Data Cleaning - Definition, Automation & How to Clean Data Efficiently
In this ever-evolving world of technology, businesses need to stay competitive. That said, they must have robust business processes and 100% accurate data at any time. However, the irony is most data that organizations receive from various sources are inconsistent and contain some errors.
With businesses aiming to leverage data-driven decisions, it becomes imperative to access accurate and correct data across the enterprise. Data could contain multiple inconsistencies - formatting issues, syntax errors, typos, irrelevant values, missing entries, etc. All these have to be tackled appropriately to achieve “clean” data. That leads us to the concept of - data cleaning.
Well, this article delves into what data cleaning is, how data cleaning works, why to use data cleaning, data cleaning use cases/examples, data cleaning for enterprises, data cleaning automation, and more.
So, let’s get started.
What is Data Cleaning?
Data cleaning refers to going through the database and correcting errors in data sets by fixing inaccurate, duplicates, or other erroneous values. Data cleaning includes removing and updating improperly formatted values, incorrect values, irrelevant or duplicates, etc.
In essence, data cleaning aims to make the data free of any inconsistencies and thus ensure the highest quality, making it apt for informational decision-making.
What types of errors can you fix with data cleaning?
Some of the types of errors fixed as a part of the data-cleaning process include:
Typos, Invalid or Missing data: Data cleaning corrects various errors like misspellings, wrong numerical entries, blank fields that must contain data, etc.
Inconsistent Information: Data cleaning checks for inconsistencies in the given data set. For example, say you have data in a spreadsheet wherein the zip code is entered for addresses of certain employees while it isn’t for others. Besides, some terms or identifiers might also differ across the dataset. Data cleaning eliminates such non-uniformities to ensure the data is analyzed correctly.
Merging or eliminating duplicates: Sometimes, your data sheets may contain duplicate values. Furthermore, if you combine two data systems, the new system might include copies. Data cleaning handles these issues by eliminating or merging duplicates and creating single records.
Irrelevant data: Data cleaning helps remove unrelated data which may not be pertinent to the analyses. For example, some out-of-date entries are not significant for the process. Thus, data cleaning reduces data redundancy, makes the data streamlined, and ensures optimal storage and processing resource usage.
How does data cleaning work?
Data cleaning primarily deals with cleaning up your inconsistent data. It includes removing and updating errors like typos, and syntax errors, standardizing your data, removing unwanted outliers, dealing with missing entries, and finally, validating the data.
Based on the volume of your datasets, you can adopt manual or automated data-cleaning techniques. While the manual process could be highly time-consuming, data cleaning automation could significantly help improve quality and efficiency by reducing time spent and eliminating human effort.
Why should you use data cleaning?
While we often hear about data cleaning in the professional arena, the term is relevant and essential to individuals and businesses.
Data Cleaning for individuals
Often, people store a lot of information on their systems as various files. These include bank details, credit card details, and personal information. Over time, the number of files increases, and the systems get cluttered.
This would not help in the long run as it could result in problems like files getting misplaced or losing some information. Well, that’s where data cleaning comes into the picture. It helps ensure your files contain only relevant information which is up-to-date and accurate.
Data cleaning obviates the need to wade through several hundreds of files or documents on your system before you get the one you are looking for. Additionally, it prevents you from storing unwanted or huge amounts of information to find the required data easily.
Data Cleaning for Organizations
Businesses need to store a lot of information. Taxes, receipts, employee data, bank statements, contracts, etc.
This, in turn, creates the requirement of keeping the data safe and well-organized. Data cleaning is the step to having a complete and structured database.
With data cleaning, you can ensure that all the business data is correct, in order, and securely stored. Any time you refer to the data, it will be accurate and reliable.
Data cleaning increases data quality and enhances productivity. In addition, it avoids incurring unexpected costs. For instance, some data you store may be used on essential business documents. If it contains errors, your reputation could be at stake.
Data cleaning avoids such situations, ensuring that the data stored and maintained is of the utmost quality.
Want to automate repetitive data cleaning?
How to clean data?
Data cleaning essentially involves the below-mentioned steps.
Step 1. Remove undesirable observations
The first stage in data cleaning involves removing irrelevant data points from focus. While you may have a tremendous volume of data, not everything may be relevant, considering the current problem you are trying to solve. Say you are studying the lifestyle characteristics of senior citizens in a location, so having data related to children may not make sense.
Make sure you get rid of all such data in the first place. This step also involves removing duplicate entries from your dataset that may have popped up while combining two systems or fetching data from third-party sources.
Step 2. Fix Structural Errors
In the next stage, the errors like improper labeling, typos, inconsistent capitalization of words, and such are fixed. Depending on the data you are handling, these could range from a handful to several hundred. In addition, you may also need to look for underscores, hyphens, or other such inconsistencies, if any, in the naming conventions used.
Step 3. Standardize your data
While removing capitalization errors is crucial, you must see other aspects that standardize your data.
For example, either all the values in the dataset are in lowercase or uppercase. In the case of numerical measurement, all values represent the data in the same units - for example, all distances in kilometers.
Likewise, in the case of dates, either everywhere month precedes days in the format or vice-versa.
Step 4. Remove inappropriate outliers
Outliers are special data points that differ from the others in the dataset. The role and significance of outliers depend on the analysis or approach you are adopting.
In some cases, like decision trees used in machine learning, outliers are significant, while in the case of linear regression, they may adversely impact the results. Ensure you remove an outlier only when you are confident it is erroneous or irrelevant to your current scenario.
Step 5. Tackle Contradictory data errors
Contradictory data errors are those which involve a complete record of inconsistent data.
For example, if the total marks obtained by a student are unequal to the sum of the marks scored in individual subjects, then it is considered a contradictory data error. Other instances could be staff’s taxes being greater than gross pay.
Step 6. Check for Type Conversion
While completing the above steps may make you think that everything is complete; however, you may miss one vital aspect.
In your dataset, you must ensure type conversion - meaning text data is entered as text, numerical data as numbers, dates as objects, etc. This might also bring your attention to correct syntax errors like extra white spaces etc., if any.
Step 7. Handle Missing data
Now, it’s possible some fields in your dataset may be blank, as in values missing. While you can remove all the missing entries or enter some values randomly, this may not be a recommended suggestion.
Alternatively, based on the type of data that the value must hold, say if it’s a number, you can put ‘0’. This would make your analysis more logical and render informative outcomes.
Step 8. Validate your dataset
The final stage is to perform a thorough validation of the dataset. This involves checking if all the processes of standardizing, checking for typos, syntax errors, etc., are complete.
Usually, there are scripts that are run through the datasets to carry out the validation. In case it returns any errors, you must fix them before proceeding.
Want to use robotic process automation? Check out Nanonets workflow-based document processing software. No code. No hassle platform.
How to automate data cleaning?
All the steps in data cleaning can be automated easily using no-code workflows. Platforms like Nanonets can help you automate every aspect of data cleaning with simple workflows:
Set up automated data collection
Most data automation platforms can collect data, documents, or more automatically.
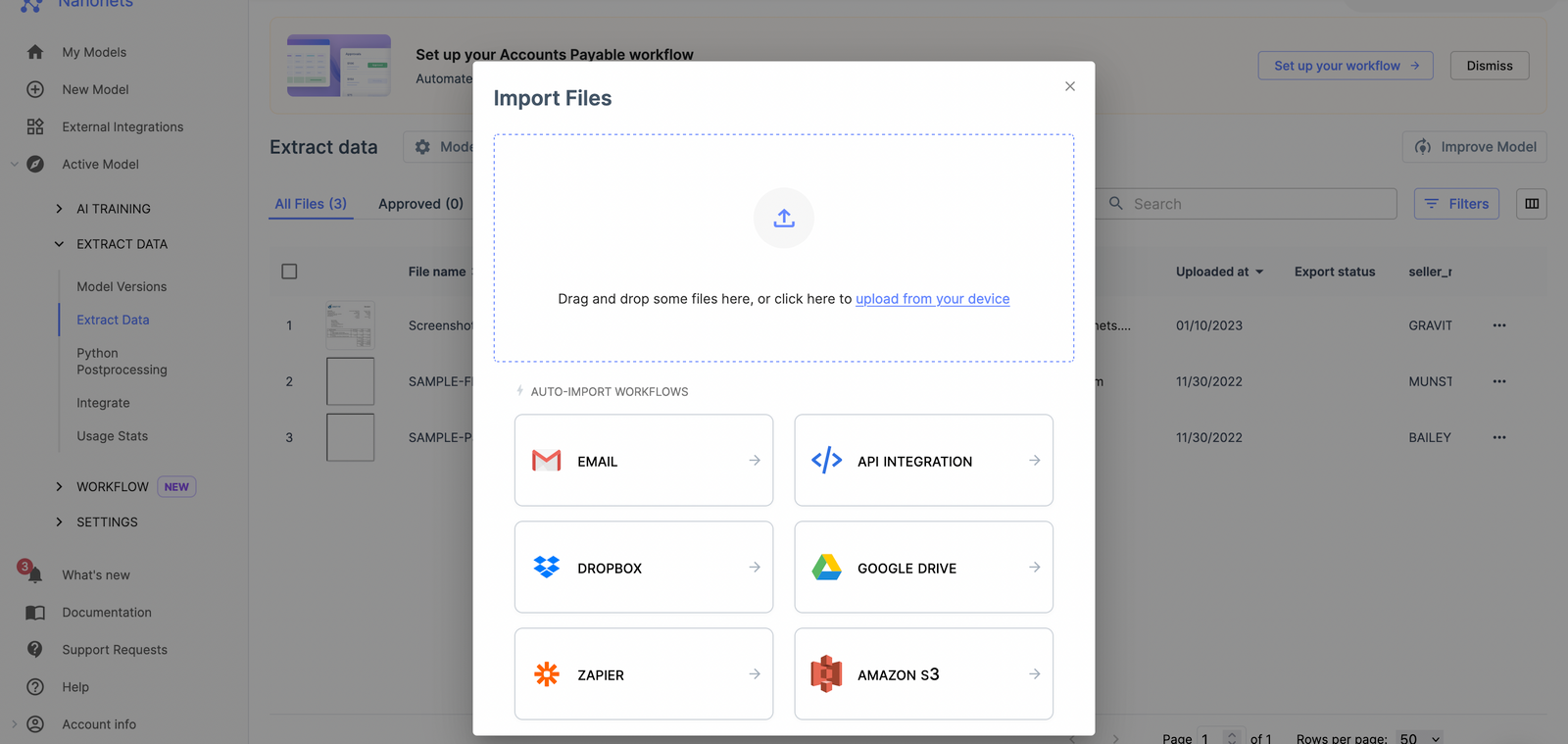
Set up rules to clean data easily
Decide all the tasks you want to perform and set up all the rules on the workflow.
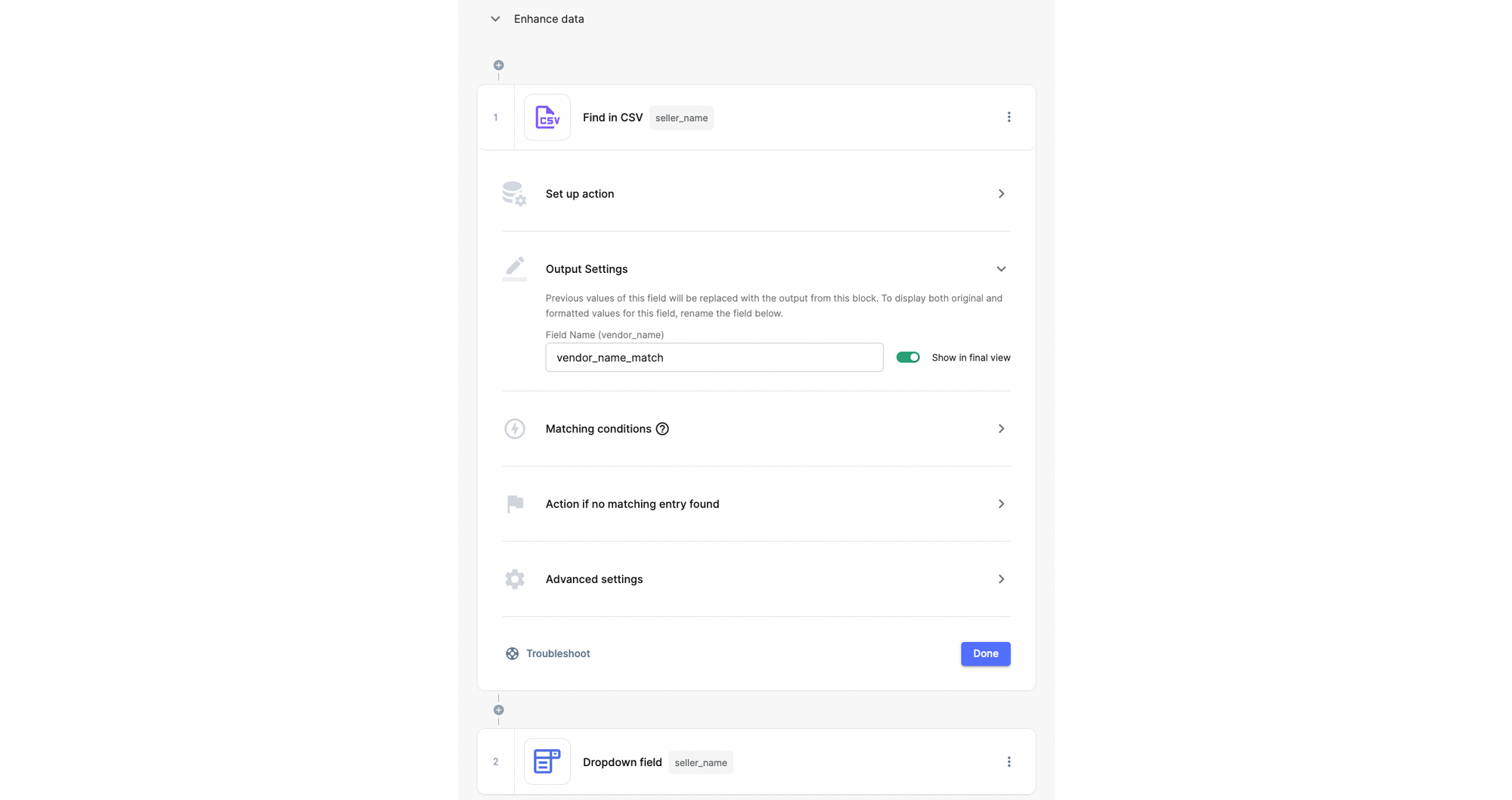
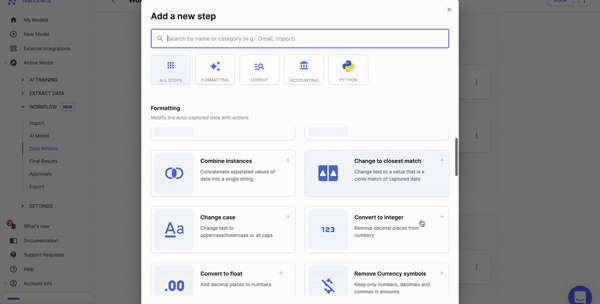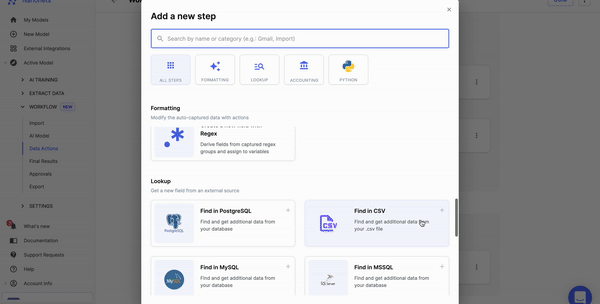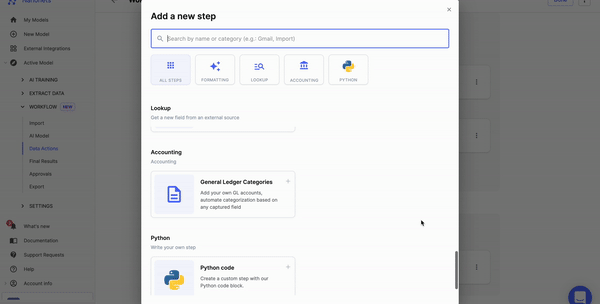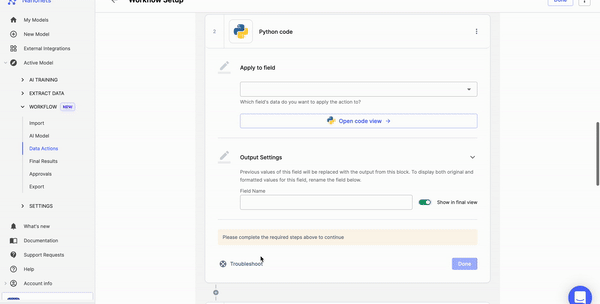
Select the data transformation options that you need
There are many options to perform data cleaning without writing any code. Select the options that you need.
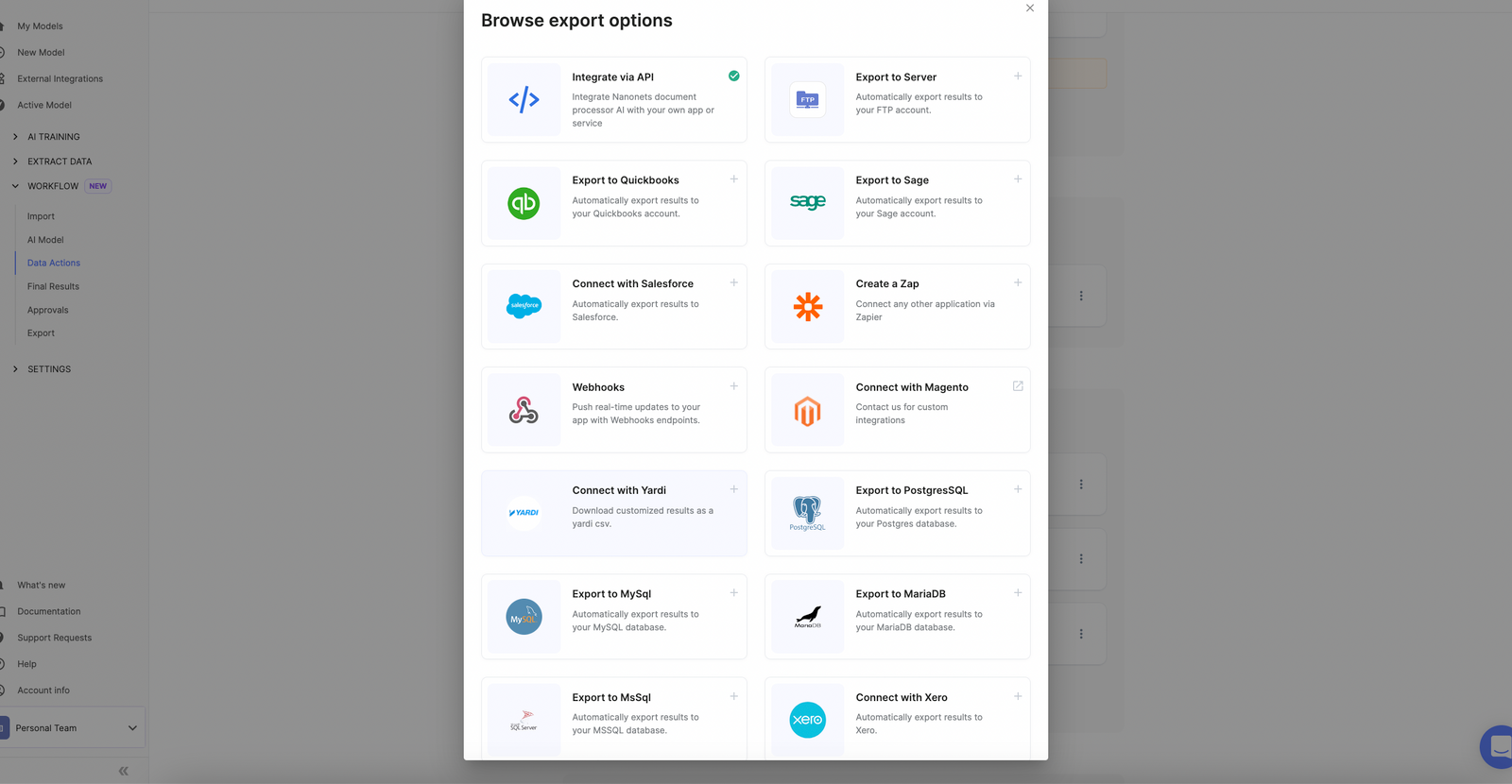
Export to the software of your choice
Once data is cleaned, sync the data with multiple data options that are possible.
What are the best practices for data cleaning?
Some of the best practices recommended for data cleaning include:
Formulating a data-quality strategy
Having a well-structured data-quality strategy in place could help address several challenges. The steps include setting expectations for your data, data-quality KPIs, finding incorrect data, understanding the root cause of the issue, and developing an action plan to ensure the accuracy and reliability of your data.
Ensure correct data is entered
Create appropriate standard operating procedures for employees to follow about entering data into various company systems. Make sure they always enter the correct data in the proper format.
Test the accuracy of the data
In this step, you validate the accuracy of your datasets. While this can be done manually, an automated process is recommended for complex and huge volumes of datasets as it saves time and effort. You can divide the datasets into smaller ones and validate each separately. Finally, you can validate the complete dataset to check for any inconsistencies.
Fill in the missing data
Sometimes, you need to append the dataset with missing information such as email address, last name, date of birth, address, etc. However, finding these values could be somewhat tricky. It is recommended that companies take the help of reliable third-party sources to complete this task.
Enforce the use of clean data across your enterprise
Emphasize the ideology of using clean data among your employees. Communicate regularly on the importance of clean data through various channels. Make sure your employees adhere to the usage of clean data, regardless of the function, department, or domain they might be in.
If you work with invoices, and receipts or worry about ID verification, check out Nanonets online OCR or PDF text extractor to extract text from PDF documents for free. Click below to learn more about Nanonets Enterprise Automation Solution.
What are the different use cases for data cleaning?
Data cleaning offers several useful applications across industry domains, making it a primary component of business processes. Let’s check some of the major data cleaning use cases/examples from various domains.
Marketing
Let’s consider an example of marketing. For example, the marketing division of a company wants to run campaigns that require information on demographics like age, location, gender, etc. Based on the campaign outcomes, the division would finalize its ad budget.
Suppose the data obtained on demographics is incorrect; the exercise's purpose would be invalidated. This is where data cleaning comes into the picture. The division must clean the data, remove all inconsistencies and errors and then do a fresh analysis to obtain accurate results.
Operations
Take the case of the manufacturing industry, where operations have a major role. These days, most operational activities are programmed for Robotic Process Automation (RPA) and are executed based on the automation software.
The automation will not render the desired outcomes if wrong data is fed into the system. That makes it imperative to use clean data, free from errors, typos, and such.
Finance
As data is the key driver in the financial domain, it offers a valuable data-cleaning use case. Data holds the power to make or break it. Everything relies on data from managing customer accounts and financial analysis to creating reconciliations and preparing budgetary plans.
Using inaccurate data anywhere could result in disastrous circumstances that could hamper the company’s reputation, leading to huge financial losses as well. That makes data cleaning all the more important for the finance domain.
Sales
While marketing focuses on attracting customers, sales include retaining existing customers as well. Imagine if incorrect contact information or the purchase history of existing customers is stored; you could lose a valued customer. And if this recurs, there could be a domino effect, resulting in you losing several precious customers.
Banking
The banking space involves handling and processing enormous volumes of transactions daily. All these revolve around the central element - data. That said, having complete, accurate, and reliable data is very critical. Banks perform various activities like loan processing, assessing credit worthiness of individuals, and more. If the data maintained is inconsistent, it could result in serious consequences. Data cleaning helps ensure that the data used is consistent and correct.
Compliance
With the increased volume of data that businesses handle, various compliance regulations have gained significant momentum. Data security and data privacy are more important than ever before.
Maintaining incorrect data and not updating it regularly could result in data leaks and hacks. This poses a greater threat to companies as they may suffer financial and reputational losses. That, in turn, mandates businesses to embrace data cleaning and practice it religiously across divisions and departments.
Want to automate repetitive manual tasks? Save Time, Effort & Money while enhancing efficiency!
Data Cleaning for enterprises
With data becoming more critical, data cleaning has become a mandate for enterprises. Most data that businesses receive from various sources are inaccurate and inconsistent. In addition, companies use data for purposes like predictive modeling, which involves forecasting future trends based on historical data. If the past data is incorrect, it would certainly impact the outcomes. That said, experts in organizations must perform data cleaning and ensure that data is 100% accurate and consistent, making it appropriate for making forecasts.
In addition, businesses transact with others, and in many ways, these data come into the picture. Responding to customers or stakeholders with inaccurate or erroneous information could drastically hamper the business reputation, dilute the trust and affect the opportunities of constituting long-lasting professional relationships.
Conclusion
Data cleaning ensures that the data you need is free of any errors or inconsistencies to conduct a detailed analysis. Businesses must adopt data cleaning if they haven’t yet and leverage its capabilities to derive meaningful outcomes.
The various aspects of data cleaning, including what data cleaning is, how it works, data cleaning automation, data cleaning use cases/examples, and more, are discussed in the article.
Nanonets online OCR & OCR API have many interesting use cases that could optimize your business performance, save costs and boost growth. Find out how Nanonets' use cases can apply to your product.


