Did that dreaded "Please find attached PDF" email just land in your inbox? That's another afternoon lost to copy-pasting tables into Excel? I get it.
As someone who helps companies process thousands of PDFs monthly, I've seen how much time gets wasted on manual data entry. The average office worker spends nearly 2 hours every week just copying data between applications — that's over 90 hours a year!
Here's the thing about PDFs: they're designed for viewing, not editing. That's why extracting tables from them is such a headache for businesses worldwide. Whether you're dealing with invoices, financial statements, analytical reports, or customer data, accurately getting this information into a spreadsheet can be a nightmare. Tables break apart, numbers go missing, and formatting disappears, all while those deadlines keep getting closer.
An efficient OCR to spreadsheet workflow can help businesses overcome these challenges by seamlessly extracting data from PDFs and placing it into a well-organized spreadsheet, saving time and reducing errors.
I'm sharing the eight methods I tested to copy tables from PDFs to Excel. Whether you need a quick fix for a one-time task or a robust solution for thousands of documents, you'll find one that fits your needs. No more wasted afternoons manually retyping or reformatting PDF data — just more meaningful work.

A quick overview of all PDF to Excel methods
Here's the table with the links removed:
| Method | Use Cases | Key Benefit |
|---|---|---|
| Copy PDF table to Excel manually | Occasional processing of simple, small tables from digital PDFs (e.g., reports, presentations, or data sheets) | No additional tools required |
| Google Docs/MS Word | Text-heavy digital PDFs with simple formatting (e.g., contracts, research papers, manuals) | Simple workflow |
| Adobe Acrobat Pro | Occasional processing of digital PDFs with tables, forms, or financial data (e.g., invoices, bank statements, tax forms) | Maintains original formatting |
| Excel's Get Data feature | Frequent processing of digital PDFs with simple, well-defined tables (e.g., price lists, inventory reports, sales data) | Built-in Excel feature |
| Online conversion tools | Occasional, small-scale conversions of digital PDFs with basic tables (e.g., product catalogs, price sheets, simple reports) | Fast and convenient |
| Open-source (Tabula, Excalibur) | Frequent processing of digital PDFs with consistent, well-structured tables (e.g., research data, financial reports, government documents) | Great for sensitive data |
| AI-powered OCR tools (Nanonets) | High-volume processing of digital or scanned PDFs with complex layouts (e.g., invoices, receipts, forms, reports) | Automated and scalable |
Copy tables from PDF to Microsoft Excel without any additional software
Sometimes, you may not have the time or permission to install or sign up for new software. You want to quickly transfer the PDF data into an Excel table and continue your work.
Here are a few different ways to do it:
1. The standard copy-paste method
Let's start with the most basic approach – copying and pasting from a PDF. Fair warning: while it's quick and requires no extra tools, you'll likely need to clean up the formatting afterward. This works best for simple tables when you're in a hurry.
Here's a quick step-by-step guide to copy and paste a table from a PDF to Excel:
- Open your PDF document
- Select the data table you want to copy
- Right-click and choose 'Copy' or press Ctrl+C (Cmd+C on a Mac)
- Open a new Excel spreadsheet
- Right-click on the cell where you want to paste the data and select 'Paste' or press CTRL + V (Cmd + V on a Mac)
The content will now be in an Excel table. The formatting might be a bit wonky, so you may need to clean it up a bit.
I'd like to point out that manually copying tables, with or without the wizard, might not work so well with scanned images or PDFs with really intricate layouts. If you are dealing with bigger or more complex tabular data, I recommend you check out the other methods discussed in this article.
You cannot manually copy PDF data into Excel tables if the data is in scanned images or documents with complex layouts. Consider one of the other methods discussed in the article for larger or more complicated tasks.
2. Copy PDF tables from Google Docs or MS Word
Google Docs and Microsoft Word have built-in capabilities for opening and editing PDF files. This can be handy if you need to copy from a PDF to Excel quickly.
To use Google Docs to copy data from a PDF into Excel tables, follow these steps:
- Go to your Google Drive
- Upload your PDF
- Right-click the file and select 'Open with > Google Docs'
- Find the PDF content imported into a new Google Docs document
- Edit the content, if needed
- Copy and paste the tables into the spreadsheet you’re working on
To use MS Word as an intermediary to copy data from PDF into Excel, follow these steps:
- Go to 'File' > 'Open' > 'Browse'
- Select the PDF file you want to open
- The PDF will be opened in a new Word document
- Edit the content, if needed
- Copy and paste the relevant tables into your spreadsheet
- Format the data in Excel as needed. You may need to adjust column widths, merge cells, or realign data.
In Excel, click on the 'Paste' menu to see more paste options. You can choose to match the destination formatting or keep the source formatting. Additionally, if you want to maintain a link to the original Word table, select 'Paste Link' in the Paste Special menu.
Google Docs and Microsoft Word's built-in OCR works well for some because it is free. But you may want to temper your expectations. During my testing, I ended up struggling with jumbled paragraphs, skewed tables, and misaligned data. If you go this route, budget some extra time for cleanup — you'll probably need it.
These tools struggle with complex tables, scanned images, and PDFs with intricate layouts. They work better for simpler, text-heavy PDF files.
3. Use Adobe Acrobat Pro to copy PDF tables to Excel
Acrobat Reader Pro offers several built-in features for extracting tables from PDF to Excel. Firstly, convert the PDF table to Excel using its 'Export PDF to' feature.
The steps involved in converting PDF to XLSX using Adobe Acrobat Reader:
- Open the PDF file in Adobe Acrobat Reader Pro
- Click on 'Convert' from the top menu bar
- Select 'Microsoft Excel (XLSX)' as the output format
- Set your document language
- Adjust the 'Save As XLSX Settings' based on your preference — choose to have the entire document in one worksheet or have new worksheets for each table/page, and decide how numeric data should be detected
- Select the destination where you want to save the file, whether it's on your desktop, Adobe Cloud, or other cloud storage services
- Set a name for the output XLSX file and click 'Save'
- Open the file, copy the required cells, and paste them into the Excel spreadsheet you're working on
In my tests, this method handled simple, well-structured tables beautifully. But accuracy dropped to significantly with scanned documents and complex multi-page reports. The real dealbreaker? It can only process one file at a time — makes it impractical for large-scale tasks.
Adobe's 'Select text' feature offers another way to grab your data. Just highlight the table content you want, copy it over to Excel, and you're done.
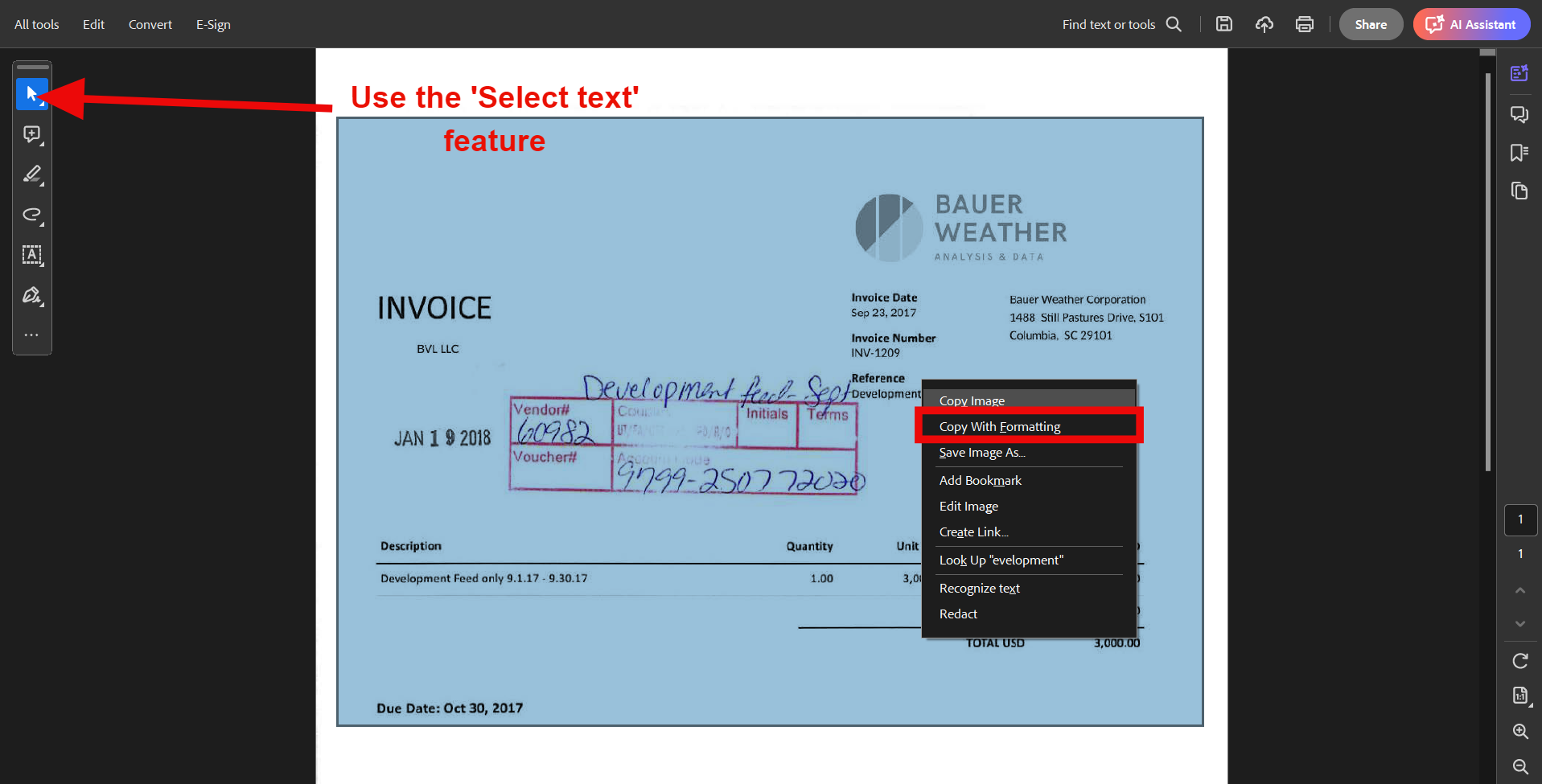
Here's how to extract PDF tables with formatting using Adobe Acrobat Reader:
- Open the PDF file in Adobe Acrobat Pro
- Select the 'Select' tool from the top toolbar
- Drag your mouse to select the table content you want to copy
- Right-click the selected content and choose 'Copy With Formatting’
- Open a new Excel spreadsheet and paste the copied content
- Adjust the formatting as needed
This method works even for scanned PDFs. Acrobat’s OCR technology can recognize and extract text from images. Since the workflow is relatively straightforward, it is an intuitive option for users who need to copy tables from PDF to Excel quickly.
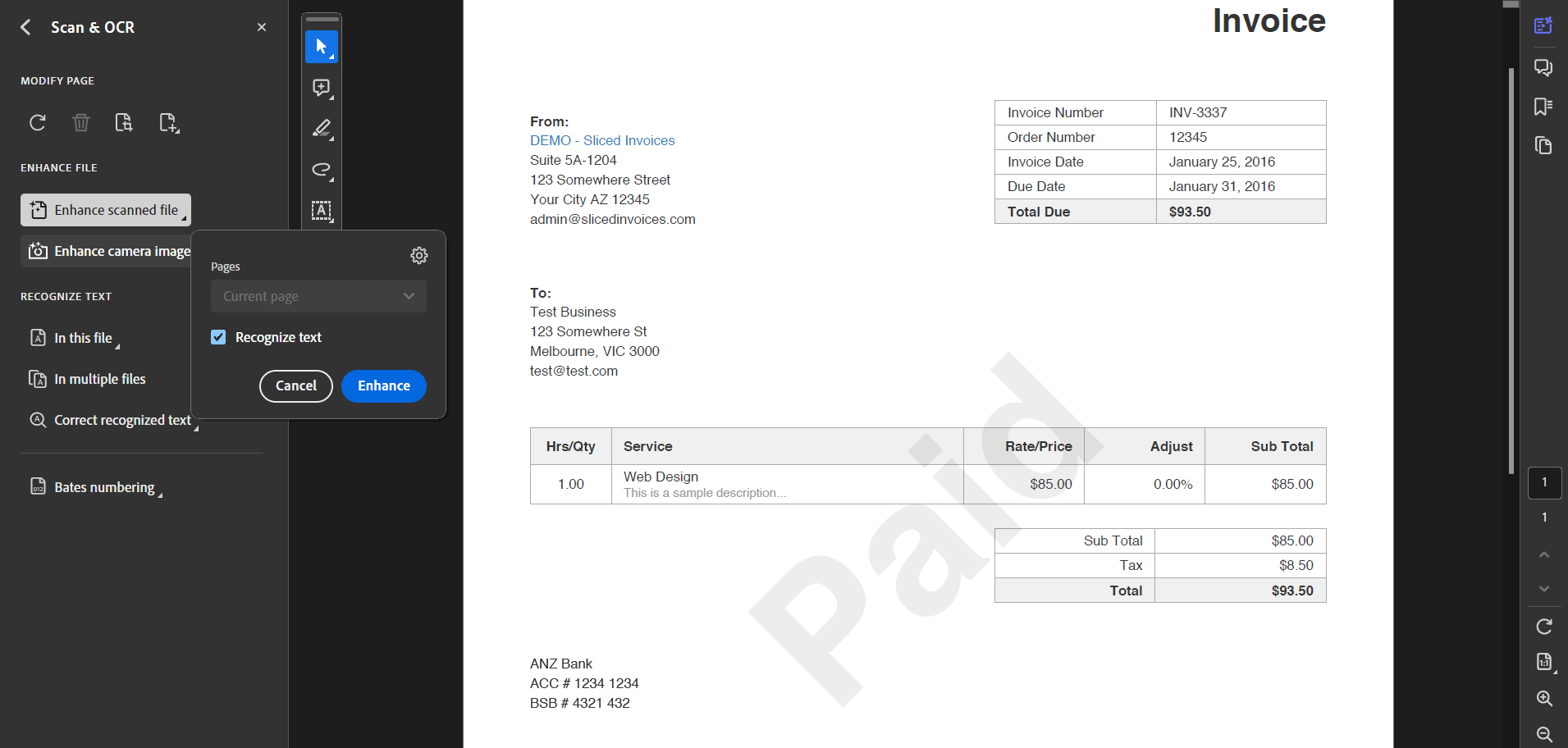
However, it can be time-consuming if you have multiple tables or pages to extract or if the tables span multiple pages. I also found that it may struggle with complex layouts or poor-quality scans. I ended up manually fixing much of the data before I could use it in my analysis.
Bonus tip: Adobe lets you copy tables as images. Perfect for preserving complicated formatting or if the table contains complex elements that don't copy correctly as text. However, it may not be helpful if you need to edit or manipulate the data in Excel.
4. Directly import table from PDF to Excel
Let's face it, sometimes, you just need to copy a table from a PDF to Excel. No bells and whistles — you just need a straightforward solution.
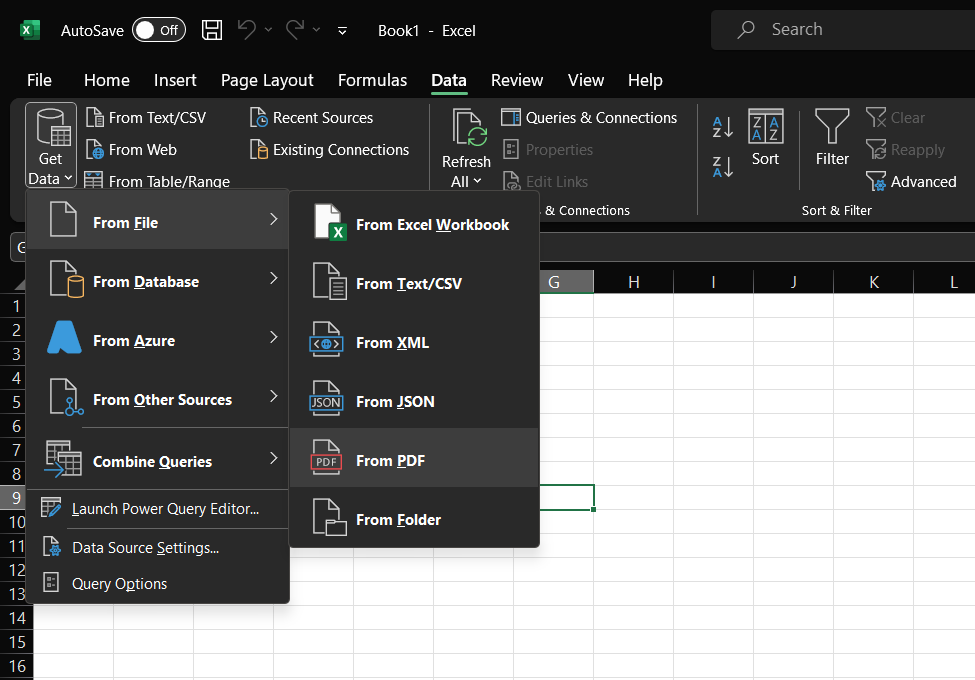
Microsoft Excel's Get Data feature is what you need. It is quick and easy. And you don't need any additional software.
Steps to use Excel's built-in PDF import option:
- Open an Excel spreadsheet
- Click on the Data tab in the upper menu
- Click on the Get Data menu, followed by 'From File' and then 'From PDF'
- Select the PDF file from which you want to import data into Excel
- Review the different PDF tables that Excel has identified
- Select the table(s) you want to import and click 'Load'
- Copy the required cells and paste them into the Excel spreadsheet you're working on
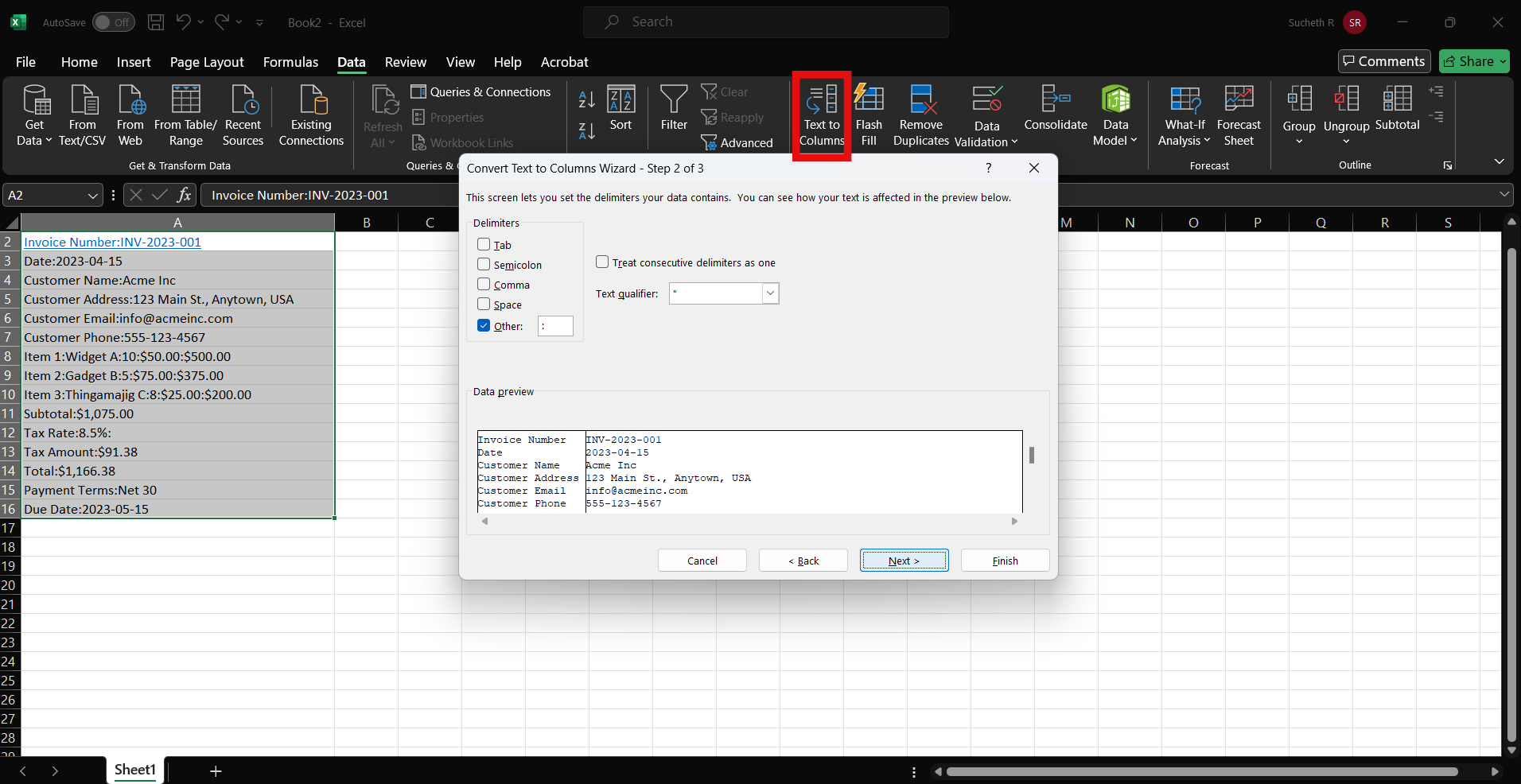
You have the option to select individual tables or all the tables present on a single page. Moreover, you can also transform the sheet using a Power Query editor. This editor allows you to adjust the data, like removing unnecessary columns or rows, splitting or merging columns, changing data types, filtering or sorting the data, and adding calculated columns.
5. Upload your PDF to an online conversion tool
There are many simple web-based conversion tools out there that can simplify the PDF table to Excel workflow. Whether you want the output in CSV, XLS, or XLSX format, these tools can manage it all.
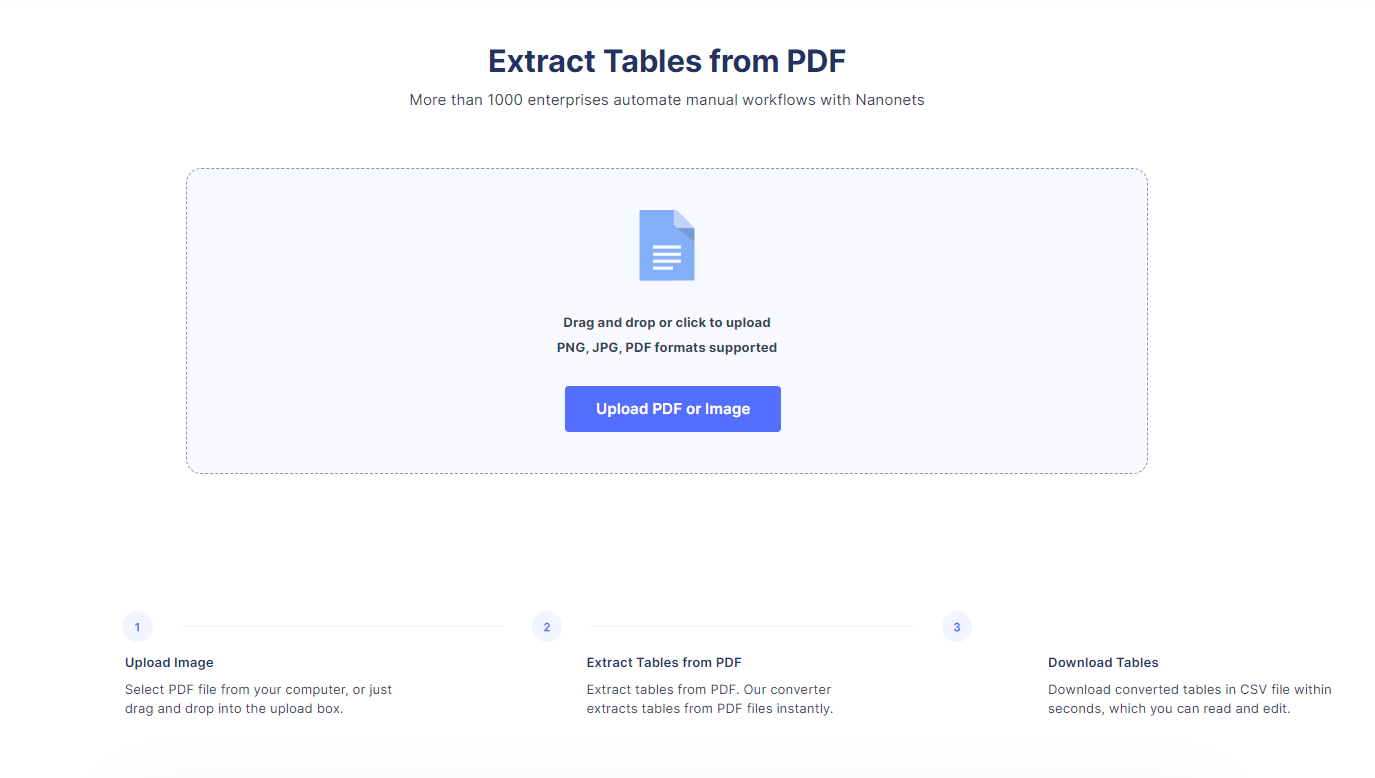
All you have to do is upload the PDF. Let the tool process and convert the file. You can then download it in the spreadsheet format of your choice. The reliability, functionality, and accuracy of these tools can vary greatly, but they generally work well for simple tasks.
Some of the most popular PDFs to Excel converters include:
- PDF to Excel
- PDF to CSV
- ilovepdf
- Acrobat's PDF converter tools
- SodaPDF
- Smallpdf
- Pdf2go
- Pdftoexcelonline
- Freepdfconvert
- Freepdftoexcel
Here's how to convert PDF tables to Excel using online converters:
- Head over to the website of the online tool
- Click on 'Upload file' or 'Choose file'
- Select the PDF file you want to convert
- Choose the output format (usually CSV, XLS, or XLSX)
- Click 'Convert'
- Download the converted file
- Open the file, copy the table and paste it into your Excel spreadsheet
While these tools offer free plans, I'd be careful about using them for sensitive data. Most require upgrading to premium for advanced features, and you may want to think twice before uploading financial documents to any online service. Read those privacy policies carefully — your data security might depend on it.
Despite being easy to use, these tools have their limitations. If you are dealing with complex tables, scanned or image-based PDFs, or multi-page tables, these online converters might not yield the best results. More importantly, these tools won't be adequate if you need to copy a large number of tables regularly or if you require batch-processing capabilities.
Extract PDF table to Excel using dedicated open-source software
Open-source software can provide powerful solutions for extracting tables from PDFs to Excel. These tools are free to use and can often handle more complex tasks than the abovementioned methods.
Plus, since everything runs locally on your machine, you never have to worry about your sensitive data leaving your control.
6. Snip PDF tables and extract data using Tabula
If you are an open-source enthusiast, then Tabula is an excellent choice. This Java-based tool allows you to extract tables from PDF files and convert them into CSV or Microsoft Excel format.
Since it is a desktop application, you must download and install it on your computer. Then follow these steps to extract your PDF table into Excel:
- Import your PDF file
- Snip the rows and columns of the table you want to extract
- Click on the 'Preview & Export Extracted Data' button
- Verify the data in the preview; if it looks good, click 'Export'
- Choose your preferred format (CSV or Excel) and save the file
- Open the saved file in Excel, copy the required cells, and paste them into your Excel spreadsheet
Tabula works best for PDFs with simple and well-structured tables. It doesn't work on PDFs with scanned images or complex layouts, nor does it support batch processing. It may not be the best choice for copying large volumes of data or dealing with intricate table structures.
7. Extract tables with Excalibur
Excalibur might suit you if you are a tech-savvy individual who doesn't mind getting your hands dirty. Excalibur is a web interface for extracting tabular data from PDFs, built on top of Camelot, a Python library known for its high accuracy and speed.
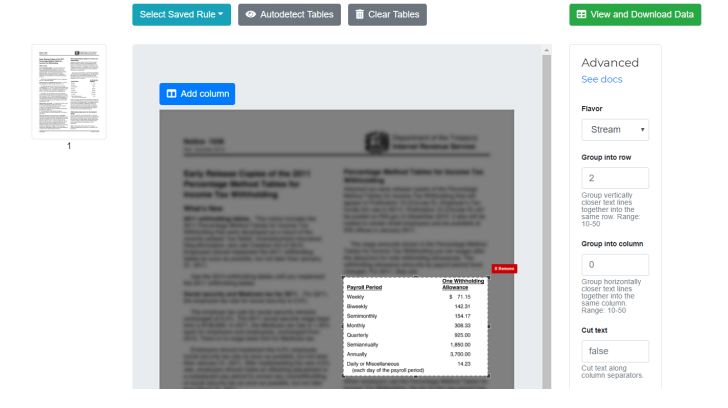
Follow these steps to use Excalibur to extract your PDF table into Excel:
- Set up Excalibur on your machine before using it
- Open any PDF using Excalibur
- Enter the page numbers where your tables are located
- Snip the relevant rows and columns or use its auto-detect feature
- Extract the data from the tables
- Download the extracted data as a CSV or Excel file
- Open the downloaded file in Excel, copy the required cells, and paste the table into your Excel worksheet
Excalibur gave me a lot more control over the extraction process — it can autodetect tables, export in multiple formats, and even fine-tune the extraction settings.
However, it requires technical knowledge and installation, which might not be suitable for everyone. It's also worth noting that, like Tabula, Excalibur might struggle with PDFs containing scanned images or complex tables and doesn't support batch processing.
☑️ Scan your documents at a high resolution (at least 300 DPI) to ensure clarity and detail.
☑️ If possible, scan in grayscale rather than black and white for better contrast and accuracy.
☑️ Make sure your scans are straight and aligned properly. Skewed or crooked scans can throw off the OCR process.
☑️ If the text in your PDF is low-contrast or hard to distinguish from the background, try using a PDF editing tool to adjust the brightness and contrast.
☑️ For low-quality digital PDFs, get the original file (Word document or Excel spreadsheet) and remake the PDF with better resolution and less compression.
☑️ Ensure that the OCR software is set to the appropriate language for the scanned text, as language-specific recognition can yield better results.
☑️ When creating digital documents, use standard, machine-readable fonts like Arial, Times New Roman, or Calibri to improve OCR accuracy.
8. Use AI-powered OCR tools to automate PDF data extraction
The manual and semi-automated methods fall short when dealing with large-scale data extraction. If you have to extract tables from hundreds or thousands of PDFs, manual methods simply won't cut it.

You'll need an automated solution that offers OCR and AI capabilities. It can accurately identify and extract tables from PDFs, regardless of the language, complexity, or layout – even scanned or image PDFs. Nanonets is a leader in this space, offering a powerful AI-based OCR tool that can handle all sorts of PDF processing with ease.
Full disclosure: I work for Nanonets. But there are several other options out there, like ABBYY FineReader, Tungsten, Docparser, and more. The right choice depends on your volume, complexity, and budget.
Convert PDF table to Excel from PDFs with Nanonets
What makes Nanonets a great fit? For starters, it offers a free PDF-to-Excel converter tool that allows you to convert your documents in a few simple steps:

- Upload your PDF file or drag and drop it into the upload box
- Click 'Convert to Excel' and let the tool work its magic
- Download your fully formatted Excel file within seconds
For more advanced features, use Nanonets' Table OCR solution. The model has been pre-trained on millions of documents and tested to ensure high accuracy and reliability out of the box. It enables you to utilize advanced AI-powered OCR on PDFs and automate even the most complex PDF-to-Excel workflows, from invoice processing to financial data extraction and beyond.
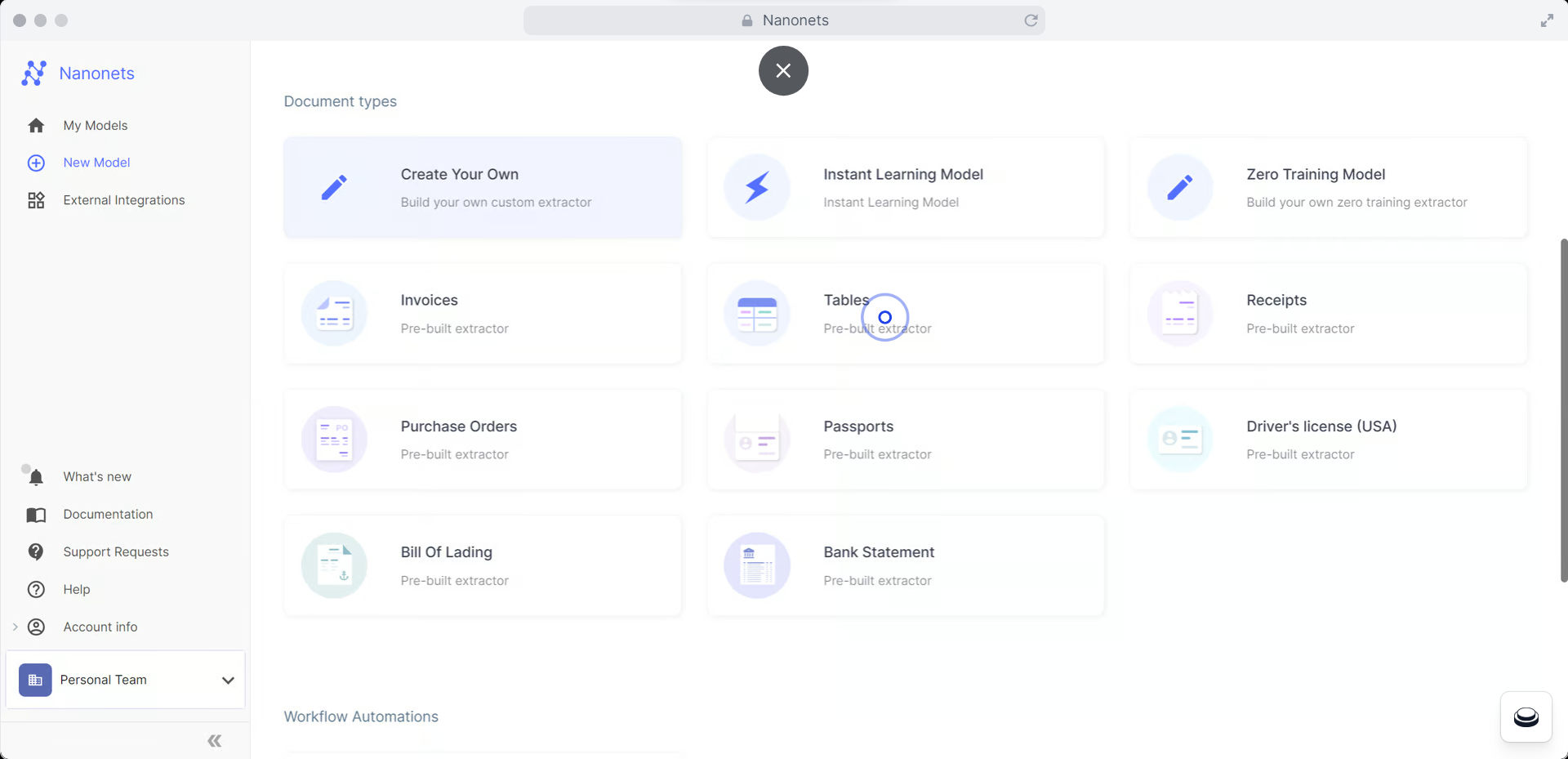
Here are the steps involved:
- Create a free account at app.nanonets.com.
- Choose the 'Table OCR' model from the main dashboard.
- Upload your PDFs or images containing tables via manual upload, cloud storage import, email, or API.
- Nanonets will automatically extract the table data.
- Review the extracted data and make any necessary corrections or adjustments.
- Export the data to your preferred format or integrate it with other tools.
- To automate the entire process, use Nanonets' Workflows feature to set up auto-import, data validations, approval flows, and auto-exports.
David Alldian, Business Analyst at Brown Strauss
With Nanonets, you can:
- Automate the ingestion of digital and scanned PDFs directly from email inboxes, cloud storage like Google Drive and Dropbox, and other business tools via APIs or Zapier integration.
- Train the models to classify the incoming documents and capture the specific table fields you need. Nanonets can handle standard fields, such as names, dates, and totals, as well as line item details, including product codes, quantities, and descriptions.
- Connect Nanonets with the tools you already use, like your ERP, accounting software, online forms, or database. Automatically sync extracted data to keep all your systems up to date.
- Fully automate your data extraction pipeline. Set up import sources, add data validations and formatting rules, configure review flows and approval hierarchies, and automate exports to your other business systems.
You can streamline data extraction for a variety of document types and industries, including:
- Financial statements and reports
- Bank statements, receipts, and transaction records
- Invoices and purchase orders
- Healthcare records and lab results
- Insurance claim submissions
- Shipping manifests and bills of lading
- Legal contracts and agreements
No matter what type of document you're working with, Nanonets can automate the extraction process and eliminate the manual entry of any tabular data. You don't need to be a tech whiz to use it; the interface is intuitive and requires no coding or special training. The platform supports API integration for custom workflows.
Let's look at a simple example. If you work in the accounts department and need to process invoices for the organization's tech tools, you may encounter invoices with varied layouts, structures, and formats. Manually checking each, copying data from tables, and inputting it into an Excel table for analysis can be a nightmare.
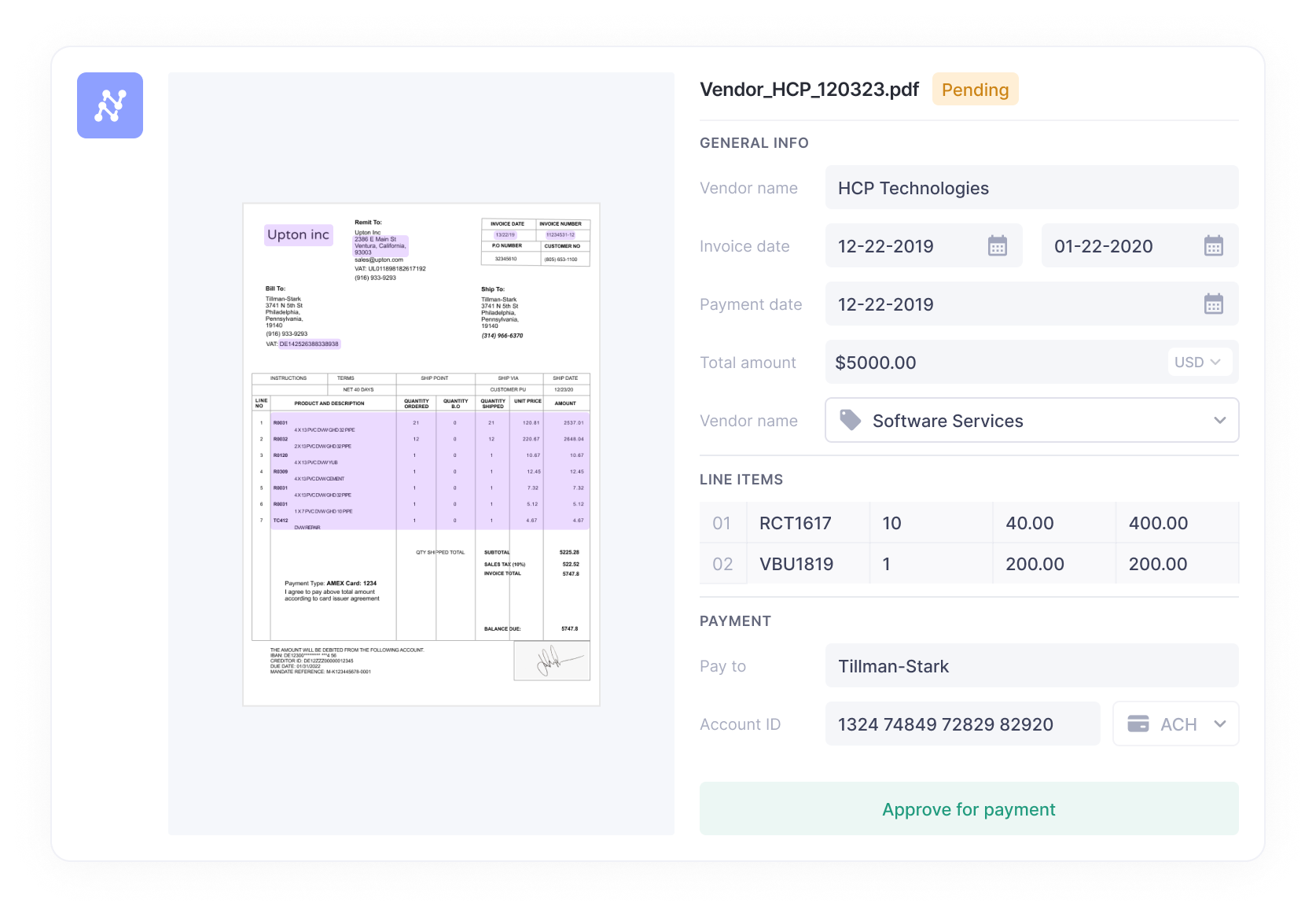
With the Nanonets, you just have to upload invoices. It does the rest: identifies the layout and extract Key-Value Pairs, invoice number, date, vendor name, amount, etc. The information is compiled into a spreadsheet and exported to accounting software like QuickBooks. No more tedious data entry or inaccurate records.
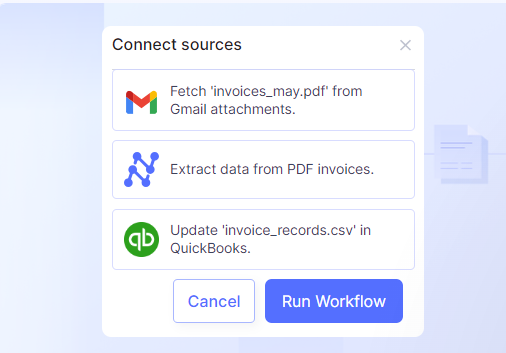
The tool learns from your edits. The AI document processing gets smarter with each interaction, making future extractions more accurate. It can handle unstructured data or complex tables in PDFs.
Nanonets takes data security and privacy seriously. It uses advanced encryption to protect data during upload, processing, and storage. The platform is GDPR and CCPA-compliant, ensuring that sensitive information remains secure.
Wrapping up
Here's hoping you won't have to look up how to transfer a table from a PDF file to Excel ever again. There is more than one way to handle this task. However, automation is undoubtedly the most efficient way to handle tasks involving large volumes of data.
The ideal method depends on your specific scenario. Assess the complexity of your tables and consider the volume and the time you're prepared to invest. After all, figuring out how to copy a table from a PDF to Excel shouldn't be an arduous task.
FAQs
How to copy a table from PDF to Excel without losing formatting?
To copy a table from PDF to Excel without losing formatting, use an AI-powered tool like Nanonets. Simply upload your PDF, let the tool automatically extract the tables, and download the data in Excel format. This preserves the original table structure and formatting.
Alternatively, you can use Excel's built-in PDF import feature. Go to the Data tab and click Get Data > From File > From PDF. Select the PDF, choose the table to import, and click Load. This brings the table into Excel, typically with formatting intact.
How do I copy an entire table from a PDF?
To copy an entire table from a PDF using Excel's Get Data feature, follow these steps:
- Open your Excel and select the 'Data' tab
- Click on 'Get Data', then select 'From File'
- Choose 'From PDF' and locate the PDF file that contains the table you want to extract
- The Navigator window will open, showing you a preview of the data
- Select the table and click 'Load'
- The data will now be imported into Excel, where you can copy the entire table
How do I import multiple tables from a PDF into Excel?
To import multiple tables from a PDF into Excel, you can use Nanonets’ automated extraction tool. Follow these steps:
- Login to your Nanonets account
- Click on the 'Tables' OCR option
- Upload the PDF containing multiple tables
- Once all the tables are extracted, you can review and correct any inaccuracies
- Download all the extracted table data in a suitable format (CSV, Excel, or JSON)
- Open the output file in Excel, and each extracted table will be on a separate sheet — Copy or import these into your main Excel spreadsheet as needed