
What is Data Matching?
Data matching is the process of finding identical entries from one or more collections of data and unifying the data records. It could be performed between datasets to ensure that data from various datasets is synced. Matching examines the extent of overlap across all entries in a single data set and returns the weighted probability of a match for each pair of records matched. After that, you can pick whichever entries are matching and take measures on the underlying data.
It can be used to eliminate duplicate content or for a variety of data mining applications. Data matching, generally, enables people with big volumes of data to do more accurate inquiries that yield more accurate results. Many data matching efforts are made to establish a critical connection between the two large datasets for advertising, safety, or other practical goals.
Download the expert's guide to document automation for Data Matching
What is Data Classification?
The technique of classifying data into corresponding classes so that it can be utilized and safeguarded more reliably is known as data classification. The classification technique, at its most basic level, makes the data easier to spot and recover. Whenever it comes to strategy governance, regulation, and data protection, data classification is critical.
Document classification entails categorizing information from documents to make it more accessible and actionable. It also removes multiple data duplications, which can save money on storage and recovery while also accelerating the processing time. However the categorization process may appear to be very complex, it is a matter that any effective manager should be familiar with.
What are the types of Data Classification?
Data classification frequently entails a plethora of categories and identifiers that characterize the sort of information, as well as its secrecy and authenticity. In data classification processes, unavailability could also be factored into the equation. The delicacy of data is frequently classed based on several degrees of paramountcy or privacy, which is then linked to safety measures implemented to safeguard each level of classification.
There are three forms of data classification which are widely used:
Content-based
Documents are inspected and interpreted for private data
Context-based
The program, locale, or developer, among many other criteria, are used as indirect markers of private data
User-based
A personal, terminal identification of every item is required for this. This categorization focuses on user expertise and judgment during development, alteration, inspection, or publication to indicate important files.
Based on the industry requirement and type of data, all three techniques could be both appropriate and inappropriate.
Want to scrape data from PDF documents, convert PDF to XML or automate table extraction? Check out Nanonets' PDF scraper or PDF parser to convert PDFs to database entries!
Data Classification Examples
Based on the risk level of the data,
What is a Data Classification Matrix?
Certain businesses may find it simple to create and classify data. Assessing the vulnerability of networks and programs is usually much easier when there aren't too many different data categories or even if the firm has limited interactions. However, many businesses with large amounts of data force a full risk assessment. Most organizations utilize a "data classification matrix" for all of this.
Using matrices to rate data based on how susceptible these ought to be corrupted and also how delicate the data is will allow you to swiftly decide how and where to properly classify and safeguard all private information.
How does Data Matching work?
Establishing that multiple "entities" are, in actuality, the same "entity" is the challenge that data matching attempts to tackle. Data matching can be done in a variety of ways. The method is frequently based on a data matching algorithm or a programmed loop, in which each item of data is examined and compared to each element of the other data set. Several algorithms are used to go explore datasets and find identical entries that fit.
Data could be linked primarily to two approaches. Record linkage that is deterministic and based on multiple matched identifiers. Probabilistic record linking is based on the likelihood of multiple identifiers matching. Probabilistic data matching is the most popular, as deterministic linking is too restrictive.
First, the data must be organized, or divided, into blocks of equal size and attribute. Following this, the matching bears place. Names, for instance, can be alphabetically and numerically matched.
The relative weight of each property is then determined to evaluate its significance. The likelihood of matching must then be calculated. Finally, to calculate the Total Match Weight, an algorithm adjusts the relative weights for each feature. The outcome is then: a probability match for two objects.
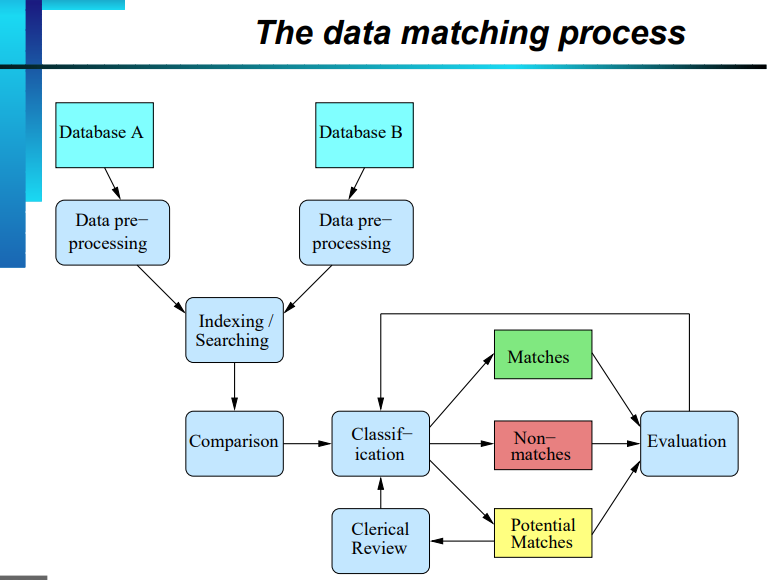
Source: Australian National University
Want to automate repetitive manual tasks? Check our Nanonets workflow-based document processing software. Extract data from invoices, identity cards or any document on autopilot!
Why is Data Matching Important?
Data matching can help us to reduce identical details. This is necessary as bad quality, replicated, and discordant data can create various complications.
Unnecessary costs
It is a costly affair for an organization to send multiple catalogs to one individual. The corporation is producing more files than necessary, and there are mailing expenses to consider, as well as any potential bad consequences; no consumer-like being pressured.
Various sources of customer information
The data must be precise and detailed if an organization desires to conduct an analysis of the data or make forecasts regarding potential trends. There is no clear picture of the customer's actions if the data has inconsistencies.
Client Service Issues
Retaining a client and giving appropriate service becomes more difficult when customer records are scattered across multiple places. It can be unpleasant for users to receive a thorough overview of their transactions or interactions if there are several transactions for the very same client under various formats.
Poor Public Opinion
Clients don't like being bombarded with content, be it in the form of a weekly email or postal mail, especially if that's the same campaign time after time. Placing identical cold calls with the same person will not make a positive impact on the client.
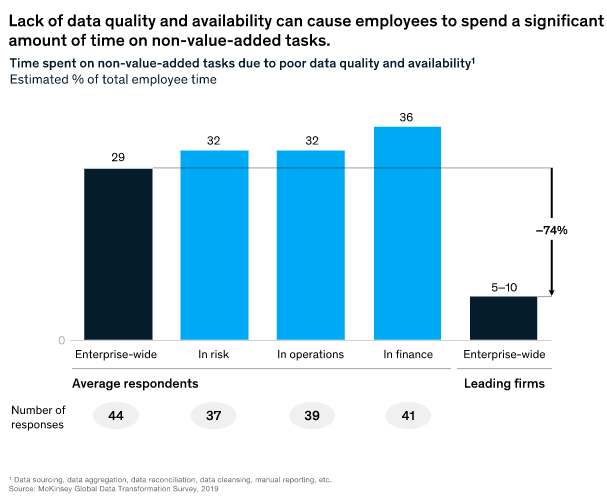
Source: McKinsey
How can Data Matching be used?
Companies can more readily discover duplicate entries using data matching – also known as record linkage – by identifying more reliable connections. Choose a master record and delete those that are alike. Also, look at the potential matches that aren't the same entity.
As a result, after analyzing and cleaning, data matching is regarded the most critical function.
Want to use robotic process automation? Check out Nanonets workflow-based document processing software. No code. No hassle platform.
What are the benefits of using Data Matching?
Data matching is among the first phases in any company's entire data management plan, especially if it's based on master data management.
Enhance Precision
Data matching makes it easier to compare data, spot trends, and indicate red flags in complex data that need to be investigated further. It's a dependable instrument that allows for better prediction requirements while limiting irrelevant data to a minimal level.
Improve Data Dependability
Organizations use a wide network of interconnected applications and data systems to create an internal data infrastructure. When data is collected from a variety of sources, however, there is a significant possibility of inconsistencies in the information. Data cleaning and reducing duplicates are critical in these situations to ensure data trustworthiness.
Structure Data
Machine learning entails combining data from a variety of sources. Skimming through several raw data sets, cleaning, characterization, minimizing repetitions, and combining for accurate analytical results is made easier using data matching technologies. To standardize data, a company must be able to organize and filter a large number of entries from multiple data sources.
It also necessitates the conversion of numerical information, such as contact information, into a suitable and uniform structure. Data is formatted and prepared to be processed and analyzed by secondary management information systems.
Improve Accuracy
Any choices taken based on inaccurate information are a waste of time and resources. Organizations will benefit from data matching to boost performance across disciplines. Work performance and overall performance will improve significantly.
Refine Data
By merging data from reliable third-party sources with an existing dataset, an organization can profit from database strengthening. Companies can improve their revenues, branding, manufacturing, and other activities by enhancing the accuracy and reliability of customer data. The upgraded data fills in any gaps in the customer information, giving the company a comprehensive picture of its customer base.
Boost Compliance
Data matching aids in ensuring that the law is followed. Before contacting a client, an organization must first obtain consent to use the user’s information, such as phone numbers, in marketing initiatives. Obtaining authorization from clients gets more complex due to the multimodal model of consumer involvement. Furthermore, the risk of penalties increases when data is wrong and varies between websites. Businesses can pinpoint the customer they are dealing with, allowing them to request special permission.
Reduce the space required for storage
Reducing duplicates is a method of reducing the number of entries in a collection. This requires less space for storage, reduces the stress on the network whenever a program requests information, and improves information quality.
Prevention of frauds
Many insurance providers loses money owing to bogus claims and reimbursements because of hidden interconnections between firms. Different programs receive a variety of data reports, and yet no data matching implies no red lights are alerted. Fraudsters generate inconsistencies by keeping identical data across multiple locations within an organization, making it difficult to trace back to the initial documentation.
Personnel may also use deception to fabricate records, such as purchase receipts or even other paperwork, to benefit themselves. Using algorithms to find the conventional relationships between different forms, data matching programs could discover relationships between different datasets.
What are the benefits of Data Classification?
Enhancing Security
When we classify client data (corporate or consumer) based on various criteria whether it is the risk level or the format, it helps us to find answers to various questions which pertain to the sensitivity level of the data, the location of the data, the grade of safety or impact of a breach of security and who can access or alter the data. Hence, changes can be made to the structure of the current framework to decrease the risk of breach, destruction, or modification of the sensitive data. It can also help us to optimize costs by allocating fewer resources to less-critical data.
Regulatory Adherence
Data classification aids in locating regulatory data within the organization, as well as ensuring that adequate safety systems are in place and also that the content is accessible and navigable, as mandated by regulatory requirements. This improves our chances of passing regular audits, ensures that data is managed securely for regulatory requirements, and keeps us by all applicable policies, and data protection laws daily.
Boosting Efficiency
Data classification will assist organizations in successfully securing, preserving, and controlling their data from the moment it is generated until that is discarded. This allows us to develop a better understanding of and regulate the records that organizations retain and distribute, as well as enable rapid direct connections to and the use of secured data throughout the organization. It also aids in risk assessment by assisting organizations in determining the power of data and the consequences of this being destroyed, purloined, mishandled, or compromised.
If you work with invoices, and receipts or worry about ID verification, check out Nanonets online OCR or PDF text extractor to extract text from PDF documents for free. Click below to learn more about Nanonets Enterprise Automation Solution.
How can we optimize Data Classification?
Forming a Data Classification system
Organizations must next establish a classification structural outline with enhanced business parameters and an awareness of their particular kinds of sensitive information when one data classification structure has already been built. However, this is not a simple task. All businesses are unique, but there's no such thing as a universal data protection plan.
Every subcategory in the data categorization outline should specify the categories to be incorporated, the hazards of data breaches, and data - management standards.
Forming various Data Classification categories
Although there are many different ways of categorizing data, most businesses use a four-input categorization outline: general, private, classified, and restricted.
- Promotional materials, contact details, client service agreements, and pricing data are examples of public information that is openly accessible and available to the general public without any limits or negative impacts.
- Customer interactions, marketing handbooks, and process diagrams are examples of inside data with a low level of security need yet not intended for public publication. The unwanted revelation of such material might result in public disgrace and a competitive disadvantage in the near term.
- Sensitive material that, if leaked, could still have a bad effect on the company's business, including damaging users, affiliates, or staff. Agreements with vendors, personnel evaluations and pay, and customer data are just a few examples.
- Extremely sensitive commercial information that, if leaked, might place the company's financial, administrative, legal, and social interests at stake. Customers' debit card details are an example.
Best policy practices
Using best practices, organizations can guarantee that their categorization procedures are successful and that they get more value out of them. Companies also prefer to prevent the risks of incorrect data categorization, which could also lead to a long-term bad impression of this important data protection tool.
Four phases are included in several best practices for building a comprehensive and effective categorization plan.
Incorporate computerized, concurrent, and durable data categorization
The proper software and hardware assessment streamlines the data categorization procedure by autonomously assessing and categorizing data according to predefined specifications.
Decide to classify your data
Cooperation from top to the bottom and through the executive team aids to promote the effort. It establishes the expectation that categorization is a primary concern and everybody is expected to take part. It also indicates that the organization appreciates its privacy and that proper data security and management are part of the organizational customs.
Define a new security adherence culture
Downsizing your presence requires training data providers, users, and proprietors on respective roles and functions in shielding data and enabling everyone to help limit your vulnerability. Many businesses regularly organize privacy-related sessions. It's preferable, though, to develop ways to instill a persistent feeling of privacy protection understanding in personnel's everyday practices.
Collaborate with IT and the organization
Companies can continue providing advice, assistance, and permission throughout every stage of the procedure by adopting a reliable procedure with IT.
Top use cases for Data Matching
Though the overall goal of data matching is to locate more precise and distinct data from a pool of identical records, the method used varies by industry.
Financial Services
Data matching is used by fintech, banking, and financial service firms to manage projects such as locating money laundering criminals and completing client credit scores. To acquire a complete overview of clients across several commercial activities, banks use data matching techniques.
Public Sector
To uncover scams, comply with the standards, and execute sociopolitical assessments, government and public sector entities rely on record centralization by reviewing personal identification data, like SSNs, and registration numbers. Data matching can aid in the detection of possible frauds, activities, and people involved. Also, for national surveys, the government receives a diverse variety of demographic data, which is typically gathered by various organizations under different guidelines and maintained in distinct systems. The authorities may develop statistics studies and gain a better understanding of various parts of the nation by combining these datasets.
Education Industry
Data matching is used in the field of education to detect duplication in learning and teaching datasets across geographies, as well as to assess the performance of students, discern varied teaching approaches, assess grade fluctuations, or differentiate between effective and ineffective teaching techniques.
Healthcare Sector
Patients' data is matched at healthcare facilities to determine proper diagnoses and precise prescriptions. To maintain the integrity of their patient records, they deploy data matching and cleaning processes through business apps. Without an automatic deduplication procedure, patients may be offered incompatible medications or obtain several treatments for the same ailments. Medical records are matched with several other datasets to assess the impact of various factors like medications, remedies, and conditions.
Marketing and Sales
By integrating data refinement and validation skills, data matching technologies enable enterprises to locate and categorize the target group depending on many sociodemographic characteristics. With appropriate personalization, a business may improve the impact of marketing and advertising operations by generating highly suitable and appropriate commercials or promotions for potential customers.
Want to automate repetitive manual tasks? Save Time, Effort & Money while enhancing efficiency!
Challenges in Data Matching
Data Matching Algorithms Can Be Complicated
Data matching is sometimes a simple process if protocols for information gathering and entry standards are already in existence. Matching techniques may require complicated reasoning to retrieve all possibly matched variables if there are fewer rigorous pre-dataset standardization techniques.
Data standardization is vital
Large amounts of data, especially, have the potential to cause problems. For instance, improper formatting, the usage of characters, and so on. Because this typed name could occur on several entries, programs must accommodate how this input should be processed.
Client Error
Clients can cause issues, particularly if they can report records and documents. If a user wrongly tags a major employer as "suspect" in an employment record, many legitimate candidates using the same firm may be flagged as "suspect" as a portion of the initial assessment. This decision will almost definitely have a detrimental impact on the corporation's recruiting operations as well as other organizations that trade and compare data.
Data Matching Errors
If two entries pertain to distinct entities, but the matcher assumes they seem to be the same, false-positive result. False negatives happen when two entries appear to be related to the very same subject, but the matcher claims they aren't. These must be understood by organizations, as well as their frequency and repercussions.
Conclusion
Data matching is critical for every organization that seeks to better its data repositories and deploy a data-based business strategy, regardless of the hurdles and limits. It enables businesses to develop scalable business and customer information duplication reduction, record linkage, reduction, enrichment, retrieval, and standardizing settings. It also creates a point source of information to optimize the usefulness of data throughout the enterprise.
Nanonets online OCR & OCR API have many interesting use cases that could optimize your business performance, save costs and boost growth. Find out how Nanonets' use cases can apply to your product.