In today's business world, data is everything. However, much of the data we need to make critical decisions is often trapped in PDF documents — invoices and expense reports to orders and delivery notes. The problem here is that PDFs are designed for viewing, not editing. It makes data manipulation a daunting task.
PDFs store information using a combination of text, images, and vector graphics. Text is stored as individual characters with associated font information, pictures and graphics are stored separately from the text, and a complex set of coordinates and rules defines the positioning of elements on a page.
When you attempt to transfer data from a PDF to a Google Sheet for analysis, you're often met with a jumbled mess of text and numbers. The solution? Converting the PDF into a format that Google Sheets can understand and work with. This is the focus of our article. We will guide you through the various methods for converting PDFs to Google Sheets.
Methods for converting PDFs to Google Sheets
Google's office suite, which includes Google Sheets, has become the go-to choice for many professionals worldwide. As of February 2024, it commanded an impressive 44% of the global market share among major office suite technologies.
Given Google Sheets' popularity and the prevalence of PDFs in business, it's essential to understand the various methods available for converting PDFs to Google Sheets.
Let's explore the different methods.
| Method | Description | Best Suited For |
|---|---|---|
| Using Google Docs | Open PDF in Google Docs, copy content, paste into Sheets. Free, easy, but limited. | - Simple PDFs - Few PDFs - Basic skills |
| Converting PDFs to CSV | Convert PDFs to CSV, import into Sheets. Handles complex PDFs, may have limits. | - Consistent layouts - Automation - Format not crucial |
| Using Add-ons | Use add-ons to extract data directly into Sheets. More features, may need subscription. | - Moderate volume - Extra features - Automation |
| Using Adobe Acrobat | Use Acrobat's OCR to extract data, preserve layout. Batch processing, paid subscription. | - Sensitive PDFs - Layout crucial - Adobe users |
| Python & Open-Source | Python & open-source for customization, flexibility. Handles complex PDFs, needs coding. | - Custom workflows - Complex PDFs - System integration |
| LLMs, OCR & Automation | Combine LLMs, OCR, automation for intelligent extraction. Flexible, requires setup. | - Automated insights - Custom workflows - Tool integration |
| Advanced OCR & Capture | Advanced OCR & capture for high volume, complex PDFs. Validation, enrichment, costly. | - High volume - Automated extraction - Enterprise integration |
1. Using Google Docs as an intermediary
This is perhaps the easiest method to convert PDF data to editable text, which can then be easily copied to Google Sheets. The online word processor now has built-in basic OCR capabilities that enables it to extract text from simple PDFs.
Here's how it works:
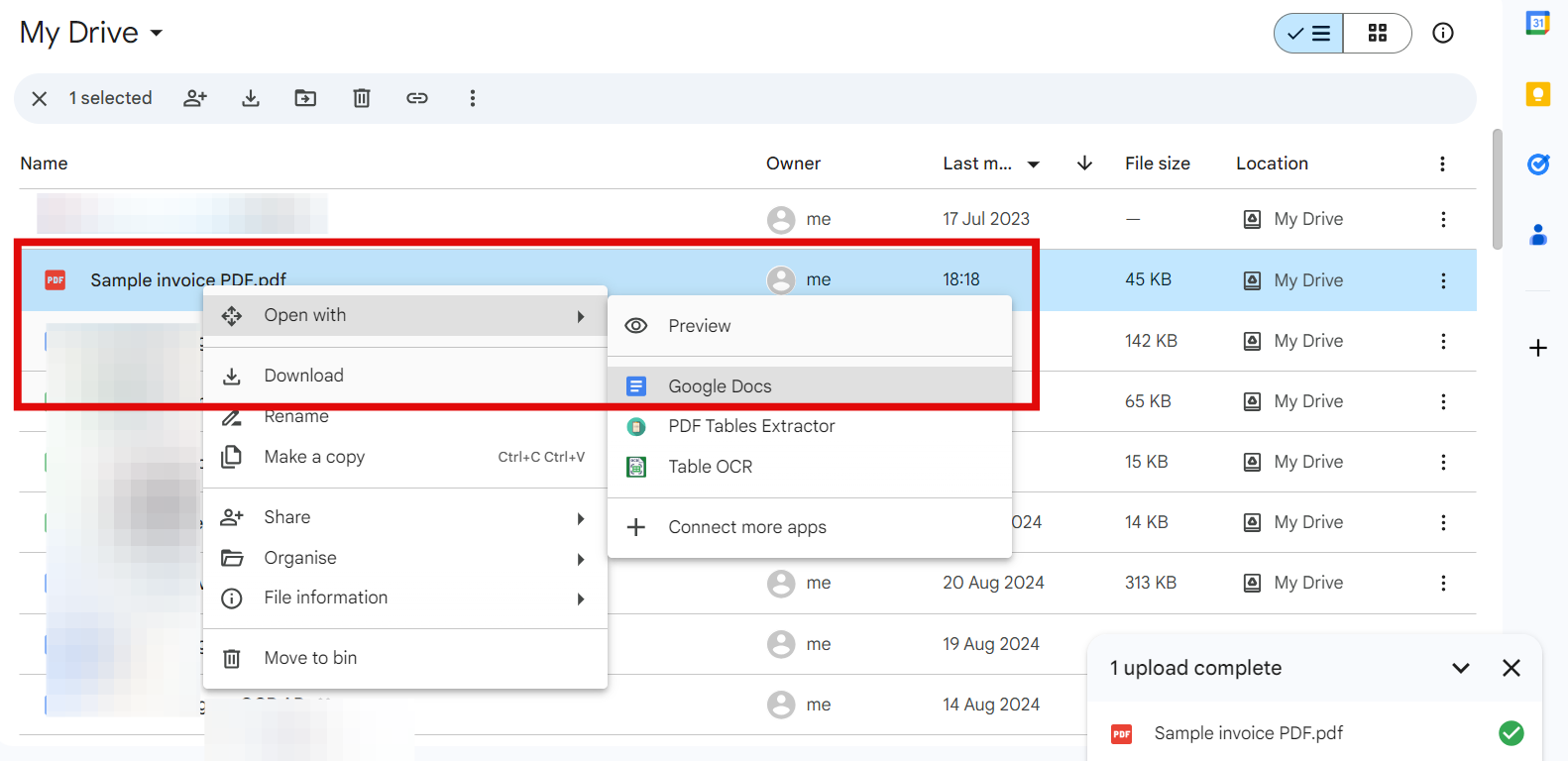
Here's how it works:
- Upload the PDF to your Google Drive
- Right-click on the PDF and select Open with and choose Google Docs
- Google Docs will OCR the PDF into an editable document
- Copy the relevant data from the Google Doc
- Paste the data into a new Google Sheets spreadsheet
Things that can prevent you from getting the perfect conversion:
- Complex PDFs with multiple columns, tables, or images may not be correctly converted
- Scanned or image-based PDFs may not be properly recognized by Google Docs
- PDFs larger than 2 MB or with low-resolution text (less than 10 pixels high) may not convert well
Suitable use-cases:
- Copying data from simple text-based PDFs with single-column layouts and basic formatting like contracts or proposals for tracking purposes.
- Extracting tables from a small number of digital invoices or receipts, for individual use or sharing with a limited audience.
This method is a quick and easy way to extract data from a PDF and transfer it to Google Sheets without the need for any additional tools or software. However, it may not be ideal for more complex PDFs with multiple columns, tables, or images.
2. Converting PDFs to CSV using a converter
This method involves converting the PDF to a CSV (Comma-Separated Values) file first, which can then be easily imported into Google Sheets. You can use any online converter tool to perform the conversion. These tools typically use OCR to automatically recognize content in the PDF and convert it into a machine-readable format like a CSV file with rows, columns, and tables.

Here's how it works:
- Use an online PDF to CSV converter tool (e.g., PDF to CSV, Zamzar, Smallpdf, Veryfi)
- Upload the PDF and convert it to a CSV file
- Download the CSV file to your computer
- Open a new Google Sheets spreadsheet
- Go to File > Import and select the CSV file
- Choose the appropriate import options (e.g., separator type, range)
- The data from the PDF will now appear in your Google Sheets
Things that can prevent you from getting the perfect conversion:
- PDFs with complex layouts or multiple tables or handwritten content may not be correctly converted
- Some online converters may have limitations on file size or the number of pages
- Password-protected or encrypted PDFs may not be supported by some converters
Suitable use-cases:
- Extracting data from publicly available PDF reports or documents, such as government statistics, research papers, or product catalogs, for analysis, comparisons, and forecasts.
- Consolidating the monthly expense reports from employees into a single master Google Sheet to categorize expenses, calculate totals, and identify trends or anomalies.
This method is more effective than Google Docs, but features vary by tool. Some are free; others require subscriptions for advanced features or batch processing. Beware of ads and pop-ups. Review their privacy and security policies first if you plan to process sensitive documents.
3. Using add-ons to extract data directly into Google Sheets
Google Sheets offers a variety of third-party add-ons that allow you to import PDF data into your spreadsheet. Each add-on works slightly differently. Some may take you to their web app to process the PDF, while others work directly within Google Sheets.
Some popular add-ons include Table OCR, PDF to Google Sheets Converter, PDF Importer, PDF Tools by Smallpdf, and PDF Extractor. For this example, let's focus on the Table OCR add-on. It enables you to extract tables and other data from PDFs directly into your Google Sheets spreadsheet.
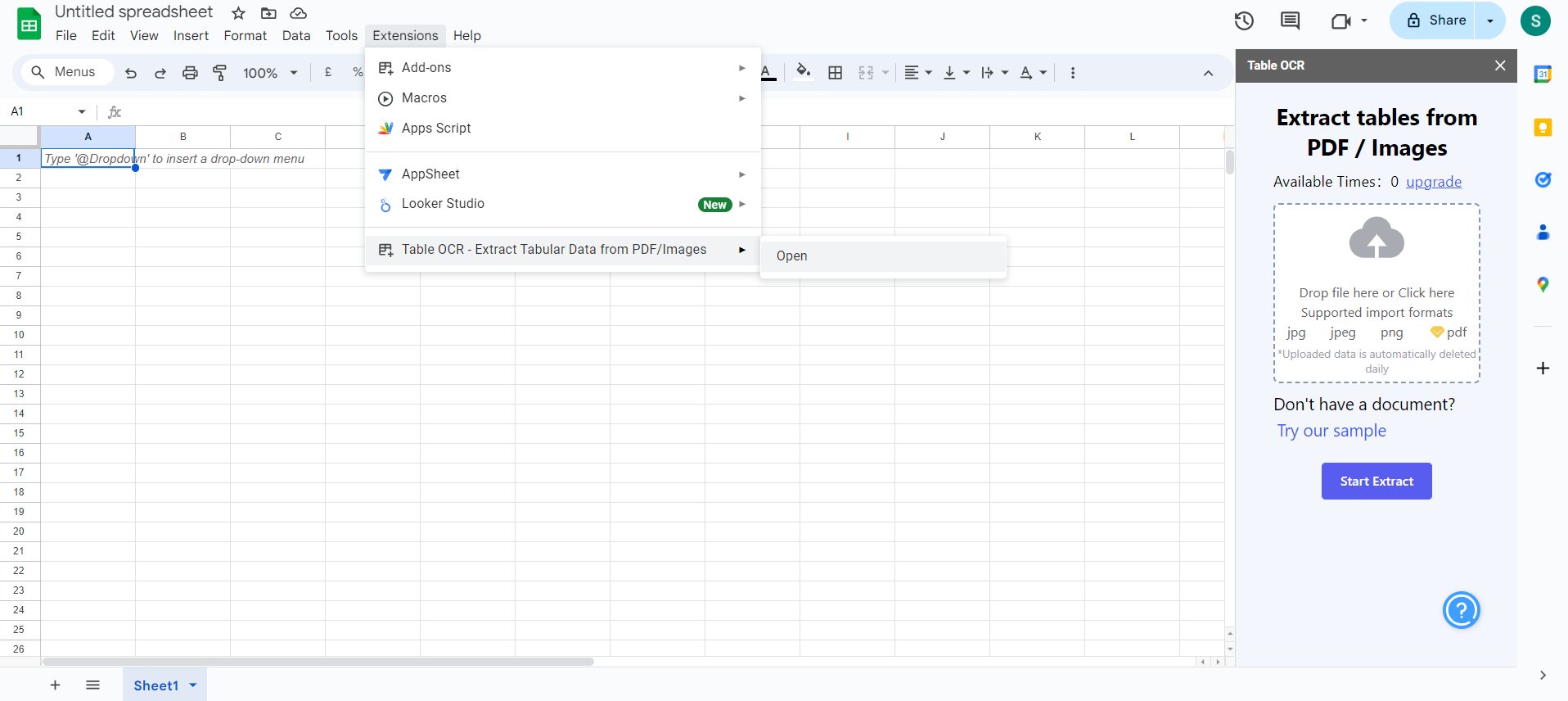
Here's how it works:
- Install the add-on from the Google Workspace Marketplace.
- Open your Sheets document, click 'Extensions' in the toolbar, and select 'Table OCR' from the dropdown menu.
- A sidebar will appear on the right side of the sheet. Click 'Upload PDF/Image' and select the PDF file from your computer or Google Drive.
- The add-on will detect tables in the document. Select the table(s) you want to extract and click 'Extract' to start the OCR-data extraction process.
- Preview the extracted data in the sidebar and make any necessary adjustments.
- Click 'Insert to Sheet' to import the extracted data into your Google Sheets document, starting from the selected cell.
Things that can prevent you from getting the perfect conversion:
- You might hit the free limit, after which you'll need to upgrade to a paid plan.
- If you don't give Google Drive access permissions to the add-on, it may not be able to work.
- Complex layouts, images, or non-standard fonts in the PDF could lead to inaccurate data extraction.
Suitable use-cases:
- Digitizing a large number of paper forms with similar layouts or structures, such as survey responses or patient records, and importing them into a database for analysis or record-keeping.
- Processing documents centrally stored in Google Drive — with add-ons you can easily access and extract data from PDFs without downloading them to your local device.
Each add-on has its strengths and limitations, so evaluate your specific needs and choose the one that best suits your requirements. Some add-ons may offer advanced features like batch processing, local processing, automatic table detection, or support for multiple languages. Remember that using add-ons may raise privacy concerns, as they may have to access your Google Drive files.
4. Using Adobe Acrobat Reader to convert PDFs into XLSX
Adobe’s Acrobat Reader is a powerful PDF viewer and editor that offers various features for converting PDFs to formats compatible with Google Sheets, including XLSX and TXT. One of its key features is the ability to recognize text in scanned documents or image-based PDFs using OCR (Optical Character Recognition).
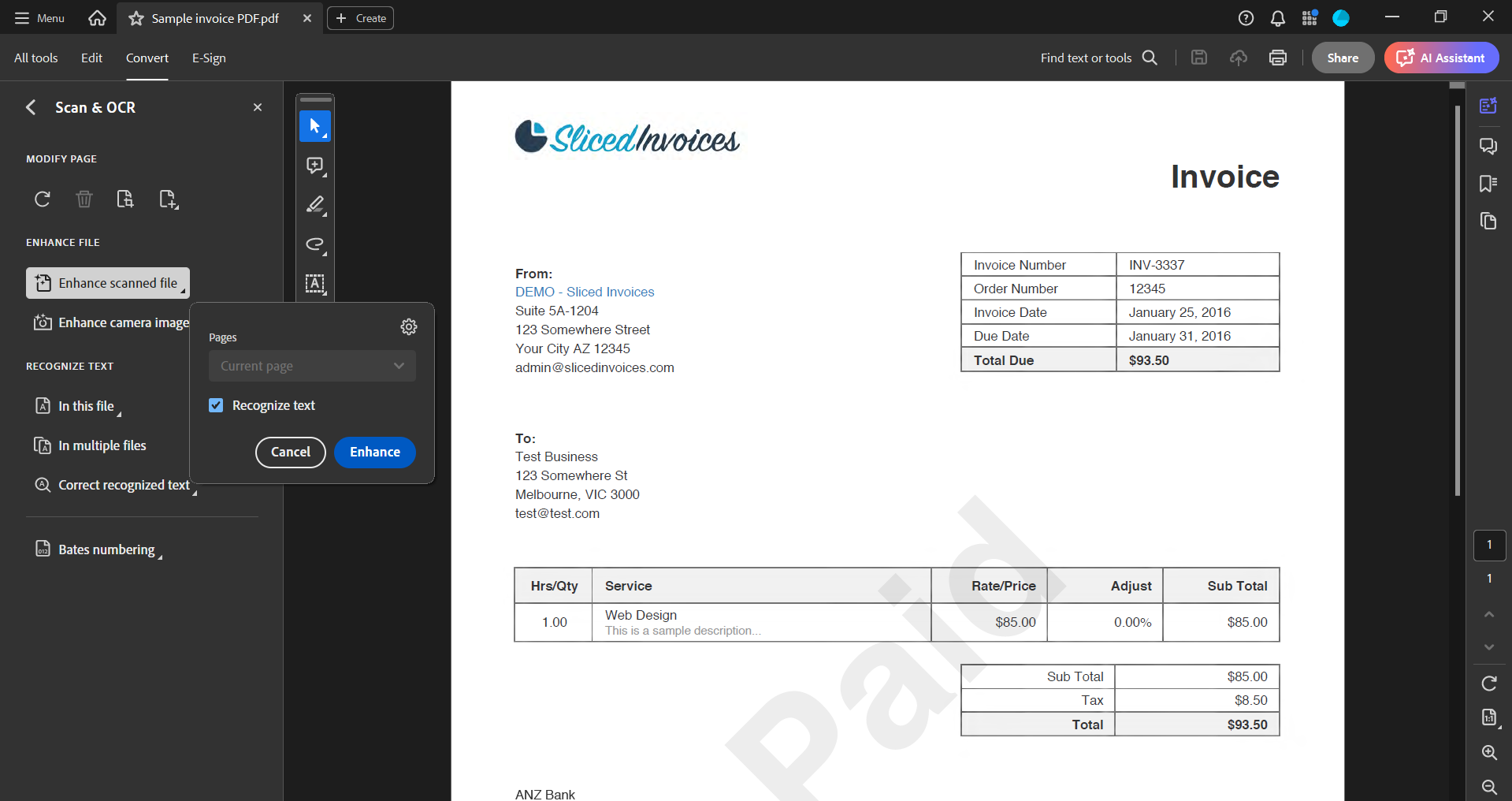
Here’s how to use it:
- Open the PDF in Adobe Acrobat.
- Select ‘Scan & OCR’ from the Tools center or right-hand pane if the PDF is a scanned document.
- Select ‘Enhance scanned file’ to clean up the image.
- Acrobat will automatically recognize text from scanned documents. For image files, select ‘Recognize Text’ to manually initiate the OCR process.
- Once the OCR process is complete, the data will be searchable— you can make text and formatting changes, if required
- Head over to the Convert menu and select the file format you prefer — XLSX, XML, or TXT, tweak the workbook settings if needed, and click 'Export'.
- Open Google Sheets and import the converted file using the File > Import option.
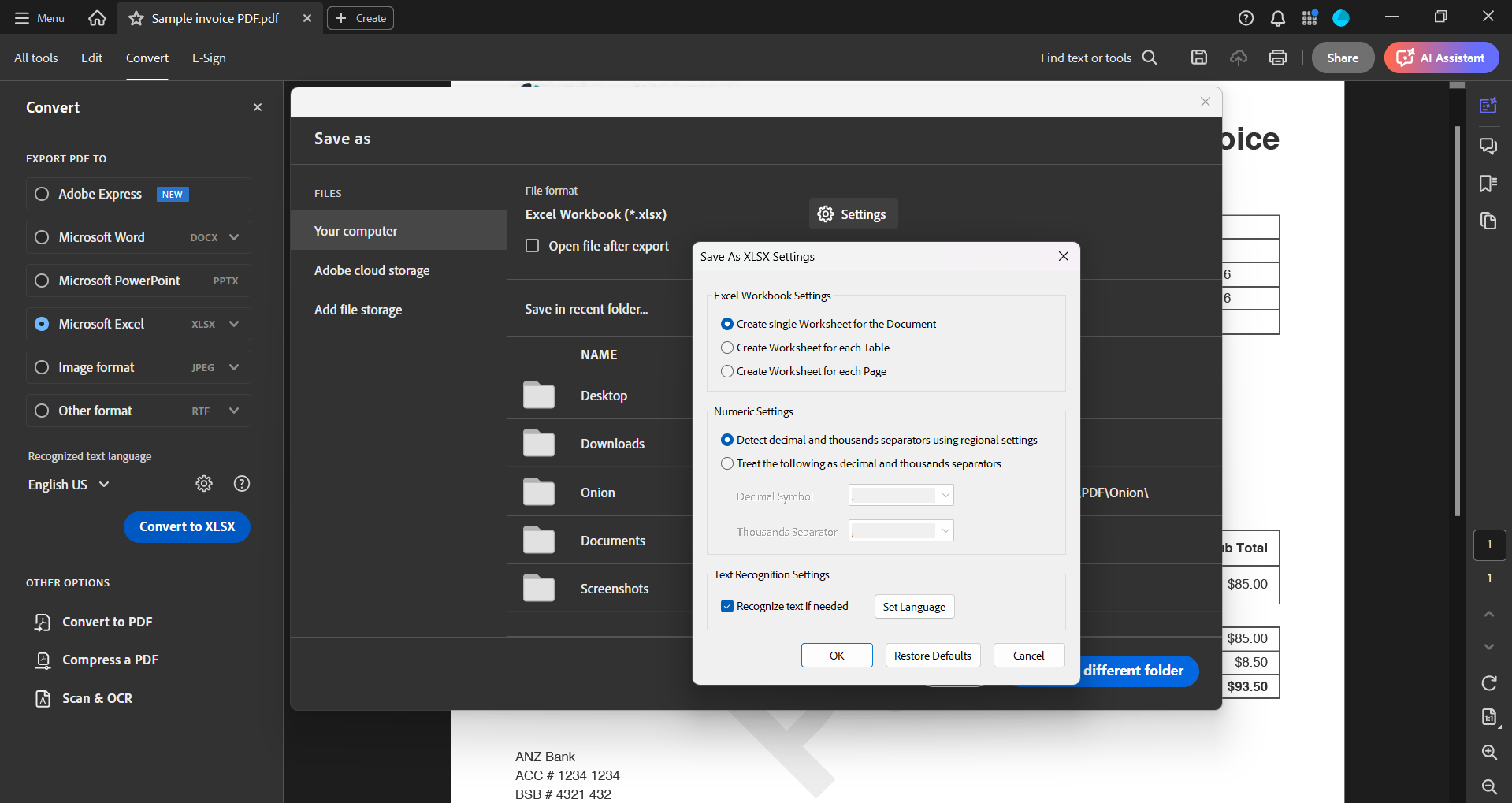
Things that can prevent you from getting the perfect conversion:
- If the PDF already contains editable text, Acrobat will not perform OCR on it.
- Uncommon fonts or languages not supported by Adobe Acrobat
- Documents containing complex layouts with a mix of text, graphs, tables, and images.
Suitable use-cases:
- Securely extracting sensitive financial data from PDF documents for auditing purposes while maintaining data confidentiality and compliance with regulations.
- Digitizing legal contracts with complex layouts and formatting for e-discovery and importing the extracted text into Google Sheets for analysis.
- Extracting patient data from medical forms in PDF format for research purposes while ensuring patient privacy and compliance with healthcare regulations.
Adobe Acrobat provides a user-friendly interface and robust OCR capabilities for converting PDFs to formats compatible with Google Sheets. It offers a secure, local solution for digitizing sensitive documents without relying on cloud-based services. However, the OCR feature is only available in the paid version, which can be expensive for individual users or small businesses. Additionally, while Adobe Acrobat excels at handling a wide range of PDF formats and layouts, bulk processing large volumes of documents can be time-consuming.
5. Using Python libraries and open source tools to extract PDF data
Python, a versatile and powerful programming language, offers several libraries that can be used to convert PDFs to Google Sheets. Additionally, there are open-source tools available that provide a more user-friendly interface for those who may not be comfortable with programming.
Python Libraries:
One popular Python library for interacting with Google Sheets is gspread. It provides a simple API for opening, creating, and manipulating Google Sheets spreadsheets.
To use gspread, you'll first need to set up authentication using a service account and obtain the necessary credentials. Once authenticated, you can use gspread to perform various operations like reading and writing data to a worksheet.
For PDF extraction, you can use libraries like PyPDF2, tabula-py, or camelot-py. These libraries allow you to read and extract data from PDF files programmatically.
- PyPDF2 is a pure-Python library for working with PDF files, allowing you to extract text and metadata from PDFs.
- tabula-py is a Python wrapper for the Tabula Java library, which can read tables in PDF files and convert them into a pandas DataFrame.
- camelot-py is another Python library that can extract tables from PDF files, supporting both lattice and stream table extraction methods.
- DocStrange is an open source Python library that converts documents to Markdown, JSON, CSV, XML, and HTML quickly and accurately.
Here's a basic example of how you can use camelot python library to extract tables from a PDF and save them as a CSV file:
import camelot
# Path to the PDF file
pdf_path = 'input.pdf'
# Extract tables from the first page using the lattice method
tables = camelot.read_pdf(pdf_path, pages='1', flavor='lattice')
# Export the extracted table to a CSV file
output_csv = 'output.csv'
tables[0].to_csv(output_csv)You can then use gspread to import the CSV file into a Google Sheets spreadsheet. First, make sure you have the gspread library installed. You can install it using pip:
pip install gspreadNext, you'll need to set up authentication to access your Google Sheets API. After that, you can use the following Python code to import a CSV file into a Google Sheets spreadsheet:
import gspread
import csv
from oauth2client.service_account import ServiceAccountCredentials
# Set up authentication
scope = ['https://spreadsheets.google.com/feeds', 'https://www.googleapis.com/auth/drive']
creds = ServiceAccountCredentials.from_json_keyfile_name('path/to/keyfile.json', scope)
client = gspread.authorize(creds)
# Open the Google Sheets spreadsheet
sheet_url = 'https://docs.google.com/spreadsheets/d/your-spreadsheet-id'
sheet = client.open_by_url(sheet_url)
worksheet = sheet.worksheet('Sheet1') # Replace 'Sheet1' with the desired worksheet name
# Read the CSV file
with open('path/to/file.csv', 'r') as file:
reader = csv.reader(file)
data = list(reader)
# Write the data to the Google Sheets worksheet
worksheet.update('A1', data)Make sure to replace 'path/to/keyfile.json' with the path to your service account JSON key file, 'your-spreadsheet-id' with the ID of your Google Sheets spreadsheet (which can be found in the spreadsheet URL), and 'path/to/file.csv' with the path to your CSV file.
Here's what the code does:
- It sets up authentication using the service account JSON key file and the specified scope.
- It opens the Google Sheets spreadsheet using the spreadsheet URL and selects the desired worksheet.
- It reads the CSV file using the csv module and converts the data into a list of lists.
- It writes the data to the Google Sheets worksheet using the update() method, starting from cell 'A1'.
This code will import the contents of the CSV file into the specified Google Sheets worksheet, overwriting any existing data in the range where the CSV data is inserted.
Combining gspread code with the previous examples of extracting tables from PDFs using libraries like camelot-py, you can automate the process of converting PDF tables to CSV files and then importing them into Google Sheets.
Open-source tools:
These tools provide a graphical user interface (GUI) for converting PDFs to Google Sheets without the need for programming knowledge.
- Tesseract: An open-source OCR engine that can be used with various programming languages, including Python.
- OCRmyPDF: It is a Python script and a command-line tool that automates the process of adding an OCR text layer to scanned PDF files.
- Excalibur: A free and open-source web interface that allows you to easily extract tabular data from PDFs. It is powered by the Python library Camelot, which provides two methods for extracting tables: Lattice (for tables formed with lines) and Stream (for tables formed with whitespaces).
Each tool or library has its own specific installation and usage instructions. For the purpose of this article, let's look at how to use Excalibur:
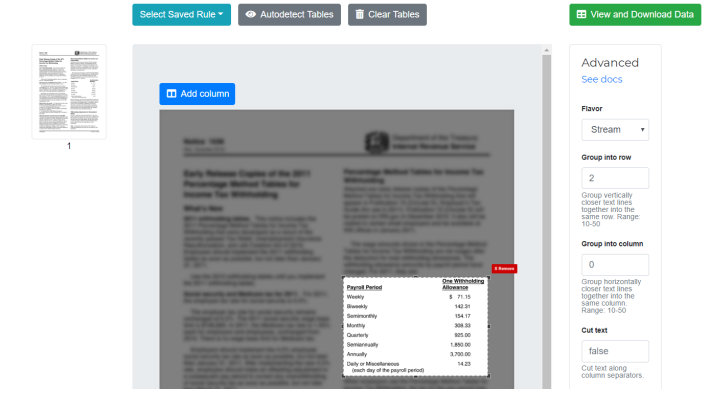
- Install and set up Excalibur on your local machine.
- Open your PDF file with Excalibur.
- Specify the page numbers where the target data is located.
- Select the tables you want to extract by either manually snipping the relevant rows and columns or using Excalibur's auto-detect feature.
- Initiate the table extraction process.
- Once the extraction is complete, download the extracted data in your preferred format, such as CSV or XLS.
- Import the file into Google Drive and either insert it as a new sheet or create a new spreadsheet.
Things that can prevent you from getting the perfect conversion:
- Limitations or bugs in the Python libraries or open-source tools used or incorrect configuration
- PDF documents with intricate layouts, unconventional formatting, or handwritten and cursive text
- Lack of technical knowledge or programming experience for using open-source tools and libraries
Suitable use-cases:
- Creating budget-friendly automated data extraction workflows for non-profits and small businesses with limited resources.
- Digitizing and extracting text from large archives of legacy data stored in scanned PDFs or images and making them searchable and usable for modern data processing and analysis.
Open-source OCR tools and Python libraries offer a cost-effective and flexible solution for converting PDFs to Google Sheets, particularly for users with programming experience or specific customization requirements. However, they may require additional setup and configuration compared to commercial tools. Moreover, some tools like Excalibur that are powered by the Camelot library may only work with text-based PDFs and not scanned documents or image-based PDFs.
6. Integrating LLMs with OCR and automation tools for enhanced processing
Large Language Models (LLMs) like ChatGPT or Claude can be combined with OCR tools and automation tools, such as Zapier, to extract data from PDFs, process it using AI, and automatically populate Google Sheets with the results.
This integration enables businesses and individuals to automate data extraction and analysis tasks, potentially saving time and effort while leveraging the capabilities of AI models.
Here's what the potential workflow would look like:
- PDFs are uploaded to a storage service like Google Drive or Dropbox.
- Zapier triggers OCR tool to extract text, images, and data from the uploaded PDFs.
- The extracted data is sent to an LLM via Zapier.
- The LLM processes the data based on predefined instructions, such as summarizing content, categorizing information, or generating insights.
- The output from the LLM is automatically sent to Google Sheets through Zapier, populating the spreadsheet with the processed data.
- The populated Google Sheet can be further analyzed, shared, or integrated with other tools using additional Zapier automation.
Things that can prevent you from getting the perfect conversion:
- Limitations in the LLM's understanding or ability to process certain types of data
- Incorrect setup or configuration of the integration between the OCR tool, LLM, and Google Sheets
- API rate limits or usage restrictions imposed by the LLM or integration tool provider
Suitable use-cases:
- Automatically extracting key information from reports in PDF format, using Claude to generate summaries, and storing the results in Google Sheets for easy access and sharing.
- Extracting data from customer feedback forms or surveys in PDF format, using Claude to analyze sentiment and identify trends, and populating Google Sheets with the insights for further action.
By combining these tools, businesses, and individuals can create custom workflows that integrate OCR, LLMs, and Google Sheets to streamline their PDF data extraction and processing tasks. However, the specific capabilities and limitations of these integrations may depend on the tools and technologies used and the quality and complexity of the input PDFs.
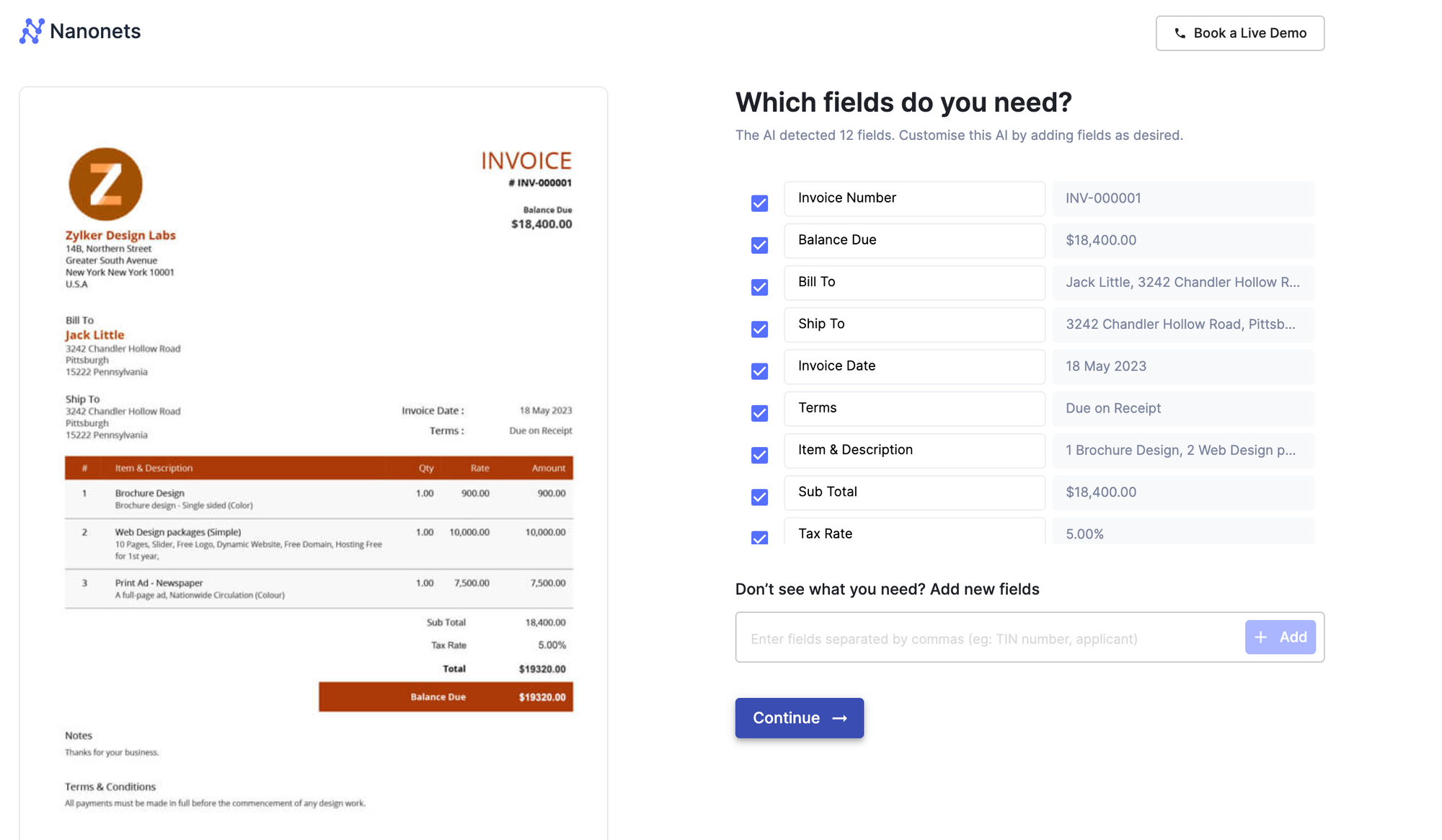
7. Using intelligent data capture to automate PDF-to-Sheets conversion
Advanced OCR and intelligent data capture solutions provide a comprehensive approach to converting PDFs to editable formats, such as CSV or Google Sheets. These platforms combine powerful OCR engines with machine learning algorithms and workflow automation to extract, validate, and process data from high volumes of complex documents.
Take a look at this 2-min demo that shows how Nanonets can seamlessly extract data from multiple invoices within seconds and automatically export it to Google Sheets.
Here’s how these solutions work:
- Documents are input into the system through various methods, such as manual upload, email integration, or automatic file transfer.
- The solution preprocesses the documents to enhance image quality and optimize them for OCR.
- Advanced AI classifies documents and extracts text, images, and data from the documents, handling a wide range of languages, fonts, and layouts.
- Intelligent data capture techniques, such as pattern recognition and contextual analysis, are used to identify and extract specific data fields.
- Extracted data is validated, enriched, and automatically routed through predefined workflows for further processing or integration with other systems.
- The final output, such as a CSV file or a populated Google Sheet, is generated and delivered to the appropriate destination.
Things that can prevent you from getting the perfect conversion:
- Extremely poor quality or damaged documents
- Handwritten or cursive text
- Uncommon languages or scripts
- Incorrect configuration or training of the data capture components
Suitable use-cases:
- Capturing and extracting data from customer feedback forms, surveys, and questionnaires to enable sentiment analysis, trend identification, and data-driven decision-making for product development and customer service improvements.
- Extracting and reconciling data from bank statements, credit card statements, and other financial documents to automate account reconciliation and detect potential fraud or discrepancies.
- Automating the extraction and processing of large volumes of invoices, purchase orders, and receipts from various formats and layouts for accounts payable processing and financial analysis.
While advanced OCR and intelligent data capture solutions offer significant benefits for high-volume, complex document processing, they require careful planning, investment, and ongoing maintenance. Organizations should thoroughly assess their needs and choose a vendor that can provide the necessary support and expertise to ensure successful implementation and ROI.
Troubleshooting common conversion issues
When converting PDFs to Google Sheets, you may encounter various issues that can hinder the process or result in inaccurate data. Common problems include poor image quality, complex layouts, or unsupported file types.
Q: How can I convert encrypted or password-protected PDFs to Google Sheets?
A: Remove the encryption or password using tools like Adobe Acrobat or Smallpdf before converting the PDF to Google Sheets.
Q: What should I do if the converted data is inaccurate or missing information?
A: Try using a different conversion method or tool. Ensure the original PDF is high-quality and not corrupted.
Q: How can I convert PDFs with multiple tables or complex layouts to Google Sheets?
A: Use advanced OCR tools with intelligent data capture, like Nanonets or ABBYY FineReader, to handle complex PDF structures and extract data accurately.
Q: Can I convert scanned or image-based PDFs to Google Sheets?
A: Yes, use OCR tools such as Google Cloud Vision API, Adobe Acrobat, ABBYY FineReader, or Tesseract to extract text from images and convert it to a format compatible with Google Sheets.
Final thoughts
Converting PDFs to Google Sheets enables you to extract and analyze data more efficiently. By exploring various methods and tools, from manual conversion to advanced OCR solutions, you can find the best approach for your specific needs.
Remember to consider factors such as document complexity, volume, and data accuracy when choosing a conversion method. With the right tools and techniques, you can unlock the full potential of your PDF data and streamline your data management processes.