
Imagine being part of a finance team that processes hundreds of invoices, contracts, or reports daily. I know how frustrating it can be to deal with PDFs generically named like document(1).pdf. Finding the right file in such a sea of ambiguity is a task that eats into precious time.
Renaming PDFs based on their content—say, “Invoice_CompanyName_Date.pdf” has been a game-changer for me. It saves hours of searching, reduces errors, and keeps things organised. But when the document volume is large, manually renaming files isn’t just tedious—it’s error-prone.
That’s where automation comes in. It not only simplifies the process but also ensures consistency and accuracy, which are critical for maintaining organised digital records.
In this blog, I’ll walk you through three effective methods I’ve used to rename PDF files effortlessly. I’ll also help you decide which method works best for your needs by weighing the pros and cons.
Let's get started!
Renaming PDF Files based on Content using Python
Python has been my go-to for renaming PDF files efficiently. It’s particularly effective for text-based PDFs with a clear structure. Imagine a folder, "Test" filled with invoices generically named, like "abc invoice" or "document(1)"—it’s a nightmare to manage.
Now, imagine instantly renaming those files based on unique invoice numbers extracted from each document. Sounds amazing, right?
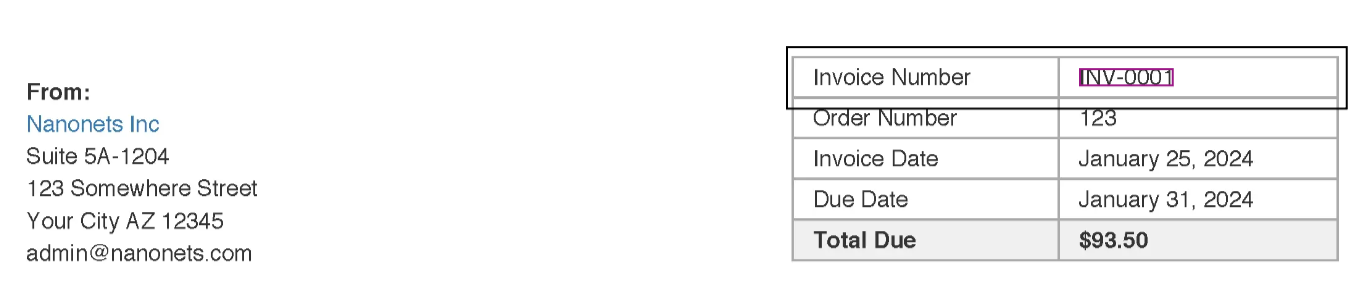
What if you could instantly rename all your invoices using the unique invoice numbers listed within each document (as shown in the below image)?
Here's how I did it with a simple python script. It effortlessly extracts invoice numbers from each file and renames them.
Step 1: Import Necessary Libraries
We start by importing the essential libraries: os for file operations, re for regular expressions, and PyPDF2 for reading PDFs.
import os
import re
from PyPDF2 import PdfReader
Step 2: Define the Folder Path
The script points to the folder where your PDFs are stored. In this example, it's the Test folder located in the Downloads directory.
folder_path = os.path.expanduser('~/Downloads/Test')
Step 3: Create a Regular Expression:
The regular expression is designed to match invoice numbers. For instance, in our sample invoice, the invoice number might be in the format "INV-1234."
invoice_regex = re.compile(r'Invoice\s*Number\s*\n?\s*INV-\d+')To accurately identify text within your documents, you will need to use the appropriate regex patterns. Each file may require a different regex to extract the correct data.
Step 4: Loop Through All PDF Files:
The script iterates through all the PDF files in the Test folder.
for filename in os.listdir(folder_path):
if filename.endswith('.pdf'):
Step 5: Extract Text from Each PDF:
For each PDF, the script extracts the text from all pages. This text is then used to search for the invoice number.
pdf_path = os.path.join(folder_path, filename)
with open(pdf_path, 'rb') as pdf_file:
pdf_reader = PdfReader(pdf_file)
text = ''
for page in pdf_reader.pages:
text += page.extract_text()
Step 6: Search for the Invoice Number:
The script uses the regular expression to find the invoice number within the extracted text.
match = invoice_regex.search(text)
if match:
invoice_number = match.group(0).split()[-1]
Step 7: Rename the PDF File:
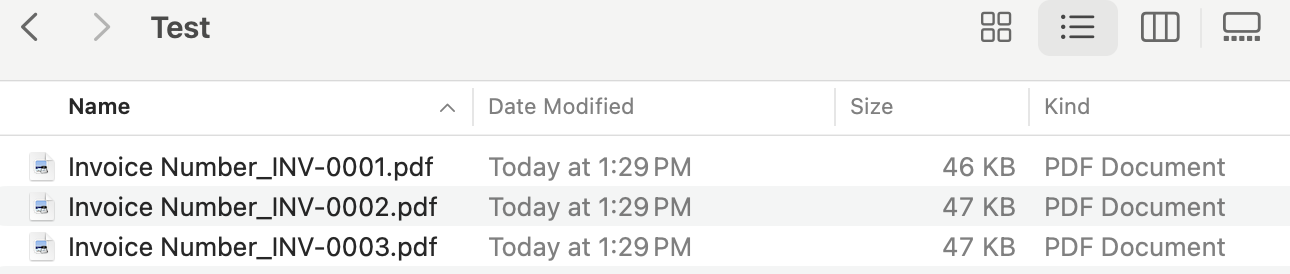
If an invoice number is found, the file is renamed accordingly. For example, the file named document(1).pdf will be renamed to Invoice Number_INV-0003.pdf.
new_filename = f"Invoice Number_{invoice_number}.pdf"
new_filepath = os.path.join(folder_path, new_filename)
os.rename(pdf_path, new_filepath)
print(f"Renamed {filename} to {new_filename}")When executed successfully, the code will display a list of all the current file names and their corresponding new names, similar to the following example.

And after running the script, the files will be renamed based on their content:
Download Full Code:
Just as we extracted invoice numbers to rename PDF files, we can also extract other details such as dates, vendor names, and more. By leveraging this information, you can create a naming system that reflects the key attributes of each document, making organization and retrieval even easier.
The initial setup requires programming knowledge and is limited to text-based PDFs with specific content patterns. Additionally, it may need ongoing adjustments to accommodate changes in document structure.
Renaming PDF Files Using Adobe Plugins
If you’re already using Adobe Acrobat, plugins can be a simple and effective way to rename files. I found it particularly useful for batch renaming PDFs without needing additional tools or coding.
With Adobe, I could search for content like invoice numbers or dates within the PDF, define naming conventions, and rename files in bulk. I loved how it integrated seamlessly with existing tools and saved time.
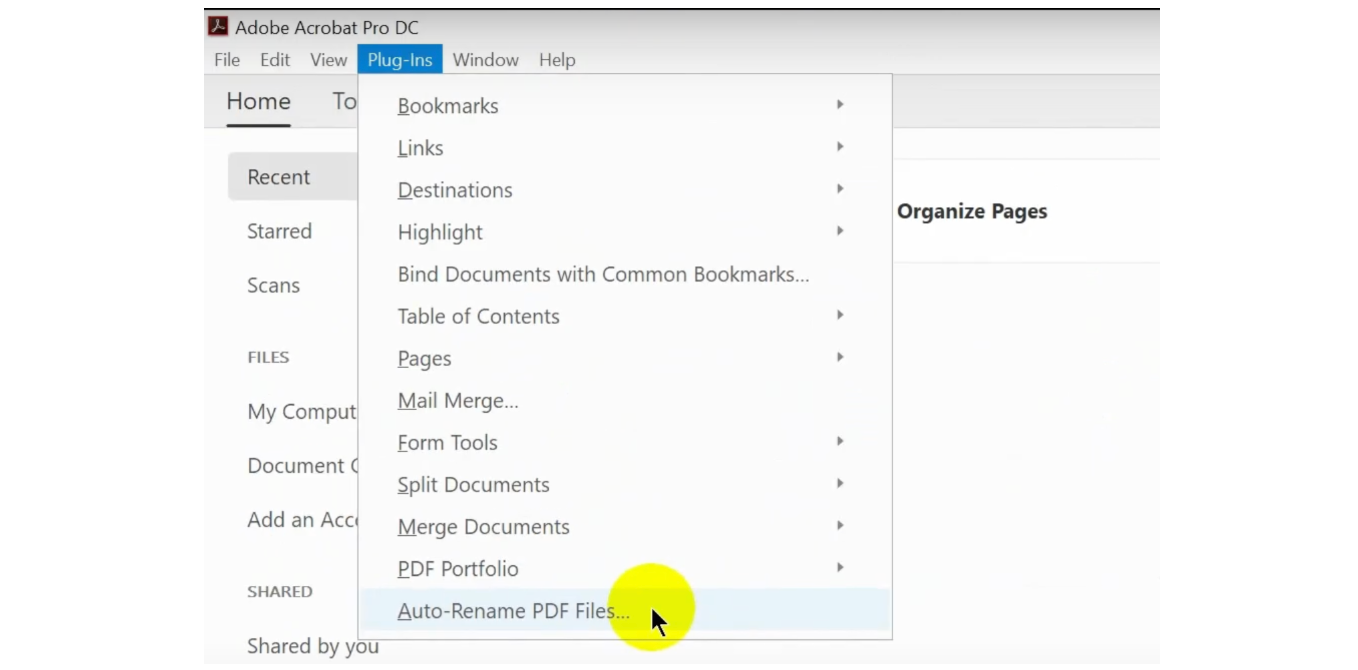
Step 1: Open the “Auto-Rename PDF Files” Menu
Begin by closing all open PDF documents to avoid file access conflicts. Launch Adobe Acrobat, and go to Plug-ins > Auto-Rename PDF Files… from the main menu.
Step 2: Add a New Naming Component
Click “Add…” to create a new naming component. This defines the structure of your new filenames. Below are the different options presents in the plugin:
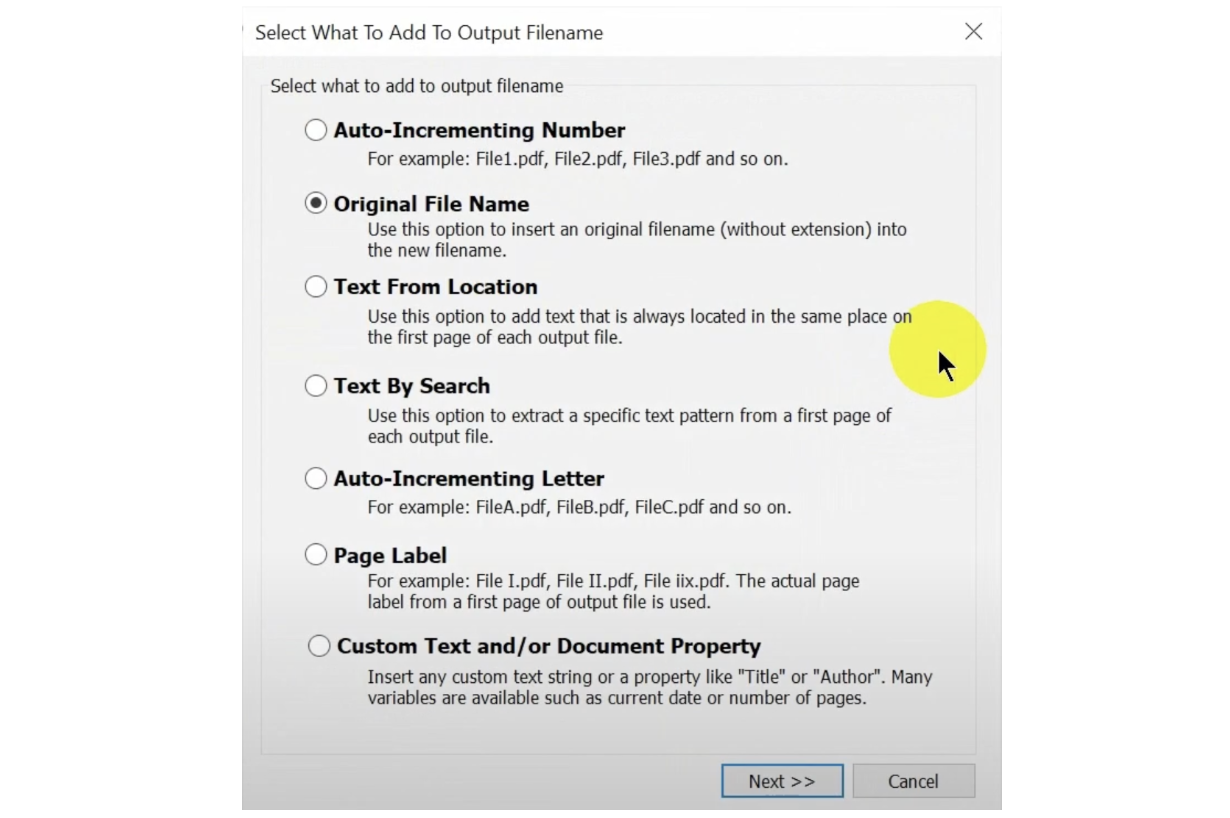
Step 3: Select the “Text by Search” Option and Enter Search Expression
Choose the “Text By Search” option, then click “Next.” This lets you specify which content within the PDF will be used for renaming. In the "Find Text" dialog, enter a search expression to locate the text that will be used as part of the filename.
Invoice\s*Number\s*\n?\s*INV-\d+Enter the regex expression to find the Invoice Number from the document just like we did in last method using python code.
Confirm your search settings, such as “Match whole words only” or “Match case,” to ensure accuracy. Click “OK” to finalize the setup.
Step 4: Add Files for Renaming
Press “Add Files…” to select the PDF files you want to rename. You can add files from multiple folders if necessary. Once all files are selected, click “OK.”
Step 5: Review and Rename Files
The software will display a preview of the new filenames. Review them, and if everything looks correct, press “Rename” to apply the changes.
The plug-in can be configured to search each PDF file for both invoice number and date, and use it in the new file names. The renaming settings can be saved and reused later on the different set of files.
Adobe plugins require Adobe Acrobat Pro and additional paid plugins, which adds to the cost. The setup can be complex, especially for varied file types, and the plugins may not handle all document types or complex patterns effectively.
Rename file based on content using GenAI IDP softwares
For large-scale, diverse document types, Intelligent Document Processing (IDP) tools like Nanonets have been better suited than Python Scripts or Adobe Plugins. With Nanonets, I could automate the renaming process entirely, no matter how varied the file formats or layouts were.
Additionally, it integrated seamlessly into existing workflows, offering scalability and consistency that surpass simpler, single-purpose solutions.
It was a simple 3-step process:
- Upload Files: Upload your PDFs to the IDP software.
- Set Naming Rules: Define the rules and conventions for renaming the files based on their content or metadata.
- Automate Renaming: The software will automatically scan the internal content, apply the naming rules, and rename the files accordingly.
Here is a demo of the Nanonets Rename PDF workflow in action.
Rename files based on content or your own naming conventions
Using IDP software for renaming PDFs saved significant time and reduces the risk of errors. It ensured consistency in naming conventions and helped maintain an organized DMS, enhancing overall productivity and efficiency. This automated approach is ideal for businesses dealing with a high volume of documents.
You can follow the below steps to rename PDFs in bulk based on their content using Nanonets -
- Sign up / login into https://app.nanonets.com.
- Choose a pre-trained model based on your document type / create your own document extractor within minutes.
- Verify the data extracted by Nanonets. Your data extraction model is ready now.
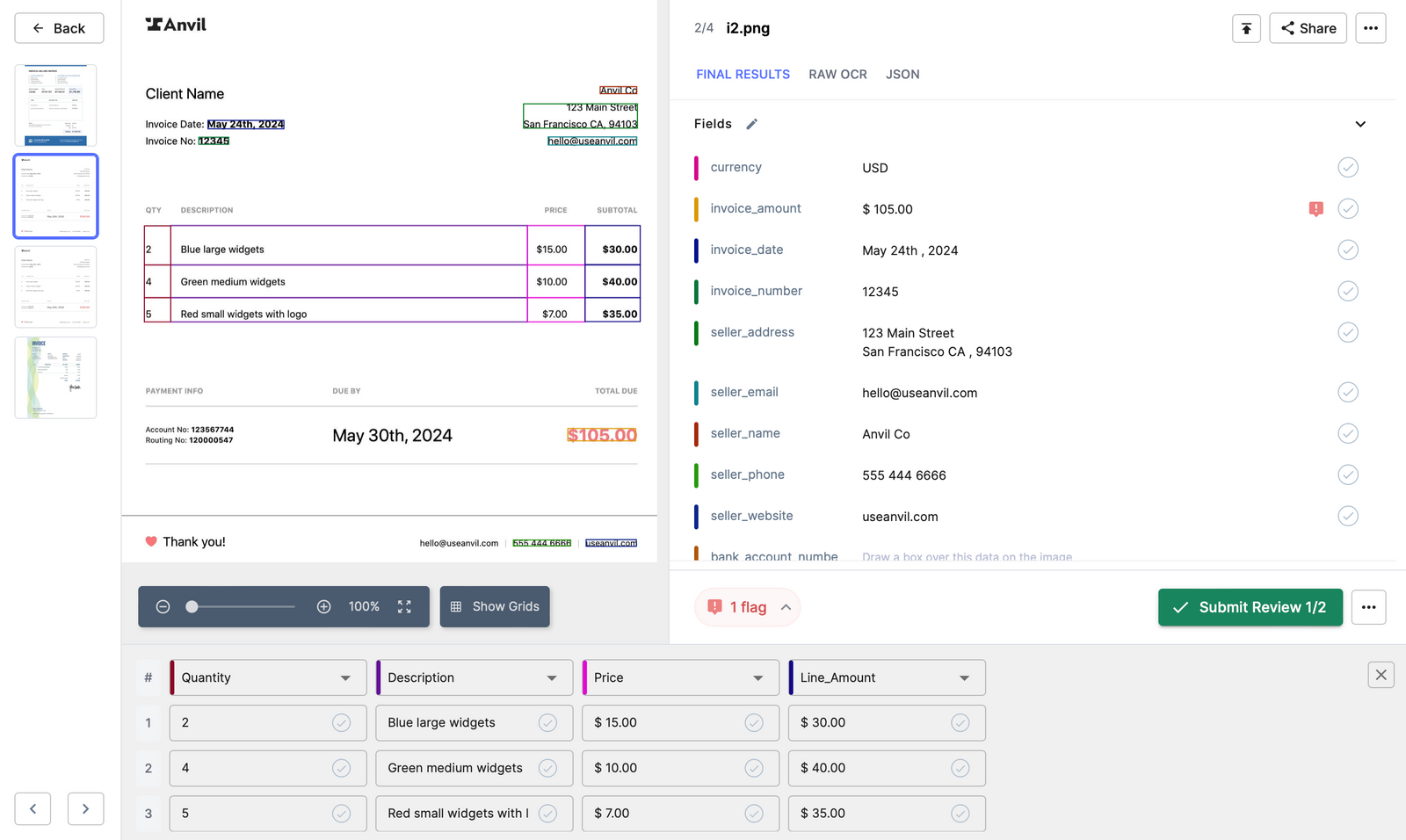
- Once you have created your model, go to the workflow section of your model.
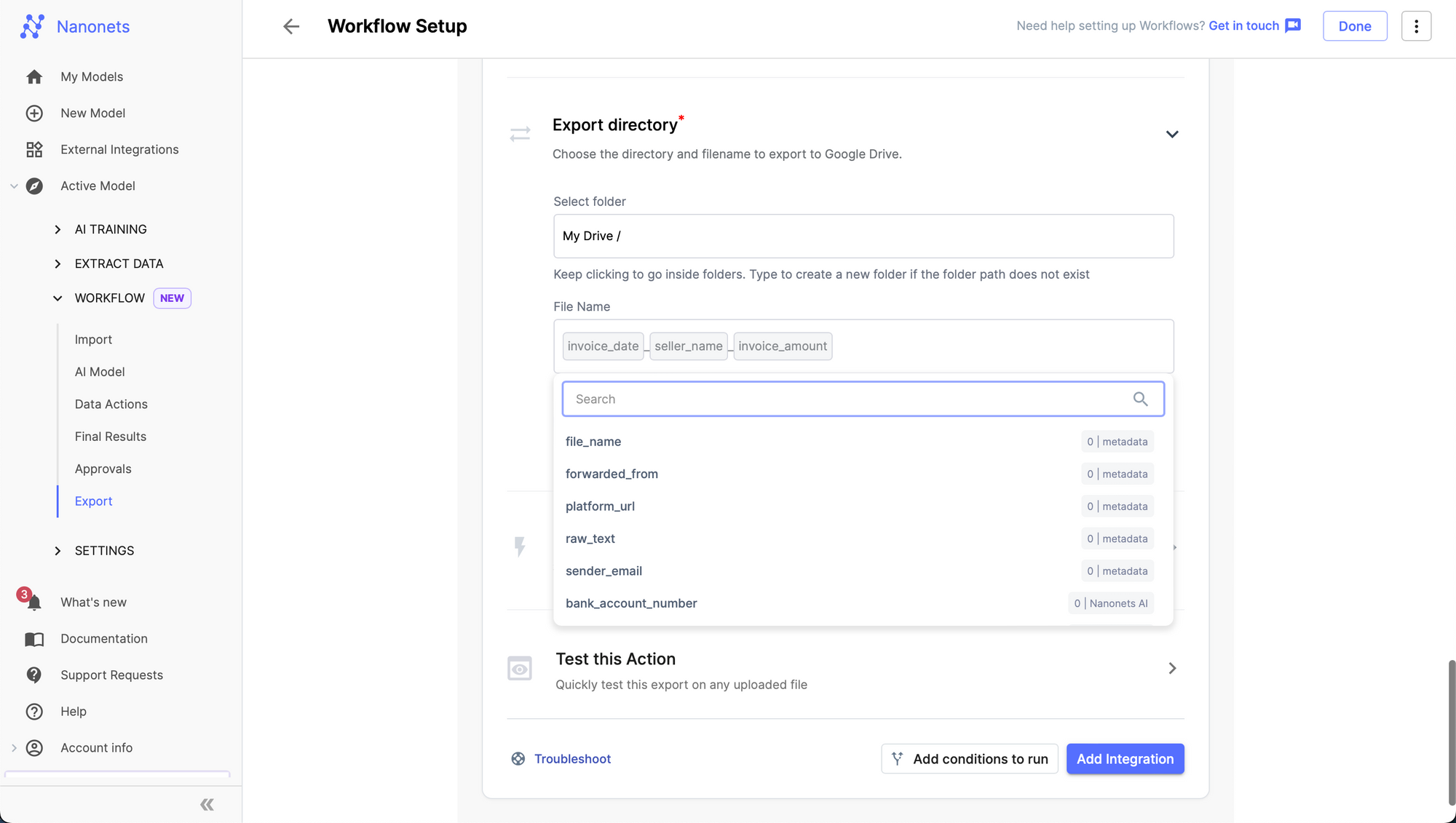
- Go to the export tab and select "Export files to Google Drive" and connect your google account.
- Choose the Drive folder where you want to send the renamed PDF.
- Specify a renaming format for your files based on the data extracted by Nanonets. I have specified a format here to rename files based on invoice date, seller name, and invoice amount as follows:
- Choose your export trigger and test using a file.
- Click on "Add Integration" and you are good to go.
Nanonets leverages AI & ML capabilities to only extract relevant data accurately from documents - essentially turning a flat scan into a searchable PDF with structured data. This makes renaming PDFs or any other documents based on content pretty straightforward & scalable.
Nanonets can handle documents with unknown or new layouts/formatting with ease. Its algorithms learn continuously and keep getting better with time. Do you want to rename multiple documents that come in various file formats, different layouts and/or multiple languages? Nanonets can handle it all.
- Fully automated, scalable & accurate
- AI/ML capabilities that keep learning continuously
- Renames multiple files automatically in seconds
- Handles unknown layouts and various file formats
Looking to create Rename PDF workflows on Nanonets? Check out Nanonets Rename PDF tool or use below action buttons to start creating your end to end workflow.
Final Thoughts
Renaming PDFs based on their content has transformed how I manage documents. Standardised file names make locating files a breeze, improving efficiency and reducing errors.
While Python scripts and Adobe plugins work well for specific scenarios, Nanonets’ IDP software stands out as a comprehensive, automated solution. It has helped me streamline workflows, enhance productivity, and maintain a well-organised document management system.
If you’re looking to take your document management to the next level, give Nanonets a try. You’ll wonder how you managed without it!