It’s Monday morning. You open your laptop, and there it is: an inbox flooded with vendor invoices, scanned receipts from the sales team, and a dozen PDF contracts waiting for review. It’s the digital equivalent of a paper mountain, and for decades, the challenge was simply to get through it.
But now, there’s a new pressure. The C-suite is asking about Generative AI. They aim to develop an internal chatbot capable of answering questions about sales contracts, as well as an AI tool to analyze financial reports. And suddenly, that mountain of messy documents isn’t just an operational bottleneck; it’s the roadblock to your entire AI strategy.
This digital document mountain is what we call unstructured data. It’s the chaos of the real world, and according to industry estimates, it accounts for 80-90% of an organization's data. Yet, in a staggering disconnect, Deloitte's findings reveal that only 18% of companies have efficiently extracted value from this uncharted digital territory.
This is a practical guide to solving the single biggest problem holding back enterprise AI: turning your chaotic documents into clean, structured, LLM-ready data.
Understanding the three types of data in your business
It's the information that exists in its raw, native format. This data contains the essential context and nuance of business operations, but it doesn't fit into the rigid rows and columns of a traditional database.
Let’s quickly clarify the three types of data you’ll encounter:
- Structured: This is highly organized data that adheres to a predefined model, fitting neatly into spreadsheets and relational databases. Think of customer names, addresses, and phone numbers in a CRM. Each piece of information has its own designated cell.
- Unstructured: This is data without a predefined model or organization. It includes the text within an email, a scanned image of an invoice, a lengthy legal contract, or a customer support chat log. There are no neat rows or columns.
- Semi-structured: This is a hybrid. It doesn't conform to a formal data model but contains tags or markers to separate semantic elements. A classic example is an email, which has structured parts (To, From, Subject lines) but a completely unstructured body.
| Parameter | Structured Data | Unstructured Data | Semi-structured Data |
|---|---|---|---|
| Data Model | - Follows a rigid schema with rows and columns - Easily stored in relational databases (RDBMS) |
- Lacks predefined format - Appears as emails, images, videos, etc. - Requires dynamic storage |
- Identifiable patterns and markers (e.g., tags in XML/JSON) - Does not fit into a traditional database structure |
| Data Analysis | - Simplifies analysis - Allows straightforward data mining and reporting |
- Requires complex techniques like NLP and machine learning - More effort to interpret |
- Easier to analyze than unstructured data - Recognizable tags aid in analysis |
| Searchability | - Highly searchable with standard query languages like SQL - Quick and accurate data retrieval |
- Difficult to search - Needs specialized tools and advanced algorithms |
- Partial organization aids in searchability - Metadata and tags can help |
| Visionary Analysis | - Predictive analytics and trend analysis are straightforward due to quantifiable nature | - Rich in qualitative insights for visionary analysis - Requires significant effort to mine |
- Partial organization allows some direct visionary analysis - May need processing for deeper insights |
This spectrum isn't just theoretical; it often manifests daily in the form of invoices from hundreds of different vendors, purchase orders in varying formats, and legal agreements. These documents, which are fundamental to business operations, are prime examples of the critical, messy, unstructured data that organizations must manage.
The old way of "extracting" data was broken

For years, businesses tackled this mess with two primary methods: manual data entry and traditional Optical Character Recognition (OCR). Manual entry is slow, expensive, and a perfect recipe for errors like data duplication and inconsistent formats.
Traditional OCR, the supposed "automated" solution, was often worse. These were rigid, template-based systems. You’d have to create a rule for every single document layout: "For Vendor A, the invoice number is always in this exact spot." When Vendor A changed its invoice design, the system would break.
But today, these old methods create a much deeper problem. The output of traditional OCR is a "flat blob of text." It strips out all the critical context. A table becomes a jumble of words, and the relationship between a field name ("Total Amount") and its value ("$5,432.10") is lost.
Feeding this messy, context-free text to a Large Language Model (LLM) is like asking an analyst to make sense of a shredded document. The AI gets confused, misses connections, and starts to "hallucinate"—inventing facts to fill the gaps. This makes the AI untrustworthy and derails your strategy before it begins.
The goal: creating LLM-ready data
To build reliable AI, you need LLM-ready data. This isn't just a buzzword; it's a specific technical requirement. At its core, making data LLM-ready involves a few key steps:
- Cleaning and structuring: The process starts with cleaning the raw text to remove irrelevant "noise" like headers, footers, or HTML artifacts. The cleaned data is then converted into a structured format like Markdown or JSON, which preserves the document's original layout and semantic meaning (e.g., "invoice_number": "INV-123" instead of just the text "INV-123").
- Chunking: LLMs have a limited context window, meaning they can only process a certain amount of information at once. Chunking is the critical process of breaking down long documents into smaller, semantically complete pieces. Good chunking ensures that whole paragraphs or logical sections are kept together, preserving context for the AI.
- Embedding and indexing: Each chunk of data is then converted into a numerical representation called an "embedding." These embeddings are stored in a specialized vector database, creating an indexed, searchable knowledge library for the AI.
This entire pipeline—from a messy PDF to a clean, chunked, and indexed knowledge base—is what transforms chaotic documents into the context-rich fuel that high-performance AI models require.
The market has responded to this need with a variety of tools. For developers who want to build custom pipelines, powerful open-source libraries like Docling, Nanonets OCR-S, Unstructured.io, and LlamaParse provide the building blocks for parsing and chunking documents. On the other end of the spectrum, closed-source platforms from major cloud providers like Google (Document AI), Microsoft (Azure AI Document Intelligence), and Amazon (Textract) offer managed, end-to-end services.
Automating critical business documents requires more than just speed; it also demands enterprise-grade security. Ensure that the platform you select offers encryption both in transit and at rest, and has a secure infrastructure that provides a centralized, auditable system that mitigates the risks associated with scattered documents and manual processes. For instance, Nanonets is fully compliant with stringent global standards, including GDPR, SOC 2, and HIPAA, ensuring your data is handled with the highest level of care.
The Nanonets way: how our AI-powered document processing solves the problem
This is the problem we are obsessed with solving. We use AI to read and understand documents like a human would, transforming them directly into LLM-ready data.
The core of our approach is what we call AI-powered, template-agnostic OCR. Our models are pre-trained on millions of documents from around the world. It doesn't need rigid templates because it already understands the concept of an "invoice number" or a "due date," regardless of its location on the page. It sees the document's layout, understands the relationships between fields, and extracts the information into a perfectly structured format.
This is why you can upload invoices from 100 different vendors to Nanonets, and it just works.
Your automated data extraction workflow in 4 simple steps
We’ve designed a complete, end-to-end workflow that you can set up in minutes. It handles everything from the moment a document arrives to the final export into your system of record.
Step 1: Import documents automatically

The first goal is to stop manual uploads. You can set up Nanonets to automatically pull in documents from wherever they land. You can auto-forward attachments from an email inbox (like invoices@yourcompany.com), connect a folder in Google Drive, OneDrive, or SharePoint, or integrate directly with our API.
Step 2: Classify, extract, and enhance data
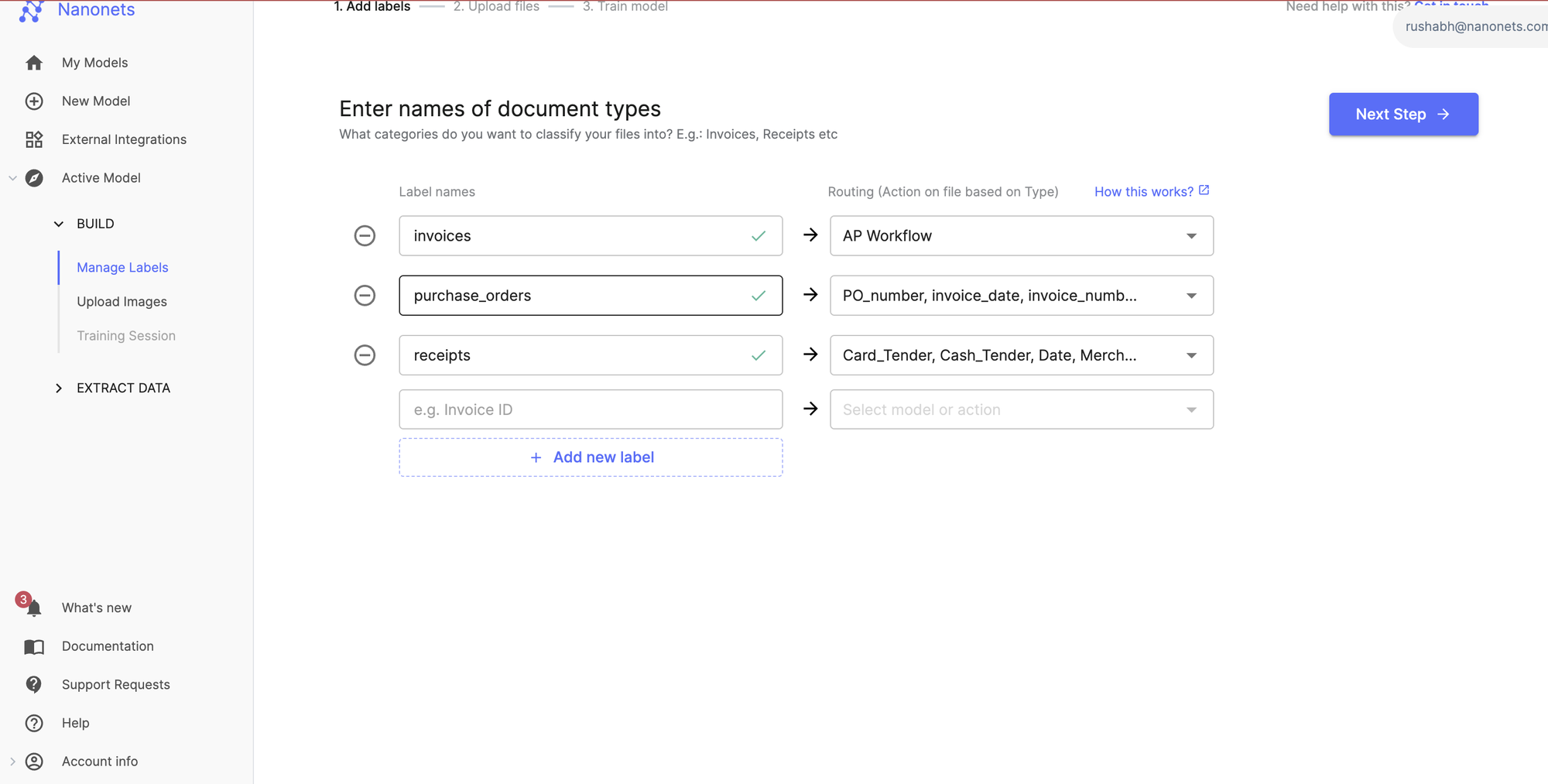
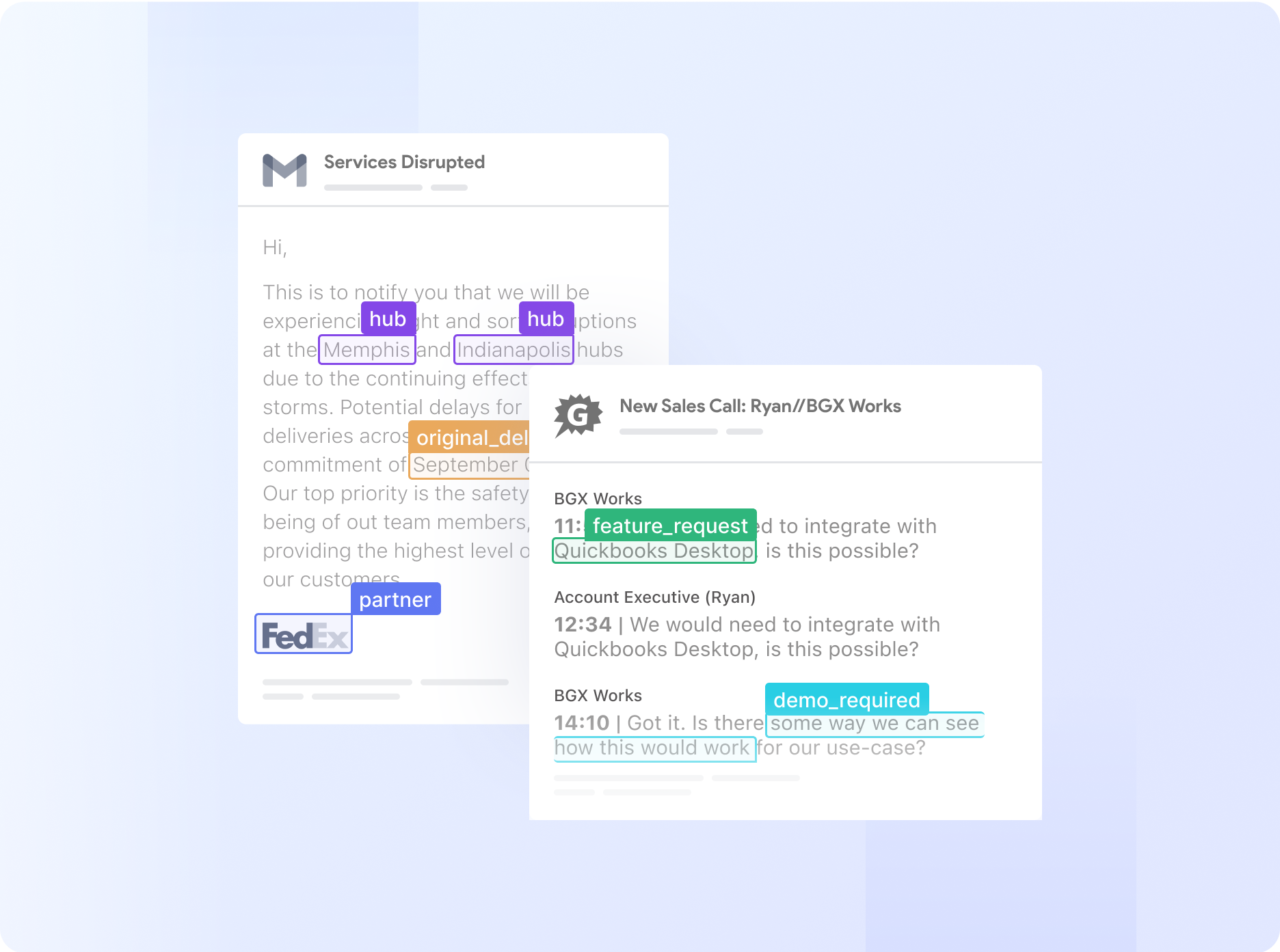
Once a document is in, the workflow gets to work. It can first classify the document type—for example, automatically routing invoices to your invoice processing model and receipts to your expense model. Then, the AI extracts the relevant data. But it doesn't stop there. You can add Data Actions to clean and standardize the information. This means you can do things like automatically format all dates to YYYY-MM-DD, remove currency symbols from amounts, or split a full name into "First Name" and "Last Name."
Step 3: Set up smart approval rules
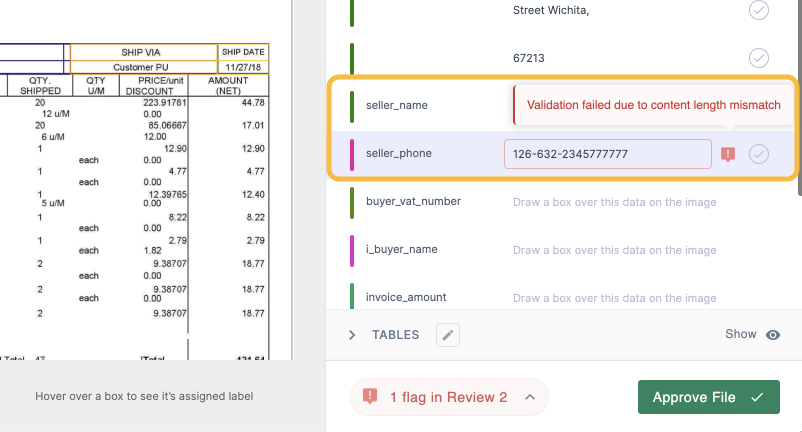
Automation doesn't mean giving up control. It means focusing your team's attention where it's needed most. You can create simple, powerful rules to manage approvals without creating bottlenecks. For example, you can set a rule like, "If the invoice total is over $10,000, flag it for manager approval." Or, a more advanced one: "Check the PO number against our database; if it doesn’t match, flag it for review." This way, your team only ever has to look at the exceptions, not every single document.
Asian Paints, one of Asia's largest paint companies, uses this to manage a network of over 22,000 vendors. Nanonets automates the data extraction from their purchase orders, invoices, and delivery notes, then flags any discrepancies for the accounts team directly within their SAP system.
Step 4: Export clean data directly to your tools
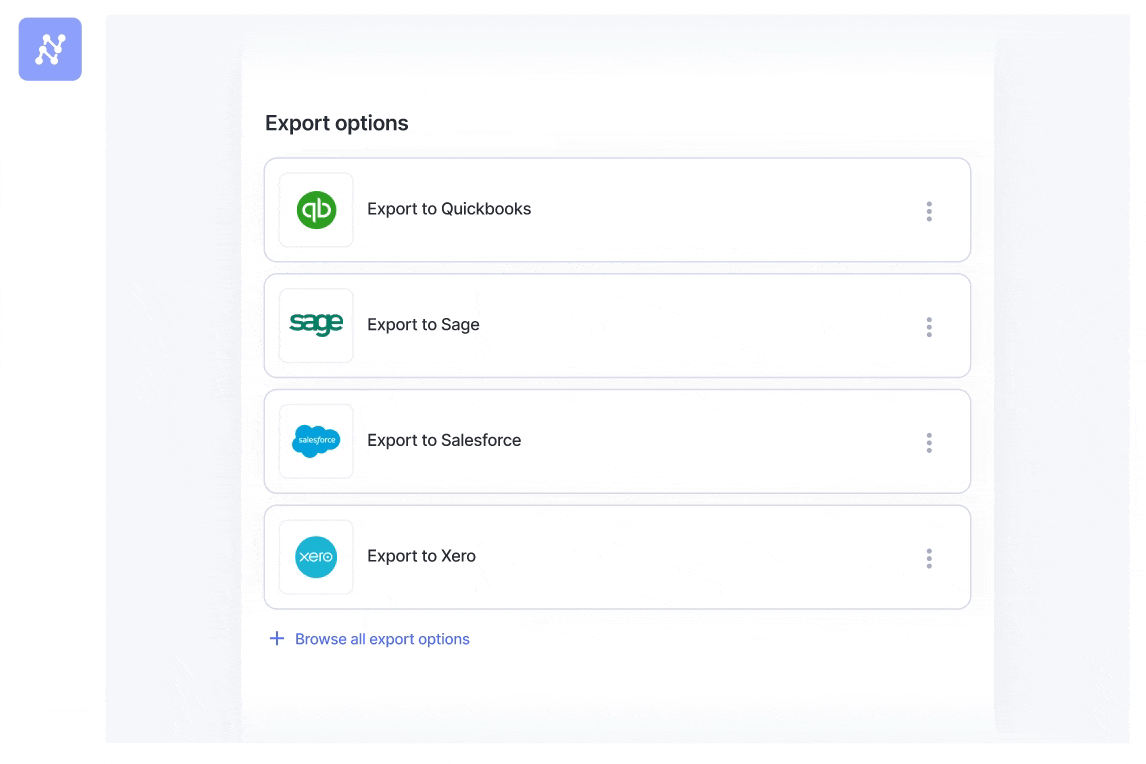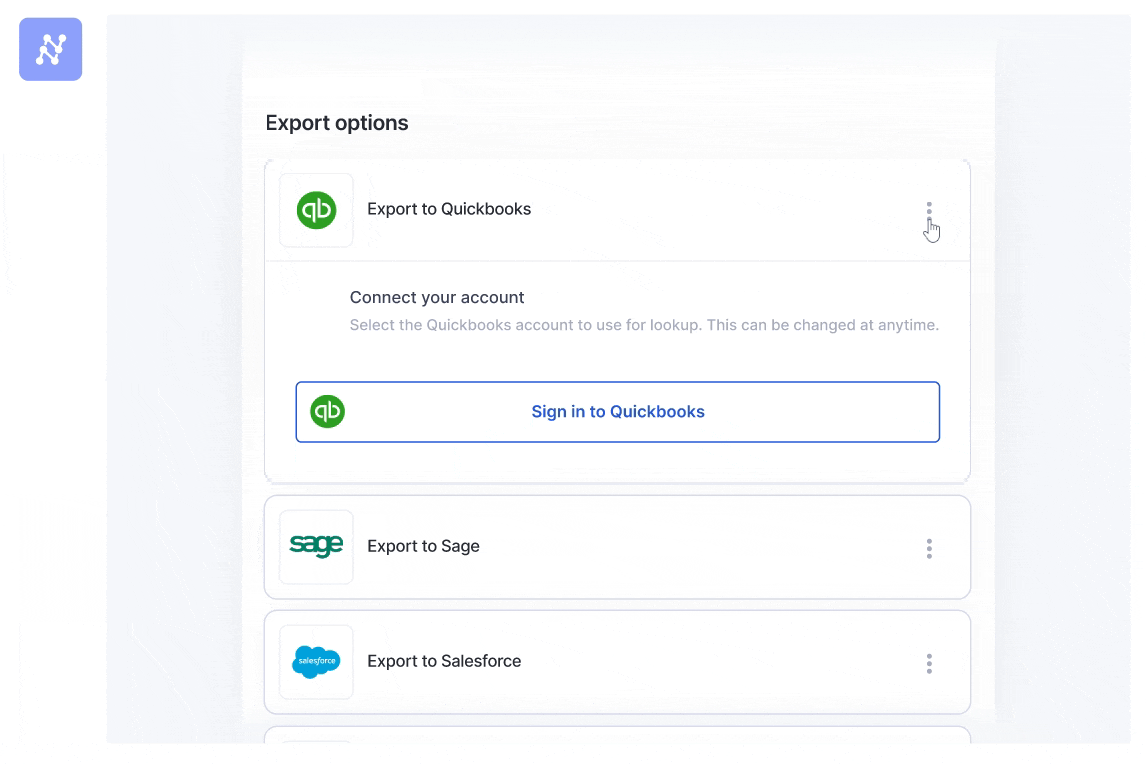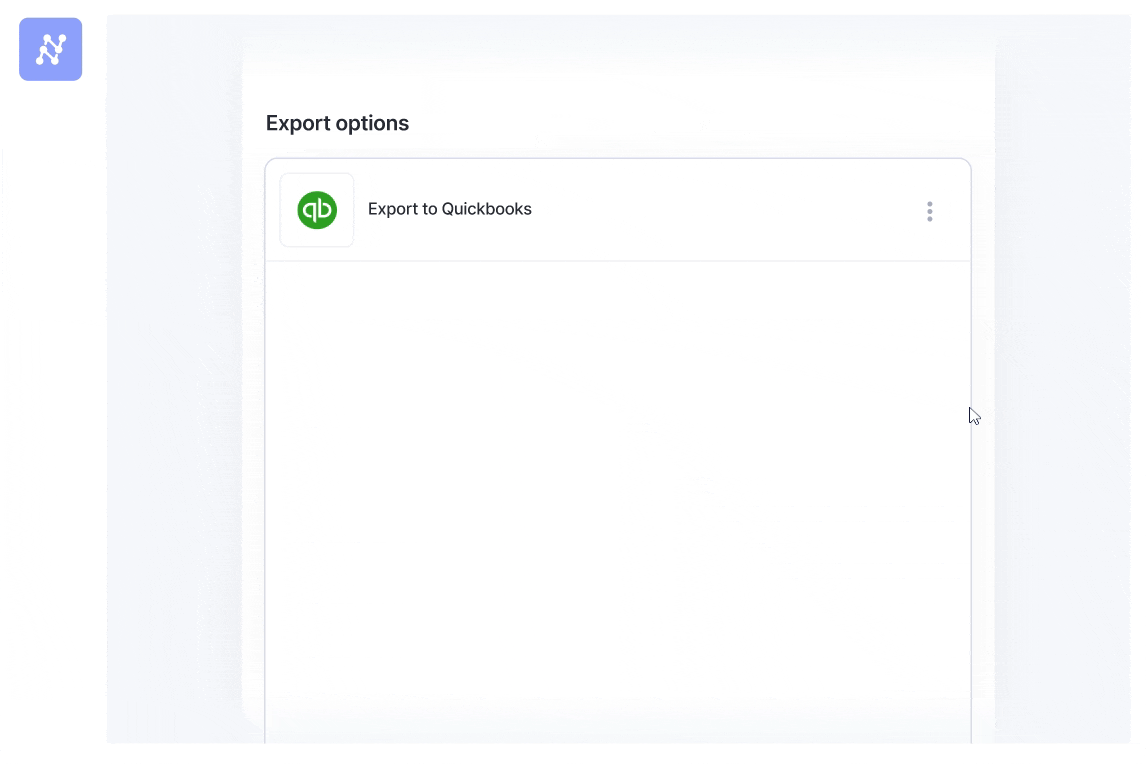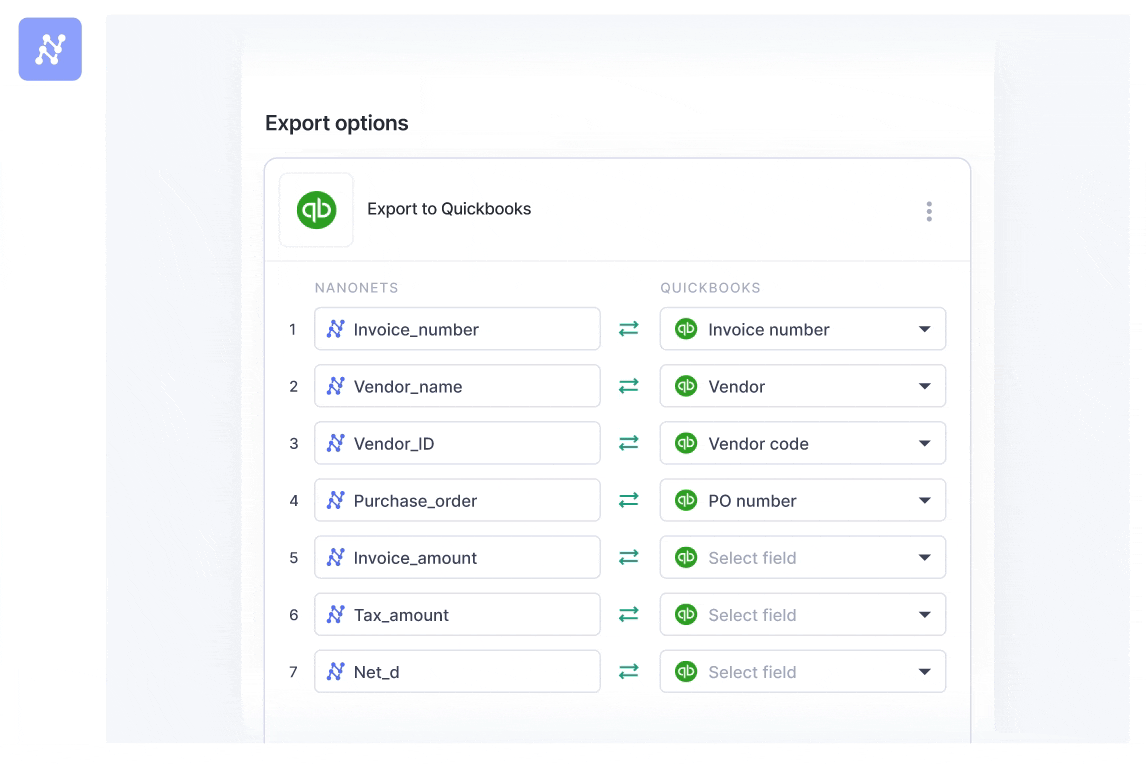
The final step is getting the clean, structured data where it needs to go, without anyone having to lift a finger. Nanonets has pre-built integrations for popular tools like QuickBooks, Salesforce, and SAP, as well as general-purpose exports to LLM applications, databases or even a simple Google Sheet. The goal is a seamless flow of information, from unstructured document to actionable data in your system.
For Augeo, an outsourced accounting firm, this was a game-changer. They use our direct Salesforce integration to automate accounts payable for a client processing 3,000 invoices every month. A process that used to take their team 4 hours each day now takes less than 30 minutes.
Unstructured data extraction in action
The impact of this technology is most profound in document-intensive industries. Here are a few examples of how our customers use intelligent automation to transform their operations:
- Banking & finance: Financial institutions are buried in documents like loan applications, financial statements, and KYC forms. We help them automate the extraction of critical data from these sources, which drastically speeds up credit decision-making, improves compliance checks, and streamlines customer onboarding.
- Insurance: The insurance claims process is notoriously paper-heavy. We see firms using automated document processing to extract data from claim forms, police reports, and medical records. This allows them to verify information faster, reduce fraud, and ultimately accelerate claim resolution for their customers.
- Healthcare: An estimated 80% of all healthcare data is unstructured, locked away in physicians' notes, lab reports, and patient surveys. By extracting and structuring this data, hospitals and research organizations can gain a more comprehensive understanding of patient history, identify candidates for clinical trials more quickly, and analyze patient feedback to improve care.
- Real Estate: Property management firms deal with a constant flow of leases, maintenance requests, and vendor contracts. Automating data extraction from these documents helps them track critical dates, manage expenses, and maintain a clear, auditable record of their operations.
The business impact of getting more out of your unstructured data
This isn't just about making a tedious process more efficient. It's about turning a data liability into a strategic asset.
- Financial impact: When you process invoices faster, you can take advantage of early payment discounts and eliminate late fees. For Hometown Holdings, a property management company, this led to a direct increase in their Net Operating Income of $40,000 annually.
- Operational scalability: You can handle five times the document volume without hiring more staff. Ascend Properties grew from managing 2,000 to 10,000 properties without scaling their AP team, saving them an estimated 80% in processing costs.
- Employee satisfaction: You free up smart, capable people from mind-numbing data entry. As Ken Christiansen, the CEO of Augeo, told us, it's a "huge savings in time" that lets his team focus on more valuable consulting work.
- Future-proof your AI strategy: This is the ultimate payoff. By building a pipeline for clean, structured, LLM-ready data, you are creating the foundation to leverage the next wave of AI. Your entire document archive becomes a queryable, intelligent asset ready to power internal chatbots, automated reporting, and advanced analytics.
How to get started
You don’t need a massive, six-month implementation project to begin. You can start small, see the value almost instantly, and then expand from there.
Here’s how to begin:
- Pick one document type that causes the most pain. Invoices are usually a great place to start.
- Use one of our pre-trained models for Invoices, Receipts, or Purchase Orders to get instant results.
- You can sign up for a free account, upload a few of your own invoices, and see the extracted data in seconds. There's no complex setup required.
Ready to tame your document chaos for good? Start your free trial or book a 15-minute call with our team. We can help you build a custom workflow for your exact needs.
FAQs
What is the difference between rule-based and AI-driven unstructured data extraction?
Rule-based extraction uses manually created templates and predefined logic, making it effective for structured documents with consistent formats but inflexible when layouts change. It requires constant manual updates and struggles with variations.
AI-driven extraction, by contrast, uses machine learning and NLP to automatically learn patterns from data, handling diverse document layouts without predefined rules. AI solutions are more flexible, scalable, and adaptable, improving over time through training. While rule-based systems work well for repetitive tasks with fixed fields (like standard invoices), AI excels with complex, varied documents like contracts and emails that have inconsistent formats.
How is AI-powered extraction different from traditional OCR software?
Traditional OCR was template-based, meaning you had to manually create a set of rules for every single document layout. If a vendor changed their invoice format, the system would break.
Our approach is template-agnostic. We use AI that has been pre-trained on millions of documents, so it understands the context of a document. It knows what an "invoice number" is, regardless of where it appears, which means you can process documents with thousands of different layouts in a single, reliable workflow.
What does it mean for data to be "LLM-ready"?
LLM-ready data is information that has been cleaned, structured, and prepared for an AI to understand effectively. This involves three key steps:
- Cleaning and Structuring: Removing irrelevant "noise" and organizing the data into a clean format like JSON.
- Chunking: Breaking down long documents into smaller, logical pieces that preserve context.
- Embedding and Indexing: Converting these chunks into numerical representations that can be searched and analyzed by AI.
How does automating data extraction help a business financially?
Automating data extraction has several direct financial benefits. It reduces costly manual errors, allows companies to capture early payment discounts on invoices, eliminates late payment fees, and enables businesses to handle a much higher volume of documents without increasing headcount.
Is unstructured data extraction scalable for large datasets?
Yes, unstructured data extraction can effectively scale to handle large datasets when implemented with the right technologies. Modern AI-based extraction systems use deep learning models (CNNs, RNNs, transformers) that process massive amounts of complex data efficiently.
Scalability is further enhanced through cloud computing platforms like AWS and Google Cloud, which provide elastic resources that grow with your needs. Big data frameworks such as Apache Spark distribute processing across machine clusters, while parallel processing capabilities enable simultaneous data handling.
Organizations can improve performance by implementing batch processing for large volumes, using pre-trained models to reduce computational costs, and adopting incremental learning approaches. With proper infrastructure and optimization techniques, these systems can efficiently process terabytes or even petabytes of unstructured data.
Do I need a team of developers to start automating data extraction from unstructured documents?
No. While developers can use APIs to build custom solutions, modern platforms are designed with no-code interfaces. This allows business users to set up automated workflows, use pre-trained models for common documents like invoices, and integrate with other business software without writing any code.