Have you ever needed to extract data from a PDF or scanned document into a spreadsheet? OCR can be a real timesaver. Simply scan your documents and convert the images into editable, searchable text. OCR makes data extraction easy, whether working with PDFs, photos, or scanned pages.
Optimize your document management process with this OCR to spreadsheet guide. We'll walk you through the workflow and provide powerful efficiency-boosting tips.
Why reorganize data into spreadsheets with OCR?
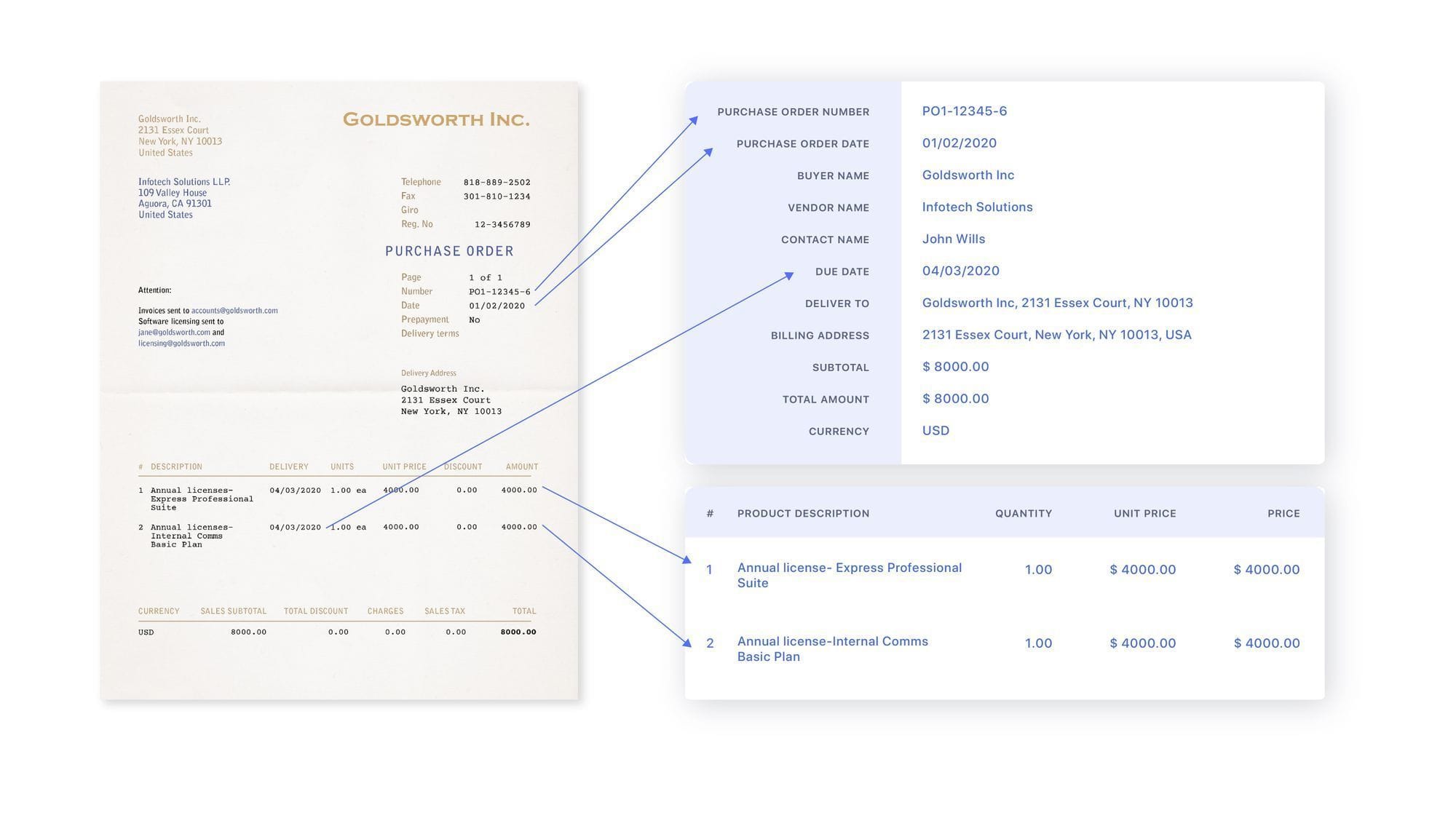
OCR is a total game-changer. It takes data locked away in your scanned documents, PDFs, and photos and turns them into structured data. We're talking ready-to-use spreadsheets. This opens up a whole new world of possibilities.
Here are some reasons why you should consider using OCR to organize your data into spreadsheets:
1. Easier data analysis
Once your data is extracted and organized neatly into rows and columns in a spreadsheet, it becomes much easier to analyze and work with. You can quickly spot trends, sort, filter, use formulas, and create pivot tables and charts. This level of data manipulation is not possible in scanned documents or PDFs.
2. Better data quality
OCR conversion to spreadsheets gives you clean, structured data. The data can be validated and standardized during the OCR process. This improves overall data quality and accuracy compared to unstructured scanned documents.
3. Improved searchability
Scanned documents and images are complex to search — OCR fixes this by converting the images into actual text. Once in a spreadsheet, the data becomes fully searchable. You can instantly find what you need.
4. Enhanced data sharing
Spreadsheets containing extracted data can be easily shared with others for collaboration. The data is now in a standardized reusable format instead of trapped in individual document images.
5. Automation capabilities
Spreadsheet data can be automated and streamlined across business systems. With the ability to output CSV files, the OCR extracted data can automatically flow into databases and other line-of-business applications.
6. Skip manual processing
Your team will no longer need to manually transcribe data from scanned documents nor endure the tedious and ineffective copy-paste workflow for PDFs. You can reduce errors and save time cleaning and validating data by eliminating monotonous data entry tasks. As a result, your staff can dedicate their efforts to more productive and fulfilling work.
7. Scalability
OCR conversion scales well as data volumes grow. Whether you need to process hundreds or even thousands of document pages, OCR automation handles it smoothly. Manual data entry does not scale as quickly for large volumes.
The OCR to spreadsheets workflow
Converting documents into spreadsheets with OCR is straightforward when you follow these key steps. By setting up an efficient workflow, you can save hours of manual data entry and quickly access information locked away in PDFs or scanned files.
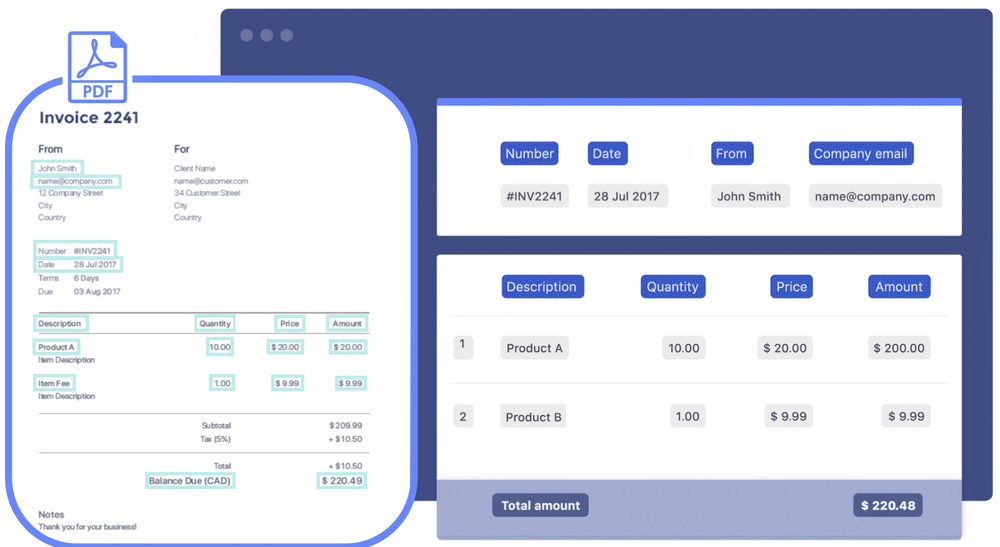
Let’s dive in.
1. Gather documents for OCR
First, collect the document images, PDFs, or scanned papers containing the data you need to extract. Nanonets allows you to easily import files from multiple sources, including email, cloud storage, Dropbox, Google Drive, OneDrive, and more.

You can also set up folders or email accounts to process any new files or incoming attachments automatically. API calls and integrations with other business software can also be set up for seamless data extraction.
2. Define data fields
Next, specify the data fields or columns you want to extract, such as invoice number, date, customer name, amount due, etc. Nanonets offers different AI models for document types like invoices, customer orders, receipts, business cards, and more.

The pre-built models already know how to intelligently extract standard fields from each document type. You can also configure your custom fields and train the AI model. You can then prepare the model with a few samples. Just draw zones on sample documents to map out where the critical data resides.
3. Run OCR with AI data extraction
Now, you're ready to run the OCR and extract data from your documents. Nanonets leverages advanced AI and ML algorithms to automatically identify and capture text from complex document layouts with high accuracy. The AI "reads" each document, extracts the defined fields, and outputs structured data ready for export.
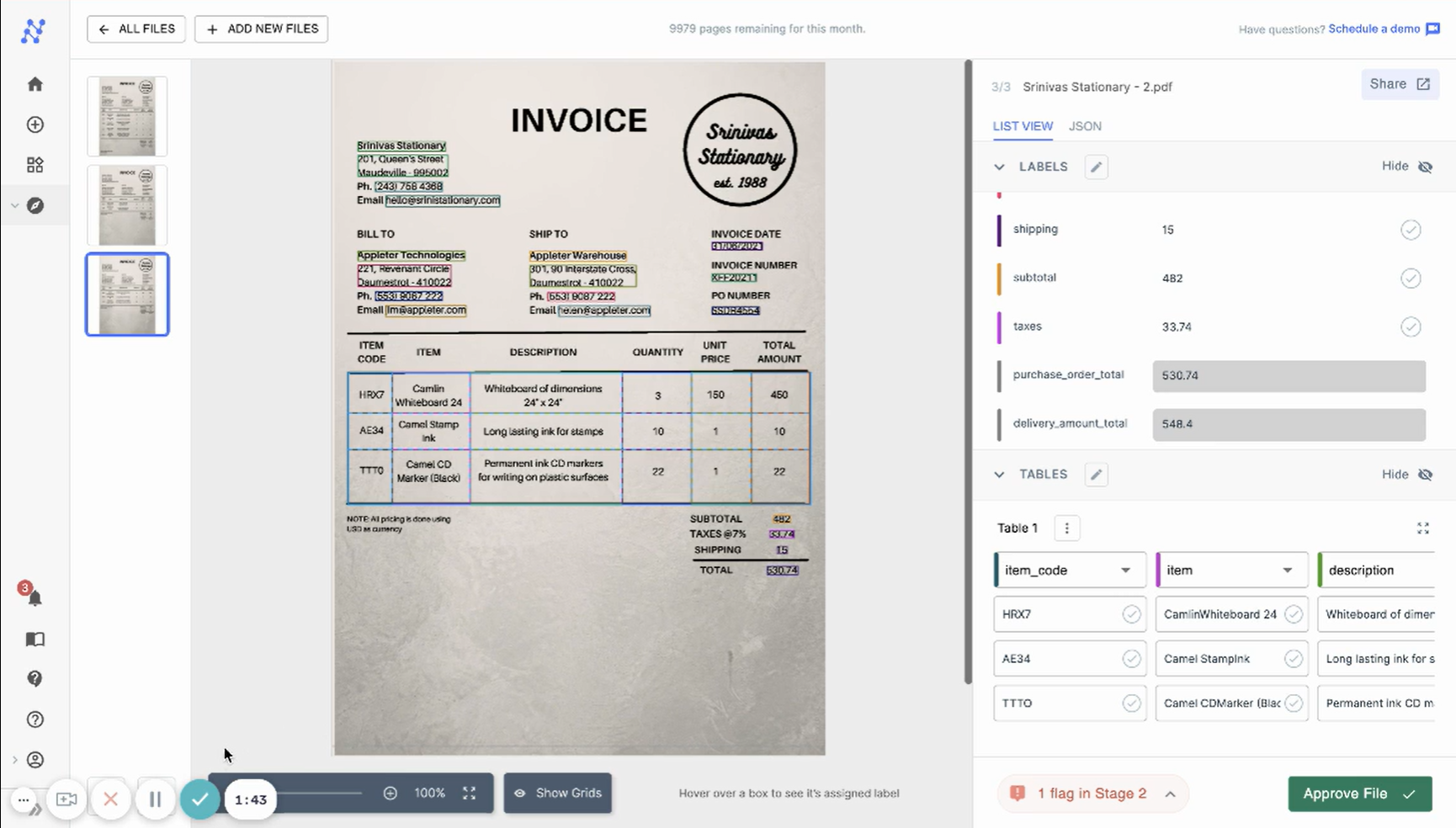
This step is entirely automated for you once the data fields and AI model are correctly configured. Behind the scenes, OCR technology converts scanned images into text. Intelligent zone detection then picks out the relevant data fields.
4. Validate and correct data
Review the extracted data for accuracy. Nanonets makes this easy as it lets you make corrections right on the document viewer. For more advanced users, you can also edit the structured JSON output.
You can also use automated validation capabilities to set up rules to validate the captured data. For example, you can check whether a date falls within a valid range or a numeric value below a threshold. Any validation issues get flagged for review.
5. Export and integrate spreadsheet data
The final output containing the structured data extracted from your scanned documents or PDFs can be downloaded and used for downstream purposes. Nanonets allows you to export it as a CSV, Excel, or JSON file, enabling you to easily import the data into your preferred spreadsheet application or other business software.
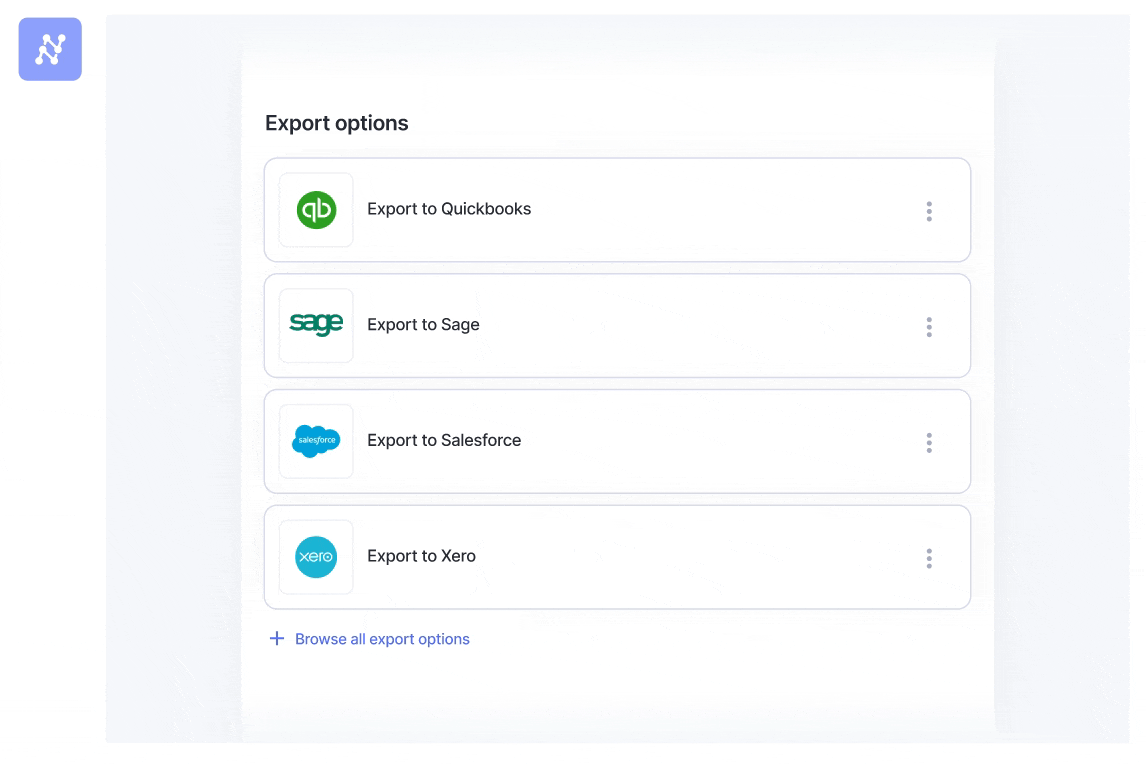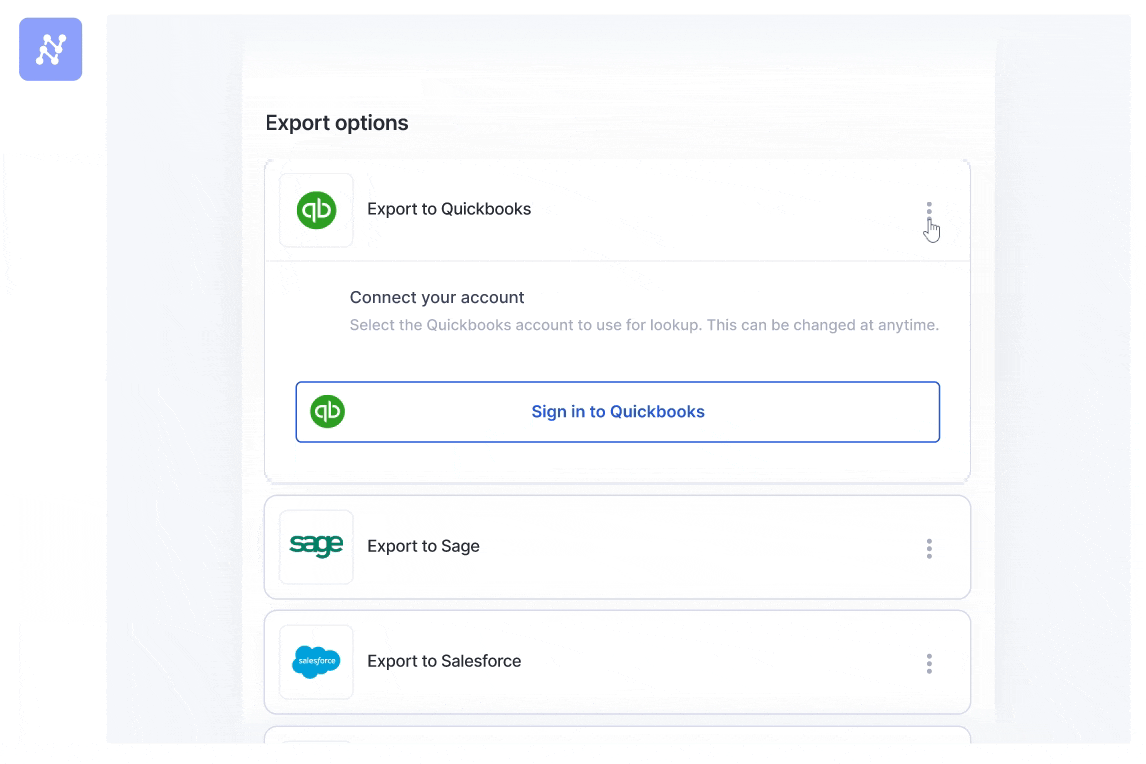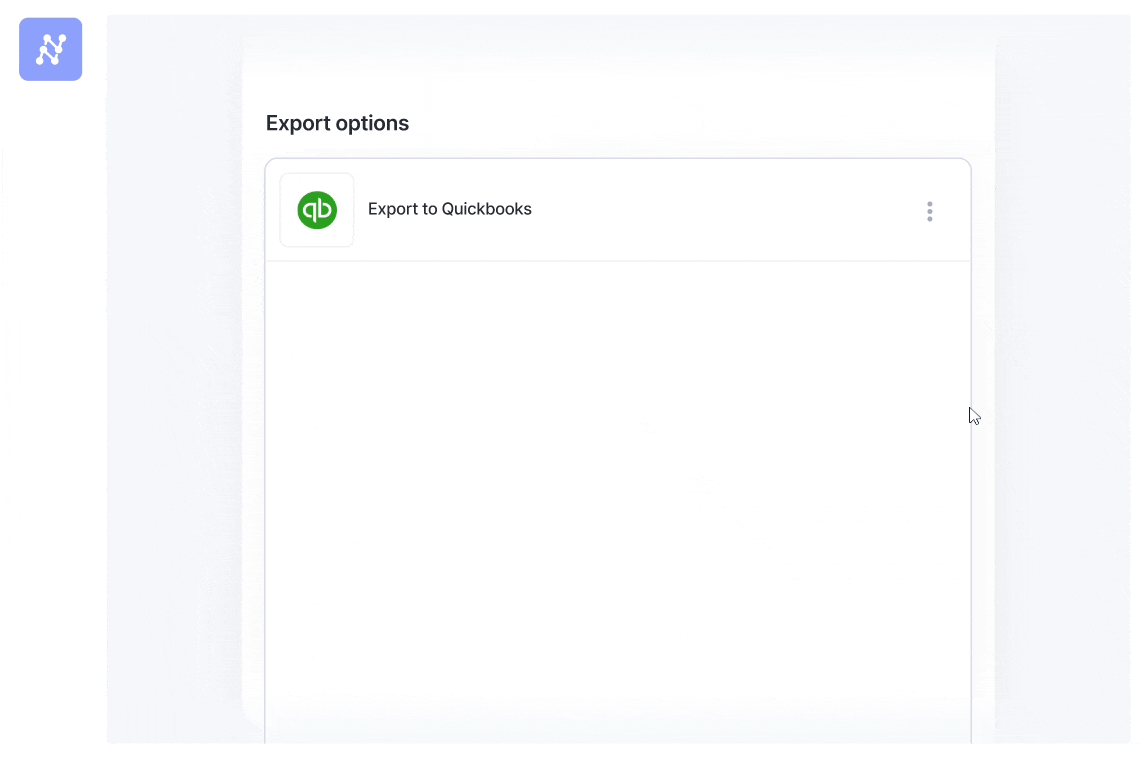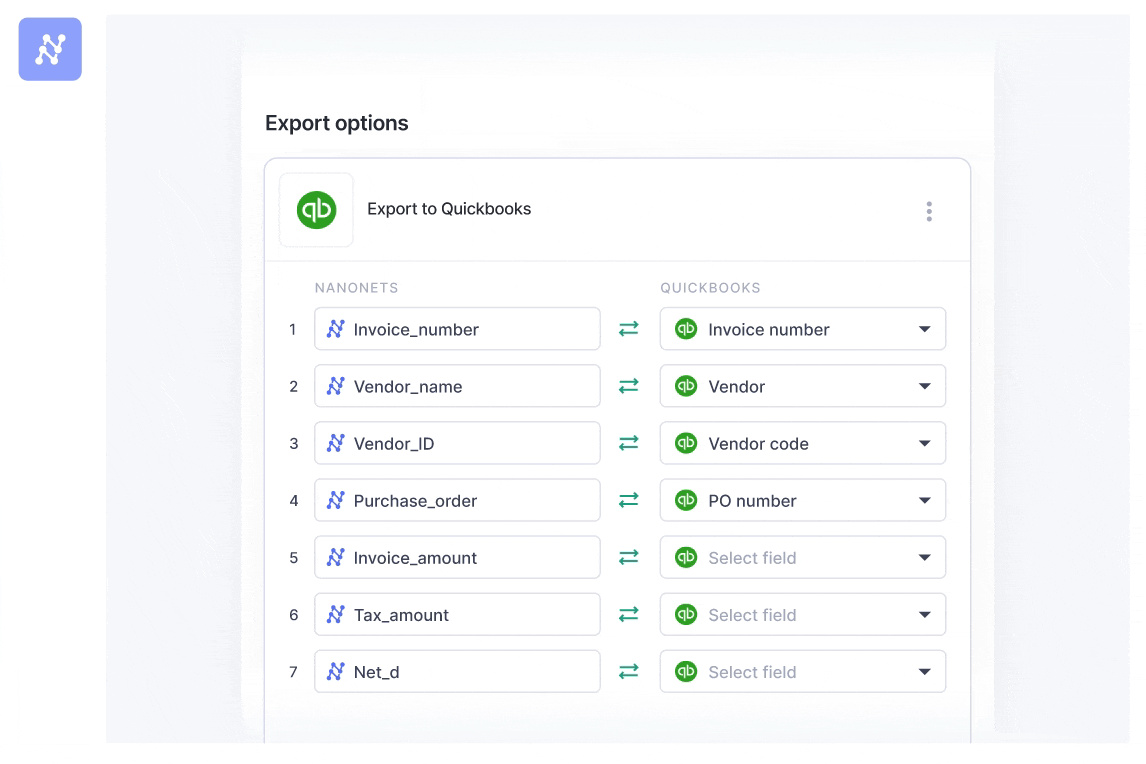
You can also directly integrate with popular applications like Google Sheets, QuickBooks, Salesforce, etc. The Zapier integration allows you to connect with over 5000+ apps for seamless data flow. This integration ensures that your data is automatically updated across all your platforms in real-time.
How to improve the OCR to spreadsheet process
OCR technology is not perfect. It can sometimes struggle with low-quality scans, complex layouts, or unusual fonts. But, even minor marginal improvements in the OCR process can lead to significant time and cost savings.
Suppose you run an insurance firm that processes thousands of documents per day. Even a 2% improvement in OCR accuracy can save hundreds of labor hours per week.
Here are some ways to improve the OCR to spreadsheet process:
1. Improve the quality of your scans
Ensure the documents you're scanning are clear and legible. Poor-quality scans can lead to errors in the OCR process. So, preprocess scans to enhance image quality before feeding them into your OCR system.

Tips for improving scan quality:
- Use a high-resolution scanner (at least 300 dpi). This captures finer detail that can help the OCR engine accurately recognize characters.
- Make sure pages are correctly aligned and not skewed. Deskewing fixes tilted scans.
- Check scan brightness and contrast. Adjust levels so the text is clearly visible and not too light or dark.
- Clean the scanner glass to avoid dust, smudges, or artifacts on scanned images.
- Use Adobe Scan or similar apps to capture high-quality scans using your smartphone.
- Use image enhancement techniques like sharpening, noise reduction, and binarization.
2. Standardize your documents
Consistency in document layout and design can significantly improve OCR accuracy. If possible, standardize the format of the documents you process. This means keeping data fields in the exact location on each document, using consistent fonts and sizes, and maintaining a clean, uncluttered layout.

Here are some tips for standardizing documents:
- Use a consistent template for all documents of the same type.
- Keep essential data fields in the same place on every document.
- Use clear, legible fonts and avoid artistic or unusual fonts.
- Avoid clutter and keep the layout clean and simple.
- Limit the use of images, logos, and graphics near important text fields.
- Use high-contrast colors for text and background to improve legibility.
3. Invest in an AI-powered OCR system
These systems use machine learning algorithms to learn from every document processed, continually improving their ability to recognize and extract relevant data.

Nanonets is a prime example of an AI-powered OCR system. It offers pre-trained models for different document types and allows you to customize the model according to your needs. The more data it processes, the better it recognizes patterns and accurately extracts data.
Moreover, AI-powered OCR systems' language recognition and context understanding capabilities allow them to handle documents in various languages, currencies, tax formats, and more. This makes them highly versatile and adaptable to diverse business needs.
4. Set up automated workflows
Automating repetitive manual steps in your OCR workflow can enhance efficiency and minimize errors. For example, you can set up auto-import rules that ensure the OCR system automatically processes every invoice sent to accounting@yourbusiness.com.
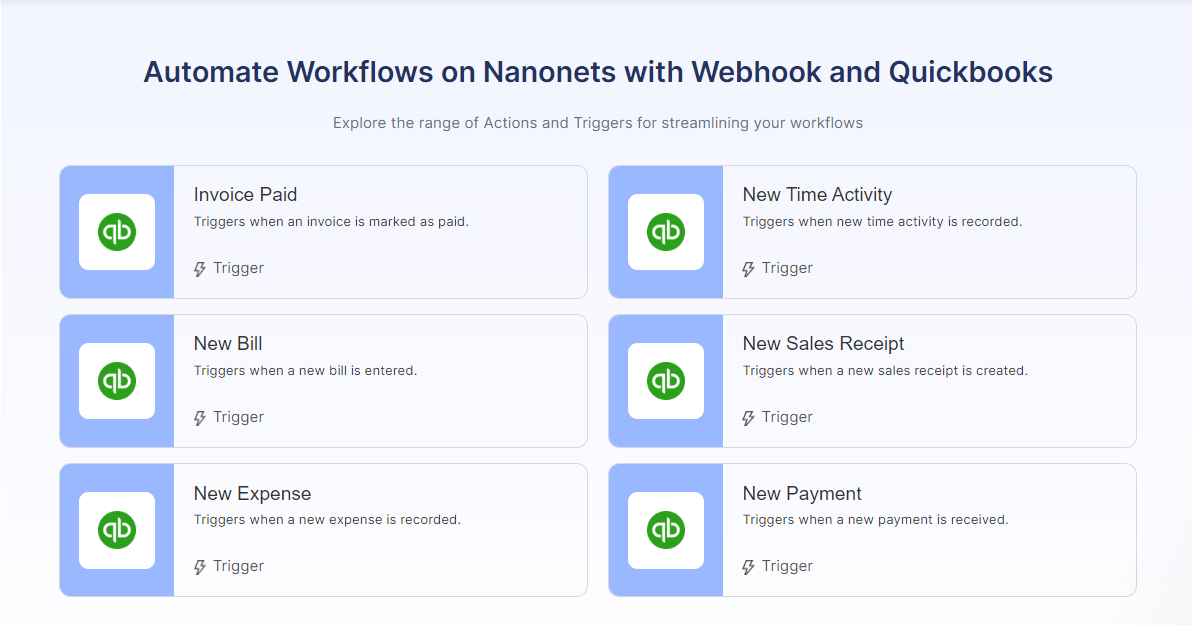
Integrations with business software like ERPs allow seamless data flow. The extracted spreadsheet data can automatically sync to downstream databases. Automated validation rules help catch any extraction errors early. Workflows can route documents needing review to appropriate staff. Automatic notifications and reminders ensure no deadline is missed.
Final thoughts
OCR technology has revolutionized how we extract and work with data from scanned documents and PDFs. By converting images into structured spreadsheet data, OCR eliminates tedious manual entry while enhancing analysis capabilities.
As this guide outlined, creating an efficient OCR workflow with the right tools, like Nanonets, can save massive amounts of time. Minor improvements in accuracy also quickly translate into significant savings.
Want to see how OCR can accelerate your business workflows? Nanonets offers a free version to test out AI-powered data extraction from your documents. Converting PDF tables or scanned invoices into editable Excel sheets has never been easier. Sign up now to get started!