
Several organisations and businesses rely on PDF documents to share important documents such as invoices, payslips, financials, work orders, receipts, and more. However, PDFs are not the go-to formats for storing historical data since they can’t be easily exported & organised into workflows. So people use information extraction algorithms to digitise PDFs & scanned documents into structured formats like JSON, CSV, Tables or Excel that can easily be converted into other organisational workflows.
In some cases, PDFs hold essential information to be processed in different ERPs, CMS, and other database-driven systems. Unfortunately, PDF documents do not have an easy PDF to database function, and writing scripts or building a workflow around this task is a bit complicated. Hence, in this blog post, we will look at different ways to export PDF to Database.
How to convert PDF to Databases
We will be covering how to export PDF to databases for the most popular databases–MySQL, PostgreSQL, and MS-SQL using Python and Nanonets.
Convert PDF to databases using Python
Converting PDF to Database using Python is a two-step process that requires–extracting text/tables from PDFs and exporting the extracted data to a database
We have comprehensive blogs that cover how to extract text from PDF using Python, extract data from PDF documents, and extract tables from PDFs using Python. You should definitely give them a read.
Hence, we will only focus on how to export the extracted data from PDF to databases. We will be covering the most popular relational as well as non-relational databases.
Before we push our table into databases, first, we should establish a connection to it from our program, and we can do this using the sqlalchemy client in python. We will cover the most popular databases–MySQL, PostgreSQL, and Microsoft SQL Server
Exporting data to PostgreSQL database
This method works with Pandas 0.14 or higher. First, you need to ensure that all required libraries are installed.
pip install pandas sqlalchemy psycopg2-binary
Once installed, we need to create a connection engine using SQLAlchemy to write the table to the database. Replace username, password, db_host, db_port, db_name with the values from your database.
import pandas as pd
from sqlalchemy import create_engine
engine=create_engine('postgresql://username:password@db_host:db_port/db_name')
Use .to_sql to write the data frame to the database. Replace db_table with the name of the table that you want. The below code will create the table if it does not exist and replace the table if it exists.
df.to_sql(db_table, engine, if_exists='replace', index=False)
Exporting data to MySQL database
Ensure that all the required libraries are installed.
pip install pandas sqlalchemy pymysql
Once installed, we need to create a connection engine using SQLAlchemy to write the table to the database. Replace username, password, db_host, db_port, db_name with the values from your database.
import pandas as pd
from sqlalchemy import create_engine
engine=create_engine('mysql+pymysql://username:password@db_host:db_port/db_name')
Use .to_sql to write the data frame to the database. Replace db_table with the name of the table that you want. The below code will create the table if it does not exist and replace the table if it exists.
df.to_sql(db_table, engine, if_exists='replace', index=False)
Exporting data to Microsoft SQL server database
Ensure that all the required libraries are installed.
pip install pandas sqlalchemy pyodbc
Once installed, we need to create a connection engine using SQLAlchemy to write the table to the database. Replace username, password, db_host, db_port, db_name with the values from your database.
from sqlalchemy import create_engine
engine=create_engine("mssql+pyodbc://username:password@db_host:db_port/db_name?driver=ODBC+Driver+17+for+SQL+Server")
Use .to_sql to write the data frame to the database. Replace db_table with the name of the table that you want. The below code will create the table if it does not exist and replace the table if it exists.
df.to_sql(db_table, engine, if_exists='replace', index=False)
Convert PDF to databases using Nanonets
This section will look at how Nanonets can help us perform tables to the database in a more customizable and easier way.
One of the highlights of Nanonets is the simplicity it offers. Users can take advantage of these services without any programming background and easily perform PDF data extraction using cutting-edge technology. The following is a brief outline of how effortlessly PDFs can be converted into a database.
Step 1: Sign up / Login on https://app.nanonets.com.
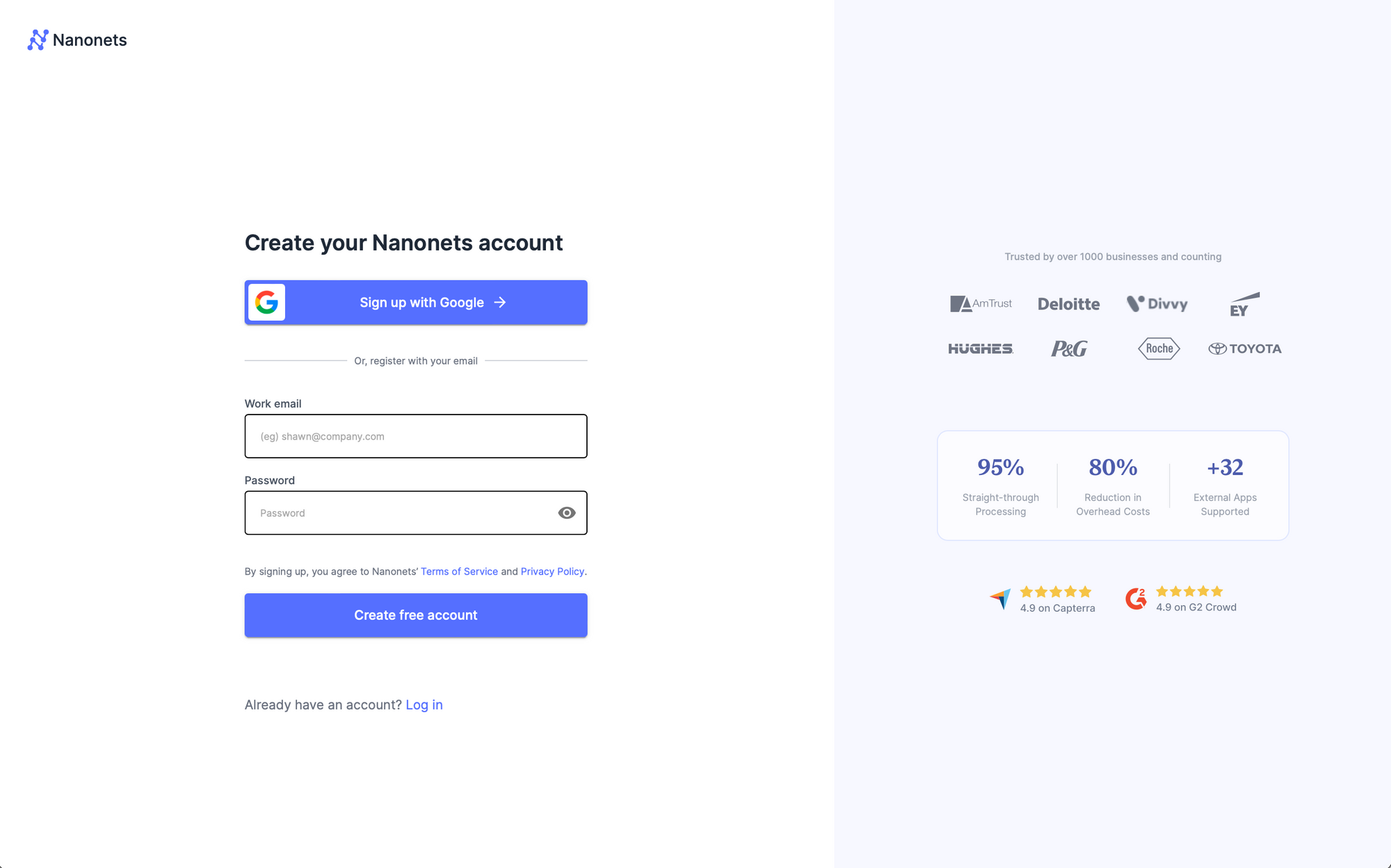
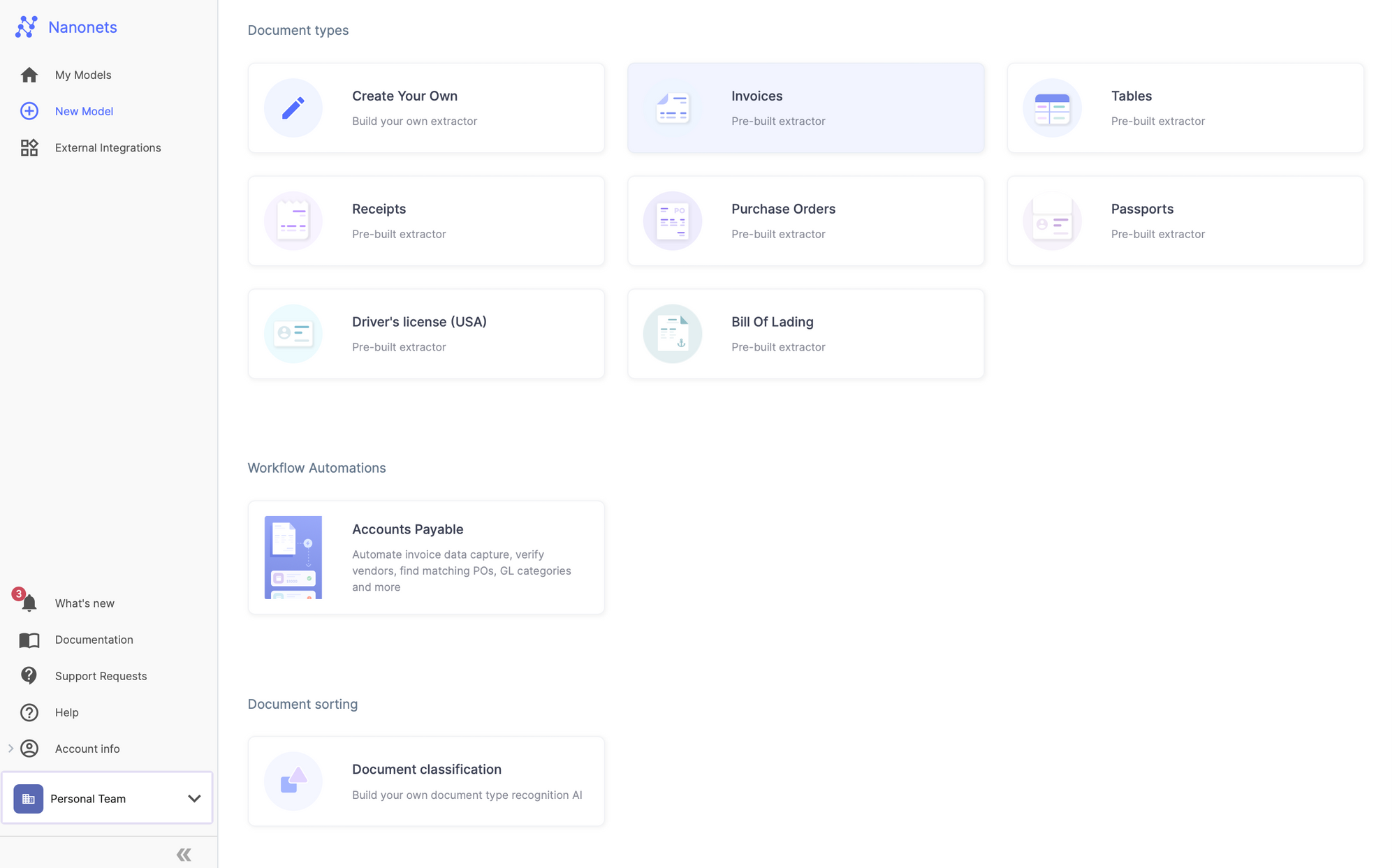
Step 2: After registration, go to the “Choose to get started” area, where you can use the pre-built extractors or create one on our own using your dataset. Here, we will be using Invoice pre-built invoice extractor.
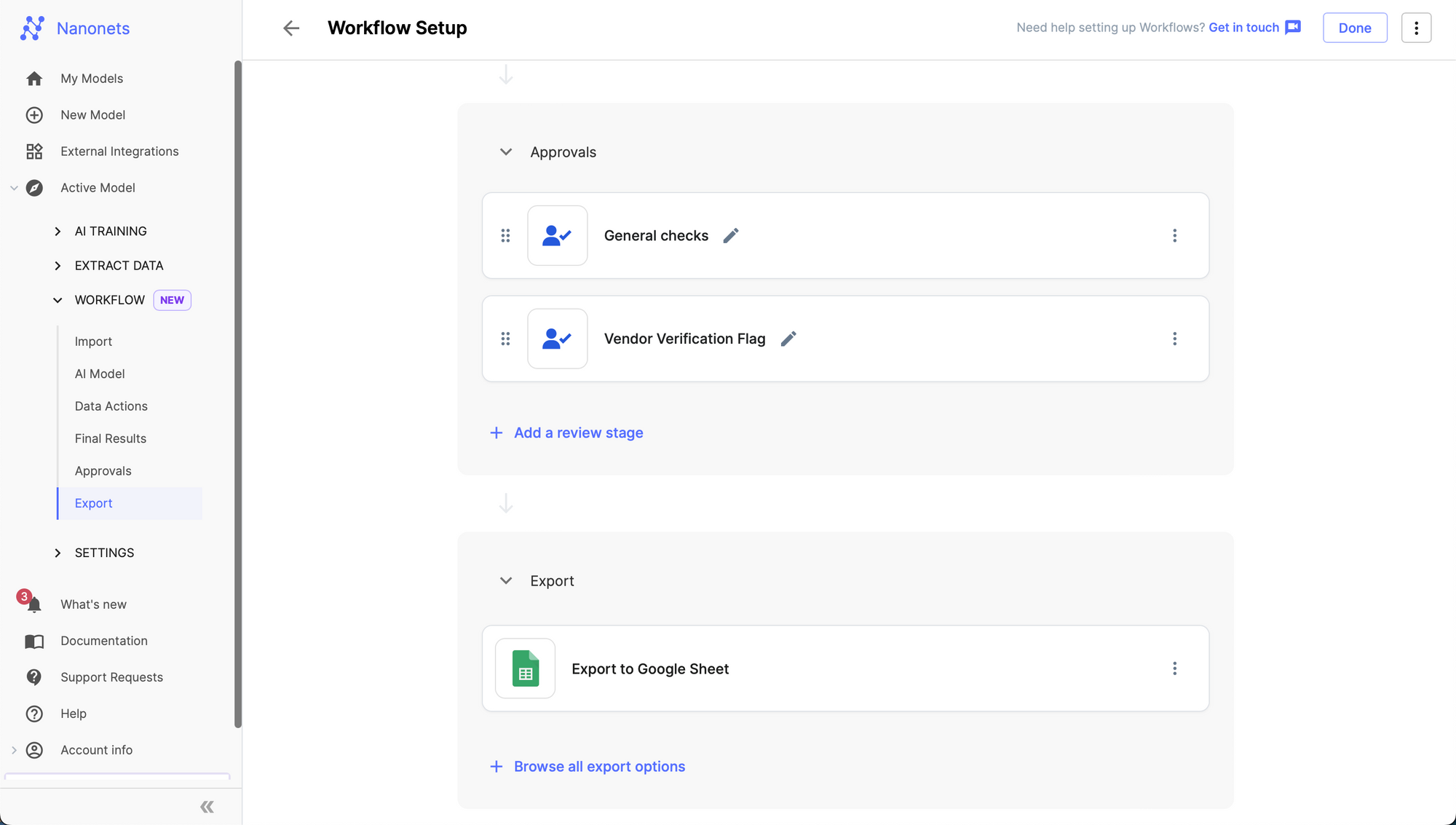
Step 3: Go to the Workflow section in the left navigation page, and navigate to the Export subsection.
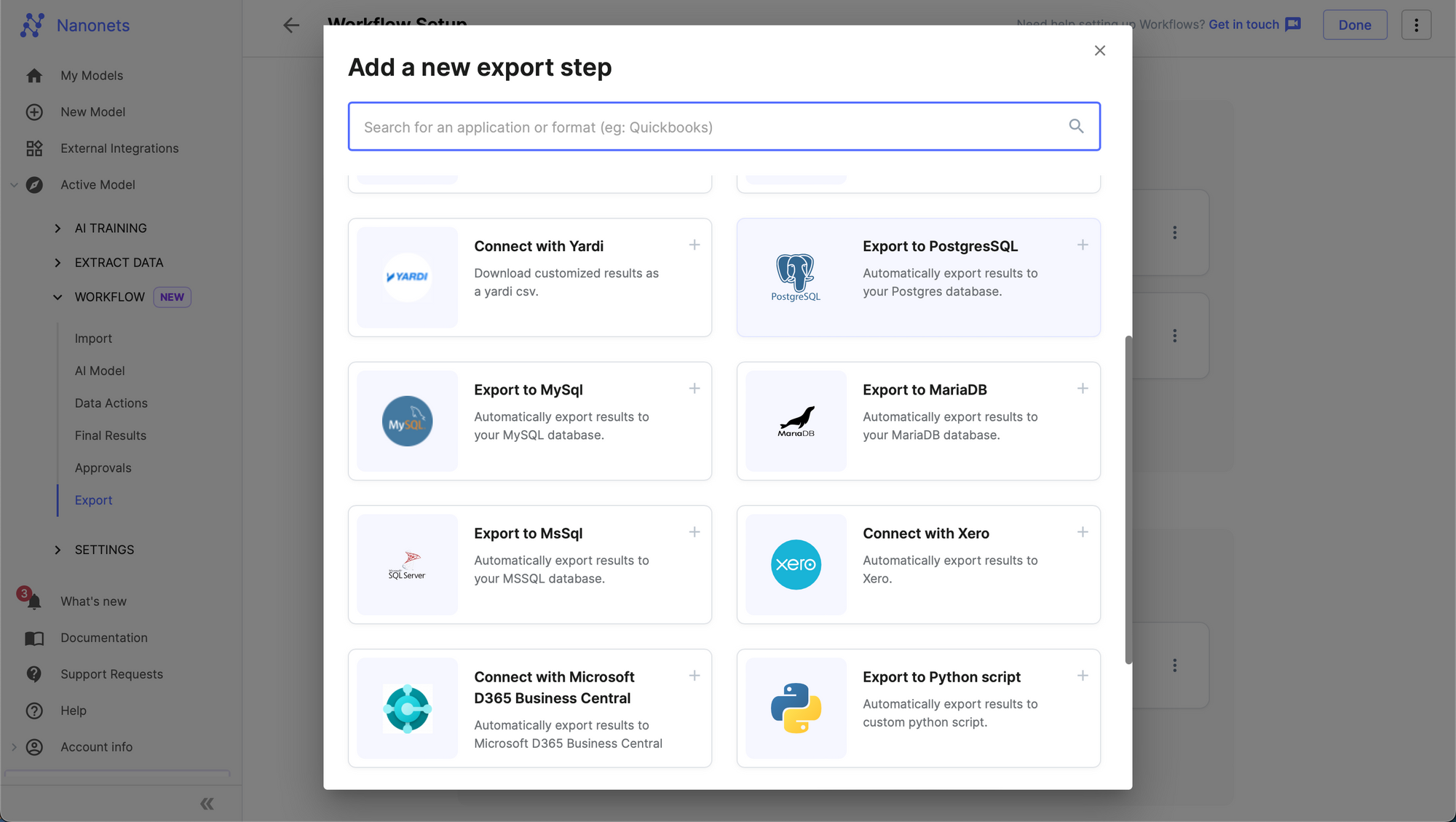
Step 4: Add a new export from the "Browse all export options" by selecting your choice of RDBMS export - MSSQL / MySQL / PostgreSQL / MariaDB.
Step 5: Setup your credentials and match the fields extracted by Nanonets to columns of the table where you specify where you want the data to be populated.
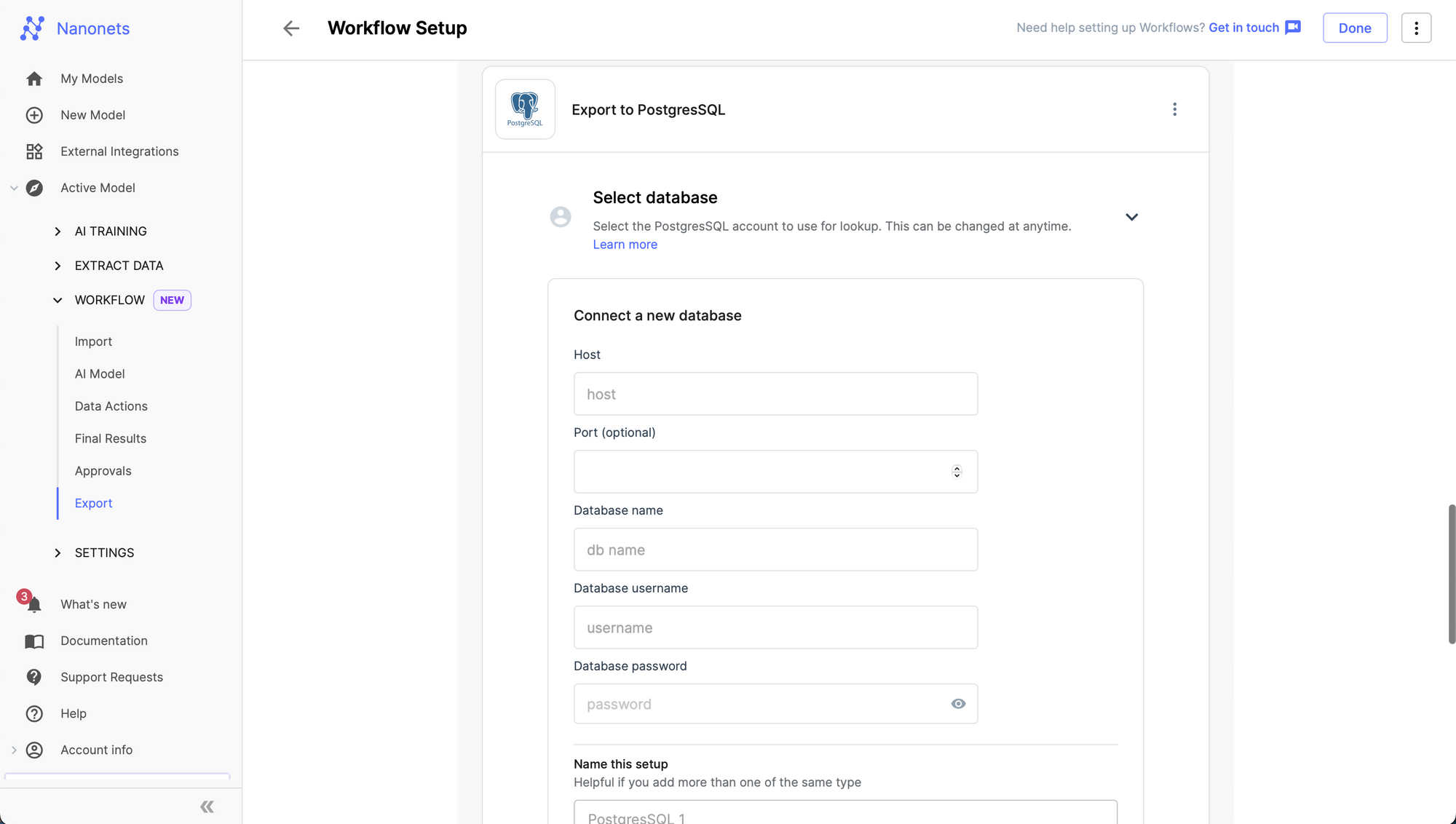
Step 6: Establish data connection and click add integration.
With this, the data will be extracted and automatically uploaded onto a database whenever files are uploaded.
Conclusion
Converting PDF to Databases is not an easy task. It is a two-step task that requires data extraction and export. Both these tasks can be accomplished using Python. However, it requires a significant coding effort.
With Nanonets, you can seamlessly extract data from any PDF file, and export the extracted information within minutes to the most popular databases such as MySQL, MS-SQL, and PostgreSQL.