
Salesforce is a renowned cloud-based software company headquartered in San Francisco, California. It is best known for its Customer Relationship Management (CRM) solution that empowers businesses to manage all interactions with clients more effectively and efficiently. The CRM platform is highly customizable and allows users to automate sales, marketing, customer service, analytics, and application development.
Salesforce's services are divided into several broad categories: Sales Cloud for salesforce automation, Service Cloud for customer support, Marketing Cloud for digital marketing campaigns, Commerce Cloud for online shopping, and more. These solutions are interconnected, enabling a seamless flow of data and insights that drive business growth.
Artificial intelligence is integrated into the platform through Salesforce Einstein, which delivers AI-powered analytics for sales, service, and marketing. Salesforce also offers the Trailhead platform for user training and skills advancement, emphasizing its commitment to user success.
The Need of OCR and Document Data Extraction for Salesforce
In the age of digital transformation, businesses are inundated with vast amounts of data. Customer interactions, business transactions, and administrative procedures generate massive volumes of documents that require careful management. Salesforce, a leading Customer Relationship Management (CRM) platform, serves as the hub for this data, facilitating its analysis to drive strategic business decisions. However, the effectiveness of Salesforce is significantly enhanced when coupled with Optical Character Recognition (OCR) and Document Data Extraction technologies.
OCR is a technology that converts different types of documents, including scanned paper documents, PDF files, or images captured by a digital camera, into editable and searchable data. Document Data Extraction, on the other hand, is a process that collects specific information from various types of documents, transforming unstructured data into a structured format for further processing and analysis.
Manual data entry is not only labor-intensive but also prone to errors, which can compromise the quality of data within Salesforce. The introduction of OCR and Document Data Extraction eliminates this challenge. These technologies streamline the process of data input by automatically capturing, classifying, and entering data into Salesforce. Consequently, they increase efficiency, reduce human error, and ensure that high-quality, accurate data is available for business intelligence and decision-making.
Consider the example of a company dealing with numerous invoices, contracts, and forms. OCR technology could digitize these documents, making them searchable and editable, while Document Data Extraction could extract relevant information such as dates, amounts, contract terms, or customer details. The extracted data can then be automatically entered into Salesforce, reducing administrative workload and improving the overall accuracy of the data.
OCR and Document Data Extraction technologies can also play a crucial role in enhancing customer service and support, a core aspect of Salesforce. By rapidly processing customer-related documents and communications, they can accelerate response times and enhance the quality of customer service. Information from physical documents, emails, or digital forms can be swiftly made available to customer service representatives, enabling them to provide more personalized and timely support.
In addition to efficiency and accuracy, these technologies also bring a level of scalability that manual processes simply cannot match. As businesses grow and the volume of their data increases, OCR and Document Data Extraction technologies can scale accordingly, ensuring consistent data quality and process efficiency.
Compliance is another area where OCR and Document Data Extraction offer significant advantages. Many industries are subject to regulations that require certain data to be retained, often in specific formats. By automating the extraction and classification of this data, businesses can ensure they are compliant with regulatory requirements and have ready access to necessary data for audits or investigations.
In conclusion, the integration of OCR and Document Data Extraction with Salesforce is a powerful synergy. These technologies enhance the capacity of Salesforce as a CRM tool by improving data quality, increasing process efficiency, enhancing customer service, enabling scalability, and facilitating regulatory compliance. As businesses continue to navigate the digital landscape, the incorporation of these technologies into their data management strategies will increasingly become not just a competitive advantage, but a necessity.
Examples of OCR Workflows with Salesforce
Invoice Processing: Companies receive countless invoices from various suppliers. With Nanonets OCR, these invoices can be digitized, and pertinent information such as supplier name, invoice number, date, line item details, and total amount can be extracted. This extracted data can be automatically populated into the Salesforce Billing or FinancialForce systems. The OCR solution enables automatic reconciliation of purchase orders and invoices, helping finance teams manage payables more efficiently.
Sales Order Management: Businesses often deal with physical or digital sales orders. Using Nanonets OCR, essential data like customer name, order number, product details, and quantities can be extracted from these documents. The data can then be imported into Salesforce's Sales Cloud to automatically create or update Sales Orders and associated Opportunity records. This can streamline the sales process and ensure the accuracy of order data.
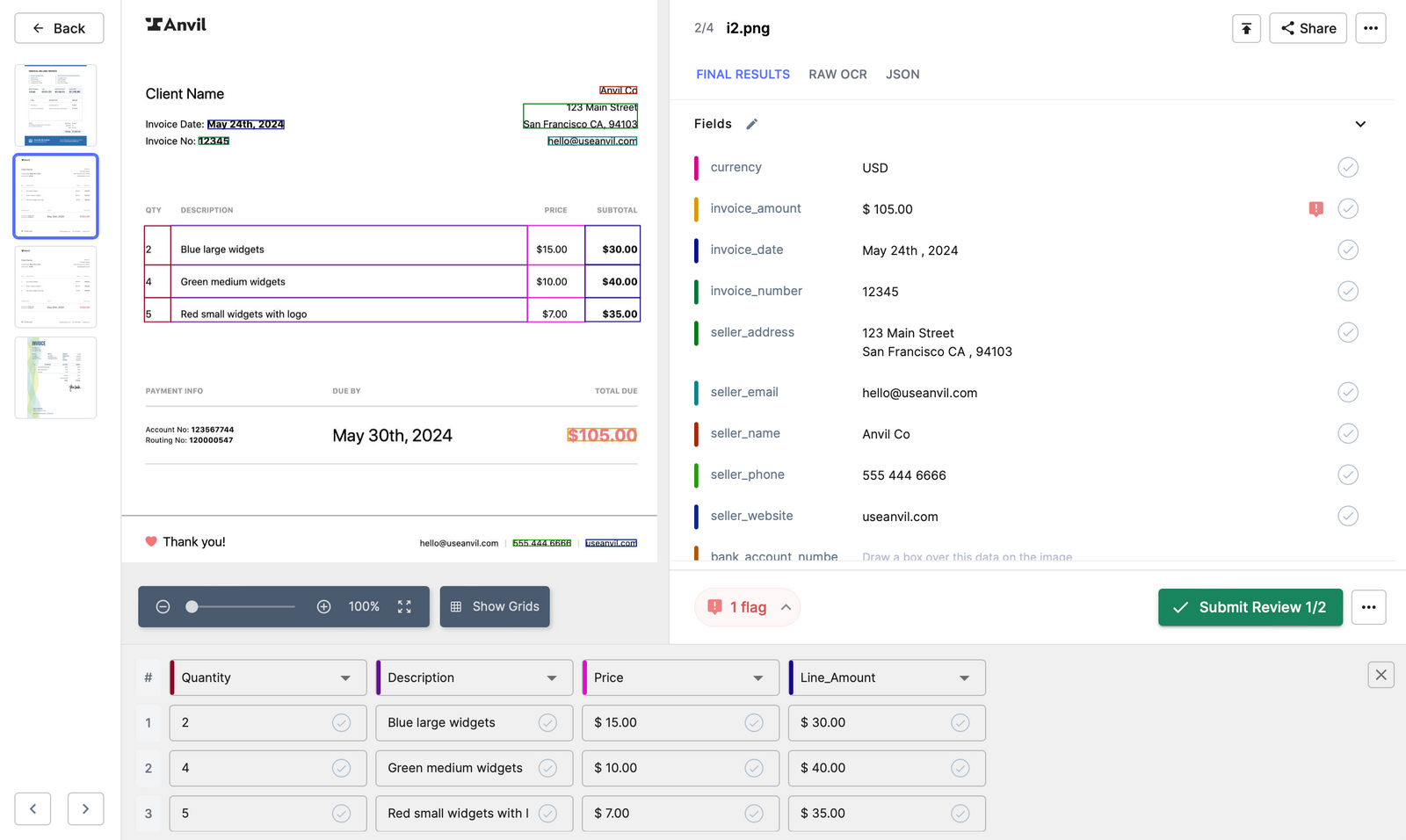
Customer Onboarding: During the customer onboarding process, businesses collect various documents like identity proofs, proof of address, or financial documents. Nanonets OCR can be used to extract important data from these documents like customer name, address, date of birth, etc. This data can be used to populate the new customer's record in Salesforce's Service Cloud, expediting the onboarding process and ensuring accurate customer data for future interactions.
Contract Management: Businesses often deal with multiple types of contracts, like vendor contracts, lease agreements, or customer contracts. Automate data extraction from contracts using tools like Nanonets OCR to extract key data such as contract term, renewal date, clauses, or parties involved. This information can be entered into Salesforce's Contract Management system, enabling companies to keep track of contractual obligations and automate renewal reminders, thus reducing the risk of contract violations or lapses.
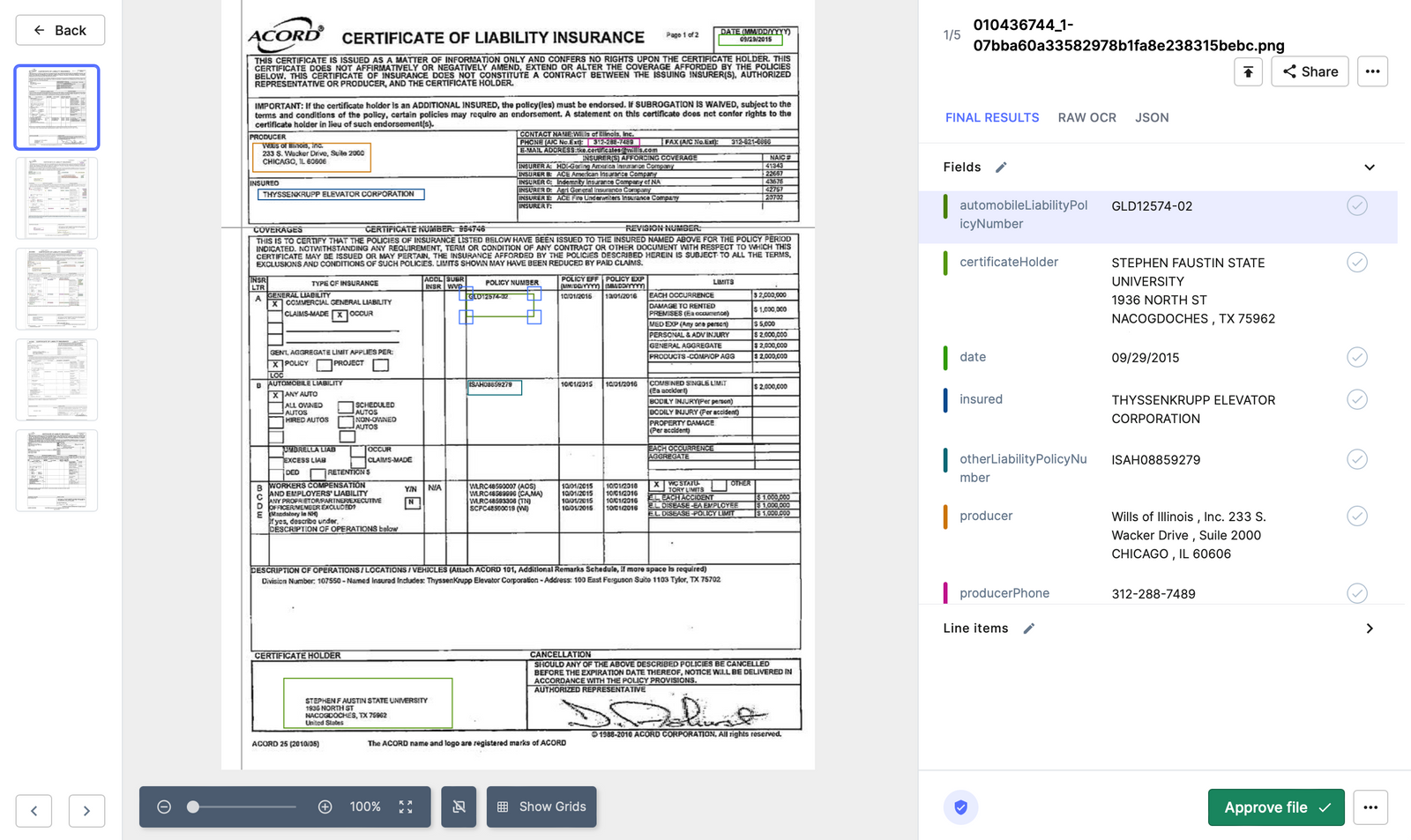
Insurance Claim Processing: In the insurance industry, claims processing involves reviewing various types of documents, such as accident reports, medical documents, or receipts. Nanonets OCR can extract pertinent data like claim number, policy number, amount claimed, or nature of the claim. This data can be fed into Salesforce's Insurance Claim Management system to expedite the claims processing time, improve accuracy, and enhance customer satisfaction.
How to Set up OCR and Document Extraction in Salesforce with Nanonets
You can follow the below steps to set up OCR and document extraction for Salesforce with Nanonets -
- Sign up / Login on https://app.nanonets.com.
- Choose a pretrained model based on your document type / create your own document extractor within minutes.
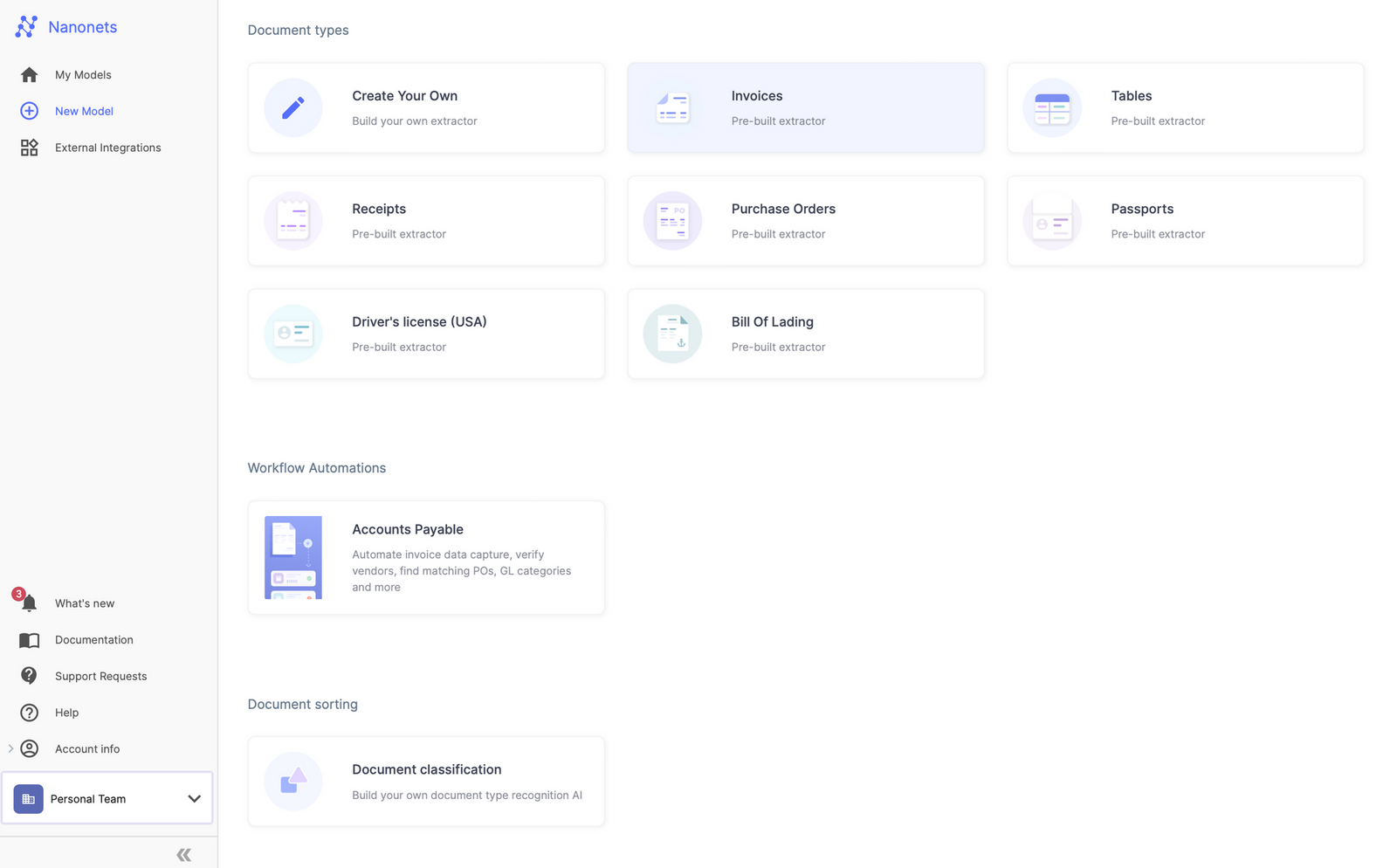
- Once you have created the model, navigate to the Workflow section in the left navigation pane.
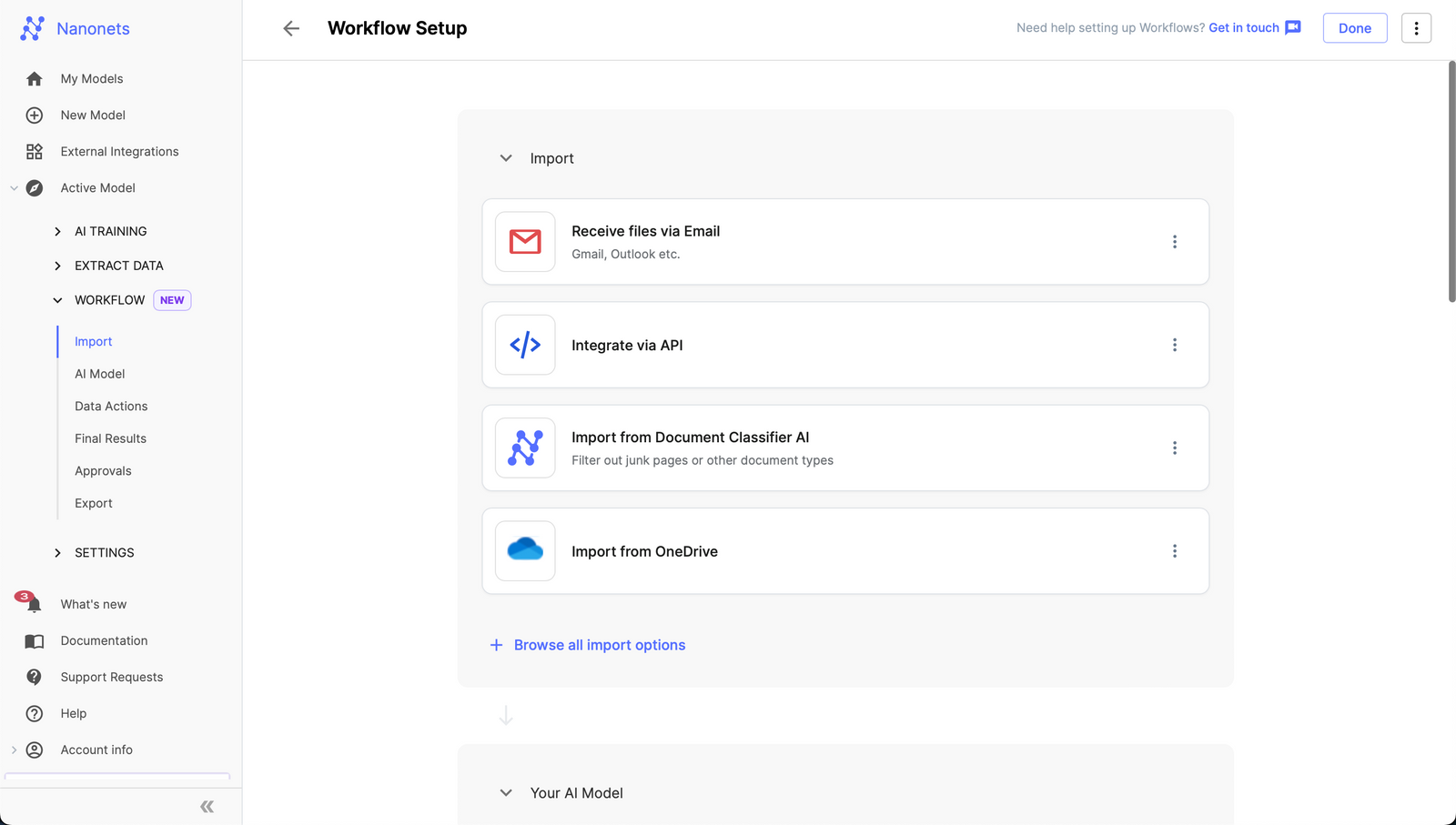
- On the Workflow Screen, go to the export tab and click on "Export to Salesforce".
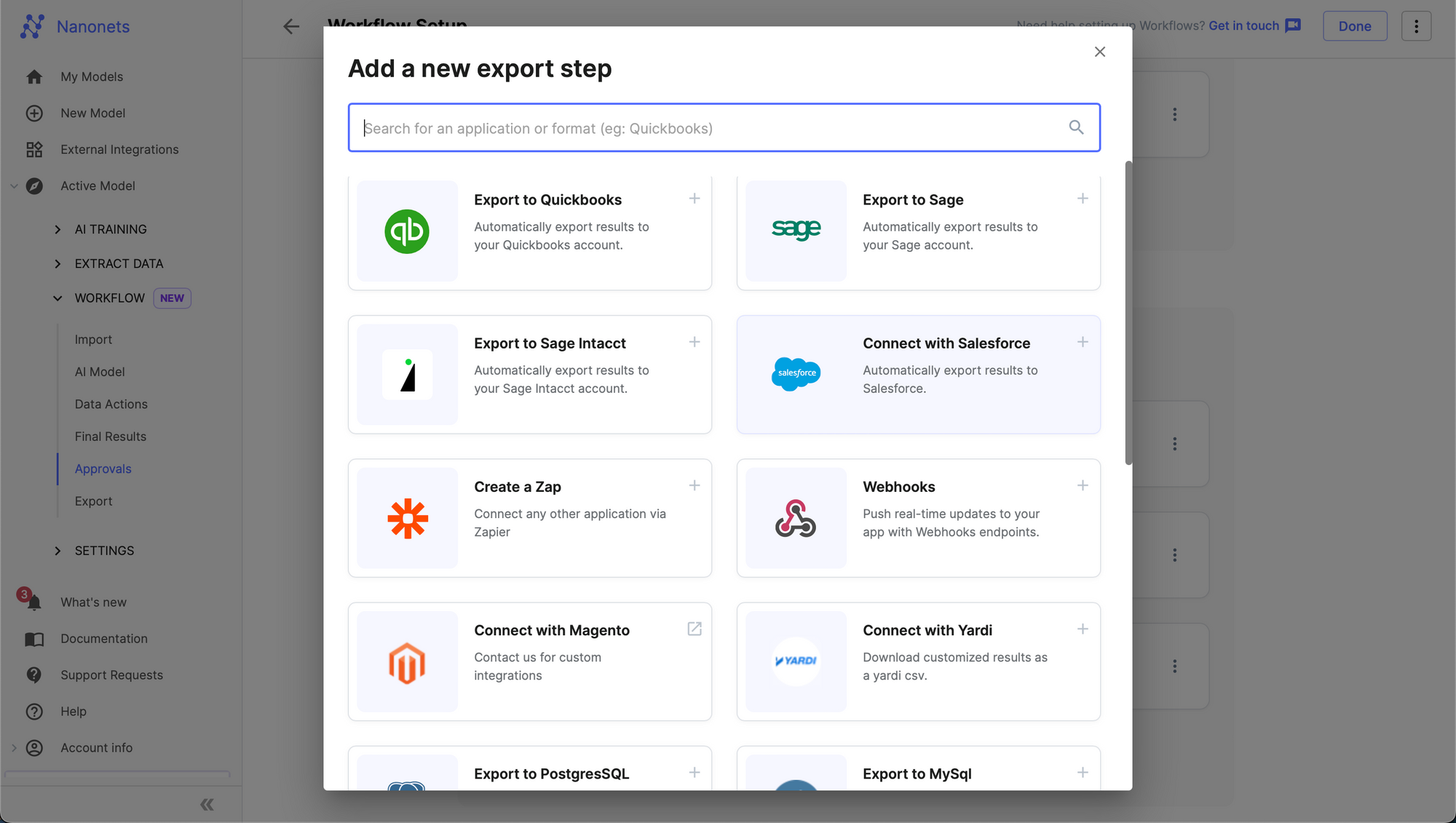
- Click on Sign in to Salesforce.
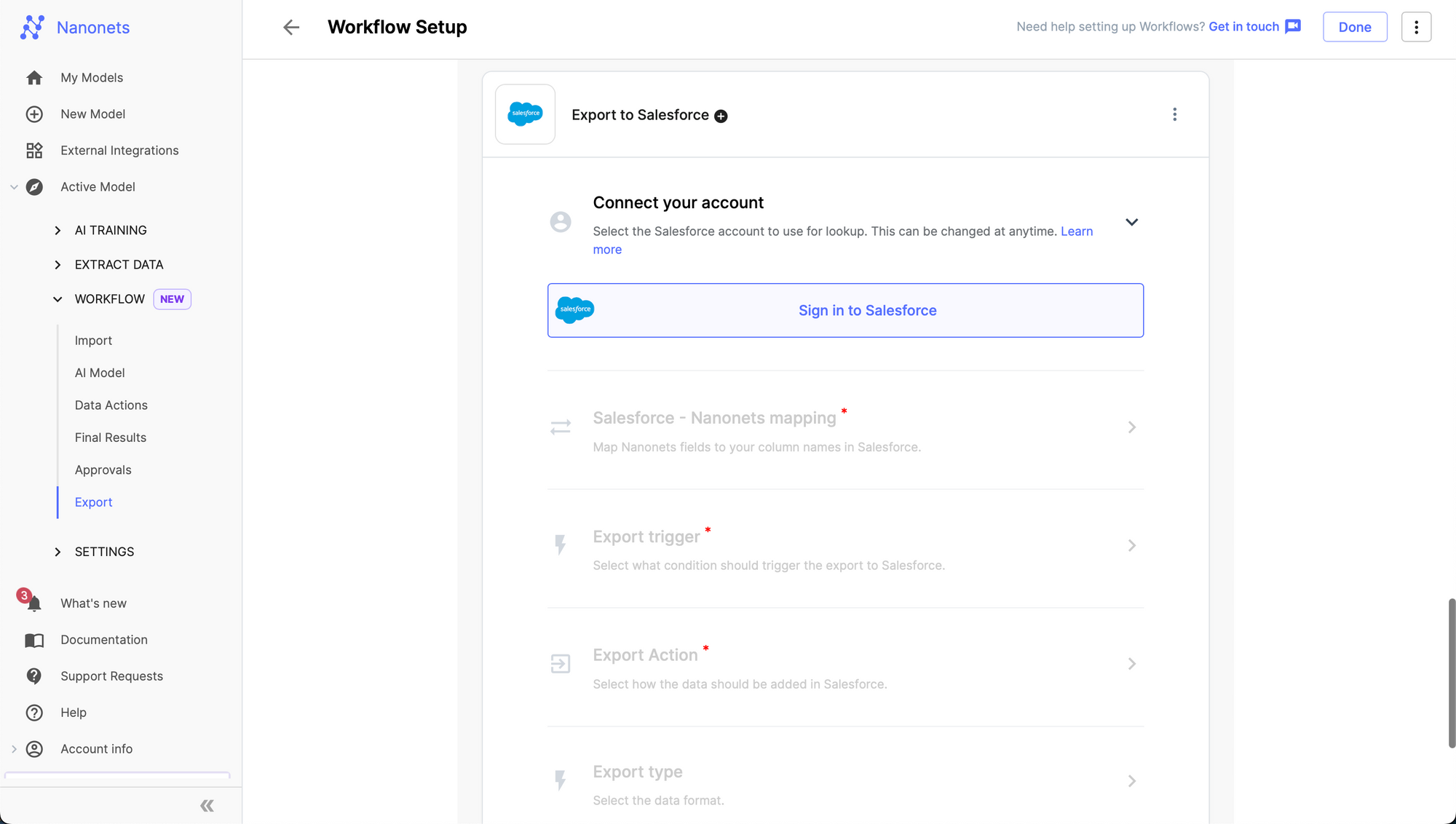
- Enter your Salesforce credentials.
- Back on the Nanonets Salesforce card, map the Nanonets fields to the corresponding columns in Salesforce.
Eg: The Invoice_number captured in Nanonets should be populated under 'Invoice ID' in Salesforce. To link these two entities, they need to be mapped in the Nanonets export modal. - Select an Export Trigger:
- The file can be exported as soon as it is processed OR
- The file can be exported only if marked Approved - Click on Done and you are good to go.
Once you have added the integration, Nanonets will send data extracted from incoming files to Salesforce based on your export configuration.
Nanonets for OCR and Automated Data Extraction for Salesforce
As we delve into an era of increasing digital data, businesses face the challenge of effectively managing, interpreting, and integrating this data into their CRM systems. Salesforce, as a leading CRM platform, facilitates the efficient handling of this information. But its power can be substantially amplified when integrated with advanced technologies like Optical Character Recognition (OCR) and Automated Data Extraction. Nanonets is one such potent tool that serves this purpose and revolutionizes the way businesses manage their data.
Nanonets is a machine learning-based OCR and data extraction solution that allows businesses to extract data from PDFs using AI and transform unstructured data from various documents into structured, actionable information. It works seamlessly with a myriad of document types, such as sales orders, invoices, contracts, orders, and forms, extracting crucial data and making it ready for analysis and processing.
The first step in the process involves scanning and digitizing the documents. Nanonets OCR employs advanced algorithms to accurately recognize text within the documents, irrespective of their format or the quality of the scan. This means that data from scanned paper documents, PDF files, or even images can be easily converted into an editable and searchable format.
Next, the Automated Data Extraction feature of Nanonets comes into play. It can identify and extract specific data points from the digitized documents, such as names, dates, numbers, or any other pertinent details. The solution's ability to learn and improve over time ensures high accuracy in data extraction, reducing the chances of human error that come with manual data entry.
The beauty of Nanonets lies in its seamless integration with Salesforce. The data extracted by Nanonets can be automatically populated into the appropriate fields in Salesforce. For instance, invoice data can be directed to the Salesforce Billing system, sales order details can update Sales Orders and Opportunities, and customer data from onboarding documents can be fed into Service Cloud.
In essence, Nanonets serves as the bridge that connects unstructured data from various documents with Salesforce's structured environment. This not only saves significant time and resources involved in manual data entry but also ensures the reliability of data within the Salesforce system. Consequently, businesses can leverage high-quality, accurate data to drive strategic decisions, enhance customer service, and improve overall operational efficiency.
Moreover, Nanonets' scalability means it can handle growing volumes of data as businesses expand, ensuring the data quality and process efficiency remain consistent. Compliance is another area where Nanonets provides significant benefits. It assists in extracting and classifying data that need to be retained for regulatory requirements, aiding businesses to stay compliant and ready for audits or investigations.
In conclusion, Nanonets offers a powerful, automated solution for OCR and data extraction, which, when integrated with Salesforce, can significantly enhance the CRM platform's effectiveness. It enables businesses to capitalize on their data, turning it into a strategic asset that drives customer engagement, operational efficiency, and business growth. As we move further into the digital age, solutions like Nanonets will become indispensable for businesses seeking to leverage their data to its fullest potential. The synergy of Nanonets and Salesforce offers a glimpse into the future of data management, a future where data extraction and interpretation are seamless, accurate, and inherently intelligent.