ChoiceFields, into higher-order constructs called ChoiceGroups.
These are used as information collection mechanisms to achieve better user experience. This is possible by arranging the constituent elements in a linear order in natural reading order and feeding their spatial and textual representations to the Seq2Seq framework. The Seq2Seq framework sequentially makes predictions for each element of a sentence depending on the context. This allows it to process more information and arrive at a better understanding of the task at hand.
The model achieved an accuracy of 90% on the classification task, which was higher than that of segmentation based baseline models. The F1 on text blocks, text fields and choice fields were 86.01%, 61.63% respectively. This framework achieved the state of the results on the ICDAR dataset for table structure recognition.
Best Practices for Implementing Form Data Extraction
Now that we've explored advanced techniques like Graph CNNs, LayoutLM, and Form2Seq, the next step is to consider best practices for implementing form data extraction in real-world scenarios.
Here are some key considerations:
Data Preparation
Ensure a diverse dataset of form images, covering various layouts and styles.
- Include samples of all form types you expect to process
- Consider augmenting your dataset with synthetic examples to increase diversity
Pre-processing
Implement robust image preprocessing techniques to handle variations in quality and format.
- Develop methods for denoising, deskewing, and normalizing input images
- Standardize input formats to streamline subsequent processing steps
Model Selection
Choose an appropriate model based on your specific use case and available resources.
- Consider factors like form complexity, required accuracy, and processing speed
- Evaluate trade-offs between model sophistication and computational requirements
Fine-tuning
Adapt pre-trained models to your specific domain for improved performance.
- Use transfer learning techniques to leverage pre-trained models effectively
- Iteratively refine your model on domain-specific data to enhance accuracy
Post-processing
Implement error-checking and validation steps to ensure accuracy.
- Develop rule-based systems to catch common errors or inconsistencies
- Consider implementing a human-in-the-loop approach for critical or low-confidence extractions
Scalability
Design your pipeline to handle large volumes of forms efficiently.
- Implement batch processing and parallel computation where possible
- Optimize your infrastructure to handle peak loads without compromising performance
Continuous Improvement
Regularly update and retrain your models with new data.
- Establish a feedback loop to capture and learn from errors or edge cases
- Stay informed about advancements in form extraction techniques and incorporate them as appropriate.
These best practices can help maximize the effectiveness of your form data extraction system, ensuring it delivers accurate results at scale. However, implementing these practices can be complex and resource-intensive.
That's where specialized solutions like Nanonets' AI-based OCR come in. The platfom incorporates many of these best practices, offering a powerful, out-of-the-box solution for form data extraction.
Why Nanonets AI-Based OCR is the Best Option
Though OCR software can convert scanned images of text to formatted digital files such as PDFs, DOCs, and PPTs, it is not always accurate. Nanonets offers a best-in-class AI-based OCR deep learning that tackles the limitations of conventional methods head-on. The platform offer superior accuracy in creating editable files from scanned documents, helping you streamline your workflow and boost productivity.

1. Tackling Your Accuracy Woes
Imagine processing invoices with high-accuracy, regardless of font styles or document quality. Nanonets' system is designed to handle:
- Diverse fonts and styles
- Skewed or low-quality scans
- Documents with noise or graphical elements
By potentially reducing errors, you could save countless hours of double-checking and corrections.
2. Adapting to Your Diverse Document Types
Does your work involve a mix of forms, from printed to handwritten? Nanonets' AI-based OCR aims to be your all-in-one solution, offering:
- Efficient table extraction
- Handwriting recognition
- Ability to process various unstructured data formats
Whether you're dealing with resumes, financial statements, or medical forms, the system is built to adapt to your needs.
3. Seamlessly Fitting Into Your Workflow
Think about how much time you spend converting extracted data. Nanonets is designed with your workflow in mind, offering:
- Export options to JSON, CSV, Excel, or directly to databases
- API integration for automated processing
- Compatibility with existing business systems
This flexibility aims to make the transition from raw document to usable data smooth and effortless.
4. Enhancing Your Document Security
Handling sensitive information? Nanonets' advanced features aim to add an extra layer of security:
- Fraud checks on financial or confidential data
- Detection of edited or blurred text
- Secure processing compliant with data protection standards
These features are designed to give you peace of mind when handling confidential documents.
5. Growing With Your Business
As your business evolves, so should your OCR solution. Nanonets' AI is built to:
- Learn and improve from each processed document
- Automatically tune based on identified errors
- Adapt to new document types without extensive reprogramming
This means the system could become more attuned to your specific document challenges over time.
6. Transforming Your Document Processing Experience
Imagine reducing your document processing time by up to 90%. By addressing common pain points in OCR technology, Nanonets aims to offer you a solution that not only saves time but also improves accuracy. Whether you're in finance, healthcare, legal, or any other document-heavy industry, Nanonets' AI-based OCR system is designed to potentially transform how you handle document-based information.
The Next Steps
Form data extraction has evolved from simple OCR to sophisticated AI-driven techniques, revolutionizing how businesses handle document processing workflows. As you implement these advanced methods, remember to focus on data quality, choose the right models for your needs, and continuously refine your approach.
Schedule a demo with us today and understand how Nanonets can streamline your workflows, increase accuracy, and save valuable time. With Nanonets, you can process diverse document types, from invoices to medical records, with ease and precision.