Summary: This post outlines how to digitize Purchase Orders for Automation using Deep Learning. AI and ML can now be used to help in AP automation
A typical procurement automation process at any company has multiple documents like Invoices, Purchase Orders, Delivery Notes, etc. This process has consistently focused on technology-based improvements to reduce overhead. A major optimization has been through the digitization of these documents leading to lower costs, faster turnaround times, and a reduction in error rates. This post will outline the current state-of-the-art technology in OCR-based data capture from these documents specifically focusing on Purchase Orders.
Without going into too much detail a typical procurement workflow looks like this:
- Buyer shares a Purchase Order
- The vendor generates an Invoice
- Buyer generates a GRN / Order Receipt Note
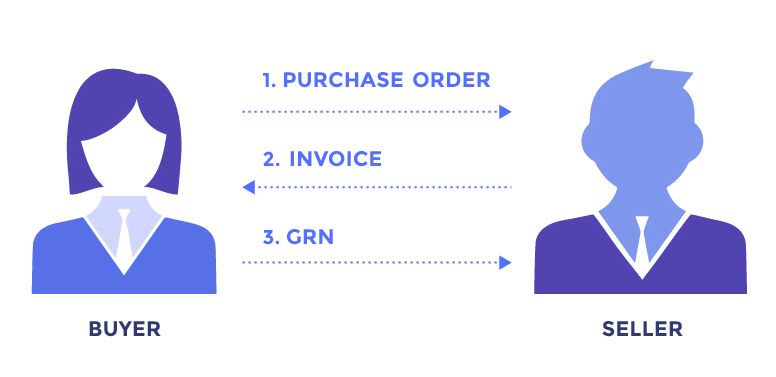
There are some subtle differences between the data capture process and requirements for each of these documents because of the difference in the information contained and the structure of these documents. A major difference is also because of who is preparing the document and as a result who has the need to digitize the document.
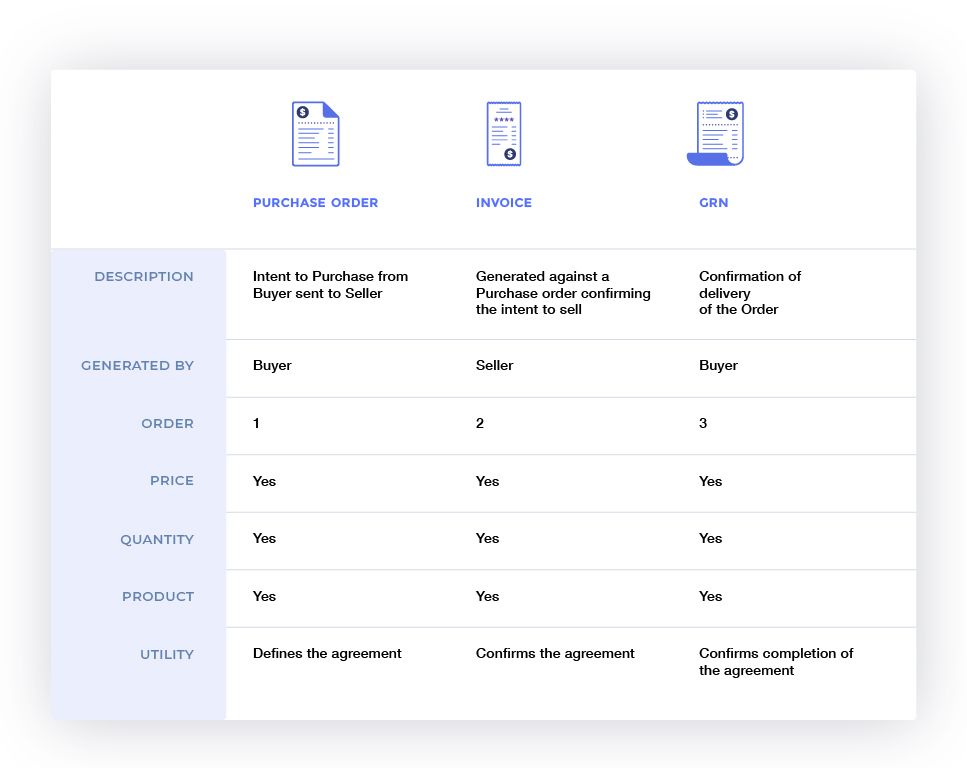
3 Way Matching
A major reason for the digitization is because these documents need to all corroborate and tell a consistent story of the transaction. The process of corroboration of these 3 documents is referred to as 3-way matching. The need for and process of 3-way matching vastly differ depending on who is conducting the match, the buyer or the seller.
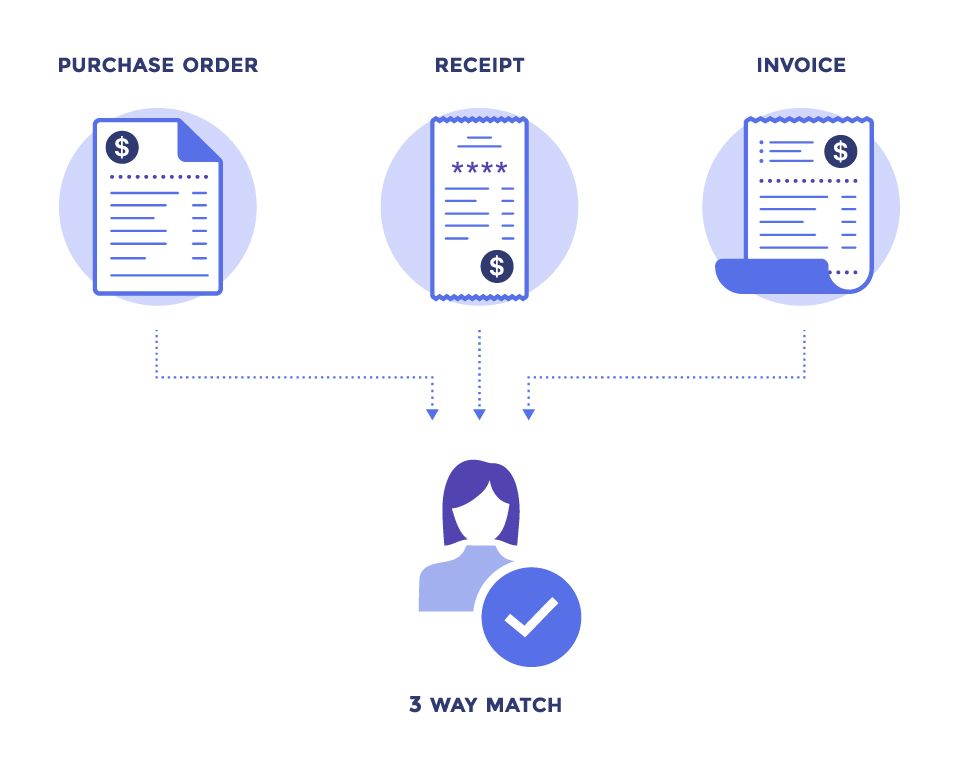
Buyer’s Perspective:
The Buyer generates the PO and the Receipt and has this information which can be easily reconciled in their software. Need to match the Invoice to the Purchase Order and Receipt. The Buyer needs to digitize the Invoice the other documents are already inside their ERP system.
There are a variety of reasons why a Buyer needs to perform 3-way matching:
- Ensuring that the purchase is authorized by matching an invoice and GRN with a Purchase Order
- Ensuring the correct product is purchased by matching across documents
- Ensuring the correct quantity authorized has been procured and delivered.
- Ensuring the price paid for each product was authorized
- Ensuring the correct vendor was selected and the correct vendor will eventually get paid since the same products might be procured from different vendors
- Matching inventory with quantities in the GRN for downstream quality of data
Seller’s Perspective:
The Seller generates the Invoice and needs to make sure the PO and Receipt match the information in the Invoice. The Seller needs to digitise the Purchase Order and Receipt the Invoice is generated from his ERP.
Seller’s need for 3 Way Matching
- Checking if a Purchase order can be fulfilled given inventory in the system
- Ensuring goods shipped to match the product that was requested
- Ensuring the correct customer was sent the requested product
- Ensuring the products requested are the ones that are delivered to the customer
- Ensuring the correct quantities are given to the customer
- Ensuring price in PO has a gross margin that can be fulfilled
Looking for an AI based OCR solution to automate Purchase Orders? Give Nanonets™ Intelligent Automation Platform a spin and put your Purchase Orders on autopilot!
Problems with Manual 3 Way Matching
Since the 3 way matching problem is fairly critical for both sides to meet their end of the contract efficiency and accuracy are paramount. However this is a fairly high process cost from a variety of perspectives:
Human Cost of Document Tracking and Errors
- It is a messy process especially when the PO is revised multiple times. Maintaining the correct version of the PO can be difficult. If not done correctly, it can lead to multiple payments, delivery of extra items, etc.
- There are multiple similar documents and transactions between a frequent supplier, buyer. These transactions can be consumed.
- The process cannot scale. Maintaining optimal human resources is hard when the volume of processing changes rapidly. Most companies have these departments overstaffed to compensate for spikes in volume
Payment or Procurement Delays
- Data from the documents is entered manually. This process becomes a bottleneck when the volume of documents processed increases
- Delays can lead to a delay in delivery/payment / procurement. Leading to a high cost of working capital or loss of revenue due to delays in procuring raw materials etc.
Inventory Errors
- If Inventory systems are not correctly integrated with this process there can be a high cost of miscalculating inventory. Resulting in overstocking, duplicate orders, understocking and loss of revenue.
Errors in 3 Way Matching
There are a variety of different errors that occur in this process. Below are a few examples

Vendor Matching Errors
Vendor matching is typically done based on two things, Vendor Name and Address. Since the same company could have various subsidiaries and different business units issuing similar invoices.
If the address from the Purchase Order and Invoice don’t have the correct address and Vendor name identified there could be issues in matching. Also as can be clearly seen just direct text matching doesn't work in matching the Invoice and PO.
| Purchase Order | Invoice | Status |
|---|---|---|
| Acme Inc. | Acme Inc. | Works |
| Acme Inc. | Acme Inc. Africa | Fails |
| Acme | Acme LLC. | Fails |
| Acme LLC. | Acme LLC. Artillery Division | Fails |
Product Matching Errors
Products are the most difficult item to match since they rarely follow the same name in the purchase order and invoice and receipt. This is most likely the biggest cause for errors.
Causes for errors could be because there are different versions of the same product, different sizes, specifications and prices. The product might have had a recent update, a substitute for an unavailable item was provided etc.
| Purchase Order | Invoice | Status |
|---|---|---|
| TYLENOL Sinus Pressure and Pain | TYLENOL Sinus Pressure and Pain | Works |
| Tylenol | TYLENOL Sinus Pressure and Pain | Fails |
| TYLENOL Sinus Pressure and Pain | TYLENOL® Sinus Pressure and Pain | Fails |
| TYLENOL Extra Strength | TYLENOL Extra Strength Pain Reliever & Fever Reducer 500 mg Caplets | Fails |
| TYLENOL Extra Strength Pain Reliever & Fever Reducer 500 mg Caplets | TYLENOL Extra Strength Pain Reliever & Fever Reducer 250 mg Caplets | Fails |
Quantity Matching Errors
Even if the product is matched correctly there might be errors in matching the quantity if the product in a specified quantity is unavailable etc. This is typically true between the purchase order and GRN as well since there is usually a time lag between these two documents.
Price Matching Errors
If there was a change in price during the entire product purchase lifecycle or if the product was updated or substituted this error might occur.
Duplicate Documents
If there are frequent purchases of similar products from the same vendor there might be multiple documents that look very similar. If the reference number to a PO is not mentioned in the Invoice and on the GRN for either the Invoice or the PO then there is a significant scope for document mismatch.
Digitising Purchase Orders
To get gather all of the relevant data from Purchase Orders the following fields need to be extracted:
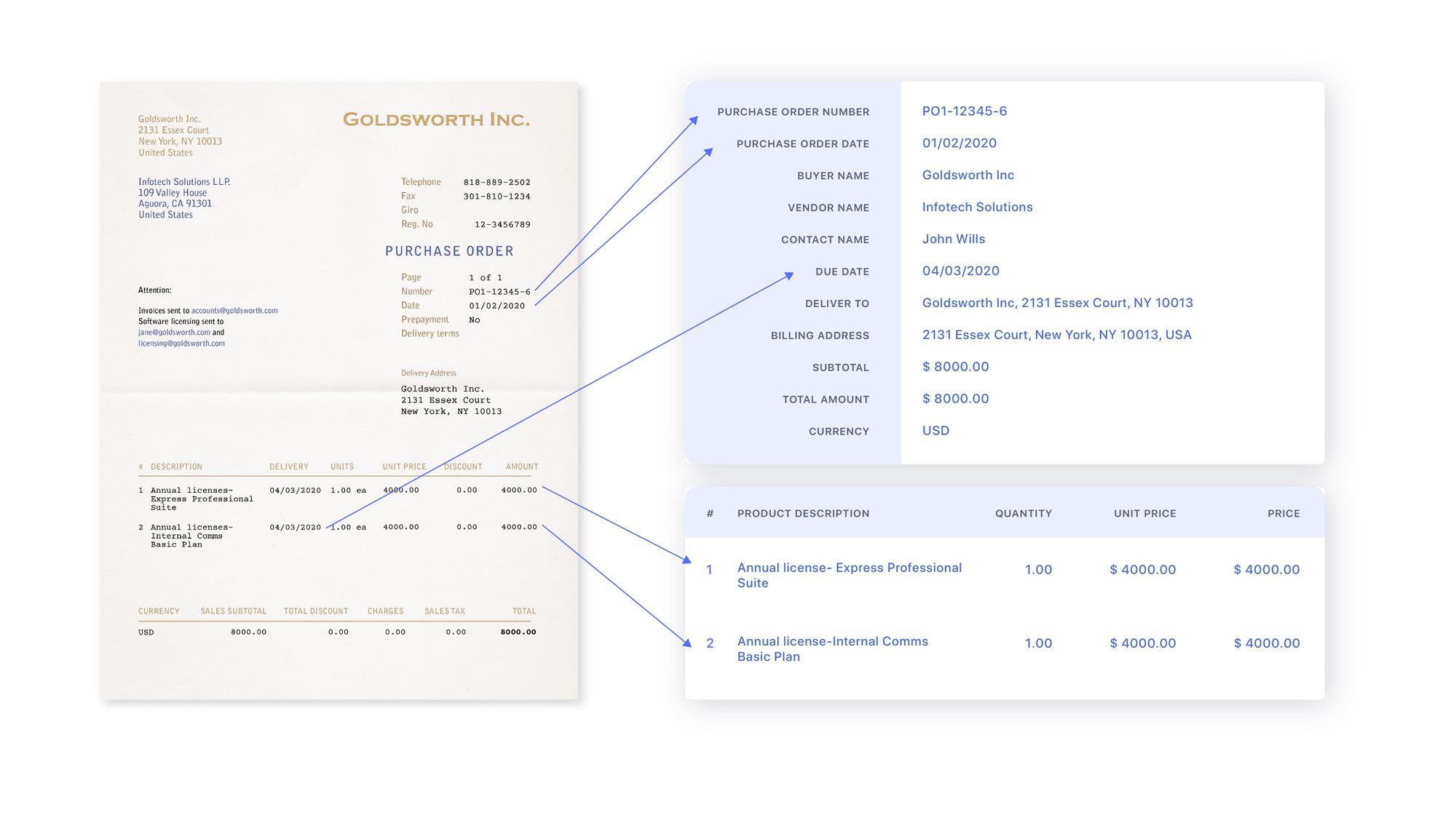
Common list of fields to be extracted (across Purchase Orders they might have different names):
| Billing Address | Payment Terms | Sub Total |
| Buyer Name | PO Number | Subject |
| Contact Name | Product | Total |
| Currency | Purchase Order Date | Unit Price |
| Deliver To | Quantity | Vendor Name |
| Due Date | Requisition No |
Current Solutions and their Problems
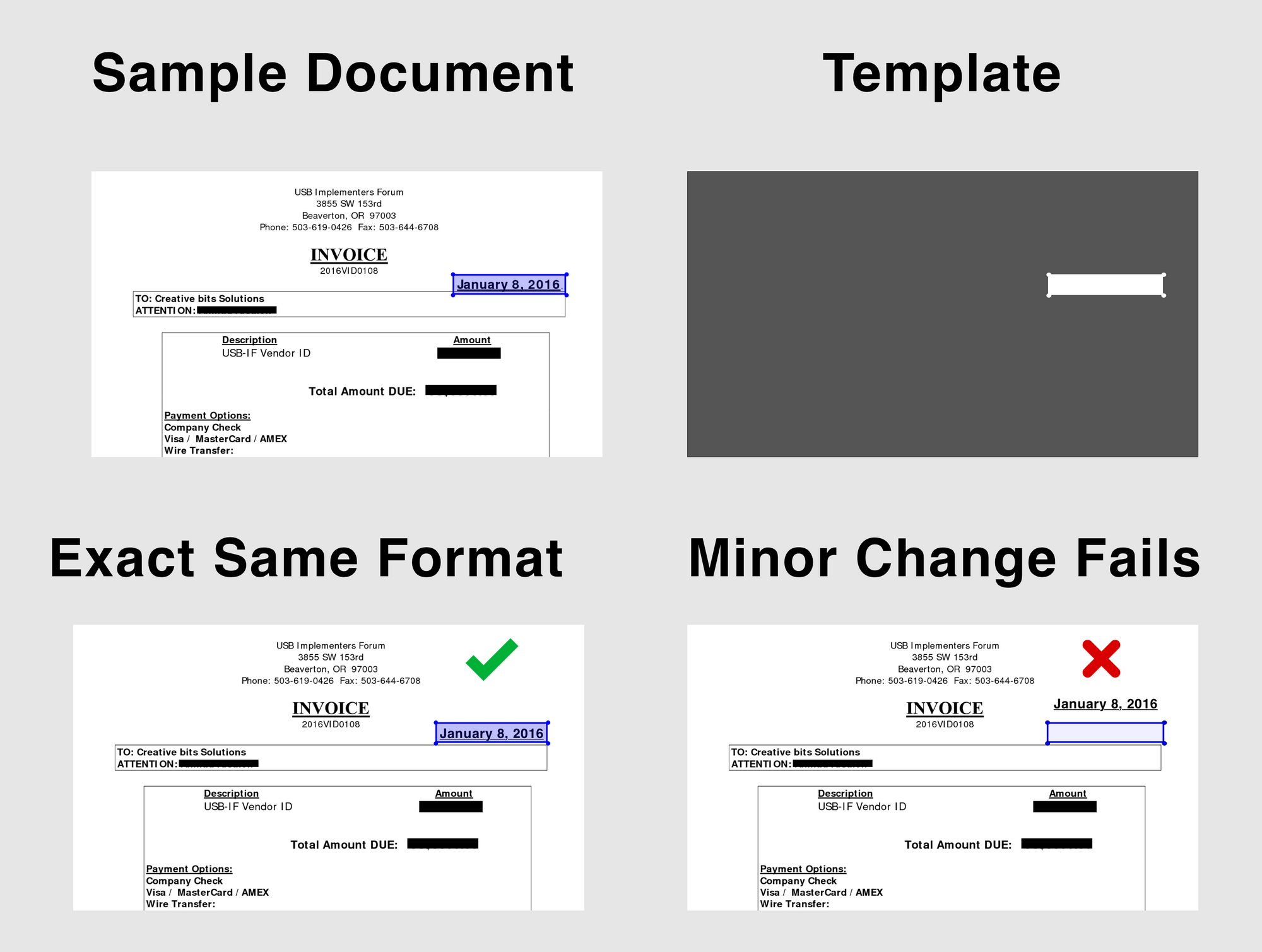
Template + Text Matching
This involves defining the exact region to look for a particular piece of information. So let’s say if you are looking to extract the date and the format is exactly the same across documents and the date occurs at the exact same place in the document. We define the area to look for in the document for the date.
Here is the process:
- Convert the document to an image
- We give a sample document
- Mark the region where the date is found (the document is viewed as a coordinate system where the top left corner is (0,0)) we might mark (200,300) to (350,450) which is the region of interest for the date
- When there is a new document we go and check (200,300) to (350,450) and extract the text there
Historically this has been one of the most common approaches to solving this problem. This is due to a variety of reasons:
- Simplicity of software and to implement. A competent programmer could create this solution in less than a day
- There is no uncertainty how the solution will work, if the document is exactly the same format it will work perfectly
- It requires very limited compute resources to extract the data
There are however some very obvious challenges given how rudimentary this method is:
- It doesn't work if there even a slight difference in documents
- It doesn't work if the Buyer updates their format
- For each buyer there is a new format that needs to be setup
- It doesn't work for scanned documents
OCR + NLP + Text Matching
OCR + NLP is a newer technique to extract data from documents. OCR is a fairly well studied problem and extracting text from documents works most of the time. The next step is to take all of the raw text that is extracted from the document and then try to parse each of the individual pieces of text in the document

Within NLP there a variety of techniques that can be employed to solve this problem
- Regex (Regular Expressions)
To extract a date a regular expression would look like:
^(?:(?:31(\/|-|\.)(?:0?[13578]|1[02]|(?:Jan|Mar|May|Jul|Aug|Oct|Dec)))\1|(?:(?:29|30)(\/|-|\.)(?:0?[1,3-9]|1[0-2]|(?:Jan|Mar|Apr|May|Jun|Jul|Aug|Sep|Oct|Nov|Dec))\2))(?:(?:1[6-9]|[2-9]\d)?\d{2})$|^(?:29(\/|-|\.)(?:0?2|(?:Feb))\3(?:(?:(?:1[6-9]|[2-9]\d)?(?:0[48]|[2468][048]|[13579][26])|(?:(?:16|[2468][048]|[3579][26])00))))$|^(?:0?[1-9]|1\d|2[0-8])(\/|-|\.)(?:(?:0?[1-9]|(?:Jan|Feb|Mar|Apr|May|Jun|Jul|Aug|Sep))|(?:1[0-2]|(?:Oct|Nov|Dec)))\4(?:(?:1[6-9]|[2-9]\d)?\d{2})$
Extracts 01/02/2020
Source: https://stackoverflow.com/questions/15491894/regex-to-validate-date-format-dd-mm-yyyy
The downside of the Regex based solution is that each new format needs to be programmed separately. If there is a new format it needs to be added to the regular expression. It does not identify if a particular date is the delivery date, due by date or date of the purchase order.
2. NER (Named Entity Recognition)
To extract field types using NER
results = stanford_ner_tagger.tag(article.split()) print('Original Sentence: %s' % (article)) for result in results: tag_value = result[0] tag_type = result[1] if tag_type != 'O': print('Type: %s, Value: %s' % (tag_type, tag_value))
Prints
Type: DATE, Value: 01/02/2020
Source: https://towardsdatascience.com/named-entity-recognition-3fad3f53c91e
The downside of NER based extraction is that it works well for well defined types but fails for a variety of types like addresses and things that are non standard formats. It works well for Dates, Currency, Phone numbers etc. It works occasionally for Names and Entities. It suffers from a similar problem of not knowing which date it is the delivery date, due by date or date of the purchase order.
3. Force Vendor / Buyer to use your software to submit document
If a Vendor or a Buyer has significant leverage in a transaction he can force the other party to use their software to submit their document. This removes most problems and offloads the entire responsibility to the vendor and no document digitisation is required. However this suffers from the obvious issue of not being ubiquitous and requires that the other party interact with your software. Even if a few 3 parties don't follow this protocol it requires a significant effort to add it to your existing system.
Deep Learning
Deep Learning technology has become fairly advanced in recent times in extracting data and more importantly extracting features that can lead to better predictions.
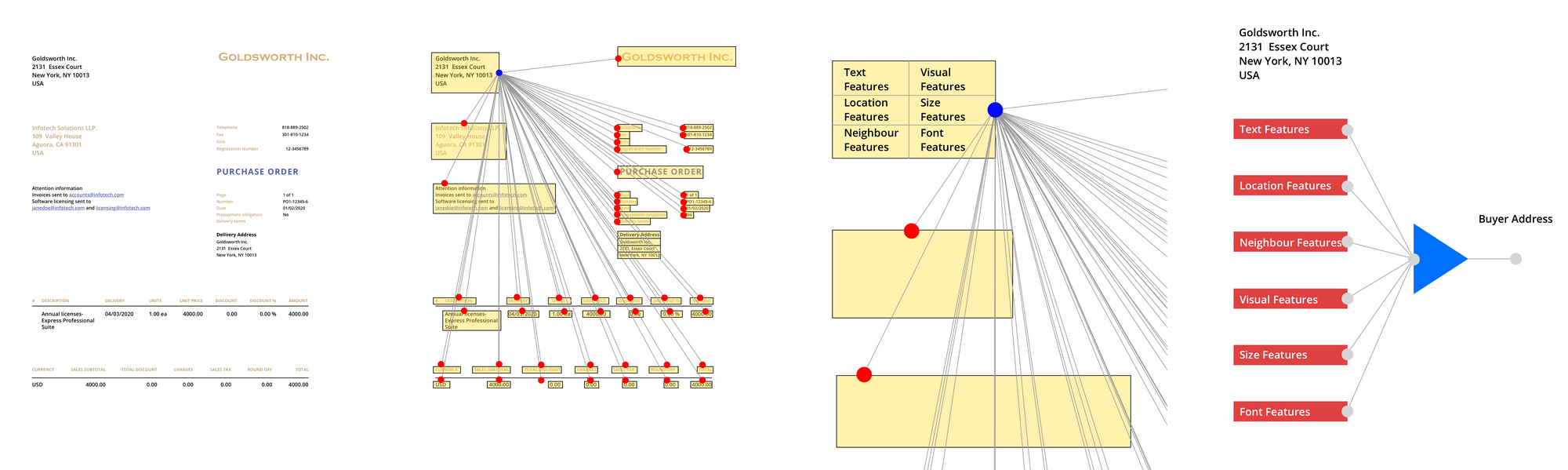
Data Extraction using Graph Convolutional Neural Networks
Graph Convolutional Neural Networks (GCN) can be used to extract data from these documents. We feed the GCN a variety of different features, each of which is used to be able to extract the correct information.
It can be broken down into 2 steps:
1. Feature Extraction
We extract various features from each text block.
a) Text Features
b) Visual Features
c) Location Features
d) Size Features
e) Font Features
2. Graph Creation
These features are created for each block of text and then a graph is created. For each text block it is passed the features of its neighbour. With the graph features and other features created for each text block it is then classified as one of the fields of interest or as None.
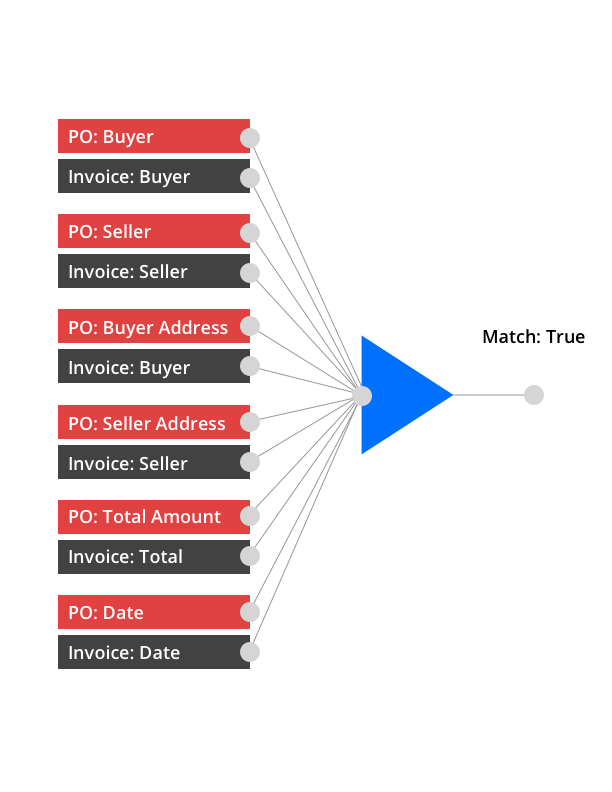
Document Matching
To match the documents Deep Learning is also a great solution where extracted fields from each of the document types can be parsed to give a final prediction if the documents match.
Problems with Deep Learning
There are two classes of information to be extracted
1. Problems with Key values (PO number, date, etc)

- Identifying key value pairs. They are not uniformly positioned across formats and unclear how many neighbours to look through.
- Taking multiple languages into account.
- Not enough data to train for a particular key (class imbalance)
2. Problems with Table values

- Classifying any box as table
- Missing tables in pages with multiple tables
- Merging two close columns
- Misinterpreting page borders as table borders
3. Other Problems
- Rotation and Cropping
- Poor quality images
- Data drift
Using Nanonets
Solving the Problems in using Deep Learning for OCR on Purchase Orders
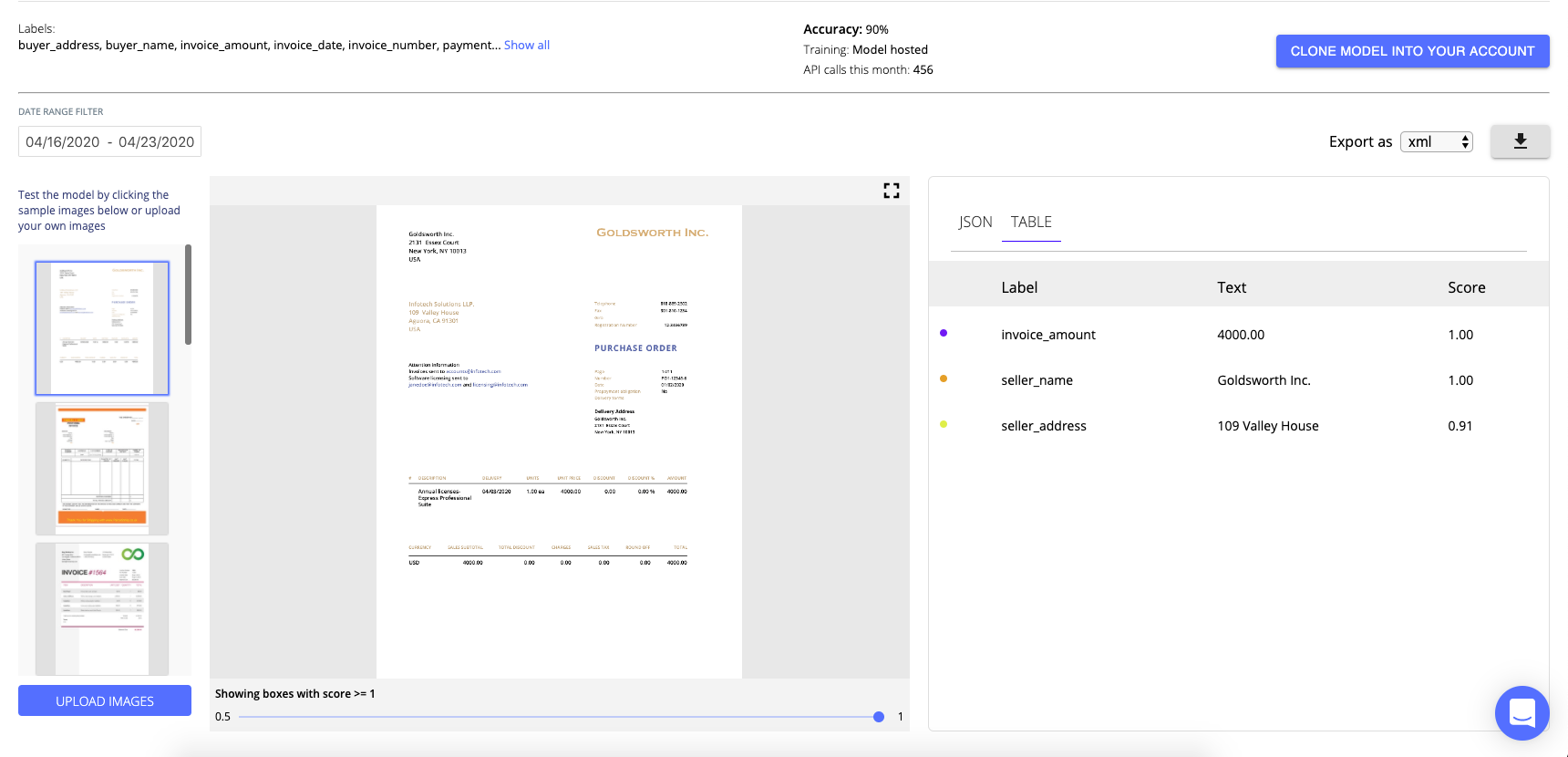
Using the Nanonets API You can automatically extract all the required keys required for matching documents. Just upload a document and get all the extracted fields returned in the format of your choosing.
We tackle most of the problems listed above so you don't have to spend time reinventing the wheel.
Key Value Pairs:
1.Identifying key value pairs. They are not uniformly positioned across formats.
Using our GCN implementation we are able to parse keys across documents. Our GCN implementation includes optimisations for finding the right neighbourhood search to get the best tread-off between feature explosion and lack of context for the model to correctly interpret which key each belongs to
2. Taking multiple languages into account.
Our models have been trained with text embeddings that are language agnostic. This is achieved by creating a feature space such that the word embeddings for 'Invoice' and 'Faktura' (Invoice in German) and चलाना (Invoice in Hindi) all map to the same feature space. So the text features become language independent and the model need not be trained per language. Nanonets can be used as OCR software in 200+ more languages.
3. Not enough data to train for a particular key (class imbalance)
We have a large corpus of financial documents our models are trained on which mitigates this issue.
Tables
1.Classifying any box as table
We have built a robust classifier which can identify a variety of different tables in different formats and settings. This uses a mixture of visual features and layout features along with text based features to identify the structure of the table.
2. Missing tables in pages with multiple tables
Having identified each of the different table structures across pages we have a merge logic that decides if the structure is similar enough to merge and if a table on a previous page was incomplete to determine if two tables should be merged.
3. Merging two close columns
If we rely solely on visual features this becomes a problem as it is difficult to identifying space based separation. However with the inclusion of visual text and position based features it becomes possible to identify where the kind of data contained in a column is different enough to be called a new column.
4. Misinterpreting page borders as table borders
Similar to the above this problem is solved by using a variety of features to determine if a particular structure is a table or a page border.
Other Problems
1.Rotation and Cropping
We've implemented a rotation and cropping model as a part of our pre processing step to identify the edges of a document and then correctly orient the document. This uses a model similar to an object detection model with the objective function modified to identify 4 corners as opposed to 2 points that is standard in an object detection problem. This solves for both rotation and cropping
2. Blur and Poor document quality
We have a quality model placed as a part of our preprocessing pipeline that only accepts documents above a certain quality threshold. This is a binary classifier which is a simple image classification model trained on a number of documents that are both good and bad quality. In the document capture pipeline documents can be rejected early if they don't meet the quality standards required and can be sent for recapture or manual processing.
2. Data drift
Data drift is a problem when the model is exposed only to data from a single vendor or single region. If the model has been historically trained on a variety of different vendors, geographies industries etc the possibility of data drift greatly reduces since it has already been exposed to these variances.
Start Digitising POs and Invoices Now with Nanonets - 1 Click PO Digitisation and streamline sales order automation:
Further Reading
- Purchase Order processing automation
- Cardinal Graph Convolution Framework for Document Information Extraction
- 4 Challenges of Transitioning from a Legacy Procurement System to Automation
Update 1:
Added further reading material around extracting information from Purchase Orders and using OCR for Automation
Update 2: We have significantly improved the accuracies of our models to extract data from POs.
Setup a Demo
Setup a demo to learn about how Nanonets can help you solve this problem