
Introduction
Recruitment is a $200 Billion industry globally with millions of people uploading resumes and applying for jobs everyday on thousands of employment platforms. Businesses have their openings listed on these platforms and job seekers come apply. Every business has a dedicated recruitment department that manually goes through the applicant resumes and extract relevant data to see if they are a fit.
As people get creative with their resumes in terms of style and presentation, automating data extraction from these resume is difficult and it is still mostly a manual job. A few studies have shown only 1% of applicant resumes on these job portals pass through to the next stage. So we're talking about hours of time wasted looking at resumes that don't even have say, the required basic skillset.
The situation from a job seeker's lens is also not ideal. You have 50 different job portals like Monster or Indeed where you have to create a new profile each time. You then have to go down the rabbit hole of finding a role (that rhymed!) that's suitable and the list just seems never-ending. You always feel that sense of dissatisfaction that there might be more jobs out there here and you should dig further. You also sign up to that email newsletter which sends you the most irrelevant jobs out there.
So the question here is, how do we make this resume information extraction process, smarter and better? What if the system could auto-reject applicants with skills sets on their resumes don't meet the criteria? What if you as a job seeker could just upload your resume and be shown all the relevant jobs accurately?
In this article we aim to solve this exact problem. We'll be looking at deep-diving into how we can leverage deep learning and PDF OCR for Resume Parsing.
Automate your resume parsing workflows. Build a custom resume parser with Nanonets.
An Ideal System for Resume Filtering
Let’s try to design an ideal system for an intelligent data extraction system for resume filtering.
Resumes from the applicants have different formats in terms of presentation, design, fonts, and layouts. An ideal system should extract insightful information or the content inside these resumes as quickly as possible and help recruiters no matter how they look because they contain essential qualifications like the candidate's experience, skills, academic excellence. Also, in the opposite case, a candidate can upload a resume to a job listing platform like Monster or Indeed and get matching jobs shown to him/her instantaneously and even further on email alerts about new jobs.
What is Resume Parsing?
It converts an unstructured form of resume data into the structured format. It's a program that analyses and extracts resume/CV data and returns machine-readable output such as XML or JSON. This helps to store and analyze data automatically.
Advantages of OCR Based Parsing
A recruiter can set criteria for the job, and candidates not matching those can be filtered out quickly and automatically.
- A ton of person-hours is saved for the recruiter to cater to potential candidates better.
- Candidates can be assessed and matched for other suitable roles.
- A company can track the quality of applicants over time. Meaningful analytics on candidates can be generated.
- If the next steps are to take an online test, the shortlisting and the test process can be reasonably integrated.
- The signup process for a job portal becomes straightforward. Currently, a candidate has to enter her/his info in a form while signing up for the website.
Why is automated data extraction for Resumes tough using traditional methods?
Now, we’ll look at a research of Resume Information Extraction, published in the year 2018, by a team at the Beijing Institute of Technology. The end goal was to extract information from resumes and provide automatic job matching. We quote this work as a Traditional Technique because the proposed algorithm uses simple rule heuristics and text matching patterns. The authors of this research proposed two simple steps to extract information. In the first step, the raw text of the resume is identified as different resume blocks. To achieve the goal, they designed a feature called Writing Style, to model sentence syntax information on the text blocks.
To identify the text blocks, the algorithm simply follows a few captions like “Project Experiments” and “Interests and Hobbies.” Whenever these captions are identified, they facilitate the follow-up work by going through each line and until the next captions are identified. After these blocks are segmented, they use their feature Writing Style and perform a few rule-based heuristics for every line. In their scenario, they considered the Chinese resume where spaces are used to separate different tags, which is a very clear Writing Style feature. Here's an example of how they mention their work experience.
“2005–2010 [company name] [job position],” “[company name] [job position] [working time],” and “[university] [major] [degree] [time range].”
Below is an image defining their Heuristic Rules and their respective operations.
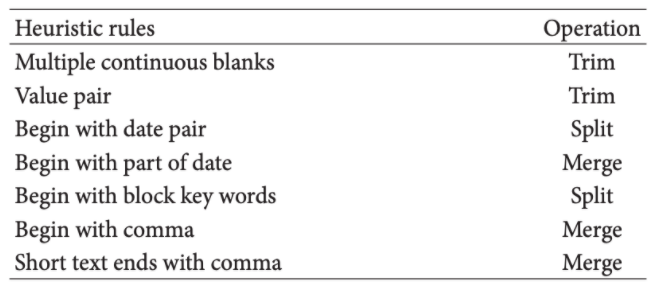
In the second step, several classifiers are used to identify different features of fact information in resumes. Different name entities are collected, such as university name, company name, job positions, and department, which are easy to extract from resumes. Below is the text algorithm,

Looking at this algorithm, it’s a straight forward regular expression based pattern matching system. Similar to this, there are several tools and research proposed.
Using Named Entity Recognition
One more traditional approach is using Named Entity Recognition. It is used when you want a specific set of strings from the extracted regions. For example, consider the component of a resume below,

Say you want only programming languages he’s good at. These type of problems can be solved using NER, before going into depth, let’s see what’s it about,
Named Entity Recognition is an algorithm where it takes a string of text as an input (either a paragraph or sentence) and identifies relevant nouns (people, places, and organizations) and other specific words. For example, in a given resume if you want to extract, only Name and Phone Number using NER would make our job much easier. It can be achieved by deep learning. This is because of a technique called word embeddings, which is capable of understanding the semantic and syntactic relationship between words. There’s some pre-processing involved for most of the programs that involve data, even this Resume Parsing includes one. In most of the cases, resumes are saved as PDFs or DOCX, hence to make it easy, in the first steps, we’ll convert the word document into a save in a variable. Follow the code below,
import docx2txt
def extract_text_from_doc(doc_path):
temp = docx2txt.process(doc_path)
text = [line.replace('\t', ' ') for line in temp.split('\n') if line]
return ' '.join(text)
path = "vihark.docx"
text = extract_text_from_doc(path)
As we can see here, we’ve used a library called doct2txt that copies all information present in the word document to a variable name text. Next, we’ll be importing the spacy library and load a pre-trained model for NER. You also need to download it, before we put it into use.
import spacy
from spacy.matcher import Matcher
# load pre-trained model
nlp = spacy.load('en_core_web_sm')
# initialize matcher with a vocab
matcher = Matcher(nlp.vocab)
def extract_name(resume_text):
nlp_text = nlp(resume_text)
# First name and Last name are always Proper Nouns
pattern = [{'POS': 'PROPN'}, {'POS': 'PROPN'}]
matcher.add('NAME', None, pattern)
matches = matcher(nlp_text)
for match_id, start, end in matches:
span = nlp_text[start:end]
return span.text
name = extract_name(text)
print(name)
I’ve used my Resume and the model is able to pull out the name from the Resume. Similarly, we can extract other components from the Resumes using NER.
Output: Vihar Kurama
Challenges Traditional Algorithms Fails
- Iterating through different resume templates and writing rules is impossible due to the 1000 different formats with no straight order
- Creating hierarchies between the captions and the nested content within are tricky
- Creating rules for extracting values like experience, graduation year, etc. isn’t always straightforward.
- Rules will need to change as the language changes when the area of the job (marketing vs. engineering) changes.
Building an Accurate Resume Parsing Engine using Deep learning
In the previous section, we’ve discussed traditional methods. Here we’ll be discussing how we can build an accurate automated model for Resume Parsing. Let’s get started!
How do we do this? How can we build a model that is generic for all the resume templates out there? This is where Deep Learning (DL) and Computer Vision (CV) comes into the picture. If you are not familiar with DL, think of it as an artificial brain that learns from data using mathematical functions. Unlike traditional algorithms, these were considered to be intelligent, meaning they can work in different scenarios with high accuracy. One more additional advantage is that unlike traditional algorithms, these algorithms can be easily integrated or deployed into any existing systems. On the other hand, the Computer Vision algorithms are like the eyes for the machines, they intelligently detect and preprocess the images and convert them to editable data within no time.
Considering our problem of Resume Parsing, at a high level, Deep Learning intelligently finds useful regions from the resumes and passes on to Computer Vision where it converts the identified portions into editable text. Now we’ll understand the entire process of building the model by going through different techniques.
Object Detection and OCR
Resumes are basically live templates consisting of different sections. Meaning most of the sections in the resume are similar, but they are organized in different formats. The various components of resumes are [Career Objective, Educational Background, Work Experience, Leadership, Publications, etc.].
To extract these components, we consider these as the objects and detect them through an object detection algorithm. Techniques such as Raspberry Pi object detection can be employed for low-cost, edge-based solutions, enabling localized processing of resume data in real-time.
There are several challenges that need to be addressed, such as table extraction (sometimes components like educational background are added in tables), font variation, and template variation.
We’ll now delve into how object detection is used to extract components from resumes. To achieve this Convolution Neural Networks (CNNs) are commonly used. There are several applications based on CNNs that achieved a state of the art performance for Image Classifications and Segmentation problems. Below is an image of a simple CNN,

For resume parsing using Object detection, page segmentation is generally the first step. The main goal of page segmentation is to segment a resume into text and non-text areas. Later, we extract different component objects, such as tables, sections from the non-text parts. Unlike traditional rule-based methods where a lot of parameters are involved, the main goal of learning-based (CNN in this case) methods is to split document pages into lines at first, then to classify each line and combine the classification results by different rules.
Now we’ll discuss a few Object Detection Methods
[ Note: These algorithms are not always the same, with new techniques and different neural network architectures performance consistently changes]
Method 1: CNN Based Page Object Detection in Document Images
This work was proposed by Xiaohan Yi and his team in the year 2017 at ICDAR (International Conference on Document Analysis and Recognition). The goal of this research is to detect specific regions from the scanned pages using CNNs. The proposed algorithm was able to achieve good results after three phases, let’s discuss them.
Phase 1: In this phase, a dataset is collected by authors that consist of 12,000 English document page images selected from 1,100 scientific papers of CiteSeer. Each of these documents has variations in terms of layouts as well as text (font, color). In this phase, a dataset is collected by authors that consist of 12,000 English document page images selected from 1,100 scientific papers of CiteSeer. Each of these documents has variations in terms of layouts as well as text (font, color). They've annotated the objects in each page manually, a total of 380,000 document page objects in all, consisting of 350,000 text-lines, 22,000 formulae, 5,783 figures, and 2,295 tables.
To detect objects, two methods are used. Firstly, Rough Proposal, Where a Breadth-First Search (BFS) is utilized to find all the 8-connected component areas in the filtered binary image, once a component is generated, it is replaced by its bounding rectangle to decrease the irrelevant information in images. Second, a pruning strategy is used to detect the columns in pages and filter the regions that exist in multi-columns.
Phase 2: The second phase Involves designing and training a convolutional neural network. The authors proposed a Spatial Pyramid Pooling (SPP) based CNN built on top of the VGG-16 Network. One key difference using SPP over CNNs are, The (SPP) structure pools the feature maps to fixed size by a fixed scale down-sampling. Stochastic Gradient Descent is used for training the network.
VGG-16 is already an existing trained network that has achieved the state of the art performance for classification tasks on the ImageNet dataset.
Phase 3: In the last phase, the results were pulled out. The proposed network has achieved a recall accuracy of segmenting text-line, forums, tables, and figures with 94.1%, 90.9%, 88.5%, 83.2% respectively. Below is an image of the entire process,

Reference: CNN Based Page Object Detection in Document Images - IEEE Conference Publication
Method 2: Extract Semantic Structure from Documents using Multimodal CNNs
In this section, I’ll be discussing the work “Learning to Extract Semantic Structure from Documents Using Multimodal Fully Convolutional Neural Networks” which was proposed by researchers from Adobe and The Pennsylvania State University. The authors proposed an end-to-end, multimodal, fully convolutional network for extracting semantic structures from document images. This network takes a document as input and splits it into regions of interest and to recognize the role of each region. Let’s see how this is achieved in different phases proposed.
Phase 1: The first phase is similar to one discussed in the previous approach -- page segmentation. Here instead of directly annotating the images, text embedding maps (you can consider these as learned embeddings from the text where words that have the same meaning have a similar representation) were used. The advantage here using text embedding is it could even tell the difference between a list and several paragraphs as they'll be represented in lower dimensions.
Phase 2: The phase is referred to as logical structure analysis. It’s based on image semantics with which it categorizes each region into semantically-relevant classes like paragraph and caption. This is basically the output from the multimodal fully convolutional neural network they’ve proposed. Let’s now discuss the architecture of the proposed model, below is a screenshot.
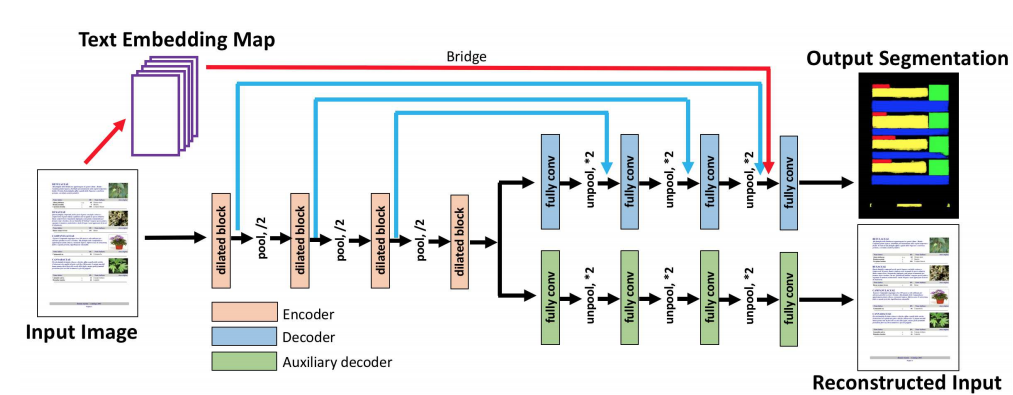
One core feature of this model is that it uses an alternative skip connection which is illustrated by the blue arrows in the image and dilated convolution blocks which are inspired by the Inception architecture. Each dilated convolution block consists of 5 dilated convolutions with a 3 × 3 kernel size and a dilation d = 1, 2, 4, 8, 16. The necessity of using these in regular CNNs is to reduce the information loss while downsampling. This architecture was trained on a collected dataset consisting of a total of 271 labeled documents with varied, complicated layouts. All convolutional layers have a three × three kernel size and a stride of 1. The pooling (in the encoders) and un-pooling (in the decoders) have a kernel size of 2 × 2. Batch normalization layers are applied immediately after each convolution and before all non-linear functions. The network has achieved IOU Accuracy in extracting bkg, figure, table, section, caption, list, paragraph with 84.6%, 83.3%, 79.4%, 58.3%, 61.0%, 66.7%, 77.1% accuracies respectively. Below is an image of how the model returns the segmented regions of interest.

Automate your resume parsing workflows. Build a custom resume parser with Nanonets.
Using Nanonets
Using the Nanonets API You can automatically extract all the necessary information from the Resumes required for job searching and matching. Just upload a Resume and get all the extracted fields returned in the format of your choosing.

Automate your resume parsing workflows. Build a custom resume parser with Nanonets.
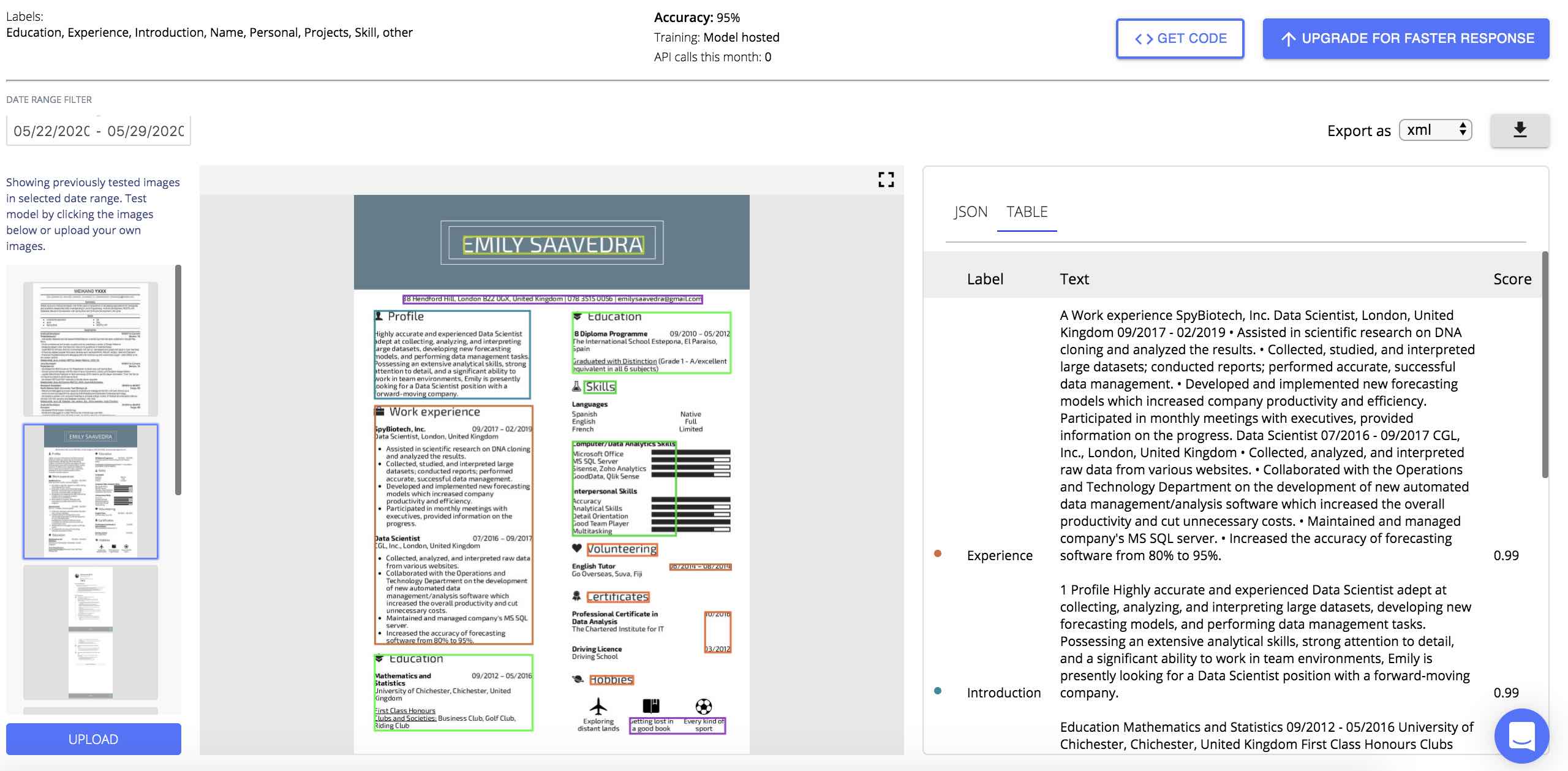
We tackle most of the problems listed above so you don't have to spend time reinventing the wheel.
- Identifying key-value pairs: They are not uniformly positioned across formats: Using our GCN implementation we are able to parse keys across Resumes. Our GCN implementation includes optimizations for finding the right neighborhood search to get the best trade-off between feature explosion and lack of context for the model to correctly interpret which key each belongs to.
2. Taking multiple languages into account.
Our models have been trained with text embeddings that are language agnostic. This is achieved by creating a feature space such that the word embeddings for 'Education' and 'educación' (spanish) and 'educação' (portuguese) all map to the same feature space. So the text features become language independent and the model need not be trained per language.
3. Not enough data to train for a particular key (class imbalance): We have a large corpus of Resumes our models are trained on which mitigates this issue.
Other Problems
- Rotation and Cropping: We've implemented a rotation and cropping model as a part of our pre-processing step to identify the edges of a document and then correctly orient the document. This uses a model similar to an object detection model with the objective function modified to identify 4 corners as opposed to 2 points that are standard in an object detection problem. This solves for both rotation and cropping
- Blur and Poor document quality: We have a quality model placed as a part of our preprocessing pipeline that only accepts documents above a certain quality threshold. This is a binary classifier which is a simple image classification model trained on a number of documents that are both good and bad quality. In the document capture pipeline documents can be rejected early if they don't meet the quality standards required and can be sent for recapture or manual processing.
- Data drift: Data drift is a problem when the model is exposed only to data from a single vendor or a single region. If the model has been historically trained on a variety of different vendors, geographies industries, etc the possibility of data drift greatly reduces since it has already been exposed to these variances.