
Have an information extraction problem in mind? Want to leverage NLP along with OCR & NER to automate information extraction?
Working with an enormous amount of text data is always hectic and time-consuming. Hence, many companies and organisations rely on Information Extraction techniques to automate manual work with intelligent algorithms. Information extraction can reduce human effort, reduce expenses, and make the process less error-prone and more efficient.
This article will delve into building information extraction algorithms on unstructured data using OCR, Deep Learning, and NLP techniques. It will also cover use cases, challenges, and discuss how to set up unstructured data extraction and information extraction NLP workflows for your business.

Table of Contents
- What is Information Extraction?
- How Does Information Extraction Work?
- Setting up an Information Extraction Workflow
- A few applications of Information Extraction
- Conclusion
Have an OCR problem in mind for information extraction? Want to digitize invoices, PDFs or number plates? Head over to Nanonets and build OCR models for free!
What is Information Extraction?
Information Extraction is the process of parsing through unstructured data and extracting essential information into more editable and structured data formats.
For example, consider we're going through a company’s financial information from a few documents. Usually, we search for some required information when the data is digital or manually check the same. But with information extraction NLP algorithms, we can automate the data extraction of all required information such as tables, company growth metrics, and other financial details from various kinds of documents (PDFs, Docs, Images etc.).
Below is a screenshot explaining how we can extract information from an Invoice.
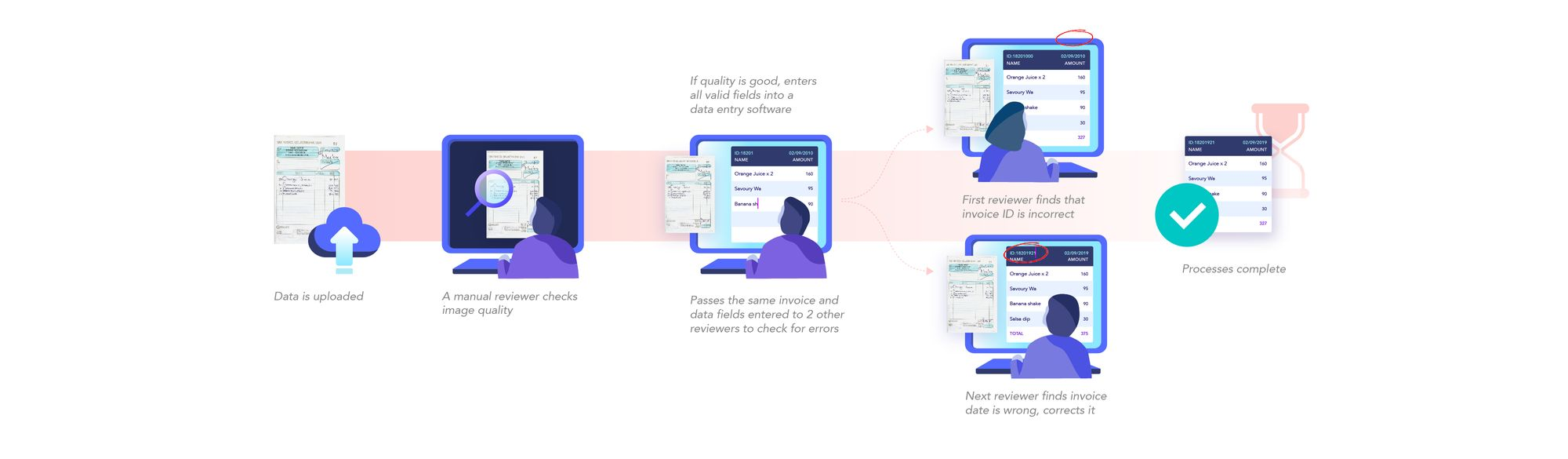
Information Extraction from text data can be achieved by leveraging Deep Learning and NLP techniques like Named Entity Recognition. However, if we build one from scratch, we should decide the algorithm considering the type of data we're working on, such as invoices, medical reports, etc. This is to make sure the model is specific to a particular use case. We’ll be learning more about this in the following sections.
How Does Information Extraction Work?
To understand the mechanics of Information Extraction NLP algorithms, we should understand the kind of data we are working on. This will help us to sort out the information we want to extract from the unstructured data. For example, for invoice related information, the algorithm should understand the invoice items, company name, billing address etc. While working on medical reports, it should identify and extract patient names, drug information, and other general reports.
After curating the data, we’ll then start applying the information extraction NLP techniques, to process and build models around the data. Below are some of the most common techniques that are frequently used.
Tokenization
Computers usually won't understand the language we speak or communicate with. Hence, we break the language, basically the words and sentences, into tokens and then load it into a program. The process of breaking down language into tokens is called tokenization.
For example, consider a simple sentence: "NLP information extraction is fun''. This could be tokenized into:
- One-word (sometimes called unigram token): NLP, information, extraction, is, fun
- Two-word phrase (bigram tokens): NLP information, information extraction, extraction is, is fun, fun NLP
- Three-word sentence (trigram tokens): NLP information extraction, information extraction is, extraction is fun
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("Apple is looking at buying U.K. startup for $1 billion")
for token in doc:
print(token.text)Apple
is
looking
at
buying
U.K.
startup
for
$
1
billion
Parts of Speech Tagging
Tagging parts of speech is very crucial for information extraction from text. It'll help us understand the context of the text data. We usually refer to text from documents as ''unstructured data'' – data with no defined structure or pattern. Hence, with POS tagging we can use techniques that will provide the context of words or tokens used to categorise them in specific ways.
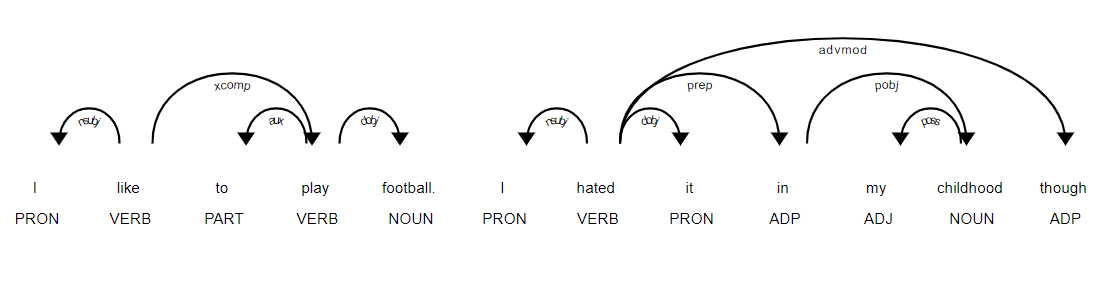
In parts of speech tagging, all the tokens in the text data get categorised into different word categories, such as nouns, verbs, adjectives, prepositions, determiners, etc. This additional information connected to words enables further processing and analysis, such as sentiment analytics, lemmatization, or any reports where we can look closer at a specific class of words.
Here’s a simple python code snippet using spacy, that’ll return parts of speech of a given sentence.
import spacy
NLP = spacy.load("en_core_web_sm")
doc = NLP("Apple is looking at buying U.K. startup for $1 billion")
for token in doc:
print(token.text, token.pos_)Apple PROPN
is AUX
looking VERB
at ADP
buying VERB
U.K. PROPN
startup NOUN
for ADP
$ SYM
1 NUM
billion NUM
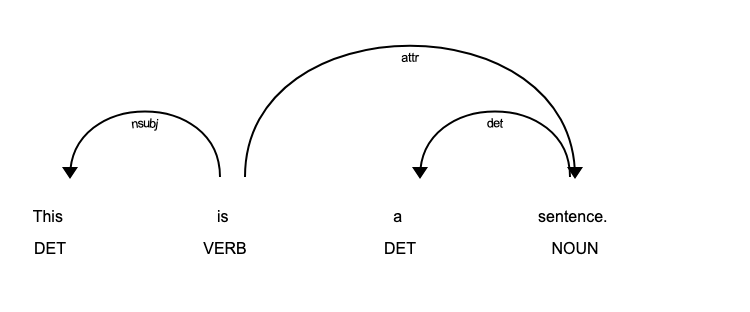
Dependency Graphs
Dependency graphs help us find relationships between neighbouring words using directed graphs. This relation will provide details about the dependency type (e.g. Subject, Object etc.). Following is a figure representing a dependency graph of a short sentence. The arrow directed from the word faster indicates that faster modifies moving, and the label `advmod` assigned to the arrow describes the exact nature of the dependency.

Similarly, we can build our own dependency graphs using frameworks like nltk and spacy. Below is an example:
import spacy
from spacy import displacy
NLP = spacy.load("en_core_web_sm")
doc = NLP("This is a sentence.")
displacy.serve(doc, style="dep")
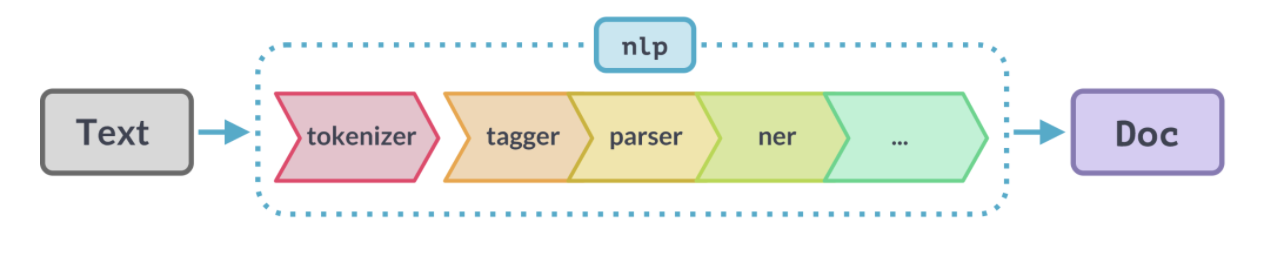
NER with Spacy
NER with Spacy is an open-source NLP library for advanced Natural Language Processing in Python and Cython. It's well maintained and has over 20K stars on Github. To extract information with spacy NER models are widely leveraged.
Make sure to install the latest version of python3, pip and spacy. Additionally, we'll have to download spacy core pre-trained models to use them in our programs directly. Use Terminal or Command prompt and type in the following command after installing spacy:
python -m spacy download en_core_web_smCode:
# import spacy
import spacy
# load spacy model
NLP = spacy.load('en_core_web_sm')
# load data
sentence = "Apple is looking at buying U.K. startup for $1 billion"
doc = NLP(sentence)
# print entities
for ent in doc.ents:
print(ent.text, ent.start_char, ent.end_char, ent.label_)Output:
Apple 0 5 ORG
U.K. 27 31 GPE
$1 billion 44 54 MONEY
We've loaded a simple sentence here and applied NER with Spacy, and it works like magic. Let's decode the program now.
Firstly, we've imported the spacy module into the program. Next, we load the spacy model into a variable named NLP. Next, we load the data into the model with the defined model and store it in a doc variable. Now we iterate over the doc variable to find the entities and then print the word, its starting, ending characters, and the entity it belongs to.
This is a simple example: if we want to try this on real large datasets, we can use the medium and large models in spacy.
NLP = spacy.load('en_core_web_md')
NLP = spacy.load('en_core_web_lg')
These work with high accuracy in identifying some common entities like names, location, organisation etc. In the next section, let us look at some of the business applications where NER is of utmost need!
Nanonets has interesting use cases and unique customer success stories. Find out how Nanonets can power your information extraction use cases.
An Example of Information Extraction
Several industries deal with lots of documents every day and rely on manual work. Those include finance, medical chains, transportation, and construction. Using NLP information extraction techniques on documents will allow everyone on the teams to search, edit, and analyse important transactions and details across business processes.

Now we’ll look at an example in detail on how information extraction from text can be done generically for documents of any kind.
#1 Information Collection
Firstly, we’ll need to collect the data from different sources to build an information extraction model. Usually, we see documents on emails, cloud drives, scanned copies, computer software, and many other sources for business. Hence, we’ll have to write different scripts to collect and store information in one place. This is usually done by either using APIs on the web or building RPA (Robotic Process Automation) pipelines.
#2 Process Data
After we collect the data, the next step is to process them. Usually, documents are two types: electronically generated (editable) and the other non-electronically generated (scanned documents). For the electronically generated documents, we can directly send them into the preprocessing pipelines. Still, we’ll need OCR to first read all the data from images and then send them into preprocessing pipelines for the scanned copies. We can either use open-source tools like Tesseract or any online services like Nanonets or Textract. After all the data is in editable or electronic format, we can then apply to pre-process steps like Tokenization and POS tagging and then use data loaders to load the data into the NLP information extraction models.
#3 Choosing the Right Model
As discussed in the above sections, choosing a suitable model mostly depends on the type of data we’re working with. Today, there are several state-of-the-art models we could rely on. Below are some of the frequently use open-source models:
- Named Entity Recognition on CoNLL 2003 (English)
- Key Information Extraction From Documents: Evaluation And Generator
- Deep Reader: Information extraction from Document images via relation extraction and Natural Language
These are some of the information extraction models. However, these are trained on a particular dataset. If we are utilising these on our models, we’ll need to experiment on the hyperparameters and fine-tune the model accordingly.
The other way is to utilize the pre-trained models and fine-tuning them based on our data. For Information Extraction from text, in particular, BERT models are widely used.
#4 Evaluation of the Model
We evaluate the training process is crucial before we use the models in production. This is usually done by creating a testing dataset and finding some key metrics:
- Accuracy: the ratio of correct predictions made against the size of the test data.
- Precision: the ratio of true positives and total predicted positives.
- Recall the ratio of true positives and total actual positives.
- F1-Score: harmonic mean of precision and recall.
Different metrics take precedence when considering different use cases. In invoice processing, we know that an increase in the numbers or missing an item can lead to losses for the company. This means that besides needing a good accuracy, we also need to make sure the false positives for money-related fields are minimum, so aiming for a high precision value might be ideal. We also need to ensure that details like invoice numbers and dates are always extracted since they are needed for legal and compliance purposes. Maintaining a high recall value for these fields might take precedence.
#5 Deploying Model in Production
The full potential of the NLP models only knows when they are deployed in production. Today, as the world is entirely digital, these models are stored on cloud servers with a suitable background. In most cases, Python is utilised as its more handy programming language when it comes to Text data and machine learning. The model is either exported as API or an SDK (software development kit) for integrating with business tools. However, we need not build everything from scratch as there are several tools and online services for this kind of use-cases. For example, Nanonets has a highly accurate, fully trained invoice information extraction NLP model, and you can directly integrate on our applications using APIs or supported SDKs.
Ideally, these are the steps that are required for information extraction from text data. Here’s an example of how Nanonets performs on an ID card:

A few applications of Information Extraction
There are several applications of Information Extraction, especially with large capital companies and businesses. However, we can still implement IE tasks when working with significant textual sources like emails, datasets, invoices, reports and many more. Following are some of the applications:
- Invoice Automation: Automate the process of invoice information extraction.
- Healthcare Systems: Manage medical records by identifying patient information and their prescriptions.
- KYC Automation: Automate the process of KYC by extracting ethical information from customer's identity documents.
- Financial Investigation: Extract import information from financial documents. (Tax, Growth, Quarterly Revenue, Profit/Losses)
Conclusion
In this tutorial, we've learned about information extraction techniques from text data with various NLP based methods. Next, we've seen how NER is crucial for information extraction, especially when working with a wide range of documents. Next, we've learned about how companies can create workflows to automate the process of information extraction using a real-time example.
Update August 2021: this post was originally published in July 2021 and has since been updated.
Here's a slide summarizing the findings in this article. Here's an alternate version of this post.